









摘要:本文介绍了 StreamX 的部署安装,内容主要分为以下几个部分:
1. 系统架构
2. 部署环境要求
3. 平台部署
4. 系统配置
5. 开发部署应用
6. 结束语
1. 系统架构
StreamX 的初衷是让流处理更简单, 可能你还没遇到她, 也许第一眼就命中注定的恋爱了, 来, 让我们一块走进 StreamX 的世界! 这会是一个系列的文章, 为你详细讲述关于 StreamX 的故事。
StreamX 总体组件栈架构如下, 由 streamx-core 和 streamx-console 两个大的部分组成 , streamx-console 是一个非常重要的模块, 定位是一个 综合实时数据平台,流式数仓平台, 低代码 ( Low Code ), Flink & Spark 任务托管平台,可以较好的管理 Flink 任务,集成了项目编译、发布、参数配置、启动、savepoint ,火焰图 ( flame graph ),Flink SQL,监控等诸多功能于一体,大大简化了 Flink 任务的日常操作和维护,融合了诸多最佳实践。其最终目标是打造成一个实时数仓,流批一体的一站式大数据解决方案。

(👆🏻 StreamX 架构图 )
2. 部署环境要求
streamx-console 提供了开箱即用的安装包,安装之前对环境有些要求,具体要求如下:
环境要求
| 要求 | 环境 | 是否必须 | 说明 |
| 操作系统 | Linux |
| 必须 |
| JAVA | 1.8+ |
| 必须 |
| Maven | 3+ |
| 可选 |
| Node.js |
| 必须 | |
| Flink | 1.12.0+ |
| 必须 |
| Hadoop | 2+ |
| 可选 |
| MySQL | 5.6+ |
| 必须 |
| Python | 2+ |
| 可选 |
| Perl |
| 可选 |
(👆🏻 StreamX的环境要求)
Linux
选择 centos 7.5
JDK
选择1.8
Maven
选择3.8.5
cd /opt/software
wget https://dlcdn.apache.org/maven/maven-3/3.8.5/binaries/apache-maven-3.8.5-bin.tar.gz --no-check-certificate
tar -xzvf apache-maven-3.8.5-bin.tar.gz -C /opt/module
sudo ln -s /opt/module/apache-maven-3.8.5/bin/mvn /usr/bin/mvnNode.js
前端部分采用vue开发,需要nodejs环境,下载安装最新的nodejs即可。
sudo yum install -y nodejs查看nodejs版本。
node --versionv16.13.2MySQL
选择5.7.16
Flink
选择 1.13.6 并且需要配置FLINK_HOME环境变量:
export FLINK_HOME=/opt/module/flink-1.13.6Hadoop
这里使用的是 Flink on Yarn, 需要部署的集群安装并配置 Hadoop的相关环境变量,如你是基于 CDH 安装的 Hadoop 环境,相关环境变量可以参考如下配置:
export HADOOP_HOME=/opt/cloudera/parcels/CDH/lib/hadoop #hadoop 安装目录
export HADOOP_CONF_DIR=/etc/hadoop/conf
export HIVE_HOME=$HADOOP_HOME/../hive
export HBASE_HOME=$HADOOP_HOME/../hbase
export HADOOP_HDFS_HOME=$HADOOP_HOME/../hadoop-hdfs
export HADOOP_MAPRED_HOME=$HADOOP_HOME/../hadoop-mapreduce
export HADOOP_YARN_HOME=$HADOOP_HOME/../hadoop-yarn特别注意: 如果是 Hadoop 3.x 系列, 除了正常的配置外, 需要在 core-site.xml 中特别指定下以下配置:
<property>
<name>dfs.client.datanode-restart.timeout</name>
<value>30</value>
</property>3. 平台部署
本次基于 1.2.2 稳定版本进行安装部署,如果是本地编译部署安装的话, 请看下面的操作演示:
也可以直接下载发行包进行安装部署, 此方式也是推荐的安装部署方式, 简单, 快捷。
cd /opt/software
wget https://github.com/streamxhub/streamx/releases/download/v1.2.2/streamx-console-service-1.2.2-bin.tar.gz
tar -zxvf streamx-console-service-1.2.2-bin.tar.gz -C /opt/module
1. 创建数据库
CREATE DATABASE `streamx` CHARACTER SET utf8 COLLATE utf8_general_ci;2. 初始化表
use streamx;
source /opt/module/streamx-console-service-1.2.2/script/final.sql3. 配置连接信息
进入到 conf 下,修改 application.yml, 找到 datasource 这一项,找到 mysql 的配置,修改成对应的信息即可,如下:
datasource:
dynamic:
# 是否开启 SQL 日志输出,生产环境建议关闭,有性能损耗
p6spy: false
hikari:
connection-timeout: 30000
max-lifetime: 1800000
max-pool-size: 15
min-idle: 5
connection-test-query: select 1
pool-name: HikariCP-DS-POOL
# 配置默认数据源
primary: primary
datasource:
# 数据源-1,名称为 primary
primary:
username: $user
password: $password
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc: mysql://$host:$port/streamx?useUnicode=true&characterEncoding=UTF-8&useJDBCCompliantTimezoneShift=true&useLegacyDatetimeCode=false&serverTimezone=GMT%2B84. 配置workspace
同样进入到 conf 下,修改 application.yml,找到 streamx 这一项,找到 workspace 的配置,修改成一个用户有权限的目录。
streamx:
# HADOOP_USER_NAME 如果是on yarn模式( yarn-prejob | yarn-application | yarn-session)则需要配置 hadoop-user-name
hadoop-user-name: hdfs
# 本地的工作空间,用于存放项目源码,构建的目录等.
workspace:
local: /opt/streamx_workspace # 本地的一个工作空间目录(很重要),用户可自行更改目录,建议单独放到其他地方,用于存放项目源码,构建的目录等.
remote: hdfs:///streamx # support hdfs:///streamx/ 、 /streamx 、hdfs://host:ip/streamx/注意:其中,数据库用户名密码及JDBC连接URL需要修改为自己数据库的相关属性,hadoop-user-name及workspace需要根据自己的实际情况进行修改。其他情况可以暂时使用默认配置。
5. 启动服务
进入到 bin 下直接执行 startup.sh 即可启动项目,默认端口是10000,如果没啥意外则会启动成功,相关的日志会输出到streamx-console-service-1.2.2/logs/streamx.out 里。
/opt/module/streamx-console-service-1.2.2/bin/startup.sh启动成功之后使用jps可以看到如下进程

( 👆🏻 进程查看 )
6. 浏览器登录系统
打开浏览器输入 http://ip:10000 即可登录系统:

(👆🏻 Web UI登录界面 )
默认用户名:admin 默认密码:streamx

(👆🏻 StreamX UI 主界面)
4. 系统配置
进入系统之后,第一件要做的事情就是修改系统配置,在菜单 StreamX/Setting 下,这里可以添加一个Flink HOME 和 Flink Cluster。
2. 配置 Flink Cluster
StreamX 做到了灵活的支持Flink 多版本的能力, 在任务里指定一个Flink 版本即可完成, 因此需要先添加一个或多个(如果你的任务依赖多个不同版本的Flink) 部署机器上安装的 Flink 到系统, 操作页面如下:
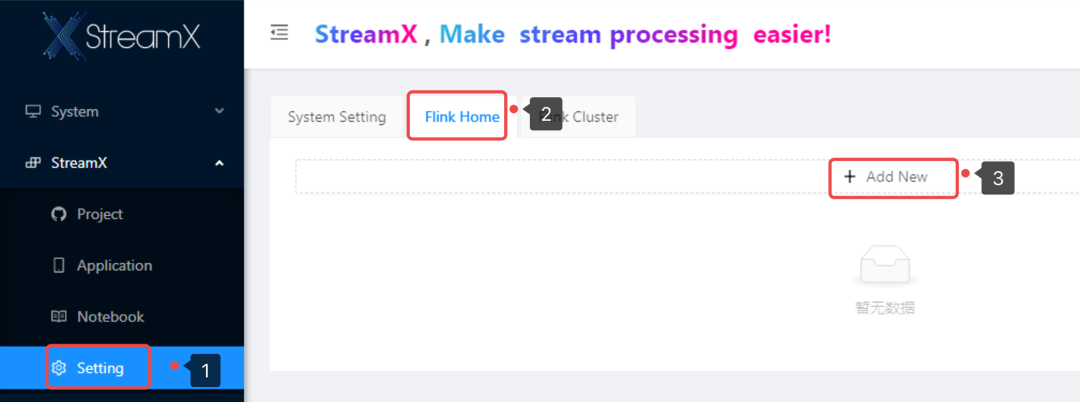
打开 Flink Home 标签页直接添加即可。
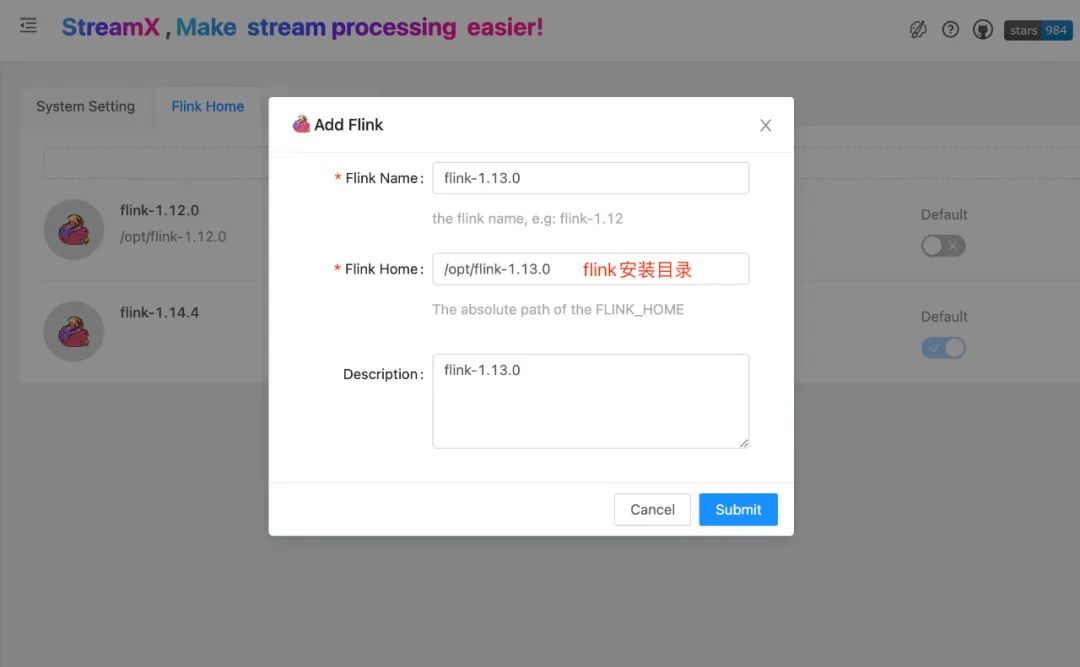
( 👆🏻 配置Flink HOME )
2. 配置 Flink Cluster
StreamX 做到了 Remode (standalone) 模式的任务提交 (将Flink 任务提交到一个指定的集群), 如果有这类部署需求,就先需要在系统里添加一个或多个已经存在的 Flink standalone 集群。
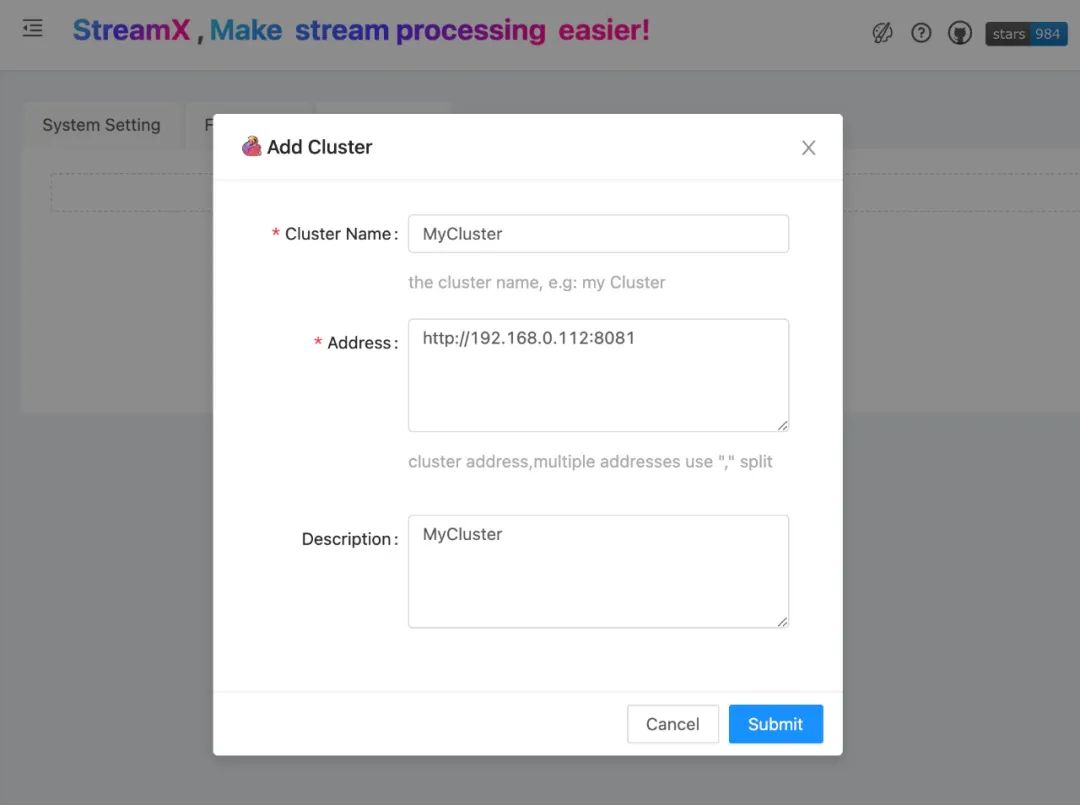
5. 开发部署应用
千呼万唤始出来, 以上准备工作和系统环境设置都完成了, 到这一步, 终于可以在 streamx-console 平台上开发启动任务了, Let's go~
Flink SQL 任务
1. 指定Flink版本
StreamX 支持 Flink 多版本(1.12+), 具体使用的时候非常简单,编辑自带的 Flink SQL 示例任务, 直接指定任务里对应的Flink 版本即可。

( 👆🏻 编辑任务 )

( 👆🏻 指定任务运行的Flink 版本 )
2. 指定Flink Cluster
这里以运行在 Standalone 集群上为例, 将 Execution Mode 选择为 remote, 然后指定下 Flink Cluster 即可。

( 👆🏻 运行模式选择remote )
remote模式选择之后,会出现Flink cluster 选项,为必填项, 选择添加已有的Flink Cluster 即可:

( 👆🏻 选择 Flink Cluster )
更多使用参数可查看官网文档和 Flink 参数相关说明,以上操作都完成之后,直接点击保存任务。
3. 上线任务
所有的任务添加和修改之后,都必须经过上线这一步。这一步内部会做很多准备工作,对于用户来说直接点击上线按钮即可完成此步骤。
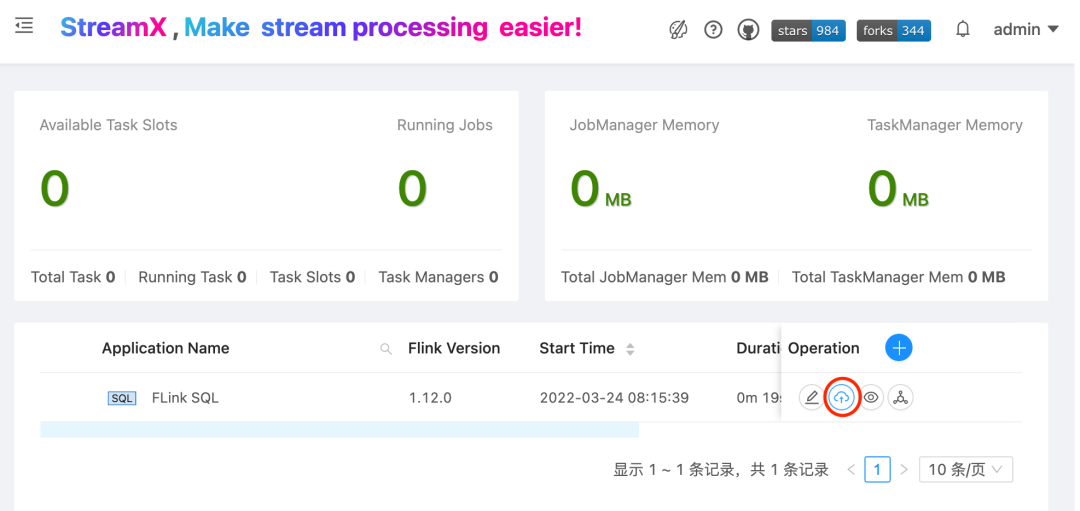
( 👆🏻 上线任务 )
注意:上线这一步不是任务启动,而是一个准备工作的步骤,内部会做很多工作。如: 如果是 yarn-application的模式会将相关的 jar 上传到hdfs,如果是 on k8s 会打镜像等...
4. 启动任务
上面的步骤都完成之后,就会看到有个启动按钮,点击启动任务,稍等一会就会看到任务处于运行状态,点击任务名 就会直接跳转到Flink WebUI中。
Datastream 任务:
StreamX 在开发之初就完整的支持了 Flink SQL 任务 和 Datastream 任务,关于 Datastream任务,Flink 版本的指定, Flink Cluster 的指定(如果是 remote 模式) 和上面的 Flink SQL 任务一样,这里不做赘述,下面以一个视频的方式简单直接的呈现:
( 👆🏻 Datastream 任务部署演示 )
6. 结束语
这将是一个系列的文章,本文是第一篇,详细介绍了 StreamX 平台的编译部署安装到运行的整个过程。每个环节图文并茂,相信很多小伙伴已经跃跃欲试了,快去试试吧 ~ 更多精彩的地方等你来发掘 😁















 3472
3472











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











