






Ningxin Gui*, Qianghuai Jia
†
{ }^{\dagger}
†, Feijun Jiang
†
{ }^{\dagger}
†, Yuling Jiao*, dechun wang
†
{ }^{\dagger}
†, Jerry Zhijian Yang*
* 数学与统计学院
武汉大学
邮箱: gui-ningxin@whu.edu.cn
†
{ }^{\dagger}
† 阿里巴巴国际数字商务
摘要
我们介绍了CRPE(Code Reasoning Process Enhancer),这是一个创新的三阶段框架,用于数据合成和模型训练,以推动大型语言模型(LLMs)复杂代码推理能力的发展。基于现有的系统1模型,CRPE解决了增强LLMs在代码生成任务中的分析和逻辑处理能力的基本挑战。我们的框架提供了一种方法论严谨且可实施的方法,以培养语言模型的高级代码推理能力。通过实施CRPE,我们成功开发了增强版COT-Coder,该版本在代码生成任务中表现出显著改进。LiveCodeBench(20240701-20240901)上的评估结果显示,我们的COT-Coder-7B-StepDPO,源自Qwen2.5-Coder-7B-Base,在pass@1准确率为21.88的情况下,超越了所有相同或更大规模的模型。此外,基于Qwen2.5-Coder-32B-Base的COT-Coder-32B-StepDPO表现出优越性能,其pass@1准确率为35.08,优于GPT4O基准测试。总体而言,CRPE代表了一个全面的开源方法,涵盖了从指令数据获取到专家代码推理数据合成的完整流程,最终实现自主推理增强机制。
关键词—代码生成,推理增强
I. 引言
代码生成,也被称为程序合成,旨在自动生成符合既定编程规范的源代码,这些规范通常以自然语言表述。近年来,大型语言模型的编码能力有了显著提升 [1],[2],使它们能够有效地帮助用户解决实际的编码挑战。
然而,这些模型在面对复杂的编码问题时常产生次优结果。这主要是因为这些问题需要复杂的推理过程来得出解决方案,而这要求模型具备系统2思维能力。在OpenAI O1推出之前,大型语言模型在代码生成任务中主要表现出系统1能力。尽管存在诸如链式思维(COT)[3] 和树状思维(TOT)[4] 等方法,以促进模型逐步推理,但这些方法依赖于并受限于模型固有的推理能力。最近一系列推理模型在具有挑战性的数学和编码任务中展示了有希望的表现。
然而,训练此类推理模型的最佳方法尚不清楚。因此,研究如何增强这些模型的推理能力对于推进解决复杂代码生成领域至关重要。
当前的研究在提高大型语言模型的数学推理能力方面取得了重大进展 [5],[6]。许多旨在改进编码能力的努力集中在生成具有挑战性和高质量的代码问题和解决方案上,以便进行监督微调,而忽略了导致这些代码答案的推理过程 [7]-[9]。也有一些基于强化学习的方法 [10]-[12] 允许模型通过自我探索来提高其编码能力,这些方法主要强调生成正确的最终答案,而不是专注于代码推理过程。然而,代码生成背后的推理过程同样重要,可以增强模型的编码能力。为了解决这一挑战,我们提出了一种名为代码推理过程增强(CRPE)的新方法,可以有效提高LLMs的代码推理能力。这种方法旨在弥补与O 1的差距,并通过逐步思考过程带来高质量代码解决方案的改进。
在我们的方法中,考虑到高质量和高难度数据的稀缺性,我们首先建立了一个代码指令生成管道,包括收集和过滤开源数据以及基于LLM的指令合成。最终,这条管道使我们能够创建大量高质量和具有挑战性的代码问题。接下来,考虑到缺乏高质量的代码推理数据,我们设计了一个多代理框架,利用强大的系统1模型合成高质量的代码推理数据。然后将这些数据用于SPT,使LLMs学习专家的代码推理思路。最后,考虑到合成专家代码推理数据的高成本,我们开发了一种基于树搜索的自我探索和增强方法。这使得代码推理模型能够探索正确和错误的推理步骤,通过Step-DPO实现自我改进。
总结来说,CRPE采用了三阶段的数据合成和训练方法:
- 我们设计了一种简单而有效的数据合成方法
第二步:COT 解决方案生成

第三步:自我探索&自我改进
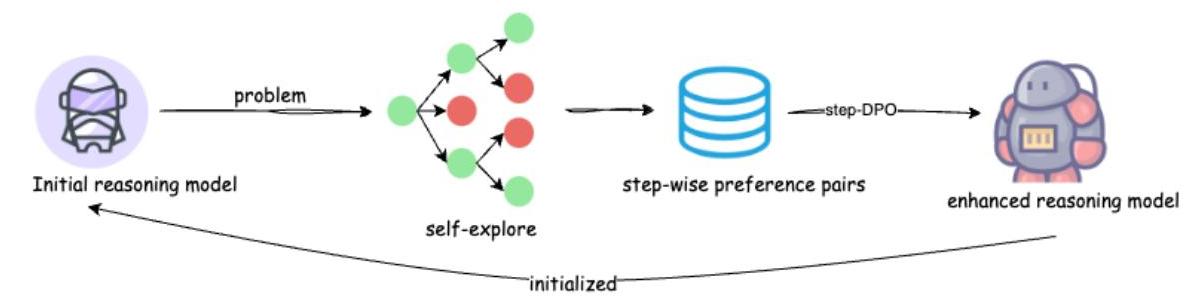
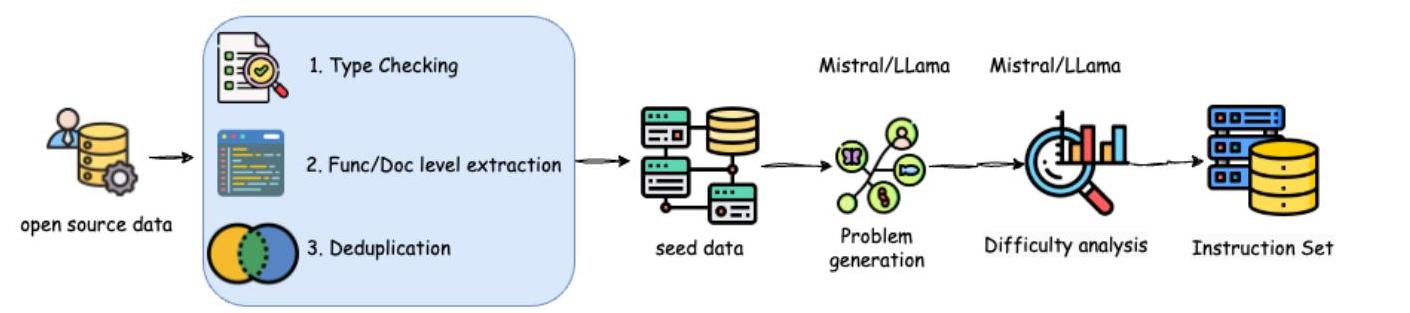
图1. CRPE的概述,包含三个步骤:(i) 合成大规模代码问题 (ii) 合成高质量代码推理数据用于监督微调 (iii) 提示从第二步衍生出的代码推理模型采样推理路径并实现自我改进。
生成竞赛级别的编程问题。
2) 我们开发了一个复杂的多代理框架,用于合成高质量的链式思维(CoT)数据。这些数据作为冷启动指令集,引导模型的基本认知过程和输出结构。
3) 我们利用第二阶段生成的数据训练推理代码模型。我们使用优化的树搜索算法采样新的推理过程数据。值得注意的是,这种树搜索过程的一个副产品是生成了大量的分步偏好对。这些对随后被用来通过分步直接偏好优化(step-DPO)进一步精炼模型。这个阶段可以迭代执行,允许持续精炼和扩展模型的推理能力。
LiveCodeBench上的实验结果表明,我们的方法通过提高其代码推理能力,有效增强了LLM的代码生成能力。
我们的贡献如下:
- 我们提出了CRPE方法,一种三阶段数据合成和训练方法,有效增强了模型的代码推理能力。
-
- 我们提出了一个代码指令数据的合成管道,并构建了一个大规模、高质量的代码问题数据集。
-
- 我们设计了一个多代理框架,并构建了一个高质量的代码-COT SFT数据集。
-
- 我们设计了一种新颖的合成方法,用于收集分步代码-COT偏好数据以进行step-DPO。
-
- 实验表明,CRPE可以有效增强大型语言模型的代码生成能力。
II. 相关工作
CodeLLM. LLMs在经过大量代码数据集训练后,在代码生成任务中表现出令人印象深刻的性能。[13]-[15] 由于高质量数据难以获取,合成数据成为增强模型代码能力的重要途径。这种方法的关键在于利用强大的基础模型生成高质量的指令数据和相应的代码解决方案。此过程涉及定义某些指令筛选标准,并利用编译器确保生成代码的正确性。合成数据可用于增强其他较弱模型的代码能力或实现自我改进。[16],[17]Llama3和StarCoder2通过构建从代码数据库开始的完整数据合成管道来合成困难和高质量的代码数据。[7],[9]EvolInstruct和OSS-instruct设计特殊提示以改进指令数据。最后,合成的代码数据以问答对的形式用于SFT。一些其他工作旨在通过强化学习增强LLM的代码能力。由于代码任务可以通过编译器获得执行信息,因此可以收集或生成测试用例来执行,并将执行结果用作奖励来训练策略模型 [11],[12],[18],[19]。[10]StepCoder分解代码生成过程并逐步完成答案,降低了模型探索正确解决方案的难度。[20] CodeDPO通过偏好学习优化解决方案的正确性和效率。但这些工作只教LLM正确答案,而不是如何推理得出这些答案。
增强LLM的代码推理能力。最近,LLM的推理能力得到了进一步增强。值得注意的工作包括OpenAI O1 [21],QwQ [22],DeepSeek-R1-Lite。这些推理LLM在复杂的数学推理和代码生成任务中表现出色,但如何实现这样的编码推理模型尚不清楚。一些工作 [23],[24] 通过训练过程奖励模型(PRM)和强化学习(RL)实现代码推理模型。这些方法需要训练多个模型,增加了训练过程的复杂性。我们的工作借助强大的系统1 LLM提供了一种新方法来增强LLM的代码推理能力。
III. 方法论
在本节中,我们将详细介绍我们的CRPE,以增强LLM的代码推理能力。我们首先在子节3.1中介绍一些关于后续训练的背景知识。然后,在子节3.2中,我们解释用于收集和生成将在后期训练中使用的代码问题的方法。在子节3.3中,我们介绍了设计用于生成Code-COT SFT数据的多代理框架,这使得模型能够采用代码推理范式并加强其代码推理能力。最后,在子节3.4中,我们说明了一条生成推理数据以实现自我改进的管道。
A. 基础知识
大型语言模型的后续训练通常涉及两个步骤:监督微调(SFT)和基于人类反馈的强化学习(RLHF)。SFT通常在问答(QA)对上进行。
RLHF包括两个阶段:训练奖励模型和训练策略模型。整个过程相当复杂。[25]提出了DPO,通过使用偏好数据直接训练策略模型简化了RLHF的训练过程。
为了进一步增强模型的推理能力,在训练过程中更关注每个推理步骤的细节至关重要。对于难思考的问题 x x x,答案 y y y可能还包括所有的推理步骤。因此, y y y可以分解为一系列推理步骤 s 1 , … , s n s_{1}, \ldots, s_{n} s1,…,sn,其中 s i s_{i} si是第 i i i个推理步骤。为了实现更细粒度的偏好学习,[26]提出了Step-DPO,它使用分步偏好数据对进行训练。具体来说,Step-DPO的目标是在给定问题和部分正确推理步骤的情况下,最大化下一个正确推理步骤的概率,同时最小化下一个错误推理步骤的概率。
B. 代码问题数据准备
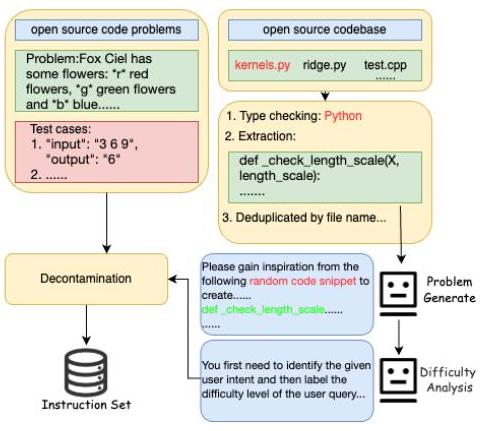
图2. 代码问题管道。
考虑到大多数开源代码数据可能已经在LLM的预训练中使用过,相关的问题可能不需要复杂的推理就能得出正确答案。因此,对这些问题进行进一步训练并不能有效增强模型的代码推理能力。因此,除了收集开源代码指令外,我们还通过数据合成构建更具挑战性的代码指令。
- 开源数据收集:我们收集了一些开源代码问题。这些数据主要由来自Codeforces或LeetCode的困难编程问题组成,以及相应的测试用例和可能的正确答案。测试用例用于验证LLM生成代码的正确性。当模型无法生成正确代码时,可能的正确答案可以帮助模型分析编码问题并进行修正。由于获取高质量数据的难度,我们最终收集了几千条代码指令及其各自的测试用例和可能的正确代码答案。
- 代码问题合成:为了增强代码指令的多样性和复杂性,我们还参考了OSS-Instruct [9] 和Evol-Instruct [7] 的方法。我们从stackv2 [17] 的种子数据中提取代码片段,并按文件名和函数名进行去重。提取的代码片段用于提示LLMs(如Llama或Mistral Large)生成新的代码指令,并利用Evol-Instruct优化这些代码指令。最后,我们通过LLMs过滤合成的指令。主要过滤规则包括:(1) 指令是否有明确意图,即是否需要编写一段代码来实现特定目标;(2) 指令是否具有挑战性,促使LLMs判断问题是否困难并需要推理才能得出答案;(3) 问题是否自包含,即是否仅使用Python的标准库就可以解决以避免因环境依赖而导致的执行错误。最终,我们生成了200万条代码指令数据,其中只有一部分用于后续训练。
- 去污染:为了确保我们的模型不会因测试集泄漏而产生膨胀结果,我们对所有获得的代码问题进行了去污染。具体方法类似于Qwen2.5-Coder [13] 中使用的方法,即删除任何与测试数据有10-gram重叠的训练集数据。
C. 基于多代理框架的Code-COT Maker
Code-COT Maker由三个代理(思考代理、反思代理和执行代理)组成,它们在一个工作流中运行。思考代理接收编码问题并逐步推理以得出最终答案。反思代理的任务是分析思考代理的推理步骤是否正确,并决定下一步是让思考代理继续推理还是输出代码答案。如果反思代理决定输出代码答案,则执行代理将使用编译器和LLM-as-Critic来确定代码答案是否正确。如果代码答案正确,过程结束;如果代码答案错误,则执行代理将执行结果传递给反思代理,反思代理将结合当前答案分析编码错误并提示思考代理生成新答案。将预先设置最大执行反馈尝试次数阈值,以防止整个工作流变得非终止。最终,执行代理认为正确的推理路径将被保留用于训练。
- 思考代理:思考代理由LLMs驱动。它的任务是逐步推理生成最终代码答案,并纠正错误的代码答案。我们设计了特殊的系统提示,鼓励思考代理在提供答案之前进行多步推理,不限制推理步骤的数量或每一步的具体内容;这些由编码问题和模型本身决定。如果思考代理提供的最终答案错误,它将从反思代理收到代码错误分析报告,并根据该报告优化代码,直到通过执行代理的检查或达到允许的最大检查次数。
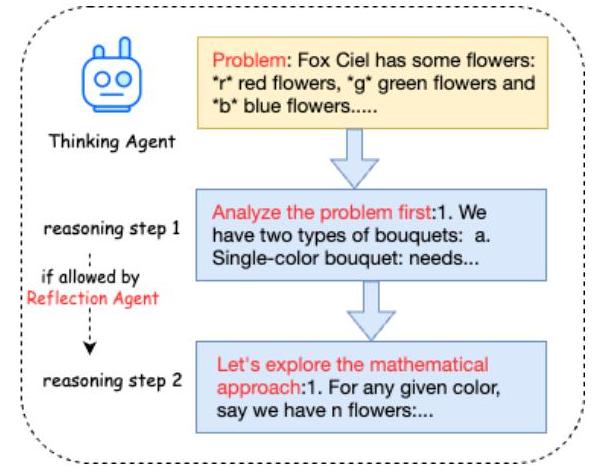
图3. 思考代理说明。
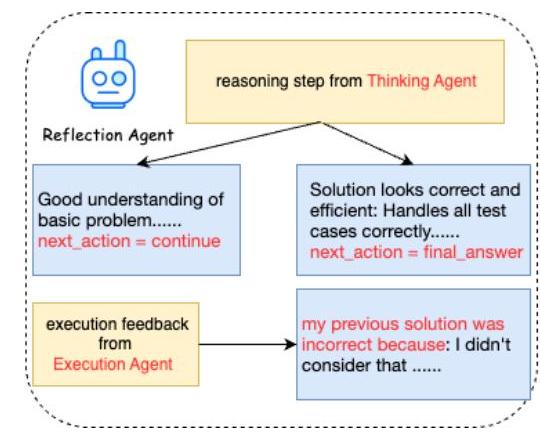
图4. 反思代理说明。
2) 反思代理:反思代理也由LLMs驱动。它需要分析思考代理提供的每一步推理内容并确定其是否正确,从而决定是否允许思考代理继续推理或将输出交给执行代理进行评估。当执行代理确定生成的答案错误时,反思代理将结合执行代理的执行结果与思考代理的代码答案分析编码错误的原因。这种分析将总结成代码错误分析报告,发送回思考代理以重新生成答案。如果经过几次执行代理的检查后,代码仍然含有错误且我们的数据包含正确代码答案,则会向反思代理提供正确答案以提供更准确的反思。然而,反思代理不会直接提供正确答案;而是基于正确答案分析当前答案错误的原因。
3) 执行代理:执行代理的任务是验证思考代理生成的代码是否正确。它由三个组件组成:编译器、测试生成器和结果检查器。如果当前
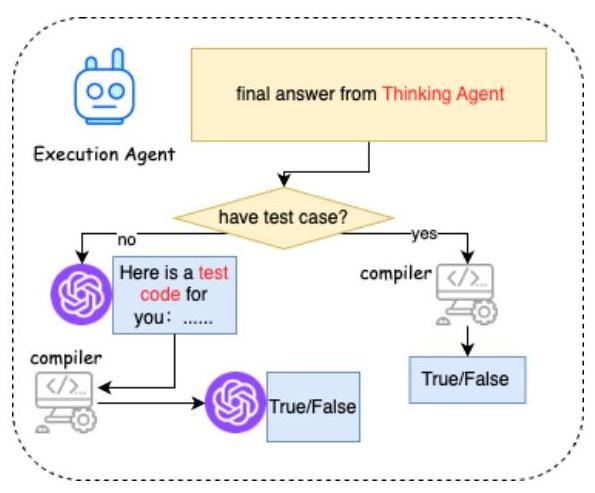
图5. 执行代理说明。
编码问题包含可执行的测试用例,执行代理将直接执行代码和测试用例,并提供结果是否正确或不正确的信号。如果执行结果不正确,它将传递具体的错误信息给反思代理。如果编码问题不带测试用例,测试生成器将基于编码问题和代码答案创建测试用例,并将其组织成可执行格式。生成的测试用例然后使用编译器执行,执行结果传递给结果检查器以确定代码的正确性。测试生成器和结果检查器均由LLMs驱动。
D. 通过自我改进增强推理能力
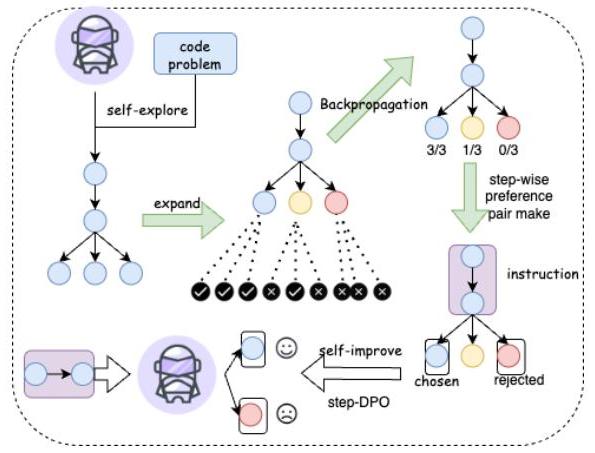
图6. 自我探索&自我改进。
虽然使用强大的系统1模型合成的代码推理数据训练模型可以增强模型的代码推理能力,但生成这样的合成数据非常昂贵,并且最终会受到系统1模型能力的限制。因此,我们也探索了Code-COT模型的自我改进。我们提出了一种改进的树搜索算法来收集分步偏好数据。使用收集的分步偏好数据,我们通过stepDPO优化模型的代码推理能力。
接下来,我们介绍用于合成单步偏好数据的改进树搜索算法。然而,检查推理路径中的错误步骤颇具挑战性,因为我们只能根据最终答案节点的执行结果确定路径是否错误,难以确定哪个具体步骤存在问题。基于此分析,我们设计了一种改进的树搜索以协助生成单步偏好数据。
我们的树搜索算法包括四个迭代步骤:选择、扩展、模拟和反向传播。类似于[27]中使用的方法,我们将扩展和模拟步骤结合起来。选择一个节点后,沿该节点生成一条完整路径,并通过代码执行评估生成路径的正确性。
如果一个节点通向正确答案节点,则将其分类为“接受”节点。相反,如果一个节点在采样超过’max_path_num’路径后仍未能产生正确答案,则将其分类为“拒绝”节点,表示该节点错误或从该节点生成正确答案困难。我们使用超参数’max_path_num’限制代码树的宽度,使用’max_depth_num’限制代码树的深度。
树搜索的具体细节如下:
选择:我们从根节点开始进行层次遍历。如果当前层的节点已完全探索,即从这些节点出发的路径数量达到了’max_path_num’,我们将从“接受”的子节点中选择节点,前提是生成的路径并非全部正确,直到到达答案节点或探索深度达到’max_depth_num’。
扩展:从选定的节点生成剩余路径并进行多次采样,直到采样路径数量达到’max_path_num’。每个路径中的答案代码被执行以进行验证。然后我们将最终答案全部错误的节点标记为“拒绝”节点;否则,将其分类为“接受”节点。
反向传播:保留从选定节点生成的所有路径,并更新从选定节点出发的所有节点的路径数量和正确路径数量。
对于最终生成的代码推理树中的每个“接受”节点,我们选择“接受”子节点和“拒绝”子节点,或准确性率差异显著的“接受”子节点,以构建偏好数据对。对于每个节点,我们选择两个子节点形成一个偏好对,以进行进一步的step-DPO。
IV. 实验
在本节中,我们首先在第4.1节介绍实验设置。然后,在第4.2节中展示主要结果。在第4.3节中,我们分析代码推理数据的有效性并评估我们的COT-Coder在其他基准上的表现。
A. 实验设置
代码问题准备 在数据合成阶段,我们使用Llama-3-70B-Instruct生成问题并使用Mistral-large进行难度分析。在数据去污染过程中,我们将我们的代码问题逐一与LiveCodeBench中的所有代码问题进行比较并移除相似数据。使用我们的代码问题管道,我们最终收集了4,749个开源代码问题并从合成代码问题数据集中提取了6 k个代码问题。这些代码问题用于代码推理过程生成和后续训练。
Code-COT数据生成 我们使用上述获得的代码问题数据,并使用Claude-3.5-sonnet作为Code-COT Maker中的三个代理,利用强大的系统1模型合成高质量的代码推理数据。在分析思考代理和反思代理的输出时,我们发现反思代理无法对思考代理的小推理步骤提供有效的反思,通常回应“现在的推理步骤是正确的,请继续推理。” 考虑到这些中间反思无助于推理并浪费令牌,我们消除了这些中间反思过程,仅保留反思代理在收到执行代理反馈后的反思。我们认为这种类型的反思可以帮助思考代理进行有效的推理。在去除无效的中间反思过程后,我们使用 < < < step > > > 连接相邻的推理步骤,从而划分每个小推理步骤。思考代理的推理过程位于 <thinking > > > 和 < < < /thinking > > > 之间,而反思代理的反思过程则被封闭在 < < < reflection > > > 和 < < < /reflection $> 之间。整个代码推理链被封装在 < < < ChainOfThought > > > 和 < / </ </ ChainOfThought > > > 之间,最终代码答案随后提供。最终,我们合成了Code-COT数据集,其中包含2,810个高质量的代码推理过程数据条目,用于SFT以获得Cot-Coder模型。
SFT详细信息 我们使用的基线模型是Qwen2.5-Coder-7B-Base和Qwen2.5-Coder-32B-Base。我们使用Code-COT数据集对基线模型进行监督微调,获得SFT模型:COT-Coder-7B-SFT和COT-Coder-32B-SFT。我们训练模型3个周期。全局批次大小设置为256 ,学习率设置为
5
e
−
6
5 \mathrm{e}-6
5e−6. 使用AdamW优化器和余弦衰减学习率调度器。Weight_decay 设置为
0.1.
β
1
0.1 . \beta_{1}
0.1.β1 设置为
0.9.
β
2
0.9 . \beta_{2}
0.9.β2 设置为0.95 。Warmup_steps 设置为30 。使用DeepSpeed ZeRO2减少GPU内存使用。
自我探索&自我改进 我们使用COT-Coder模型进行树搜索采样,生成大量推理步骤,每个推理步骤被视为一个节点。每个节点根据从中得出的正确答案数量进行评分。为了确保探索高效且有效,我们配置了树搜索的采样参数。具体来说,max_path_num 设置为5,max_depth_num 设置为64 。此外,我们对每个单独路径设置了最多25,000个令牌的限制,截断任何超出此长度的路径。任何被截断的路径被视为错误答案。由于存在没有单元测试来检查正确性的代码问题,我们使用Qwen2.5-7B-Instruct结合编译器生成测试代码并针对COT-Coder-7B-SFT进行正确性检查。对于COT-Coder-32B-SFT,我们使用Qwen2.5-32B-Instruct。然后我们使用采样数据进行step-DPO。对于每个节点,我们将通向该节点的推理过程作为指令,并选择得分差异最大的两个子节点形成偏好对。
对于step-DPO,我们训练模型3个周期。学习率设置为 5 e − 6 5 \mathrm{e}-6 5e−6。全局批次大小设置为256 。超参数 β \beta β 设置为0.1 。我们使用AdamW优化器和余弦学习率调度器,warmup_ratio 设置为0.2 。我们在所选序列上添加一个额外的NLL损失项,缩放系数为0.2,类似于Llama3的训练方法。使用DeepSpeed ZeRO3与CPU卸载。
为了评估,我们使用公开可用的LiveCodeBench。LiveCodeBench是一个具有挑战性的基准,包含106个编码任务,收集自2024年7月1日至2024年9月1日,旨在评估LLMs的代码生成能力。我们遵循推荐的设置,对每个问题采样10个解法,温度为0.2,并估计Pass@1结果。
我们比较的基线是当前强大的系统1模型。除我们的模型外的所有结果均参考官方排行榜。
B. 主要结果
表1
LiveCodeBench的主要结果
| 模型 | 总体 | 简单 | 中等 | 困难 |
|---|---|---|---|---|
| Claude-3.5-Sonnet-20241022 | 35.4 | 91.4 | 26.8 | 4.4 |
| GPT-4O-2024-05-13 | 33.6 | 83.1 | 29.7 | 3.3 |
| Gemini-Flash-2.0-Exp | 30 | 78.3 | 19.4 | 5.8 |
| LLama3.3-70b-Instruct | 26.88 | 75.17 | 13.52 | 4.88 |
| Deepseek-Coder-33B-Instruct | 19.62 | 57.24 | 10.88 | 1.16 |
| Qwen2.5-Coder-32B-Instruct | 29.71 | 74.48 | 25.88 | 2.55 |
| Deepseek-Coder-6.7B-Instruct | 13.58 | 37.58 | 10.29 | 0 |
| Qwen2.5-Coder-7B-Instruct | 15.94 | 50.00 | 6.76 | 0.23 |
| COT-Coder-7B-SFT(ours) | 20.18 | 54.48 | 15.29 | 0.93 |
| COT-Coder-7B-StepDPO(ours) | 21.88 | 63.79 | 12.05 | 1.39 |
| COT-Coder-32B-SFT(ours) | 33.49 | 81.72 | 29.11 | 4.41 |
| COT-Coder-32B-StepDPO(ours) | 35.09 | 86.20 | 28.23 | 6.04 |
表I展示了各种模型的全面比较,涵盖开源和闭源模型。在LiveCodeBench上,我们的CRPE-7B模型得分为21,超过了Qwen2.5-Coder-7B-Instruct和Deepseek-Coder-6.7B-Instruct。我们的CRPE-32B模型得分为34.22 ,与主流模型如GPT-4o和Claude-3.5-Sonnet相当。结果表明,我们的方法通过提高其代码推理能力有效增强了LLM的代码生成能力。
表II
COT对比直接法
| 模型 | 总体 | 简单 | 中等 | 困难 |
|---|---|---|---|---|
| COT-Coder-7B-SFT(部分数据) | 19.15 | 55.51 | 11.76 | 0.46 |
| Coder-7B-SFT-2 | 16.60 | 46.55 | 11.76 | 0.23 |
| Coder-7B-SFT-1 | 14.71 | 45.17 | 7.35 | 0.0 |
- cot 数据真的有用吗?: 在这一节中,我们旨在验证将推理过程数据纳入SFT数据可以增强模型的代码生成能力。
对于相同的编码问题,我们使用三种不同风格的答案作为SFT数据。这三种不同风格的答案如下:程序员书写的正确答案,LLM生成的无推理过程的正确答案,以及LLM生成的带推理过程的正确答案。我们的编码问题和带推理过程的答案提取自我们的Cot-Code-SFT数据集。然后我们去除中间的推理过程步骤,仅保留最终答案以形成无推理过程的正确答案。最后,我们提取程序员书写的正确答案,这些答案已在数据收集过程中获得。为了确保用于训练的编码问题相同,删除了一些不包含程序员书写的正确答案的编码问题。程序员书写的代码和LLM生成的代码之间的区别在于,程序员书写的答案可能缺乏注释且更加简洁,而LLM生成的代码包含逐行解释,使其更容易理解且更符合LLM典型的输出风格。
我们使用这三种不同风格的数据在相同的训练参数设置下基于Qwen2.5-coder-7B-base模型进行SFT,得到以下模型:Coder-7B-SFT-1(基于程序员书写的正确答案),Coder-7B-SFT-2(基于LLM生成的无推理过程的正确答案),和COT-Coder-7B-SFT(基于LLM生成的带推理过程的正确答案)。
训练详情。我们训练模型3个周期。全局批次大小设置为256 ,学习率设置为 5 e − 5 \mathrm{e}- 5e− 6。我们使用AdamW优化器和余弦衰减学习率调度器,将热身步骤设置为30。使用DeepSpeed ZeRO2减少GPU内存使用。
然后我们在LiveCodeBench上评估这三个模型。我们的实验结果表明,基于LLM生成的答案训练的模型(16.60)比基于程序员书写的正确答案训练的模型(14.71)表现更好。这也与一些关于合成数据的工作案例一致,这些案例表明使用LLM重写收集的答案可以提高性能。COT-Coder-7B-SFT和Coder-7B-SFT-2的结果显示,添加推理过程步骤进一步增强了模型的代码生成能力(
16.60
→
16.60 \rightarrow
16.60→ 19.15)。因此,除了使用LLM重写答案外,合成高质量的推理步骤也非常有价值。
2) 在HumanEval和MBPP上的表现:在这一节中,我们分析了我们的COT-Coder-7B-SFT在HumanEval和MBPP上的表现。
Humaneval和MBPP也是用于评估LLMs代码生成能力的基准。然而,与需要为代码问题生成完整解决方案的LiveCodeBench不同,HumanEval和MBPP主要关注函数级别的生成,特别是生成单独的函数。此外,要生成的函数名称已经在代码问题中指定。在LiveCodeBench中,代码问题的描述更为详细,明确规定了输入和输出的表示以及实现要求。相比之下,Humaneval和MBPP中代码问题的描述较为简明。这两个基准中的代码问题对我们来说是分布外的。这里的测试使用了EvalPlus [28]中的代码。
我们在测试中使用贪婪采样。生成完成后,我们提取最后一个生成的代码片段进行评估。我们的COT-Coder-7B-SFT在Hu manEval上得分为73.2/67.7,在MBPP上得分为72.5/61.4。
在HumanEval的结果中,COT-Coder-7B-SFT生成了44个错误答案。其中,两个答案由于函数名称错误而失败。具体来说,预期的函数名称是special factorial和fibfib,但生成的名称是brazilian factorial和fibfib_iterative。如果我们修复函数名称,COT-Coder在HumanEval上的得分提高到74.4/68.9。剩余的问题主要源于生成代码中的错误。剩余的失败案例主要由于COT-Coder生成的代码中的问题。HumanEval中一些描述简单的代码问题需要结合示例测试用例来理解,这与我们的SFT代码指令不同。
在MBPP的结果中,COT-Coder-7B-SFT生成了104个错误答案,其中32个答案无法正确提取函数代码。在这32个答案中,30个答案的函数名称错误,2个答案陷入了思考和反思的循环,导致生成的文本超过了max_tokens限制。我们分析了这30个错误的函数名称,发现原始函数名称不符合命名约定,导致模型在生成答案时修改了函数名称。例如,原始函数名称是check_Consecutive,模型将其修改为check_consecutive。尽管修改后的函数名称更符合命名约定且代码仍然正确,但这最终导致测试失败。修正这30个错误的函数名称后,COT-Coder-7B-SFT在MBPP上的得分提高到78.6/66.1。
V. 结论
在本文中,我们介绍了CRPE,这是一种通过显式增强代码推理能力来提升LLMs代码生成能力的方法。简而言之,这是一种三阶段的数据合成和训练方法,利用现有的强大系统1模型增强代码推理模型的代码推理能力,最终实现代码推理模型的自我改进。我们还生成了一个高质量的代码问题数据集和一个高质量的代码推理过程数据集。LiveCodeBench上的实验结果证明了CRPE在提升LLMs代码生成能力方面的有效性。未来的工作将重点放在提高基础模型自我改进的效率和优化模型推理过程中的token长度。
VI. 局限性
CRPE通过强化代码推理能力提升了LLMs的代码生成能力,但也面临新的挑战。
首先,这种方法依赖于高质量的代码问题。尽管目前有关于合成数据的大量工作,但这些努力并未针对正在训练的模型构建定制数据。此外,缺乏评估数据对正在训练的模型有效性的方法,这可能导致资源浪费。
其次,我们的CRPE模型在推理过程中可能会陷入反馈循环,无法提供最终答案。这主要是因为推理过程由推理部分和反思部分组成,模型可能会反复循环推理和反思,无法得出最终答案。未来的迭代将解决这个问题。通过解决这些局限性,我们可以使我们的CRPE方法更高效和实用。
参考文献
[1] Hui, B., Yang, J., Cui, Z., Yang, J., Liu, D., Zhang, L., Liu, T., Zhang, J., Yu, B., Dang, K., Yang, A., Men, R., Huang, F., Ren, X., Ren, X., Zhou, J., Lin, J., “Qwen2.5-Coder Technical Report,” Sep. 2024, arXiv:2409.12186 [cs]. [Online]. Available: http://arxiv.org/abs/2409.12186
[2] DeepSeek-AL Q. Zhu, D. Guo, Z. Shao, D. Yang, P. Wang, R. Xu, Y. Wu, Y. Li, H. Gao, S. Ma, W. Zeng, X. Bi, Z. Gu, H. Xu, D. Dai, K. Dong, L. Zhang, Y. Piao, Z. Gou, Z. Xie, Z. Hao, B. Wang, J. Song, D. Chen, X. Xie, K. Guan, Y. You, A. Liu, Q. Du, W. Gao, X. Lu, Q. Chen, Y. Wang, C. Deng, J. Li, C. Zhao, C. Ruan, F. Luo, and W. Liang, “DeepSeek-Coder-V2: Breaking the Barrier of ClosedSource Models in Code Intelligence,” Jun. 2024, arXiv:2406.11931 [cs]. [Online]. Available: http://arxiv.org/abs/2406.11931
[3] Wei, J., Wang, X., Schuurmans, D., Bosma, M., Chi, E. H., Le, Q., & Zhou, D., “Chain of thought prompting elicits reasoning in large language models,” CoRR, vol. abs/2201.11903, 2022. [Online]. Available: https://arxiv.org/abs/2201.11903
[4] Yao, S., Yu, D., Zhao, J., Shafran, I., Griffiths, T. L., Cao, Y., & Narasimhan, K., “Tree of thoughts: Deliberate problem solving with large language models,” 2023. [Online]. Available: https: //arxiv.org/abs/2305.10601
[5] Chen, G., Liao, M., Li, C., & Fan, K., “Alphamath almost zero: Process supervision without process,” 2024. [Online]. Available: https://arxiv.org/abs/2405.03553
[6] Zhang, D., Wu, J., Lei, J., Che, T., Li, J., Xie, T., Huang, X., Zhang, S., Pavone, M., Li, Y., Ouyang, W., & Zhou, D., “Llama-berry: Pairwise optimization for o1-like olympiad-level mathematical reasoning,” 2024. [Online]. Available: https://arxiv.org/abs/2410.02884
[7] Luo, Z., Xu, C., Zhao, P., Sun, Q., Geng, X., Hu, W., Tao, C., Ma, J., Lin, Q., & Jiang, D., “Wizardcoder: Empowering code large language models with evo1-instruct,” 2023. [Online]. Available: https://arxiv.org/abs/2306.08568
[8] Yu, Z., Zhang, X., Shang, N., Huang, Y., Xu, C., Zhao, Y., Hu, W., & Yin, Q., “Wavecoder: Widespread and versatile enhancement for code large language models by instruction tuning,” 2024. [Online]. Available: https://arxiv.org/abs/2312.14187
[9] Wei, Y., Wang, Z., Liu, J., Ding, Y., & Zhang, L., “Magicoder: Empowering code generation with ons-instruct,” 2024. [Online]. Available: https://arxiv.org/abs/2312.02120
[10] Dou, S., Liu, Y., Jia, H., Xiong, L., Zhou, E., Shen, W., Shan, J., Huang, C.,Wang, X., Fan, X., Xi, Z., Zhou, Y., Ji, T., Zheng, R., Zhang, Q., Huang, X., & Gui, T., “Stepcoder: 通过编译器反馈改进代码生成的强化学习,” 2024. [Online]. Available: https://arxiv.org/abs/2402.01391
[11] Shojaee, P., Jain, A., Tipirneni, S., & Reddy, C. K., “基于深度强化学习的执行代码生成,” 2023. [Online]. Available: https://arxiv.org/abs/2301.13816
[12] Liu, J., Zhu, Y., Xiao, K., Fu, Q., Han, X., Yang, W., & Ye, D., “Rltf: 从单元测试反馈中进行强化学习,” 2023. [Online]. Available: https://arxiv.org/abs/2307.04349
[13] Hui, B., Yang, J., Cui, Z., Yang, J., Liu, D., Zhang, L., Liu, T., Zhang, J., Yu, B., Lu, K., Dang, K., Fan, Y., Zhang, Y., Yang, A., Men, R., Huang, F., Zheng, B., Miao, Y., Quan, S., Feng, Y., Ren, X., Ren, X., Zhou, J., & Lin, J., “Qwen2.5-coder技术报告,” 2024. [Online]. Available: https://arxiv.org/abs/2409.12186
[14] Guo, D., Zhu, Q., Yang, D., Xie, Z., Dong, K., Zhang, W., Chen, G., Bi, X., Wu, Y., Li, Y. K., Luo, F., Xiong, Y., & Liang, W., “Deepseek-coder: 当大型语言模型遇到编程 - 代码智能的崛起,” 2024. [Online]. Available: https://arxiv.org/abs/2401.14196
[15] Rozière, B., Gehring, J., Gloeckle, F., Sootla, S., Gat, I., Tan, X. E., Adi, Y., Liu, J., Sauvestre, R., Remez, T., Rapin, J., KestLevnikov, A., Evtimov, I., Bhattacharya, M., Ferrer, C. C., Grattafiori, A., Xiong, W., Déтомez, A., Copet, J., Azhar, F., Touvron, H., Martin, L., Usunier, N., Scialom, T., & Synnaeve, G., “Code llama: 开源代码基础模型,” 2024. [Online]. Available: https://arxiv.org/abs/2308.12950
[16] Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., AlDahle, A., Letman, A., Mathur, A., Schelten, A., Vaughan, A., Yang, A., Fan, A., Goyal, A., Hartshorn, A., Yang, A., Mitra, A., Sravankumar, A., Korenev, A., Hinsvark, A., Rao, A., Zhang, A., Rodriguez, A., Gregerson, A., Spataru, A., Roziere, B., Biron, B., Tang, B., Chern, B., Caucheteux, C., Nayak, C., Bi, C., Marra, C., McConnell, C., Keller, C., Touret, C., Wu, C., Wong, C., Ferrer, C. C., Nikolaidis, C., Allonsius, D., Song, D., Pintz, D., Livshits, D., Wyatt, D., Esiobu, D., Choudhary, D., Mahajan, D., Garcia-Olano, D., Perino, D., Hupkes, D., Lakomkin, E., AlBadawy, E., Lobanova, E., Dinan, E., Smith, E. M., Radenovic, F., Guzmán, F., Zhang, F., Synnaeve, G., Lee, G., Anderson, G. L., Thattai, G., Nail, G., Mialon, G., Pang, G., Cucurell, G., Nguyen, H., Korevaar, H., Xu, H., Touvron, H., Zarov, I., Ibarra, I. A., Kloumann, I., Misra, I., Evtimov, I., Zhang, J., Copet, J., Lee, J., Geffert, J., Vranes, J., Park, J., Mahadeokar, J., Shah, J., van der Linde, J., Billock, J., Hong, J., Lee, J., Fu, J., Chi, J., Huang, J., Liu, J., Wang, J., Yu, J., Bitton, J., Spisak, J., Park, J., Rocca, J., Johnston, J., Saxe, J., Jia, J., Alwala, K. V., Prasad, K., Upasani, K., Plawiak, K., Li, K., Heafield, K., Stone, K., El-Arini, K., Iyer, K., Malik, K., Chiu, K., Bhalla, K., Lakhotia, K., Rantala-Yeary, L., van der Maaten, L., Chen, L., Tan, L., Jenkins, L., Martin, L., Madaan, L., Malo, L., Blécher, L., Landzaat, L., de Oliveira, L., Muzzi, M., Pasupuleti, M., Singh, M., Paluri, M., Kardas, M., Tsimpoukelli, M., Oldham, M., Rita, M., Pavlova, M., Kambadur, M., Lewis, M., Si, M., Singh, M. K., Hassan, M., Goyal, N., Torabi, N., Bashlykov, N., Bogoychev, N., Chatterji, N., Zhang, N., Duchenne, O., Çelebi, O., Alrassy, P., Zhang, P., Li, P., Vasic, P., Weng, P., Bhargava, P., Dubal, P., Krishnan, P., Koura, P. S., Xu, P., He, Q., Dong, Q., Srinivasan, R., Ganapathy, R., Calderon, R., Cabral, R. S., Stojnic, R., Raileanu, R., Maheswari, R., Girdhar, R., Patel, R., Sauvestre, R., Polidoro, R., Sumbaly, R., Taylor, R., Silva, R., Hou, R., Wang, R., Hosseini, S., Chemabasappa, S., Singh, S., Bell, S., Kim, S. S., Edunov, S., Nie, S., Narang, S., Raparthy, S., Shen, S., Wan, S., Bhosale, S., Zhang, S., Vandenhende, S., Batra, S., Whitman, S., Sootla, S., Collot, S., Gururangan, S., Borodinsky, S., Herman, T., Fowler, T., Sheasha, T., Georgiou, T., Scialom, T., Speckbacher, T., Mihaylov, T., Xiao, T., Karn, U., Goswami, V., Gupta, V., Ramanathan, V., Kerkez, V., Gonguet, V., Do, V., Vogeti, V., Albiero, V., Petrovic, V., Chu, W., Xiong, W., Fu, W., Meers,
X. Martinet, X. Wang, X. Wang, X. E. Tan, X. Xia, X. Xie, X. Jia, X. Wang, Y. Goldschlag, Y. Gaur, Y. Babaei, Y. Wen, Y. Song, Y. Zhang, Y. Li, Y. Mao, Z. D. Coudert, Z. Yan, Z. Chen, Z. Papakipos, A. Singh, A. Srivastava, A. Jain, A. Kelsey, A. Shajnfeld, A. Gangidi, A. Victoria, A. Goldstand, A. Menon, A. Sharma, A. Boesenberg, A. Baevski, A. Feinstein, A. Kallet, A. Sangani, A. Teo, A. Yunus, A. Lupu, A. Alvarado, A. Caples, A. Gu, A. Ho, A. Poulton, A. Ryan, A. Ramchandani, A. Dong, A. Franco, A. Goyal, A. Saraf, A. Chowdhury, A. Gabriel, A. Bharambe, A. Eisenman, A. Yazdan, B. James, B. Maurer, B. Leonhardi, B. Huang, B. Loyd, B. D. Paola, B. Paranjape, B. Liu, B. Wu, B. Ni, B. Hancock, B. Wasti, B. Spence, B. Stojkovic, B. Gamido, B. Montalvo, C. Parker, C. Burton, C. Mejia, C. Liu, C. Wang, C. Kim, C. Zhou, C. Hu, C.-H. Chu, C. Cai, C. Tindal, C. Feichtenhofer, C. Gao, D. Civin, D. Beaty, D. Kreynner, D. Li, D. Adkins, D. Xu, D. Testuggine, D. David, D. Parikh, D. Liskovich, D. Foss, D. Wang, D. Le, D. Holland, E. Dowling, E. Jamil, E. Montgomery, E. Presani, E. Hahn, E. Wosil, E.-T. Le, E. Brinkman, E. Arcaute, E. Dunbar, E. Smothers, F. Sun, F. Kreuk, F. Tian, F. Kokkinos, F. Ozgenel, F. Caggioni, F. Kanayet, F. Seide, G. M. Florez, G. Schwarz, G. Badeer, G. Swee, G. Halpern, G. Herman, G. Sizov, Guangyi, Zhang, G. Lakshminarayanan, H. Inan, H. Shojanazeri, H. Zou, H. Wang, H. Zha, H. Habeeb, H. Rudolph, H. Suk, H. Aspegren, H. Goldman, H. Zhan, I. Damlaj, I. Molybog, I. Tufanov, I. Leontiadis, I.-E. Veliche, I. Gat, J. Weissman, J. Geboski, J. Kohli, J. Lam, J. Asher, J.-B. Gaya, J. Marcus, J. Tang, J. Chan, J. Zhen, J. Reizenstein, J. Teboul, J. Zhong, J. Jin, J. Yang, J. Cummings, J. Carvill, J. Shepard, J. McPhie, J. Torres, J. Ginsburg, J. Wang, K. Wu, K. H. U, K. Saxena, K. Khandelwal, K. Zand, K. Matosich, K. Michelena, K. Li, K. Jagadeesh, K. Huang, K. Chawla, K. Huang, L. Chen, L. Garg, L. A, L. Silva, L. Bell, L. Zhang, L. Guo, L. Yu, L. Moshkovich, L. Wehrstedt, M. Khabsa, M. Avslani, M. Bhatt, M. Mankus, M. Hasson, M. Lemrie, M. Reso, M. Groshev, M. Naumov, M. Lathi, M. Keneally, M. Liu, M. L. Seltzer, M. Valko, M. Restrepo, M. Patel, M. Vyatskov, M. Samvelyan, M. Clark, M. Macey, M. Wang, M. J. Hermoso, M. Metanat, M. Rastegari, M. Bansal, N. Santhanam, N. Parks, N. White, N. Bawa, N. Singhal, N. Egebo, N. Usunier, N. Mehta, N. P. Laptev, N. Dong, N. Cheng, O. Chernoguz, O. Hart, O. Salpekar, O. Kalinli, P. Kent, P. Parekh, P. Saab, P. Balaji, P. Ritmer, P. Bontrager, P. Roux, P. Dollar, P. Zvyagina, P. Ratanchandani, P. Yuvraj, Q. Liang, R. Alao, R. Rodriguez, R. Ayub, R. Murthy, R. Nayani, R. Mitra, R. Parthasarathy, R. Li, R. Hogan, R. Battey, R. Wang, R. Howes, R. Rinott, S. Mehta, S. Siby, S. J. Bondu, S. Datta, S. Chugh, S. Hunt, S. Dhillon, S. Sidorov, S. Pan, S. Mahajan, S. Verma, S. Yamamoto, S. Ramaswamy, S. Lindsay, S. Feng, S. Lin, S. C. Zha, S. Patil, S. Shankar, S. Zhang, S. Zhang, S. Wang, S. Agarwal, S. Sajuyipbe, S. Chintala, S. Max, S. Chen, S. Kehoe, S. Satterfield, S. Govindaprasad, S. Gupta, S. Deng, S. Cho, S. Virk, S. Subramanian, S. Choudhury, S. Goldman, T. Remez, T. Glaser, T. Best, T. Koehler, T. Robinson, T. Li, T. Zhang, T. Matthews, T. Chou, T. Shaked, V. Vontimitta, V. Ajayi, V. Montanez, V. Mohan, V. S. Kumar, V. Mangla, V. Ionescu, V. Poenaru, V. T. Mihailescu, V. Ivanov, W. Li, W. Wang, W. Jiang, W. Bouaziz, W. Constable, X. Tang, X. Wu, X. Wang, X. Wu, X. Gao, Y. Kleinman, Y. Chen, Y. Hu, Y. Jia, Y. Qi, Y. Li, Y. Zhang, Y. Zhang, Y. Adi, Y. Nam, Yu, Wang, Y. Zhao, Y. Hao, Y. Qian, Y. Li, Y. He, Z. Rait, Z. DeVito, Z. Rosnbrick, Z. Wen, Z. Yang, Z. Zhao, 和 Z. Ma, “Llama 3 模型群,” 2024. [Online]. Available: https://arxiv.org/abs/2407.21783
[17] Lozhkov, A., Li, R., Allal, L. B., Cassano, F., Lamy-Poirier, J., Tazi, N., Tang, A., Pykhtar, D., Liu, J., Wei, Y., Liu, T., Tian, M., Kocetkov, D., Zucker, A., Belkada, Y., Wang, Z., Liu, Q., Abulkhanov, D., Paul, J., Li, Z., Li, W.-D., Risdal, M., Li, J., Zhu, J., Zhuo, T. Y., Zheltonozhskii, E., Dade, N. O. O., Yu, W., Krauß, L., Jain, N., Su, Y., He, X., Dey, M., Abati, E., Chai, Y., Muennighoff, N., Tang, X., Ohlokulov, M., Akiki, C., Marone, M., Mou, C., Mishra, M., Gu, A., Hui, B., Dao, T., Zebaze, A., Dehaene, O., Patry, N., Xu, C., McAuley, J., Hu, H., Scholak, T., Paquet, S., Robinson, J., Wolf, T., Guha, A., von Werra, L., and de Vries, H., “Starcoder 2 和 stack v2:下一代,” 2024. [Online]. Available: https://arxiv.org/abs/2402.19173
[18] Wang, X., Wang, Y., Wan, Y., Mi, F., Li, Y., Zhou, P., Liu, J., Wu, H., Jiang, X., and Liu, Q., “使用编译器反馈的可编译神经代码生成,” 2022. [Online]. Available: https://arxiv.org/abs/2203.05132
[19] Le, H., Wang, Y., Gotmare, A. D., Savarese, S., and H.
Hoi, “Coderl: 通过预训练模型和深度强化学习掌握代码生成,” 2022. [Online]. Available: https: //arxiv.org/abs/2207.01780
[20] Zhang, K., Li, G., Dong, Y., Xu, J., Zhang, J., Su, J., Liu, Y., and Jin, Z., “Codedpo: 使用自动生成和验证的源代码对齐代码模型,” 2024. [Online]. Available: https://arxiv.org/abs/2410.05605
[21] OpenAI, “学习用大型语言模型推理.” 2024. [Online]. Available: https://openai.com/index/learning-to-reason-with-llms/
[22] Q Team, “Qwq-32b-preview.” 2024. [Online]. Available: https: //qwentlm.github.io/zh/blog/qwq-32b-preview/
[23] Dai, N., Wu, Z., Zheng, R., Wei, Z., Shi, W., Jin, X., Liu, G., Dun, C., Huang, L., and Yan, L., “过程监督引导的代码生成策略优化,” 2024. [Online]. Available: https://arxiv.org/abs/2410.17621
[24] Zhang, Y., Wu, S., Yang, Y., Shu, J., Xiao, J., Kong, C., and Sang, J., “o1-coder: o1在编码方面的复制,” 2024. [Online]. Available: https://arxiv.org/abs/2412.00154
[25] Rafailov, R., Sharma, A., Mitchell, E., Ermon, S., Manning, C. D., and Finn, C., “直接偏好优化:你的语言模型实际上是一个奖励模型,” 2024. [Online]. Available: https: //arxiv.org/abs/2305.18290
[26] Lai, X., Tian, Z., Chen, Y., Yang, S., Peng, X., and Jia, J., “Step-dpo: 长链推理的分步偏好优化,” 2024. [Online]. Available: https://arxiv.org/abs/2406.18629
[27] Xin, H., Ren, Z. Z., Song, J., Shao, Z., Zhao, W., Wang, H., Liu, B., Zhang, L., Lu, X., Du, Q., Gao, W., Zhu, Q., Yang, D., Gou, Z., Wu, Z. F., Luo, F., and Ruan, C., “Deepseek-prover-v1.5: 利用证明助手反馈进行强化学习和蒙特卡罗树搜索,” 2024. [Online]. Available: https://arxiv.org/abs/2408.08152
[28] Liu, J., Xia, C. S., Wang, Y., and Zhang, L., “你的代码真的是由ChatGPT生成的吗?对用于代码生成的大规模语言模型进行严格评估,” 2023. [Online]. Available: https://arxiv.org/abs/2305.01210
附录
请从以下随机代码片段中获取灵感,创建一个高质量的编程问题。将您的输出分为两个不同的部分:[问题描述]和[解决方案]。
用于启发的代码片段:
$code
每个部分的指南:
- [问题描述]:这部分应 ∗ ∗ { }^{* *} ∗∗ 完全自包含 ∗ ∗ { }^{* *} ∗∗,提供理解并解决该问题所需的所有上下文信息。假设具备常见的编程知识,但确保任何特定于该问题的上下文、变量或代码片段都明确包含。
-
- [解决方案]:提供一个全面的、
∗
∗
{ }^{* *}
∗∗ 正确的
∗
∗
{ }^{* *}
∗∗ 解决方案,准确解决您提供的[问题描述]。
图7. 生成代码问题的提示
- [解决方案]:提供一个全面的、
∗
∗
{ }^{* *}
∗∗ 正确的
∗
∗
{ }^{* *}
∗∗ 解决方案,准确解决您提供的[问题描述]。
指令
您首先需要识别给定的用户意图,然后根据用户查询的内容标记用户查询的难度级别。
## 用户查询
・.
$input
⋯
\cdots
⋯
## 输出格式
根据用户查询,在您的输出中,您首先需要识别用户意图以及解决用户查询任务所需的知識。
然后,将用户查询的难度级别评为非常简单、简单、中等、困难或非常困难。
现在,请以json格式输出以下占位符中的内容[]:
{
“intent”: “用户想要 […]”,
“knowledge”: “要解决此问题,模型需要知道 […]”,
“difficulty”: “[非常简单/简单/中等/困难/非常困难]”
}]
## 难度级别标准
非常简单:基础知识,简单任务,直截了当的答案
简单:常见知识,比非常简单稍复杂一点
中等:需要一些特定的知识或技能,中等复杂度
困难:需要深入的知识或高级技能,复杂任务
非常困难:需要专家级知识,高度复杂或专业任务
请分析用户查询并以指定格式提供您的响应。
图8. 难度分析提示
写下许多关于如何解决用户问题的思考链条。在这种情况下,将所有您的思考放在标签内。
您的思考仅对自己可见,用户看不到它们,并且它们不应被视为最终响应的一部分。
考虑每一个可能的角度,在每一步重新检查您的工作,必要时回溯。您应该将您的思考用作草稿纸,就像人类在进行复杂数学计算时使用纸和笔一样。不要省略任何计算,明确写出所有内容。
涉及计数或数学时,写下极其详细的草稿,包含完整的计算、计数或证明,确保为每一步的计算贴上标签,并逐步写下解决方案。
始终记住,如果您发现自己一直陷入困境,退一步重新考虑您的方法是个好主意。如果多个解决方案合理,分别探索每个解决方案,并提供多个答案。
始终提供数学答案的数学证明。尽可能正式,并使用LaTeX。
不要害怕给出显而易见的答案。在经过多页深入思考后,最后综合出最终答案,放在标签内。
在您的最终答案中的思维链条之后,您不应该给出任何单元案例来测试您的最终代码。并且演示测试可能会导致代码失败。
这意味着在您的代码的READ-INPUT部分中,您需要按照问题中描述的格式获取输入数据,并且演示包括许多测试案例,您的代码只需要一次解决一个测试案例。
在实际问题中,您应该直接从标准输入读取数据使用input()。
记住,思考和反思没有时间限制——更多的思考和反思总会带来更好的解决方案。
您应该始终在思考部分给出代码,而不要在反思部分给出代码。
将复杂任务分解成更小的步骤。
例如,
<
<
< thinking
>
>
>
单步推理
<
<
< thinking
>
>
>
您每次只会生成一个推理步骤。
图9. 思考代理提示
写下许多关于如何解决用户问题的思考链条。在这种情况下,您将所有您的思考放在标签内。
您的思考仅对自己可见,用户看不到它们,并且它们不应被视为最终响应的一部分。
考虑每一个可能的角度,在每一步重新检查您的工作,必要时回溯。您应该将您的思考用作草稿纸,就像人类在进行复杂数学计算时使用纸和笔一样。不要省略任何计算,明确写出所有内容。
涉及计数或数学时,写下极其详细的草稿,包含完整的计算、计数或证明,确保为每一步的计算贴上标签,并逐步写下解决方案。
始终记住,如果您发现自己一直陷入困境,退一步重新考虑您的方法是个好主意。如果多个解决方案合理,分别探索每个解决方案,并提供多个答案。
始终提供数学答案的数学证明。尽可能正式,并使用LaTeX。
不要害怕给出显而易见的答案
记住,思考和反思没有时间限制——更多的思考和反思总会带来更好的解决方案。
您每次只会生成一个推理步骤,并等待用户完成他们的思考。
在每一步之后,对您之前的思考进行反思,使用标签帮助您验证并纠正您的思考。
寻找“啊哈”时刻或新的见解。
考虑替代视角或方法。识别您所做的假设并挑战它们。寻找您可能最初错过的模式或联系。
花点时间。如果需要,想象深呼吸或喝杯咖啡。
您应该始终在思考部分给出代码,而不要在反思部分给出代码。
例如:
<
<
< reflection>
验证您的解决方案并给出您对下一步探索方向的想法
next_action = (值:‘继续’ 或 ‘最终答案’)
<
<
< /reflection>
您是一个单元测试员,擅长编写测试代码。
接下来,我将为您提供一个编码问题及相应的解决方案代码。您需要根据编码问题和解决方案代码编写测试代码进行测试。
您的测试代码应包括答案代码,并使用答案代码与一些测试用例进行测试。
您应该使用测试输入执行答案并打印输出,如下例所示。
确保您的代码可以直接通过 ‘python test.py’ 执行。
在您的测试代码中,不要使用 pytest。
如果代码需要使用 input() 获取输入,并且这可能导致测试失败,您应该重写测试用例的代码以进行测试。
您需要在
<
<
< Test
>
>
> 标签中编写您的测试代码!
例如:
=
=
= 问题
>
>
>
请使用Python解决以下问题:给定一个整数数组 ‘nums’ 和一个整数 ‘target’,
返回使两数之和等于 ‘target’ 的索引 indices
/
n
:
n
/ \mathrm{n}: \mathrm{n}
/n:n 您可以假设每个输入
只有一个确切的解
∗
∗
* *
∗∗, 并且您不能两次使用相同的元素:
:
n
: n
:n 您可以按任意顺序返回答案:
n
:
n
n: n
n:n
**示例 1:
∗
∗
:
n
/
n
∗
∗
{ }^{* *}: n / n^{* *}
∗∗:n/n∗∗ 输入:
∗
∗
{ }^{* *}
∗∗ nums
=
\
{
2
,
7
,
11
,
15
\
}
=\backslash\{2,7,11,15 \backslash\}
=\{2,7,11,15\}, target
=
9
:
n
∗
∗
=9: n^{* *}
=9:n∗∗ 输出:
∗
∗
\
{
0
,
1
\
}
:
n
{ }^{* *} \backslash\{0,1 \backslash\}: n
∗∗\{0,1\}:n **解释:
∗
∗
{ }^{* *}
∗∗ 因为 nums
\
{
0
\
}
+
\backslash\{0 \backslash\}+
\{0\}+ nums
\
{
1
\
}
=
=
9
\backslash\{1 \backslash\}==9
\{1\}==9, 我们返回
\
{
0
,
1
\
}
:
n
:
n
\backslash\{0,1 \backslash\}: n: n
\{0,1\}:n:n **示例 2:
∗
∗
:
n
/
n
∗
∗
{ }^{* *}: n / n^{* *}
∗∗:n/n∗∗ 输入:
∗
∗
{ }^{* *}
∗∗ nums
=
\
{
3
,
2
,
4
\
}
=\backslash\{3,2,4 \backslash\}
=\{3,2,4\}, target
=
6
:
n
∗
∗
=6: n^{* *}
=6:n∗∗ 输出:
∗
∗
\
{
1
,
2
\
}
:
n
:
n
{ }^{* *} \backslash\{1,2 \backslash\}: n: n
∗∗\{1,2\}:n:n **示例 3:
∗
∗
:
n
/
n
∗
∗
{ }^{* *}: n / n^{* *}
∗∗:n/n∗∗ 输入:
∗
∗
{ }^{* *}
∗∗ nums
=
\
{
3
,
3
\
}
=\backslash\{3,3 \backslash\}
=\{3,3\}, target
=
6
:
n
∗
∗
=6: n^{* *}
=6:n∗∗ 输出:
∗
∗
\
{ }^{* *} \backslash
∗∗\
{
0
,
1
\
}
\{0,1 \backslash\}
{0,1\} :
n
:
n
∗
∗
n: n^{* *}
n:n∗∗ 约束:
∗
∗
:
n
:
n
∗
:
2
<
=
{ }^{* *}: n: n^{*} \quad: 2<=
∗∗:n:n∗:2<= nums.length
<
=
10
4
′
:
n
∗
:
−
109
<
=
<=104^{\prime}: n^{*} \quad:-109<=
<=104′:n∗:−109<= nums[i]
<
=
10
9
′
:
n
∗
:
−
109
<
=
<=109^{\prime}: n^{*} \quad:-109<=
<=109′:n∗:−109<= target
<
=
<=
<=
10
9
′
:
n
∗
∗
109^{\prime}: n^{*} *
109′:n∗∗
只有唯一有效的答案存在。
∗
∗
:
n
:
n
{ }^{* *}: n: n
∗∗:n:n
∗
∗
{ }^{* *}
∗∗ 跟进:
∗
∗
{ }^{* *}
∗∗ 您能否提出一种时间复杂度小于’O(n2)'的算法?
<
<
< 问题
>
>
>
<
<
< 答案
>
>
>
def twoSum(nums, target):
map
=
\
{
}
=\backslash\{\}
=\{}
for i, num in enumerate(nums):
complement
=
=
= target - num
if complement in map:
return [map[complement], i]
map[num]
=
i
=\mathrm{i}
=i
return []
<
/
</
</ 答案
>
>
>
您的答案:
<
<
< 测试
>
>
>
′
′
′
{ }^{\prime \prime \prime}
′′′ python
def twoSum(nums, target):
map
=
\
{
}
=\backslash\{\}
=\{}
for i, num in enumerate(nums):
complement
=
=
= target - num
if complement in map:
return [map[complement], i]
map[num]
=
i
=\mathrm{i}
=i
return []
print(twoSum([2, 7, 11, 15], 9)) #期望 [0,1]
print(twoSum([3, 2, 4], 6)) # 期望 [1, 2]
print(twoSum([3, 3], 6)) # 期望[0, 1]
<
/
</
</ 测试
>
>
>
图11. 提示执行代理生成测试代码
您将获得一段代码及其执行结果。
通过代码,您可以了解输入的测试用例和预期输出。
通过执行结果,您可以了解函数代码在输入下的执行情况。
您应该根据执行结果和预期输出验证代码是否正确。
您只能回答是或否。
不要回答其他任何内容!
是表示执行结果和预期输出相同,代码正确。否表示代码错误或执行结果与预期输出不同。
图12. 提示执行代理检查执行结果的正确性
参考论文:https://arxiv.org/pdf/2505.10594



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











