







前言
最近在学习python爬虫,为了巩固爬虫的知识,偶尔会写一些简单的脚本来加强对语法的熟练度。
一、模拟知乎登录的准备
因为知乎的防爬机制会识别selenium,所有我们不能直接实例化浏览器对象,可以通过接管已经打开的浏览器进行账户的输入。
系统环境变量:在path中添加chrome浏览器的路径
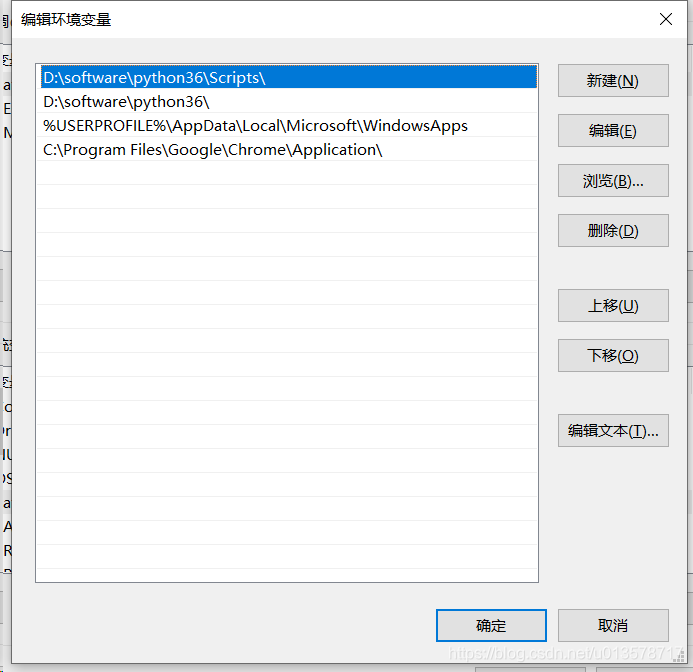
在cmd中输入以下命令启动浏览器
chrome.exe --remote-debugging-port=9222 --user-data-dir=“E:\data_info\selenium_data
remote-debugging-port=:端口号
user-data-dir:数据存储路径
需要安装的包
- pillow
- pyHook
- PyUserInput
- selenium == 3.8.0
- Keras==2.0.1
- numpy==1.12.1
- scikit-learn==0.18.1
- h5py==2.6.0
- tensorflow==1.13.1
python第三方库:下载链接
安装的时候找不到对应库可以去上方链接下载并安装
二、登录验证码的问题
1.英文验证码
一般情况下,我们输入验证码需要保持在同一session下,如果用selenium需要保持在同一cookie下;当然知乎与此不同:
- 首先在网页的源码中找到图片所在的属性
- 对图片进行保存
- 输入验证码,此处采用手动输入
代码如下(示例):
# 获取它的src返回的是base64的字符串,解码并保存图片
english_captcha = driver.find_element_by_class_name('Captcha-englishImg')
base64_text = english_captcha.get_attribute('src')
code = base64_text.replace('data:image/jpg;base64', '').replace('%0A', '')
with open('img.jpeg', 'wb') as f:
f.write(base64.b64decode(code))
# 用Image模块打开图片并手动输入验证码
try:
im = Image.open('img.jpeg')
im.show()
im.close()
except:
pass
yzm = input("请输入验证码:")
2.中文倒立文字验证码
知乎多次登录之后偶尔会提示点击倒立中文验证码
- 保存中文倒立验证码的图片
- 计算出倒立中文字体的坐标
- 控制鼠标自动取点击对应的坐标即可
中文倒立字体坐标计算可以用github上面的模块:链接
zheye使用方法:
from zheye import zheye
z = zheye()
positions = z.Recognize('path/to/captcha.gif')
代码如下(示例):
# 保存图片
chinese_captcha = driver.find_element_by_class_name('Captcha-chineseImg')
base64_text = chinese_captcha.get_attribute("src")
code = base64_text.replace('data:image/jpg;base64', '').replace('%0A', '')
with open('img.jpeg', 'wb') as f:
f.write(base64.b64decode(code))
# 元素在浏览器中的位置
ele_position = chinese_captcha.location
x_relative = ele_position["x"]
y_relative = 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 3121
3121











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









