







 上海人工智能实验室发布的OpenCompass2.0评测体系评估大模型能力,GPT-4Turbo在综合表现上领先,但国内模型在特定领域仍有优势。评测强调了复杂推理和全面性的提升,展示了大模型技术的发展现状与挑战。
上海人工智能实验室发布的OpenCompass2.0评测体系评估大模型能力,GPT-4Turbo在综合表现上领先,但国内模型在特定领域仍有优势。评测强调了复杂推理和全面性的提升,展示了大模型技术的发展现状与挑战。
OpenCompass 2.0,也称为“司南”,是由上海人工智能实验室发布的一个大模型评测体系。这个评测体系旨在为大语言模型和多模态模型等提供一站式的评测服务,全面量化这些模型在知识、语言、理解、推理和考试等五大能力维度的表现。据2023年的评测结果显示,GPT-4 Turbo 在这些评测中获得了最佳表现,紧随其后的是国内的一些模型,例如智谱清言GLM-4、阿里巴巴Qwen-Max 和百度文心一言4.0。

OpenCompass 2.0的评测维度包括基础能力和综合能力两个层级。基础能力维度侧重于语言、知识、理解、数学、代码等方面,而综合能力则考察模型在运用知识、数学推理、代码工具等多种能力完成复杂任务的水平。
值得注意的是,尽管 GPT-4 Turbo 在评测中表现出色,但它也只在复杂推理方面有所提升,仍然存在改进空间。国内大模型在中文场景下表现出色,特别是在语言理解和知识方面,但它们在推理、数学、代码和智能体等方面与 GPT-4 Turbo 还存在一定差距。
此外,OpenCompass 2.0 还引入了首创的循环评估(Circular Evaluation)策略,并构建了超过 1.5 万道高质量中英文双语问题,以确保评测的全面性和客观性。
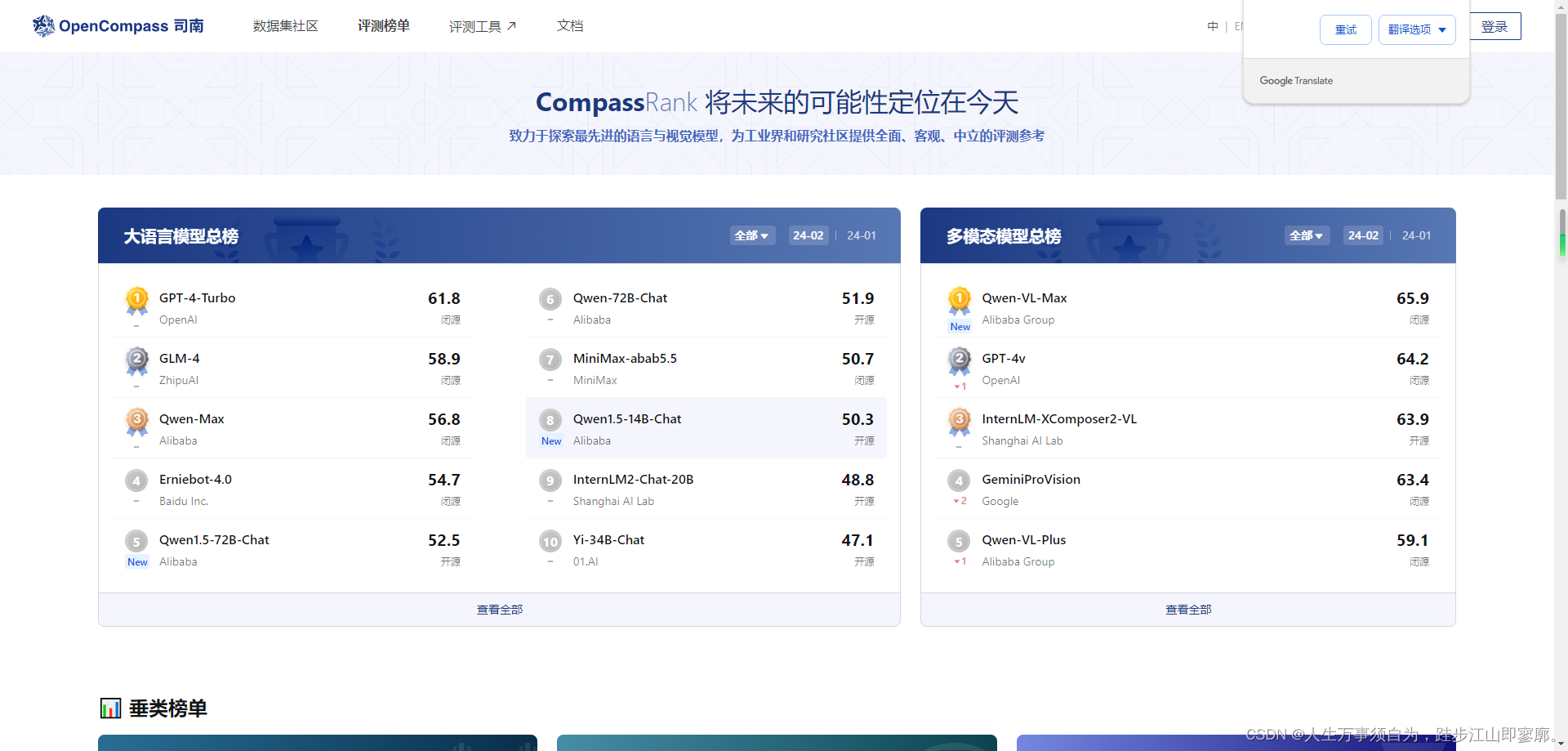
总体来看,OpenCompass 2.0 评测体系为理解和改进大模型提供了重要的指导和参考,同时也展示了当前大模型技术的发展趋势和所面临的挑战。尽管 OpenCompass 2.0 提供了一个全面的评测框架,但大模型技术仍需要在复杂推理、可靠地解决复杂问题等方面继续进步。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











