






蔡瑞初
a
,
a
{ }^{\mathrm{a}, \mathrm{a}}
a,a, 陈曦
a
{ }^{\mathrm{a}}
a, 乔杰
a
{ }^{\mathrm{a}}
a, 李子健
L
i
a
\mathrm{Li}^{\mathrm{a}}
Lia, 刘跃群
a
{ }^{\mathrm{a}}
a, 陈伟
a
{ }^{\mathrm{a}}
a, 张可丽
b
{ }^{\mathrm{b}}
b, 郑嘉乐
b
{ }^{\mathrm{b}}
b
a
{ }^{a}
a 广东工业大学计算机学院,广州,510006,中国
b
{ }^{\mathrm{b}}
b 华为诺亚方舟实验室,华为,深圳,518116,中国
摘要
在异常条件下进行决策是一个关键过程,涉及评估当前状态并确定以可接受的成本将系统恢复到正常状态的最佳行动。然而,在这种情况下,现有的决策框架高度依赖于强化学习或根本原因分析,导致它们经常忽视行动的成本或未能充分结合因果机制。通过放松现有的因果决策框架来解决必要原因,我们提出了一个基于反事实推理的最小成本因果决策(MiCCD)框架,以应对上述挑战。重点在于在存在大量混合异常数据的情况下使反事实推理过程可识别,以及在连续决策空间中找到最佳干预状态。具体来说,它基于因果图构建了一个代理模型,使用异常模式聚类标签作为监督信号。这使得能够在变量之间近似结构因果模型,并为可识别的反事实推理奠定基础。在近似因果结构的基础上,我们进一步建立了基于反事实估计的优化模型。然后采用序列二次规划(SLSQP)算法,在考虑成本的同时优化干预策略。实验评估表明,MiCCD在合成和真实世界数据集上的多个指标(包括F1分数、成本效率和排名质量(nDCG@k值))上优于传统方法,从而验证了其有效性和广泛适用性。
a
{ }^{\text {a }}
a 对应作者。
电子邮件地址:cai ruichu@gmail.com (Ruichu Cai)
# 1. 引言
决策是解决问题和实现目标的基本过程,涉及评估当前状态并在一组备选方案中选择最合适的行动,同时保持可接受的成本 Yuan 等人(2024);Shehadeh 等人(2024)。尽管决策在各种领域中已经证明了其有效性 Waqar(2024);Hu 和 Lin(2019);Fang 等人(2022);Schmitt(2023);Venkatesan 等人(2024);Saadatmand 等人(2024);Zheng 等人(2024b),但在处理异常时,其作用变得更加重要,及时和准确的决策可以修复系统故障、减少损失并提高运营效率。在工业和医疗保健等高风险行业中,尤其是在异常情况下做出的不良决策可能会导致严重、昂贵甚至不道德的后果。这些挑战突显了对能够处理异常的强大决策框架的迫切需求。
目前针对异常情况下的决策方法主要分为两类:强化学习(RL)和根本原因分析(RCA)。RL 方法主要通过在线 Mnih 等人(2015);Schulman 等人(2015, 2017)或离线 Wu 等人(2019);Kumar 等人(2020);Kostrikov 等人(2022)学习中的试错过程强调最优学习行动。然而,这种探索性策略通常涉及巨大的成本,并可能引发伦理问题。另一方面,RCA 方法旨在识别异常行为的根本原因,从而根据推断出的根本原因进行决策。基于相关性的 RCA 方法 Ribeiro 等人(2018);Idé 等人(2021);Casalicchio 等人(2019);Carletti 等人(2019);Pan 等人(2020);Hyun 等人(2025);Tamanampudi(2020);Du 等人(2017),由于缺乏因果依据,可能会识别出虚假的依赖关系,而因果 RCA Rehak 等人(2023);Assaad 等人(2023);Budhathoki 等人(2022);Nguyen 等人(2024)通常仅根据根本原因推荐行动,而不考虑当前状态的可行性和成本。一个关键挑战仍然存在:不仅仅是诊断异常,而是识别有效的、可行的和成本高效的干预措施。一个典型的例子如图 1(b) 所示。
为了解决上述差距,我们提出了最小成本因果决策(MiCCD),这是一种新颖的决策框架,将因果建模与成本感知的反事实推理相结合,以指导在异常情况下的决策。具体来说,MiCCD 将决策视为干预,并自适应地识别成本有效的反事实干预策略,从而消除持续试错过程的需要。
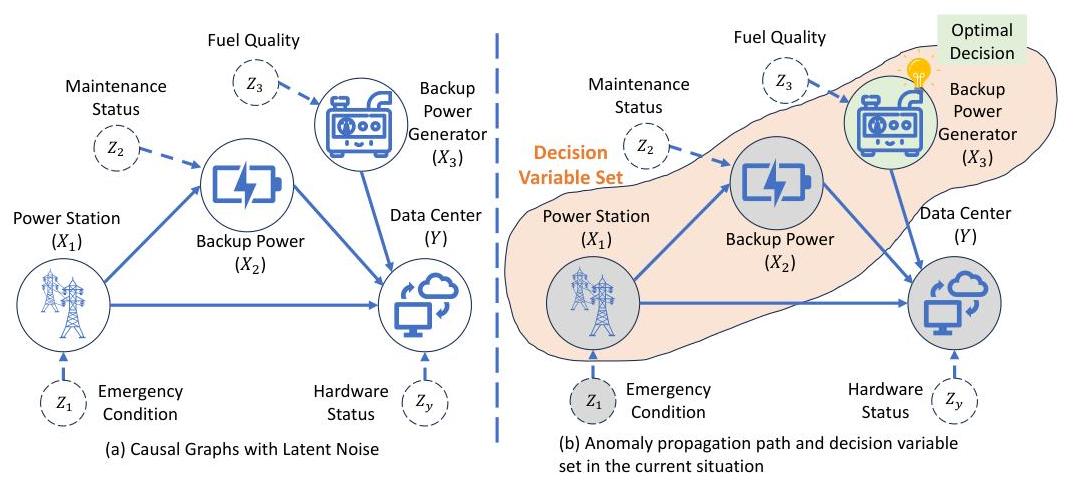
图 1: 一个简单的决策示例。如果数据中心
(
Y
)
(Y)
(Y) 因地震
(
Z
1
)
\left(Z_{1}\right)
(Z1) 断电并依赖备用电源
(
X
2
)
\left(X_{2}\right)
(X2),RCA 可能会建议修理电站(根本原因
(
X
1
)
\left(X_{1}\right)
(X1)),但这是不可行的,因为备用电源
(
X
2
)
\left(X_{2}\right)
(X2) 在修理完成之前就会耗尽。一种可行且成本更低的解决方案——例如增加备用发电机的燃料供应(
X
3
X_{3}
X3 )——需要超越根本原因识别,结合成本和反事实评估。这里,实心节点表示观察变量,虚线节点表示潜在噪声。灰色填充的节点代表异常,绿色代表发生异常时的最佳决策。
鉴于实际应用中反事实推理的必要性以及可能存在较大且连续的动作空间,MiCCD 被设计用于解决以下两个关键挑战:1) 反事实识别:如何在给定异常状态和特定动作的情况下识别反事实结果?2) 成本感知优化:如何在大且连续的动作空间内找到最优的最低成本决策?
对于第一个挑战,MiCCD 依赖于准确建模因果机制,包括外生噪声项的分布(例如, X 1 X_{1} X1 和 Z 2 Z_{2} Z2 对 X 2 X_{2} X2 的影响)。这些噪声项的可识别性至关重要;否则,反事实预测将变得模糊,降低决策可靠性。MiCCD 通过分离噪声模式并对异常状态进行聚类,重建其不同的分布影响,解决了这一问题。
对于第二个挑战,MiCCD 平衡了必要性(干预是否解决异常)和经济性(其成本)。使用代理模型来
近似因果效应,它迭代估计干预的影响,并使用序列最小二乘规划(SLSQP)在成本最小化目标下优化干预选择和强度。
本文的主要贡献总结如下:
- 提出了一个新的成本感知决策框架 MiCCD,将反事实推理与干预优化相结合,以解决异常处理问题。
-
- 开发了一个代理模型以近似潜在因果关系,从而使干预结果的反事实估计成为可能。通过定义必要概率和成本感知公式量化干预的必要性和可行性。
-
- 通过在合成和真实世界数据集上的广泛实验验证了 MiCCD,与现有方法相比表现出优越的性能和成本效率。
2. 相关工作
RL 方法。强化学习(RL)涵盖了一系列方法,每种方法都旨在从在线或离线试错过程中学习,以解决决策任务。在传统的 RL 中,决策策略是通过与环境的直接在线交互进行优化(称为在线学习),其中智能体通过主动探索和利用环境实时学习。典型的方法包括深度 Q 网络(DQN)Mnih 等人(2015),信任区域策略优化(TRPO)Schulman 等人(2015),近端策略优化(PPO)Schulman 等人(2017),以及软演员批评(SAC)Haarnoja 等人(2018)。相比之下,离线 RL 侧重于从静态试错数据集中学习策略。代表性的离线 RL 方法包括行为正则化演员评论家(BRAC)Wu 等人(2019),保守 Q 学习(CQL)Kumar 等人(2020),隐式 Q 学习(IQL)Kostrikov 等人(2022),以及批量约束 Q 学习(BCQ)。然而,基于 RL 的模型仍然依赖于从试错过程中显式或隐式派生的数据以实现有效的决策。
RCA 方法。根本原因分析(RCA)方法可以分为基于相关性和因果方法两类。基于相关性的方法包括 LIME Ribeiro 等人(2018),LC Idé 等人(2021),和 NaiveRCA Strumbelj 和 Kononenko(2010),
这些方法评估特征的重要性;CAFCA Hyun 等人(2025),它基于分类分组分析数据;以及 DeepLog Du 等人(2017),它建立输入特征和目标变量之间的统计关联。但由于缺乏因果推理,这些方法往往会产生虚假的依赖关系。例如,高温可能导致机器损坏并增加空气湿度,但基于相关性的方法可能会错误地将空气湿度识别为根本原因。基于因果的方法通过引入因果结构解决了这些限制。例如,为了定位根本原因,JRCS Rehak 等人(2023)识别因果图中的异常,而 CausalRCA Budhathoki 等人(2022)和 BIGEN Nguyen 等人(2024)使用结构化的因果模型和贝叶斯推理来识别根本原因。EEL Strobl 和 Lasko(2023)使用结构方程模型和 Shapley 值进行样本特定的 RCA。然而,这些方法仅专注于识别根本原因,而不考虑干预的成本或后果,限制了它们在决策场景中的适用性。
基于因果的决策方法。最近,Qin 等人(2024)提出了一种排练学习框架,利用概率图形模型和结构方程减轻意外未来(AUF)。Du 等人(2024)扩展了该框架,通过 AUF-MICNS 将决策成本纳入考虑并适应非平稳环境。然而,这些方法在群体层面而非个体层面决策上运行。
3. 问题表述
因果决策基于特定的因果结构,通常用有向无环图(DAG)Pearl(2009)表示。考虑随机变量 X = { X 1 , … , X d } \mathbf{X}=\left\{X_{1}, \ldots, X_{d}\right\} X={X1,…,Xd} 具有索引集 V : = { 1 , … , d } V:=\{1, \ldots, d\} V:={1,…,d}。一个图 G = ( V , ε ) \mathcal{G}=(V, \varepsilon) G=(V,ε) 包含节点 V V V 和边 ε ⊆ V 2 \varepsilon \subseteq V^{2} ε⊆V2,其中 ( i , j ) ∈ ε (i, j) \in \varepsilon (i,j)∈ε 对于任何 i , j ∈ V i, j \in V i,j∈V。如果 e i j ∈ ε e_{i j} \in \varepsilon eij∈ε 且 e j i ∉ ε e_{j i} \notin \varepsilon eji∈/ε,则节点 i i i 称为 j j j 的父节点。 j j j 的父节点集记为 P A j G \mathbf{P A}_{j}^{\mathcal{G}} PAjG。因果关系的图表示形式化讨论如下:
定义 1(结构因果模型)。结构因果模型(SCM)
C
:
=
\mathfrak{C}:=
C:=
(
S
,
Z
)
(\mathbf{S}, \mathbf{Z})
(S,Z) 由一组函数集合
S
\mathbf{S}
S 组成,
X
i
:
=
f
i
(
P
A
i
G
,
Z
i
)
,
i
∈
[
d
]
X_{i}:=f_{i}\left(\mathbf{P A}_{i}^{\mathcal{G}}, Z_{i}\right), i \in[d]
Xi:=fi(PAiG,Zi),i∈[d],其中
P
A
i
⊂
{
X
1
,
…
,
X
d
}
\
{
X
i
}
\mathbf{P A}_{i} \subset\left\{X_{1}, \ldots, X_{d}\right\} \backslash\left\{X_{i}\right\}
PAi⊂{X1,…,Xd}\{Xi} 是
X
i
X_{i}
Xi 的父节点,以及联合分布
Z
=
{
Z
1
,
…
,
Z
d
}
\mathbf{Z}=\left\{Z_{1}, \ldots, Z_{d}\right\}
Z={Z1,…,Zd},要求噪声变量独立。
令
{
x
(
i
)
}
i
=
1
n
\left\{\mathbf{x}^{(i)}\right\}_{i=1}^{n}
{x(i)}i=1n 和
{
y
(
i
)
}
i
=
1
n
\left\{y^{(i)}\right\}_{i=1}^{n}
{y(i)}i=1n 表示样本集,其中
x
=
[
x
1
,
…
,
x
d
]
∈
\mathbf{x}=\left[x_{1}, \ldots, x_{d}\right] \in
x=[x1,…,xd]∈
R
d
\mathbb{R}^{d}
Rd 和
y
∈
R
y \in \mathbb{R}
y∈R,对应于 SCM 的附加目标。同样,
z
=
[
z
1
,
…
,
z
d
,
z
y
]
∈
R
d
+
1
\mathbf{z}=\left[z_{1}, \ldots, z_{d}, z_{y}\right] \in \mathbb{R}^{d+1}
z=[z1,…,zd,zy]∈Rd+1 表示
Z
\mathbf{Z}
Z 的样本。
本研究的目标是开发和形式化一个决策框架,旨在解决因果系统中的现有挑战。在这样的系统中,预期行为的偏差可能是由于异常(例如传感器故障、对抗攻击)或有意修改(例如政策调整、系统升级)引起的,每种情况都会引入不同的噪声模式,显著改变反事实结果的分布。不失一般性,该问题被建模为一个异常场景,其中异常是由噪声分布的扰动引起的,从 Z i ∼ N ( μ i , σ i 2 ) Z_{i} \sim \mathcal{N}\left(\mu_{i}, \sigma_{i}^{2}\right) Zi∼N(μi,σi2) 到 Z i ′ ∼ N ( μ i ′ , σ i ′ 2 ) Z_{i}^{\prime} \sim \mathcal{N}\left(\mu_{i}^{\prime}, \sigma_{i}^{\prime 2}\right) Zi′∼N(μi′,σi′2)。如图 1(a) 和 (b) 所示,如果异常是由于 Z 1 Z_{1} Z1 分布的变化引起的,则 Z 1 Z_{1} Z1 是异常噪声分布的一部分。相反,如果异常是由其他变量中的噪声引起的,则 Z 1 Z_{1} Z1 的分布不同。随后,这通过因果图传播,导致系统结果发生变化。
决策被框架化为一个反事实问题,其中目标是识别一个变量或一组变量,当对其进行干预时,可以在最小干预成本下缓解目标变量 Y Y Y 的异常。通过根据阈值 t t t 对目标变量进行分类来实现异常解决。具体来说,如果检测到异常 ( Y > t ) (Y>t) (Y>t),则将目标变量赋值为 1;否则,赋值为 0 表示异常已解决。
为了严格评估干预对目标的影响,引入了必要性概率(PN)度量 Pearl(2009)。与传统方法不同,PN 在反事实框架内量化干预的因果必要性,并正式定义如下:
P N ( X → Y ) = P ( Y d o ( X = x ∗ ) = 0 ∣ X = x , Y = 1 ) P N(X \rightarrow Y)=P\left(Y_{d o\left(\mathbf{X}=\mathbf{x}^{*}\right)}=0 \mid \mathbf{X}=\mathbf{x}, Y=1\right) PN(X→Y)=P(Ydo(X=x∗)=0∣X=x,Y=1)
这里, Y d o ( X = x ∗ ) Y_{d o\left(\mathbf{X}=\mathbf{x}^{*}\right)} Ydo(X=x∗) 表示反事实结果。直观上,PN 寻求回答以下问题:如果干预将原始输入 x \mathbf{x} x 改变为 x ∗ \mathbf{x}^{*} x∗,结果 Y Y Y 为零(即已解决)的概率是多少?这种表述为决策者提供了一个原则性的框架,以评估干预是否真正有必要对结果产生变化。
因此,目标重新表述为在 PN 超过预定义阈值
ι
\iota
ι 的前提下最小化干预成本:
x
s
=
arg
min
x
∗
∈
R
n
C
(
d
o
(
X
=
x
∗
)
,
x
)
s.t.
P
(
Y
d
o
(
X
=
x
∗
)
=
0
∣
X
=
x
,
Y
=
1
)
≥
ι
\begin{aligned} \mathbf{x}^{\mathbf{s}} & =\arg \min _{\mathbf{x}^{*} \in \mathbb{R}^{n}} C\left(d o\left(\mathbf{X}=\mathbf{x}^{*}\right), \mathbf{x}\right) \\ & \text { s.t. } P\left(Y_{d o\left(\mathbf{X}=\mathbf{x}^{*}\right)}=0 \mid \mathbf{X}=\mathbf{x}, Y=1\right) \geq \iota \end{aligned}
xs=argx∗∈RnminC(do(X=x∗),x) s.t. P(Ydo(X=x∗)=0∣X=x,Y=1)≥ι
这里, x s = [ x 1 s , … , x d s ] \mathbf{x}^{s}=\left[x_{1}^{s}, \ldots, x_{d}^{s}\right] xs=[x1s,…,xds] 表示最优干预向量,它以最小成本将 Y Y Y 从 1 改变为 0。成本函数 C C C 通常取决于诸如 x ∗ \mathbf{x}^{*} x∗ 和 x \mathbf{x} x 之间的步长、与单个变量相关的干预成本以及受影响变量的数量等因素。 C C C 的具体形式可以根据应用上下文而有所不同。
4. 最小成本因果决策框架
在本节中,介绍了最小成本因果决策(MiCCD)框架,该框架旨在解决两个关键挑战:(1)因果结构下反事实的可识别性,以及(2)成本感知干预的优化以确定最小成本决策。
4.1. 干预下的反事实推理的可识别性
反事实推理的一个主要挑战是在不进行实际干预的情况下难以恢复噪声变量 Z \mathbf{Z} Z。此挑战通过首先形式化干预过程、识别与估计后干预分布相关的主困难,并随后提出基于理论保证的解决方案来解决。
为了识别有效的干预措施,我们首先选择干预向量 x ∗ \mathbf{x}^{*} x∗。并非所有干预措施在 x ∗ \mathbf{x}^{*} x∗ 中都能有效影响目标变量 Y Y Y。以下规则用于筛选无效干预措施:
规则 1. 对于所有元素在 X ∗ = X \mathbf{X}^{*}=\mathbf{X} X∗=X 中,需要以下筛选过程:
-
S1. 删除满足 x i ∗ = x i x_{i}^{*}=x_{i} xi∗=xi 的所有元素:
X R ∗ ← X ∗ \ { X i ∗ ∣ x i ∗ = x i , ∃ i ∈ { 1 , … , i , … , d } } \mathbf{X}_{\mathbf{R}}^{*} \leftarrow \mathbf{X}^{*} \backslash\left\{X_{i}^{*} \mid x_{i}^{*}=x_{i}, \exists i \in\{1, \ldots, i, \ldots, d\}\right\} XR∗←X∗\{Xi∗∣xi∗=xi,∃i∈{1,…,i,…,d}} -
S2. 对于每个剩余元素 X i ∗ ∈ X R ∗ X_{i}^{*} \in \mathbf{X}_{\mathbf{R}}^{*} Xi∗∈XR∗,识别每条路径 E ( X i ∗ , Y ) E\left(X_{i}^{*}, Y\right) E(Xi∗,Y) 从 X i ∗ X_{i}^{*} Xi∗ 到 Y Y Y。如果对于每条路径 e ∈ E ( X i ∗ , Y ) e \in E\left(X_{i}^{*}, Y\right) e∈E(Xi∗,Y),路径中的所有中间元素都属于剩余元素集 X R ∗ \mathbf{X}_{\mathbf{R}}^{*} XR∗,则从 X R ∗ \mathbf{X}_{\mathbf{R}}^{*} XR∗ 中删除 X i ∗ X_{i}^{*} Xi∗。按照因果顺序重复上述步骤,直到无法再进行删除:
X R ∗ ← X R ∗ \ { X i ∗ ∣ ∀ e ∈ E ( X i ∗ , Y ) , ∀ m ∈ e , m ∈ X R ∗ } \mathbf{X}_{\mathbf{R}}^{*} \leftarrow \mathbf{X}_{\mathbf{R}}^{*} \backslash\left\{X_{i}^{*} \mid \forall e \in E\left(X_{i}^{*}, Y\right), \forall m \in e, m \in \mathbf{X}_{\mathbf{R}}^{*}\right\} XR∗←XR∗\{Xi∗∣∀e∈E(Xi∗,Y),∀m∈e,m∈XR∗}
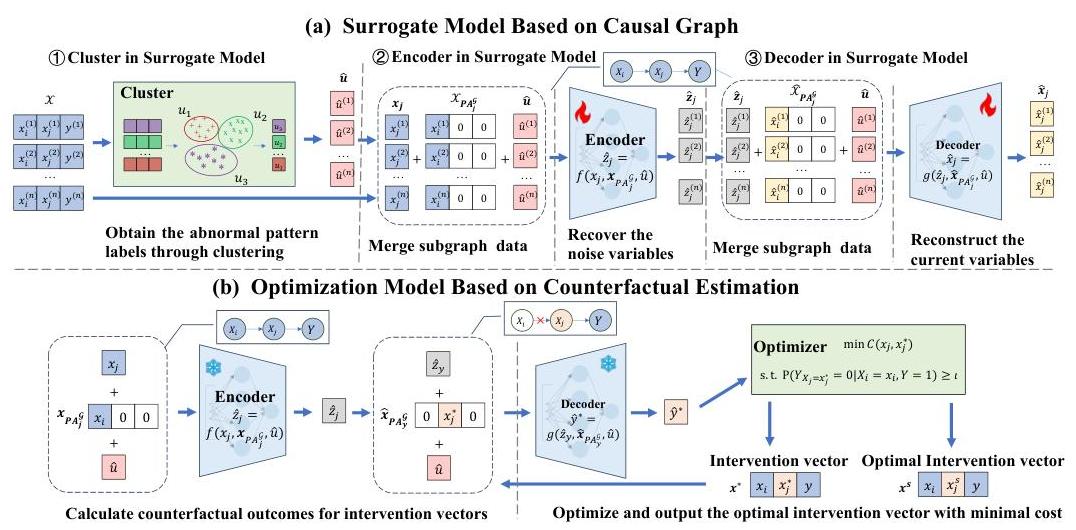
图 2: MiCCD 框架包含两个组件:(a) 代理模型通过恢复噪声变量和预测结果来近似 SCM,以启用反事实推理,以及 (b) 优化方法基于反事实推理识别最小成本干预。在代理模型中,首先通过聚类获得异常模式标签,并将其合并到子图样本中——包括当前变量及其父变量——以恢复相应的噪声变量。然后将这些噪声变量连同父变量一起输入解码器,以重构当前变量或反事实变量(如果父变量受到干预)。在优化阶段,编码器和解码器用于估算由优化器生成的候选干预向量的反事实结果。通过迭代细化,框架确定成本最小化的干预。
最终的
X
R
∗
\mathbf{X}_{\mathbf{R}}^{*}
XR∗ 对应的动作
x
R
∗
\mathbf{x}_{\mathbf{R}}^{*}
xR∗ 被认为是有效的。
这个筛选过程确保只有能够影响目标的干预才会被考虑,从而减少了搜索空间。例如,在
X
2
←
X
1
→
Y
,
X
2
X_{2} \leftarrow X_{1} \rightarrow Y, X_{2}
X2←X1→Y,X2 不影响
Y
Y
Y 的情况下会被筛选掉。
为了估计干预
X
R
∗
\mathbf{X}_{R}^{*}
XR∗ 后目标节点
Y
Y
Y 的分布,可以根据贝叶斯推导得出以下表达式。这里,
D
E
R
G
\mathrm{DE}_{R}^{\mathcal{G}}
DERG
表示
G
\mathcal{G}
G 中节点集
R
R
R 的后代集:
p ( y ∣ d o ( X R ∗ = x R ∗ ) ) = ∫ x D E R G ∫ z D E R G d o ( X R ∗ = x R ∗ ) × ∏ i ∈ D E R G p ( x i ∣ x P A i G , z i ) × ∏ i ∈ D E R G p ( z i ) d x D E R G d z D E R G \begin{aligned} & p\left(y \mid d o\left(\mathbf{X}_{\mathbf{R}}^{*}=\mathbf{x}_{\mathbf{R}}^{*}\right)\right)=\int_{\mathbf{x}_{\mathbf{D E}_{R}^{G}}} \int_{\mathbf{z}_{\mathbf{D E}_{R}^{G}}} d o\left(\mathbf{X}_{\mathbf{R}}^{*}=\mathbf{x}_{\mathbf{R}}^{*}\right) \\ & \times \prod_{i \in \mathbf{D E}_{R}^{G}} p\left(x_{i} \mid \mathbf{x}_{\mathbf{P A}_{i}^{G}}, z_{i}\right) \times \prod_{i \in \mathbf{D E}_{R}^{G}} p\left(z_{i}\right) d \mathbf{x}_{\mathbf{D E}_{R}^{G}} d \mathbf{z}_{\mathbf{D E}_{R}^{G}} \end{aligned} p(y∣do(XR∗=xR∗))=∫xDERG∫zDERGdo(XR∗=xR∗)×i∈DERG∏p(xi∣xPAiG,zi)×i∈DERG∏p(zi)dxDERGdzDERG
从方程 5 可以看出,估计后干预分布需要识别噪声分布 Z \mathbf{Z} Z 和后干预的 D E R G \mathbf{D E}_{R}^{G} DERG 分布。这带来了几个挑战:(1) 现实条件很少允许试错方法,需要正确且可以直接推导的代理模型;(2) 在没有强假设的情况下,混合异常数据中的 Z \mathbf{Z} Z 分布本质上难以识别 Locatello 等人(2019);(3) 识别 Z \mathbf{Z} Z 的分布可能需要从数据集聚类中结合辅助信息,尽管异常模式标签通常不可用。
为了解决上述挑战,通过聚类生成的异常标签区分不同的噪声分布。这些标签作为变分自动编码器的监督信号,引导编码器恢复噪声变量(引理 1)。例如,在电力供应背景下,聚类可以区分“地震造成的电站损坏”和“备用电源过载”的噪声分布,确保代理模型中噪声恢复的可识别性。
4.1.1. 聚类的可识别性
聚类的可识别性在以下充分条件下成立:
引理 1(基于弱可分离变量的可识别性的充分条件。Tahmasebi 等人(2018))。任何具有潜在变量 θ = \theta= θ= ( F 1 : K ; w ) ∈ Θ K , L , M \left(F_{1: K} ; \mathbf{w}\right) \in \Theta_{K, L, M} (F1:K;w)∈ΘK,L,M 的混合模型,只要 L w ( F 1 : K ; w ) ≥ 2 K \mathcal{L}_{w}\left(F_{1: K} ; \mathbf{w}\right) \geq 2 K Lw(F1:K;w)≥2K,就是可识别的。
含义。对于根据定义 1 生成的
(
d
+
1
)
(d+1)
(d+1) 维数据,假设每个样本至少包含一个异常变量,除了目标变量外,每个变量至少表现出一种异常。在正常情况下,每个变量
X
i
X_{i}
Xi 遵循高斯分布
N
(
μ
i
,
σ
i
2
)
\mathcal{N}\left(\mu_{i}, \sigma_{i}^{2}\right)
N(μi,σi2),其中
μ
i
\mu_{i}
μi 和
σ
i
2
\sigma_{i}^{2}
σi2 分别表示变量
X
i
X_{i}
Xi 的均值和方差。在异常情况下,
X
i
X_{i}
Xi 遵循
N
(
μ
i
′
,
σ
i
′
2
)
\mathcal{N}\left(\mu_{i}^{\prime}, \sigma_{i}^{\prime 2}\right)
N(μi′,σi′2),影响其后代
X
D
E
i
G
\mathbf{X}_{\mathbf{D E}_{i}^{G}}
XDEiG。对于
每个变量,至少存在一种不同的分布,无论是在正常和异常条件下还是在其自身异常和受祖先异常影响的情况下。因此,至少
2
d
=
2
K
2 d=2 K
2d=2K 个弱可分离变量满足可识别条件。
这一结果保证了聚类方法可以有效地区分异常模式,从而为噪声恢复提供必要的监督。
4.1.2. 潜在噪声变量的可识别性。
假设潜在变量的先验 p θ ( z ∣ u ) p_{\theta}(\mathbf{z} \mid \mathbf{u}) pθ(z∣u) 是条件因子分解的,其中每个元素 z i ∈ z z_{i} \in \mathbf{z} zi∈z 给定条件变量 u \mathbf{u} u 遵循一元指数族分布。对 u \mathbf{u} u 的条件通过任意函数 λ ( u ) \lambda(\mathbf{u}) λ(u)(如查找表或神经网络)执行,输出指数族的各个参数 λ i , j \lambda_{i, j} λi,j。因此,概率密度函数为:
p T , λ ( z ∣ u ) = ∏ i Q i ( z i ) Z i ( u ) exp [ ∑ j = 1 k T i , j ( z i ) λ i , j ( u ) ] p_{\mathbf{T}, \lambda}(\mathbf{z} \mid \mathbf{u})=\prod_{i} \frac{Q_{i}\left(z_{i}\right)}{Z_{i}(\mathbf{u})} \exp \left[\sum_{j=1}^{k} T_{i, j}\left(z_{i}\right) \lambda_{i, j}(\mathbf{u})\right] pT,λ(z∣u)=i∏Zi(u)Qi(zi)exp[j=1∑kTi,j(zi)λi,j(u)]
潜在噪声变量 Z \mathbf{Z} Z 的可识别性通过以下引理建立:
引理 2(潜在噪声变量的可识别性 Khemakhem 等人(2020))。假设观察数据根据定义 1 和方程 6 生成,参数为 ( f , T , λ ) (\mathbf{f}, \mathbf{T}, \lambda) (f,T,λ)。在以下条件下,这些参数的可识别性成立:
- A1: 定义 1 中的混合函数 f i f_{i} fi 是单射的。
-
- A2: 方程 6 中的充分统计量 T i , j T_{i, j} Ti,j 几乎处处可微,且 ( T i , j ) 1 ≤ j ≤ k \left(T_{i, j}\right)_{1 \leq j \leq k} (Ti,j)1≤j≤k 在 X \mathbf{X} X 的任何测度大于零的子集上是线性独立的。
-
- A3: 存在
n
k
+
1
n k+1
nk+1 个不同点
u
0
,
⋯
,
u
n
k
\mathbf{u}^{0}, \cdots, \mathbf{u}^{n k}
u0,⋯,unk,使得矩阵
L = ( λ ( u 1 ) − λ ( u 0 ) , ⋯ , λ ( u n k ) − λ ( u 0 ) ) L=\left(\lambda\left(\mathbf{u}_{1}\right)-\lambda\left(\mathbf{u}_{0}\right), \cdots, \lambda\left(\mathbf{u}_{n k}\right)-\lambda\left(\mathbf{u}_{0}\right)\right) L=(λ(u1)−λ(u0),⋯,λ(unk)−λ(u0))
- A3: 存在
n
k
+
1
n k+1
nk+1 个不同点
u
0
,
⋯
,
u
n
k
\mathbf{u}^{0}, \cdots, \mathbf{u}^{n k}
u0,⋯,unk,使得矩阵
大小为
n
k
×
n
k
n k \times n k
nk×nk 的矩阵是可逆的。
那么参数
(
f
,
T
,
λ
)
(\mathbf{f}, \mathbf{T}, \lambda)
(f,T,λ) 是
∼
A
\sim_{A}
∼A-可识别的。
含义。直观上,这一理论结果表明,可以通过利用其分布变化来识别潜在变量
Z
\mathbf{Z}
Z,正如引理 1 中所建立的不同集群反映不同的生成过程或数据中的异常模式。因此,这一引理提供了恢复
Z
\mathbf{Z}
Z 的理论基础,从而确保了我们框架中反事实的可识别性。
4.2. 最小成本因果决策的优化
在前一节中,我们建立了反事实可识别性的理论保证,强调了辅助标签区分噪声分布和促进准确反事实推理的必要性。在此基础上,本节介绍了 MiCCD 框架的优化过程。如图 2 所示,MiCCD 包含两个主要组成部分:(a) 一个用于反事实推理的代理模型,该模型利用聚类和因果可识别的变分自动编码器近似 SCM,以及 (b) 一个旨在识别最小成本干预向量的优化方案,该向量可以有效缓解目标变量中的异常并具有高 PN。
4.2.1. 基于因果图的代理模型
如图 2(a) 所示,代理模型旨在通过基于变分推理的神经架构恢复潜在噪声变量并预测内生变量,从而执行归纳推理。虽然模型本身支持归纳和预测,但也能够进行干预,从而促进反事实推理。这是通过对观测数据进行干预并利用恢复的噪声变量生成更新的预测来实现的(详见第 4.2.2 节)。代理模型由三个关键部分组成:(1) 一个异常模式聚类模块,提供辅助标签以引导噪声恢复,(2) 一个推断结构化噪声变量的编码器,以及 (3) 一个基于学习到的因果结构进行预测的解码器。
异常模式聚类。为了生成辅助变量,利用了异常数据的关键特征:每个异常模式都具有独特的统计特性,这在数据分布中产生了可分离的聚类。具体来说,采用了高斯混合模型(GMM)Dempster 等人(1977)进行聚类,假设数据是从高斯成分的混合中生成的。通过优化 GMM 参数,将模式标签
u
\mathbf{u}
u 分配给异常
样本。这些标签作为控制信号,引导噪声恢复,提供关于异常来源的关键信息,从而支持准确反事实推理所需的可识别性。
嵌入因果结构的变分自动编码器。代理模型采用变分自动编码器(VAE)框架,恢复潜在噪声变量并重构内生变量,从而促进对 SCM 的准确近似。为了确保与底层因果结构一致,推导并利用了 SCM 信息的证据下界(ELBO)作为训练目标。该目标的形式表达见方程 8,详细推导见附录 A。
log p ( x ∣ u ) = ∑ j = 1 d E q ( z j ∣ x P A j Q , x j , u ) [ log p ( x j ∣ z j , x P A j Q , u ) ] ⏟ L R E − ∑ j = 1 d D K L ( q ( z j ∣ x P A j Q , x j , u ) ∥ p ( z j ∣ x P A j Q , u ) ) \begin{aligned} \log p(\mathbf{x} \mid \mathbf{u})= & \sum_{j=1}^{d} \underbrace{\mathbb{E}_{q\left(z_{j} \mid \mathbf{x}_{P A_{j}^{Q}}, x_{j}, \mathbf{u}\right)}[\log p\left(x_{j} \mid z_{j}, \mathbf{x}_{P A_{j}^{Q}}, \mathbf{u}\right)]}_{\mathcal{L}_{R E}} \\ & -\sum_{j=1}^{d} D_{K L}\left(q\left(z_{j} \mid \mathbf{x}_{P A_{j}^{Q}}, x_{j}, \mathbf{u}\right) \| p\left(z_{j} \mid \mathbf{x}_{P A_{j}^{Q}}, \mathbf{u}\right)\right) \end{aligned} logp(x∣u)=j=1∑dLRE Eq(zj∣xPAjQ,xj,u)[logp(xj∣zj,xPAjQ,u)]−j=1∑dDKL(q(zj∣xPAjQ,xj,u)∥p(zj∣xPAjQ,u))
项 ∑ j = 1 d \sum_{j=1}^{d} ∑j=1d 表示对单个节点的求和。项 L R E \mathcal{L}_{R E} LRE 衡量重构误差,而 D K L D_{K L} DKL 强制先验分布 p ( z j ∣ x P A j Q , u ) p\left(z_{j} \mid \mathbf{x}_{P A_{j}^{Q}}, \mathbf{u}\right) p(zj∣xPAjQ,u) 与后验分布 q ( z j ∣ x P A j Q , x j , u ) q\left(z_{j} \mid \mathbf{x}_{P A_{j}^{Q}}, x_{j}, \mathbf{u}\right) q(zj∣xPAjQ,xj,u) 之间的一致性。
方程 8 展示了优化代理模型中的编码器和解码器的优化方案,如图 2(a) 所示。首先,通过异常聚类模型处理观测数据以生成模式标签。这些标签与输入数据集成,以捕捉由异常驱动的变化。随后,由于当前变量依赖于其父变量和自身的噪声,实现了多层感知机(MLP)的编码器处理每个变量及其父变量和相应的异常模式,以在因果图定义的因果顺序指导下恢复潜在噪声变量 z \mathbf{z} z。
同样实现为 MLP 的解码器利用恢复的噪声变量和父变量来重构目标变量。重构变量随后作为后续变量的父输入,以顺序方式进行。这一迭代过程确保与底层因果关系的一致性,包括线性和非线性交互。特别是,编码器对应于负责噪声恢复的逆结构方程,而解码器表示前向结构方程,有助于内生变量的准确预测。有关特定 MLP 训练配置,请参阅附录 C。
4.2.2. 基于反事实估计的优化模型
基于学习到的代理模型,通过修改其解码器并优化干预决策以达到最小成本并满足目标变量的约束条件,实施反事实推理。本节概述了反事实估计过程和用于识别最小成本干预的优化框架。
反事实估计。反事实推理通过三个基本步骤进行:归纳推理、干预和预测。首先,归纳推理涉及使用代理模型的编码器组件从观测数据和异常模式标签 u 推断 z 来恢复潜在噪声变量 z。然后,干预通过在变量 X i X_{i} Xi 上执行硬干预 d o ( X i = x i ∗ ) d o\left(X_{i}=x_{i}^{*}\right) do(Xi=xi∗),将其值设置为 x i ∗ x_{i}^{*} xi∗ 并去除其对父变量的依赖。最后,预测通过因果图传播干预的效果:对于每个子变量 X j ∈ X C h i X_{j} \in X_{C h i} Xj∈XChi,编码器恢复其噪声 z j z_{j} zj,解码器使用干预后的父值 x i ∗ x_{i}^{*} xi∗ 和推断的噪声 z j z_{j} zj 重构其值。这一过程按因果顺序迭代进行,导致目标变量 Y Y Y 的反事实结果 y ∗ y^{*} y∗。这些步骤共同使代理模型能够模拟假设情景,并为优化干预决策提供基础。
最小成本优化。现在解决了识别最优干预向量 x ∗ \mathbf{x}^{*} x∗ 的问题,该向量以最小干预成本解决目标变量 Y Y Y 中的异常。目标是识别使成本函数 C ( d o ( X = x ∗ ) , x ) C\left(d o\left(\mathbf{X}=\mathbf{x}^{*}\right), \mathbf{x}\right) C(do(X=x∗),x) 最小化的干预向量,同时满足约束条件 P ( Y d o ( X = x ∗ ) = 0 ∣ X = x , Y = 1 ) ≥ ι P\left(Y_{d o\left(\mathbf{X}=\mathbf{x}^{*}\right)}=0 \mid \mathbf{X}=\mathbf{x}, Y=1\right) \geq \iota P(Ydo(X=x∗)=0∣X=x,Y=1)≥ι。然而,在许多现实场景中,干预的动作空间通常是大且连续的,可能在这个空间中有无穷多个干预向量 x ∗ \mathbf{x}^{*} x∗。
为了解决这个问题,将其公式化为一个约束优化任务。使用 Karush-Kuhn-Tucker (KKT) 条件推导出最优性的必要条件。拉格朗日函数 L L L 定义如下:
L ( x ∗ , λ ) = C ( d o ( X = x ∗ ) , x ) + λ ⋅ g ( x ∗ ) L\left(\mathbf{x}^{*}, \lambda\right)=C\left(d o\left(\mathbf{X}=\mathbf{x}^{*}\right), \mathbf{x}\right)+\lambda \cdot g\left(\mathbf{x}^{*}\right) L(x∗,λ)=C(do(X=x∗),x)+λ⋅g(x∗)
约束函数为
g
(
x
∗
)
=
ι
−
P
(
Y
d
o
(
X
=
x
∗
)
=
0
∣
X
=
x
,
Y
=
g\left(\mathbf{x}^{*}\right)=\iota-P\left(Y_{d o\left(\mathbf{X}=\mathbf{x}^{*}\right)}=0 \mid \mathbf{X}=\mathbf{x}, Y=\right.
g(x∗)=ι−P(Ydo(X=x∗)=0∣X=x,Y= 1),对应的拉格朗日乘数为
λ
≥
0
\lambda \geq 0
λ≥0。
为了高效解决这一非线性优化问题,采用了序列最小二乘规划(SLSQP)算法 Boggs 和 Tolle(1995)。SLSQP 进行迭代搜索以识别最优干预向量
x
∗
\mathbf{x}^{*}
x∗ 和相应的拉格朗日乘数
λ
\lambda
λ,从而使 KKT 条件得到满足。同时,强制执行成本最小化和
P
N
≥
ι
P N \geq \iota
PN≥ι 的约束条件。这里,PN 起到“有效性过滤器”的作用,将搜索空间限制为具有高成功率的干预解决方案,即使在大连续动作空间中也是如此。通过整合反事实推理和数值优化,所提出的框架促进了复杂现实场景中的高效且成本敏感的决策制定。
5. 实验 在本节中,首先描述了实验中使用的数据集、基准方法和评估指标。随后提供了数值结果和深入讨论,以解决以下关键研究问题:Q1. 与现有基线相比,MiCCD 在泛化设置中的表现如何?Q2. 当由基于干预的策略指导时,根本原因分析的有效性如何?Q3. MiCCD 框架的每个组件在反事实推理中贡献的程度如何?
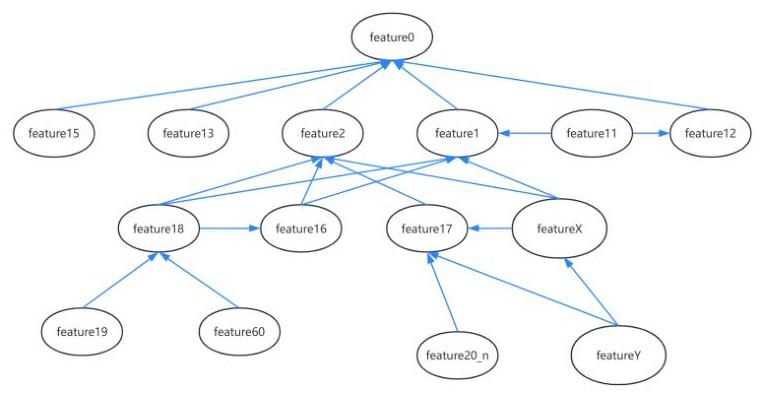
图 3: 删除隐藏变量后由一些领域专家总结的不完整因果关系图。
5.1. 实验设置
数据集。实验在基于随机因果图的模拟数据集和三个真实世界数据集上进行。对于模拟数据集,使用随机生成的因果图构建了结构因果模型(SCM),其中变量数为 n = 5 , 10 , 20 n=5,10,20 n=5,10,20。图结构包括链式和随机拓扑,稀疏水平设置为 0.2 和 0.3。因果边的权重被采样以反映不同程度的相关强度,包括弱、中和强关联。根据定义 1 生成训练样本,并通过扰动随机选择变量的噪声项引入异常。对于每种配置,使用不同的随机种子生成五个数据集。所有报告的结果都是这五个数据集的平均值,并报告部分标准差以反映运行间的变异性。
除了合成数据外,还使用了三个真实世界数据集:
-
AIOPs 数据集 Zhang 等人 (2022)。该数据集包含一个真实的 5G 数据集,其中包括因果图和相关特征数据集。特征数据集包含 23 个可观测变量,约 45 % 45\% 45% 的样本被仔细标记为相关根本原因。由于涉及隐藏变量的 MiCCD 方法仍在开发中,仅考虑关系图中的观测变量。图 3 显示了我们实验中使用的调整后的因果图。
-
- Lemma-RCA 数据集 Zheng 等人 (2024a)。该数据集包含一系列真实的系统故障,涵盖实际应用场景,如微服务、水处理或分配系统。预处理的 IT 系统数据被选作实验。
-
- 城市空气污染物数据集 Zhu 等人 (2018)。该数据集包含 2013-2014 年期间从北京奥林匹克体育中心站收集的空气质量监测数据,由中国国家环境监测中心发布。它包括 PM2.5、PM10、SO2 和 NO2 等污染物的小时浓度水平。Zhu 等人研究了 APEC 会议期间实施的各种空气质量保护措施,包括尾号限行、工业停产和施工停工,并评估了这些措施对空气质量改善的直接影响。
-
图 4 展示了同一季度内的污染关系,呈现了 APEC 会议前后污染物的因果路径。
评估指标。对于所有实验评估,采用以下标准: -
F1 分数 Powers (2020) 定义为精确率和召回率的调和平均值,该指标评估决策的正确性。
-
- 归一化成本 (N-Cost) 一种将每次干预决策相关的成本归一化的指标,反映经济可行性。
-
- 归一化折扣累积增益 @ K \mathbf{K} K (nDCG@k) Yining 等人 (2013) 衡量排名质量,通过量化预测根本原因与其理想排名在前 K 位置内的一致性。
-
- 相对均方误差 (r-MSE) Legendre (1806) 将标准均方误差归一化以评估反事实预测的可靠性。
这些指标共同从多个维度评估所提出的框架。F1 分数确保准确性,N-Cost 强调成本效益,nDCG@k 捕捉根本原因排名的实际相关性,而 r-MSE 验证反事实推理的稳健性。这种全面评估对于现实世界的部署至关重要,因为既要考虑技术性能,也要考虑操作可行性。
- 相对均方误差 (r-MSE) Legendre (1806) 将标准均方误差归一化以评估反事实预测的可靠性。
基线方法。为了评估所提出方法的有效性,与相关工作中描述的几种基线方法进行了比较,包括 NaiveRCA Casalicchio 等人 (2019),CausalRCA Budhathoki 等人 (2022),BIGEN Nguyen 等人 (2024),LIME Ribeiro 等人 (2018),LC Idé
等人 (2021),AUF-MICNS Du 等人 (2024)。为了公平起见,所提出的方法和 AUF-MICNS 使用相同的成本函数。有关基线方法的详细信息,请参阅附录 B。
5.2. 结果与讨论
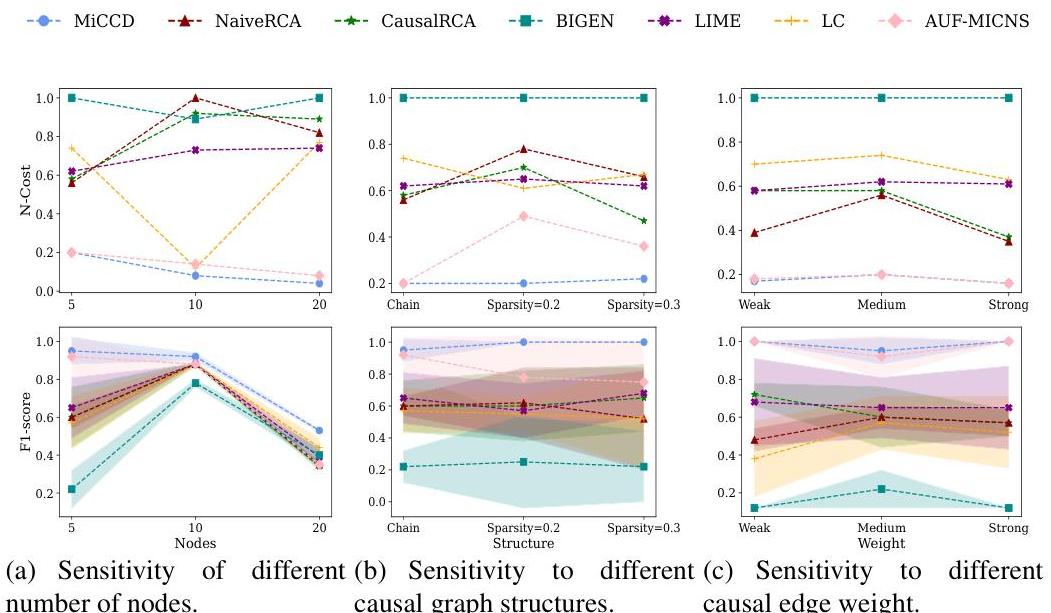
图 5: 在不同实验设置下的结果比较。在三种不同设置下评估了不同方法的性能:节点数量(左)、因果图的稀疏水平(中)和因果边权重的强度(右)。在每个子图中,顶部行报告归一化决策成本,而底部行呈现相应的 F1 分数。可以看出,所提出的方法在所有设置下始终实现最低的干预成本并产生优越的 F1 分数,表明相比基线方法具有更高的决策效率和诊断准确性。
整体性能 (Q1)。在多个模拟数据集上比较了所有方法的 N-Cost、F1 分数和 nDCG@k 值。结果总结在图 5 和图 6 中,突出显示了在不同实验条件下的整体性能。如图所示,所提出的方法在成本效益、决策准确性和排名质量方面始终优于所有基线方法。
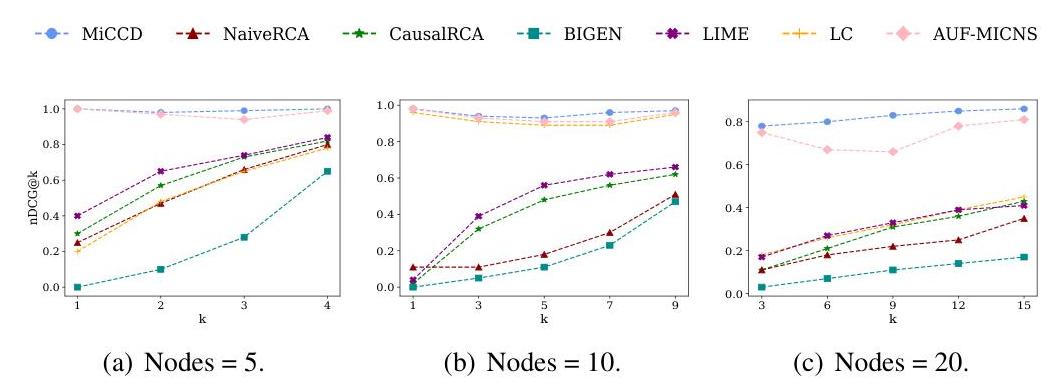
图 6: 在不同节点数量下的 nDCG@k 值比较。在包含 5、10 和 20 个节点的数据集中比较了不同 k 值的 nDCG@k 值。在所有配置中,MiCCD 相对于基线方法始终产生更高的 nDCG@k 分数,表明改进的排名质量和更有效的根本原因识别。
在图 5 中,每一列代表在不同控制设置下进行的实验。第一列表示在不同节点数量下的结果;第二列表示不同因果图结构的影响,其特征在于不同的稀疏水平;第三列表示在不同因果边权重强度下的性能。在每次实验中,单个因素发生变化,而其他两个保持不变,从而可以清楚地评估其对模型性能的单独影响。
如图 5 所示,第一行结果表明 MiCCD 在所有实验设置下始终实现最低的决策成本。重要的是要强调,MiCCD 和 AUF-MICNS 使用相同的成本评估指标。尽管 AUF-MICNS 的决策成本比其他基线方法(排除 MiCCD)低,但其成本始终高于 MiCCD。第二行结果表明,MiCCD 不仅在不同条件下实现最高的 F1 分数,而且与竞争方法相比显示出显著更窄的误差条。这些发现表明,MiCCD 能够同时减少误报率和决策成本,同时在精确率和召回率之间保持平衡,从而确认其优越的整体性能。此外,随着节点数量和因果图结构复杂性的增加,MiCCD 继续保持强大的稳定性和适应性——尤其是在更高稀疏度的随机图中。这些结果突显了 MiCCD 在资源有限干预和高误报成本的真实场景中的适用性,展示了其在广泛实际领域中支持经济高效且稳健决策的潜力。
图 6 展示了所有方法在包含 5、10 和 20 个节点的数据集上的不同 k 值的 nDCG 性能。
CausalRCA、NaiveRCA、LIME 和 LC 的性能强烈依赖于 k 的值。当 k 较小时,它们的 nCDG 值保持较低,表明排名能力有限。相比之下,MiCCD 和 AUF-MICNS 在不同条件下表现出相对稳定性。然而,AUF-MICNS 显示出更明显的波动,表明 MiCCD 在泛化任务中始终表现良好。这种稳定性对于决策过程至关重要,确保潜在解决方案的准确和可靠优先级排序。
基于有效干预的根本原因分析性能 (Q2)。如表 1 定量所示,MiCCD 在所有三个真实世界数据集中实现了最先进的性能。这种持续的优势提供了关于 MiCCD 在根本原因定位中的两个关键见解:
复杂场景中的优势:为了展示 MiCCD 在引导根本原因定位方面的能力,潜在根本原因被视为解决数据异常的选项,并将问题公式化为多类分类任务。计算 F1 分数以评估所提出方法识别的干预变量是否对应于真正的根本原因。在此任务(AIOP 和 Lemma-RCA)中,MiCCD 的表现比专门的基线高出多达 44 个百分点 (pp)。值得注意的是,即使是专门的根本原因定位方法,如 NaiveRCA、CausalRCA 和 BIGEN,在这种经典场景中也无法超越 MiCCD。MiCCD 在通过最小化成本进行决策方面比基于因果 Shapley 值的方法(CausalRCA)高出 23-46pp,突显了其优势。与基于鲁棒相关性的方法(LIME)相比,MiCCD 仍保持 12-44pp 的领先优势,证明了其避免虚假依赖的能力。
二元任务效率:为了基于有效干预评估面向性能的根本原因分析,利用了城市空气污染物数据集,假设某些污染物不受 APEC 期间实施干预的影响,因此被标记为非干预变量,而那些显著减少的则被分类为干预变量。此设置使任务可框架化为二元分类问题,目标是使用两个真实世界数据集区分可干预和不可干预变量。计算 F1 分数以评估识别变量与地面真实干预结果的一致性,从而反映所提出方法和基线算法在可行决策场景中的有效性。尽管 MiCCD 和 BIGEN 在空气污染物数据集上都取得了完美分数,但由于任务仅专注于识别可干预性,限制了其揭示干预规划性能差异的能力。重要的是,MiCCD 进一步通过结合最小成本优化展示了其在面向性能的根本原因分析中的优势,从而能够生成同样准确但更高效的干预策略,相较于 BIGEN。
表 1: 不同方法在三个真实数据集任务上的 F1 分数
| 方法 | AIOPs | 空气污染物 | Lemma-RCA |
|---|---|---|---|
| MiCCD | 0.95 \mathbf{0 . 9 5} 0.95 | 1.00 \mathbf{1 . 0 0} 1.00 | 0.94 \mathbf{0 . 9 4} 0.94 |
| NaiveRca | 0.79 | 0.76 | 0.44 |
| CausalRca | 0.72 | 0.80 | 0.48 |
| BIGEN | 0.88 | 1.00 \mathbf{1 . 0 0} 1.00 | 0.63 |
| LIME | 0.83 | 0.74 | 0.50 |
| LC | 0.87 | 0.82 | 0.50 |
| AUF-MICNS | 0.82 | 0.60 | 0.50 |
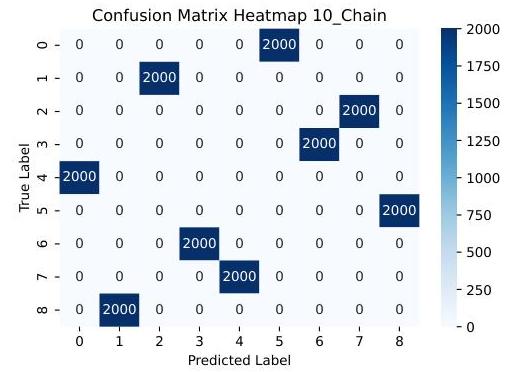
图 7: 混淆矩阵热图:当数据集包含 10 个节点、链式因果结构且因果边权重为中等水平时的聚类结果。
组件有效性及反事实能力 (Q3)。为了评估代理模型中每个组件的重要性,设计了两个变体:a) MiCCD-u,不使用作为监督信号的异常模式标签;b) MiCCD-g,省略因果图并绕过逐变量迭代。表 2 展示了 MiCCD、其两个变体以及 AUF-MICNS 杜等人 (2024) 的反事实估计模型的性能。在包含 10 个节点的情况下表现出优越性能,这归因于链式结构中学习因果机制的容易性,使得因果图的重要性降低。然而,在更复杂的结构中(例如,稀疏度
=
0.3
=0.3
=0.3),MiCCD-g 的 r-MSE 从 0.011 增加到 0.038,突显了纳入因果图的价值。结果进一步表明模式标签监督在低维设置中的关键作用。值得注意的是,由于 AUF-MICNS 依赖于群体层面优化,不适合实例特定的异常,因此其性能始终较差。尽管所提出的变体在处理异常数据方面受到限制,但它们比 AUF-MICNS 表现出更大的适应性,从而支持 MiCCD 的稳健性。重构性能在附录 D 中进一步验证。
以包含 10 个节点、链式因果结构和中等因果权重的数据集为例,图 7 展示了使用异常模式聚类来区分异常模式的有效性。这种高分离性提供了一个可靠的监督信号;当移除时(MiCCD-u),整个结构的反事实 r-MSE 增加,如表 2 所示。
6. 结论
最小成本因果决策(MiCCD)框架作为一种创新范式被引入,用于在复杂的异常出现情景中进行决策,包括人工智能的操作和维护。MiCCD 将因果推理与连续优化相结合,以应对在实现期望结果的同时最小化干预成本的挑战。该框架包含两个主要组成部分:(a) 一个代理模型,通过异常模式的聚类标签近似现实世界的因果关系;(b) 一个优化策略,通过反事实估计识别最具成本效益的干预措施。实证结果表明,MiCCD 通过分配变量特定的成本展现出在多样化决策背景下的适应性,从而实现根本原因识别和目标干预。该框架通过定制策略以适应特定系统
或情景(例如个性化医学或智能制造),突显了其广泛的适用性和有效性。
表 2: 三种方法在不同设置下的反事实估计平均 r-MSE
| 结构 | 方法 | 5 | 10 | 20 |
|---|---|---|---|---|
| 链式 | MiCCD | 0.019 | 0.018 | 0.008 |
| MiCCD-u | 0.040 | 0.037 | 0.009 | |
| MiCCD-g | 0.050 | 0.011 | 0.048 | |
| AUF-MICNS | 0.168 | 0.098 | 0.059 | |
| 稀疏度 = 0.2 =0.2 =0.2 | MiCCD | 0.063 | 0.043 | 0.018 |
| MiCCD-u | 0.067 | 0.069 | 0.031 | |
| MiCCD-g | 0.117 | 0.063 | 0.084 | |
| AUF-MICNS | 0.251 | 0.196 | 0.173 | |
| 稀疏度 = 0.3 =0.3 =0.3 | MiCCD | 0.038 | 0.020 | 0.004 |
| MiCCD-u | 0.100 | 0.034 | 0.005 | |
| MiCCD-g | 0.079 | 0.038 | 0.007 | |
| AUF-MICNS | 0.206 | 0.131 | 0.035 |
或情景(例如个性化医疗或智能制造),从而突显其广泛的适用性和有效性。
附录 A. 证据下界
在本小节中,我们展示证据下界。
log p ( x ∣ u ) = log p ( x 1 , x 2 , … , x d ∣ u ) = ∑ j = 1 d log p ( x j ∣ x P A j G , u ) = ∑ j = 1 d log ∫ p ( x j , z j ∣ x P A j G , u ) d z j = ∑ j = 1 d log ∫ p ( x j ∣ z j , x P A j G , u ) p ( z j ∣ x P A j G , u ) d z j = ∑ j = 1 d log ∫ p ( x j ∣ z j , x P A j G , u ) p ( z j ∣ x P A j G , u ) q ( z j ∣ x P A j G , x j , u ) q ( z j ∣ x P A j G , x j , u ) d z j = ∑ j = 1 d log E q ( z j ∣ x P A j G , x j , u ) [ p ( x j ∣ z j , x P A j G , u ) p ( z j ∣ x P A j G , u ) q ( z j ∣ x P A j G , x j , u ) ] ≥ ∑ j = 1 d E q ( z j ∣ x P A j G , x j , u ) [ log p ( x j ∣ z j , x P A j G , u ) p ( z j ∣ x P A j G , u ) q ( z j ∣ x P A j G , x j , u ) ] = ∑ j = 1 d E q ( z j ∣ x P A j G , x j , u ) [ log p ( x j ∣ z j , x P A j G , u ) + log p ( z j ∣ x P A j G , u ) − log q ( z j ∣ x P A j G , x j , u ) ] = ∑ j = 1 d E q ( z j ∣ x P A j G , x j , u ) [ log p ( x j ∣ z j , x P A j G , u ) ] − ∑ j = 1 d D K L ( q ( z j ∣ x P A j G , x j , u ) ∥ p ( z j ∣ x P A j G , u ) ) \begin{aligned} \log p(\mathbf{x} \mid \mathbf{u}) & =\log p\left(x_{1}, x_{2}, \ldots, x_{d} \mid \mathbf{u}\right) \\ & =\sum_{j=1}^{d} \log _{p}\left(x_{j} \mid \mathbf{x}_{P A_{j}^{\mathcal{G}}}, \mathbf{u}\right) \\ & =\sum_{j=1}^{d} \log \int p\left(x_{j}, z_{j} \mid \mathbf{x}_{P A_{j}^{\mathcal{G}}}, \mathbf{u}\right) d z_{j} \\ & =\sum_{j=1}^{d} \log \int p\left(x_{j} \mid z_{j}, \mathbf{x}_{P A_{j}^{\mathcal{G}}}, \mathbf{u}\right) p\left(z_{j} \mid \mathbf{x}_{P A_{j}^{\mathcal{G}}}, \mathbf{u}\right) d z_{j} \\ & =\sum_{j=1}^{d} \log \int p\left(x_{j} \mid z_{j}, \mathbf{x}_{P A_{j}^{\mathcal{G}}}, \mathbf{u}\right) p\left(z_{j} \mid \mathbf{x}_{P A_{j}^{\mathcal{G}}}, \mathbf{u}\right) \frac{q\left(z_{j} \mid \mathbf{x}_{P A_{j}^{\mathcal{G}}}, x_{j}, \mathbf{u}\right)}{q\left(z_{j} \mid \mathbf{x}_{P A_{j}^{\mathcal{G}}}, x_{j}, \mathbf{u}\right)} d z_{j} \\ & =\sum_{j=1}^{d} \log \mathbb{E}_{q\left(z_{j} \mid \mathbf{x}_{P A_{j}^{\mathcal{G}}}, x_{j}, \mathbf{u}\right)}\left[\frac{p\left(x_{j} \mid z_{j}, \mathbf{x}_{P A_{j}^{\mathcal{G}}}, \mathbf{u}\right) p\left(z_{j} \mid \mathbf{x}_{P A_{j}^{\mathcal{G}}}, \mathbf{u}\right)}{q\left(z_{j} \mid \mathbf{x}_{P A_{j}^{\mathcal{G}}}, x_{j}, \mathbf{u}\right)}\right] \\ & \geq \sum_{j=1}^{d} \mathbb{E}_{q\left(z_{j} \mid \mathbf{x}_{P A_{j}^{\mathcal{G}}}, x_{j}, \mathbf{u}\right)}\left[\log \frac{p\left(x_{j} \mid z_{j}, \mathbf{x}_{P A_{j}^{\mathcal{G}}}, \mathbf{u}\right) p\left(z_{j} \mid \mathbf{x}_{P A_{j}^{\mathcal{G}}}, \mathbf{u}\right)}{q\left(z_{j} \mid \mathbf{x}_{P A_{j}^{\mathcal{G}}}, x_{j}, \mathbf{u}\right)}\right] \\ & =\sum_{j=1}^{d} \mathbb{E}_{q\left(z_{j} \mid \mathbf{x}_{P A_{j}^{\mathcal{G}}}, x_{j}, \mathbf{u}\right)}\left[\log p\left(x_{j} \mid z_{j}, \mathbf{x}_{P A_{j}^{\mathcal{G}}}, \mathbf{u}\right)+\log p\left(z_{j} \mid \mathbf{x}_{P A_{j}^{\mathcal{G}}}, \mathbf{u}\right)-\log q\left(z_{j} \mid \mathbf{x}_{P A_{j}^{\mathcal{G}}}, x_{j}, \mathbf{u}\right)\right] \\ & =\sum_{j=1}^{d} \mathbb{E}_{q\left(z_{j} \mid \mathbf{x}_{P A_{j}^{\mathcal{G}}}, x_{j}, \mathbf{u}\right)}\left[\log p\left(x_{j} \mid z_{j}, \mathbf{x}_{P A_{j}^{\mathcal{G}}}, \mathbf{u}\right)\right] \\ & -\sum_{j=1}^{d} D_{K L}\left(q\left(z_{j} \mid \mathbf{x}_{P A_{j}^{\mathcal{G}}}, x_{j}, \mathbf{u}\right) \| p\left(z_{j} \mid \mathbf{x}_{P A_{j}^{\mathcal{G}}}, \mathbf{u}\right)\right) \end{aligned} logp(x∣u)=logp(x1,x2,…,xd∣u)=j=1∑dlogp(xj∣xPAjG,u)=j=1∑dlog∫p(xj,zj∣xPAjG,u)dzj=j=1∑dlog∫p(xj∣zj,xPAjG,u)p(zj∣xPAjG,u)dzj=j=1∑dlog∫p(xj∣zj,xPAjG,u)p(zj∣xPAjG,u)q(zj∣xPAjG,xj,u)q(zj∣xPAjG,xj,u)dzj=j=1∑dlogEq(zj∣xPAjG,xj,u) q(zj∣xPAjG,xj,u)p(xj∣zj,xPAjG,u)p(zj∣xPAjG,u) ≥j=1∑dEq(zj∣xPAjG,xj,u) logq(zj∣xPAjG,xj,u)p(xj∣zj,xPAjG,u)p(zj∣xPAjG,u) =j=1∑dEq(zj∣xPAjG,xj,u)[logp(xj∣zj,xPAjG,u)+logp(zj∣xPAjG,u)−logq(zj∣xPAjG,xj,u)]=j=1∑dEq(zj∣xPAjG,xj,u)[logp(xj∣zj,xPAjG,u)]−j=1∑dDKL(q(zj∣xPAjG,xj,u)∥p(zj∣xPAjG,u))
附录 B. 基线细节
-
NaiveRCA Casalicchio 等人 (2019) 通过直接应用现有的异常分数(如 z 分数)对变量进行排名,以估计它们成为异常根本原因的可能性。
-
表 A.3: MLP 训练配置(我们用 AP 表示城市空气污染物)
| | 链式 | | | 稀疏度=0.2 | | | 稀疏度=0.3 | | | | | |
| :–: | :–: | :–: | :–: | :–: | :–: | :–: | :–: | :–: | :–: | :–: | :–: | :–: |
| 数据集 | 5 | 10 | 20 | 5 | 10 | 20 | 5 | 10 | 20 | AIOPs | AP | Lemma-RCA |
| 批量大小 | 64 | 64 | 64 | 64 | 64 | 64 | 64 | 64 | 64 | 64 | 64 | 64 |
| 轮次 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 |
| 隐藏维度 | 50 | 30 | 30 | 50 | 30 | 30 | 50 | 30 | 30 | 50 | 50 | 50 |
| 深度 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 |
| 学习率 | 1e-3 | 1e-3 | 1e-3 | 1e-3 | 1e-3 | 1e-3 | 1e-3 | 1e-3 | 1e-3 | 1e-3 | 1e-3 | 1e-3 |
| 激活函数 | frelu | frelu | frelu | frelu | frelu | frelu | frelu | frelu | frelu | frelu | frelu | frelu | -
CausalRCA Budhathoki 等人 (2022) 使用功能因果模型 (FCM) 来量化每个观察到的异常变量的贡献。Shapley 值被用来公平评估这些贡献,从而促进根因的正式识别。
-
- BIGEN Nguyen 等人 (2024) 提出了一种框架,将贝叶斯推断与基于梯度的归因方法相结合,以有效识别和归因复杂系统中异常的根本原因,同时考虑节点和边噪声。
-
- LIME Ribeiro 等人 (2018) 通过采样附近的点在测试样本周围构建局部邻域。然后训练一个线性模型(如线性回归)来拟合这个邻域,通过模型的系数解释预测,这些系数反映了每个特征对结果的贡献。
-
- LC Idé 等人 (2021) 通过评估模型预测与实际观察值之间的偏差为每个输入变量分配责任分数。基于可能性导出一个校正项以解释异常预测。
-
- AUF-MICNS Du 等人 (2024) 通过在线梯度下降和集成技术动态更新变量之间的影响关系。随后通过概率区域构造和凸二次约束二次规划 (QCQP) 生成最小成本变更建议。
附录 C. 实现细节
表 A.3 提供了编码器和解码器中使用的多层感知机(MLP)模型的训练配置。
表 D.4: 三种方法在不同设置下的重建平均相对 MSE
| 链式 | 稀疏度=0.2 | 稀疏度=0.3 | |||||||
|---|---|---|---|---|---|---|---|---|---|
| 方法 | 5 | 10 | 20 | 5 | 10 | 20 | 5 | 10 | 20 |
| MiCCD | 0.025 | 0.017 | 0.008 | 0.036 | 0.023 | 0.013 | 0.018 | 0.011 | 0.002 |
| MiCCD-u | 0.034 | 0.034 | 0.009 | 0.039 | 0.042 | 0.016 | 0.070 | 0.027 | 0.003 |
| AUF-MICNS | 0.135 | 0.088 | 0.057 | 0.211 | 0.156 | 0.134 | 0.151 | 0.109 | 0.027 |
附录 D. 更多实验结果
模型在测试集上的重建结果已呈现。表 D.4 总结了 MiCCD、MiCCD-u 和 AUF-MICNS 在模拟数据集上的 r-MSE。由于 MiCCD-g 在训练期间向解码器提供完整的输入向量 x,因此未对其进行评估。结果表明,所提出的方法显著优于其变体和基线。
参考文献
Charles K Assaad, Imad Ez-Zejjari, 和 Lei Zan. 给定带有循环的无环摘要因果图的时间序列集体异常的根本原因识别。在国际人工智能与统计会议论文集,第 8395-8404 页。PMLR, 2023.
Paul T Boggs 和 Jon W Tolle. 序列二次规划。Acta numerica, 4:1-51, 1995.
Kailash Budhathoki, Lenon Minorics, Patrick Blöbaum, 和 Dominik Janzing. 基于因果结构的异常根本原因分析。在国际机器学习会议论文集,第 2357-2369 页。PMLR, 2022.
Mattia Carletti, Chiara Masiero, Alessandro Beghi, 和 Gian Antonio Susto. 工业 4.0 中的可解释机器学习:通过评估异常检测中的特征重要性来启用根本原因分析。在 2019 IEEE 国际系统、人与控制论会议 (SMC) 论文集,第 21-26 页。IEEE, 2019.
Giuseppe Casalicchio, Christoph Molnar, 和 Bernd Bischl. 黑盒模型特征重要性的可视化。在欧洲机器学习与知识发现会议 (ECML PKDD) 2018 论文集,第 655-670 页。Springer, 2019.
Arthur P Dempster, Nan M Laird, 和 Donald B Rubin. 通过 EM 算法从不完全数据中获得最大似然估计。Journal of the royal statistical society: series B (methodological), 39(1):1-22, 1977.
Min Du, Feifei Li, Guineng Zheng, 和 Vivek Srikumar. Deeplog:通过深度学习从系统日志中进行异常检测和诊断。在 2017 ACM SIGSAC 计算机和通信安全会议论文集,第 1285-1298 页,2017.
Wen-Bo Du, Tian Qin, Tian-Zuo Wang, 和 Zhi-Hua Zhou. 在非平稳环境中以最小成本避免不良未来。在第三十八届年度神经信息处理系统会议论文集,2024.
Zhou Fang, Jiaxin Qi, Lubin Fan, Jianqiang Huang, Ying Jin, 和 Tianren Yang. 基于多阶段深度学习方法的人机交互街道网络设计框架。Computers, Environment and Urban Systems, 96:101853, 2022.
Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, 和 Sergey Levine. Soft actor-critic:带随机行为者的离线最大熵深度强化学习。在国际机器学习会议论文集,第 1861-1870 页。PMLR, 2018.
Yuh-Jong Hu 和 Shang-Jen Lin. 深度强化学习优化金融组合管理。在 2019 amity 国际人工智能会议 (AICAI) 论文集,第 14-20 页。IEEE, 2019.
Sangwon Hyun, Eunkyoung Jee, 和 Doo-Hwan Bae. 基于上下文模糊聚类的赛博物理系统系统的协作失败分析。Empirical Software Engineering, 30(2):1-29, 2025.
Tsuyoshi Idé, Amit Dhurandhar, Jiří Navrátil, Moninder Singh, 和 Naoki Abe. 利用似然补偿进行异常归属。在 AAAI 人工智能会议论文集,第 35 卷,第 4131-4138 页,2021.
Ilyes Khemakhem, Diederik Kingma, Ricardo Monti, 和 Aapo Hyvarinen. 变分自动编码器和非线性 ICA:统一框架。在国际人工智能与统计会议论文集,第 2207-2217 页。PMLR, 2020.
Ilya Kostrikov, Ashvin Nair, 和 Sergey Levine. 带隐式 Q 学习的离线强化学习。在国际学习表示会议论文集,2022.
Aviral Kumar, Aurick Zhou, George Tucker, 和 Sergey Levine. 保守 Q 学习用于离线强化学习。Advances in Neural Information Processing Systems, 33:1179-1191, 2020.
Adrien Marie Legendre. 确定彗星轨道的新方法:附有对 1805 年两颗彗星的完善方法及其应用的补充。Courcier, 1806.
Francesco Locatello, Stefan Bauer, Mario Lucic, Gunnar Raetsch, Sylvain Gelly, Bernhard Schölkopf, 和 Olivier Bachem. 对无监督学习解缠表示的常见假设的挑战。在国际机器学习会议论文集,第 4114-4124 页。PMLR, 2019.
Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A Rusu, Joel Veness, Marc G Bellemare, Alex Graves, Martin Riedmiller, Andreas K Fidjeland, Georg Ostrovski, 等. 通过深度强化学习实现人类级别的控制。Nature, 518(7540):529-533, 2015.
Phuoc Nguyen, Truyen Tran, Sunil Gupta, Thin Nguyen, 和 Svetha Venkatesh. 在嘈杂机制下的异常根本原因解释。在 AAAI 人工智能会议论文集,第 38 卷,第 20508-20515 页,2024.
Renjian Pan, Zhaobo Zhang, Xin Li, Krishnendu Chakrabarty, 和 Xinli Gu. 集成系统的无监督根本原因分析。在 2020 IEEE 国际测试会议 (ITC) 论文集,第 1-10 页。IEEE, 2020.
Judea Pearl. 因果关系。剑桥大学出版社, 2009.
David MW Powers. 评估:从精度、召回率和 F 测量到 ROC、知情性、标记性和相关性。arXiv 预印本 arXiv:2010.16061, 2020.
Tian Qin, Tian-Zuo Wang, 和 Zhi-Hua Zhou. 排练学习以避免不良未来。Advances in Neural Information Processing Systems, 36, 2024.
Josephine Rehak, Anouk Sommer, Maximilian Becker, Julius Pfrommer, 和 Jürgen Beyerer. 基于异常检测和因果图的反事实根本原因分析。在 2023 IEEE 第 21 届工业信息学国际会议 (INDIN) 论文集,第 1-7 页。IEEE, 2023.
Marco Tulio Ribeiro, Sameer Singh, 和 Carlos Guestrin. 锚点:高精度模型无关解释。在 AAAI 人工智能会议论文集,第 32 卷,2018.
Mohammadsaleh Saadatmand, Tugrul Daim, Carlos Mena, Haydar Yalcin, Gulin Bolatan, 和 Manali Chatterjee. 面向机器学习和数据科学 ( m l / d s \mathrm{ml} / \mathrm{ds} ml/ds) 的金融策略评估框架:案例研究驱动的决策模型。IEEE 工程管理事务,2024.
Marc Schmitt. 自动化机器学习:业务分析中的 AI 驱动决策。智能系统与应用,18:200188, 2023.
John Schulman, Sergey Levine, Pieter Abbeel, Michael I Jordan, 和 Philipp Moritz. 信任区域策略优化。在第 32 届国际机器学习会议论文集,第 1889-1897 页。PMLR, 2015.
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, 和 Oleg Klimov. 近端策略优化算法。arXiv 预印本 arXiv:1707.06347, 2017.
Ali Shehadeh, Odey Alshboul, Khaled F Al-Shboul, 和 Omer Tatari. 高速公路建设专家系统:增强粒子群优化多目标优化以实现最佳设备管理。专家系统与应用,249:123621, 2024.
Eric Strobl 和 Thomas A Lasko. 含隐变量的样本特定根本因果推断。在因果学习与推理会议论文集,第 895-915 页。PMLR, 2023.
Erik Strumbelj 和 Igor Kononenko. 使用博弈理论对个体分类进行高效解释。The Journal of Machine Learning Research, 11 : 1 − 18 , 2010 11: 1-18,2010 11:1−18,2010.
Behrooz Tahmasebi, Seyed Abolfazl Motahari, 和 Mohammad Ali MaddahAli. 有限混合物有限乘积测量的可识别性。arXiv 预印本 arXiv:1807.05444, 2018.
Venkata Mohit Tamanampudi. 数据驱动的事件管理方法:通过基于机器学习的根本原因分析增强 DevOps 操作。分布式学习与科学研究的广泛应用,6:419466, 2020.
katesan, TV Ambuli, Kabirdoss Devi, K Sampath, 和 S Kumaran. 数据驱动决策:将机器学习整合到人力资源和财务管理中。在 2024 年第七届电路、电力与计算技术国际会议 (ICCPCT) 论文集,第 1 卷,第 1829-1834 页。IEEE, 2024.
Ahsan Waqar. 建设工程中的智能决策支持系统:人工智能和机器学习方法。专家系统与应用,249:123503, 2024.
Yifan Wu, George Tucker, 和 Ofir Nachum. 行为正则化离线强化学习。arXiv 预印本 arXiv:1911.11361, 2019.
Wang Yining, Wang Liwei, Li Yuanzhi, He Di, Chen Wei, 和 Liu Tie-Yan. 一种理论分析 ndcg 排名度量的方法。在第 26 届年度学习理论会议论文集,2013.
Haitao Yuan, Jing Bi, Ziqi Wang, Jinhong Yang, 和 Jia Zhang. 混合边缘和云计算系统中的部分和成本最小化计算卸载。专家系统与应用,250:123896, 2024.
[数据集] Tianjian Zhang, Qian Chen, Yi Jiang, Dandan Miao, Feng Yin, Tao Quan, Qingjiang Shi, 和 Zhi-Quan Luo. ICASSP-SPGC 2022:无线网络故障定位的根本原因分析。在 ICASSP 2022 - 2022 IEEE 国际声学、语音和信号处理会议 (ICASSP) 论文集,第 9301-9305 页。IEEE, 2022.
[数据集] Lecheng Zheng, Zhengzhang Chen, Dongjie Wang, Chengyuan Deng, Reon Matsuoka, 和 Haifeng Chen. Lemma-RCA:一个大型多模态多领域根本原因分析数据集。arXiv 预印本 arXiv:2406.05375, 2024.
Yu Zheng, Qianyue Hao, Jingwei Wang, Changzheng Gao, Jinwei Chen, Depeng Jin, 和 Yong Li. 城市决策制定的机器学习综述:规划、交通和医疗保健中的应用。ACM Computing Surveys, 2024.
[数据集] Julie Yixuan Zhu, Chao Zhang, Huichu Zhang, Shi Zhi, Victor OK Li, Jiawei Han, 和 Yu Zheng. p-因果关系:使用城市大数据识别空气污染物的空间时间因果路径。arXiv 预印本 arXiv:1610.07045, 2018.
参考论文:https://arxiv.org/pdf/2505.08343



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











