






张福军
内蒙古大学计算机科学学院,zfjimu@163.com
摘要
微调预训练语言模型(PLMs)已成为将PLMs应用于下游任务的主要范式。然而,即使在有限的微调下,PLMs仍然难以弥合从PLMs编码器获得的表示与PLMs解码器最佳输入之间的差异。本文通过学习校准PLMs在潜在空间中的表示来解决这一挑战。在提出的表示校准方法(RepCali)中,我们在编码器后的潜在空间中集成了一个特定的校准块,并使用校准后的输出作为解码器的输入。所提出的RepCali的优点包括其适用于所有具有编码器-解码器架构的PLMs、插件即用性以及易于实现。在8个任务(包括英文和中文数据集)上对25个基于PLM的模型进行的广泛实验表明,所提出的RepCali为PLMs(包括LLMs)提供了理想的增强,并显著提高了下游任务的性能。跨4个基准任务的对比实验表明,RepCali优于代表性的微调基线。
1 引言
预训练语言模型(PLMs)在捕捉文本数据的句法和语义信息方面表现出令人印象深刻的性能,使其在各种下游任务中极具价值(Devlin等,2019)。实际上,预训练数据通常是领域通用的,而下游任务数据则显著地因领域而异,预训练任务和下游任务的目标也大不相同。由于预训练任务和下游任务之间的领域差距和目标差距,当应用于特定的下游任务时,PLMs需要使用任务特定的数据进行训练,以增强其处理语言特征的能力。
如图1所示,在潜在空间表征分析中,我们观察到T5编码器在微调前的输出呈现出无序分布,而在微调后其分布结构显著紧凑化,但尚未达到最佳状态。这表明,尽管微调可以有效地提高下游任务的性能,但在有限数量的微调周期内,PLMs仍难以完全适应目标领域的特性(Ruder, 2021; Chen等, 2022)。本质上,当前的性能瓶颈源于目标领域潜在空间中模型编码器表示分布与解码器期望的最佳输入分布之间仍然存在不可忽视的跨域差异。
Meng等(2022)在PLM的嵌入潜在空间中学习和聚类,以提高模型生成的多样性和质量。Li等(2020)确认了学习潜在空间的重要性。基于此,我们认为在微调过程中通过可学习块直接调整PLMs编码器在潜在空间中的表示将更为有效。因此,
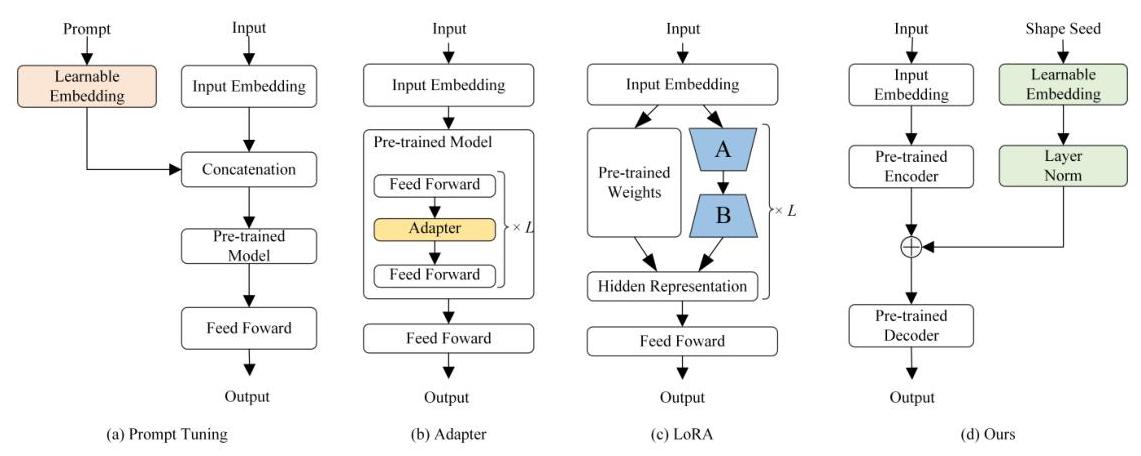
图2:各种微调方法的详细架构。
本文提出了RepCali,这是一种简单有效的表示校准方法,它在PLMs编码器后的潜在空间中集成了精心设计的校准块,并使用校准后的输出作为PLMs解码器的输入进行PLM微调。校准块仅涉及形状种子、可学习嵌入和层归一化。
值得注意的是,我们的表示校准方法不同于其他微调方法,例如提示微调、适配器和LoRA,如图2所示。提示微调通常包含可学习参数,并将学习到的提示嵌入附加到输入嵌入以引导预训练模型。适配器层是插入预训练模型层间的小型神经网络模块,其参数在微调期间更新。LoRA引入低秩矩阵以修改Transformer架构的自注意力机制,并仅更新这些低秩矩阵。与这些方法不同,我们的方法在PLM的编码器和解码器之间引入了一个专门的表示校准块,该块在校准后的编码器输出被送入解码器之前对其进行校准。因此,PLM的解码器接收到改进的输入并生成更好的结果。
在25个基于PLM的模型上进行的广泛实验涵盖了其他8个NLP下游任务,证明RepCali显著增强了PLMs(包括大型语言模型(LLMs)),为PLMs带来了实质性的改进。与4个代表性微调基线在3个基准任务上的对比实验表明,我们提出的微调方法RepCali优于这些基线。所提出的表示校准方法RepCali的优点包括其
对所有具有编码器-解码器架构的PLMs的普适适用性、其插件即用性质及其易于实现性,仅略微增加模型参数。我们的实验包括英文和中文数据集,结果均表明RepCali能有效推广到不同的语言。
2 相关工作
2.1 微调方法
近年来,适配器逐渐成为PLM微调的主流。Houlsby等人(2019)提出了一种适配器模块,为每个任务引入最少数量的可训练参数,使新任务的添加不会影响先前训练的任务。Rücklé等人(2020)提出了AdapterDrop,该方法在训练和推理过程中战略性地消除来自较低Transformer层的适配器,整合了这些不同方法的原则。Mahabadi等人(2021)展示了通过使用共享超网络生成模型内的适配器参数,条件于任务特定和层特定细节,从而在所有层和任务中学习适配器参数的可行性,优化了跨各种任务的微调过程。Luo等人(2023)提出了重新参数化的架构,通用目的适配模块也可以无缝集成到大多数巨型视觉模型中,从而在推理过程中实现零成本。LoRA(Hu等人,2022)是一种低秩适应方法,冻结预训练模型的权重并在Transformer架构的每一层注入可训练的秩分解矩阵,从而显著减少任务中可训练参数的数量。
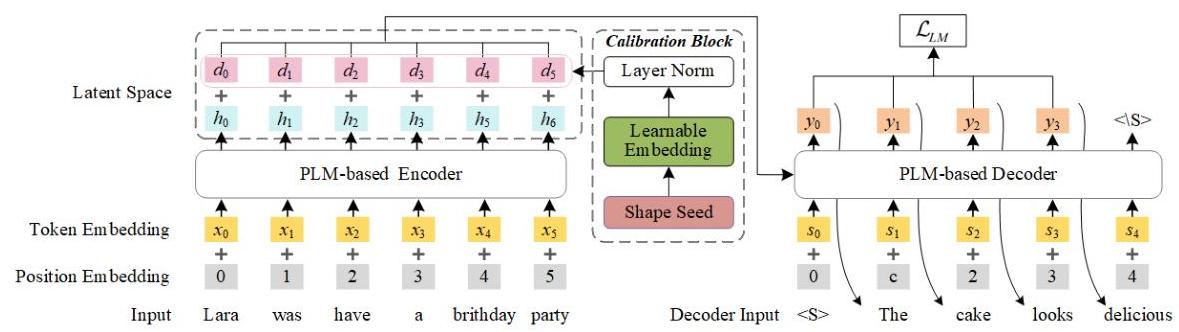
图3:我们表示校准方法的概述。
随着LLMs和视觉模型的发展和应用,研究人员意识到提示对模型性能有很大影响。提示微调(Lester等人,2021)仅在原始输入嵌入前附加并更新任务特定的可训练参数。Chen等人(2023)提出了一种基于迭代标签映射的视觉提示框架,该框架自动重新映射源标签为目标标签,并逐步提高视觉提示的目标任务准确性。Zaken等人(2022)提出了BitFit,一种稀疏微调方法,仅修改模型的偏置项(或其子集)。Delta微调(Ding等人,2022)仅微调模型的一小部分参数,而保持其余参数不变,极大地减少了计算和存储成本。Lian等人(2022)提出了一种新的参数高效微调方法,表明研究人员可以通过简单地缩放和移动预训练模型提取的深层特征来赶上完全微调的性能。
2.2 潜在空间
Meng等人(2022)提出了一种通用的句子潜在嵌入空间,首先在大规模文本语料库上进行预训练,然后针对各种语言生成和理解任务进行微调。Li等人(2020)确认了学习潜在空间的重要性。DISCODVT(Ji和Huang,2021)学习潜在变量序列,每个潜在代码抽象局部文本跨度为话语结构,指导模型生成具有更好长距离连贯性的长文本。还有几项研究(Liu等人,2021;Subramani等人,2022)将潜在结构学习纳入语言模型预训练。
3 方法论
为了提高PLMs在下游任务中的性能,关键在于最小化PLMs编码器获得的表示与模型解码器最佳输入之间的差异。为此,我们提出在潜在空间中校准PLMs的表示,如图3所示。表示校准块的输出直接加到基于PLM的编码器的输出上以校准解码器的输入。我们的表示校准块涉及形状种子、可学习嵌入和层归一化。具体细节如下。
为了校准编码器在潜在空间中的表示,我们引入了形状种子的概念,这是一个设计为符合输入维度的矩阵,有助于精确校准编码器的表示。我们表示校准块的输入是形状种子,这是一个大小为batchsize × \times × n n n的矩阵。这里, n n n等于标记嵌入的长度。我们将形状种子初始化为全1矩阵。然后,我们使用可学习嵌入层LearnEmb对形状种子进行编码以获得 d i d_{i} di,作为校准值。接下来,我们在潜在空间中将校准值 d i d_{i} di加到编码器输出 h i h_{i} hi上,得到校准输出 p i p_{i} pi。这个过程重新对齐了编码器的输出,使其在潜在空间中更具合理性,从而使PLM更适合下游任务。
给定输入 X X X,上述校准过程可以公式化为
{ h i } i = 1 n = Encoder ( X ) { d i } i = 1 n = LearnEmb ( Shape Seed ) { p i } i = 1 n = { h i + λ ∗ d i } i = 1 n y ^ = Decoder ( y < t , { p i } i = 1 n ) \begin{aligned} & \left\{h_{i}\right\}_{i=1}^{n}=\operatorname{Encoder}(X) \\ & \left\{d_{i}\right\}_{i=1}^{n}=\operatorname{LearnEmb}(\text { Shape Seed }) \\ & \left\{p_{i}\right\}_{i=1}^{n}=\left\{h_{i}+\lambda * d_{i}\right\}_{i=1}^{n} \\ & \quad \hat{y}=\operatorname{Decoder}\left(y_{<t},\left\{p_{i}\right\}_{i=1}^{n}\right) \end{aligned} {hi}i=1n=Encoder(X){di}i=1n=LearnEmb( Shape Seed ){pi}i=1n={hi+λ∗di}i=1ny^=Decoder(y<t,{pi}i=1n)
| 任务 & 数据集 | 额外 | 准确率 ( ↑ ) (\uparrow) (↑) | MCC ( ↑ ) \operatorname{MCC}(\uparrow) MCC(↑) | 平均值 ( ↑ ) (\uparrow) (↑) | ||
|---|---|---|---|---|---|---|
| SST2 | RET | MNLI | COLA | |||
| 提示微调 (Lester et al., 2021) | 0.03 % 0.03 \% 0.03% | 92.20 | 45.32 | 35.43 | 0.00 | 43.23 |
| 前缀微调 (Li and Liang, 2021) | 7.93 % 7.93 \% 7.93% | 92.66 | 72.66 | 82.21 | 50.95 | 74.62 |
| 适配器 (Houlsby et al., 2019) | 2.38 % 2.38 \% 2.38% | 93.35 | 78.42 | 83.90 | 44.66 | 75.08 |
| LoRA (Hu et al., 2022) | 0.38 % 0.38 \% 0.38% | 92.29 | 79.14 | 83.74 | 49.40 | 76.14 |
| BitFit ⊙ \odot ⊙ (Zaken et al., 2022) | 0.22 % 0.22 \% 0.22% | 93.20 | 75.30 | 84.10 | 53.20 \mathbf{5 3 . 2 0} 53.20 | 76.45 |
| RepCali | 0.35 % 0.35 \% 0.35% | 94.31 \mathbf{9 4 . 3 1} 94.31 | 80.04 \mathbf{8 0 . 0 4} 80.04 | 84.69 \mathbf{8 4 . 6 9} 84.69 | 51.15 | 77.55 \mathbf{7 7 . 5 5} 77.55 |
表1:SST2、RET和COLA的整体测试性能。我们在T5-BASE骨干上评估了所有这些微调方法。基线的结果来自Ding等人(2022)。
⊙
\odot
⊙表示结果不是来自原论文,而是由我们重现的。
其中
λ
\lambda
λ是一个控制校准程度的超参数。如果不使用我们的校准块,则基于PLM的原始模型的输出为
y ^ = Decoder ( y < t , { h i } i = 1 n ) \hat{y}=\operatorname{Decoder}\left(y_{<t},\left\{h_{i}\right\}_{i=1}^{n}\right) y^=Decoder(y<t,{hi}i=1n)
我们方法中的表示校准块非常简单且插件即用。只有可学习嵌入层带来模型参数数量的边际增加,这在第5.3节的表10中进行了分析。当我们将在下游任务中现有的基于PLM的模型中集成所提出的校准方法时,无需更改这些模型中使用的损失函数 L L M \mathcal{L}_{L M} LLM。
4 微调方法实验
4.1 任务和数据集
我们使用SST-2、RET、MNLI和CoLA数据集(Wang等人,2018)比较所提出的方法与三种微调方法,以突出其优势和改进。基线的结果来自Ding等人(2022)。我们在3个不同的随机种子上进行实验,报告的结果是这三次实验的平均值。
4.2 方法性能比较
我们的表示校准方法是一种新颖的微调方法。我们主要关注微调PLMs编码器的潜在表示;在NLU任务中,我们冻结了整个PLM解码器,以减少RepCali中的微调参数数量,同时验证RepCali的校准效果。
如表1所示,RepCali在所有四个任务上都取得了最佳结果。与LoRA、适配器和前缀微调相比,我们的方法在所有四个任务上都有超过 1 % 1 \% 1%的提升。RepCali仅向T5-base模型引入了 0.35 % 0.35 \% 0.35%的额外参数,增加量也少于上述基线。这证明了我们方法的简单性和高效性,只需少量参数即可带来巨大的提升。所提出的RepCali不仅适用于NLG任务,也适用于NLU任务。使用RepCali时,无需考虑在哪里添加到模型中,从而提高了微调的效率。
4.3 额外参数比较
如表2所示,我们量化了各种微调方法引入的额外参数。值得注意的是,我们的方法增加了极少数参数,强调了其在提升模型性能的同时不显著扩展复杂性的效率。
5 下游任务实验
5.1 下游任务和数据集
我们在8个下游任务上进行了全面实验:端到端响应生成、归纳常识推理 ( α \alpha α NLG)、面向任务的对话系统、知识图谱转文本、摘要生成、对话摘要生成、对话响应生成和句子排序。我们在总共25个不同的基于PLM的模型上集成了我们的表示校准方法,所有模型都基于
| 名称 | 方法 | 参数数 |
|---|---|---|
| 适配器 (Houlsby et al., 2019) | LayerNorm
(
X
+
H
(
X
)
)
→
(X+H(X)) \rightarrow
(X+H(X))→ LayerNorm
(
X
+
A
D
T
(
H
(
X
)
)
)
(X+A D T(H(X)))
(X+ADT(H(X))) A D T ( X ) = X + σ ( X W d h + d m ) W d m + d b , σ = A D T(X)=X+\sigma\left(\mathbf{X W}_{d_{h}+d_{m}}\right) \mathbf{W}_{d_{m}+d_{b}}, \sigma= ADT(X)=X+σ(XWdh+dm)Wdm+db,σ= 激活函数 | L × 2 × ( 2 d h d m ) ( L − n ) × 2 × ( 2 d h d m ) \begin{aligned} & L \times 2 \times\left(2 d_{h} d_{m}\right) \\ & (L-n) \times 2 \times\left(2 d_{h} d_{m}\right) \end{aligned} L×2×(2dhdm)(L−n)×2×(2dhdm) |
| 前缀微调 (Li and Liang, 2021) |
H
i
=
A
T
T
(
X
W
q
(
i
)
)
⋅
[
M
L
P
q
(
i
)
(
P
q
∗
)
:
X
W
q
(
i
)
)
⋅
[
M
L
P
v
(
i
)
(
P
v
∗
)
:
X
W
v
(
i
)
]
H_{i}=A T T\left(X W_{q}^{(i)}\right) \cdot\left[M L P_{q}^{(i)}\left(P_{q}^{*}\right): X W_{q}^{(i)}\right) \cdot\left[M L P_{v}^{(i)}\left(P_{v}^{*}\right): X W_{v}^{(i)}\right]
Hi=ATT(XWq(i))⋅[MLPq(i)(Pq∗):XWq(i))⋅[MLPv(i)(Pv∗):XWv(i)] ) M L P ( i ) ( X ) = σ ( X W d m + d m ) W d m + d b ( i ) M L P^{(i)}(X)=\sigma\left(\mathbf{X W}_{d_{m}+d_{m}}\right) \mathbf{W}_{d_{m}+d_{b}}^{(i)} MLP(i)(X)=σ(XWdm+dm)Wdm+db(i) P ′ = W n + d m \mathbf{P}^{\prime}=\mathbf{W}_{n+d_{m}} P′=Wn+dm | n × d m + d m ∗ + L × 2 × d h d m \begin{aligned} & n \times d_{m}+d_{m}^{*} \\ & +L \times 2 \times d_{h} d_{m} \end{aligned} n×dm+dm∗+L×2×dhdm |
| LoRA (Hu et al., 2022) | A D T ( X ) = X W d h + d m W d m + d b A D T(X)=\mathbf{X W}_{d_{h}+d_{m}} \mathbf{W}_{d_{m}+d_{b}} ADT(X)=XWdh+dmWdm+db | L × 2 × ( 2 d h d m ) L \times 2 \times\left(2 d_{h} d_{m}\right) L×2×(2dhdm) |
| 我们的方法 (RepCali) | 解码器(编码器
(
X
)
)
→
(X)) \rightarrow
(X))→ 解码器
(
\left(\right.
( 编码器
(
X
)
+
d
i
)
\left.(X)+d_{i}\right)
(X)+di),其中
d
i
=
RepCali
(
X
)
d_{i}=\operatorname{RepCali}(X)
di=RepCali(X) RepCali ( X ) = \operatorname{RepCali}(X)= RepCali(X)= 层归一化(可学习嵌入(形状种子)) | 2 × d h 2 \times d_{h} 2×dh |
表2:不同微调方法的比较。[:]: 是拼接操作; d h d_{h} dh 表示Transformer模型的隐藏维度; d m d_{m} dm 是降维投影和升维投影之间的中间维度,其中 d m d_{m} dm 远小于 d h d_{h} dh。前缀微调添加了一个 n n n个过去键/值向量的前缀。
| 端到端响应生成 | MultiWOZ | |
|---|---|---|
| 模型 | Inf/Suc ( ↑ \uparrow ↑ ) | B-4/Com ( ↑ \uparrow ↑ ) |
| MinTL (T5-small) (Lin et al., 2020) | 80.04 / 72.71 80.04 / 72.71 80.04/72.71 | 19.11 / 95.49 19.11 / 95.49 19.11/95.49 |
| MinTL (T5-small)+RepCali | 82.08 / 74.07 \mathbf{8 2 . 0 8 / 7 4 . 0 7} 82.08/74.07 | 19.58 / 97.66 \mathbf{1 9 . 5 8 / 9 7 . 6 6} 19.58/97.66 |
| MinTL (T5-base) (Lin et al., 2020) | 82.15 / 74.44 82.15 / 74.44 82.15/74.44 | 18.59 / 96.88 18.59 / 96.88 18.59/96.88 |
| MinTL (T5-base)+RepCali | 83.75 / 76.08 \mathbf{8 3 . 7 5 / 7 6 . 0 8} 83.75/76.08 | 19.75 / 99.68 \mathbf{1 9 . 7 5 / 9 9 . 6 8} 19.75/99.68 |
| MinTL (BART-large) (Lin et al., 2020) | 84.88 / 74.91 84.88 / 74.91 84.88/74.91 | 17.89 / 97.78 17.89 / 97.78 17.89/97.78 |
| MinTL (BART-large)+RepCali | 88.99 / 80.28 \mathbf{8 8 . 9 9 / 8 0 . 2 8} 88.99/80.28 | 19.35 / 103.90 \mathbf{1 9 . 3 5 / 1 0 3 . 9 0} 19.35/103.90 |
| MinTL (T5-large) (Lin et al., 2020) ◯ \bigcirc ◯ | 79.68 / 71.27 79.68 / 71.27 79.68/71.27 | 19.55 / 95.03 19.55 / 95.03 19.55/95.03 |
| MinTL (T5-large)+RepCali | 81.68 / 73.57 \mathbf{8 1 . 6 8 / 7 3 . 5 7} 81.68/73.57 | 19.61 / 97.24 \mathbf{1 9 . 6 1 / 9 7 . 2 4} 19.61/97.24 |
| MinTL (T5-3B) (Lin et al., 2020) ◯ \bigcirc ◯ | 78.48 / 66.87 78.48 / 66.87 78.48/66.87 | 14.65 / 87.33 14.65 / 87.33 14.65/87.33 |
| MinTL (T5-3B)+RepCali | 81.98 / 70.57 \mathbf{8 1 . 9 8 / 7 0 . 5 7} 81.98/70.57 | 15.87 / 92.15 \mathbf{1 5 . 8 7 / 9 2 . 1 5} 15.87/92.15 |
表3:MultiWOZ2上的端到端响应生成结果。
◯
\bigcirc
◯ 表示由我们重现的结果;其他结果来自原论文。
微调。为了公平比较,我们遵循原论文发布的其他训练参数。我们在3个不同的随机种子上进行实验,报告的结果是3次实验的平均值。由于页面限制,基准数据集的详细信息、实现细节和实验结果报告在附录A、附录B和附录C中。
5.2 实验结果分析
端到端响应生成:我们使用MultiWOZ数据集(Budzianowski等人,2018)对各种模型进行全面评估。在MinTL框架(Lin等人,2020)中,我们融入了我们的校准方法,涵盖BART-large(Lewis等人,2020)和各种尺寸的T5模型(small、base、large、3B)(Raffel等人,
α
\alpha
α NLG
| 模型 | SB-3/4 ( ↓ \downarrow ↓ ) | B-4/R-L ( ↑ \uparrow ↑ ) |
|---|---|---|
| BART-base (Lewis et al., 2020) | 56.32 / 52.44 56.32 / 52.44 56.32/52.44 | 13.53 / 38.42 13.53 / 38.42 13.53/38.42 |
| BART-base+RepCali | 48.13 / 49.24 \mathbf{4 8 . 1 3 / 4 9 . 2 4} 48.13/49.24 | 14.42 / 39.66 \mathbf{1 4 . 4 2 / 3 9 . 6 6} 14.42/39.66 |
| MoE_embed (Cho et al., 2019) | 29.02 / 24.19 29.02 / 24.19 29.02/24.19 | 14.31 / 38.91 14.31 / 38.91 14.31/38.91 |
| MoE_embed+RepCali | 29.01 / 23.92 \mathbf{2 9 . 0 1 / 2 3 . 9 2} 29.01/23.92 | 14.90 / 39.71 \mathbf{1 4 . 9 0 / 3 9 . 7 1} 14.90/39.71 |
| MoE_prompt (Shen et al., 2019) | 28.05 / 23.18 28.05 / 23.18 28.05/23.18 | 14.26 / 38.78 14.26 / 38.78 14.26/38.78 |
| MoE_prompt+RepCali | 27.93 / 22.02 \mathbf{2 7 . 9 3 / 2 2 . 0 2} 27.93/22.02 | 15.91 / 40.75 \mathbf{1 5 . 9 1 / 4 0 . 7 5} 15.91/40.75 |
| MoKGE (Yu et al., 2022) | 27.40 / 22.43 27.40 / 22.43 27.40/22.43 | 14.17 / 38.82 14.17 / 38.82 14.17/38.82 |
| MoKGE+RepCali | 24.67 / 19.07 \mathbf{2 4 . 6 7 / 1 9 . 0 7} 24.67/19.07 | 15.25 / 40.16 \mathbf{1 5 . 2 5 / 4 0 . 1 6} 15.25/40.16 |
表4:
α
\alpha
α NLG数据集上的多样性和质量评估。基线来自原论文。
2020)。按照Lin等人(2020),我们使用诸如Inform、Success、BLEU4 和 Combined
(
(
( Inform + Success
)
×
0.5
+
) \times 0.5+
)×0.5+ BLEU4) (Papineni等人,2002;Mehri等人,2019)等指标来评估模型。
如表3所示,每个基准模型在加入我们的表示校准块后,性能都得到了显著提升。特别是MinTL(BART-large),在Inform方面提升了
4.11
%
4.11 \%
4.11%,在Success方面提升了
5.37
%
5.37 \%
5.37%,在BLEU-4方面提升了
1.46
%
1.46 \%
1.46%,在Combined得分方面提升了
6.21
%
6.21 \%
6.21%。我们的方法显著增强了大型语言模型(LLMs),突显了其普遍性和有效性。我们观察到,在MinTL框架中,T5-3B的表现低于T5-base,可能是因为更大模型的过拟合(尤其是在小型数据集上)和超参数设置。
归纳常识推理 (
α
\alpha
α NLG):我们利用
A
R
T
\mathcal{A R} \mathcal{T}
ART基准数据集(Bhaga-
| 面向任务的对话系统 | CamRest | |
|---|---|---|
| 模型 | BLEU-4 ( † \dagger † ) | F1 ( † \dagger † ) |
| BART-base (Lewis et al., 2020) | 19.05 | 55.92 |
| BART-base+RepCali | 19.56 \mathbf{1 9 . 5 6} 19.56 | 56.40 \mathbf{5 6 . 4 0} 56.40 |
| T5-base (Raffel et al., 2020) | 18.73 | 56.31 |
| T5-base+RepCali | 19.04 \mathbf{1 9 . 0 4} 19.04 | 57.34 \mathbf{5 7 . 3 4} 57.34 |
| KB_BART (Andreas et al., 2022) | 20.24 | 56.70 |
| KB_BART+RepCali | 22.61 \mathbf{2 2 . 6 1} 22.61 | 60.52 \mathbf{6 0 . 5 2} 60.52 |
| KB_T5 (Andreas et al., 2022) | 21.11 | 59.67 |
| KB_T5+RepCali | 21.78 \mathbf{2 1 . 7 8} 21.78 | 61.78 \mathbf{6 1 . 7 8} 61.78 |
| KB_T5 (large) (Andreas et al., 2022) ◯ \bigcirc ◯ | 21.12 | 63.54 |
| KB_T5 (large)+RepCali | 21.72 \mathbf{2 1 . 7 2} 21.72 | 64.76 \mathbf{6 4 . 7 6} 64.76 |
表5:CamRest上的结果。 ◯ \bigcirc ◯ 表示由我们重现的结果;其他结果来自原论文。
| 知识图谱转文本 | WebNLG |
|---|---|
| 模型 | BLEU-4 / METEOR / R-L ( † \dagger † ) |
| BART-base (Lewis et al., 2020) | 64.55 / 46.51 / 75.13 64.55 / 46.51 / 75.13 64.55/46.51/75.13 |
| BART-base+RepCali | 64.76 / 46.72 / 75.38 \mathbf{6 4 . 7 6} / \mathbf{4 6 . 7 2} / \mathbf{7 5 . 3 8} 64.76/46.72/75.38 |
| T5-base (Raffel et al., 2020) | 64.42 / 46.58 / 74.77 64.42 / 46.58 / 74.77 64.42/46.58/74.77 |
| T5-base+RepCali | 64.90 / 46.83 / 75.14 \mathbf{6 4 . 9 0} / \mathbf{4 6 . 8 3} / \mathbf{7 5 . 1 4} 64.90/46.83/75.14 |
| JointGT (BART) (Ke et al., 2021) | 65.92 / 47.15 / 76.10 65.92 / 47.15 / 76.10 65.92/47.15/76.10 |
| JointGT (BART)+RepCali | 66.10 / 47.35 / 76.18 \mathbf{6 6 . 1 0} / \mathbf{4 7 . 3 5} / \mathbf{7 6 . 1 8} 66.10/47.35/76.18 |
| JointGT (T5) (Ke et al., 2021) | 66.14 / 47.25 / 75.90 66.14 / 47.25 / 75.90 66.14/47.25/75.90 |
| JointGT (T5)+RepCali | 66.72 / 47.46 / 76.46 \mathbf{6 6 . 7 2} / \mathbf{4 7 . 4 6} / \mathbf{7 6 . 4 6} 66.72/47.46/76.46 |
| GAP (BART) (Colas et al., 2022) | 66.20 / 46.77 / 76.36 \mathbf{6 6 . 2 0} / 46.77 / 76.36 66.20/46.77/76.36 |
| GAP (BART)+RepCali | 66.20 / 46.89 / 76.41 \mathbf{6 6 . 2 0} / \mathbf{4 6 . 8 9} / \mathbf{7 6 . 4 1} 66.20/46.89/76.41 |
表6:WebNLG上的知识图谱转文本结果。基线来自原论文。
vatula等人,2020),按照Yu等人(2022)的数据划分。我们在BART-base(Lewis等人,2020)、MoE-based方法(Cho等人,2019;Shen等人,2019)、MoKGE(Yu等人,2022)上集成了我们的RepCali块。按照Yu等人(2022),我们使用Self-BLEU3/4(Zhu等人,2018)作为多样性评估指标,使用BLEU-4(Papineni等人,2002)和ROUGE-L(Lin,2004)作为生成质量指标。
如表4所示,仅仅使用我们的方法,所有基线都有很大的改进。对于之前的SOTA模型MoKGE,分别在多样性指标Self-BLEU-3/4上提高了 2.73 % 2.73 \% 2.73%和 3.36 % 3.36 \% 3.36%,在生成质量指标BLEU-4和ROUGE-L上分别提高了 1.08 % 1.08 \% 1.08%和 1.34 % 1.34 \% 1.34%。这证明了RepCali有效地使编码器的输出更适合解码器。面向任务的对话系统:我们实
| 抽取式摘要生成 | XSum |
|---|---|
| 模型 | R-1 / R-2 / R-L ( † ) (\dagger) (†) |
| BART-large (Lewis et al., 2020) | 45.14 / 22.27 / 37.25 45.14 / 22.27 / 37.25 45.14/22.27/37.25 |
| BART-large+RepCali | 45.42 / 22.60 / 37.63 \mathbf{4 5 . 4 2} / \mathbf{2 2 . 6 0} / \mathbf{3 7 . 6 3} 45.42/22.60/37.63 |
| PEGASUS (Zhang et al., 2020) | 47.46 / 24.69 / 39.53 47.46 / 24.69 / 39.53 47.46/24.69/39.53 |
| PEGASUS+RepCali | 47.78 / 24.75 / 39.70 \mathbf{4 7 . 7 8} / \mathbf{2 4 . 7 5} / \mathbf{3 9 . 7 0} 47.78/24.75/39.70 |
| BRIO-Mul (Liu et al., 2022) | 49.07 / 25.29 / 49.40 49.07 / 25.29 / 49.40 49.07/25.29/49.40 |
| BRIO-Mul+RepCali | 49.18 / 25.50 / 49.49 \mathbf{4 9 . 1 8} / \mathbf{2 5 . 5 0} / \mathbf{4 9 . 4 9} 49.18/25.50/49.49 |
表7:XSum数据集上的抽取式摘要生成结果。
| 对话响应生成 | PersonaChat |
|---|---|
| 模型 | R-1 / R-2 / R-L ( † ) (\dagger) (†) |
| Blenderbot (Roller et al., 2021) | 17.02 / 2.73 / 14.52 17.02 / 2.73 / 14.52 17.02/2.73/14.52 |
| Blenderbot+RepCali | 18.53 / 3.21 / 15.66 \mathbf{1 8 . 5 3} / \mathbf{3 . 2 1} / \mathbf{1 5 . 6 6} 18.53/3.21/15.66 |
| Keyword-Control (Ji et al., 2022) | 17.31 / 3.02 / 14.81 17.31 / 3.02 / 14.81 17.31/3.02/14.81 |
| Keyword-Control+RepCali | 17.98 / 3.07 / 15.30 \mathbf{1 7 . 9 8} / \mathbf{3 . 0 7} / \mathbf{1 5 . 3 0} 17.98/3.07/15.30 |
| Focus-Vector (Ji et al., 2022) | 20.81 / 3.98 / 17.58 20.81 / 3.98 / 17.58 20.81/3.98/17.58 |
| Focus-Vector+RepCali | 21.28 / 4.19 / 17.96 \mathbf{2 1 . 2 8} / \mathbf{4 . 1 9} / \mathbf{1 7 . 9 6} 21.28/4.19/17.96 |
表8:PersonaChat数据集上的对话响应生成结果。基线来自原论文。
现了我们的RepCali块在BART-base、T5-base、KB_BART(Andreas等人,2022)和KB_T5(Andreas等人,2022)上的应用。按照Andreas等人(2022),我们使用CamRest数据集(Wen等人,2016),并采用BLEU-4和F1分数。
如表5所示,使用我们的表示校准方法后,所有四个基线模型都得到了显著改善。特别是KB_BART,在BLEU-4和F1分数上分别提高了
2.370
%
2.370 \%
2.370%和
3.818
%
3.818 \%
3.818%。
知识图谱转文本:我们在BART-base(Lewis等人,2020)、T5-base(Raffel等人,2020)、JointGT(BART)(Ke等人,2021)、JointGT(T5)(Ke等人,2021)和GAP(Colas等人,2022)上实现了我们的RepCali块。按照Ke等人(2021);Colas等人(2022),我们使用WebNLG(Shimorina和Gardent,2018)数据集,并采用BLEU-4、METEOR(Banerjee和Lavie,2005)和ROUGE-L作为评估指标。
如表6所示,在使用我们的方法后,所有五个基线模型都有显著的改进。与JointGT (T5)在三个指标上的表现相比,分别有
0.58
%
,
0.21
%
0.58 \%, 0.21 \%
0.58%,0.21%, 和
0.56
%
0.56 \%
0.56%的提升。Rep-Cali显著增强了模型相对于以往的工作。例如,与JointGT相比,GAP在BLEU-4和R-L上分别提高了
0.28
%
0.28 \%
0.28%和
0.26
%
0.26 \%
0.26%,但在METEOR上下降了
0.38
%
0.38 \%
0.38%。而JointGT在使用RepCali后,三个指标分别提高了
0.18
%
,
0.20
%
0.18 \%, 0.20 \%
0.18%,0.20%, 和
0.08
%
0.08 \%
0.08%。这表明RepCali是对模型的合理增强,在所有指标上均有提升。与以往的工作相比,RepCali通过增加少量参数带来了显著的改进。
抽取式摘要生成:我们使用XSum(Narayan等人,2018)数据集进行抽取式摘要生成任务。我们在BART-large(Lewis等人,2020)、PEGASUS(Zhang等人,2020)和BRIO(Liu等人,2022)上实现了我们的RepCali块。按照Liu等人(2022),我们采用ROUGE-1、ROUGE-2和ROUGE-L(Lin,2004)作为评估指标。
如表7所示,在使用我们的表示校准块后,所有三个基线模型都有显著的提升。对于Sota模型BRIO-Mul,三个指标分别提升了
0.11
%
,
0.21
%
0.11 \%, 0.21 \%
0.11%,0.21%和
0.09
%
0.09 \%
0.09%。尽管某些指标的提升较小,但与以往的工作相比,这种提升是显著的。
对话响应生成:我们在PersonaChat(Zhang等人,2018)数据集上进行了对话响应生成实验。我们在Blenderbot(Roller等人,2021)、Keyword-Control(Ji等人,2022)和Focus-Vector(Ji等人,2022)上采用了我们的表示校准块。按照Ji等人(2022),我们采用ROUGE-1、ROUGE-2和ROUGE-L作为评估指标。
如表8所示,所有基线模型都有很大的提升。相对于Blenderbot,三个指标分别提升了
1.51
%
,
0.48
%
1.51 \%, 0.48 \%
1.51%,0.48%和
1.14
%
1.14 \%
1.14%。这进一步证明了我们表示校准方法的泛化能力和有效性。
句子排序:我们在ROCStories数据集上进行了句子排序实验。我们在BART和RE-BART(Chowdhury等人,2021)上实现了我们的表示校准块。按照(Chowdhury等人,2021),我们采用准确率(ACC)、完全匹配率(PMR)和肯德尔相关系数
(
τ
)
(\tau)
(τ)作为评估指标。
如表9所示,所有基线模型都有很大的提升。相对于BART,在三个指标上分别提升了 1.96 % , 1.17 % 1.96 \%, 1.17 \% 1.96%,1.17%,和0.2。对于之前的
| 句子排序 | ROCStories |
|---|---|
| 模型 | ACC / PMR / τ ( ↑ ) \tau(\uparrow) τ(↑) |
| BART (Lewis et al., 2020) | 80.42 / 63.50 / 0.85 80.42 / 63.50 / 0.85 80.42/63.50/0.85 |
| BART+RepCali | 82.36 / 64.67 / 0.87 \mathbf{8 2 . 3 6 / 6 4 . 6 7 / 0 . 8 7} 82.36/64.67/0.87 |
| RE-BART (Chowdhury et al., 2021) | 90.78 / 81.88 / 0.94 90.78 / 81.88 / 0.94 90.78/81.88/0.94 |
| RE-BART+RepCali | 91.16 / 82.68 / 0.94 \mathbf{9 1 . 1 6 / 8 2 . 6 8 / 0 . 9 4} 91.16/82.68/0.94 |
表9:ROCStories上的句子排序结果。基线结果来自原论文。
| 模型 | 尺寸 | 模型 | 尺寸 |
|---|---|---|---|
| MinTL(T5-small) (Lin et al., 2020) | 102M | +RepCali | 102M |
| BART-base (Lewis et al., 2020) | 139M | +RepCali | 140M |
| MoE_embed (Cho et al., 2019) | 139M | +RepCali | 140M |
| MoE_prompt (Shen et al., 2019) | 139M | +RepCali | 140M |
| KB_BART (Andreas et al., 2022) | 140M | +RepCali | 140M |
| MoKGE (Shen et al., 2019) | 145M | +RepCali | 146M |
| JointGT(BART) (Ke et al., 2021) | 160M | +RepCali | 161M |
| T5-base (Raffel et al., 2020) | 220M | +RepCali | 221M |
| KB_T5 (Andreas et al., 2022) | 222M | +RepCali | 223M |
| JointGT(T5) (Ke et al., 2021) | 265M | +RepCali | 265M |
| MinTL(T5-base) (Lin et al., 2020) | 360M | +RepCali | 361M |
| Blenderbot (Roller et al., 2021) | 364M | +RepCali | 365M |
| Keyword-Control (Ji et al., 2022) | 364M | +RepCali | 365M |
| Focus-Vector (Ji et al., 2022) | 364M | +RepCali | 365M |
| BART-large (Lewis et al., 2020) | 400M | +RepCali | 407M |
| RE-BART (Chowdhury et al., 2021) | 400M | +RepCali | 407M |
| PEGASUS (Zhang et al., 2020) | 569M | +RepCali | 569M |
| BRIO-Mul (Liu et al., 2022) | 569M | +RepCali | 570M |
| MinTL(BART-large) (Lin et al., 2020) | 609M | +RepCali | 610M |
| T5-large (Raffel et al., 2020) | 770M | +RepCali | 770M |
| MinTL(T5-large) (Lin et al., 2020) | 1.17B | +RepCali | 1.17B |
| MinTL(T5-3B) (Lin et al., 2020) | 4.5B | +RepCali | 4.5B |
表10:添加我们的校准块前后的所有基线模型的尺寸。M:百万,B:十亿
Sota模型RE-BART,在准确率(ACC)和完全匹配率(PMR)上分别提高了 0.38 % 0.38 \% 0.38%和 0.8 % 0.8 \% 0.8%。与之前的工作相比,这种改进是显著的。
实验结果表明,我们的表示校准方法为PLMs(包括LLMs)提供了理想的增强,并显著提高了任务的性能。英文和中文数据集上的实验结果表明,RepCali可以有效地推广到不同的语言。这突显了我们表示校准方法的有效性和广泛的适用性。通过最小化从
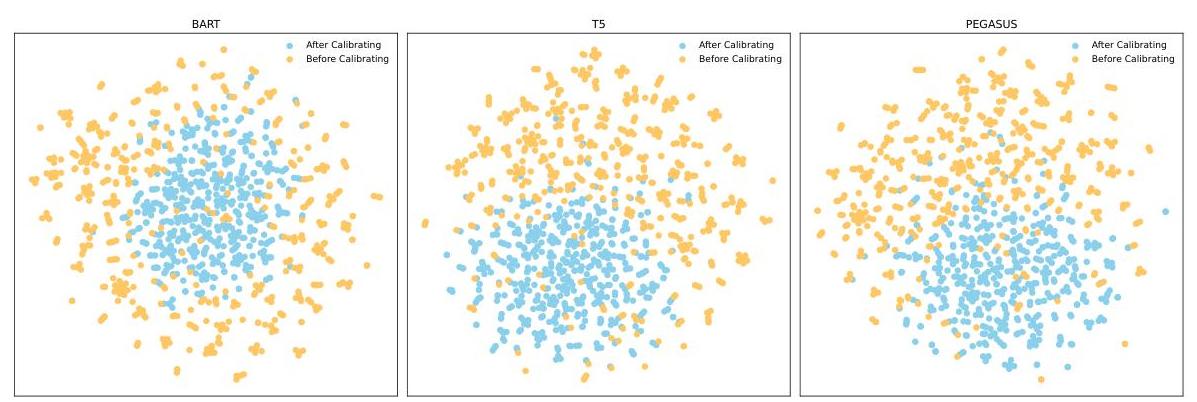
图4:我们选择了三种不同的PLMs,即BART、T5和PEGASUS进行可视化和潜在空间分析。蓝色点是在使用我们的校准方法RepCali微调后获得的隐藏表示,黄色点是在对PLMs微调后获得的隐藏表示。
PLMs编码器和模型解码器的最佳输入之间的差异在潜在空间中,我们的方法显著增强了PLMs在下游任务中的性能。值得注意的是,我们的方法既高效又轻量,仅涉及一个额外的可学习嵌入层。尽管其对模型参数数量的影响很小,但带来了显著的性能提升。总体而言,RepCali仅增加了0-0.8%的额外参数却带来了显著的性能提升。
5.3 模型尺寸
如表10所述,每个模型的参数增长根据其隐藏状态维度有所不同,例如,BART-base的隐藏状态维度为768,而BART-large的隐藏状态维度为1024。可以看出,最大的模型MinTL(T5-3B)拥有强大的4.5亿参数。这一观察结果突显了我们的表示校准方法与大型语言模型的兼容性,持续为LLMs提供有价值的增强。我们计算了参数数量,因为它们未在相应论文中提及。总体而言,我们的方法仅增加了0-0.8%的额外参数。
5.4 潜在空间的可视化分析
我们使用tSNE(Van der Maaten和Hinton,2008)将学习到的特征可视化到二维地图上。使用归纳常识推理( α N L G \alpha \mathrm{NLG} αNLG)的验证集提取潜在特征。我们选择了三种不同的PLMs,即BART、T5和PEGASUS进行可视化和潜在空间分析。如图4所示,与没有RepCali进行表示校准的PLMs相比,具有RepCali的PLMs学习到了更平滑的空间,具有更有组织的潜在模式,同时潜在表示更加紧凑,这就是为什么使用RepCali的增强模型可以获得更好的性能。这与Li等人(2020)的工作中的论点一致,该论点表明潜在空间上的平滑正则化有助于提高模型性能。
6 结论
在本文中,我们提出了一种通用的表示校准方法(RepCali),以最小化从PLMs编码器获得的表示与模型解码器最佳输入之间的差异。在微调阶段,我们将表示校准块集成到编码器后的潜在空间,并使用校准后的输出作为解码器输入。我们的表示校准方法适用于所有具有编码器-解码器架构的PLMs以及基于PLMs的模型。我们的表示校准方法既插件即用又易于实现。跨4个基准任务的对比实验表明,RepCali优于代表性的微调基线。在涵盖8个下游任务(包括英文和中文数据集)的25个基于PLM的模型上的广泛实验表明,所提出的RepCali为PLMs(包括LLMs)提供了理想的增强,并显著提高了下游任务的性能。
参考论文:https://arxiv.org/pdf/2505.08463



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











