







本文首发于个人博客,文章链接为:https://blog.d77.xyz/archives/186911b0.html
前言
上一篇文章中爬取了爬虫练习平台的所有 ssr 网站,都是比较简单的,没有反爬措施,这次来爬一下后面的 spa 系列。
环境准备
这里沿用了上篇文章的环境和设置,就不重新搭建环境了。
开始爬取
spa1
spa1 说明如下:
电影数据网站,无反爬,数据通过 Ajax 加载,页面动态渲染,适合 Ajax 分析和动态页面渲染爬取。
还是无反爬,Ajax 加载数据,那么最简单的方法就是打开 Chrome 控制台, 找 xhr 请求。
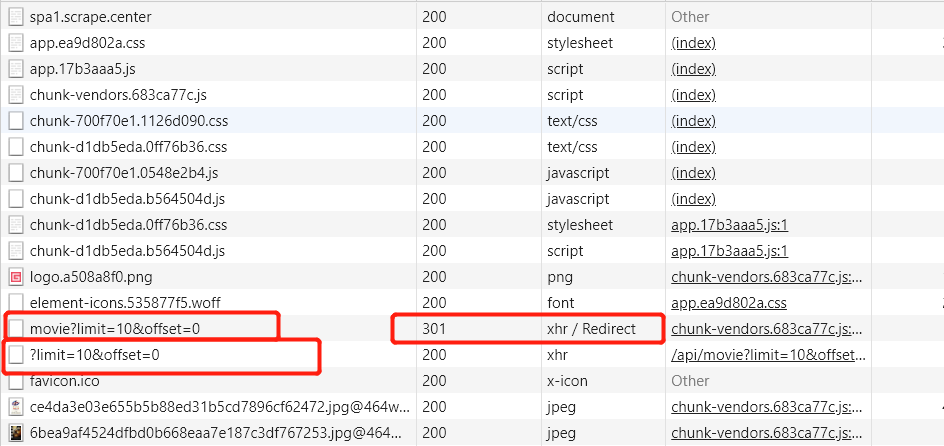
一共有两个请求,第一个请求经过了 301 重定向,所以实际接收到数据的是第二个请求。

查看数据,基本数据都有了,但是没有作者信息,随便点击一个电影,查看详细信息,查找接口。


通过 id 和另一个 API 接口获取详细信息,可以找到作者,OK,开始写代码。
其他代码和之前从 HTML 中解析数据的逻辑一致,只是在解析方法上不一样。
class SPA1Spider(scrapy.Spider):
name = "spa1"
def start_requests(self):
urls = [
f'https://spa1.scrape.center/api/movie/?limit=10&offset={a}' for a in range(0, 100, 10)
]
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response, **kwargs):
result = response.json()
for a in result['results']:
item = SPA1Item()
item['title'] = a['name'] + a['alias']
item['fraction'] = a['score']
item['country'] = '、'.join(a['regions'])
item['time'] = a['minute']
item['date'] = a['published_at']
yield Request(url=response.urljoin(f'/api/movie/{a["id"]}/'), callback=self.parse_person,
meta={
'item': item})
def parse_person(self, response):
result = response.json()
item = response.meta['item']
item['director'] = result['directors'][0]['name']
yield item
因为是通过 API 接口进行遍历的,所以使用总的页数进行循环就可以得到所有的起始 URL。
然后通过读取 JSON 格式的响应,依次循环获取数据,然后进入到详情页获取作者信息,最后返回数据。
完整代码详见https://github.com/libra146/learnscrapy/tree/spa1
spa2
spa2 说明如下:
电影数据网站,无反爬,数据通过 Ajax 加载,数据接口参数加密且有时间限制,适合动态页面渲染爬取或 JavaScript 逆向分析。
和 spa1 相比多了一个数据接口参数加密,先打开控制台看一下多了什么参数。
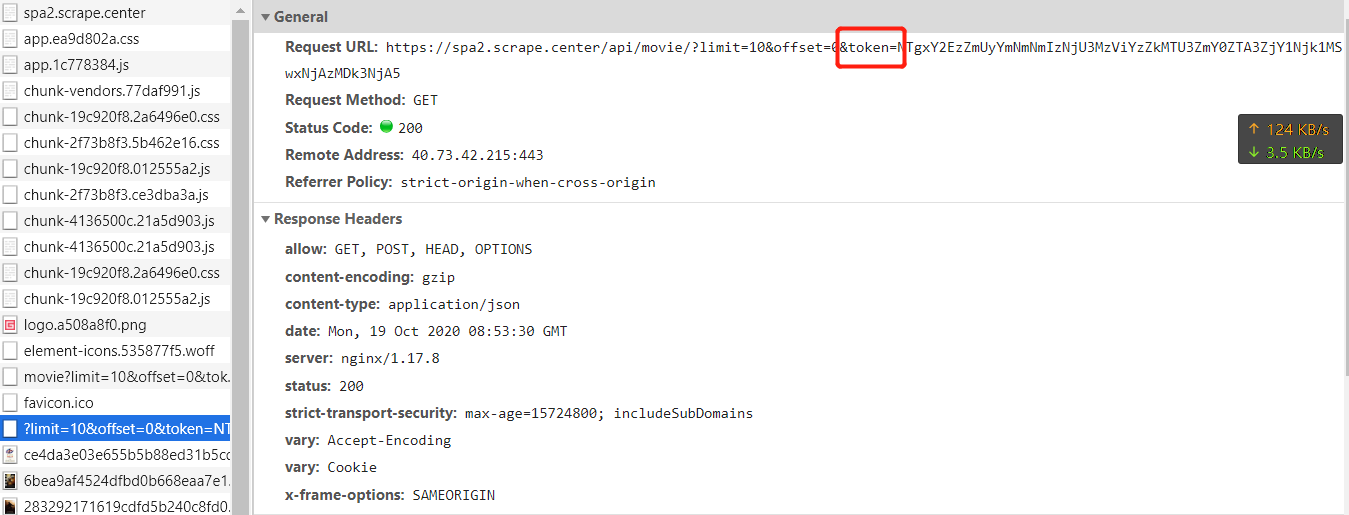
接口没有变,只是多了一个 token 参数,接下来来寻找一下这个 token 是怎么生成的。
既然是网络请求,而且 URL 中包含 token,那么分析 token 来源就要从 URL 断点入手。

下断点,凡是包含 token 字符串的 URL 全部会断下,刷新页面,断点断下,格式化 js 代码,可以看到断下的位置为 send 函数,用来发送请求。


按照右侧调用栈依次往下看,发现在 onFetchData 函数附近发现了 token 参数,取消 URL 断点,在 token 的生成位置下断点。重新刷新页面,断点断下。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 466
466











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









