










事件溯源导论
简单是可靠的先决条件。 ——Edsger Dijkstra
推动DDD发展的动力是填补软件架构师和领域专家在业务领域上的见解差异。与关系型建模相比,DDD是一项突破,因为它促进领域建模代替数据建模。关系型建模着眼于数据实体和它们的关系。而领域建模则着眼于领域中可观察的行为。
事件溯源(Event Sourcing,ES)并非只是使用事件对业务逻辑进行建模。在ES场景里,你的数据源只包含持久化事件。
ES并非全能独立的架构,而是一个能让领域模型和CQRS等架构进一步发挥所长的特性。当把ES添加到系统时,你只是改变了数据源的结构和实现。
- 事件的突破
- 下一件大事
总的来说,认为事件是软件开发的下一件大事。绑定上下文以及领域事件和继承事件共同为架构师指明了一条道路,使它们更有效地理解和实现需求。
把可观察的业务事件看做持久化数据为开发打开了新的视角。 - 现实世界不仅有模型,还有事件
模型是现实的抽象,是架构师根据会面领域专家、利益相关者和最终用户得到的结果创建的。
最终,模型只是模型,而非我们在现实事件直接观察到的东西。 - 抛弃“最近已知的正常状态”
当我们用观察到的事件构建模型时,模型就是我们想要持久化的东西。一个模型通常是一组对象。
ES的关注点主要在你观察道德事件序列上。事件就是你想保存到持久化存储的东西。
- 最近已知的正常状态:软件正常运行时,某个对象的最近已知的正常状态。
一般而言,在实体的历史里也可能有事件改编实体的结构。“最近已知的正常状态”方案是好的,但在业务领域里展开时并非有效表示项目的生命周期的理想方案。 - 跟踪刚才发生的事情
从事件溯源的角度来看,事件是系统数据的主要来源。当一个事件触发时,与之关联的数据将被保存。这样,系统就能跟踪正在发生的事情及其带来的信息。
- 最近已知的正常状态:软件正常运行时,某个对象的最近已知的正常状态。
- 事件对软件架构的深刻影响
- 你不会错过任何事情
事件的主要好处是分析报告提到的任何领域事件都能在几乎任何时候添加到系统并保存到存储。
事件并没有固定的格式或结构。事件只是一组属性,将以某种方式持久化,但不一定持久化到关系型数据库。 - 几乎无限业务场景可扩展性
事件会想你详述某个特定领域里的业务。
处理事件持久化需要新的架构元素,如事件存储,事件就是记录在这里的。 - 支持假设场景
通过储存和处理事件,可以再任何需要的时候构建内容的当前状态。
使用假设场景的可能性是使用ES的主要业务原因之一。 - 没有强制要求的技术
事件溯源并未显式地绑定任何技术或产品。
事件溯源需要某些软件工具,主要是事件存储。
事件和事件溯源关乎架构;技术按照种类界定。 - 缺点:抵制改变
如果你找到一个或多个领域专家需要你产生的事件序列,那么事件许愿就是一个进一步探索的方案。
- 你不会错过任何事情
- 下一件大事
- 事件溯源架构
决定把事件用作你的分层系统的主要数据源时你需要做什么。有两个基本方面要考虑:持久化事件以及为查询奠定基础。
- 持久化事件
事件应被持久化成审计日志,并记录以发生的事情。
事件存储时普通数据库,但它不是用来持久化数据模型的。它持久化的是一组事件对象。
事件存储有三个主要特征:
①它保存的事件对象包含了重建这个时间引用的对象状态所需的任何信息。
②它必须可以返回与给定键关联的数据流。
③它只能添加存储,不支持更新和删除。
事件对象必须通过某种方式引用业务对象。
- 事件和业务逻辑的整体流程
事件溯源基本上是关于以时间序列的方式捕获应用程序状态的所有改变。但是,事件是源自信息。每个事件都是事件存储里的一条记录,但每个事件都记录了已发生的某件事。 - 事件存储的选择
事件存储最终还是一个数据库。
- 事件和业务逻辑的整体流程
- 回放事件
事件溯源的主要作用是持久化消息,它使你可以跟踪应用程序状态的所有改变。
- 构建业务实体的状态
- 回放事件意味着什么
- 数据快照
- 持久化事件
- 总结
事件促进基于任务的方案的分析和实现。
构建一个保罗万象的模型有时候很难,而命令和查询之间的分离展示了更加高效地构建系统的方式。
使用事件溯源时,每次重播事件都必须创建聚合状态。
持久层
知识只是对事实的拥有,智慧则是对它们的活用。 ——Thomas Jefferson
从应用程序的角度来看,数据源不再是物理数据库,而是构建在业务领域之上的逻辑模型
持久层概览
在某种程度上,现在的软件都需要访问数据,然后将数据保存或者以某种方式展示给客户。持久层这个名字通常用来指代了解数据访问那些繁杂细节的代码:字符串连接、查询语言、索引和JSON数据结构等。- 持久层的职责
持久层通常会创建成类库、被领域层(特别是领域服务)和应用程序层引用。持久层可以引用任何用于访问数据的技术。
- 永久保存数据 :持久层提供一组类,它们知道如何永久保存数据。永久数据是应用程序需要处理的数据,可以再将来任何时间继续使用。
- 处理事务:持久层应该了解应用程序的事务需求,但是,持久层亲自处理的应该只有与数据访问有关的工作单元的事务。这意味着持久层应该负责在单个工作单元的某个聚合边界内更新多个表。总之,持久层的事务职责不会超出数据聚合上下文里的普通数据访问的边界。
- 读取永久数据:持久层负责从任何永久存储读取数据。出于性能的考虑,更好的办法是把读取的工作放在单独的服务器列表上,并充分利用缓存数据。持久层也是数据源内容缓存策略集中实现的理想地方。
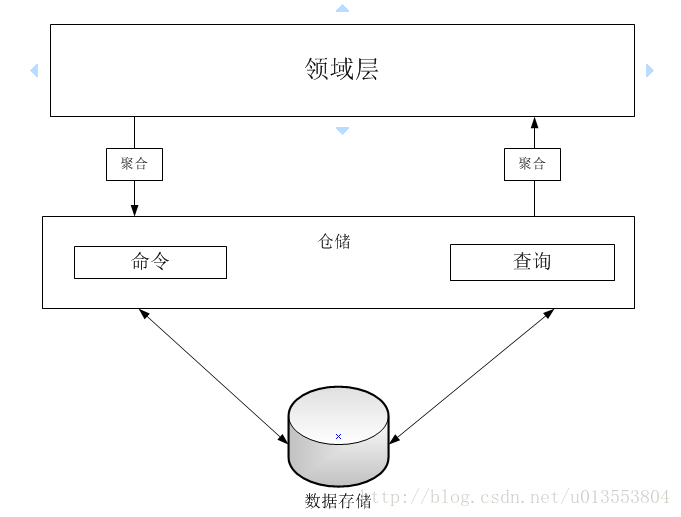
仓储模式的设计
仓储是一个类,里面的每个方法都表示一个针对数据源的操作——无论是什么操作。这就是说,仓储类的实际结构在不同的场景和应用程序里可能会有较大差别。仓储模式:仓储式一个协调领域模型和数据映射层的组件,使用类似集合的接口访问领域对象。仓储在分层架构里所处的位置:
使用仓储的好处:- 实现关注点分离
- 减少重复数据访问代码的可能
- 把数据访问代码用作可注入组件,增加应用程序层和领域层里的可测试代码。
此外,一组良好隔离的仓储类能为一些应用程序的部署打下坚实的基础,以便一些数据访问层可以应对不同的数据库。
- 工作单元模式:Uow被定义构成一个业务事务的一组操作。一个支持这个模式的组件,比如仓储,可以协调在单个物理事务里的写入更改,其中包括解决并发问题。总而言之,支持工作单元一位置调用方可以通过把仓储暴露的操作组合起来安排逻辑事务。
- 仓储模式与CQRS:若选择CQRS,通常只在命令栈里建仓储,每个聚合对应一个仓储类。仓储类只有写入方法和一个根据ID返回聚合的Get方法。在CQRS场景里,只读栈通常不需要仓储类。
- 仓储模式与领域模型:在领域模型场景里,每个聚合都有一个仓储。这个仓储类会处理查询和命令。
- 命令仓储的接口:无论使用领域模型还是CQRS,都需要一个仓储为聚合执行写入操作。仓储基于泛型接口,这个接口通常定义在领域层。接口的实现则通常放在基础设施层的一个单独的程序集里。
- 持久层的职责
为何考虑非关系型存储
NoSQL,不仅仅是SQL。- 哪些地方正在使用NoSQL:
- 海量数据以及数百万潜在用户。
- 每秒上千次查询。
- 非结构化/半结构化数据以不同形式出现,但仍需统一处理(多态数据)。
- 使用云计算和虚拟化硬件满足极端伸缩性需要
- 数据库是一个天然的事件源
- NoSQL类型:
- 文档/对象存储
- 图存储
- 键值存储
- 表格存储
优缺点
关系型数据库
优点:- 支持标准数据访问语言(SQL)
- 表格模型易于理解,设计和规范流程定义明确。
缺点:
- 对通过SQL读写复杂类型仅提供有限支持
- 需要数据库结构的知识才能创建即席查询。
- 对大量记录进行索引(数百万行级别)会变得很慢。
- NoSQL
优点:
- 简单的扩展
- 快速读写
- 低廉的成本
缺点: - 不提供对SQL的支持
- 支持的特性不够丰富
- 现有产品不够成熟
- 哪些地方正在使用NoSQL:
- 总结
- 无需读写数据的应用程序和绑定上下文是不存在的。
- 读写不一定发生在相同的数据存储。其次,数据存储不一定是数据库。
- 了解系统的机制和数据的特征,然后制定出最可行的架构。
- 针对企业场景,应该使用不同的存储技术来存储不同类型的数据。
- 没有理由通过单个技术或产品来统一存储。
- 多元化持久化要求你学习不同的存储技术和产品。
2017/12/26 9:36:19
彩蛋
- 今天的编程是软件工程师和老天之间的竞赛,前者努力构建更大、更好、白痴也能用的程序,后者尝试创造更大、更好的白痴。到目前为止,老天领先。
- 程序员的麻烦是你要等到一切都晚了才能搞清楚程序员在做什么。
- 给人程序,毁人一天;教人编程,毁人一生。
- 你曾遇到的最大灾难是你的第一门编程语言。
- 程序是写给人读的,写给机器运行指示偶然。
- 面向对象的致富途径是什么?当然是继承。
- 如有疑问,蛮力为之。
- 如果蛮力无法解决你的问题,那是你没用力。
- 好的判断源自经验,而经验源自坏的判断。
- 电脑就像比基尼,避免人们过多猜测。
- 如果你只知道SQL,那么所有数据看起来都是关系型的。
- 如果答案就是太多记录,你可以改写这句查询吗?
- 如果开发者可以再你设计的数据库里放入错误的数据,那么最终会有某个开发者这样做。















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









