







转载自:https://i-blog.csdnimg.cn/blog_migrate/fa180072f4c9d4f9fb019e6e96d29e5c.png
K-Means算法的基本思想是初始随机给定K个簇中心,按照最邻近原则把待分类样本点分到各个簇。然后按平均法重新计算各个簇的质心(这个点可以不是样本点),从而确定新的簇心。一直迭代,直到簇心的移动距离小于某个给定的值。
K-Means聚类算法主要分为三个步骤:
(1)第一步是为待聚类的点寻找聚类中心
(2)第二步是计算每个点到聚类中心的距离,将每个点聚类到离该点最近的聚类中去
(3)第三步是计算每个聚类中所有点的坐标平均值,并将这个平均值作为新的聚类中心
反复执行(2)、(3),直到聚类中心不再进行大范围移动或者聚类次数达到要求为止
下图展示了对n个样本点进行K-means聚类的效果,这里k取2:
(a)未聚类的初始点集
(b)随机选取两个点作为聚类中心
(c)计算每个点到聚类中心的距离,并聚类到离该点最近的聚类中去
(d)计算每个聚类中所有点的坐标平均值,并将这个平均值作为新的聚类中心
(e)重复(c),计算每个点到聚类中心的距离,并聚类到离该点最近的聚类中去
(f)重复(d),计算每个聚类中所有点的坐标平均值,并将这个平均值作为新的聚类中心

k均值常用的邻近度,质心和目标函数的选择:
邻近度函数:曼哈顿距离。质心:中位数。目标函数:最小化对象到其簇质心的距离和
邻近度函数:平方欧几里德距离。质心:均值。目标函数:最小化对象到其簇质心的距离的平方和
邻近度函数:余弦。质心:均值。最大化对象与其质心的余弦相似度和
邻近度函数:Bregman 散度。质心:均值。目标函数:最小化对象到其簇质心的Bregman散度和
算法实现:
我们以k-means算法为例来实现划分聚类。该算法的复杂度为O(KnI),其中I是迭代次数。这种算法的一个变体是依次分析每个数据点,而且一旦有数据点被重新分配就更新聚类中心,反复的在数据点中循环直到解不再变化。k-means算法的搜索过程局限于全部可能的划分空间的一个很小的部分。因此有可能因为算法收敛到评分函数的局部而非全局最小而错过更好的解。当然缓解方法可以通过选取随机起始点来改进搜索(我们例子中的KMPP算法),或者利用模拟退火等策略来改善搜索性能。因此,从这个角度来理解,聚类分析实质上是一个在庞大的解空间中优化特定评分函数的搜索问题。
不多说了,直接上代码吧!!!
k-means算法:
for k = 1, … , K 令 r(k) 为从D中随机选取的一个点;
while 在聚类Ck中有变化发生 do
形成聚类:
For k = 1, … , K do
Ck = { x ∈ D | d(rk,x) <= d(rj,x) 对所有j=1, … , K, j != k};
End;
计算新聚类中心:
For k = 1, … , K do
Rk = Ck 内点的均值向量
End;
End;
java实现:
具体实现部分因为有Apache Commons Math的现成代码,秉着Eric Raymond的TAOUP中的极大利用工具原则,我没有写k-means的实现,而是直接利用Apache Commons Math中的k-means plus plus代码来作为例子。
具体如何测试这一算法,给出了测试代码如下:
 private
static
void
testKMeansPP()
{
private
static
void
testKMeansPP()
{2
3
//ori is sample as n instances with m features, here n=8,m=24
5
 int ori[][] = {{2,5},{6,4},{5,3},{2,2},{1,4},{5,2},{3,3},{2,3}};
int ori[][] = {{2,5},{6,4},{5,3},{2,2},{1,4},{5,2},{3,3},{2,3}};6
7
int n = 8;8
9
Collection<EuclideanIntegerPoint> col = new ArrayList<EuclideanIntegerPoint>();10
11
for(int i=0;i<n;i++){12
13
EuclideanIntegerPoint ec = new EuclideanIntegerPoint(ori[i]);14
15
col.add(ec);16
17
 }
}18
19
KMeansPlusPlusClusterer<EuclideanIntegerPoint> km = new KMeansPlusPlusClusterer<EuclideanIntegerPoint>(new Random(n));20
21
List<Cluster<EuclideanIntegerPoint>> list = new ArrayList<Cluster<EuclideanIntegerPoint>>();22
23
list = km.cluster(col, 3, 100);24
25
output(list);26
27
 }
}
28

29
private
static
void
output(List
<
Cluster
<
EuclideanIntegerPoint
>>
list)
{30
31
int ind = 1;32
33
Iterator<Cluster<EuclideanIntegerPoint>> it = list.iterator();34
35
while(it.hasNext()){36
37
Cluster<EuclideanIntegerPoint> cl = it.next();38
39
System.out.print("Cluster"+(ind++)+" :");40
41
List<EuclideanIntegerPoint> li = cl.getPoints();42
43
Iterator<EuclideanIntegerPoint> ii = li.iterator();44
45
while(ii.hasNext()){46
47
EuclideanIntegerPoint eip = ii.next();48
49
System.out.print(eip+" ");50
51
}52
53
System.out.println();54
55
}56
57
}
58
59
/**60
61
*@param args62
63
*/
64
65
public
static
void
main(String[] args)
{66
67
//testHierachicalCluster();68
69
testKMeansPP();70
71
//testBSAS();72
73
//testMBSAS();74
75
}
76
77
R语言实现:
> x<-iris[,1:4]
> km <- kmeans(x,3)
> km


> plot(x, col = km$cluster)

算法优缺点分析:
k-means算法比较简单,但也有几个比较大的缺点:
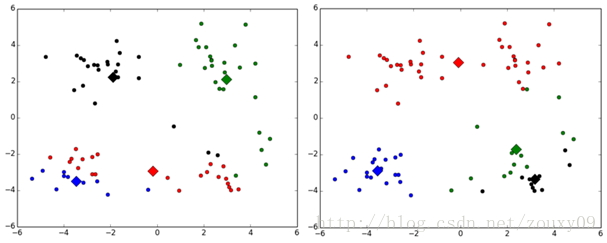
(1)k值的选择是用户指定的,不同的k得到的结果会有挺大的不同,如下图所示,左边是k=3的结果,这个就太稀疏了,蓝色的那个簇其实是可以再划分成两个簇的。而右图是k=5的结果,可以看到红色菱形和蓝色菱形这两个簇应该是可以合并成一个簇的:
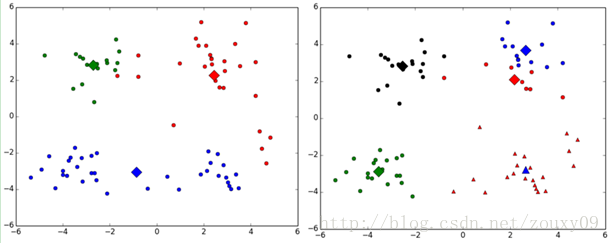
(2)对k个初始质心的选择比较敏感,容易陷入局部最小值。例如,我们上面的算法运行的时候,有可能会得到不同的结果,如下面这两种情况。K-means也是收敛了,只是收敛到了局部最小值:
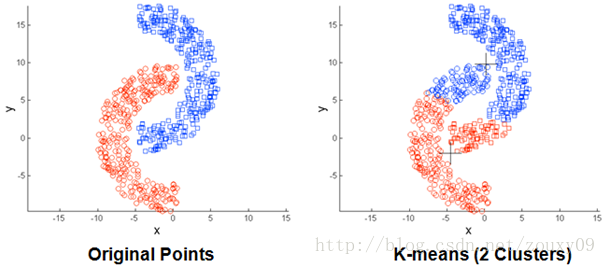
(3)不能处理不同尺寸,不同密度的簇及不能处理非球形的簇:
(4)数据库比较大的时候,收敛会比较慢。
(5)离群值可能有较大干扰(因此要先剔除)
k-means老早就出现在江湖了。所以以上的这些不足也被世人的目光敏锐的捕捉到,并融入世人的智慧进行了某种程度上的改良。例如问题(1)对k的选择可以先用一些算法分析数据的分布,如重心、层次聚类和密度等,然后选择合适的k。而对问题(2),有人提出了另一个成为二分k均值(bisecting k-means)算法,它对初始的k个质心的选择就不太敏感,这个算法我们下一个博文再分析和实现。















 248
248

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









