






廖昊
1
{ }^{1}
1,卢文盛
1
{ }^{1}
1,连建勋
2
∗
{ }^{2 *}
2∗,吴明奇
3
{ }^{3}
3,王硕
1
{ }^{1}
1,张勇
1
{ }^{1}
1,黄义天
1
{ }^{1}
1,周明阳
1
{ }^{1}
1,谢星
2
{ }^{2}
2
1
{ }^{1}
1 中国深圳大学
2
{ }^{2}
2 微软亚洲研究院
3
{ }^{3}
3 微软游戏
haoliao@szu.edu.cn, jianxun.lian@outlook.com
摘要
大型语言模型(LLMs)因其在用户交互方面的变革能力,在生成式推荐系统中显示出潜力。然而,确保它们不推荐域外(OOD)项目仍然是一个挑战。我们研究了两种不同的方法来解决这个问题:RecLM-ret,一种基于检索的方法,和RecLM-cgen,一种约束生成方法。这两种方法都能与现有的LLMs无缝集成,以确保域内推荐。在三个推荐数据集上的全面实验表明,RecLM-cgen在准确性方面始终优于RecLM-ret和现有的基于LLM的推荐模型,同时消除了OOD推荐,使其成为首选采用的方法。此外,RecLM-cgen保持了强大的通才能力,并且是一个轻量级的即插即用模块,可以轻松集成到LLMs中,为社区提供了宝贵的实用好处。源代码可在https://github.com/microsoft/RecAI获取
1 引言
大型语言模型(LLMs)在各种任务中表现出显著的能力,如语言生成、推理和指令跟随。将LLMs转化为领域特定专家的趋势正在医疗保健(Cascella等人,2023年)、游戏(Wan等人,2024年)、软件开发(Jin等人,2024年)和教育(Wang等人,2025年)等领域增长。研究人员也在利用LLMs进行推荐系统,特别是对话式推荐,因为LMs提供了多个重要优势,如基于文本的内容融合、冷启动推荐、详细解释、跨域偏好推理和互动可控性。这些优势使LLMs成为推进推荐系统的一个令人兴奋的研究领域。
一些研究集中在构建带有LLMs的推荐模型上。(Yao等人,2023年)将领域特定模式注入提示中,而(Gao等人,2023年;Huang等人,2023年)使用代理框架来改进LLMs的推荐能力,而不改变原始LLMs。其他方法涉及通过领域知识微调LLMs(Lu等人,2024年;Zhang等人,2024年;Ji等人,2024年)。虽然这些方法提高了从基础LLMs的推荐准确性,但它们仍然可能导致域外(OOD)项目推荐(即推荐当前领域中不存在的项目),从而可能带来负面的商业影响。
在本文中,我们解决了OOD项目推荐问题,以增强基于LLM的推荐的可信度。我们研究了两种独特的针对微调推荐语言模型(RecLM)的接地方法:
- RecLM-ret: 基于检索的方法。每次RecLM想要推荐一个项目时,它首先输出一个特殊标记,这表示项目标题的开始。而不是像平常一样继续生成项目标题,这种方法使用当前标记的情境嵌入,根据嵌入相似性从领域数据集中检索最相关的项目。
-
- RecLM-cgen: 约束生成方法。我们首先基于当前领域的项目标题构建前缀树。每次RecLM生成标记时,这种方法都会在前缀树上启动约束生成过程,直到生成完整的项目标题。
一个自然的担忧是,这两种方法是否会引荐准确性和消除域外项目之间的权衡。为了验证这一点,我们在三个公共推荐数据集上进行了全面的实验。结果表明,尽管RecLM-ret通常会
- RecLM-cgen: 约束生成方法。我们首先基于当前领域的项目标题构建前缀树。每次RecLM生成标记时,这种方法都会在前缀树上启动约束生成过程,直到生成完整的项目标题。
2
∗
{ }^{2 *}
2∗ 对应作者
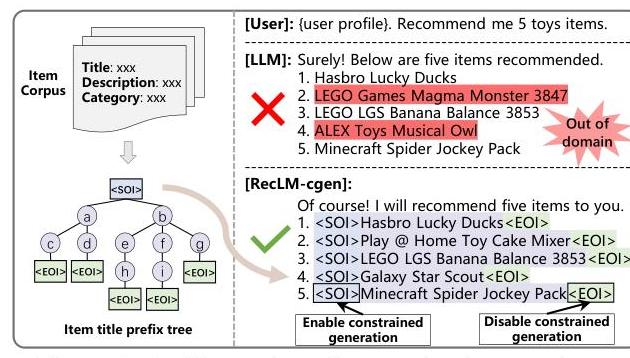
图1:受约束生成的插图
| 数据集 | 指标 | Llama3 | Llama3-cgen | RecLM-cgen |
|---|---|---|---|---|
| Steam | NDCG 910 OOD 910 \begin{aligned} & \text { NDCG } 910 \\ & \text { OOD } 910 \end{aligned} NDCG 910 OOD 910 | 0.0120 15.26 % \begin{aligned} & 0.0120 \\ & 15.26 \% \end{aligned} 0.012015.26% | 0.0125 2.59 % \begin{aligned} & 0.0125 \\ & 2.59 \% \end{aligned} 0.01252.59% |
0.0433
\mathbf{0 . 0 4 3 3}
0.0433 0.00 % \mathbf{0 . 0 0 \%} 0.00% |
| Movies | NDCG 910 OOD 910 \begin{aligned} & \text { NDCG } 910 \\ & \text { OOD } 910 \end{aligned} NDCG 910 OOD 910 | 0.0025 52.52 % \begin{aligned} & 0.0025 \\ & 52.52 \% \end{aligned} 0.002552.52% | 0.0106 11.91 % \begin{aligned} & 0.0106 \\ & 11.91 \% \end{aligned} 0.010611.91% |
0.1296
\mathbf{0 . 1 2 9 6}
0.1296 0.00 % \mathbf{0 . 0 0 \%} 0.00% |
| Toys | NDCG 910 OOD 910 \begin{aligned} & \text { NDCG } 910 \\ & \text { OOD } 910 \end{aligned} NDCG 910 OOD 910 | 0.0020 90.99 % \begin{aligned} & 0.0020 \\ & 90.99 \% \end{aligned} 0.002090.99% | 0.0153 4.16 % \begin{aligned} & 0.0153 \\ & 4.16 \% \end{aligned} 0.01534.16% |
0.0479
\mathbf{0 . 0 4 7 9}
0.0479 0.00 % \mathbf{0 . 0 0 \%} 0.00% |
表1:约束生成有效解决域外推荐问题
表现为准确性和可信度之间的权衡,RecLM-cgen没有表现出这种权衡。相反,RecLM-cgen在准确性方面始终优于RecLM-ret和现有的基于LLMs的推荐器。进一步分析显示,RecLM-cgen在多轮对话中表现出色并保持通才能力,使其成为首选方法。图1说明了RecLM-cgen的工作流程,表1提供了一个快速性能概述,其中RecLM-cgen实现了最高的准确性和消除了OOD问题。总结一下,本文的主要贡献如下:
- 我们通过应用两种简单而有效的方法:RecLM-ret和RecLM-cgen,解决了OOD项目推荐的问题。我们提出了一种统一框架,将这两种不同的接地范式整合起来进行比较。
-
- 我们对RecLM-ret和RecLM-cgen在总体准确性和训练动态方面的深入分析进行了对比,得出结论RecLM-cgen是优选采用的方法。这些研究为研究社区提供了有价值的见解和经验。
-
- 我们在三个公共推荐数据集上进行了广泛的实验。结果表明,RecLM-cgen在解决域外推荐问题的同时,始终优于现有的基于LLM的推荐方法。
2 相关工作
2.1 大型语言模型在推荐系统中的应用
大型语言模型(LLMs)对包括推荐系统在内的各种NLP应用产生了重大影响。其在促进新型生成推荐系统方面的潜力已被广泛认可(Wu等人,2024;Lian等人,2024;Lyu等人,2024;Ji等人,2024)。Said(2025)提供了一份关于使用LLMs生成推荐解释的文献综合评论。Yao等人(2023)和Bacciu等人(2024)介绍了选择性地将领域特定知识注入提示中的方法,以增强LLMs的推荐能力,而无需微调。另一条研究线专注于微调LLMs以注入领域知识,展示了推荐性能的重大改进(Zhang等人,2024;Lu等人,2024;Yang等人,2023;Zhu等人,2024)。然而,这些方法经常面临生成域外(OOD)项目的挑战,LLMs可能会推荐当前领域中不存在的项目,从而可能导致负面的商业影响。
2.2 解决OOD推荐问题
OOD项目生成问题是部署基于LLM的推荐器的关键挑战。Bao等人(2025)提出了一种先生成后对齐的方法,以确保推荐项目在领域项目集内有根。Gao等人(2023)和Huang等人(2023)利用代理框架,其中LLMs充当控制器和自然语言界面进行用户交互。当进行推荐时,这些框架调用传统的推荐模型来检索相关项目。另一个有前景的方向是约束生成。这种范式将LLM的解码空间限制在由上下文条件化的子空间内,从而避免OOD生成(Dong等人,2024)。约束生成方法保持传统语言生成过程,不需要对LLM进行重大修改。虽然一些研究探索了约束生成在一般NLP任务中的应用(Geng等人,2025;Park等人,2025;Beurer-Kellner等人,2024;Koo等人,2024),例如格式化结构化输出(如API调用或JSON格式),但在生成推荐中的应用仍较少被探索。
3 方法论
我们的目标是避免推荐域外项目,使基于LLM的推荐器更可靠,适用于工业服务。实现这一目标基本上有两种范式:域内检索范式和约束生成范式。我们设计了一个简单的框架,该框架只需对骨干LLM(如Llama 3)进行最小修改即可适应这两种方法,允许在一个统一的设置下公平比较它们的有效性。关键策略涉及引入一个特殊的项目指示符。
3.1 特殊项目指示符标记
我们将两个特殊标记和添加到骨干模型的词汇表中。这些标记分别表示项目开始和项目结束。我们将微调后的LLM称为RecLM。每当RecLM推荐一个项目时,它会首先输出标记,随后输出标记,如序列:项目标题所示。通过利用这两个特殊标记,LLM的生成过程可以分为两个不同的阶段:项目生成阶段和普通文本生成阶段。当LLM输出标记时,它标志着项目生成阶段的开始。相反,输出标记则标志着项目生成阶段的结束,使模型回到普通文本生成阶段。基于这个框架,在项目生成阶段,我们可以采用域内检索范式(导致RecLM-ret)或约束生成范式(导致RecLM-cgen),以防止生成超出预定义域的项目,如图2所示。
3.2 RecLM-ret
在此方法中,我们首先使用bge-m3(Chen等人,2024)为每个目标域中的项目 i i i生成项目嵌入 e i \mathbf{e}_{i} ei,通过将标题、描述和类别信息作为输入文本连接起来。然后我们得到域项目嵌入基 E = { e i } \mathcal{E}=\left\{\mathbf{e}_{i}\right\} E={ei}。
接下来,当RecLM输出标记时,我们提取与此标记关联的最后一层隐藏表示 h < S O I > ( i ) \mathbf{h}_{<S O I>}^{(i)} h<SOI>(i)。然后使用投影层将 h < S O I > ( i ) \mathbf{h}_{<S O I>}^{(i)} h<SOI>(i)与预先生成的项目嵌入向量空间 E \mathcal{E} E对齐。最后,根据相似度得分检索推荐项目,并将检索到的项目标题以及结束标记与当前生成文本连接。
在训练阶段,我们使用提示模板将用户行为 < I history ( 1 , . . n ) , I rec ( 1 , . k ) > <I_{\text {history }}^{(1, . . n)}, I_{\text {rec }}^{(1, . k)}> <Ihistory (1,..n),Irec (1,.k)>转换为监督微调(SFT)数据样本: < < < 指令: X X X,响应: Y > Y> Y>。 I history ( 1 , . . n ) I_{\text {history }}^{(1, . . n)} Ihistory (1,..n)包含用户的历次交互项目列表,这些项目作为指令: X X X中的用户画像,而 I rec ( 1 , . . k ) I_{\text {rec }}^{(1, . . k)} Irec (1,..k)是推荐给用户的 k k k个项目列表,这些项目作为响应: Y Y Y中的标签。我们遵循(Lu等人,2024)中的数据增强经验,即 I rec ( 1 , . k ) I_{\text {rec }}^{(1, . k)} Irec (1,.k)中的第一个项目是用户历史中的下一个实际交互项目(即 I history n + 1 I_{\text {history }}^{n+1} Ihistory n+1),其余项目 ( I rec ( 2 , . k ) ) \left(I_{\text {rec }}^{(2, . k)}\right) (Irec (2,.k))由传统的推荐器SASRec(Kang和McAuley,2018)增强。相关提示见附录A.3。我们不对属于项目标题和标记的响应: Y Y Y中的标记计算损失,如方程(1)所示。这里, θ \theta θ表示基础模型的可训练参数。
L Im = ∑ j = 1 Y j ∉ { item, <EOI> } ∣ Y ∣ − log P θ ( Y j ∣ Y < j , X ) \mathcal{L}_{\text {Im }}=\sum_{\substack{j=1 \\ Y_{j} \notin\{\text { item, <EOI> }\}}}^{|Y|}-\log P_{\theta}\left(Y_{j} \mid Y_{<j}, X\right) LIm =j=1Yj∈/{ item, <EOI> }∑∣Y∣−logPθ(Yj∣Y<j,X)
用于检索任务的损失函数用于训练模型如何检索相关项目。我们获得响应: Y Y Y中所有 k k k个项目的隐藏层向量 h < S O I > ( 1 , . k ) \mathbf{h}_{<S O I>}^{(1, . k)} h<SOI>(1,.k)。然后将这些向量输入到投影层 proj ϕ ( h < S O I > ( j ) ) \operatorname{proj}_{\phi}\left(\mathbf{h}_{<S O I>}^{(j)}\right) projϕ(h<SOI>(j))。随后,我们在这些投影向量和所有项目 E \mathcal{E} E的嵌入之间进行相似度匹配。此过程的损失函数如方程(2)所示。最终的整体训练损失如方程(3)所示。
L ret = 1 k ∑ j = 1 k σ ( proj ϕ ( h < S O I > ( j ) ) ⋅ e j ) L RecLM-ret = L Im + α ret ∗ L ret \begin{gathered} \mathcal{L}_{\text {ret }}=\frac{1}{k} \sum_{j=1}^{k} \sigma\left(\operatorname{proj}_{\phi}\left(\mathbf{h}_{<S O I>}^{(j)}\right) \cdot \mathbf{e}_{j}\right) \\ \mathcal{L}_{\text {RecLM-ret }}=\mathcal{L}_{\text {Im }}+\alpha_{\text {ret }} * \mathcal{L}_{\text {ret }} \end{gathered} Lret =k1j=1∑kσ(projϕ(h<SOI>(j))⋅ej)LRecLM-ret =LIm +αret ∗Lret
这里的 σ ( ⋅ ) \sigma(\cdot) σ(⋅)是softmax函数,旨在最大化真实项目 e j \mathbf{e}_{j} ej相对于 E \mathcal{E} E中所有项目的相似度。 α ret \alpha_{\text {ret }} αret 是一个权重超参数。
3.3 RecLM-cgen
在此方法中,我们使用基于前缀树的约束生成策略。我们首先基于目标域中的所有项目标题构建前缀树。在生成阶段,一旦LLM生成
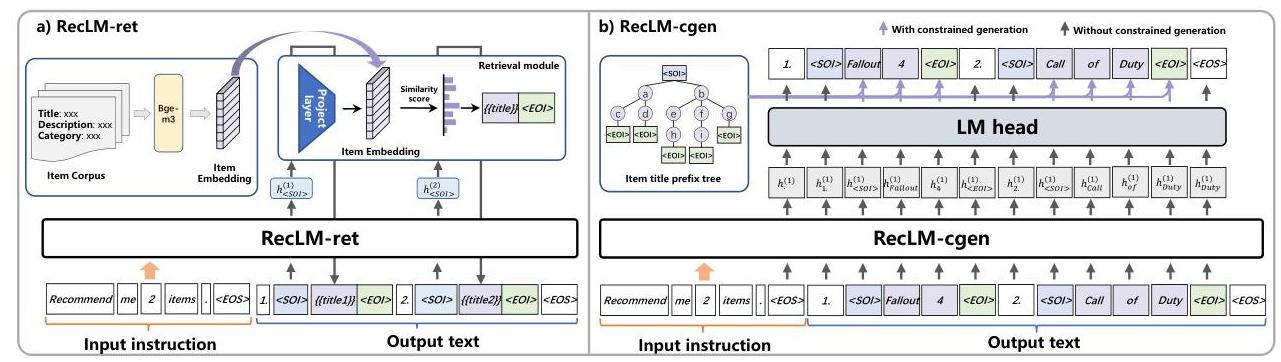
图2:两种替代范式的图形说明:RecLM-ret和RecLM-cgen。
标记时,我们激活约束生成,从而将LLM的生成空间限制在域内项目的标题上。生成标记时,我们停用约束生成,使模型过渡到普通文本生成阶段。RecLM-cgen的一个关键特点是其推断的简单性,如图3所示。
Clin: FastPref(aContrainedLogitsProcessor(LogitsProcessor):
def _control
self;
iten_title_set: list[str];
start_control_symbol: str,
end_control_symbol: str,
tokenizer
}
…
logits_processor = fastPref(aContrainedLogitsProcessor(
iten_title_set, # 所有域内项目标题
start_control_symbol, # 开始控制符号标记
end_control_symbol, # 结束控制符号标记
tokenizer # 模型分词器
)
output = model.generate(**input_data, logits_processor=[logits_processor])
图3:RecLM-cgen仅需几行代码更改即可进行推断
范围掩码训练 考虑到在前缀树上解码标记时,模型的下一标记概率不是在整个标记词汇表上,而是受限于前缀树中可见的子集标记,我们在RecLM-cgen的训练中引入范围掩码损失以保持训练和推断之间的一致性。在计算与项目标题相关的标记损失时,仅将前缀树中的标记包含在softmax函数的分母中:
L cgen o m = ∑ j = 1 ∣ Y ∣ − log logit ( Y j ∣ Y < j , X , θ ) ∑ t ∈ N T ( Y < j ) logit ( t ∣ Y < j , X , θ ) \mathcal{L}_{\text {cgen }}^{\mathrm{om}}=\sum_{j=1}^{|Y|}-\log \frac{\operatorname{logit}\left(Y_{j} \mid Y_{<j}, X, \theta\right)}{\sum_{t \in \mathrm{NT}\left(Y_{<j}\right)} \operatorname{logit}\left(t \mid Y_{<j}, X, \theta\right)} Lcgen om=j=1∑∣Y∣−log∑t∈NT(Y<j)logit(t∣Y<j,X,θ)logit(Yj∣Y<j,X,θ)
这里, N T ( Y < j ) \mathrm{NT}\left(Y_{<j}\right) NT(Y<j)是一个函数,给定一个前缀标记序列,返回基于指定推荐域的可能下一标记集合。如果当前标记 Y j Y_{j} Yj位于普通文本部分(例如,在结束控制符号之后),该函数返回整个标记词汇表。如果当前标记 Y j Y_{j} Yj位于项目标题部分(例如,在和之间),该函数返回基于前缀树的候选标记集。
多轮对话数据 我们观察到,如果只包括单轮SFT样本如<指令: X X X,响应: Y Y Y>,模型倾向于塌陷为单轮推荐,显著降低其通用能力。因此,我们将大约 10 % 10 \% 10%的多轮对话(MRC)数据样本纳入训练集。这些MRC样本是通过从ShareGPT 1 { }^{1} 1语料库中随机选择一个数据样本,并将其与单轮推荐任务样本结合创建的。推荐任务样本出现在ShareGPT对话之前的可能性为 50 % 50 \% 50%,出现在之后的可能性为 50 % 50 \% 50%。
4 实验
4.1 实验设置
数据集 我们在三个现实世界的公共数据集上进行实验:Steam 2 { }^{2} 2、Amazon Movies & TV 3 { }^{3} 3(简称为Movies)和Amazon Toys & Games 3 { }^{3} 3(简称为Toys)(Ni等人,2019)。我们遵循先前的工作(Kang和McAuley,2018;Lu等人,2024),采用留一法进行训练和评估。原始数据集的预处理从过滤掉少于17次交互的用户开始。随后,我们随机抽取10k用户,并按时间顺序排列每位用户的交互序列,限
1
{ }^{1}
1 https://huggingface.co/datasets/anon8231489123/ ShareGPT_Vicuna_unfiltered
2
{ }^{2}
2 https://www.kaggle.com/datasets/antonkozyriev/ game-recommendations-on-steam
3
{ }^{3}
3 https://mcauleylab.ucsd.edu/public_datasets/data/ amazon_v2/categoryFiles
制每位用户的最近交互次数为17次。每位用户的交互序列中的最后一次交互用于测试,倒数第二次交互保留用于验证,其余15次交互用于训练。表A1列出了数据集的基本统计信息。
实现 我们使用Llama3-8b-instruct
4
{ }^{4}
4作为主干来训练RecLM-ret和RecLM-cgen。用户行为的截止长度(作为指令中的用户画像)为10。模型的最大输入和输出长度分别为512个标记。使用PEFT
5
{ }^{5}
5中实现的LoRA方法微调LLMs的所有线性层,优化器为Adam。学习率为
1
e
−
4
1 e-4
1e−4,lora
r
r
r为16,lora alpha为8,批次大小为64。通过多次实验,我们发现训练通常在20个epoch内收敛。此外,控制符号和的标记嵌入分别初始化为对应于"start of an item"和"end of an item"文本的平均嵌入。
指标 我们使用Top-k命中率
(
H
R
@
K
)
(H R @ K)
(HR@K)和Top-k标准化折扣累积增益(
N
D
C
G
@
K
N D C G @ K
NDCG@K)来评估推荐的准确性,因为这是推荐系统中最广泛使用的两个指标。为了评估LLMs推荐能力的可靠性,我们采用了两个额外的指标:Repeat@k,衡量在Top-k推荐中重复项目的概率,以及
O
O
D
@
k
O O D @ k
OOD@k,表示推荐项目中落在指定域外的比例。
4.1.1 基线
传统推荐模型:鉴于我们的实验设置涉及到顺序推荐任务,我们将我们的方法与该领域的一些最受欢迎的模型进行比较。这些模型包括单纯根据流行度推荐、SASRec(Kang和McAuley,2018)和GRU4Rec(Hidasi等人,2016)。SASRec和GRU4Rec是基于ID的顺序模型,不使用项目的文本内容作为输入。由于基于ID和基于语言的模型代表了推荐系统中的两种不同范式,本文的目标并不是用基于语言的推荐器超越基于ID的推荐器。相反,这些基准模型用作参考
以衡量基于LLM的推荐器的性能。
通用目的LLMs:我们利用闭源LLMs,具体是gpt-4-0613(称为GPT4)和gpt-4o-2024-05-13(称为GPT-4o)来自Azure OpenAI。此外,我们还使用开源LLM Llama3-8b-instruct(称为Llama3,正是调整RecLMs的基础模型)。Llama3的一个变体称为Llama3cgen也被使用。在此方法中,我们提示Llama3在提到项目前输出特殊符号,然后它就会启动我们的约束生成。
微调LLMs:BIGRec(Bao等人,2025):该方法微调LLM以生成与推荐项目相关的信息,然后使用嵌入模型(bge-m3)将生成的文本映射到域项目语料库。CtrlRec(Lu等人,2024):该方法强调基于LLM的推荐模型的可控性。它采用两个训练阶段:监督微调(SFT)和强化学习。在SFT过程中,CtrlRec还使用SASRec作为教师模型进行数据增强。PALR(Yang等人,2023):该模型仅依赖SFT来利用大型模型的学习推荐任务的能力。由于(Lu等人,2024)证明使用SASRec进行数据增强可以显著提高准确性,我们在实验中也为PALR(以及RecLMs)启用了此配置。本组中的所有三个基准都使用Llama3作为主干模型。
4.2 总体性能
表2报告了总体结果。我们有几个观察:
首先,关于本文最受关注的指标OOD @ 10,两种范式,即RecLM-ret和RecLM-cgen,都成功避免了推荐域外项目,OOD @ 10指标降至零。此外,检索范式和约束生成范式都有效地确保了范围内的推荐,这可以归因于RecLM精确输出标记的能力(我们将在小节4.3.3中有更多讨论)。
其次,在推荐准确性方面,RecLM-cgen的表现优于所有其他基于LLM的基线,包括其对应方法RecLM-ret。这表明RecLM-cgen在避免OOD推荐的同时,并没有牺牲推荐准确性,
4
{ }^{4}
4 https://huggingface.co/meta-llama/Meta-Llama-3-8B
5
{ }^{5}
5 https://github.com/huggingface/peft
| 指标 | 传统推荐器 | LLMs (冻结) | LLMs (微调) | LLMs (我们的) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 流行度 | SASRec | GRU4Rec | GPT-4 | GPT-4o | Llama3 | Llama3-cgen | BIGRec | CtrlRec | PALR | RecLM-ret | RecLM-cgen | ||
| 数据集: Steam | |||||||||||||
| HB/010 ↑ \uparrow ↑ | 0.0266 | 0.0694 | 0.0589 | 0.0247 | 0.0263 | 0.0230 | 0.0261 | 0.0396 | 0.0736 | 0.0720 | 0.0453 | 0.0797(+5.4%) | |
| NDCG/010 ↑ \uparrow ↑ | 0.0121 | 0.0308 | 0.0281 | 0.0131 | 0.0194 | 0.0120 | 0.0125 | 0.0244 | 0.0397 | 0.0408 | 0.0248 | 0.0433(+6.1%) | |
| HB/05 ↑ \uparrow ↑ | 0.0132 | 0.0428 | 0.0323 | 0.0163 | 0.0234 | 0.0136 | 0.0147 | 0.0291 | 0.0507 | 0.0488 | 0.0337 | 0.0540(+6.5%) | |
| NDCG/05 ↑ \uparrow ↑ | 0.0077 | 0.0224 | 0.0193 | 0.0104 | 0.0147 | 0.0090 | 0.0088 | 0.0201 | 0.0318 | 0.0305 | 0.0211 | 0.0360(+13.2%) | |
| repeat/010 ↓ \downarrow ↓ | - | - | - | 2.56% | 1.07% | 2.06% | 0.00% | 0.00% | 1.08% | 1.05% | 0.00% | 0.00% | |
| OOD/010 ↓ \downarrow ↓ | - | - | - | 45.12% | 16.08% | 15.26% | 2.59% | 0.00% | 2.40% | 2.46% | 0.00% | 0.00% | |
| 数据集: Movies | |||||||||||||
| HB/010 ↑ \uparrow ↑ | 0.0095 | 0.1510 | 0.0722 | 0.0350 | 0.0046 | 0.0049 | 0.0246 | 0.0861 | 0.1347 | 0.1335 | 0.1131 | 0.1424(+5.7%) | |
| NDCG/010 ↑ \uparrow ↑ | 0.0043 | 0.1201 | 0.0556 | 0.0150 | 0.0028 | 0.0025 | 0.0106 | 0.0760 | 0.1248 | 0.1244 | 0.1018 | 0.1296(+3.8%) | |
| HB/05 ↑ \uparrow ↑ | 0.0047 | 0.1422 | 0.0625 | 0.0122 | 0.0027 | 0.0029 | 0.0123 | 0.0823 | 0.1304 | 0.1294 | 0.1056 | 0.1365(+4.7%) | |
| NDCG/05 ↑ \uparrow ↑ | 0.0027 | 0.1323 | 0.0525 | 0.0079 | 0.0022 | 0.0019 | 0.0064 | 0.0747 | 0.1234 | 0.1230 | 0.0993 | 0.1277(+3.5%) | |
| repeat/010 ↓ \downarrow ↓ | - | - | - | 8.34% | 0.89% | 3.15% | 0.00% | 0.00% | 9.02% | 34.69% | 0.00% | 0.00% | |
| OOD/010 ↓ \downarrow ↓ | - | - | - | 57.36% | 61.21% | 52.52% | 11.91% | 0.00% | 8.13% | 14.85% | 0.00% | 0.00% | |
| 数据集: Toys | |||||||||||||
| HB/010 ↑ \uparrow ↑ | 0.0073 | 0.0589 | 0.0389 | 0.0084 | 0.0031 | 0.0039 | 0.0354 | 0.0405 | 0.0473 | 0.0438 | 0.0553 | 0.0642(+16.1%) | |
| NDCG/010 ↑ \uparrow ↑ | 0.0037 | 0.0484 | 0.0228 | 0.0063 | 0.0013 | 0.0020 | 0.0153 | 0.0272 | 0.0378 | 0.0369 | 0.0412 | 0.0479(+16.3%) | |
| HB/05 ↑ \uparrow ↑ | 0.0044 | 0.0529 | 0.0276 | 0.0063 | 0.0021 | 0.0019 | 0.0191 | 0.0311 | 0.0426 | 0.0407 | 0.0406 | 0.0534(+14.6%) | |
| NDCG/05 ↑ \uparrow ↑ | 0.0027 | 0.0464 | 0.0192 | 0.0056 | 0.0010 | 0.0013 | 0.0104 | 0.0242 | 0.0363 | 0.0359 | 0.0384 | 0.0444(+15.6%) | |
| repeat/010 ↓ \downarrow ↓ | - | - | - | 8.52% | 0.31% | 2.10% | 0.00% | 0.00% | 5.91% | 29.50% | 0.00% | 0.00% | |
| OOD/010 ↓ \downarrow ↓ | - | - | - | 64.67% | 89.57% | 90.99% | 4.16% | 0.00% | 7.80% | 37.90% | 0.00% | 0.00% |
表2:不同方法在三个数据集上的性能比较。最佳结果以粗体突出显示,次佳结果以下划线表示。值得注意的是,传统推荐器组中的方法仅作为参考,不参与最佳或次佳性能的确定。
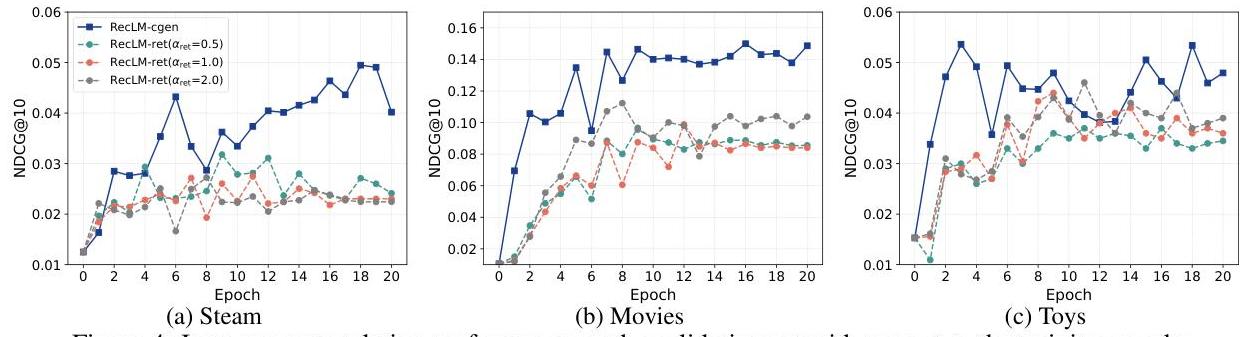
图4:关于训练epoch的验证集项目推荐性能。
反而增强了两方面。此外,Repeat@10指标保持在最优水平(
0
%
0 \%
0%),表明该方法成功避免了(Lu等人,2024)中提到的重复项目格式化问题。因此,我们建议RecLM-cgen作为生成推荐的首选方法。为了更好地理解RecLM-ret和RecLM-cgen的模式,我们在图4中进一步绘制了训练收敛曲线,包括系数
α
ret
\alpha_{\text {ret }}
αret 的三种不同值。由于生成评估非常耗时,我们在图4中仅使用验证集的320个数据样本。尽管有限的数据导致曲线波动,但模式仍然清晰。RecLM-cgen收敛到更好的状态,显示出更强的能力。更多讨论请参见小节A.6。
第三,BIGRec和RecLM-ret都属于避免域外推荐的映射范式。尽管RecLM-ret比BIGRec有所改进,但两者在推荐准确性方面都逊色于诸如CtrlRec、PALR和RecLM-cgen等生成方法。这表明两阶段映射范式可能牺牲推荐准确性以确保范围内的可靠性。Llama3-cgen的OOD@10指标未降至 0 % 0 \% 0%,这可归因于Llama3-cgen较弱的指令跟随能力。偶尔,它会在未先生成项目起始符号的情况下提及项目标题。
最后,关于传统的基于ID的推荐器如SASRec和GRU4Rec,尽管本文重点在于基于LLM的生成推荐器,并不旨在在准确性方面超越基于ID的推荐器,但SASRec和GRU4Rec提供了一个有用的参考来衡量生成推荐器的性能水平。如表2所示,RecLM-cgen在两个数据集上取得了与SASRec相当的结果,其中一个数据集表现优于SASRec,而在另一个数据集上略逊一筹。这表明生成推荐器具有提供令人满意的准确性的巨大潜力。此外,生成推荐器相较于传统的基于ID的推荐器具有多重优势,
如生成推理和解释以及支持对话式推荐。因此,基于LLM的生成推荐器可能为新一代推荐系统的变革铺平道路。
4.3 深入分析
| 数据集 | 指标 | v0 | v1 | v2 | full |
|---|---|---|---|---|---|
| HR@10 ↑ \uparrow ↑ | 0.0731 | 0.0749 | 0.0746 | 0.0797 | |
| N D C G @ 10 ↑ \mathrm{NDCG} @ 10 \uparrow NDCG@10↑ | 0.0396 | 0.0406 | 0.0410 | 0.0433 | |
| Steam | H R @ 5 ↑ \mathrm{HR} @ 5 \uparrow HR@5↑ | 0.0495 | 0.0508 | 0.0502 | 0.0540 |
| N D C G @ 5 ↑ \mathrm{NDCG} @ 5 \uparrow NDCG@5↑ | 0.0320 | 0.0329 | 0.0332 | 0.0360 | |
| Repeat@10 | 2.33% | 0.00% | 0.00% | 0.00% | |
| OOD@10 | 1.75% | 0.00% | 0.00% | 0.00% | |
| Movies | HR@10 ↑ \uparrow ↑ | 0.1331 | 0.1400 | 0.1443 | 0.1424 |
| N D C G @ 10 ↑ \mathrm{NDCG} @ 10 \uparrow NDCG@10↑ | 0.1240 | 0.1269 | 0.1318 | 0.1296 | |
| HR@5 ↑ \uparrow ↑ | 0.1297 | 0.1334 | 0.1396 | 0.1365 | |
| N D C G @ 5 ↑ \mathrm{NDCG} @ 5 \uparrow NDCG@5↑ | 0.1229 | 0.1248 | 0.1303 | 0.1277 | |
| Repeat@10 | 39.26% | 0.00% | 0.00% | 0.00% | |
| OOD@10 | 17.48% | 0.00% | 0.00% | 0.00% | |
| Toys | HR@10 ↑ \uparrow ↑ | 0.0400 | 0.0581 | 0.0605 | 0.0642 |
| N D C G @ 10 ↑ \mathrm{NDCG} @ 10 \uparrow NDCG@10↑ | 0.0346 | 0.0429 | 0.0442 | 0.0479 | |
| HR@5 ↑ \uparrow ↑ | 0.0380 | 0.0475 | 0.0496 | 0.0534 | |
| N D C G @ 5 ↑ \mathrm{NDCG} @ 5 \uparrow NDCG@5↑ | 0.0340 | 0.0395 | 0.0407 | 0.0444 | |
| Repeat@10 | 34.57% | 0.00% | 0.00% | 0.00% | |
| OOD@10 | 35.85% | 0.00% | 0.00% | 0.00% |
表3:消融研究
鉴于表2中观察到的RecLM-cgen的优势,我们在本节中深入研究其三个组成部分。我们标记了几个变体:v0表示在推荐数据集上微调的Llama3,能够在提及项目前生成符号,但未启用约束生成过程。我们感兴趣的是确定单独的特殊符号是否能提醒微调后的Llama3生成域内项目。v1是在v0的基础上添加了约束生成组件的变体。v2进一步在训练过程中引入了范围掩码损失,基于v1构建。full表示最终版本的RecLM-cgen,它在v2的基础上进一步包含了多轮对话训练数据。
4.3.1 消融研究
表3报告了四个变体的推荐性能。约束生成组件的好处最为明显,从v0到v1,准确性和错误减少都有显著改进。从v1到v2的变化展示了范围掩码损失的效果,显示出增量的准确性改进。然而,我们注意到范围掩码损失在跨域推荐中的额外好处,这将在小节4.3.2中讨论。关于多轮对话,
| 模型 | 响应 R 1 R_{1} R1 | 响应 R 2 R_{2} R2 | |||
|---|---|---|---|---|---|
| HR@10 ↑ \uparrow ↑ | N D C G @ 10 ↑ \mathrm{NDCG} @ 10 \uparrow NDCG@10↑ | C N N R v 10 ↑ \mathrm{CNN}_{\mathrm{R}}^{\mathrm{v} 10} \uparrow CNNRv10↑ | ACC spects ↑ _{\text {spects }} \uparrow spects ↑ | C N N R v 1 ↑ \mathrm{CNN}_{\mathrm{R}}^{\mathrm{v} 1} \uparrow CNNRv1↑ | |
| 数据集: Steam | |||||
| Llama3-cgen | 0.0258 | 0.0119 | 0.717 | 0.676 | 1.000 |
| PALR | 0.0629 | 0.0364 | - | 0.585 | - |
| CnIRev | 0.0662 | 0.0349 | - | 0.022 | - |
| RecLM-ml | 0.0308 | 0.0257 | 0.998 | 0.669 | 0.987 |
| RecLM-cgen v 1 _{v 1} v1 | 0.0697 | 0.0395 | 1.000 | 0.274 | 0.384 |
| RecLM-cgen v 2 { }_{v 2} v2 | 0.0705 | 0.0395 | 1.000 | 0.067 | 0.064 |
| RecLM-cgen v 10 { }_{v 10} v10 | 0.0713 | 0.0410 | 1.000 | 0.673 | 0.990 |
| 数据集: Movies | |||||
| Llama3-cgen | 0.0403 | 0.0241 | 0.206 | 0.667 | 1.000 |
| PALR | 0.0482 | 0.0399 | - | 0.617 | - |
| CnIRev | 0.0455 | 0.0404 | - | 0.391 | - |
| RecLM-ml | 0.0516 | 0.0396 | 0.998 | 0.640 | 1.000 |
| RecLM-cgen v 1 { }_{v 1} v1 | 0.0546 | 0.0427 | 0.998 | 0.676 | 0.978 |
| RecLM-cgen v 2 { }_{v 2} v2 | 0.0561 | 0.0457 | 1.000 | 0.599 | 0.714 |
| RecLM-cgen v 10 { }_{v 10} v10 | 0.0584 | 0.0484 | 1.000 | 0.718 | 0.998 |
表4:多轮对话评估
| D beam D_{\text {beam }} Dbeam | D trap D_{\text {trap }} Dtrap | 模型 | HR@10 ↑ \uparrow ↑ | N D C G @ 10 ↑ \mathrm{NDCG} @ 10 \uparrow NDCG@10↑ |
|---|---|---|---|---|
| Llama3-cgen | 0.0246 | 0.0106 | ||
| Out rg _{\text {rg }} rg | 0.0743 | 0.0651 | ||
| Out rg _{\text {rg }} rg | 0.0953 | 26.26% | ||
| Out rg _{\text {rg }} rg | 0.0745 | 0.0648 | ||
| Out rg _{\text {rg }} rg | 0.1170 | 57.05% | ||
| Movies | Toys | Llama3-cgen | 0.0354 | 0.0133 |
| Out rg _{\text {rg }} rg | 0.0563 | 0.0384 | ||
| Out rg _{\text {rg }} rg | 0.0572 | 13.72% | ||
| Out rg _{\text {rg }} rg | 0.0481 | 0.0386 | ||
| Out rg _{\text {rg }} rg | 0.0527 | 9.56% | ||
| 0.0414 | 13.11% |
表5:跨域推荐评估训练,RecLM-cgen的完整版本在Steam和Toys数据集上表现最佳。考虑到表3在单轮对话设置下评估性能,我们还进行了多轮对话评估,见表4(更多细节将在子章节4.3.3中介绍)。多轮对话包括一般任务问题(如来自GSM8K的问题,记为响应 R 2 R_{2} R2)和推荐任务问题(记为响应 R 1 R_{1} R1)。从表4可以看出,纳入多轮对话训练对于维持多轮对话场景下的鲁棒性至关重要,因为一些变体,如RecLM-cgen v 2 {}_{v 2} v2,在响应 R 2 R_{2} R2中遇到显著问题。
4.3.2 跨域推荐
我们发现,在训练期间引入范围掩码可以增强跨域推荐能力。为了证明这一点,表5展示了两种设置:(1)在玩具领域训练模型,然后在电影领域进行测试;(2)在电影领域训练模型,然后在玩具领域进行测试。为了更好地进行比较,我们将RecLM-cgen的变体分组,并使用下标加以区分。我们的表示对应于子章节4.3.1中的v0基础配置,下标表示添加的组件:cg代表约束生成,sm代表范围掩码,mr代表多轮对话。在两种跨域场景中,我们观察到当引入范围掩码组件时,基础版本的一致改进。
4.3.3 控制符号研究
我们通过将GSM8K任务与项目推荐任务结合,设置了一个三轮对话测试,以评估模型在多轮对话设置中的能力:
| 用户: {GSM8K训练样本问题} | |||||
|---|---|---|---|---|---|
| LLM: {GSM8K训练样本答案} | |||||
| 用户: {推荐任务指令} | |||||
| LLM: {LLM生成的响应 R 1 R_{1} R1} | |||||
| 用户: {GSM8K测试样本问题} | |||||
| LLM: {LLM生成的响应 R 2 R_{2} R2} |
具体来说,我们使用一个GSM8K训练样本(包括问题和回答)作为用户-LLM的第一轮对话。在第二轮对话中,我们使用项目推荐指令(推荐10个项目)作为用户输入,LLM将生成响应 R 1 R_{1} R1。在第三轮对话中,我们使用一个GSM8K测试样本作为用户输入,LLM将生成响应 R 2 R_{2} R2。为了测试模型是否能在面对不同的用户问题时正确应用控制符号,我们使用度量标准 C S N R ∗ n = k CSN_{R_{*}}^{n=k} CSNR∗n=k来测量响应 R ∗ R_{*} R∗中控制符号数量正确匹配k的比例。例如,对于项目推荐响应 R 1 R_{1} R1,我们期望模型生成一个包含10个推荐项目的列表,因此我们测量响应 R 1 R_{1} R1中包含10个控制符号的比例, C S N R 1 n = 10 CSN_{R_{1}}^{n=10} CSNR1n=10。对于响应 R 2 R_{2} R2,我们期望模型不生成项目或控制符号,因此我们测量响应 R 2 R_{2} R2中包含0个控制符号的比例, C S N R 2 n = 0 CSN_{R_{2}}^{n=0} CSNR2n=0。从表4可以看出,RecLLM-cgen f u l l {}_{full} full成功地在项目推荐场景中应用符号( C S N R 1 n = 10 CSN_{R_{1}}^{n=10} CSNR1n=10始终等于1.0),并在GSM8K场景中偶尔错误应用(例如,在Movies数据集中, C S N R 2 n = 0 CSN_{R_{2}}^{n=0} CSNR2n=0等于0.988)。
4.3.4 通用任务评估
最后,我们考察了模型在对齐到推荐任务后其通用能力受到影响的程度。我们选择了四个通用
| 数据集 | 模型 | MMLU | GSM8K | CSQA | Human-eval |
|---|---|---|---|---|---|
| - | Llamu3 | 0.675 | 0.791 | 0.796 | 0.640 |
| Steam | BIGBec | 0.632 | 0.722 | 0.747 | 0.402 |
| PALR | 0.639 | 0.745 | 0.778 | 0.512 | |
| CtrlBec | 0.646 | 0.697 | 0.764 | 0.567 | |
| RecLM-ret | 0.653 | 0.722 | 0.762 | 0.573 | |
| RecLM-cgen c 1 { }_{c 1} c1 | 0.663 | 0.765 | 0.776 | 0.585 | |
| RecLM-cgen c 2 { }_{c 2} c2 | 0.654 | 0.755 | 0.755 | 0.549 | |
| RecLM-cgen f u l { }_{f u l} ful | 0.657 | 0.777 | 0.767 | 0.591 | |
| Movies | BIGBec | 0.669 | 0.689 | 0.711 | 0.299 |
| PALR | 0.651 | 0.747 | 0.747 | 0.555 | |
| CtrlBec | 0.649 | 0.729 | 0.756 | 0.549 | |
| RecLM-ret | 0.650 | 0.501 | 0.761 | 0.555 | |
| RecLM-cgen c 1 { }_{c 1} c1 | 0.653 | 0.765 | 0.769 | 0.579 | |
| RecLM-cgen c 2 { }_{c 2} c2 | 0.659 | 0.774 | 0.759 | 0.585 | |
| Toys | REGBec IIG \begin{aligned} & \text { REGBec } \\ & \text { IIG } \end{aligned} REGBec IIG | 0.622 | 0.661 | 0.710 | 0.445 |
| PALR | 0.645 | 0.729 | 0.737 | 0.561 | |
| CtrlBec | 0.623 | 0.721 | 0.728 | 0.561 | |
| RecLM-ret | 0.653 | 0.340 | 0.754 | 0.561 | |
| RecLM-cgen c 1 { }_{c 1} c1 | 0.651 | 0.739 | 0.741 | 0.585 | |
| RecLM-cgen c 2 { }_{c 2} c2 | 0.654 | 0.770 | 0.752 | 0.579 | |
| RecLM-cgen f u l { }_{f u l} ful | 0.653 | 0.767 | 0.747 | 0.598 |
表6:通用任务评估
任务进行评估:MMLU(5-shot)、GSM8K(8-shot)、CommonsenseQA(7-shot)和HumanEval(0-shot)。这些任务分别衡量模型在理解、数学、常识推理和代码生成方面的能力。如表6所示,RecLM-cgen
f
u
l
l
{}_{full}
full保持强大的通用能力,性能接近未调整的基础模型Llama3。
5 结论
我们通过探索两种方法解决了基于LLM的生成推荐中关键的域外项目生成问题:RecLM-ret和RecLM-cgen。这两种方法采用了不同的接地范式——基于检索和约束生成——以确保推荐项目牢固地扎根于预定义域内。实验表明,这两种方法成功消除了OOD问题。值得注意的是,RecLM-cgen在准确率方面始终优于RecLM-ret和现有的基于LLM的推荐模型,使其成为该方向上的首选方法。此外,RecLM-cgen是一个轻量级的即插即用解决方案,可以轻松集成到现有的LLMs中。我们认为它为这一快速发展的领域提供了有前途且实用的解决方案。
6 局限性
尽管RecLM-cgen在推荐准确性和解决域外项目生成问题方面表现出显著改进,但仍有一些局限性值得进一步讨论和研究。
6.1 推理延迟和可扩展性
基于LLM的生成推荐的主要关注点之一是其推理延迟,可能无法满足大规模实时推荐服务的需求。行业推荐系统通常需要同时为数百万用户提供服务,并在短时间内响应用户请求(例如,100毫秒)。大型模型尺寸和自回归生成过程增加了在这种环境中部署此类系统的挑战。未来的工作应集中在通过模型蒸馏、缓存、模型量化、边缘计算和平行计算等技术减少推理延迟。这些优化有助于提高RecLMcgen的效率和可扩展性,使其更适合工业应用。
6.2 超越准确性的评估
我们当前的评估主要集中在推荐准确性指标上,如NDCG和命中率。然而,推荐系统的一些其他重要方面,如多样性、公平性和用户满意度,尚未得到彻底检查。例如,虽然最大化准确性,模型可能会生成缺乏多样性的推荐,导致单调的用户体验。同样,如果模型不成比例地偏向某些类型的项目或用户,可能会出现公平性问题,从而导致偏差推荐。这些因素对于推荐系统的整体评估至关重要。然而,这些指标通常是主观的,需要人类研究进行深入分析。未来的研究应结合全面的人类评估,以评估推荐的整体质量和影响,确保系统提供平衡和公平的用户体验。
6.3 跨域零样本推荐
尽管RecLM-cgen在其训练域内表现出色,但其跨域零样本推荐能力仍然有限。正如我们在实验中所展示的那样,RecLM-cgen在跨域任务中的表现显著低于使用域内数据微调时的表现。这一限制突显了在没有额外微调的情况下适应完全新领域的挑战。可能的解决方法包括使用多样化的领域集预训练通用RecLM,并研究与训练数据相关的规模定律,以提高跨域零样本性能。
参考文献
Andrea Bacciu, Enrico Palumbo, Andreas Damianou, Nicola Tonellotto, and Fabrizio Silvestri. 2024. Generating query recommendations via llms. arXiv preprint arXiv:2405.19749.
Keqin Bao, Jizhi Zhang, Wenjie Wang, Yang Zhang, Zhengyi Yang, Yancheng Luo, Chong Chen, Fuli Feng, and Qi Tian. 2025. A bi-step grounding paradigm for large language models in recommendation systems. ACM Trans. Recomm. Syst. Just Accepted.
Luca Beurer-Kellner, Marc Fischer, and Martin Vechev. 2024. Guiding llms the right way: fast, noninvasive constrained generation. In Proceedings of the 41st International Conference on Machine Learning, ICML’24. JMLR.org.
Marco Cascella, Jonathan Montomoli, Valentina Bellini, and Elena Bignami. 2023. Evaluating the feasibility of chatgpt in healthcare: an analysis of multiple clinical and research scenarios. Journal of medical systems, 47(1):33.
Jianlyu Chen, Shitao Xiao, Peitian Zhang, Kun Luo, Defu Lian, and Zheng Liu. 2024. M3embedding: Multi-linguality, multi-functionality, multi-granularity text embeddings through selfknowledge distillation. In Findings of the Association for Computational Linguistics: ACL 2024, pages 2318-2335, Bangkok, Thailand. Association for Computational Linguistics.
Yixin Dong, Charlie F Ruan, Yaxing Cai, Ruihang Lai, Ziyi Xu, Yilong Zhao, and Tianqi Chen. 2024. Xgrammar: Flexible and efficient structured generation engine for large language models. arXiv preprint arXiv:2411.15100.
Yunfan Gao, Tao Sheng, Youlin Xiang, Yun Xiong, Haofen Wang, and Jiawei Zhang. 2023. Chatrec: Towards interactive and explainable llmsaugmented recommender system. arXiv preprint arXiv:2303.14524.
Saibo Geng, Hudson Cooper, Michal Moskal, Samuel Jenkins, Julian Berman, Nathan Ranchin, Robert
West, Eric Horvitz, and Harsha Nori. 2025. Generating structured outputs from language models: Benchmark and studies. arXiv preprint arXiv:2501.10868.
Balázs Hidasi, Alexandros Karatzoglou, Linas Baltrunas, and Domonkos Tikk. 2016. Session-based recommendations with recurrent neural networks. In 4th International Conference on Learning Representations, ICLR 2016, San Juan, Puerto Rico, May 2-4, 2016, Conference Track Proceedings.
Xu Huang, Jianxun Lian, Yuxuan Lei, Jing Yao, Defu Lian, and Xing Xie. 2023. Recommender ai agent: Integrating large language models for interactive recommendations. arXiv preprint arXiv:2308.16505.
Jianchao Ji, Zelong Li, Shuyuan Xu, Wenyue Hua, Yingqiang Ge, Juntao Tan, and Yongfeng Zhang. 2024. Genrec: Large language model for generative recommendation. In Advances in Information Retrieval: 46th European Conference on Information Retrieval, ECIR 2024, Glasgow, UK, March 24-28, 2024, Proceedings, Part III, page 494-502, Berlin, Heidelberg. Springer-Verlag.
Haolin Jin, Linghan Huang, Haipeng Cai, Jun Yan, Bo Li, and Huaming Chen. 2024. From llms to llm-based agents for software engineering: A survey of current, challenges and future. arXiv preprint arXiv:2408.02479.
Wang-Cheng Kang and Julian McAuley. 2018. Selfattentive sequential recommendation. In 2018 IEEE international conference on data mining (ICDM), pages 197-206. IEEE.
Terry Koo, Frederick Liu, and Luheng He. 2024. Automata-based constraints for language model decoding. arXiv preprint arXiv:2407.08103.
Jianxun Lian, Yuxuan Lei, Xu Huang, Jing Yao, Wei Xu, and Xing Xie. 2024. Recai: Leveraging large language models for next-generation recommender systems. In Companion Proceedings of the ACM on Web Conference 2024, pages 1031-1034.
Wensheng Lu, Jianxun Lian, Wei Zhang, Guanghua Li, Mingyang Zhou, Hao Liao, and Xing Xie. 2024. Aligning large language models for controllable recommendations. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2024, Bangkok, Thailand, August 11-16, 2024, pages 81598172. Association for Computational Linguistics.
Hanjia Lyu, Song Jiang, Hanqing Zeng, Yinglong Xia, Qifan Wang, Si Zhang, Ren Chen, Chris Leung, Jiajie Tang, and Jiebo Luo. 2024. LLM-rec: Personalized recommendation via prompting large language models. In Findings of the Association for Computational Linguistics: NAACL 2024, pages 583-612, Mexico City, Mexico. Association for Computational Linguistics.
Jianmo Ni, Jiacheng Li, and Julian McAuley. 2019. Justifying recommendations using distantly-labeled reviews and fine-grained aspects. In Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLPIJCNLP), pages 188-197.
Kanghee Park, Timothy Zhou, and Loris D’Antoni. 2025. Flexible and efficient grammar-constrained decoding. arXiv preprint arXiv:2502.05111.
Alan Said. 2025. On explaining recommendations with large language models: a review. Frontiers in Big Data, 7:1505284.
Hongyu Wan, Jinda Zhang, Abdulaziz Arif Suria, Bingsheng Yao, Dakuo Wang, Yvonne Coady, and Mirjana Prpa. 2024. Building llm-based ai agents in social virtual reality. In Extended Abstracts of the CHI Conference on Human Factors in Computing Systems, pages 1-7.
Tianfu Wang, Yi Zhan, Jianxun Lian, Zhengyu Hu, Nicholas Jing Yuan, Qi Zhang, Xing Xie, and Hui Xiong. 2025. Llm-powered multi-agent framework for goal-oriented learning in intelligent tutoring system. arXiv preprint arXiv:2501.15749.
Likang Wu, Zhi Zheng, Zhaopeng Qiu, Hao Wang, Hongchao Gu, Tingjia Shen, Chuan Qin, Chen Zhu, Hengshu Zhu, Qi Liu, et al. 2024. A survey on large language models for recommendation. World Wide Web, 27(5):60.
Fan Yang, Zheng Chen, Ziyan Jiang, Eunah Cho, Xiaojiang Huang, and Yanbin Lu. 2023. Palr: Personalization aware llms for recommendation. arXiv preprint arXiv:2305.07622.
Jing Yao, Wei Xu, Jianxun Lian, Xiting Wang, Xiaoyuan Yi, and Xing Xie. 2023. Knowledge plugins: Enhancing large language models for domain-specific recommendations. arXiv preprint arXiv:2311.10779.
Junjie Zhang, Ruobing Xie, Yupeng Hou, Xin Zhao, Leyu Lin, and Ji-Rong Wen. 2024. Recommendation as instruction following: A large language model empowered recommendation approach. ACM Trans. Inf. Syst. Just Accepted.
Yaochen Zhu, Liang Wu, Qi Guo, Liangjie Hong, and Jundong Li. 2024. Collaborative large language model for recommender systems. In Proceedings of the ACM on Web Conference 2024, pages 31623172 .
A 附录
A. 1 数据增强和实验设置
| 数据集 | #用户 | #物品 | #交互 | #稀疏性 |
|---|---|---|---|---|
| Steam | 10,000 | 11,726 | 170,000 | 99.85 % 99.85 \% 99.85% |
| Movies | 10,000 | 34,452 | 170,000 | 99.95 % 99.95 \% 99.95% |
| Toys | 10,000 | 49,985 | 170,000 | 99.96 % 99.96 \% 99.96% |
表A1:三个数据集的基本统计信息
在训练过程中,我们采用在线数据增强策略。对于每个用户的历次交互记录,记为
I
history
(
1
…
n
)
I_{\text {history }}^{(1 \ldots n)}
Ihistory (1…n),我们随机抽取一段连续的片段
I
history
(
a
…
b
)
I_{\text {history }}^{(a \ldots b)}
Ihistory (a…b),其中
1
≤
a
<
b
≤
10
<
n
1 \leq a<b \leq 10<n
1≤a<b≤10<n,作为增强训练数据。为了构造对应的训练标签
I
history
(
a
,
b
)
I_{\text {history }}^{(a, b)}
Ihistory (a,b),记为
I
rec
(
1
…
k
)
I_{\text {rec }}^{(1 \ldots k)}
Irec (1…k),其中
k
k
k是一个介于1和10之间的随机整数,我们遵循(Lu等人,2024)中描述的方法。具体来说,
I
rec
(
1
)
I_{\text {rec }}^{(1)}
Irec (1)对应下一个交互项目
I
history
(
b
+
1
)
I_{\text {history }}^{(b+1)}
Ihistory (b+1),而
I
rec
(
2
…
k
)
I_{\text {rec }}^{(2 \ldots k)}
Irec (2…k)由教师模型SASRec根据
I
history
(
a
,
b
)
I_{\text {history }}^{(a, b)}
Ihistory (a,b)提供。
在每个epoch开始之前,对每位用户进行数据增强抽样。因此,每个epoch的训练数据对应于数据集中用户的总数,通过在线增强确保训练样本的更大多样性。在测试阶段,不应用数据增强。相反,测试样本的数量固定为10,000 。
A. 2 RecLM-ret的投影层
在RecLM-ret中,为了使基础模型的隐藏表示 h < S O I > ( i ) \mathbf{h}_{<S O I>}^{(i)} h<SOI>(i)与预先生成的项目嵌入向量空间 E \mathcal{E} E对齐,我们引入了一个投影层。其公式如方程A1所示。
proj ϕ ( h < S O I > ( i ) ) = G E L U ( h < S O I > ( i ) ⋅ W 1 ) ⋅ W 2 \operatorname{proj}_{\phi}\left(\mathbf{h}_{<S O I>}^{(i)}\right)=G E L U\left(\mathbf{h}_{<S O I>}^{(i)} \cdot \mathbf{W}_{1}\right) \cdot \mathbf{W}_{2} projϕ(h<SOI>(i))=GELU(h<SOI>(i)⋅W1)⋅W2
这里, W 1 ∣ d × d 2 ∣ \mathbf{W}_{1}^{|d \times \frac{d}{2}|} W1∣d×2d∣和 W 2 ∣ d 2 × c ∣ \mathbf{W}_{2}^{|\frac{d}{2} \times c|} W2∣2d×c∣构成投影层的可训练参数 ϕ \phi ϕ。 d d d是基础模型的维度。 c c c是项目嵌入 E \mathcal{E} E的维度。
A. 3 提示
我们在清单A1中提供了提示,用于将用户行为
<
I
history
(
1
…
n
)
<I_{\text {history }}^{(1 \ldots n)}
<Ihistory (1…n),
I
rec
(
1
…
k
)
>
I_{\text {rec }}^{(1 \ldots k)}>
Irec (1…k)>转换为监督微调数据样本
<
<
< 指令:
X
X
X,响应:
Y
>
Y>
Y>。为了增加数据多样性,我们使用四种提示模板。
A. 4 RecLM-cgen的推断速度
| 数据集 | CG | Token i n _{i n} in | Token i n ⋅ _{i n} \cdot in⋅ | Speed
avg
_{\text {avg }}
avg (token/s) | Search Time
i
n
_{i n}
in (ms/token) | Search Time
i
n
t
⋅
_{i n t} \cdot
int⋅ (ms/token) |
|---|---|---|---|---|---|---|
| Steam | w/ | 7726 | 7552 | 35.0385 | 1.0725 | 0.3234 |
| w/o | 7872 | 7552 | 36.6986 | |||
| Movies | w/ | 12970 | 7552 | 34.5347 | 1.4535 | 0.3221 |
| w/o | 11900 | 7552 | 36.3846 | |||
| Toys | w/ | 20838 | 7552 | 34.0883 | 1.9922 | 0.3237 |
| w/o | 19910 | 7552 | 36.9466 | - | - |
表A2:推断期间约束生成的计算成本说明。
为了说明约束生成不会对LLM推断造成显著延迟,我们进行了一次推断吞吐量实验。我们从三个数据集的测试集中选择128个测试样本,每个测试样本生成10个项目的推荐。模型使用Hugging Face Transformers库 6 { }^{6} 6 部署在一个单一的A100 GPU(40GB)上,推断批次大小设置为1 。我们使用5个测试样本进行热身并忽略生成第一个标记所需的时间。然后,我们汇总内部前缀树标记(Token i n _{i n} in )和外部前缀树标记(Token o u t _{o u t} out )的数量,计算两种标记类型在设置中的平均搜索时间。这里的搜索时间对应于确定下一个标记解码的有效空间的操作。表A2显示了5次重复实验的平均结果,数字是从128个测试样本的响应文本中汇总的,我们报告了带和不带约束生成的两种设置。
对于Steam数据集,启用约束生成时,总共生成了7,726个内部标记和7,552个外部标记。平均生成速度为35.0385 tokens/second。内部标记的平均搜索时间为 1.0725 m s / 1.0725 \mathrm{~ms} / 1.0725 ms/ 标记,而外部标记则为 0.3234 m s / 0.3234 \mathrm{~ms} / 0.3234 ms/ 标记。随着项目标题长度从Steam数据集(6.0359 tokens/item)增加到Movies数据集(10.1328 tokens/item)再到Toys数据集(16.2797 tokens/item),外部标记的搜索时间保持稳定,而内部标记的搜索时间逐渐增加。
A. 5 实验环境
所有实验都在配备4个Intel Xeon Gold 6248R CPU @ 3.00 GHz和1512 GB RAM的机器上进行。软件环境利用Ubuntu 20.04 LTS,CUDA 12.1,
6
{ }^{6}
6 https://github.com/huggingface/transformers
启用了混合精度训练的PyTorch 2.1.2。为了可重复性,我们将所有随机种子(Python、NumPy和PyTorch)固定为0 。我们使用2个NVIDIA A100 GPUs(40GB VRAM)进行模型训练。
A. 6 RecLM-cgen与RecLM-ret的讨论
在本节中,我们提供了一些理论视角,解释为什么RecLM-cgen倾向于比RecLM-ret实现更高的推荐准确性。
RecLMcgen和RecLM-ret的主要区别在于单阶段生成与两阶段检索。RecLM-ret依赖于一个两步过程:
- 生成一个特殊的标记。
-
- 在外部嵌入索引中执行基于相似性的查找以选择项目。
这种分离可能会以两种方式降低准确性。首先,模型的隐藏状态嵌入与项目语料库嵌入之间的任何不匹配都可能导致次优项目的选取。其次,由于检索实际上是一个外部的“硬选择”,它无法从逐标记的语言建模反馈中受益,即一旦生成,模型的后续文本对哪个项目被检索到没有影响。相比之下,RecLM-cgen从未离开其原生的自回归过程。一旦被生成,模型继续为项目标题生成标记,只是它将标记分布限制在前缀树中存储的有效项目标题内。换句话说,构成推荐项目的每个标记都是在模型的下一个标记概率中选择的。一方面,不存在嵌入不匹配的情况。模型的隐藏状态直接转化为项目标记预测,而不是依赖于外部嵌入查询。另一方面,它使用统一的生成信号。每个生成的标记都会细化项目选择过程。模型的完整上下文理解,如用户偏好、对话历史等,都会影响哪些项目标记出现。
- 在外部嵌入索引中执行基于相似性的查找以选择项目。
数学上,我们可以将RecLM-ret视为将推荐过程分解为:
P ( item ) ≈ N N ( ϕ ( h S O I ) , E ) P(\text { item }) \approx \mathrm{NN}\left(\phi\left(\mathbf{h}_{\mathrm{SOI}}\right), \mathbf{E}\right) P( item )≈NN(ϕ(hSOI),E)
其中 ϕ \phi ϕ是模型隐藏状态的投影,而 E \mathbf{E} E是预计算的项目嵌入基。
ϕ ( h SOI ) \phi\left(\mathbf{h}_{\text {SOI }}\right) ϕ(hSOI )中的小误差可能会导致次优推荐。
相反,RecLM-cgen有效地实现了:
P ( item ∣ context ) = ∏ i P θ ( w i ∣ w < i , context ) P(\text { item } \mid \text { context })=\prod_{i} P_{\theta}\left(w_{i} \mid w_{<i}, \text { context }\right) P( item ∣ context )=i∏Pθ(wi∣w<i, context )
带有前缀树约束过滤掉无效标记。这种直接对项目字符串进行语言建模利用了LLM的整个生成能力,通常在训练期间收敛到更高的推荐准确性。一方面,模型被训练以最大化项目标题中每个正确标记的概率,直接将语言建模损失与更好的项目预测联系起来;另一方面,在项目选择和项目文本生成之间没有间断性,每个标记反映了学习用户上下文的相同内部分布。
参考论文:https://arxiv.org/pdf/2505.03336



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











