






 本文详细介绍了Java线程的基本概念,包括线程的不同状态,如新建、就绪、运行、阻塞、等待和终止。此外,文章还着重讲解了synchronized、volatile、CAS以及Java并发工具如CountDownLatch、CyclicBarrier、Phaser、ReadWriteLock、Semaphore、Exchanger和LockSupport的作用和使用。最后讨论了CPU密集型和IO密集型任务的线程配置策略。
本文详细介绍了Java线程的基本概念,包括线程的不同状态,如新建、就绪、运行、阻塞、等待和终止。此外,文章还着重讲解了synchronized、volatile、CAS以及Java并发工具如CountDownLatch、CyclicBarrier、Phaser、ReadWriteLock、Semaphore、Exchanger和LockSupport的作用和使用。最后讨论了CPU密集型和IO密集型任务的线程配置策略。
1、线程的基本概念
1.1、基本概念
线程的状态:
- 新建状态(New)。当一个线程对象被创建但还未调用start()方法来启动线程时,线程处于新建状态。此时线程已经分配了内存空间并初始化完毕,但还没有启动它的执行代码。
- 就绪状态(Runnable)。线程通过调用start()方法进入就绪状态,此时线程已经具备了运行条件,但还没有被分配到CPU,即不一定会被立即执行,此时线程位于线程就绪队列,等待系统为其分配CPU。
- 运行状态(Running)。一旦获取CPU(被JVM选中),线程就进入运行状态,线程的run()方法才开始被执行。在运行状态的线程执行自己的run()方法中的操作,直到调用其他的方法而终止、或者等待某种资源而阻塞、或者完成任务而死亡。
- 阻塞状态(Blocked)。当线程处于阻塞状态时,表示该线程暂时无法获取所需的锁,因此无法继续执行。常见的原因包括等待锁、被其他线程调用了wait()方法、等待输入/输出(I/O)操作完成等。
- 等待状态(Waiting)。当线程处于等待状态时,表示该线程需要等待其他线程通知它去唤醒自己才能继续执行。常见的情况包括等待其他线程的操作、调用了wait()方法而进入等待状态、调用了join()方法等待另一个线程执行完毕等。
- 计时等待状态(Timed Waiting)。和等待状态类似,但是计时等待状态有超时时间,当等待的时间超过了指定的时间后就会自动恢复到Runnable状态。
- 终止状态(Terminated)。线程执行完毕或被中断或被异常退出,该线程到达终止状态。一旦某一线程进入Terminated状态,他就再也不能进入一个独立线程的生命周期了。
1.2、synchronized
synchronized能够在同一时刻最多只有一个线程执行该代码,已达到并发线程同步安全的效果,
synchronized能保证线程的原子性,可见性和有序性
jdk早期版本中,synchronized的底层实现是重量级的,都是去找操作系统去申请锁的地步。
后续版本进行了优化,有个锁升级的过程(无锁->偏向锁->自旋锁->重量级锁)
Java 对象包含3部分内容:对象头、实例数据、填充字节
对象头中的信息如下
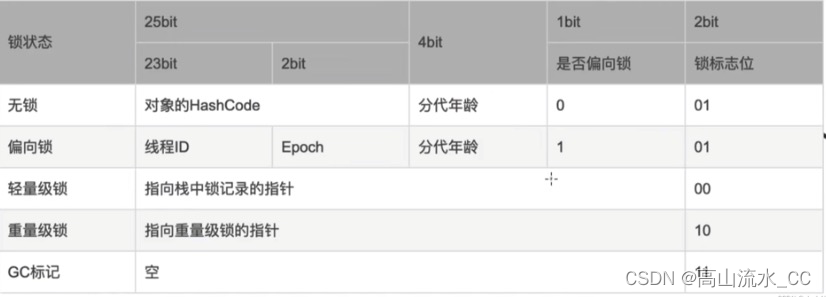
当我们使用sync(Object)时,
偏向锁判断,该位置有标记,是偏向锁,升级到自旋锁,否则存下档前线程ID,执行对应代码块
轻量级锁判断,自旋尝试获取锁,尝试10次还未获取到,就升级重量级锁,否则执行对应代码块
注:JDK1.6前:默认10次自旋,-XX:PreBlockSpin配置,或者超过CPU核数的一半,自动升级重量级锁 。JDK1.6之后,自适应自旋(Adaptive Self Spinning),JVM自动调整;
重量级锁判断,去操作系统申请资源;
1.3、volatile与CAS
volatile使一个变量在多个线程中可见
volatile保证线程的可见性;
voliate读写变量的过程
-
写过程: 当一个线程修改某个voliate变量的值的时候,JMM会把该线程对应的本地内存中的共享变量值刷新到主内存。
-
读过程: 当一个线程读取某个voliate变量的值的时候,JMM会把该线程对应的本地内存置为无效,线程接下来将从主内存读取共享变量。
voliate可见性底层实现原理
-
实际上voliate的可见性实现借助了CPU的lock指令,即在写voliate变量的时候,在该指令前加一个lock指令,这个指令有两个作用: 1)写volatile时处理器会将缓存写回到主内存。 2)一个处理器的缓存写回到主内存会导致其他处理器的缓存失效。(即其他线程缓存该变量地址失效,下次读取时会自动从主存中读取)
voliatile禁止指令重新排序;
CAS
CAS的ABA问题解决,增加版本号
CAS实现原理使用了Unsafe这个类
2、JUC同步工具
CountDownLatch
倒计时门栓,门栓倒计时到0时,门栓就打开
一次性的,计数器的值只能在构造方法中初始化一次
常用方法:countDown()对应数量减1;await()门闩不为0就一直等待,为0就打开;
CountDownLatch countDownLatch = new CountDownLatch(2);
Thread thread1 = new Thread(()->{
try {
Thread.sleep(2000);
System.out.println("thread1 end");
countDownLatch.countDown();
} catch (InterruptedException e) {
e.printStackTrace();
}
});
Thread thread2 = new Thread(()->{
try {
Thread.sleep(1000);
System.out.println("thread2 end");
countDownLatch.countDown();
} catch (InterruptedException e) {
e.printStackTrace();
}
});
thread1.start();
thread2.start();
//等待上面两个线程执行完成
countDownLatch.await();
System.out.println("main end");
执行结果如下:
thread2 end
thread1 end
main endCyclicBarrier
循环栅栏,什么时候人满了就把栅栏推到,出去之后栅栏又重新起来,再来人,满了,推到之后继续;
构造方法中指定的计数器数量N达到了才放过,达到N了才执行
CyclicBarrier cyclicBarrier = new CyclicBarrier(2, ()->{
System.out.println("cyclicBarrier end");
});
for(int i=0;i<10;i++){
final int j =i;
Thread thread = new Thread(()->{
try {
Thread.sleep(new Random().nextInt(10) * 1000);
System.out.println("thread"+j+" end");
cyclicBarrier.await();
} catch (Exception e) {
e.printStackTrace();
}
});
thread.start();
}
System.out.println("main end");
执行结果如下:
main end
thread4 end
thread6 end
cyclicBarrier end
thread3 end
thread2 end
cyclicBarrier end
thread0 end
thread9 end
cyclicBarrier end
thread7 end
thread1 end
cyclicBarrier end
thread8 end
thread5 end
cyclicBarrier end
Phaser
Phaser是一个灵活的同步工具类,它允许多个线程在一个或多个屏障(barrier points)上进行协调,可以把Phaser想象成一个多线程聚会的组织者,它负责确保所有参与的线程都到达某个阶段后再一起进行下一步
Phaser 常见用途:
多阶段任务:Phaser 可以用于将一个任务分解为多个阶段,每个阶段由多个线程并行执行,等待所有线程完成当前阶段后再进入下一个阶段。
多阶段并行算法:Phaser 可以用于实现多阶段的并行算法,每个阶段的计算可以由多个线程同时进行,等待所有线程完成当前阶段后再进入下一阶段。
多线程协作:Phaser 可以用于多个线程之间的协作,实现一种分治的并发编程模式。
Phaser 的主要方法包括:
arriveAndAwaitAdvance():使当前线程到达同步点并等待其他线程,直到所有线程都到达同步点后才继续执行。
arriveAndDeregister():使当前线程到达同步点并注销,不再参与后续的同步操作。
getPhase():获取当前阶段的编号。
register():注册一个线程,使其参与后续的同步操作
// 注册线程可以通过构造函数的参数指定,也可以通过 phaser.register(); 方法注册线程。
Phaser phaser = new Phaser(3){
@Override
protected boolean onAdvance(int phase, int registeredParties) {
System.out.println("第" + phase + "阶段完成");
return false; // 返回 true 会终止 phaser
}
};
for (int i = 0; i < 3; i++) {
// phaser.register(); // 如果上面造函数的参数没有指定,则启用这句话来注册线程
new Thread(() -> {
// 使用 for 循环来模拟3个阶段
for (int phase = 1; phase <= 2; phase++) {
// 这是第 phase 阶段
System.out.println(Thread.currentThread().getName() + "执行第 phase"+phase+" 阶段 任务...");
phaser.arriveAndAwaitAdvance(); // 等待其他线程到达屏障点
}
System.out.println("完成所有阶段");
// 解除线程的注册
phaser.arriveAndDeregister();
}).start();
}
}
执行结果:
Thread-0执行第 phase1 阶段 任务...
Thread-2执行第 phase1 阶段 任务...
Thread-1执行第 phase1 阶段 任务...
第0阶段完成
Thread-1执行第 phase2 阶段 任务...
Thread-0执行第 phase2 阶段 任务...
Thread-2执行第 phase2 阶段 任务...
第1阶段完成
完成所有阶段
完成所有阶段
完成所有阶段
第2阶段完成ReadWriteLock
读写锁,就是共享锁和排他锁,读锁是共享锁,写锁是排他锁。
从以下对比结果可以看出,读操作共享直接并行执行提高了效率
public class ReadWriteLockTest {
static ReentrantLock lock = new ReentrantLock();
static ReadWriteLock writeReadLock = new ReentrantReadWriteLock();
static Lock readLock = writeReadLock.readLock();
static Lock writeLock = writeReadLock.writeLock();
//模拟读操作
public static void read(Lock lock){
try {
lock.lock();
Thread.sleep(1000);
System.out.println(Thread.currentThread().getName() + " read end");
}catch (InterruptedException e) {
e.printStackTrace();
}finally {
lock.unlock();
}
}
public static void write(Lock lock, String message){
try {
lock.lock();
Thread.sleep(1000);
System.out.println("write ing "+message);
System.out.println(Thread.currentThread().getName() +" write end");
}catch (Exception e){
e.printStackTrace();
}finally {
lock.unlock();
}
}
public static void main(String[] args) throws InterruptedException {
CountDownLatch countDownLock = new CountDownLatch(8);
Long lockStartTime = System.currentTimeMillis();
// 读写锁不区分
for(int i=0;i<5;i++){
new Thread(()->{
read(lock);
countDownLock.countDown();
}).start();
}
for(int i=0;i<3;i++){
new Thread(()->{
write(lock,String.valueOf(new Random().nextInt()));
countDownLock.countDown();
}).start();
}
countDownLock.await();
System.out.println("use lock costs:"+(System.currentTimeMillis()-lockStartTime));
CountDownLatch countDownReadWriteLock = new CountDownLatch(8);
Long readWriteLockStartTime = System.currentTimeMillis();
//读写锁做区分,性能明显提升
for(int i=0;i<5;i++){
new Thread(()->{
read(readLock);
countDownReadWriteLock.countDown();
}).start();
}
for(int i=0;i<3;i++){
new Thread(()->{
write(writeLock,String.valueOf(new Random().nextInt()));
countDownReadWriteLock.countDown();
}).start();
}
countDownReadWriteLock.await();
System.out.println("use readWriteLock costs:"+(System.currentTimeMillis()-readWriteLockStartTime));
}
}
打印结果:
Thread-0 read end
Thread-1 read end
Thread-2 read end
Thread-3 read end
Thread-4 read end
write ing 896233572
Thread-5 write end
write ing 981429523
Thread-6 write end
write ing 1864625511
Thread-7 write end
use lock costs:8067
Thread-9 read end
Thread-11 read end
Thread-10 read end
Thread-8 read end
Thread-12 read end
write ing 566287197
Thread-13 write end
write ing -1077734491
Thread-14 write end
write ing 1078226018
Thread-15 write end
use readWriteLock costs:4012Semaphore
信号量
每次只允许指定数量的线程去执行
使用场景:限流使用
public class SemaphoreTest {
public static void main(String[] args) {
//默认false,true代表公平锁,2指定对应数量允许2个线程执行
Semaphore semaphore = new Semaphore(2,true);
for(int i=0;i<3;i++){
new Thread(()->{
try {
semaphore.acquire();
System.out.println(Thread.currentThread().getName()+" running");
Thread.sleep(1000);
System.out.println(Thread.currentThread().getName()+" end");
} catch (InterruptedException e) {
e.printStackTrace();
}finally {
semaphore.release();
}
}).start();
}
}
}
打印结果:
Thread-1 running
Thread-0 running
Thread-1 end
Thread-0 end
Thread-2 running
Thread-2 endExchanger
交换器,两个线程间互相交换数据用的
应用场景:游戏中互换装备
public class ExchangeTest {
static Exchanger<String> exchanger = new Exchanger<>();
public static void main(String[] args) {
new Thread(()->{
String s = "t1";
try {
s = exchanger.exchange(s);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName()+" result:"+s);
},"t1").start();
new Thread(()->{
String s = "t2";
try {
s = exchanger.exchange(s);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName()+" result:"+s);
},"t2").start();
}
}
打印结果:
t2 result:t1
t1 result:t2LockSupport
为什么要用lockSupport:
wait(),notify()必须要在synchronized中使用,且必须一致保持对应关系;
LockSupport的park()和unpark()可以实现线程的阻塞和唤醒。
/**
* 模拟2个线程
* 1、线程1向容器中添加10个元素
* 2、线程2 实时监控容器个数,当容器个数为5个时,线程2给出提示并结束
*/
public class LockSupportTest {
volatile List<Integer> lists = new ArrayList<>();
public void add(Integer i){
lists.add(i);
}
public int size(){
return lists.size();
}
static Thread t1 = null, t2 = null;
public static void main(String[] args) {
LockSupportTest lockS = new LockSupportTest();
t1 = new Thread(()->{
System.out.println("线程t1开始");
for(int i=0;i<10;i++){
lockS.add(i);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("线程t1 add "+i);
if(i == 5){
LockSupport.unpark(t2);
LockSupport.park();
}
}
},"t1");
t2 = new Thread(()->{
System.out.println("线程t2开始");
if(lockS.size() != 5){
LockSupport.park();
}
LockSupport.unpark(t1);
System.out.println("线程t2结束");
},"t2");
t1.start();
t2.start();
}
}
打印结果:
线程t1开始
线程t2开始
线程t1 add 0
线程t1 add 1
线程t1 add 2
线程t1 add 3
线程t1 add 4
线程t1 add 5
线程t2结束
线程t1 add 6
线程t1 add 7
线程t1 add 8
线程t1 add 9AQS源码解析
使用双向链表的优点包括:
FIFO(先进先出)的顺序:
双向链表可以保持线程加入等待队列的顺序,即先加入的线程排在队列前面,后加入的线程排在队列后面。这有助于实现公平性,即等待时间较长的线程更有机会先获得锁。
便于在两端进行操作:
双向链表支持在队列的两端进行高效的操作,例如在头部添加新节点、在尾部移除节点等。这对于在等待队列中的线程状态的管理和维护是非常有用的。
节点的前驱和后继信息:
每个等待队列节点都有指向其前驱节点和后继节点的引用。这使得在等待队列中的线程状态的变化可以高效地传播,例如当前驱节点释放锁时,可以唤醒后继节点。这对于实现线程的唤醒和阻塞是关键的。
简化队列操作:
双向链表的结构可以简化在队列中的节点插入、删除和移动等操作,而这些操作是在多线程环境下需要高效完成的。
3、IO密集型和CPU密集型
3.1、CPU密集型
-
需非常多CPU计算资源,让每个CPU核心都参与计算,CPU性能充分利用,避免过多线程上下文切换,理想方案是:线程数 = CPU核数+1
-
也可CPU核数*2,要看JDK版本,及CPU配置(服务器CPU有超线程)。1.8来增加并行计算,想线程数 = CPU内核线程数*2
-
3.2、IO密集型
-
网络、磁盘 IO (与DB、缓存),一旦IO,线程就等待,结束才执行。多设线程数,等待时去做其它事,提高效率。
线程上下文切换有代价。IO密集型公式:线程数 = CPU核心数/(1-阻塞系数) 阻塞系数一般0.8~0.9,双核CPU理想线程数20,动态线程池看压测情况。
-
CPU 密集:减少上下文切换,核心线程数5,队列长100,最大线程数和核心线程数一致。
IO 密集:分配一点核心线程数,更好利用 CPU,核心线程数 8,队列长100,最大线程池10
上面都是理论上的值。从核心线程数5 开始压测,对比结果,确定合适设置。极限:核心线程数和最大线程数都是 4,队列96,刚好100 请求















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









