






Kazuki Fujii
1
,
2
{ }^{1,2}
1,2, Yukito Tajima
1
{ }^{1}
1, Sakae Mizuki
1
,
2
{ }^{1,2}
1,2, Hinari Shimada
1
{ }^{1}
1, Taihei Shiotani
1
{ }^{1}
1, Koshiro Saito
1
{ }^{1}
1, Masanari Ohi
1
{ }^{1}
1, Masaki Kawamura
1
{ }^{1}
1, Taishi Nakamura
1
,
2
{ }^{1,2}
1,2, Takumi Okamoto
1
{ }^{1}
1, Shigeki Ishida
1
{ }^{1}
1, Kakeru Hattori
1
,
2
{ }^{1,2}
1,2, Youmi Ma
1
{ }^{1}
1, Hiroya Takamura
2
{ }^{2}
2, Rio Yokota
2
,
3
{ }^{2,3}
2,3, 和 Naoaki Okazaki
1
,
2
{ }^{1,2}
1,2
1
{ }^{1}
1 东京理科大学计算机科学系
2
{ }^{2}
2 国家先进工业科学技术研究所
3
{ }^{3}
3 东京理科大学综合研究学院超级计算研究中心
https://huggingface.co/datasets/tokyotech-1lm/swallow-code https://huggingface.co/datasets/tokyotech-1lm/swallow-math
摘要
大型语言模型(LLM)在程序合成和数学推理方面的表现从根本上受限于其预训练语料库的质量。我们引入了两个根据Llama 3.3社区许可公开发布的数据集,通过系统地重写公共数据显著提升了LLM的性能。SwallowCode(约161亿个标记)通过一个新颖的四阶段管道改进了The-Stack-v2中的Python片段:语法验证、基于pylint的样式过滤以及两阶段LLM重写过程,该过程强制执行样式一致性并将片段转换为自包含且算法高效的示例。与依赖排除性过滤或有限变换的先前方法不同,我们的转换和保留方法升级了低质量代码,最大化了数据效用。SwallowMath(约23亿个标记)通过去除样板代码、恢复上下文并重新格式化解决方案为简洁的分步解释增强了Finemath-4+。在固定的500亿标记训练预算内,使用SwallowCode对Llama-3.1-8B进行持续预训练相比Stack-Edu,在HumanEval上提高了pass@1 + 17.0 \mathbf{+ 17 . 0} +17.0,在HumanEval+上提高了 + 17.7 \mathbf{+ 17 . 7} +17.7。类似地,替换为SwallowMath后,GSM8K上的准确率提高了 + 12.4 \mathbf{+ 12 . 4} +12.4,MATH上的准确率提高了 + 7.6 \mathbf{+ 7 . 6} +7.6。消融研究表明,每个管道阶段都逐步贡献,其中重写提供了最大的收益。所有数据集、提示和检查点均公开可用,支持可重复的研究,并推动LLM在专业领域的预训练。
1 引言
大型语言模型(LLMs)已在各种任务中展示了出色的零样本和少量样本能力,但在数学推理和程序合成方面的能力仍受到预训练语料库质量的限制。现有的专业领域公开数据集,例如用于代码的The-Stack-v1和v2 [1, 2]以及用于数学的Finemath-4+ [3],主要依赖从网络爬虫(如CommonCrawl)[4]提取的数据或基于模型评分来过滤低质量样本。然而,这些方法通常保留噪声大、冗余或样式不一致的数据,限制了它们的有效性。例如,如图1所示,持续预训练Llama-3.1-8B [5]在The-Stack-v1/v2上通常保持基准性能在HumanEval和HumanEval+等基准测试中,但由于未解决的数据质量问题,难以实现显著增益。与专注于过滤或保留原始样本的先前方法不同,我们建议重写预训练语料库以消除噪声和冗余,提供高质量的自包含数据,从而提高模型学习效率。
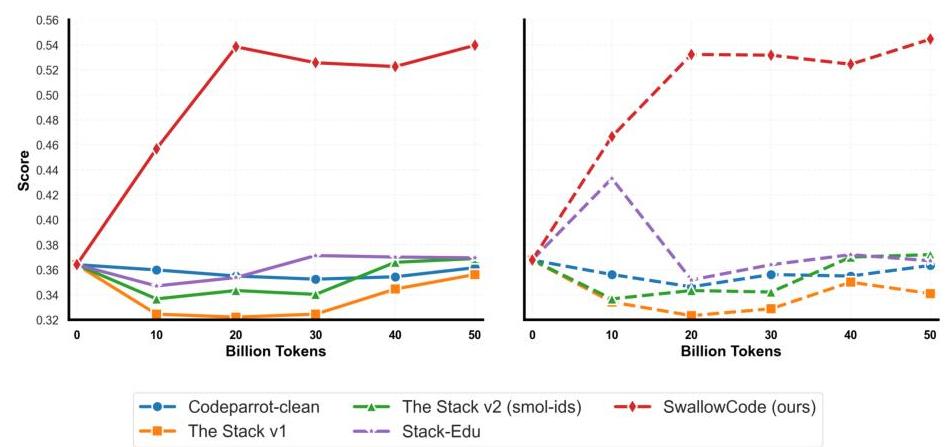
图1:在500亿标记持续预训练设置下,Python-only数据集的比较。SwallowCode在HumanEval(左)和HumanEval+(右)上实现了最高的pass@1分数,优于CodeParrot-Clean、The-Stack-v1、The-Stack-v2-Smol和Stack-Edu。
本文介绍了两个根据Llama 3.3社区许可公开发布的数据集,旨在提升LLM在代码生成和数学推理方面的能力。SwallowCode(约161亿个标记)通过一个新颖的四阶段管道改进了The-Stack-v2中的Python片段:顺序语法验证、基于pylint的样式过滤以及两阶段LLM重写过程,该过程强制执行样式一致性并将片段转换为算法高效、自包含的示例。通过重写而非仅过滤,我们消除了像Stack-Edu中持续存在的噪声和冗余,提供了提高模型学习效率的高质量数据(图1)。SwallowMath(约23亿个标记)通过去除样板代码、恢复缺失的上下文并重新格式化解决方案为简洁且分步的解释改进了Finemath-4+。尽管我们的实验专注于Python以方便自动评估,但该管道是语言无关的:任何具有可解析语法和linter的编程语言都可以从相同处理中受益,扩大了其在多样化编码领域的适用性。
对Llama-3.1-8B [5]进行500亿标记的持续预训练时,使用SwallowCode和多语言数据集相比使用Stack-Edu [3]的等价预算,HumanEval上的pass@1提高了
+
17.0
\mathbf{+ 17 . 0}
+17.0,HumanEval+上的pass@1提高了
+
17.7
\mathbf{+ 17 . 7}
+17.7。类似地,将Finemath-4+替换为SwallowMath后,GSM8K上的准确率提高了
+
12.4
\mathbf{+ 12 . 4}
+12.4,MATH上的准确率提高了
+
7.6
\mathbf{+ 7 . 6}
+7.6。为了确保这些增益的稳健性,我们进行了严格的测试集泄漏检查,流式传输整个161亿标记的SwallowCode语料库,未发现与HumanEval或HumanEval+提示完全匹配或高度相似的文档(Jaccard相似度
≥
0.8
\geq 0.8
≥0.8)。所有数据集、提示和检查点均已公开发布,支持可重复的研究。SwallowCode和SwallowMath提供了一个可扩展的框架,用于增强LLM预训练,推动自动化推理和软件开发的进步。
2 相关工作
2.1 开源代码语料库
The Stack v1 [1] 聚合了大约3TB的允许自由使用的源代码,来自公共GitHub存储库,涵盖358种编程语言。虽然进行了去重和许可证审核,但其过滤主要是语法层面的,保留了样板代码和自动生成的文件,而没有进行特定于语言的细化。这限制了其在训练能够处理高质量、语义丰富代码的模型方面的实用性。The Stack v2 [2] 扩展了这一流程,从Software Heritage档案中获取数据,放宽了许可证约束,并引入了特定语言的过滤器以提高数据质量。规模约为9000亿标记,相较于v1有显著增加。然而,像其前身一样,v2采用了选择性方法,保存文件而不进行语义增强,留下了不一致的编码风格和碎片化的脚本未解决的问题。
2.2 基于分类器的代码语料库过滤
最近的研究表明,基于分类器的过滤策略,例如FineWeb-Edu方法 [6],在创建高质量数据集方面有效 [7]。这些方法旨在通过从大规模语料库中选择语义丰富且文档良好的样本来提高模型在代码相关任务上的性能。在此背景下,Stack-Edu [3] 是创建StarCoder2Data [2] 的过滤变体的重要努力,优先考虑高质量代码。
Stack-Edu首先从StarCoder2Data中选择15种最流行的编程语言,形成大约4500亿标记的子集。为了评估代码质量,Stack-Edu利用Llama-3-70B-Instruct [5]为50万代码片段生成合成注释,根据教育性和结构质量对其进行0到5的评分。这些注释训练了基于StarEncoder模型 [8]的语言特定分类器,在应用阈值为3的二元分类时,大多数语言的F1得分超过0.7。最终数据集包含1250亿标记,并显示出比未过滤语料库更高的模型收敛速度和更高的HumanEval pass@1分数 [3]。然而,Stack-Edu的排他性过滤策略丢弃了低分片段而不是重写或增强它们,留下了保留在数据中的问题——例如缺少上下文或命名约定不一致。
2.3 LLM驱动的预训练语料库重写
利用大型语言模型(LLMs)增强代码数据集的努力已获得关注。Austin等人 [9] 探索了LLMs在程序合成中的能力,发现人类反馈显著提高了代码准确性,但他们的工作集中在合成而非数据集重写。Cosmopedia [10] 展示了合成数据生成的潜力,使用Mixtral-8×7B-Instruct [11] 创建高质量文本语料库,尽管它没有解决特定于代码的挑战。
Jain等人 [12] 应用了LLM驱动的转换到指令微调示例,重点关注变量重命名、模块化和添加注释。虽然这对微调有效,但与我们的SwallowCode管道相比,其范围和上下文有限。他们的转换只解决了部分样式改进,而我们的Style-Guided Code Rewriting(SGCR)管道全面执行了Google Python Style Guide中的十个标准,包括描述性变量命名、有效的类型注解、模块化函数设计、错误处理和以可读性为重点的格式化(详见第3.3.1节)。此外,我们的Self-Contained Optimization Rewriting(SCOR)管道引入了语义增强——通过解决依赖关系、优化算法和将琐碎的片段转换为教学示例来确保自包含性——这是Jain等人工作中所没有的(详见第3.3.2节)。此外,Jain等人针对的是指令微调数据,这是一个较小且更精心策划的数据集,而SwallowCode系统地重写了大规模预训练语料库,由于代码样本的多样性和数量,这是一项更具挑战性的任务。我们的管道整合了严格的预处理和基于语法错误和linter的过滤,以确保重写的高质量输入,并在消融研究中评估了基于LLM的评分,比较其计算成本和有效性与重写(详见第3.2.3节)。相比之下,Jain等人既不采用过滤也不评估其转换的成本效益。
SwallowCode的转换和保留范式升级了低质量代码而不是丢弃它,解决了现有数据集(如The Stack [1, 2]、Stack-Edu [7, 3] 和OpenCoder [13])依赖排他性过滤的局限性。通过结合过滤、SGCR和SCOR,SwallowCode生成了一个高质量的语料库,显著提高了HumanEval和HumanEval+基准测试的性能,推动了代码数据集整理的技术前沿。
3 代码语料库的构建
SwallowCode的开发由实证方法驱动,受数据消融实验评估数据处理管道各阶段的影响启发,如图2所示。这些实验的详细结果见附录H.1,其中呈现了消融实验的详细结果。在本节中,我们展示实验结果并描述塑造语料库的设计选择。除非另有说明,所有消融实验均遵循迭代数据集构建过程,其中每个小节的基线模型仅包含前一小节描述的处理步骤。为了确保完全可重复性,所有代码、配置和支持材料均可在https://github.com/rioyokotalab/swallow-code-math 公开获取。

图2:构建SwallowCode的四个阶段管道:(1) 语法过滤以删除无效的Python代码,(2) 使用pylint进行linter-based过滤以强制执行编码标准,以及(3-4) 使用Style-Guided Code Rewriting (SGCR)的两阶段LLM重写,以强制执行一致的样式和可读性,以及Self-Contained Optimization Rewriting (SCOR),以确保自包含性和优化算法效率。
3.1 实验设置
为了评估我们数据处理管道中每个设计选择的影响,我们进行了系统的数据消融研究。每个消融训练一个模型,唯一的区别在于目标预训练数据集,其他因素保持不变,包括模型架构、参数数量、非目标数据、总标记预算和超参数。具体而言,我们从Llama-3.1-8B开始进行持续预训练,总共约500亿标记,最大序列长度为8,192,全局批量大小约为4百万标记,使用Llama-3 tokenizer。目标数据集在每个消融中处理不到一个周期。我们每约100亿标记使用一组下游基准测试评估模型检查点。
持续预训练使用Megatron-LM(版本core_r0.9.0)[14] 进行。对于评估,我们在以下基准测试中使用BigCodeBench [15] 和Im-evaluation-harness [16]:OpenBookQA [17]、TriviaQA [18]、HellaSwag [19]、SQuAD 2.0 [20]、XWINO [21]、MMLU [22]、GSM8K [23]、BBH [24]、HumanEval [25] 和 HumanEval+ [26]。代码语料库的有效性特别通过HumanEval和HumanEval+进行评估。
预训练数据混合物由
84
%
84 \%
84% 多语言文本和
16
%
16 \%
16% 代码组成。详细的比例和数据来源见附录A.4.1,完整的训练超参数见附录A.1。所有消融模型、相关的检查点和支持材料都在我们的Hugging Face仓库中公开,以确保完全可重复性。
3.2 过滤
为了构建SwallowCode语料库,即高质量的Python代码数据集,我们从the-stack-v2-train-smol-ids [2]作为基础数据集开始,实施了一个严格的过滤管道。过滤过程对于确保只保留语法正确且结构良好的代码至关重要,从而提高代码生成任务中的下游性能。我们专注于Python代码以在消融研究中保持一致性并能公平比较现有公开语料库。我们的管道采用了两种关键的过滤技术:语法错误过滤和基于linter的过滤,这两种技术显著提高了代码质量。我们还评估了基于LLM的评分在消融实验中的表现,但由于其相对于计算成本的性能增益有限,最终管道未采用这种方法。图3总结了这些方法在HumanEval和HumanEval+基准测试中的表现,展示了我们过滤策略的影响。
3.2.1 语法错误过滤
尽管经过前期处理,the-stack-v2-train-smol-ids [2] 中仍包含不符合Python 3.10标准的无效Python代码样本。为了解决这个问题,我们通过Python内置的compile()函数进行语法错误过滤,丢弃任何无法编译的样本。这个过程将数据集从大约4100万减少到3700万样本,减少了
10.6
%
10.6 \%
10.6% 。如图3所示,移除语法无效样本提高了
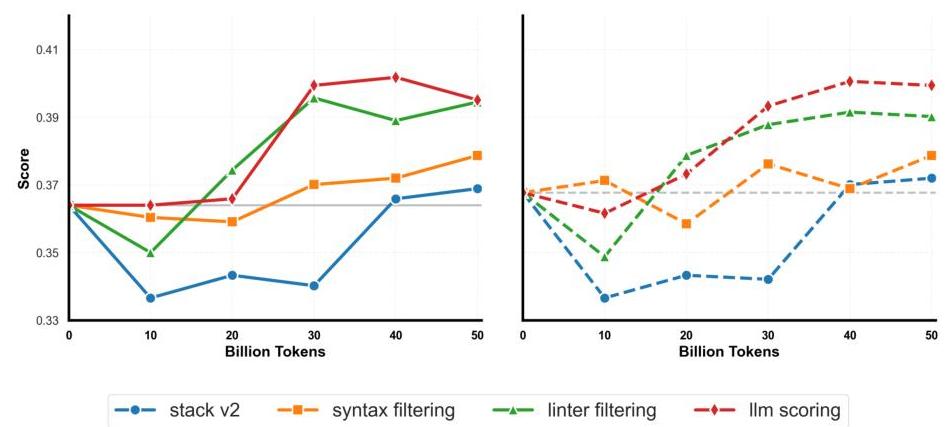
图3:过滤方法在HumanEval(左)和HumanEval+(右)基准测试中的性能比较。基线(Stack v2)与经过语法错误过滤、基于linter的过滤和基于LLM的评分(在消融研究中评估但未采用)处理的数据集进行比较。语法和基于linter的过滤提高了代码生成性能,而基于LLM的评分在考虑计算成本的情况下提供了边际增益。
HumanEval和HumanEval+上的表现。因此,我们将语法错误过滤作为后续实验的标准步骤。
3.2.2 基于linter的过滤
除了语法正确性,代码质量还取决于是否遵守编码标准。初始数据集中许多样本结构较差,当通过静态分析工具分析时会生成大量警告。我们使用Pylint,一种广泛使用的Python linter,来强制执行质量阈值,排除评分低于0-10刻度上7.0分的样本。此外,我们使用定制的启发式评分算法(详见附录B)惩罚过于冗长的注释。这一步将数据集从3670万减少到2410万样本,减少了 34.3 % 34.3 \% 34.3% 。图3展示了基于linter的过滤在HumanEval和HumanEval+上超过1分的性能提升。因此,我们将基于linter的过滤,设定7.0的阈值,作为后续实验的标准步骤。
3.2.3 基于LLM的评分过滤
最近的方法利用大型语言模型(LLMs)生成训练质量分类器的合成注释,然后使用这些分类器通过保留高质量样本过滤大规模语料库(例如,FineWeb [6], Stack-Edu [3])。不同于训练单独的分类器,我们直接提示Llama-3.3-70B-Instruct [5] 对每个Python代码片段进行0-10的评分,评分标准包括代码可读性、模块化和遵循命名约定等十项内容,源自Google Python Style Guide。详细的评分提示和质量评分分布见附录C。
我们排除评分低于6的样本,仅保留被认为足够高质量的样本,并在消融研究中使用此过滤后的子集与多语言数据一起进行持续预训练。如图3所示,基于LLM的过滤在HumanEval和HumanEval+基准测试中带来了适度的改进(不足1分)。
鉴于这些有限的增益,我们将基于LLM的评分与我们的LLM驱动重写管道进行比较,后者通过增强清晰度和正确性改进代码片段(第3.3节)。比较图3和图4,尽管基于LLM的评分需要1.22倍的计算资源(增加了22%),但它在HumanEval和HumanEval+上实现了显著更大的性能提升(详见附录F)。因此,我们在后续实验中未纳入基于LLM的评分,而是倾向于更有效且相对高效的重写方法。
1
{ }^{1}
1 The Stack v2的表现轨迹显示了初期下降随后恢复的现象,这与先前持续预训练研究中观察到的遗忘和随后适应现象一致。这种行为并不特别值得注意。
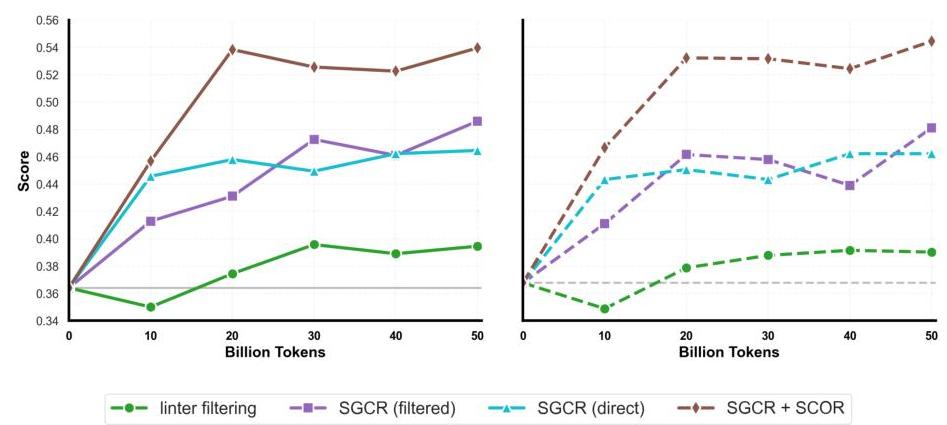
图4:LLM驱动重写管道在HumanEval(左)和HumanEval+(右)基准测试中的性能比较。基线(语法错误和基于linter的过滤)与Style-Guided Code Rewriting(SGCR)和Self-Contained Optimization Rewriting(SCOR)进行比较。SGCR提高了超过9分的性能,而SCOR在SGCR之后进一步提高了超过5分的分数,证明了SwallowCode管道中样式和语义重写的有效性。
3.3 LLM驱动的重写
最近的研究强调了大型语言模型(LLMs)在转换训练数据以增强指令调整模型性能方面的潜力。Jain等人 [12] 提出了三种转换——变量重命名、模块化和计划注释——用于代码清理,并展示了它们在指令调整中的有效性。然而,他们的方法局限于精心策划的指令调整数据和狭窄的样式改进,缺乏语义优化或预处理。在此基础上,我们的SwallowCode管道系统地重写了大规模的预训练语料库。
我们介绍了两个互补的LLM驱动重写管道:Style-Guided Code Rewriting(SGCR)和Self-Contained Optimization Rewriting(SCOR),两者都被纳入SwallowCode构建管道以增强预训练的代码质量。SGCR提示LLM根据Google Python Style Guide的标准修订Python代码片段
2
{ }^{2}
2,强制执行诸如清晰命名和模块化设计之类的样式改进(第3.3.1节)。SCOR扩展了SGCR,确保自包含性并应用语义优化,例如高效算法和教学示例(第3.3.2节)。为了说明这些转换的范围,表1比较了Jain等人 [12]、Style-Guided Code Rewriting(SGCR)和Self-Contained Optimization Rewriting(SCOR)的代码转换覆盖率。虽然SGCR处理了类型提示、错误处理和文档字符串等样式标准,SCOR引入了语义增强,包括自包含性和优化(算法和数据结构),拓宽了SwallowCode管道的范围。
表1:Jain等人 [12]、Style-Guided Code Rewriting(SGCR)和Self-Contained Optimization Rewriting(SCOR)的代码转换覆盖率比较。SGCR涵盖了Google Python Style Guide中的样式标准,而SCOR扩展到了语义优化,共同构成了全面的SwallowCode管道。
| 标准 | Jain等人 | SGCR | SCOR |
|---|---|---|---|
| 变量重命名 | ✓ \checkmark ✓ | ✓ \checkmark ✓ | × \times × |
| 模块化 | ✓ \checkmark ✓ | ✓ \checkmark ✓ | × \times × |
| 注释 | ✓ \checkmark ✓ | ✓ \checkmark ✓ | × \times × |
| 类型提示 | × \times × | ✓ \checkmark ✓ | × \times × |
| 错误处理 | × \times × | ✓ \checkmark ✓ | × \times × |
| 文档字符串 | × \times × | ✓ \checkmark ✓ | × \times × |
| 自包含 | × \times × | × \times × | ✓ \checkmark ✓ |
| 优化 | × \times × | × \times × | ✓ \checkmark ✓ |
2 { }^{2} 2 https://google.github.io/styleguide/pyguide.html
3.3.1 SGCR: Style-Guided Code Rewriting
SGCR通过添加文档字符串和类型提示、统一变量重新赋值模式以及按照Google Python Style Guide标准化函数和类名来提高代码可读性。与基线(语法错误和基于linter的过滤)相比,如图4所示,SGCR在HumanEval和HumanEval+上实现了超过9分的改进。我们还评估了SGCR直接应用于原始the-stack-v2-train-smol-ids语料库与先进行语法错误和基于linter的过滤后再应用SGCR的效果。如图4所示,带有语法和linter过滤的SGCR管道在下游代码生成基准测试中比直接应用SGCR高出约2分。因此,我们在所有后续实验中采用了先进行语法和基于linter的过滤再进行SGCR的管道。
消融研究表明,SGCR显著提高了HumanEval和HumanEval+的分数,但在MBPP基准测试中导致了大约10分的下降 [9](见附录G)。分析表明,MBPP的标准解决方案经常使用非标准的函数和类名,SGCR的自动重命名引入了与MBPP测试框架不匹配的标识符,导致“未定义”错误。这些发现掩盖了模型真实的代码生成能力,促使我们在所有实验中排除MBPP作为代码生成性能指标。
3.3.2 SCOR: Self-Contained Optimization Rewriting
尽管SGCR解决了样式不一致的问题,但它不会修改程序语义。对SGCR处理的数据训练的模型进行手动检查揭示了三个反复出现的问题:(i) 缺失依赖项,模型尝试导入不存在的库或调用未定义的函数,导致运行时错误;(ii) 低效算法,例如使用幼稚递归或二次方法处理可以线性时间或动态规划解决的任务;(iii) 琐碎代码片段,例如仅打印常量或执行基本算术运算的代码,提供的训练价值最小。
为了在保留SGCR样式改进的同时解决这些限制,我们引入了SelfContained Optimization Rewriting(SCOR)。在十规则提示(见附录D.2)的指导下,并使用Llama-3.3-70B-Instruct执行,SCOR重写每个片段以确保自包含性,通过内联或满足外部依赖项,用更有效的替代方案替换低效算法,并将琐碎代码转换为有意义且可执行的示例。如图4所示,与SGCR相比,SCOR使HumanEval和HumanEval+的分数提高了超过5分。这些结果强调了语义级重写的重要性,超越了样式改进,确立了SCOR作为SwallowCode构建管道的最后阶段。虽然我们没有单独评估SCOR,但LLM提示验证实验表明,同时应用SGCR和SCOR往往会因LLM难以应对多个目标而降低重写质量,这促使我们采用两阶段的SGCR → SCOR方法,SCOR单独评估留作未来工作。
3.4 最终的SwallowCode数据集
将完整管道——语法错误过滤、基于Pylint的过滤、StyleGuided Code Rewriting(SGCR)和Self-Contained Optimization Rewriting(SCOR)——应用于the-stack-v2-train-smol-ids,产生了包含161亿标记的SwallowCode语料库。所有中间产物,包括非最优变体,均公开可用以支持未来的研究工作。
与现有语料库的比较 图1将SwallowCode与几个广泛使用的开源代码数据集进行了比较:CodeParrot-Clean(128亿标记) 3 { }^{3} 3、The Stack v1(982亿标记)[1]、The Stack v2-Smol(361亿标记)[2] 和 Stack-Edu(179亿标记)[3]。为了公平比较,我们仅提取每个语料库的Python子集,并按照第3.1节中概述的协议,在500亿标记的混合批次中分配80亿代码标记,确保每个样本最多被处理一次。SwallowCode在HumanEval(pass@1)和HumanEval+(pass@1)基准测试中超越了所有可比的公开可用语料库,证明了我们管道设计的有效性。详细结果见附录H.1。
3
{ }^{3}
3 https://huggingface.co/datasets/codeparrot/codeparrot-clean
语言通用性 尽管我们的实验专注于Python以促进自动化评估,但该管道的组件是语言无关的,只需要(i) 静态语法检查和(ii) 存在一个linter或样式工具。因此,该方法可以轻松适应其他编程语言,只需最少的修改。
4 数学语料库的构建
第3节展示了LLM驱动的重写如何显著增强代码语料库的质量。为了评估这种方法的通用性,我们对数学数据应用了专门的重写管道。我们选择了finemath-4+ [3],这是一个高质量的公开可用数学语料库,作为起点,并通过特定领域的重写管道对其进行处理。根据finemath [3]的评估,它在诸如GSM8K和MATH等基准测试中的质量超过了其他开放数学数据集,包括OpenWebMath [4]、InfiMMMath [28] 和 finemath-3+。鉴于其报告的卓越性能和公开可用性,我们采用finemath-4+作为构建数学语料库的基础语料库,以最大化我们重写方法的有效性。
4.1 实验设置
我们遵循第3.1节中概述的协议,对Llama-3.1-8B进行大约500亿标记的持续预训练,仅改变目标数学语料库。评估套件与第3.1节相同,将HumanEval+替换为MATH数据集 [29],包括以下基准测试:OpenBookQA、TriviaQA、HellaSwag、SQuAD 2.0、XWinO、MMLU、BBH、HumanEval、GSM8K 和 MATH,其中GSM8K和MATH为主要聚焦数学的基准测试。预训练混合物包括 82.2 % 82.2 \% 82.2% 多语言文本、 13.0 % 13.0 \% 13.0% 代码和 4.79 % 4.79 \% 4.79% 数学;详细比例和数据来源见附录A.4.1。完整超参数列表见附录A.1。
4.2 LLM驱动的重写
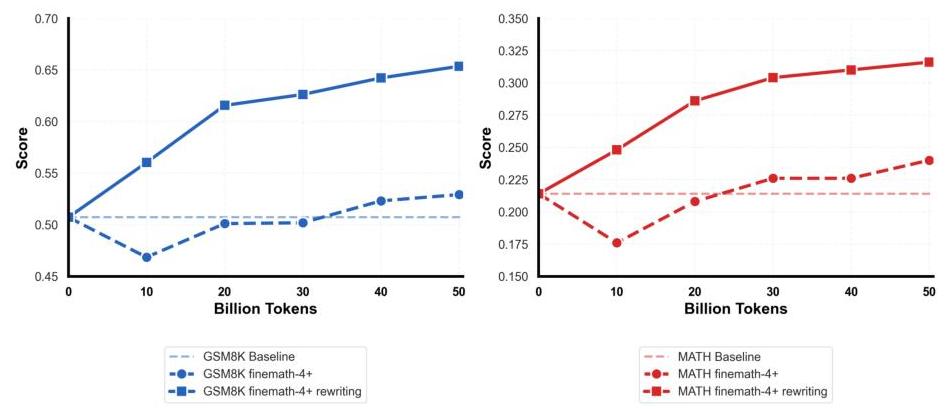
图5:在50B标记持续预训练消融研究中,LLM驱动的finemath-4+重写带来的性能提升。重写后的语料库在GSM8K(左)上提高了12.4分,在MATH(右)上提高了7.6分。
finemath-4+语料库 [3] 包含从高级数学问题到基本算术的各种数据,外加多余的非数学文档。这种异质性使得基于规则的过滤变得困难,因为它难以区分相关数学内容与无关项目。为了解决这个问题,我们设计了一个由Llama-3.3-70B-Instruct驱动的重写管道,不仅清理和精炼数据,还增强了其在数学推理任务中的质量。
该管道指示模型:(1) 删除剩余的网页标题、页脚和隐私声明;(2) 消除多余元数据,例如问题和答案的时间戳;(3) 恢复不完整问题或答案中缺失的上下文;(4) 重写解释使其简明但全面;(5) 提供清晰的分步解决方案。步骤(1)和(2)类似于应用于SwallowCode的语法错误和基于linter的过滤(第3节),解决了基于规则的方法无法有效过滤的不当内容。步骤(3)至(5)与代码重写管道的自包含性和样式增强平行,将其适应数学领域。完整的提示见附录E。
如图5所示,重写后的语料库带来了显著的改进:在500亿标记持续预训练消融实验中,GSM8K提高了12.4分,MATH提高了7.6分。这些结果表明,LLM驱动的重写虽然针对数学数据的独特特征进行了调整,但仍成功增强了已经高质量的finemath-4+语料库。这证实了我们重写方法在代码之外的通用性,提供了一种强大的方法来改进数学推理的开放领域数据集。
5 限制
尽管SwallowCode和SwallowMath显著提升了代码生成和数学推理能力,但应注意几个限制。首先,重写管道可能会保留源数据中存在的偏差。例如,the-stack-v2-train-smol-ids可能过度代表某些编码模式(如递归算法多于迭代算法),而Finemath-4+可能偏好特定问题类型(如代数多于几何)。此外,由于重写过程依赖于Llama-3.3-70B-Instruct,生成的数据集可能反映该模型的偏好,如偏好某些变量命名约定或解决方案策略,这可能限制其通用性。其次,我们的评估局限于500亿标记预算内的持续预训练,如第3.1节所述,以确保在计算限制内进行受控和可重复的实验。超出此预算的预训练影响尚未探索,较大规模任务的性能趋势可能有所不同,特别是那些需要大量训练数据的任务。第三,尽管SwallowCode管道设计为语言无关,只需要静态语法检查和linter工具,但我们的实验仅专注于Python以促进自动化评估。由于资源限制,Java、C++等其他语言的经验验证不可行,限制了该管道更广泛应用的证据。
6 结论
我们介绍了SwallowCode和SwallowMath,这两个根据Llama 3.3社区许可公开发布的语料库,旨在通过系统地重写数据来提升大型语言模型(LLM)在程序合成和数学推理方面的性能。与依赖排他性过滤(如Stack-Edu [3])或有限转换(如Jain等人 [12])的先前方法不同,我们的转换和保留范式升级了低质量数据,最大化了其效用。SwallowCode(约161亿个标记)通过四阶段管道改进了The-Stack-v2 [2] 中的Python片段:语法验证、基于pylint的样式过滤、Style-Guided Code Rewriting(SGCR)和SelfContained Optimization Rewriting(SCOR)。SwallowMath(约23亿个标记)通过删除样板代码、恢复上下文和重新格式化解决方案为简洁的分步解释增强了Finemath
4
+
[
3
]
4+[3]
4+[3]。
对Llama-3.1-8B [5]进行500亿标记的持续预训练,使用SwallowCode超越了基线模型的代码生成能力,在HumanEval上实现了pass@1增益
+
17.0
\mathbf{+ 17 . 0}
+17.0,在HumanEval+上实现了+17.7,相比Stack-Edu。类似地,替换为SwallowMath后,GSM8K上的准确率提高了+12.4,MATH上的准确率提高了+7.6。消融研究表明,每个管道阶段都逐步贡献,其中重写阶段提供了最重要的提升。严格的检查确保无测试集泄露,强化了这些结果的稳健性。
尽管我们的实验专注于Python以进行自动化评估,但该管道的设计是语言无关的,只需要可解析语法和linter,正如第3.4节讨论的那样。为了实现可重复研究并促进LLM能力的发展,我们发布了所有数据集、提示和检查点。SwallowCode和SwallowMath建立了一个高质量数据整理的可扩展框架,为增强自动推理和软件开发铺平了道路。
参考文献
[1] Denis Kocetkov, Raymond Li, Loubna Ben Allal, Jia Li, Chenghao Mou, Carlos Muñoz Ferrandis, Yacine Jernite, Margaret Mitchell, Sean Hughes, Thomas Wolf, Dzmitry Bahdanau, Leandro von Werra, 和 Harm de Vries. The stack: 3 tb of permissively licensed source code, 2022. URL https://arxiv.org/abs/2211.15533.
[2] Anton Lozhkov, Raymond Li, Loubna Ben Allal, Federico Cassano, Joel Lamy-Poirier, Nouamane Tazi, Ao Tang, Dmytro Pykhtar, Jiawei Liu, Yuxiang Wei, Tianyang Liu, Max Tian, Denis Kocetkov, Arthur Zucker, Younes Belkada, Zijian Wang, Qian Liu, Dmitry Abulkhanov, Indraneil Paul, Zhuang Li, Wen-Ding Li, Megan Risdal, Jia Li, Jian Zhu, Terry Yue Zhuo, Evgenii Zheltonozhskii, Nii Osae Osae Dade, Wenhao Yu, Lucas Krauß, Naman Jain, Yixuan Su, Xuanli He, Manan Dey, Edoardo Abati, Yekun Chai, Niklas Muennighoff, Xiangru Tang, Muhtasham Oblokulov, Christopher Akiki, Marc Marone, Chenghao Mou, Mayank Mishra, Alex Gu, Binyuan Hui, Tri Dao, Armel Zebaze, Olivier Dehaene, Nicolas Patry, Canwen Xu, Julian McAuley, Han Hu, Torsten Scholak, Sebastien Paquet, Jennifer Robinson, Carolyn Jane Anderson, Nicolas Chapados, Mostofa Patwary, Nima Tajbakhsh, Yacine Jernite, Carlos Muñoz Ferrandis, Lingming Zhang, Sean Hughes, Thomas Wolf, Arjun Guha, Leandro von Werra, 和 Harm de Vries. Starcoder 2 和 the stack v2: 下一代, 2024. URL https://arxiv.org/abs/2402.19173.
[3] Loubna Ben Allal, Anton Lozhkov, Elie Bakouch, Gabriel Martín Blázquez, Guilherme Penedo, Lewis Tunstall, Andrés Marafioti, Hynek Kydliček, Agustín Piqueres Lajarín, Vaibhav Srivastav, Joshua Lochner, Caleb Fahlgren, Xuan-Son Nguyen, Clémentine Fourrier, Ben Burtenshaw, Hugo Larcher, Haojun Zhao, Cyril Zakka, Mathieu Morlon, Colin Raffel, Leandro von Werra, 和 Thomas Wolf. Smollm2: 当smol变大时 - 小型语言模型的数据中心训练, 2025. URL https://arxiv.org/abs/2502.02737.
[4] Keiran Paster, Marco Dos Santos, Zhangir Azerbayev, 和 Jimmy Ba. Openwebmath: 一个高质量数学网络文本的开放数据集, 2023. URL https://arxiv.org/abs/2310. 06786 .
[5] Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mitra, Archie Sravankumar, Artem Korenev, Arthur Hinsvark, Arun Rao, Aston Zhang, Aurelien Rodriguez, Austen Gregerson, Ava Spataru, Baptiste Roziere, Bethany Biron, Binh Tang, Bobbie Chern, Charlotte Caucheteux, Chaya Nayak, Chloe Bi, Chris Marra, Chris McConnell, Christian Keller, Christophe Touret, Chunyang Wu, Corinne Wong, Cristian Canton Ferrer, Cyrus Nikolaidis, Damien Allonsius, Daniel Song, Danielle Pintz, Danny Livshits, Danny Wyatt, David Esiobu, Dhruv Choudhary, Dhruv Mahajan, Diego Garcia-Olano, Diego Perino, Dieuwke Hupkes, Egor Lakomkin, Ehab AlBadawy, Elina Lobanova, Emily Dinan, Eric Michael Smith, Filip Radenovic, Francisco Guzmán, Frank Zhang, Gabriel Synnaeve, Gabrielle Lee, Georgia Lewis Anderson, Govind Thattai, Graeme Nail, Gregoire Mialon, Guan Pang, Guillem Cucurell, Hailey Nguyen, Hannah Korevaar, Hu Xu, Hugo Touvron, Iliyan Zarov, Imanol Arrieta Ibarra, Isabel Kloumann, Ishan Misra, Ivan Evtimov, Jack Zhang, Jade Copet, Jaewon Lee, Jan Geffert, Jana Vranes, Jason Park, Jay Mahadeokar, Jeet Shah, Jelmer van der Linde, Jennifer Billock, Jenny Hong, Jenya Lee, Jeremy Fu, Jianfeng Chi, Jianyu Huang, Jiawen Liu, Jie Wang, Jiecao Yu, Joanna Bitton, Joe Spisak, Jongsoo Park, Joseph Rocca, Joshua Johnstun, Joshua Saxe, Junteng Jia, Kalyan Vasuden Alwala, Karthik Prasad, Kartikeya Upasani, Kate Plawiak, Ke Li, Kenneth Heafield, Kevin Stone, Khalid El-Arini, Krithika Iyer, Kshitiz Malik, Kuenley Chiu, Kunal Bhalla, Kushal Lakhotia, Lauren Rantala-Yeary, Laurens van der Maaten, Lawrence Chen, Liang Tan, Liz Jenkins, Louis Martin, Lovish Madaan, Lubo Malo, Lukas Blecher, Lukas Landzaat, Luke de Oliveira, Madeline Muzzi, Mahesh Pasupuleti, Mannat Singh, Manohar Paluri, Marcin Kardas, Maria Tsimpoukelli, Mathew Oldham, Mathieu Rita, Maya Pavlova, Melanie Kambadur, Mike Lewis, Min Si, Mitesh Kumar Singh, Mona Hassan, Naman Goyal, Narjes Torabi, Nikolay Bashlykov, Nikolay Bogoychev, Niladri Chatterji, Ning Zhang, Olivier Duchenne, Onur Çelebi, Patrick Alrassy, Pengchuan Zhang, Pengwei Li, Petar Vasic, Peter Weng, Prajjwal Bhargava, Pratik Dubal, Praveen Krishnan, Punit Singh Koura, Puxin Xu, Qing He, Qingxiao Dong, Ragavan Srinivasan, Raj Ganapathy, Ramon Calderer, Ricardo Silveira Cabral, Robert Stojnic, Roberta Raileanu, Rohan Maheswari, Rohit Girdhar, Rohit Patel, Romain Sauvestre, Ronnie Polidoro, Roshan Sumbaly, Ross Taylor, Ruan Silva, Rui Hou, Rui Wang, Saghar Hosseini, Sahana Chennabasappa, Sanjay Singh, Sean Bell, Seohyun Sonia Kim, Sergey Edunov, Shaoliang Nie, Sharan Narang, Sharath Raparthy, Sheng Shen, Shengye Wan, Shruti Bhosale, Shun Zhang, Simon Vandenhende, Soumya Batra, Spencer Whitman, Sten Sootla, Stephane Collot, Suchin Gururangan, Sydney Borodinsky, Tamar Herman, Tara Fowler, Tarek Sheasha, Thomas Georgiou, Thomas Scialom, Tobias Speckbacher, Todor Mihaylov, Tong Xiao, Ujjwal Karn, Vedanuj Goswami, Vibhor Gupta, Vignesh Ramanathan, Viktor Kerkez, Vincent Gonguet, Virginie Do, Vish Vogeti, Vítor Albiero, Vladan Petrovic, Weiwei Chu, Wenhan Xiong, Wenyin Fu, Whitney Meers, Xavier Martinet, Xiaodong Wang, Xiaofang Wang, Xiaoqing Ellen Tan, Xide Xia, Xuchao Jia, Xuewei Wang, Yaelle Goldschlag, Yashesh Gaur, Yasmine Babaei, Yi Wen, Yiwen Song, Yuchen Zhang, Yue Li, Yuning Mao, Zacharie Delpierre Coudert, Zheng Yan, Zhengxing Chen, Zoe Papakipos, Aaditya Singh, Aayushi Srivastava, Abha Jain, Adam Kelsey, Adam Shajnfeld, Adithya Gangidi, Adolfo Victoria, Ahuva Goldstand, Ajay Menon, Ajay Sharma, Alex Boesenberg, Alexei Baevski, Allie Feinstein, Amanda Kallet, Amit Sangani, Amos Teo, Anam Yunus, Andrei Lupu, Andres Alvarado, Andrew Caples, Andrew Gu, Andrew Ho, Andrew Poulton, Andrew Ryan, Ankit Ramchandani, Annie Dong, Annie Franco, Anuj Goyal, Aparajita Saraf, Arkabandhu Chowdhury, Ashley Gabriel, Ashwin Bharambe, Assaf Eisenman, Azadeh Yazdan, Beau James, Ben Maurer, Benjamin Leonhardi, Bernie Huang, Beth Loyd, Beto De Paola, Bhargavi Paranjape, Bing Liu, Bo Wu, Boyu Ni, Braden Hancock, Bram Wasti, Brandon Spence, Brani Stojkovic, Brian Gamido, Britt Montalvo, Carl Parker, Carly Burton, Catalina Mejia, Ce Liu, Changhan Wang, Changkyu Kim, Chao Zhou, Chester Hu, Ching-Hsiang Chu, Chris Cai, Chris Tindal, Christoph Feichtenhofer, Cynthia Gao, Damon Civin, Dana Beaty, Daniel Kreymer, Daniel Li, David Adkins, David Xu, Davide Testuggine, Delia David, Devi Parikh, Diana Liskovich, Didem Foss, Dingkang Wang, Duc Le, Dustin Holland, Edward Dowling, Eissa Jamil, Elaine Montgomery, Eleonora Presani, Emily Hahn, Emily Wood, Eric-Tuan Le, Erik Brinkman, Esteban Arcaute, Evan Dunbar, Evan Smothers, Fei Sun, Felix Kreuk, Feng Tian, Filippos Kokkinos, Firat Ozgenel, Francesco Caggioni, Frank Kanayet, Frank Seide, Gabriela Medina Florez, Gabriella Schwarz, Gada Badeer, Georgia Swee, Gil Halpern, Grant Herman, Grigory Sizov, Guangyi, Zhang, Guna Lakshminarayanan, Hakan Inan, Hamid Shojanazeri, Han Zou, Hannah Wang, Hanwen Zha, Haroun Habeeb, Harrison Rudolph, Helen Suk, Henry Aspegren, Hunter Goldman, Hongyuan Zhan, Ibrahim Damlaj, Igor Molybog, Igor Tufanov, Ilias Leontiadis, Irina-Elena Veliche, Itai Gat, Jake Weissman, James Geboski, James Kohli, Janice Lam, Japhet Asher, Jean-Baptiste Gaya, Jeff Marcus, Jeff Tang, Jennifer Chan, Jenny Zhen, Jeremy Reizenstein, Jeremy Teboul, Jessica Zhong, Jian Jin, Jingyi Yang, Joe Cummings, Jon Carvill, Jon Shepard, Jonathan McPhie, Jonathan Torres, Josh Ginsburg, Junjie Wang, Kai Wu, Kam Hou U, Karan Saxena, Kartikay Khandelwal, Katayoun Zand, Kathy Matosich, Kaushik Veeraraghavan, Kelly Michelena, Keqian Li, Kiran Jagadeesh, Kun Huang, Kunal Chawla, Kyle Huang, Lailin Chen, Lakshya Garg, Lavender A, Leandro Silva, Lee Bell, Lei Zhang, Liangpeng Guo, Licheng Yu, Liron Moshkovich, Luca Wehrstedt, Madian Khabsa, Manav Avalani, Manish Bhatt, Martynas Mankus, Matan Hasson, Matthew Lennie, Matthias Reso, Maxim Groshev, Maxim Naumov, Maya Lathi, Meghan Keneally, Miao Liu, Michael L. Seltzer, Michal Valko, Michelle Restrepo, Mihir Patel, Mik Vyatskov, Mikayel Samvelyan, Mike Clark, Mike Macey, Mike Wang, Miquel Jubert Hermoso, Mo Metanat, Mohammad Rastegari, Munish Bansal, Nandhini Santhanam, Natascha Parks, Natasha White, Navyata Bawa, Nayan Singhal, Nick Egebo, Nicolas Usunier, Nikhil Mehta, Nikolay Pavlovich Laptev, Ning Dong, Norman Cheng, Oleg Chernoguz, Olivia Hart, Omkar Salpekar, Ozlem Kalinli, Parkin Kent, Parth Parekh, Paul Saab, Pavan Balaji, Pedro Rittner, Philip Bontrager, Pierre Roux, Piotr Dollar, Polina Zvyagina, Prashant Ratanchandani, Pritish Yuvraj, Qian Liang, Rachad Alao, Rachel Rodriguez, Rafi Ayub, Ragavan Srinivasan, Raj Ganapathy, Ramon Calderer, Ricardo Silveira Cabral, Robert Stojnic, Roberta Raileanu, Rohan Maheswari, Rohit Girdhar, Rohit Patel, Romy Sauvestre, Ronnie Polidoro, Roshan Sumbaly, Ross Taylor, Ruan Silva, Rui Hou, Rui Wang, Saghar Hosseini, Sahana Chennabasappa, Sanjay Singh, Sean Bell, Seohyun Sonia Kim, Sergey Edunov, Shaoliang Nie, Sharan Narang, Sharadh Ramaswamy, Shaun Lindsay, Shaun Lindsay, Sheng Feng, Shenghao Lin, Shengxin Cindy Zha, Shishir Patil, Shiva Shankar, Shuqiang Zhang, Shuqiang Zhang, Sinong Wang, Sneha Agarwal, Soji Sajuyigbe, Soumith Chintala, Stephanie Max, Stephen Chen, Steve Kehoe, Steve Satterfield, Sudarshan Govindaprasad, Sumit Gupta, Summer Deng, Sungmin Cho, Sunny Virk, Suraj Subramanian, Sy Choudhury, Sydney Goldman, Tal Remez, Tamar Glaser, Tamara Best, Thilo Koehler, Thomas Robinson, Tianhe Li, Tianjun Zhang, Tim Matthews, Timothy Chou, Tzook Shaked, Varun Vontimitta, Victoria Ajayi, Victoria Montanez, Vijai Mohan, Vinay Satish Kumar, Vishal Mangla, Vlad Ionescu, Vlad Poenaru, Vlad Tiberiu Mihailescu, Vladimir Ivanov, Wei Li, Wenchen Wang, Wenwen Jiang, Wes Bouaziz, Will Constable, Xiaocheng Tang, Xiaojian Wu, Xiaolan Wang, Xilun Wu, Xinbo Gao, Yaniv Kleinman, Yanjun Chen, Ye Hu, Ye Jia, Ye Qi, Yenda Li, Yilin Zhang, Ying Zhang, Yossi Adi, Youngjin Nam, Yu Wang, Yu Zhao, Yuchen Hao, Yundi Qian, Yunlu Li, Yuzi He, Zach Rait, Zachary DeVito, Zef Rosnbrick, Zhaoduo Wen, Zhenyu Yang, Zhiwei Zhao, 和 Zhiyu Ma. The llama 3 herd of models, 2024. URL https://arxiv.org/abs/2407.21783.
[6] Guilherme Penedo, Hynek Kydlíček, Loubna Ben allal, Anton Lozhkov, Margaret Mitchell, Colin Raffel, Leandro Von Werra, 和 Thomas Wolf. The fineweb datasets: Decanting the web for the finest text data at scale, 2024. URL https://arxiv.org/abs/2406.17557.
[7] Loubna Ben Allal, Anton Lozhkov, Elie Bakouch, Leandro von Werra, 和 Thomas Wolf. Smollm - blazingly fast and remarkably powerful, 2024.
[8] Raymond Li, Loubna Ben Allal, Yangtian Zi, Niklas Muennighoff, Denis Kocetkov, Chenghao Mou, Marc Marone, Christopher Akiki, Jia Li, Jenny Chim, Qian Liu, Evgenii Zheltonozhskii, Terry Yue Zhuo, Thomas Wang, Olivier Dehaene, Mishig Davaadorj, Joel Lamy-Poirier, João Monteiro, Oleh Shliazhko, Nicolas Gontier, Nicholas Meade, Armel Zebaze, Ming-Ho Yee, Logesh Kumar Umapathi, Jian Zhu, Benjamin Lipkin, Muhtasham Oblokulov, Zhiruo Wang, Rudra Murthy, Jason Stillerman, Siva Sankalp Patel, Dmitry Abulkhanov, Marco Zocca, Manan Dey, Zhihan Zhang, Nour Fahmy, Urvashi Bhattacharyya, Wenhao Yu, Swayam Singh, Sasha Luccioni, Paulo Villegas, Maxim Kunakov, Fedor Zhdanov, Manuel Romero, Tony Lee, Nadav Timor, Jennifer Ding, Claire Schlesinger, Hailey Schoelkopf, Jan Ebert, Tri Dao, Mayank Mishra, Alex Gu, Jennifer Robinson, Carolyn Jane Anderson, Brendan Dolan-Gavitt, Danish Contractor, Siva Reddy, Daniel Fried, Dzmitry Bahdanau, Yacine Jernite, Carlos Muñoz Ferrandis, Sean Hughes, Thomas Wolf, Arjun Guha, Leandro von Werra, 和 Harm de Vries. Starcoder: may the source be with you!, 2023. URL https://arxiv.org/abs/2305.06161.
[9] Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, 和 Charles Sutton. Program synthesis with large language models, 2021. URL https://arxiv.org/abs/2108.07732.
[10] Loubna Ben Allal, Anton Lozhkov, Guilherme Penedo, Thomas Wolf, 和 Leandro von Werra. Cosmopedia, February 2024. URL https://huggingface.co/datasets/ HuggingFaceTB/cosmopedia. 软件数据集.
[11] Albert Q. Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, Gianna Lengyel, Guillaume Bour, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Sandeep Subramanian, Sophia Yang, Szymon Antoniak, Teven Le Scao, Théophile Gervet, Thibaut Lavril, Thomas Wang, Timothée Lacroix, 和 William El Sayed. Mixtral of experts, 2024. URL https://arxiv.org/abs/2401.04088.
[12] Naman Jain, Tianjun Zhang, Wei-Lin Chiang, Joseph E. Gonzalez, Koushik Sen, 和 Ion Stoica. Llm-assisted code cleaning for training accurate code generators, 2023. URL https: //arxiv.org/abs/2311.14904.
[13] Siming Huang, Tianhao Cheng, J. K. Liu, Jiaran Hao, Liuyihan Song, Yang Xu, J. Yang, Jiaheng Liu, Chenchen Zhang, Linzheng Chai, Ruifeng Yuan, Zhaoxiang Zhang, Jie Fu, Qian Liu, Ge Zhang, Zili Wang, Yuan Qi, Yinghui Xu, 和 Wei Chu. Opencoder: The open cookbook for top-tier code large language models, 2025. URL https://arxiv.org/abs/2411.04905.
[14] Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, 和 Bryan Catanzaro. Megatron-lm: Training multi-billion parameter language models using model parallelism, 2020. URL https://arxiv.org/abs/1909.08053.
[15] Terry Yue Zhuo, Minh Chien Vu, Jenny Chim, Han Hu, Wenhao Yu, Ratnadira Widyasari, Imam Nur Bani Yusuf, Haolan Zhan, Junda He, Indraneil Paul, 等人. Bigcodebench: Benchmarking code generation with diverse function calls and complex instructions. arXiv preprint arXiv:2406.15877, 2024.
[16] Leo Gao, Jonathan Tow, Baber Abbasi, Stella Biderman, Sid Black, Anthony DiPofi, Charles Foster, Laurence Golding, Jeffrey Hsu, Alain Le Noac’h, Haonan Li, Kyle McDonell, Niklas Muennighoff, Chris Ociepa, Jason Phang, Laria Reynolds, Hailey Schoelkopf, Aviya Skowron, Lintang Sutawika, Eric Tang, Anish Thite, Ben Wang, Kevin Wang, 和 Andy Zou. A framework for few-shot language model evaluation, 072024. URL https://zenodo.org/records/ 12608602 .
[17] Todor Mihaylov, Peter Clark, Tushar Khot, 和 Ashish Sabharwal. Can a suit of armor conduct electricity? a new dataset for open book question answering. In EMNLP, 2018.
[18] Mandar Joshi, Eunsol Choi, Daniel S. Weld, 和 Luke Zettlemoyer. Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, Canada, July 2017. Association for Computational Linguistics.
[19] Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, 和 Yejin Choi. Hellaswag: Can a machine really finish your sentence? In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 2019.
[20] Pranav Rajpurkar, Robin Jia, 和 Percy Liang. Know what you don’t know: Unanswerable questions for squad, 2018.
[21] Alexey Tikhonov 和 Max Ryabinin. It’s all in the heads: Using attention heads as a baseline for cross-lingual transfer in commonsense reasoning, 2021.
[22] Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, 和 Jacob Steinhardt. Measuring massive multitask language understanding, 2021. URL https: //arxiv.org/abs/2009.03300.
[23] Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, 和 John Schulman. Training verifiers to solve math word problems, 2021.
[24] Mirac Suzgun, Nathan Scales, Nathanael Schärli, Sebastian Gehrmann, Yi Tay, Hyung Won Chung, Aakanksha Chowdhery, Quoc V Le, Ed H Chi, Denny Zhou, , 和 Jason Wei. Challenging big-bench tasks and whether chain-of-thought can solve them. arXiv preprint arXiv:2210.09261, 2022.
[25] Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian, Clemens Winter, Philippe Tillet, Felipe Petroski Such, Dave Cummings, Matthias Plappert, Fotios Chantzis, Elizabeth Barnes, Ariel Herbert-Voss, William Hebgen Guss, Alex Nichol, Alex Paino, Nikolas Tezak, Jie Tang, Igor Babuschkin, Suchir Balaji, Shantanu Jain, William Saunders, Christopher Hesse, Andrew N. Carr, Jan Leike, Josh Achiam, Vedant Misra, Evan Morikawa, Alec Radford, Matthew Knight, Miles Brundage, Mira Murati, Katie Mayer, Peter Welinder, Bob McGrew, Dario Amodei, Sam McCandlish, Ilya Sutskever, 和 Wojciech Zaremba. Evaluating large language models trained on code, 2021. URL https: //arxiv.org/abs/2107.03374.
[26] Jiawei Liu, Chunqiu Steven Xia, Yuyao Wang, 和 Lingming Zhang. Is your code generated by chatgpt really correct? rigorous evaluation of large language models for code generation, 2023. URL https://arxiv.org/abs/2305.01210.
[27] Kazuki Fujii, Taishi Nakamura, Mengsay Loem, Hiroki Iida, Masanari Ohi, Kakeru Hattori, Hirai Shota, Sakae Mizuki, Rio Yokota, 和 Naoaki Okazaki. Continual pre-training for cross-lingual llm adaptation: Enhancing japanese language capabilities, 2024. URL https: //arxiv.org/abs/2404.17790.
[28] Xiaotian Han, Yiren Jian, Xuefeng Hu, Haogeng Liu, Yiqi Wang, Qihang Fan, Yuang Ai, Huaibo Huang, Ran He, Zhenheng Yang, 和 Quanzeng You. Infimm-webmath-40b: Advancing multimodal pre-training for enhanced mathematical reasoning, 2024. URL https://arxiv. org/abs/2409.12568.
[29] Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, 和 Jacob Steinhardt. Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874, 2021.
[30] Naoaki Okazaki, Kakeru Hattori, Hirai Shota, Hiroki Iida, Masanari Ohi, Kazuki Fujii, Taishi Nakamura, Mengsay Loem, Rio Yokota, 和 Sakae Mizuki. Building a large japanese web corpus for large language models, 2024. URL https://arxiv.org/abs/2404.17733.
[31] Jeffrey Li, Alex Fang, Georgios Smyrnis, Maor Ivgi, Matt Jordan, Samir Gadre, Hritik Bansal, Etash Guha, Sedrick Keh, Kushal Arora, Saurabh Garg, Rui Xin, Niklas Muennighoff, Reinhard Heckel, Jean Mercat, Mayee Chen, Suchin Gururangan, Mitchell Wortsman, Alon Albalak, Yonatan Bitton, Marianna Nezhurina, Amro Abbas, Cheng-Yu Hsieh, Dhruba Ghosh, Josh Gardner, Maciej Kilian, Hanlin Zhang, Rulin Shao, Sarah Pratt, Sunny Sanyal, Gabriel Ilharco, Giannis Daras, Kalyani Marathe, Aaron Gokaslan, Jieyu Zhang, Khyathi Chandu, Thao Nguyen, Igor Vasiljevic, Sham Kakade, Shuran Song, Sujay Sanghavi, Fartash Faghri, Sewoong Oh, Luke Zettlemoyer, Kyle Lo, Alaaeldin El-Nouby, Hadi Pouransari, Alexander Toshev, Stephanie Wang, Dirk Groeneveld, Luca Soldaini, Pang Wei Koh, Jenia Jitsev, Thomas Kollar, Alexandros G. Dimakis, Yair Carmon, Achal Dave, Ludwig Schmidt, 和 Vaishaal Shankar. Datacomp-lm: In search of the next generation of training sets for language models, 2025. URL https://arxiv.org/abs/2406.11794.
[32] Deepak Narayanan, Mohammad Shoeybi, Jared Casper, Patrick LeGresley, Mostofa Patwary, Vijay Anand Korthikanti, Dmitri Vainbrand, Prethvi Kashinkunti, Julie Bernauer, Bryan Catanzaro, Amar Phanishayee, 和 Matei Zaharia. Efficient large-scale language model training on gpu clusters using megatron-lm, 2021. URL https://arxiv.org/abs/2104.04473.
A 数据消融实验的详细设置
本节提供了在第3节和第4节描述的数据集消融实验中使用的训练超参数、训练库版本、训练环境、分布式训练设置和数据混合的详细信息。
A. 1 训练超参数
我们从Llama-3.1-8B 4 { }^{4} 4 进行了持续预训练,使用了大约500亿标记。如表2所示,模型架构和分词器与Llama-3.1-8B相同。训练超参数详见表3。
表2:训练模型的架构
| 超参数 | 值 |
|---|---|
| 架构 | Llama-3 |
| 隐藏大小 | 4096 |
| FFN隐藏大小 | 14336 |
| 层数 | 32 |
| 注意力头数 | 32 |
| 键/值头数 | 8 |
| 序列长度 | 8192 |
| 归一化 | RMSNorm |
| RMSNorm epsilon | 1.0 × 1 0 − 5 1.0 \times 10^{-5} 1.0×10−5 |
| RoPE base | 500000 |
| 注意力dropout | 0.0 |
| 隐藏层dropout | 0.0 |
| 分词器 | Llama-3 分词器 |
表3:训练超参数
| 超参数 | 值 |
|---|---|
| Adam beta1 | 0.9 |
| Adam beta2 | 0.95 |
| Adam epsilon | 1.0 × 1 0 − 8 1.0 \times 10^{-8} 1.0×10−8 |
| 梯度裁剪 | 1.0 |
| 权重衰减 | 0.1 |
| 学习率 (最大) | 2.5 × 1 0 − 5 2.5 \times 10^{-5} 2.5×10−5 |
| 学习率 (最小) | 2.5 × 1 0 − 6 2.5 \times 10^{-6} 2.5×10−6 |
| 预热步数 | 1000 |
| 预热方式 | 线性 |
| 衰减方式 | 余弦 |
A. 2 训练环境
我们在东京理科大学TSUBAME 5 { }^{5} 5 超级计算机上进行了训练。我们使用混合精度(bfloat16)并使用多个NVIDIA H100节点进行分布式并行训练。每个节点配备了四个NVIDIA H100 94GB GPU,并通过InfiniBand NDR200互连。
我们使用表4中列出的库进行了持续预训练。
4
{ }^{4}
4 https://huggingface.co/meta-1lama/Llama-3.1-8B
5
{ }^{5}
5 https://www.t4.cii.isct.ac.jp/docs/handbook.en/
表4:训练库版本
| 组件 / 库 | 版本 |
|---|---|
| 训练库 | Megatron-LM |
| mcore | 0.9 .0 |
| CUDA Toolkit | 12.4 |
| cuDNN | 9.1 .0 |
| NCCL | 2.21 .5 |
| HPC-X | 2.17 .1 |
| ninja | 1.11 .1 |
| PyTorch | 2.5 .0 |
| TransformerEngine | 1.12 |
A. 3 分布式训练设置
在单个GPU上训练大型语言模型具有挑战性,因为既受GPU内存限制,又需要大量时间来完成训练。就GPU内存而言,即使使用最新的H100 80GB,也难以训练本研究中使用的8B模型。此外,即使模型参数、梯度和优化器状态可以适应单个GPU,仅在单个GPU上训练仍需要不切实际的时间才能完成。因此,在本研究中,我们采用了结合数据并行和模型并行的分布式并行训练。我们在表5所示的分布式设置下进行了所有消融实验。
表5:消融实验的分布式训练设置
| 超参数 | 值 |
|---|---|
| 数据并行(DP) | 32 |
| 张量并行(TP) | 2 |
| 上下文并行(CP) | 1 |
| 管道并行(PP) | 1 |
| 微批次大小 | 2 |
| 全局批次大小 | 512 |
| 序列并行 | true |
| 分布式优化器 | true |
| 张量并行通信重叠 | true |
A. 4 消融实验的数据混合
A.4.1 代码消融数据混合
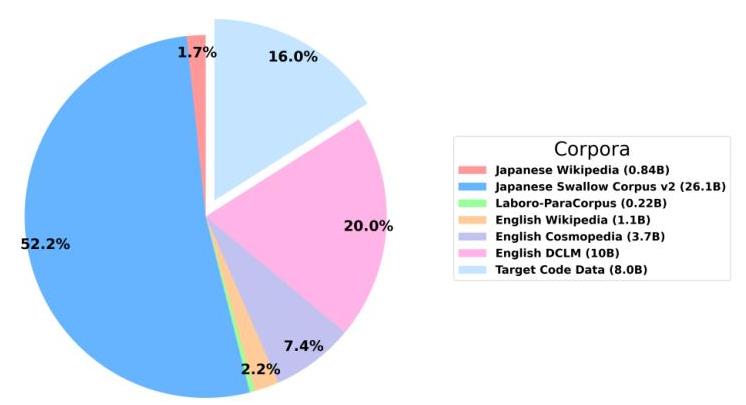
图6:SwallowCode消融实验的数据比例。
代码消融实验的训练数据集包含大约500亿标记。数据组件的分布如图6所示,以下是各组件及其相应的标记数量。请注意,目标代码数据因具体消融实验而异。
- 日本维基百科 8 : 0.84 { }^{8}: 0.84 8:0.84 亿标记
-
- 日本Swallow语料库 v2 [30]: 26.1亿标记
-
- Laboro-ParaCorpus 7 : 0.22 { }^{7}: 0.22 7:0.22 亿标记
-
- 英语维基百科 8 : 1.1 { }^{8}: 1.1 8:1.1 亿标记
-
- 英语Cosmopedia [10]: 3.7亿标记
-
- 英语DCLM [31]: 10.0亿标记
-
- 目标代码数据: 8.0亿标记
A.4.2 数学消融数据混合
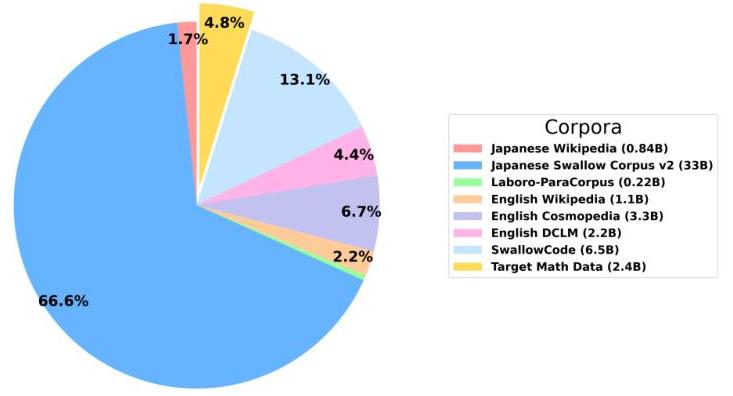
图7:SwallowMath消融实验的数据比例。
数学消融实验的训练数据集也由大约500亿标记组成。数据集的组成如图7所示,以下是各组件及其相应的标记数量。请注意,目标数学数据因具体消融实验而异。
- 日本维基百科 9 : 0.84 { }^{9}: 0.84 9:0.84 亿标记
-
- 日本Swallow语料库 v2 [30]: 33.0亿标记
-
- Laboro-ParaCorpus 10 : 0.22 { }^{10}: 0.22 10:0.22 亿标记
-
- 英语维基百科 11 : 1.1 { }^{11}: 1.1 11:1.1 亿标记
-
- 英语Cosmopedia [10]: 3.3亿标记
-
- 英语DCLM [31]: 2.2亿标记
-
- SwallowCode(语法、Pylint过滤): 6.5亿标记
-
- 目标数学数据: 2.4亿标记
8
{ }^{8}
8 https://dumps.wikimedia.org/jawiki/
7
{ }^{7}
7 https://github.com/laboroai/Laboro-ParaCorpus
8
{ }^{8}
8 https://dumps.wikimedia.org/enwiki/
9
{ }^{9}
9 https://dumps.wikimedia.org/jawiki/
10
{ }^{10}
10 https://github.com/laboroai/Laboro-ParaCorpus
11
{ }^{11}
11 https://dumps.wikimedia.org/enwiki/
B 代码lint过滤
7.0的阈值平衡了代码质量和数据集大小,同时评论处罚减少了过于冗长或非功能性脚本的数量。如第3.2.2节所述,执行linter过滤的代码在https://github.com/rioyokotalab/swallow-code-math公开提供。相关代码也在下方提供。
当使用pylint进行检查时,依赖于lint环境的警告和错误(例如导入错误或行长度违规)使用–disable选项排除。此外,一些文件主要包含文本内容的注释,具有极少的脚本功能。为了解决这个问题,如第3.2.2节所述,我们引入了一个基于注释比例的启发式处罚机制,以过滤掉此类文件。
def check_comment_ratio(code: str):
total_lines = 0
comment_lines = 0
try:
tokens = tokenize.generate_tokens(StringIO(code).readline)
for token_type, _, _, _ _ in tokens:
total_lines += 1
if token_type == tokenize.COMMENT:
comment_lines += 1
except tokenize.TokenError as e:
print(f"Token error encountered: {str(e)}“)
return 0
except IndentationError as e:
print(f"Indentation error encountered {str(e)}”)
return 0
if total_lines == 0:
return 0
return comment_lines / total_lines
def apply_comment_penalty(score: float, comment_ratio: float) -> float
if comment_ratio == 1.0:
return 0.0
elif comment_ratio > 0:
penalty_factor = 1 - comment_ratio
score += penalty_factor
return score
def check_code_quality(code: str):
with tempfile.NamedTemporaryFile(delete=False, suffix=“.py”) as
temp_file:
temp_file.write(code.encode())
temp_file.flush()
result = subprocess.run(
[“pylint”, “–persistent=n”,“–disable=E0401,C0114,C0301,
C0103,C0116,C0411,R0903,W0511,C0412”, temp_file.name],
capture_output=True,
text=True,
)
pylint_output = result.stdout
score = None
for line in pylint_output.split(“\n”):
if "Your code has been rated at" in line:
score = float(line.split("/")[0].split()[-1])
comment_ratio = check_comment_ratio(code)
if score is not None:
score = apply_comment_penalty(score, comment_ratio)
return score, pylint_output
C 基于LLM的代码评分
如第3.2.3节所述,本节介绍了用于LLM评分的提示。该提示提供给Llama-3.3-70B-Instruct以评估代码质量。评分标准参考了Google Python Style Guide 12 { }^{12} 12。实际代码管道可在https://github.com/rioyokotalab/swallow-code-math获取。通过此过程创建的数据集可在https://huggingface.co/datasets/tokyotech-1lm/swallow-code获取,通过此数据集训练的模型检查点可在https://huggingface. co/collections/tokyotech-1lm/swallowcode-6811c84ff647568547d4e443获取。
用于代码质量评估的提示
您是一位聪明的软件工程师。请根据以下标准对以下代码进行1到10的评分:
- 变量名是否描述性强且符合命名约定?
-
- 注释和文档字符串是否适当编写以解释代码的目的和功能?
-
- 是否在适用的情况下有效使用了类型注解?
-
- 函数是否模块化良好,具有明确的责任划分和清晰的关注点分离?
-
- 是否有意管理变量的生命周期,避免频繁重新赋值或过长的作用域?
-
- 在必要时是否正确实现了错误处理?
-
- 代码是否正确缩进并遵循标准格式指南?
-
- 注释是否提供上下文和理由,而不仅仅是描述代码做了什么?
-
- 函数和类是否设计为具有明确、单一的责任?
10.10. 代码是否以增强可读性的方式进行格式化?
- 函数和类是否设计为具有明确、单一的责任?
图8展示了由Llama-3.3-70B-Instruct分配的质量评分分布。
D 基于LLM的代码重写
如第3.3节所述,本节介绍了用于基于LLM重写的提示,特别是用于Style-Guided Code Rewriting(SGCR)和Self-Contained Optimization Rewriting(SCOR)。每个提示都提供给Llama-3.3-70B-Instruct以执行数据重写。
D. 1 Style-Guided Code Rewriting(SGCR)
用于SGCR的提示如下所示。通过此重写过程创建的数据集可在https://huggingface.co/datasets/tokyotech-1lm/swallow-code获取,通过此数据集训练的模型检查点可在https://huggingface.co/ collections/tokyotech-1lm/swallowcode-6811c84ff647568547d4e443获取。
12
{ }^{12}
12 https://google.github.io/styleguide/pyguide.html
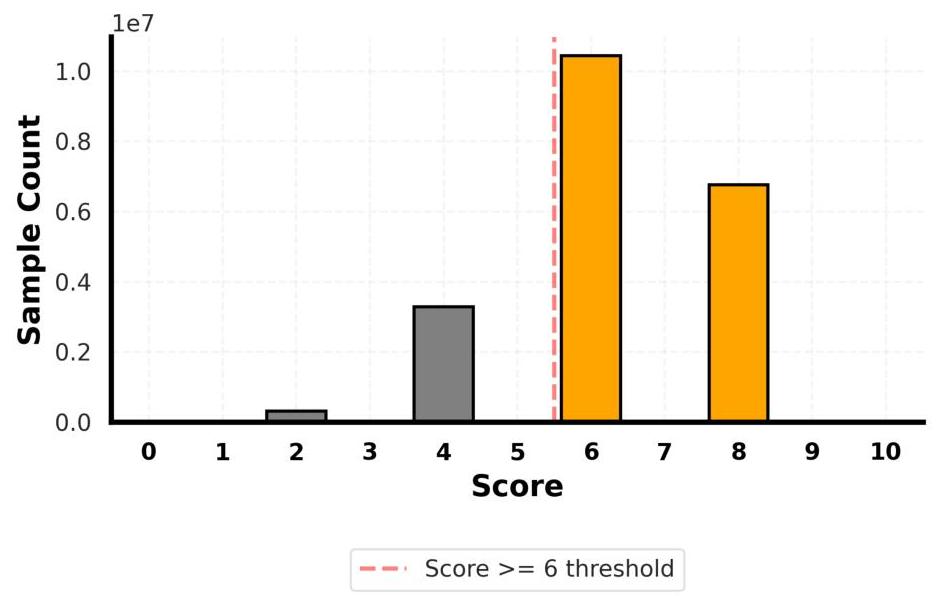
图8:Llama-3.3-70B-Instruct为Python代码语料库分配的质量评分分布。虚线表示6分的过滤阈值。值得注意的是,只有偶数评分出现,这是Llama-3.3-70B-Instruct解释评分提示的一个新兴特性。
用于SGCR的提示
您是一位聪明的软件工程师。请根据以下标准对以下代码进行1到10的评分:
- 变量名是否描述性强且符合命名约定?
-
- 注释和文档字符串是否适当编写以解释代码的目的和功能?
-
- 是否在适用的情况下有效使用了类型注解?
-
- 函数是否模块化良好,具有明确的责任划分和清晰的关注点分离?
-
- 是否有意管理变量的生命周期,避免频繁重新赋值或过长的作用域?
-
- 在必要时是否正确实现了错误处理?
-
- 代码是否正确缩进并遵循标准格式指南?
-
- 注释是否提供上下文和理由,而不仅仅是描述代码做了什么?
-
- 函数和类是否设计为具有明确、单一的责任?
10.10. 代码是否以增强可读性的方式进行格式化?
- 函数和类是否设计为具有明确、单一的责任?
并根据评估标准提供改进建议。您还可以提供一个改进版本的代码,如下所示:
### 评估: 7
### 建议: 根据评估标准提供具体、可行的改进建议。
### 改进后的代码: 提供一个结合建议改进的修订版代码。
‘’'python
def improved_function(arg1: int, arg2: str) -> str:
# 您的改进代码在此处
pass
’ ’ ’
D. 2 Self-Contained Optimization Rewriting (SCOR).
用于SCOR的提示如下所示。通过此重写过程创建的数据集可在https://huggingface.co/datasets/tokyotech-11m/swallow-code获取,通过此数据集训练的模型检查点可在https://huggingface.co/ collections/tokyotech-11m/swallowcode-6811c84ff647568547d4e443获取。
用于SCOR的提示
您是一位聪明的软件工程师。请根据以下最佳实践和Pythonic方式将给定的代码转换为自包含且结构良好的代码。
- 使用有意义的变量和函数名。
-
- 为函数编写清晰简洁的文档字符串。
-
- 在函数签名中使用类型提示。
-
- 为代码块编写清晰简洁的注释。
-
- 确保代码是自包含的,不依赖外部变量。
-
- 确保代码结构良好且易于阅读。
-
- 确保代码无错误且能正确运行。
-
- 确保代码经过优化且没有冗余操作。
-
- 确保算法和数据结构高效且简洁。
如果给定代码不是自包含的或过于简单,请将其更改为更有教育意义和实用性的代码。
- 确保算法和数据结构高效且简洁。
E 数学LLM重写
如第4.2节所述,本节介绍了在构建SwallowMath过程中使用的LLM重写提示。该提示包括五个部分:(1) 删除剩余的网页标题、页脚和隐私声明;(2) 删除多余的元数据,如问题和答案的时间戳;(3) 当问题或答案不完整时补充缺失的上下文;(4) 将解释重写为简洁但信息密集的形式;(5) 提供清晰的分步解决方案。步骤(1)-(2)与我们针对代码的语法错误和linter过滤平行,而步骤(3)-(5)对应于SwallowCode中使用的自包含性和样式重写。
用于数学重写的提示
您是一位智能的数学导师。以下是带有某些不必要的部分的数学问题和答案。请删除不需要的部分。例如,提交问题的日期、答案日期、隐私政策、页脚、页眉等应被删除。但是,请保留主要的问题和答案。
如果问题或答案缺乏一些信息或不够详尽,请使它们更加信息丰富且易于理解。如有必要,请添加更多关于分步计算过程的细节。
F 计算成本
本节量化了本研究中进行的LLM评分、LLM重写和消融实验所需的计算成本,以H100 GPU小时为单位进行测量。这些测量基于实证数据。通过分析计算成本,我们旨在阐明每种方法的数据清理管道的资源需求与下游任务性能提升之间的关系。此外,通过提供重现我们结果所需的计算资源估计,我们希望促进未来的研究。
F. 1 LLM评分的计算成本
数据合成过程使用了vLLM 0.7.2和PyTorch 2.5.1。数据集以全局批次大小为2048和张量并行度为4进行合成。数据生成使用每项作业四个H100(94 GB)GPU完成。输入处理速度约为2000标记/秒,输出生成速度约为3000标记/秒,平均输入数据集长度为836标记,平均输出数据集长度为1271标记,总样本数量为20,826,548。我们估计,在第3.2.3节描述的实验中创建数据集消耗了总计 4 , 869 H 100 G P U 4,869 \mathrm{H} 100 \mathrm{GPU} 4,869H100GPU小时。此估计排除了vLLM初始化和safetensor加载。
F. 2 LLM重写的计算成本
LLM重写的合成过程也使用了vLLM 0.7.2和PyTorch 2.5.1,全局批次大小为2048,张量并行度为4。数据生成使用每项作业四个H100(94GB)GPU完成。输入处理速度约为2000标记/秒,输出生成速度约为3000标记/秒。平均输入数据集长度为836标记,平均输出数据集长度为1819标记,总样本数量为20,826,548。我们估计,在第3.3.1节描述的实验中创建数据集消耗了总计 5 , 925 H 100 G P U 5,925 \mathrm{H} 100 \mathrm{GPU} 5,925H100GPU小时。此估计排除了vLLM初始化和safetensor加载。
F. 3 持续预训练数据消融实验的计算成本
第3.1节和第4.1节描述的消融实验使用64个H100(94GB)GPU进行了24.7小时的实验。因此,每次实验消耗了 1 , 580 H 100 G P U 1,580 \mathrm{H} 100 \mathrm{GPU} 1,580H100GPU小时。总共进行了15次实验(13次代码消融实验和两次数学消融实验),总计算成本达到了 23 , 700 H 100 G P U 23,700 \mathrm{H} 100 \mathrm{GPU} 23,700H100GPU小时。这些实验实现了每GPU 530 T F L O P / s / G P U 530 \mathrm{TFLOP} / \mathrm{s} / \mathrm{GPU} 530TFLOP/s/GPU的训练吞吐量和590,000标记/秒,这源于Megatron-LM论文[32]中提出的FLOP/s公式。这相当于H100峰值BF16 Tensor Core性能的大约 53.5 % 53.5 \% 53.5%。
G MBPP
如第3.3.1节所述,MBPP数据集 13 { }^{13} 13 包含违反标准Python风格指南的命名惯例的Python函数。例如,以下代码片段使用camelCase而不是推荐的snake_case:
def is_Power_Of_Two(x):
return x and (not(x & (x - 1)))
def differ_At_One_Bit_Pos(a, b):
return is_Power_Of_Two(a ^ b)
如第3.3.1节所述,Style-Guided Code Rewriting(SGCR)重写代码以符合Python的命名惯例
14
{ }^{14}
14,特别强制执行函数名的snake_case。因此,当要求实现使用非标准命名(例如camelCase)的函数时,基于SGCR处理的数据训练的LLM可能会将函数名重写为符合snake_case的形式。这导致在MBPP评估期间出现名称不匹配的情况,调用原始非标准名称的函数会导致“未定义”错误。
图9说明了这一问题:与仅通过语法错误和基于linter的过滤处理的数据训练的模型相比,基于SGCR重写的数据训练的模型在MBPP@1和MBPP@10上的得分较低。这种性能下降源于上述名称不匹配问题,掩盖了模型的真实代码生成能力。基于这一发现,我们得出结论,MBPP不适合用于评估我们实验中的LLM代码生成能力,因为其评估框架惩罚了对标准Python命名惯例的遵守。因此,我们从本研究中使用的基准测试中排除了MBPP。
13
{ }^{13}
13 https://github.com/google-research/google-research/blob/master/mbpp/mbpp.jsonl
14
{ }^{14}
14 https://peps.python.org/pep-0008/#descriptive-naming-styles
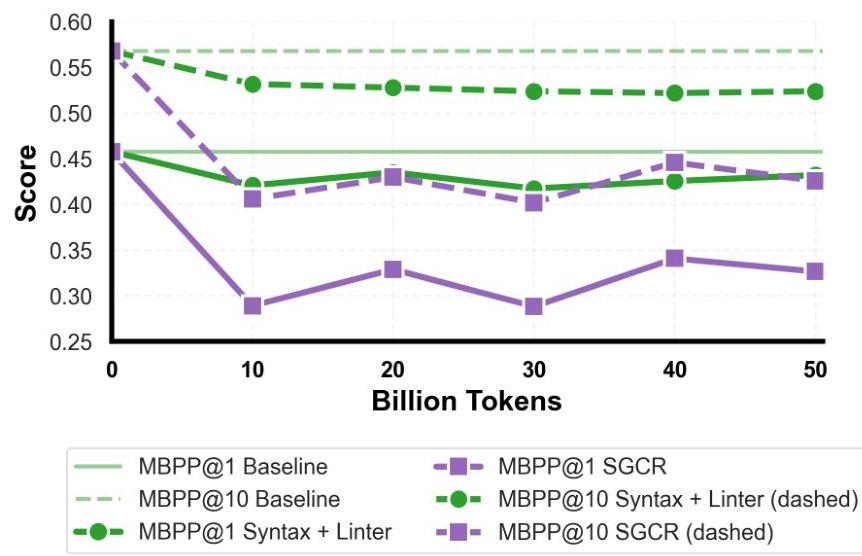
图9:在50B标记持续预训练消融研究中,比较通过linter过滤的数据和SGCR重写的数据在MBPP@1和MBPP@10上的得分。SGCR强制执行snake case命名惯例导致与MBPP非标准函数名不匹配,从而降低了得分。
H 评估
在本节中,我们展示了通过代码和数学数据集的消融实验评估的模型结果,涵盖十个包括代码和数学下游任务的基准测试。
H. 1 代码消融实验结果
如第3.1节所述,我们评估了从Llama-3.1-8B持续预训练的模型在十个英语下游任务上的表现。接下来,我们报告了13次代码消融实验的评估结果,它们的关系如图10所示。实验exp1、exp8、exp9和exp13作为基线,仅使用从现有开源代码语料库中提取的Python数据。其余实验是为了构建SwallowCode数据集而进行的。我们使用以下九个基准测试评估了性能:OpenBookQA [17]、TriviaQA [18]、HellaSwag [19]、SQuAD 2.0 [20]、XWinograd [21]、MMLU [22]、GSM8K [23]、BBH [24]、HumanEval [25] 和 HumanEval+ [26]。
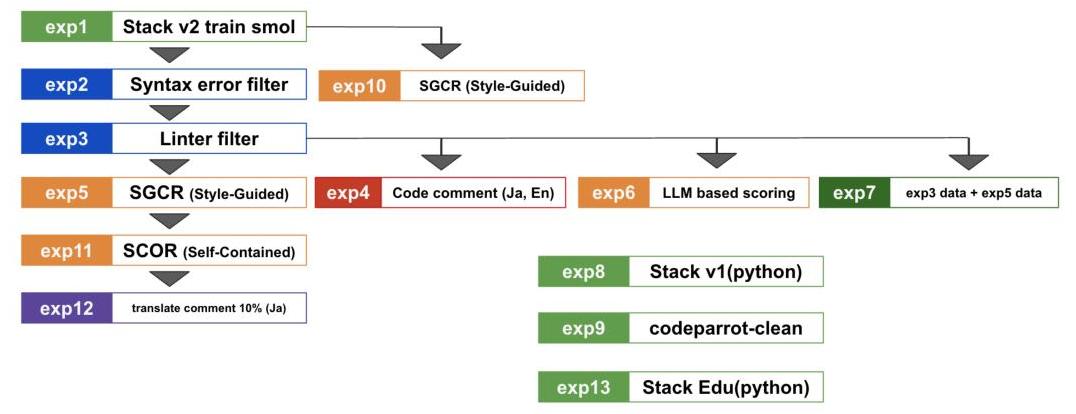
图10:代码消融实验之间的关系。
表6:the-stack-v2-train-smol-ids Python子集消融的基准测试性能。
| 实验1:the-stack-v2-train-smol-ids Python子集 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 标记数(B) | OpenBookQA | TriviaQA | HellaSwag | SQuAD2.0 | XWINO | MMLU | GSM8K | BBH | HumanEval | HumanEval+ |
| 10 | 0.3640 | 0.6659 | 0.5995 | 0.3354 | 0.9032 | 0.6294 | 0.4602 | 0.6019 | 0.3366 | 0.3366 |
| 20 | 0.3540 | 0.6567 | 0.6019 | 0.3360 | 0.9024 | 0.6238 | 0.4852 | 0.5898 | 0.3433 | 0.3433 |
| 30 | 0.3700 | 0.6588 | 0.6034 | 0.3377 | 0.9045 | 0.6263 | 0.5072 | 0.5939 | 0.3402 | 0.3421 |
| 40 | 0.3800 | 0.6618 | 0.6053 | 0.3380 | 0.9097 | 0.6341 | 0.5011 | 0.6016 | 0.3659 | 0.3701 |
| 50 | 0.3700 | 0.6679 | 0.6054 | 0.3350 | 0.9045 | 0.6340 | 0.5027 | 0.6091 | 0.3689 | 0.3720 |
表7:来自实验1的无语法错误数据消融的基准测试性能。
| 实验2:来自实验1的无语法错误数据 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 标记数(B) | OpenBookQA | TriviaQA | HellaSwag | SQuAD2.0 | XWINO | MMLU | GSM8K | BBH | HumanEval | HumanEval+ |
| 10 | 0.3560 | 0.6675 | 0.6015 | 0.3385 | 0.9062 | 0.6321 | 0.4784 | 0.5881 | 0.3604 | 0.3713 |
| 20 | 0.3520 | 0.6635 | 0.6026 | 0.3364 | 0.9049 | 0.6252 | 0.4784 | 0.5781 | 0.3591 | 0.3585 |
| 30 | 0.3560 | 0.6637 | 0.6012 | 0.3375 | 0.9080 | 0.6313 | 0.5019 | 0.5950 | 0.3701 | 0.3762 |
| 40 | 0.3580 | 0.6679 | 0.6046 | 0.3346 | 0.9062 | 0.6330 | 0.5019 | 0.5998 | 0.3720 | 0.3689 |
| 50 | 0.3660 | 0.6694 | 0.6055 | 0.3340 | 0.9084 | 0.6325 | 0.5155 | 0.6044 | 0.3787 | 0.3787 |
H. 2 数学消融实验结果
如第4.1节所述,我们评估了从Llama-3.1-8B持续预训练的模型在十个英语下游任务上的表现。下面,我们展示了两次代码消融实验的评估结果。具体来说,我们采用了以下十个评估基准:OpenBookQA [17]、TriviaQA [18]、HellaSwag [19]、SQuAD 2.0 [20]、XWinograd [21]、MMLU [22]、GSM8K [23]、BBH [24]、HumanEval [25] 和 MATH [22]。
表8:来自实验2的语法错误和Pylint过滤(得分
≥
7
\geq 7
≥7 )数据消融的基准测试性能。
| 实验3:来自实验2的语法错误和Pylint过滤(得分 ≥ 7 \geq 7 ≥7 )数据 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 标记数(B) | OpenBookQA | TriviaQA | HellaSwag | SQuAD2.0 | XWINO | MMLU | GSM8K | BBH | HumanEval | HumanEval+ |
| 10 | 0.3560 | 0.6628 | 0.6010 | 0.3340 | 0.9071 | 0.6235 | 0.4564 | 0.6007 | 0.3500 | 0.3488 |
| 20 | 0.3500 | 0.6613 | 0.6015 | 0.3361 | 0.9054 | 0.6237 | 0.4860 | 0.5838 | 0.3744 | 0.3787 |
| 30 | 0.3620 | 0.6596 | 0.6008 | 0.3359 | 0.9080 | 0.6307 | 0.4867 | 0.5921 | 0.3957 | 0.3878 |
| 40 | 0.3720 | 0.6650 | 0.6030 | 0.3352 | 0.9058 | 0.6326 | 0.4822 | 0.5990 | 0.3890 | 0.3915 |
| 50 | 0.3740 | 0.6677 | 0.6054 | 0.3291 | 0.9019 | 0.6327 | 0.4996 | 0.6145 | 0.3945 | 0.3902 |
表9:来自实验3的评论语言限制(英语和日语)数据消融的基准测试性能。
| 实验4:来自实验3的评论语言限制(英语和日语)数据 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 标记数(B) | OpenBookQA | TriviaQA | HellaSwag | SQuAD2.0 | XWINO | MMLU | GSM8K | BBH | HumanEval | HumanEval+ |
| 10 | 0.3640 | 0.6713 | 0.5988 | 0.3329 | 0.9054 | 0.6312 | 0.4708 | 0.5953 | 0.3549 | 0.3476 |
| 20 | 0.3520 | 0.6601 | 0.6011 | 0.3306 | 0.9067 | 0.6250 | 0.4898 | 0.5802 | 0.3689 | 0.3768 |
| 30 | 0.3680 | 0.6596 | 0.6047 | 0.3365 | 0.9118 | 0.6301 | 0.4989 | 0.5890 | 0.3768 | 0.3768 |
| 40 | 0.3660 | 0.6671 | 0.6049 | 0.3363 | 0.9071 | 0.6333 | 0.5155 | 0.6024 | 0.3756 | 0.3750 |
| 50 | 0.3700 | 0.6703 | 0.6061 | 0.3357 | 0.9101 | 0.6347 | 0.5133 | 0.6036 | 0.3841 | 0.3854 |
表10:来自实验3的SGCR重写数据消融的基准测试性能。
| 实验5:来自实验3的SGCR重写数据 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 标记数(B) | OpenBookQA | TriviaQA | HellaSwag | SQuAD2.0 | XWINO | MMLU | GSM8K | BBH | HumanEval | HumanEval+ |
| 10 | 0.3560 | 0.6689 | 0.5996 | 0.3295 | 0.9054 | 0.6256 | 0.4875 | 0.5991 | 0.4128 | 0.4110 |
| 20 | 0.3460 | 0.6610 | 0.6031 | 0.3352 | 0.9032 | 0.6262 | 0.4920 | 0.5801 | 0.4311 | 0.4616 |
| 30 | 0.3620 | 0.6637 | 0.6043 | 0.3378 | 0.9110 | 0.6269 | 0.5216 | 0.5984 | 0.4726 | 0.4579 |
| 40 | 0.3660 | 0.6645 | 0.6053 | 0.3372 | 0.9045 | 0.6328 | 0.4989 | 0.5945 | 0.4610 | 0.4390 |
| 50 | 0.3660 | 0.6667 | 0.6066 | 0.3325 | 0.9058 | 0.6352 | 0.5027 | 0.6065 | 0.4860 | 0.4811 |
表11:来自实验3的LLM评分(得分 ≥ 6 \geq 6 ≥6 )数据消融的基准测试性能。
| 实验6:来自实验3的LLM评分(得分 ≥ 6 \geq 6 ≥6 )数据 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 标记数(B) | OpenBookQA | TriviaQA | HellaSwag | SQuAD2.0 | XWINO | MMLU | GSM8K | BBH | HumanEval | HumanEval+ |
| 10 | 0.3640 | 0.6679 | 0.6002 | 0.3277 | 0.9041 | 0.6280 | 0.4701 | 0.5976 | 0.3640 | 0.3616 |
| 20 | 0.3540 | 0.6593 | 0.6010 | 0.3358 | 0.9045 | 0.6249 | 0.4822 | 0.5810 | 0.3659 | 0.3732 |
| 30 | 0.3660 | 0.6594 | 0.6021 | 0.3398 | 0.9071 | 0.6226 | 0.5140 | 0.5893 | 0.3994 | 0.3933 |
| 40 | 0.3700 | 0.6636 | 0.6021 | 0.3370 | 0.9080 | 0.6300 | 0.5027 | 0.6019 | 0.4018 | 0.4006 |
| 50 | 0.3640 | 0.6684 | 0.6046 | 0.3353 | 0.9084 | 0.6324 | 0.5011 | 0.6090 | 0.3951 | 0.3994 |
表12:来自实验3和实验5的混合(1:1)数据消融的基准测试性能。
| 实验7:来自实验3和实验5的混合(1:1)数据 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 标记数(B) | OpenBookQA | TriviaQA | HellaSwag | SQuAD2.0 | XWINO | MMLU | GSM8K | BBH | HumanEval | HumanEval+ |
| 10 | 0.3620 | 0.6660 | 0.5994 | 0.3293 | 0.9032 | 0.6242 | 0.4738 | 0.6156 | 0.3616 | 0.3598 |
| 20 | 0.3460 | 0.6585 | 0.6018 | 0.3297 | 0.9024 | 0.6293 | 0.4845 | 0.5809 | 0.3823 | 0.3890 |
| 30 | 0.3680 | 0.6611 | 0.6022 | 0.3384 | 0.9062 | 0.6241 | 0.5110 | 0.6045 | 0.3848 | 0.3951 |
| 40 | 0.3640 | 0.6666 | 0.6028 | 0.3327 | 0.9088 | 0.6323 | 0.5072 | 0.6056 | 0.4018 | 0.4018 |
| 50 | 0.3680 | 0.6695 | 0.6052 | 0.3320 | 0.9097 | 0.6300 | 0.5027 | 0.6051 | 0.4116 | 0.3988 |
表13:来自实验8的the-stack-v1 Python子集消融的基准测试性能。
| 实验8:来自实验1的the-stack-v1 Python子集 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 标记数(B) | OpenBookQA | TriviaQA | HellaSwag | SQuAD2.0 | XWINO | MMLU | GSM8K | BBH | HumanEval | HumanEval+ |
| 10 | 0.3660 | 0.6646 | 0.6033 | 0.3310 | 0.9028 | 0.6219 | 0.4784 | 0.5955 | 0.3244 | 0.3341 |
| 20 | 0.3500 | 0.6595 | 0.6018 | 0.3233 | 0.9037 | 0.6246 | 0.4701 | 0.5898 | 0.3220 | 0.3232 |
| 30 | 0.3640 | 0.6575 | 0.6014 | 0.3279 | 0.9071 | 0.6226 | 0.5057 | 0.5878 | 0.3244 | 0.3287 |
| 40 | 0.3680 | 0.6638 | 0.6029 | 0.3265 | 0.9067 | 0.6320 | 0.5004 | 0.5984 | 0.3445 | 0.3500 |
| 50 | 0.3620 | 0.6650 | 0.6053 | 0.3212 | 0.9084 | 0.6273 | 0.5080 | 0.5998 | 0.3561 | 0.3409 |
| 表14:来自实验1的codepartto-clean Python子集消融的基准测试性能。 |
| 实验9:来自实验1的codepartto-clean Python子集 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 标记数(B) | OpenBookQA | TriviaQA | HellaSwag | SQuAD2.0 | XWINO | MMLU | GSM8K | BBH | HumanEval | HumanEval+ |
| 10 | 0.3540 | 0.6651 | 0.6006 | 0.3221 | 0.9062 | 0.6295 | 0.4708 | 0.5875 | 0.3598 | 0.3561 |
| 20 | 0.3560 | 0.6556 | 0.6013 | 0.3358 | 0.9067 | 0.6289 | 0.4731 | 0.5870 | 0.3549 | 0.3463 |
| 30 | 0.3680 | 0.6570 | 0.6045 | 0.3390 | 0.9071 | 0.6290 | 0.4890 | 0.5976 | 0.3524 | 0.3561 |
| 40 | 0.3720 | 0.6613 | 0.6048 | 0.3352 | 0.9075 | 0.6300 | 0.4958 | 0.6108 | 0.3543 | 0.3549 |
| 50 | 0.3600 | 0.6638 | 0.6055 | 0.3321 | 0.9097 | 0.6273 | 0.5072 | 0.6139 | 0.3616 | 0.3634 |
表15:来自实验1的SGCR重写数据消融的基准测试性能。
| 实验10:来自实验1的SGCR重写数据 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 标记数(B) | OpenBookQA | TriviaQA | HellaSwag | SQuAD2.0 | XWINO | MMLU | GSM8K | BBH | HumanEval | HumanEval+ |
| 10 | 0.3640 | 0.6667 | 0.5996 | 0.3325 | 0.9032 | 0.6164 | 0.4845 | 0.5959 | 0.4457 | 0.4433 |
| 20 | 0.3460 | 0.6592 | 0.6032 | 0.3324 | 0.9067 | 0.6231 | 0.4890 | 0.5655 | 0.4579 | 0.4506 |
| 30 | 0.3660 | 0.6585 | 0.6029 | 0.3379 | 0.9101 | 0.6176 | 0.5064 | 0.5855 | 0.4494 | 0.4433 |
| 40 | 0.3600 | 0.6650 | 0.6024 | 0.3339 | 0.9067 | 0.6284 | 0.5148 | 0.5967 | 0.4622 | 0.4622 |
| 50 | 0.3600 | 0.6687 | 0.6047 | 0.3337 | 0.9084 | 0.6317 | 0.5057 | 0.6041 | 0.4646 | 0.4622 |
表16:来自实验5的SCOR重写数据消融的基准测试性能。
| 实验11:来自实验5的SCOR重写数据 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 标记数(B) | OpenBookQA | TriviaQA | HellaSwag | SQuAD2.0 | XWINO | MMLU | GSM8K | BBH | HumanEval | HumanEval+ |
| 10 | 0.3580 | 0.6680 | 0.6006 | 0.3317 | 0.9067 | 0.6237 | 0.4655 | 0.6108 | 0.4567 | 0.4665 |
| 20 | 0.3500 | 0.6564 | 0.6026 | 0.3349 | 0.9084 | 0.6241 | 0.4981 | 0.5718 | 0.5384 | 0.5323 |
| 30 | 0.3620 | 0.6640 | 0.6023 | 0.3385 | 0.9054 | 0.6253 | 0.5095 | 0.5928 | 0.5256 | 0.5317 |
| 40 | 0.3640 | 0.6705 | 0.6041 | 0.3401 | 0.9088 | 0.6317 | 0.5095 | 0.5982 | 0.5226 | 0.5244 |
| 50 | 0.3700 | 0.6685 | 0.6055 | 0.3359 | 0.9114 | 0.6322 | 0.5110 | 0.6062 | 0.5396 | 0.5445 |
表17:来自实验11和10%日译注释混合数据的消融基准测试性能。
| 实验12:90%实验11和10%日译注释混合数据 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 标记数(B) | OpenBookQA | TriviaQA | HellaSwag | SQuAD2.0 | XWINO | MMLU | GSM8K | BBH | HumanEval | HumanEval+ |
| 10 | 0.3640 | 0.6625 | 0.6020 | 0.3341 | 0.9054 | 0.6221 | 0.4738 | 0.5697 | 0.4799 | 0.4768 |
| 20 | 0.3500 | 0.6551 | 0.6021 | 0.3361 | 0.9058 | 0.6266 | 0.4943 | 0.5776 | 0.5165 | 0.5079 |
| 30 | 0.3640 | 0.6595 | 0.6034 | 0.3410 | 0.9080 | 0.6250 | 0.5011 | 0.6008 | 0.5110 | 0.5091 |
| 40 | 0.3640 | 0.6640 | 0.6022 | 0.3361 | 0.9054 | 0.6330 | 0.4898 | 0.6008 | 0.5299 | 0.5268 |
| 50 | 0.3600 | 0.6655 | 0.6057 | 0.3340 | 0.9080 | 0.6315 | 0.5072 | 0.6057 | 0.5329 | 0.5293 |
表18:来自Stack Edu Python子集消融的基准测试性能。
| 实验13:Stack Edu Python子集 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 标记数(B) | OpenBookQA | TriviaQA | HellaSwag | SQuAD2.0 | XWINO | MMLU | GSM8K | BBH | HumanEval | HumanEval+ |
| 10 | 0.3640 | 0.6696 | 0.5986 | 0.3358 | 0.9037 | 0.6246 | 0.4761 | 0.6004 | 0.3470 | 0.3433 |
| 20 | 0.3520 | 0.6632 | 0.6021 | 0.3364 | 0.9067 | 0.6233 | 0.4898 | 0.5942 | 0.3537 | 0.3518 |
| 30 | 0.3660 | 0.6600 | 0.6024 | 0.3439 | 0.9097 | 0.6251 | 0.4989 | 0.5916 | 0.3713 | 0.3640 |
| 40 | 0.3700 | 0.6650 | 0.6033 | 0.3402 | 0.9067 | 0.6325 | 0.4958 | 0.6084 | 0.3701 | 0.3720 |
| 50 | 0.3740 | 0.6665 | 0.6061 | 0.3368 | 0.9062 | 0.6350 | 0.5087 | 0.6173 | 0.3695 | 0.3671 |
表19:finemath-4+消融的基准测试性能。
| 实验1:finemath-4+ | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 标记数(B) | OpenBookQA | TriviaQA | HellaSwag | SQuAD2.0 | XWINO | MMLU | HumanEval | GSM8K | BBH | MATH |
| 10 | 0.3700 | 0.6626 | 0.5990 | 0.3350 | 0.8985 | 0.6243 | 0.3439 | 0.4685 | 0.6057 | 0.1760 |
| 20 | 0.3720 | 0.6536 | 0.5963 | 0.3510 | 0.9032 | 0.6261 | 0.3622 | 0.5011 | 0.5896 | 0.2080 |
| 30 | 0.3700 | 0.6574 | 0.5999 | 0.3506 | 0.8998 | 0.6253 | 0.3561 | 0.5019 | 0.5971 | 0.2260 |
| 40 | 0.3720 | 0.6577 | 0.6024 | 0.3499 | 0.9049 | 0.6312 | 0.3701 | 0.5231 | 0.6054 | 0.2260 |
| 50 | 0.3740 | 0.6608 | 0.6001 | 0.3550 | 0.9058 | 0.6329 | 0.3561 | 0.5292 | 0.6166 | 0.2400 |
表20:由Llama-3.3-70B-Instruct重写的finemath-4+消融的基准测试性能。
| 实验2:由Llama-3.3-70B-Instruct重写的finemath-4+ | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| 标记数(B) | OpenBookQA | TriviaQA | HellaSwag | SQuAD2.0 | XWINO | MMLU | HumanEval | GSM8K | BBH |
| 10 | 0.3720 | 0.6643 | 0.5970 | 0.3443 | 0.9015 | 0.6343 | 0.3439 | 0.5603 | 0.5535 |
| 20 | 0.3800 | 0.6580 | 0.5946 | 0.3428 | 0.8994 | 0.6293 | 0.3762 | 0.6156 | 0.5669 |
| 30 | 0.3660 | 0.6618 | 0.5964 | 0.3470 | 0.9011 | 0.6298 | 0.3530 | 0.6262 | 0.6383 |
| 40 | 0.3700 | 0.6610 | 0.5973 | 0.3535 | 0.9088 | 0.6358 | 0.3738 | 0.6422 | 0.6237 |
| 50 | 0.3800 | 0.6637 | 0.5972 | 0.3537 | 0.9045 | 0.6337 | 0.3683 | 0.6535 | 0.6414 |
参考论文:https://arxiv.org/pdf/2505.02881



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











