






高龙溪 张立 许梦伟
北京邮电大学
{gaolongxi, li.zhang,mwx}@bupt.edu.cn
摘要
训练有效的视觉语言模型(VLMs)用于图形用户界面(GUI)代理通常依赖于大规模注释数据集上的监督微调(SFT),其中收集过程耗时且容易出错。在本工作中,我们提出了一种自监督逆动力学任务,使VLMs能够通过推断导致该转换的动作从GUI转换对中学习。此训练任务提供了两个优势:(1) 它使VLMs能够忽略与用户动作无关的变化(例如,背景刷新、广告),并专注于复杂的GUI中的真实交互点,如按钮和输入字段。(2) 训练数据可以从现有的GUI轨迹中轻松获得,无需人工注释,并且可以通过自动离线探索轻松扩展。利用这一训练任务,我们提出了UIShift,一种通过自监督强化学习(RL)增强基于VLM的GUI代理的框架。仅使用来自现有数据集的2K训练样本,经过UIShift训练的两个VLM模型——Qwen2.5-VL-3B和Qwen2.5-VL-7B——在定位任务(ScreenSpot系列基准)和GUI自动化任务(AndroidControl)上实现了与SFT基线和显式激发推理能力的GUI特定模型相当或更优的性能。我们的研究结果表明,未来通过利用更多的自监督训练数据来增强用于GUI代理的VLMs具有潜在方向。
1 引言
移动GUI代理
[
8
,
10
,
19
,
29
,
34
,
38
]
[8,10,19,29,34,38]
[8,10,19,29,34,38] 解释自然语言指令并在智能手机屏幕上执行低级操作(例如点击、滚动)。它们可以像人类一样控制各种应用程序,为视障、老年人或双手被占用的用户提供更好的可访问性。视觉语言模型(VLMs)[1, 3, 25, 35] 的突破重塑了移动GUI代理的设计范式,从手工制作的启发式方法过渡到学习的、基于视觉的策略。然而,当面对复杂的多步骤任务时,这些模型难以提供令人满意的准确性
[
5
,
19
,
20
,
39
]
[5,19,20,39]
[5,19,20,39]。一种常见的增强这些VLMs的方法是应用注释数据集上的监督微调(SFT),例如使用带有手动注释任务说明的预录GUI轨迹 [13, 21]。虽然有效,但收集任务注释的GUI轨迹仍然耗时且容易出错 [6, 7, 13, 21]。例如,收集AndroidControl [13] 数据集需要一年的付费注释工作才能生成15,283个任务演示。这种数据收集过程的高成本使得这种范式难以扩展。
在本研究中,我们旨在利用大量未标记的GUI轨迹,这些轨迹可以轻松地从现有数据集中获取或通过自动离线探索扩展,例如MobileViews [7] 在百万规模上。为了释放此类数据的潜力,我们提出了一种针对GUI代理的自监督训练任务,名为
k
k
k-步UI转换。该任务将机器人技术和生物力学应用中的逆动力学建模扩展到GUI领域——将截图视为状态,将GUI动作视为命令。具体而言,训练样本由一对截图
S
t
S_{t}
St 和
S
t
+
k
S_{t+k}
St+k 组成,其中
S
t
+
k
S_{t+k}
St+k 是从状态
S
t
S_{t}
St 开始执行
k
k
k 步动作后获得的。VLM 被要求预测将
S
t
S_{t}
St 转换为
S
t
+
1
S_{t+1}
St+1 的初始动作。此训练任务消除了对预定义指令或标记轨迹的需求,因为真实的动作内在存在于GUI转换序列中。与单屏任务(例如,根据任务指令预测要在屏幕上执行的动作)相比,UI转换通过明确的状态比较增强了视觉感知,并使模型更好地将动作与视觉差异对齐。
为了利用UI转换,我们采用了组相对策略优化(GRPO)[23] 而非SFT。在SFT下,交叉熵损失应用于强制每个截图对对应一个单一的真实动作,这在下游任务需要截图加指令时会损害其性能。相比之下,GRPO在多个候选动作上进行优化:对于每对截图,它采样一组可能的动作,使用预定义的奖励函数对每个动作评分,并使用组内归一化优势对其进行排名。这种方法鼓励探索,保持遵循指令的能力,并增强对下游任务(如GUI定位和任务自动化)的泛化能力。
我们提出了UIShift,这是一种单阶段RL训练框架,仅使用UI转换数据通过GRPO微调VLMs。我们在1K/2K UI转换对上微调Qwen2.5-VL-3B和7B模型。为了展示在相同RL框架下UI转换是一项更有效的任务,我们将UIShift与两种依赖注释的基线进行比较:Task Automation Low和Task Automation High,它们分别接受单张截图和步骤级或任务级指令来预测完成步骤或推进任务的下一个动作。为了隔离GRPO本身的影响,我们还包括了一个在相同的UI转换对上进行SFT变体,没有任何推理提示。这使我们可以直接比较GRPO与交叉熵训练在相同数据上的表现。为进一步探索UI转换的内部因素,我们变化了两个设置:(1) 推理提示:三种训练-推理配置(训练和推理均推理、仅训练时推理、训练和推理均无推理)。(2) 转换距离
k
k
k :两个UI状态之间的步数,其中
k
∈
{
1
,
2
,
3
,
4
}
k \in\{1,2,3,4\}
k∈{1,2,3,4}。所有模型都在五个基准上进行评估:三个用于定位(ScreenSpot [4], ScreenSpot-V2 [31], ScreenSpot-Pro [12])和两个用于任务自动化(AndroidControl-Low/High [13])。
我们总结了关键结果如下。
-
仅基于自监督UI转换数据训练的UIShift在定位和任务自动化基准测试中始终优于依赖注释的基线。这表明UI转换为开发GUI理解和泛化能力提供了更有效的学习信号。
-
- 推理对于GUI相关任务并非必要。我们观察到,没有推理提示训练和评估的模型的表现与甚至超过那些带有推理训练的模型相当。这与Perception-R1 [36] 和UI-R1 [18] 报告的结果一致。值得注意的是,在相同的数据约束下,GRPO优于SFT,突显了其在训练数据有限时的效率。
-
- 较大的
k
k
k 改善了长期规划,但
k
=
1
k=1
k=1 提供了最平衡的性能。尽管
k
=
4
k=4
k=4 在AndroidControl-High上达到了最高的准确率,但它降低了定位性能。最佳平衡出现在
k
=
1
k=1
k=1,因此我们用
k
=
1
k=1
k=1 训练了UIShift-7B-2K。在训练和推理过程中不使用推理提示的情况下,UIShift-7B-2K 在ScreenSpot上达到了
87.81
%
87.81 \%
87.81%。在移动子集上,它达到了
96.7
%
96.7 \%
96.7%(文本)和
85.2
%
85.2 \%
85.2%(图标)的准确率,超越了所有先前的方法。在ScreenSpot-V2上,它达到了
90.3
%
90.3 \%
90.3% 的准确率,超过了使用50B令牌训练的UI-TARS-7B(
89.5
%
89.5 \%
89.5%),设定了新的最先进水平。UIShift-7B-2K 还在任务自动化基准测试中提供了持续的改进。
我们的贡献总结如下。
- 较大的
k
k
k 改善了长期规划,但
k
=
1
k=1
k=1 提供了最平衡的性能。尽管
k
=
4
k=4
k=4 在AndroidControl-High上达到了最高的准确率,但它降低了定位性能。最佳平衡出现在
k
=
1
k=1
k=1,因此我们用
k
=
1
k=1
k=1 训练了UIShift-7B-2K。在训练和推理过程中不使用推理提示的情况下,UIShift-7B-2K 在ScreenSpot上达到了
87.81
%
87.81 \%
87.81%。在移动子集上,它达到了
96.7
%
96.7 \%
96.7%(文本)和
85.2
%
85.2 \%
85.2%(图标)的准确率,超越了所有先前的方法。在ScreenSpot-V2上,它达到了
90.3
%
90.3 \%
90.3% 的准确率,超过了使用50B令牌训练的UI-TARS-7B(
89.5
%
89.5 \%
89.5%),设定了新的最先进水平。UIShift-7B-2K 还在任务自动化基准测试中提供了持续的改进。
-
我们提出了UIShift,第一个结合了 k k k-步UI转换任务与GRPO的自监督强化训练框架,用于微调VLMs。
-
- 我们探讨了静态GUI相关任务中推理的必要性,发现推理对于训练或推理都不是必需的。
-
- 我们使用UIShift以无推理配置训练了UIShift-7B-2K模型,并在五个GUI基准上评估了其性能。结果显示,它比在依赖注释的任务上训练的模型表现更好。
-
2 相关工作
2.1 移动GUI代理
近年来,移动GUI代理的进步得益于通过SFT在大规模数据集上训练的VLMs。这些模型通过指令跟随任务学习将指令映射到GUI动作,这使得高质量注释成为必要。尽管有多种GUI数据集可用 [6, 7, 13 , 14 , 17 , 21 , 27 ] 13,14,17,21,27] 13,14,17,21,27],但高质量注释的数量仍不足以实现稳健的训练,通常需要大量的人力来扩展。之前的SFT管道经常包含域外图像-标题对 [10, 28] 并补充训练以提高跨平台泛化能力 [4]。因此,整体训练数据规模往往较大:UI-TARS [19] 在50B tokens上训练;Uground [8] 使用1.3M截图训练视觉定位模型;OS-Atlas [31] 利用13M UI元素进行定位预训练。MobileVLM [30] 在预训练期间结合了动作预测任务;然而,这仅限于一步转换,并且仍然依赖于大量的精细调整以实现下游泛化。在本研究中,我们提出了一种自监督训练范式,消除了对大规模人工标注数据的依赖。通过构建一个 k k k-步逆动力学任务,其中VLMs推断从当前到未来UI状态的动作,我们的方法捕捉了长范围GUI动态,并能够在大规模、未充分利用和未标注的GUI转换数据集上进行可扩展的训练。
2.2 基于规则的强化学习
基于规则的RL已被证明是SFT的一种有前途的替代方案。GRPO [23] 使用奖励模型对每个响应进行评分,并计算组相对优势而不是训练一个大小与策略模型相当的批评模型,从而显著减少计算成本。具有可验证奖励的强化学习 [11] 进一步强调使用可验证答案来设计可靠的奖励信号。DeepSeek-R1 [9] 表明简单的格式和准确性奖励足以超越指令调优模型的性能。这种范式特别适合GUI代理,其动作空间由具有结构化参数的离散动作类型组成,使得正确性易于验证。最近的一些努力已将GRPO应用于GUI任务:UI-R1 [18] 在136个步骤指令样本上进行单阶段RL;GUI-R1 [32] 也在来自五个平台的3K任务指令样本上采用单阶段RL策略;InfiGUI-R1 [16] 采用两阶段SFT+RL流水线,并扩展到32 K GUI和非GUI领域的样本。尽管这些工作展示了基于规则的RL在GUI代理中的有效性,但仍依赖于注释指令,并要求在训练和推理过程中进行推理。不同于现有方法,UIShift采用了自监督训练范式。我们仅使用2K UI转换样本直接通过单阶段RL微调VLMs,却取得了具有竞争力的性能和强大的跨平台和任务的泛化能力。
3 UIShift框架
UIShift是一个单阶段RL训练框架,旨在使用自监督UI转换任务微调特定于GUI的VLMs。本节首先介绍UIShift中使用的GRPO及其奖励设计,然后引入 k k k-步UI转换任务及其基本原理。
3.1 预备知识:GRPO
GRPO [23] 是一种资源高效的Proximal Policy Optimization (PPO) [22] 替代方案,后者是一种流行的actor-critic RL算法。与需要单独的批评模型来估计价值函数的PPO不同,GRPO直接使用奖励模型的奖励计算标准化的组内优势 A i A_{i} Ai,从而消除了价值估计的需要并减少了计算开销。DeepSeek-R1 [9] 进一步简化了这个设置,用基于规则的功能替换了奖励模型,该功能由格式和准确性标准组成。按照这种设计,我们在框架中优化的GRPO目标是:
J
G
R
P
O
(
θ
)
=
E
[
q
∼
P
(
Q
)
,
{
o
i
}
i
=
1
G
∼
π
θ
o
l
d
(
O
∣
q
)
]
1
G
∑
i
=
1
G
(
min
(
ρ
i
A
i
,
clip
(
ρ
i
,
1
−
ϵ
,
1
+
ϵ
)
A
i
)
−
β
D
K
L
(
π
θ
∥
π
r
e
f
)
)
\begin{aligned} \mathcal{J}_{\mathrm{GRPO}}(\theta)= & \mathbb{E}\left[q \sim P(Q), \left\{o_{i}\right\}_{i=1}^{G} \sim \pi_{\theta_{\mathrm{old}}}(O \mid q)\right] \\ & \frac{1}{G} \sum_{i=1}^{G}\left(\min \left(\rho_{i} A_{i}, \operatorname{clip}\left(\rho_{i}, 1-\epsilon, 1+\epsilon\right) A_{i}\right)-\beta \mathbb{D}_{\mathrm{KL}}\left(\pi_{\theta} \| \pi_{\mathrm{ref}}\right)\right) \end{aligned}
JGRPO(θ)=E[q∼P(Q),{oi}i=1G∼πθold(O∣q)]G1i=1∑G(min(ρiAi,clip(ρi,1−ϵ,1+ϵ)Ai)−βDKL(πθ∥πref))
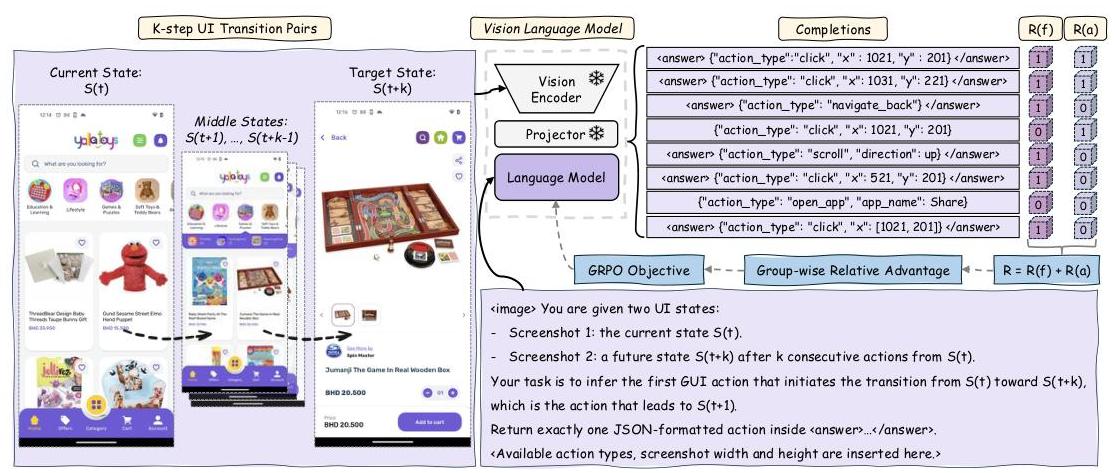
图1:UIShift框架概览。它在 k k k-步UI转换任务上应用GRPO,奖励由格式正确性 R ( f ) R(f) R(f) 和动作准确性 R ( a ) R(a) R(a) 定义。
其中 ρ i = π θ ( o i ∣ q ) π θ o l d ( o i ∣ q ) , A i = r i − mean ( { r 1 , r 2 , ⋯ , r G } ) std ( { r 1 , r 2 , ⋯ , r G } ) \text { 其中 } \quad \rho_{i}=\frac{\pi_{\theta}\left(o_{i} \mid q\right)}{\pi_{\theta_{o l d}}\left(o_{i} \mid q\right)}, \quad A_{i}=\frac{r_{i}-\operatorname{mean}\left(\left\{r_{1}, r_{2}, \cdots, r_{G}\right\}\right)}{\operatorname{std}\left(\left\{r_{1}, r_{2}, \cdots, r_{G}\right\}\right)} 其中 ρi=πθold(oi∣q)πθ(oi∣q),Ai=std({r1,r2,⋯,rG})ri−mean({r1,r2,⋯,rG})
具体来说,对于训练集中的每个问题 q q q,我们从旧策略 π θ o l d \pi_{\theta_{o l d}} πθold使用高温解码采样一组输出 { o 1 , o 2 , … , o G } \left\{o_{1}, o_{2}, \ldots, o_{G}\right\} {o1,o2,…,oG},并计算每个输出的组内相对优势 A i A_{i} Ai。然后使用带KL散度正则化的裁剪替代目标更新模型参数,确保训练稳定性。
3.2 UIShift中的奖励设计
为了评估推理在GUI相关任务中的影响,我们设计了两种训练配置:推理启用和推理禁用,取决于模型在训练过程中是否需要进行链式推理。在这两种设置中,我们应用了一个基于规则的奖励函数 R R R,它由格式奖励 R f R_{f} Rf和准确性奖励 R a R_{a} Ra组成:
R = R f + R a R=R_{f}+R_{a} R=Rf+Ra
格式奖励。我们采用了DeepSeek-R1 [9]中的格式规则,以确保模型输出遵循预期结构。在推理启用设置中,模型被要求在…中放置中间推理,并在…中放置最终答案。在推理禁用设置中,只需要…块。符合预期结构的输出接收
R
f
=
1
R_{f}=1
Rf=1;否则,
R
f
=
0
R_{f}=0
Rf=0。
准确性奖励。我们在训练和推理过程中使用统一的动作空间,涵盖五种动作类型:点击、滚动、打开应用、返回导航和输入文本。每个动作表示为包含动作类型及其关联参数的结构化JSON对象。具体来说,点击使用坐标对(
x
,
y
\mathrm{x}, \mathrm{y}
x,y)表示目标UI元素的中心点,滚动需要方向(上、下、右或左),打开应用和输入文本分别需要应用名称和要输入的文本作为字符串参数,而返回导航则是无参数的。如果预测的动作类型和所有参数与真实值匹配,则认为预测动作正确。对于非点击动作,如果所有参数完全匹配,模型将获得
R
a
=
1
R_{a}=1
Ra=1;否则,
R
a
=
0
R_{a}=0
Ra=0。对于点击,我们采用空间容忍策略:如果坐标(
x
,
y
\mathrm{x}, \mathrm{y}
x,y)落在目标UI元素的边界框(bbox)内,则认为预测正确。这反映了现实世界中的GUI行为,即在UI组件内的任何位置点击都会产生相同的效果。为此,我们根据每对UI转换的第一张截图中的真实点击动作对应的视图层次结构文件提取目标元素的边界框。该边界框随后附加到训练数据中。在训练过程中,模型被提示仅输出坐标(
x
,
y
\mathrm{x}, \mathrm{y}
x,y),然后将其与真实边界框进行比较。如果预测的坐标落在边界框内,模型将获得
R
a
=
1
R_{a}=1
Ra=1;否则,
R
a
=
0
R_{a}=0
Ra=0。
3.3 k步UI转换任务和训练
如图1所示,每个训练样本在 k k k-步UI转换任务中包含一对UI截图:当前UI状态 S t S_{t} St和未来的状态 S t + k S_{t+k} St+k,这是通过在 S t S_{t} St上执行 k k k个动作得到的。模型接收到这两张截图而不附带任何额外的指示,并被要求预测将 S t S_{t} St转换为 S t + 1 S_{t+1} St+1的第一个动作。尽管由于预训练数据中包含GUI数据,VLMs可以理解单个GUI屏幕,但它们无法捕捉状态间的变化或计划动作序列。 k k k-步UI转换任务通过迫使模型比较 S t S_{t} St和 S t + k S_{t+k} St+k,识别语义变化,定位负责区域,并输出相应的结构化动作来解决这个问题。这类似于机器人技术中的逆动力学建模,其中预测导致状态变化的控制信号会导致捕获“什么改变了”和“如何改变”的环境表示。在GUI上下文中,当模型必须关注两个UI状态之间的“什么改变了”时,它自然学会忽略无关的UI元素并关注可操作区域。这应能提升在零样本定位(基于文本查询识别小部件)或需要按顺序计划多个动作的任务自动化基准测试中应用微调模型的鲁棒性。
我们使用GRPO在 k k k-步UI转换任务上微调VLMs。对于每个输入对,模型采样 m m m个候选动作,每个动作由结合格式正确性 R f R_{f} Rf和动作准确性 R a R_{a} Ra的基于规则的奖励 R R R评分。我们计算组内标准化优势并使用GRPO目标(方程1)进行优化。GRPO适用于UI转换任务,因为它允许模型首先提出各种可能的动作,然后对其进行排名,比SFT中的单次标签反馈提供更多反馈。这自然鼓励探索,不像标准监督损失那样要求精确匹配行为。通过结合UI转换与GRPO,我们的方法可以轻松扩展,无需注释数据,并避免过度拟合到单一最佳动作。
4 实验
我们在五个基准测试中评估了VLMs在GUI代理中的两项基本能力——指令映射和GUI定位。我们的比较跨越了三个维度:(1) 先前的方法,(2) 依赖注释的任务,(3) SFT基线。我们进一步调查链式推理是否有所帮助,并探索UI转换中的 k k k-步目标如何影响性能。
4.1 实验设置
模型和训练配置。使用第
§
3
\S 3
§3节提出的训练流程和开源RL框架VLM-R1 [24],我们在
8
×
8 \times
8× A800 GPU上对Qwen2.5-VL3B/7B [1]进行了全参数强化微调8个epoch。我们最好的模型,UIShift-7B-2K,在26小时内完成了2K UI转换样本的训练。更多超参数细节见附录A。
训练任务和数据选择。在UIShift中,我们仅采用
k
k
k-步UI转换,并探索四个变体,其中
k
∈
{
1
,
2
,
3
,
4
}
k \in\{1,2,3,4\}
k∈{1,2,3,4}。我们包括两个依赖注释的任务以进行比较:(1) Task Automation Low 提供一张截图和一个步骤指示(例如,“点击分享图标”),指定了要采取的确切UI动作;(2) Task Automation High 提供一张截图和一个任务指示(例如,“通过Gmail分享新闻文章”),描述了最终目标,要求模型推断出推进该任务的下一步动作。我们从AndroidControl [13]构建所有训练任务,它提供了带有截图和指示的UI轨迹。为确保GUI多样性,我们从所有任务的不同剧集中选择训练样本。
基准测试和评估指标。对于GUI定位,我们在三个基准测试中评估模型:ScreenSpot [4],ScreenSpot-V2 [31],和ScreenSpot-Pro [12]。ScreenSpot和ScreenSpot-V2提供了跨移动、Web和桌面平台的评估,而ScreenSpot-Pro专注于高分辨率桌面接口和细粒度的UI组件。在所有三个基准测试中,模型接收文本描述并被要求通过预测其屏幕坐标(
x
,
y
\mathrm{x}, \mathrm{y}
x,y)来定位UI元素。如果坐标落在真实边界框内,则预测正确。我们报告了各种UI类型、平台和应用类别的定位准确率。
对于GUI任务自动化,我们采用AndroidControl-Low和AndroidControl-High [13],两者都提供一张截图和指示,并要求模型预测下一个动作。每个预测动作由动作类型及其关联参数组成。虽然AndroidControl-Low包含明确的步骤级指示作为直接指导,AndroidControl-High只提供任务级指示,要求模型推断当前在多步骤任务中的进度,从而使决策更具挑战性。我们报告了三个评估指标:(i) 动作类型准确率(Type),预测动作类型与真实值完全匹配的比例;(ii) 定位准确率(Grounding),预测坐标落在真实边界框内的样本比例,计算仅针对真实和预测动作均为点击的样本;(iii) 成功率(SR),预测动作类型及其所有关联参数与真实值完全匹配的比例。
推理配置和比较设置。为了研究链式推理在VLMs中的有效性,我们在训练和推理过程中实验了三种不同的配置:(1) 训练和推理均使用推理提示(完全推理依赖);(2) 训练时使用推理但推理时不使用(推理自由推理);(3) 训练和推理均不使用推理(完全推理自由)。为进一步评估RL的有效性,我们还在完全推理自由设置下对三个数据集—UI转换、Task Automation Low、Task Automation High—进行了SFT基线训练。
4.2 GUI定位和任务自动化结果
GUI任务自动化基准测试。如表1所示,UIShift-7B在AndroidControl-Low和High上始终优于Qwen2.5-VL-7B基线。仅使用1K样本,UIShift-7B-1K在AndroidControl-Low上达到
79.8
%
79.8 \%
79.8%,在High上达到
54.2
%
54.2 \%
54.2%,分别提高了
14.4
%
14.4 \%
14.4%和
17
%
17 \%
17%。扩展到2K样本进一步提升了结果至
86.0
%
86.0 \%
86.0%和
55.2
%
55.2 \%
55.2%,表明即使小规模的UI转换训练也能受益于下游自动化任务。
GUI定位基准测试。UIShift-7B-2K在ScreenSpot和ScreenSpot-V2上实现了强大的定位准确率,如表2和表3所示。在移动设备上,它在ScreenSpot上分别达到
96.7
%
96.7 \%
96.7%(文本)和
85.2
%
85.2 \%
85.2%(图标),在ScreenSpot-V2上分别达到
99.3
%
99.3 \%
99.3%(文本)和
89.6
%
89.6 \%
89.6%(图标)。在所有三个平台上的平均准确率方面,UIShift-7B-2K在ScreenSpot上达到
87.8
%
87.8 \%
87.8%,在ScreenSpot-V2上达到
90.3
%
90.3 \%
90.3%,接近UI-TARS-7B(分别为
89.5
%
89.5 \%
89.5%和
91.6
%
91.6 \%
91.6%),后者是在大约50B tokens上训练的。在高分辨率ScreenSpot-Pro基准测试中,UIShift相对于Qwen2.5-VL-7B基线表现出改善的定位准确率。ScreenSpot-Pro的详细结果见附录B。
表2:ScreenSpot上的GUI定位准确率。UIShift模型的训练和评估均未使用推理。UIShift和指令依赖训练的最佳得分分别加粗显示。对于InfiGUI-R1-3B,“12K + 20K”表示12K轨迹和20K截图。
| 模型 | 方法 | 数据 | 移动端 | 桌面端 | 网页端 | 平均 | |||
|---|---|---|---|---|---|---|---|---|---|
| 文本 | 图标 | 文本 | 图标 | 文本 | 图标 | ||||
| Qwen2.5-VL-7B [1] | 零样本 | - | 97.1 | 81.2 | 86.6 | 70.0 | 87.4 | 78.6 | 84.9 |
| 使用GRPO的UI转换(UIShift,自监督)对于 k ∈ { 1 , 2 , 3 , 4 } k \in\{1,2,3,4\} k∈{1,2,3,4} | |||||||||
| UIShift-7B-1K ( k = 1 ) (k=1) (k=1) | RL | 1 K | 96.7 | 85.2 | 87.6 | 73.6 | 89.6 | 81.1 | 86.9 |
| UIShift-7B-2K ( k = 1 ) (k=1) (k=1) | 2 K | 96.7 | 85.2 | 91.2 | 75.7 | 89.6 | 82.0 | 87.8 | |
| UIShift-7B-1K ( k = 2 ) (k=2) (k=2) | 1 K | 96.7 | 85.2 | 87.6 | 74.3 | 88.7 | 80.1 | 86.6 | |
| UIShift-7B-1K ( k = 3 ) (k=3) (k=3) | 1 K | 96.7 | 83.0 | 89.2 | 73.6 | 89.6 | 80.6 | 86.6 | |
| UIShift-7B-1K ( k = 4 ) (k=4) (k=4) | 1 K | 96.7 | 85.2 | 86.6 | 75.0 | 88.7 | 80.1 | 86.6 | |
| 指令依赖训练 | |||||||||
| CogAgent-18B [10] | SFT | - | 67.0 | 24.0 | 74.2 | 20.0 | 70.4 | 28.6 | 47.4 |
| SeeClick-9.6B [4] | SFT | 1 M | 78.0 | 52.0 | 72.2 | 30.0 | 55.7 | 32.5 | 53.4 |
| UGround-7B [8] | SFT | 1.3 M | 82.8 | 60.3 | 82.5 | 63.6 | 80.4 | 70.4 | 73.3 |
| OS-Atlas-7B [31] | SFT | 2.3 M | 93.0 | 72.9 | 91.8 | 62.9 | 90.9 | 74.3 | 82.5 |
| ShowUI-2B [15] | SFT | 256K | 92.3 | 75.5 | 76.3 | 61.1 | 81.7 | 63.6 | 75.1 |
| Aguvis-7B [33] | SFT | 1 M | 95.6 | 77.7 | 93.8 | 67.1 | 88.3 | 75.2 | 84.4 |
| UI-TARS-7B [19] | SFT | 50B tokens | 94.5 | 85.2 | 95.9 | 85.7 | 90.0 | 83.5 | 89.5 |
| UI-R1-3B [18] | RL | 136 | 95.6 | 84.7 | 90.2 | 59.3 | 85.2 | 73.3 | 83.3 |
| UI-R1-E-3B [18] | RL | 2 K | 97.1 | 83.0 | 95.4 | 77.9 | 91.7 | 85.0 | 89.2 |
| GUI-R1-7B [32] | RL | 3 K | - | - | 91.8 | 73.6 | 91.3 | 75.7 | - |
| InfiGUI-R1-3B [16] | SFT+RL | 12 K + 20 K 12 \mathrm{~K}+20 \mathrm{~K} 12 K+20 K | 97.1 | 81.2 | 94.3 | 77.1 | 91.7 | 77.6 | 87.5 |
表3:ScreenSpot-V2上的GUI定位准确率。UIShift模型的训练和评估均未使用推理。UIShift和指令依赖训练的最佳得分分别加粗显示。对于InfiGUI-R1-3B,“12K + 20K”表示12K轨迹和20K截图。
| 模型 | 方法 | 数据 | 移动端 | 桌面端 | 网页端 | 平均 | |||
|---|---|---|---|---|---|---|---|---|---|
| 文本 | 图标 | 文本 | 图标 | 文本 | 图标 | ||||
| Qwen2.5-VL-7B [1] | 零样本 | - | 98.6 | 87.2 | 93.8 | 88.7 | 90.2 | 81.3 | 87.9 |
| 使用GRPO的UI转换(UIShift,自监督)对于 k ∈ { 1 , 2 , 3 , 4 } k \in\{1,2,3,4\} k∈{1,2,3,4} | |||||||||
| UIShift-7B-1K ( k = 1 ) (k=1) (k=1) | RL | 1 K | 99.0 | 89.1 | 90.7 | 75.7 | 91.0 | 83.3 | 89.5 |
| UIShift-7B-2K ( k = 1 ) (k=1) (k=1) | 2 K | 99.3 | 89.6 | 92.3 | 77.9 | 92.3 | 82.3 | 90.3 | |
| UIShift-7B-1K ( k = 2 ) (k=2) (k=2) | 1 K | 99.0 | 89.1 | 90.7 | 75.7 | 92.3 | 81.3 | 89.5 | |
| UIShift-7B-1K ( k = 3 ) (k=3) (k=3) | 1 K | 98.6 | 87.7 | 91.2 | 75.7 | 92.3 | 81.8 | 89.3 | |
| UIShift-7B-1K ( k = 4 ) (k=4) (k=4) | 1 K | 98.6 | 90.5 | 90.2 | 76.4 | 91.5 | 83.3 | 89.8 | |
| 指令依赖训练 | |||||||||
| SeeClick-9.6B [4] | SFT | 1 M | 78.4 | 50.7 | 70.1 | 29.3 | 55.2 | 32.5 | 55.1 |
| OS-Atlas-7B [31] | SFT | 2.3 M | 95.2 | 75.8 | 90.7 | 63.6 | 90.6 | 77.3 | 84.1 |
| UI-TARS-7B [19] | SFT | 50B tokens | 96.9 | 89.1 | 95.4 | 85.0 | 93.6 | 85.2 | 91.6 |
| UI-R1-3B [18] | RL | 136 | 96.2 | 84.3 | 92.3 | 63.6 | 89.2 | 75.4 | 85.4 |
| UI-R1-E-3B [18] | RL | 2 K | 98.2 | 83.9 | 94.8 | 75.0 | 93.2 | 83.7 | 89.5 |
4.3 比较推理配置
我们在基于GRPO的训练中比较了三种推理配置——完全推理依赖、推理自由推理和完全推理自由——在AndroidControl-Low、AndroidControlHigh和ScreenSpot上。如表4和表5所示,对于每个模型尺寸,这三种推理配置在AndroidControl-High和ScreenSpot上实现了相当的性能。在AndroidControl-Low上,完全推理自由配置表现最佳:3B模型在 k = 1 k=1 k=1时达到峰值,而7B模型在 k = 4 k=4 k=4时达到最高准确率。这些结果表明,推理在推理过程中存在与否影响较小。此外,如表5所示,基于GRPO训练的模型在完全推理自由模式下仍优于其基于SFT训练的对应模型。鉴于推理配置之间的相似性能和显著的训练时间差异(推理自由的7B模型训练时间为13小时,而推理依赖的为19小时,
表4:在不同推理配置下的ScreenSpot准确率。Y/N表示训练/推理过程中是否使用推理。模型在1K样本上训练, k = 1 k=1 k=1。
| 模型 | 是否推理 | 移动端 | 桌面端 | 网页端 | 平均 | ||||
|---|---|---|---|---|---|---|---|---|---|
| 训练 | 推理 | 文本 | 图标 | 文本 | 图标 | 文本 | 图标 | ||
| UIShift-3B | Y | Y | 94.5 | 73.8 | 89.2 | 64.3 | 85.2 | 69.4 | 80.9 |
| Y | N | 94.1 | 74.2 | 84.5 | 61.4 | 82.2 | 66.0 | 78.8 | |
| N | N | 95.2 | 74.7 | 86.6 | 62.1 | 82.2 | 66.5 | 79.6 | |
| UIShift-7B | Y | Y | 97.1 | 82.1 | 89.7 | 72.1 | 91.3 | 79.1 | 86.6 |
| Y | N | 97.1 | 83.8 | 84.5 | 73.6 | 89.1 | 80.6 | 86.1 | |
| N | N | 96.7 | 85.2 | 87.6 | 73.6 | 89.6 | 81.1 | 86.9 |
表5:在不同推理配置下的AndroidControl准确率。所有UIShift模型在1K样本上训练, k = 1 k=1 k=1,最后一行除外,使用 k = 4 k=4 k=4。
| 模型 | 方法 | 是否推理 | | AndroidControl-Low | | | AndroidControl-High | | | 训练 | 推理 | 类型 | GR | SR | 类型 | GR | SR
| UIShift-3B | SFT | N | N | 95.6 | 9.4 | 28.0 | 67.0 | 7.5 | 11.3 |
| | RL | Y | Y | 93.1 | 87.6 | 82.1 | 79.6 | 59.9 | 50.1 |
| | | Y | N | 91.2 | 88.7 | 80.7 | 78.2 | 60.9 | 49.7 |
| | | N | N | 96.9 | 88.6 | 85.4 | 78.8 | 60.8 | 50.0 |
| UIShift-7B | SFT | N | N | 96.8 | 23.3 | 38.9 | 70.8 | 15.2 | 20.4 |
| | RL | Y | Y | 94.0 | 88.6 | 83.1 | 75.7 | 71.0 | 54.7 |
| | | Y | N | 97.3 | 88.3 | 85.7 | 81.1 | 65.2 | 54.3 |
| | | N | N | 90.9 | 88.4 | 79.8 | 81.7 | 65.0 | 54.2 |
| | | N | N | 97.4 | 88.4 | 85.9 | 81.7 | 66.8 | 56.1 |
鉴于1K样本的训练时间差异,我们得出结论:无推理训练提供了一种高效且有效的策略,不会影响泛化性能。
4.4 比较训练任务
我们将基于UI转换训练的模型与基于注释依赖任务——Task Automation Low和Task Automation High——的模型在AndroidControl和ScreenSpot基准测试上的表现进行比较。如表6所示,在ScreenSpot上,所有三种训练任务在3B和7B模型上都实现了相当的定位性能。值得注意的是,在完全无推理配置下,一步UI转换变体略微优于基于指令的基线。如
表6:三种训练任务在不同推理设置下的ScreenSpot准确率比较。
| 尺寸 | 任务 | 是否推理 | 移动端 | 桌面端 | 网页端 | 平均 | ||||
|---|---|---|---|---|---|---|---|---|---|---|
| 训练 | 推理 | 文本 | 图标 | 文本 | 图标 | 文本 | 图标 | |||
| 3B | Task Auto. (Low) | Y | N | 94.5 | 73.8 | 84.5 | 61.4 | 80.4 | 62.1 | 77.8 |
| Y | Y | 95.6 | 74.7 | 89.7 | 64.3 | 85.2 | 68.0 | 81.1 | ||
| Task Auto. (High) | Y | N | 94.5 | 73.4 | 85.6 | 61.4 | 80.9 | 64.6 | 78.4 | |
| Y | Y | 95.2 | 75.1 | 90.2 | 65.7 | 85.7 | 70.9 | 81.9 | ||
| UI 转换 ( k = 1 ) (k=1) (k=1) | Y | Y | 94.5 | 73.8 | 85.1 | 89.2 | 85.2 | 69.4 | 80.9 | |
| Y | N | 94.1 | 74.2 | 84.5 | 61.4 | 82.2 | 66.0 | 78.8 | ||
| N | N | 95.2 | 74.7 | 86.6 | 62.1 | 82.2 | 66.5 | 79.6 | ||
| 7B | Task Auto. (Low) | Y | N | 96.7 | 83.0 | 87.6 | 70.7 | 89.6 | 79.6 | 85.9 |
| Y | Y | 97.1 | 80.8 | 90.7 | 71.4 | 90.9 | 77.7 | 86.1 | ||
| Task Auto. (High) | Y | N | 96.7 | 85.2 | 86.1 | 73.6 | 88.3 | 80.6 | 86.3 | |
| Y | Y | 96.3 | 82.1 | 90.2 | 75.0 | 90.4 | 77.2 | 86.3 | ||
| UI 转换 ( k = 1 ) (k=1) (k=1) | Y | Y | 97.1 | 82.1 | 90.2 | 89.7 | 91.3 | 79.1 | 86.6 | |
| Y | N | 97.1 | 83.8 | 84.5 | 73.6 | 89.1 | 80.6 | 86.1 | ||
| N | N | 96.7 | 85.2 | 87.6 | 73.6 | 89.6 | 81.1 | 86.9 | ||
| 表7:三种训练任务在不同推理设置下的AndroidControl准确率比较。 |
| 尺寸 | 训练任务 | 是否推理 (训练) | AndroidControl-Low | AndroidControl-High | ||
|---|---|---|---|---|---|---|
| 推理: N \boldsymbol{N} N | 推理: Y \boldsymbol{Y} Y | 推理: N \boldsymbol{N} N | 推理: Y \boldsymbol{Y} Y | |||
| 3B | Task Auto. (Low) | Y | 85.2 | 85.4 | 34.6 | 35.5 |
| Task Auto. (High) | Y | 84.4 | 84.8 | 49.3 | 49.4 | |
| UI 转换 ( k = 1 ) (k=1) (k=1) | Y | 80.7 | 82.1 | 49.7 | 50.1 | |
| UI 转换 ( k = 1 ) (k=1) (k=1) | N | 85.4 | - | 50.0 | - | |
| 7B | Task Auto. (Low) | Y | 85.5 | 86.4 | 47.6 | 48.3 |
| Task Auto. (High) | Y | 83.8 | 80.8 | 55.4 | 56.1 | |
| UI 转换 ( k = 1 ) (k=1) (k=1) | Y | 85.7 | 83.1 | 54.3 | 54.7 | |
| UI 转换 ( k = 1 ) (k=1) (k=1) | N | 79.8 | - | 54.2 | - | |
| UI 转换 ( k = 4 ) (k=4) (k=4) | N | 85.9 | - | 56.1 | - |
如表7所示,依赖注释的任务在其各自的领域内基准测试中表现出色:Task Automation Low在AndroidControl-Low上,Task Automation High在AndroidControl-High上。然而,我们观察到,当在更具有挑战性的AndroidControl-High上评估时,训练于较简单的Task Automation Low上的模型表现出有限的泛化能力,这需要更广泛的任务级理解。相比之下,UI转换在两个任务自动化任务中表现出强大且平衡的性能,与甚至超过依赖注释的基线相匹配。我们将此归因于任务公式:模型接收当前状态 S t S_{t} St和未来状态 S t + k S_{t+k} St+k作为纯粹的视觉目标。这使模型能够专注于全局屏幕级比较和感知。与Task Automation Low和High相比,其中模型必须将当前UI屏幕与代表一步或 k k k步目标的文本指令对齐,UI转换提供了UI状态之间的更直接的视觉比较,从而消除了屏幕-文本对齐的需要。这些结果突显了UI转换在无需额外注释的情况下提供强大性能,使其成为训练特定GUI模型的有效且可扩展的替代方案。
4.5 k步UI转换的有效性
k步UI转换采用当前UI状态 S t S_{t} St和未来状态 S t + k S_{t+k} St+k,并训练模型预测从 S t S_{t} St到 S t + k S_{t+k} St+k路径中的初始动作,即导致 S t + 1 S_{t+1} St+1的动作。通过调整k,这种公式可以适应步骤级和任务级预测。我们在五个基准测试中使用1K训练样本评估不同的k值如何影响模型性能,并额外评估增加数据规模至2K( k = 1 k=1 k=1)的效果。如表1所示,使用1K训练样本时, k = 4 k=4 k=4在AndroidControl-Low和AndroidControlHigh上达到最高的准确率,但在ScreenSpot-Pro(附录B)上显示出轻微的性能下降。同时, k = 1 k=1 k=1在所有定位基准测试中表现出更稳定的性能。当数据规模增加到2K且 k = 1 k=1 k=1时,所有基准测试的性能一致提升。值得注意的是,AndroidControl-Low的准确率提高了 6.2 % 6.2 \% 6.2%。我们将这一改进归因于1步UI转换公式与AndroidControl-Low本质之间的对齐,因为每个步骤指令对应于一个一步文本目标。这些结果表明,选择k是一个关键因素,应与目标任务的粒度和结构保持一致。
5 结论
收集带有任务注释的GUI轨迹既昂贵又容易出错,这限制了监督微调在指令数据上的可扩展性。在本工作中,我们提出了UIShift,这是一种自监督的单阶段RL框架,使用GRPO在
k
k
k-步UI转换任务上微调特定于GUI的VLMs。通过预测将UI状态
S
t
S_{t}
St移动到
S
t
+
1
S_{t+1}
St+1的第一个动作,给定这对
(
S
t
,
S
t
+
k
)
\left(S_{t}, S_{t+k}\right)
(St,St+k),模型学习将屏幕级别的视觉差异映射到低级动作。该目标使其能够在没有额外标签的情况下泛化到GUI定位和任务自动化,消除注释成本,并解锁大规模未标注的GUI转换数据集。无论是在训练还是推理过程中都没有推理提示,UIShift-7B-2K在五个静态基准测试中优于依赖注释的基线,表明UI转换为GUI任务泛化提供了强大的学习信号。
本研究有两个主要局限性。首先,由于计算资源限制,我们仅在1K/2K样本上训练;评估性能随更大数据集的扩展是下一步工作。其次,我们的评估局限于静态基准;未来的工作将扩展到动态基准,如AndroidWorld [20]。
参考文献
[1] 白帅、陈克勤、刘雪静、王佳琳、葛文斌、宋思博、邓凯、王鹏、汪世杰、唐军等。2025年。Qwen2.5-vl技术报告。arXiv预印本arXiv:2502.13923(2025)。
[2] David Brandfonbrener、Ofir Nachum和Joan Bruna。2023年。逆动力学预训练学习多任务模仿的良好表示。NeurIPS会议论文。
[3] 陈哲、吴建南、王文海、苏伟杰、陈国、邢森、钟木研、张庆龙、朱西洲、陆乐伟等。2024年。Internvl:扩大视觉基础模型并对其通用视觉语言任务进行对齐。IEEE/CVF计算机视觉与模式识别会议论文集。24185-24198。
[4] 程侃智、孙启淑、楚有刚、许芳志、李炎涛、张建兵、吴志勇。2024年。SeeClick:利用GUI定位实现高级视觉GUI代理。ACL(1)。计算语言学协会,9313-9332。
[5] 戴高烈、江士琦、曹婷、李远春、杨宇青、谭睿、李墨、邱丽丽。2025年。推进移动GUI代理:一种验证驱动的实际部署方法。arXiv预印本arXiv:2503.15937(2025)。
[6] Biplab Deka、Zifeng Huang、Chad Franzen、Joshua Hibschman、Daniel Afergan、Yang Li、Jeffrey Nichols和Ranjitha Kumar。2017年。Rico:用于构建数据驱动设计应用的移动应用程序数据集。UIST会议论文。ACM出版社,845-854。
[7] 高龙溪、张立、王世和、王尚光、李远春、徐梦伟。2024年。Mobileviews:一个大规模的移动GUI数据集。arXiv预印本arXiv:2409.14337(2024)。
[8] 哥博宇、王若涵、郑博远、谢亚男、常成、舒义恒、孙欢、苏禹。2024年。像人类一样导航数字世界:通用视觉定位GUI代理。arXiv预印本arXiv:2410.05243(2024)。
[9] 郭大雅、杨德健、张浩伟、宋俊晓、张若宇、许若欣、朱启豪、马世荣、王培毅、毕晓等。2025年。Deepseek-r1:通过强化学习激励LLMs的推理能力。arXiv预印本arXiv:2501.12948(2025)。
[10] 洪文仪、王维翰、吕清松、许佳正、余文猛、季俊辉、王燕、王志涵、董昱潇、丁明、唐杰。2024年。CogAgent:一种GUI代理的视觉语言模型。CVPR会议论文。IEEE出版社,14281-14290。
[11] Nathan Lambert、Jacob Morrison、Valentina Pyatkin、黄盛一、Hamish Ivison、Faeze Brahman、Lester James V Miranda、Alisa Liu、Nouha Dziri、梁善等。2024年。T $" ulu 3:推动开放语言模型后训练的前沿。arXiv预印本arXiv:2411.15124(2024)。
[12] 李开欣、孟子阳、林宏战、罗子扬、田玉辰、马静、黄志勇、蔡书晟。2025年。Screenspot-pro:专业高分辨率计算机使用的GUI定位。arXiv预印本arXiv:2504.07981(2025)。
[13] 李伟、William E. Bishop、Alice Li、Christopher Rawles、Folawiyo Campbell-Ajala、Divya Tyamagundlu、Oriana Riva。2024年。数据规模对UI控制代理的影响。NeurIPS会议论文。
[14] 李洋、李钢、何鲁恒、郑靖杰、李红、关志伟。2020年。Widget Captioning:生成移动用户界面元素的自然语言描述。EMNLP(1)。计算语言学协会,5495-5510。
[15] 林清明宏、李林杰、高迪飞、杨正元、吴诗伟、白泽淳、雷威先、王丽娟、Mike Zheng Shou。2024年。Showui:一种适用于GUI视觉代理的视觉-语言-动作模型。arXiv预印本arXiv:2411.17465(2024)。
[16] 刘雨航、李鹏翔、谢聪凯、胡赛维、韩晓天、张胜宇、杨红霞、吴飞。2025年。Infigui-r1:从反应型演员到深思熟虑的推理者,推动多模态GUI代理的进步。arXiv预印本arXiv:2504.14239(2025)。
[17] 卢全锋、邵文奇、刘子涛、孟凡青、李博文、陈波轩、黄思源、张凯鹏、乔宇、罗平。2024年。GUI Odyssey:跨应用移动设备GUI导航的综合数据集。arXiv预印本arXiv:2406.08451(2024)。
[18] 卢正曦、柴宇翔、郭亚宣、尹喜、刘亮、王浩、肖汉、任帅、熊冠景、李洪声。2025年。Ui-r1:通过强化学习增强GUI代理的动作预测。arXiv预印本arXiv:2503.21620(2025)。
[19] 秦玉佳、叶一宁、方俊杰、王浩鸣、梁世豪、田世举、张俊达、李云新、黄世觉、李运鑫等。2025年。UI-TARS:开创原生代理自动GUI交互。arXiv预印本arXiv:2501.12326(2025)。
[20] Rawles Christopher、Clinckemaillie Sarah、Chang Yifan、Waltz Jonathan、Lau Gabrielle、Fair Marybeth、Li Alice、Bishop William、Li Wei、Campbell-Ajala Folawiyo等。2024年。Androidworld:自主代理的动态基准环境。arXiv预印本arXiv:2405.14573(2024)。
[21] Rawles Christopher、Li Alice、Rodriguez Daniel、Riva Oriana、Lillicrap Timothy。2023年。Androidinthewild:一个大规模的安卓设备控制数据集。神经信息处理系统进展36卷(2023),59708-59728。
[22] Schulman John、Wolski Filip、Dhariwal Prafulla、Radford Alec、Klimov Oleg。2017年。近端策略优化算法。arXiv预印本arXiv:1707.06347(2017)。
[23] 邵志鸿、王佩怡、朱启昊、许若欣、宋俊晓、毕晓、张浩伟、张铭川、李YK、吴Y等。2024年。Deepseekmath:推动开放式语言模型数学推理的极限。arXiv预印本arXiv:2402.03300(2024)。
[24] 申浩展、刘鹏、李景诚、方春新、马一博、廖嘉佳、沈桥利、张子伦、赵康家、张倩倩等。2025年。Vlm-r1:一个稳定且可推广的大规模视觉语言模型。arXiv预印本arXiv:2504.07615(2025)。
[25] Kimi团队、杜昂昂、殷博鸿、邢宝卫、屈博文、王博文、陈城、张晨霖、杜晨庄、崔巍等。2025年。Kimi-vl技术报告。arXiv预印本arXiv:2504.07491(2025)。
[26] 天洋、杨思哲、曾嘉、王萍、林大华、董昊、庞江淼。2024年。预测性逆动力学模型是可扩展的机器人操作学习者。arXiv预印本arXiv:2412.15109(2024)。
[27] 王犇、李刚、周欣、陈周蓉、Grossman Tovi、李阳。2021年。Screen2Words:使用多模态学习的自动移动UI摘要。UIST会议论文。ACM出版社,498-510。
[28] 王维汉、吕清松、余文猛、洪文仪、祁吉、王燕、季俊辉、杨卓毅、赵磊、宋锡萱、许佳正、陈克勤、徐斌、李菊子、董宇潇、丁明、唐杰。2024年。CogVLM:预训练语言模型的视觉专家。NeurIPS会议论文。
[29] 温浩、李远春、刘国宏、赵山会、余韬、李托比Jia-Jun、姜世奇、刘云浩、张雅琴、刘云新。2024年。AutoDroid:由LLM驱动的Android任务自动化。MobiCom会议论文。ACM出版社,543-557。
[30] 吴秦柱、许维凯、刘伟、谭涛、刘建峰、李昂、李建、王彬、商朔。2024年。MobileVLM:一种更好的内部和跨UI理解的视觉语言模型。EMNLP(Findings)会议论文。计算语言学协会,1023110251。
[31] 吴志勇、吴振宇、徐方志、王亚军、孙启淑、贾成友、程侃智、丁子晨、陈立恒、Paul Pu Liang等。2024年。Os-atlas:通用GUI代理的基础动作模型。arXiv预印本arXiv:2410.23218(2024)。
[32] 夏小波、罗润。2025年。Gui-r1:一种通用的R1风格视觉语言动作模型用于GUI代理。arXiv预印本arXiv:2504.10458(2025)。
[33] 徐亿恒、王泽坤、王军利、卢敦杰、谢天宝、Amrita Saha、Doyen Sahoo、余涛、Caiming Xiong。2024年。Aguvis:统一纯视觉代理用于自主GUI交互。arXiv预印本arXiv:2412.04454(2024)。
[34] 杨雨浩、王悦、李东旭、罗子扬、陈贝、黄超、李军楠。2024年。Aria-UI:GUI指令的视觉定位。arXiv预印本arXiv:2412.16256(2024)。
[35] 姚元、余天宇、张敖、王崇义、崔俊博、朱红继、蔡天池、李昊宇、赵伟林、何志辉等。2024年。Minicpm-v:手机上的GPT-4V水平MLLM。arXiv预印本arXiv:2408.01800(2024)。
[36] 俞恩、林康恒、赵良、尹纪盛、魏亚娜、彭元广、魏浩然、孙建剑、韩春蕊、葛政等。2025年。Perception-R1:开创性感知政策与强化学习。arXiv预印本arXiv:2504.07954(2025)。
[37] Samuel Zapolsky和Evan M. Drumwright。2017年。带刚性接触和摩擦的逆动力学。Auton. Robots 41, 4(2017),831-863。
[38] 张驰、杨昭、刘佳璇、李亚丹、李玉达、陈新、黄泽彪、傅斌、余刚。2025年。AppAgent:作为智能手机用户的多模态代理。CHI会议论文。ACM出版社,70:1-70:20。
[39] 张立、高龙溪、徐梦伟。2025年。链式推理是否有助于移动GUI代理?一项实证研究。arXiv预印本arXiv:2503.16788(2025)。
A 训练超参数
我们在所有任务中使用固定的超参数集以确保公平比较。详细信息见表8。
表8:所有GRPO训练使用的超参数设置。
| 超参数 | 值 |
|---|---|
| learning_rate | 从1e-6到0 |
| temperature | 0.9 |
| num_generations | 8 |
| num_train_epochs | 8 |
| max_prompt_length | 1024 |
| max_completion_length | 256 |
| per_device_train_batch_size | 2 |
| gradient_accumulation_steps | 8 |
| ϵ \epsilon ϵ(裁剪参数) | 0.2 |
| β \beta β(KL系数) | 0.04 |
B 评估结果
表9:ScreenSpot-Pro上的GUI定位准确率。UIShift和指令依赖训练的最佳得分分别加粗显示。
| 模型 | CAD | 开发 | 创意 | 科学 | 办公 | OS | 平均 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 文本 | 图标 | 文本 | 图标 | 文本 | 图标 | 文本 | 图标 | 文本 | 图标 | 文本 | 图标 | ||
| Zero Shot | |||||||||||||
| Qwen2.5-VL-7B [1] | 18.8 | 1.6 | 48.1 | 6.9 | 26.7 | 6.3 | 52.1 | 5.5 | 48.6 | 17 | 33.6 | 13.5 | 25.8 |
| 使用GRPO的UI转换(UIShift,自监督)对于 k ∈ { 1 , 2 , 3 , 4 } k \in\{1,2,3,4\} k∈{1,2,3,4} | |||||||||||||
| UIShift-7B-1K ( k = 1 ) (k=1) (k=1) | 21.8 | 1.6 | 50.7 | 9.0 | 31.3 | 7.0 | 51.4 | 5.5 | 48.0 | 18.9 | 41.1 | 14.6 | 27.8 |
| UIShift-7B-2K ( k = 1 ) (k=1) (k=1) | 21.8 | 3.1 | 49.4 | 6.9 | 35.9 | 6.3 | 52.1 | 6.4 | 52.5 | 20.8 | 37.4 | 10.1 | 28.2 |
| UIShift-7B-1K ( k = 2 ) (k=2) (k=2) | 21.8 | 1.6 | 50.7 | 6.9 | 30.3 | 7.0 | 50.7 | 4.6 | 49.7 | 20.8 | 37.4 | 15.7 | 27.4 |
| UIShift-7B-1K ( k = 3 ) (k=3) (k=3) | 19.8 | 0.0 | 48.7 | 7.6 | 29.8 | 7.7 | 52.8 | 4.6 | 52.0 | 22.6 | 38.3 | 10.1 | 27.2 |
| UIShift-7B-1K ( k = 4 ) (k=4) (k=4) | 20.3 | 3.1 | 50.0 | 6.9 | 27.3 | 5.6 | 49.3 | 6.4 | 44.1 | 15.1 | 37.4 | 12.4 | 25.7 |
| 指令依赖训练 | |||||||||||||
| CogAgent-18B [10] | 7.1 | 3.1 | 14.9 | 0.7 | 9.6 | 0.0 | 22.2 | 1.8 | 13.0 | 0.0 | 5.6 | 0.0 | 7.7 |
| SeeClick-9.6B [4] | 2.5 | 0.0 | 0.6 | 0.0 | 1.0 | 0.0 | 3.5 | 0.0 | 1.0 | 0.0 | 2.8 | 0.0 | 1.1 |
| OS-Atlas-7B [31] | 12.2 | 4.7 | 33.1 | 1.4 | 28.8 | 2.8 | 37.5 | 7.3 | 33.9 | 5.7 | 27.1 | 4.5 | 18.9 |
| ShowUI-2B [15] | 2.5 | 0.0 | 16.9 | 1.4 | 9.1 | 0.0 | 13.2 | 7.3 | 15.3 | 7.5 | 10.3 | 2.2 | 7.7 |
| UGround-7B [8] | 14.2 | 1.6 | 26.6 | 2.1 | 27.3 | 2.8 | 31.9 | 2.7 | 31.6 | 11.3 | 17.8 | 0.0 | 16.5 |
| UI-TARS-7B [19] | 20.8 | 9.4 | 58.4 | 12.4 | 50.0 | 9.1 | 63.9 | 31.8 | 63.3 | 20.8 | 30.8 | 16.9 | 35.7 |
| UI-R1-3B [18] | 11.2 | 6.3 | 22.7 | 4.1 | 27.3 | 3.5 | 42.4 | 11.8 | 32.2 | 11.3 | 13.1 | 4.5 | 17.8 |
| UI-R1-E-3B [18] | 37.1 | 12.5 | 46.1 | 6.9 | 41.9 | 4.2 | 56.9 | 21.8 | 65.0 | 26.4 | 32.7 | 10.1 | 33.5 |
| GUI-R1-7B [32] | 23.9 | 6.3 | 49.4 | 4.8 | 38.9 | 8.4 | 55.6 | 11.8 | 58.7 | 26.4 | 42.1 | 16.9 | - |
| InfIGUI-R1-3B [16] | 33.0 | 14.1 | 51.3 | 12.4 | 44.9 | 7.0 | 58.3 | 20.0 | 65.5 | 28.3 | 43.9 | 12.4 | 35.7 |
UIShift模型的训练和评估均未使用推理提示。在ScreenSpot-Pro上,UIShift-7B-2K达到了平均定位准确率 28.2 % 28.2 \% 28.2%,比未经调优的Qwen2.5-VL-7B基线( 25.8 % 25.8 \% 25.8%)提高了 2.4 % 2.4 \% 2.4%。
参考论文:https://arxiv.org/pdf/2505.12493



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











