



作为程序员,咱平时跟数据库打交道的时候,估计都遇到过这种糟心事儿:想从超大表里查点数据、做个分析,要么得硬着头皮写 SQL(要是表结构复杂,join 个七八张表能把人绕晕),要么碰到数据量太大,SQL 跑半天出不来结果,更别说想做个 PCA 降维、异常检测这种复杂分析了 ——SQL 根本不支持啊!
最近看到 CSIRO Data61 团队搞的一个新框架,直接把自然语言转换成查询计划,不用再死磕 SQL,还能轻松搞定大表和复杂分析,简直是咱们这些不想在 SQL 上耗时间的人的福音。今天就跟大伙儿好好唠唠这个框架,到底牛在哪儿。
先说说咱们之前用的那些方法有多坑。传统的 Text-to-SQL 虽然能把自然语言转成 SQL,但 SQL 的毛病它一点没落下:非技术同事用不了(光记语法就够喝一壶),大表处理效率低(数据量一上来就卡壳,还得搞复杂的分区),复杂分析做不了(想跑个 PCA?门儿都没有)。还有些方法直接把整个表喂给大模型,但模型上下文长度就那么点,大表只能截断或者压缩,结果要么分析不完整,要么数据丢了关键信息,纯属白费功夫。
那这个新框架是怎么解决这些问题的呢?它叫Tree-Driven Sequential Operation QA System(TSO),核心思路不是生成 SQL,而是把自然语言查询直接转成「查询计划」—— 就像给数据处理画了个流程图,从原始表(叶子节点)开始,一步步做筛选、关联、聚合这些操作,中间结果是中间节点,最后到根节点就是答案。这样一来,既避开了 SQL 的限制,又能灵活加各种复杂分析功能。
举个具体的例子,比如想查 “欧洲有哪些国家至少有 3 家汽车制造商”,涉及 CONTINENTS、COUNTRIES、CAR_MAKERS 三张表。要是用 SQL,通常得先把三张表全关联起来,再过滤欧洲的国家,中间数据量很大;但 TSO 的查询计划会先关联 COUNTRIES 和 CONTINENTS,立刻过滤出欧洲的国家,再跟 CAR_MAKERS 关联 —— 相当于提前 “瘦身”,后续操作效率直接拉满。这一步的优化,对大表来说简直是救命,能少处理好几倍的数据。
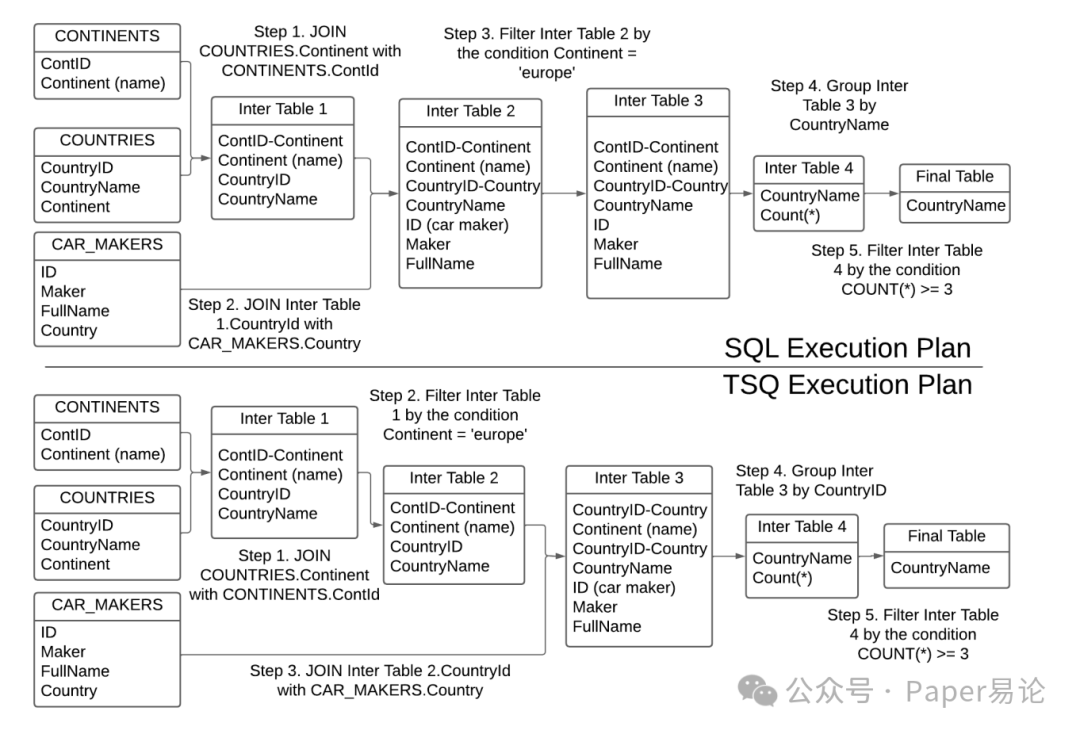
图 1:树形结构查询计划示例
(图 1 里左边是 SQL 执行计划,右边是 TSO 的树形计划,对比一下就能看出来,TSO 早过滤早轻松,中间表体积小多了)
当然,想生成这种高效的查询计划,不是拍脑袋就能成的。因为要确定最优的操作顺序,本质上是个 NP-hard 问题 —— 可能的操作组合太多,根本不可能穷举。所以 TSO 用了大模型(LLM)加 ReAct 框架的思路,让模型一步步 “思考”:先看当前有哪些表和中间结果,判断下一步该做什么操作(比如该关联哪两张表,该过滤哪个条件),做完再观察结果对不对,不对还能回溯调整。这种迭代的方式,既不用让模型一次性想出所有步骤(避免上下文爆炸),又能保证每一步都朝着目标走。
还有个特别关键的点:怎么处理成千上万列的超大表?比如农业领域的数据集,一张表可能有 8000 多列,直接给模型看 schema 都超 token 限制。TSO 搞了个三级向量索引,先给每列生成描述(比如 “这列记录的是种植前 1 年的作物轮作情况”),再把列聚类,给每个聚类生成描述,最后给整个表生成描述,然后把这些描述转成向量存起来。用户查的时候,先匹配表向量,找到可能相关的表;再匹配聚类向量,缩小范围;最后匹配列向量,精准定位需要的列。这样一来,模型只需要看少量相关的列,完全不用管那些无关的,上下文问题直接解决。
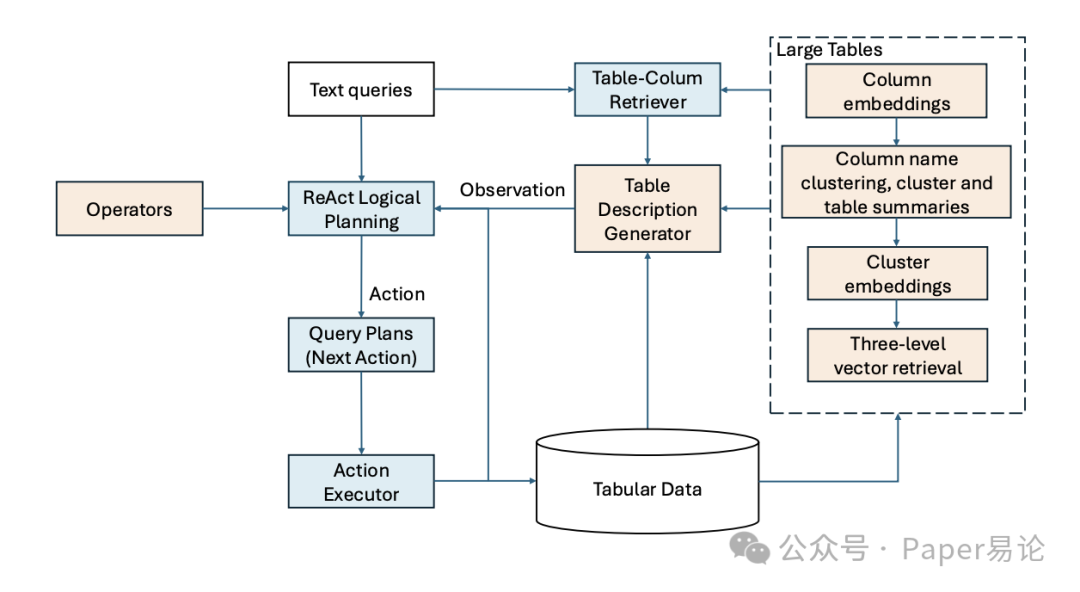
图 2:TSO 系统架构
(图 2 能清楚看到三级向量检索的流程:从用户查询到表、聚类、列的匹配,再到 ReAct 框架生成查询计划,整个链路很清晰)
光说不练假把式,咱们看看实验结果。团队用了两个数据集测试:一个是经典的 Spider 数据集(测传统表查询),一个是农业数据集(26 万行、8000 多列,测大表和复杂分析)。
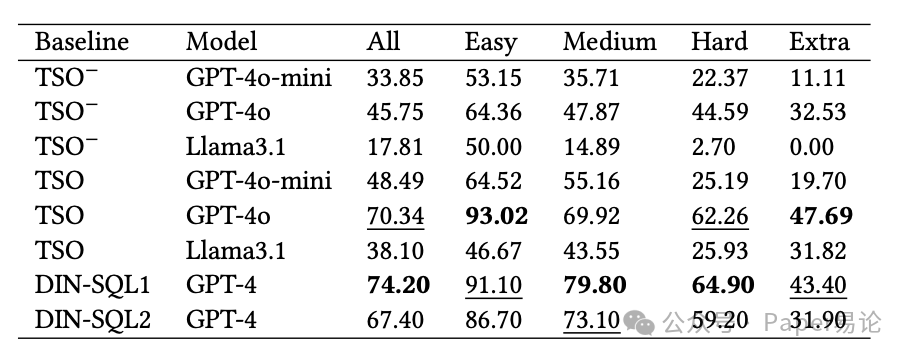
先看 Spider 数据集的结果,对比了 TSO 和目前排名靠前的 DIN-SQL。表格里能看到,用 GPT-4o 的 TSO,在 Easy 难度下准确率 93.02%,比 DIN-SQL 还高;Extra Hard 难度 47.69%,虽然比 DIN-SQL(43.40%)稍高一点,但要知道,TSO 没用到 Spider 的训练数据,完全靠模型的通用能力 —— 这已经很能打了。而且要是不给模型看表结构(TSO⁻),准确率直接掉一大截,比如 GPT-4o 从 70.34% 掉到 45.75%,这也说明,让模型知道表结构有多重要。
表 1:Spider 数据集上的实验结果,加粗是最优,下划线是次优,TSO 在 Easy 和 Extra Hard 上表现很亮眼
再看农业数据集,这个更能体现 TSO 的优势。团队设计了 20 个查询,从简单的 “计算平均谷物产量” 到复杂的 “用卫星数据做 PCA 降维” 都有。结果 16 个查对了,4 个错了,错的原因也挺有意思,能帮咱们避坑:
比如有个问题是 “列出种植前 1 年记录的不同作物轮作情况”,本来该找 “METADom_Crop_rotation_minus_1_sub_cropWheat” 这列,但模型给这列的描述写成了 “种植前 1 天”—— 差了个 “年” 和 “天”,直接找错列了。这说明列描述的准确性太重要了,以后做类似系统,得加个校验步骤,避免这种低级错误。
还有个问题是 “种植后前 80 天的累积蒸散量和谷物产量有什么关系”,用户没说清楚要关联哪几个产量列,模型只找了一个,漏了两个 —— 这就是自然语言的歧义问题,要是能让模型主动问用户 “你指的是哪几个产量指标?”,准确率肯定能再提一提。
最难的两个问题,比如 “评估高涝害试验中土壤特性的影响”,模型想用 Python 代码解决,但卡在调试上了,没在最大迭代次数内出结果。这说明复杂分析场景下,代码生成的稳定性还得加强,可能需要加个代码模板或者错误重试机制。
不过总的来说,能在 8000 多列的大表上搞定 PCA、异常检测这些操作,还能保持这么高的准确率,TSO 已经甩传统方法几条街了。
最后再唠两句,这个框架给咱们的启发其实挺多的:以后做数据查询系统,不一定非得盯着 SQL 不放,查询计划这种更灵活的方式,既能兼容传统数据库,又能扩展复杂分析;而且大模型的迭代思考能力,比让它一次性出结果靠谱多了,尤其是处理复杂问题的时候。对咱们程序员来说,以后不管是自己做工具,还是给业务同事搭查询平台,这个思路都能用得上 —— 毕竟谁不想少写点 SQL,多省点时间摸鱼呢?


















 482
482

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











