






数据结构和算法:Java 速查表
微信搜索关注《Java学研大本营》,加入读者群,分享更多精彩
借助此全面的速查表,了解 Java 中数据结构、搜索和排序算法的基本知识,以供快速参考。
1. 数据结构
Java 中的数据结构是用于组织和存储数据的专门格式,一些常见示例包括列表、映射、集合、树和队列。
-
列表允许有序访问和操作数据,通常使用 ArrayList 或 LinkedList 实现。
-
地图将数据存储为键值对,其中每个键都是唯一的并用于检索其对应的值。示例包括 HashMap 和 TreeMap。
-
集合用于存储唯一元素,没有重复项。HashSet 和 TreeSet 是集合数据结构的例子。
-
树是分层数据结构,通常用于按特定顺序对数据进行排序或组织,例如二叉搜索树和红黑树。
-
队列是一种数据结构,允许按照 FIFO(先进先出)顺序在后面添加元素并从前面移除元素,示例包括 LinkedList 和 PriorityQueue。 以下是java中的数据结构:
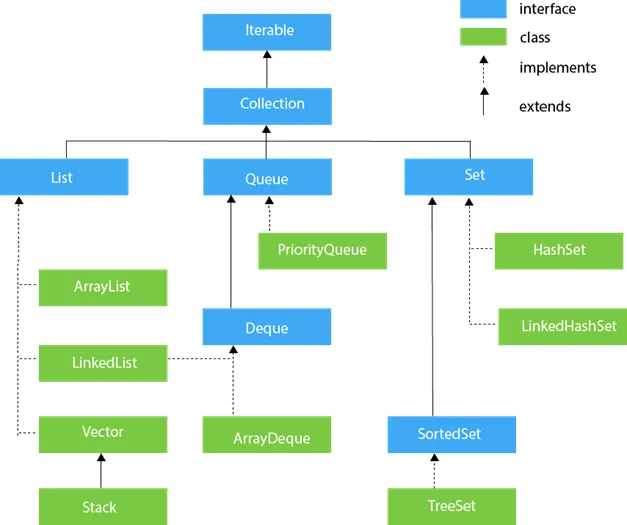
Java 中集合框架的层次结构
1.1 队列
在 Java 中,队列是一个接口,具有诸如 PriorityQueue(每个项目都有预定义的优先级)、LinkedList(在添加或删除节点时有用)、ArrayDeque(数组双端队列)和 PriorityBlockingQueue(同步)等实现。
class PriorityQueueExample{
public static void main(String args[])
{
// Creating empty priority queue
PriorityQueue<Integer> pQueue = new PriorityQueue<Integer>();
// Adding items to the pQueue using add()
pQueue.add(10);
pQueue.add(20);
pQueue.add(15);
// Printing the top element of PriorityQueue
System.out.println(pQueue.peek());
// Printing the top element and removing it
// from the PriorityQueue container
System.out.println(pQueue.poll());
// Printing the top element again
System.out.println(pQueue.peek());
}
}
1.2 列表
ArrayList(具有预设方法的数组)、LinkedList、Vector(遗留的同步数组列表)和 Stack 是实现 List 接口的具体类。
public class StackExample{
public static void main (String[] args){
Stack<String> stack = new Stack<String>();
stack.push("BMW");
stack.push("Audi");
stack.push("Ferrari");
stack.push("Bugatti");
stack.push("Jaguar");
stack.pop();
if(stack.isEmpty() == false){
System.out.println("The length of the array: "+ stack.search(stack.peek()));
}
Iterator iterator = stack.iterator();
while(iterator.hasNext()){
Object values = iterator.next();
System.out.println(values);
}
}
}
1.3 地图
LinkedHashMap 类似于 HashMap,除了它存储顺序,而 Hashtable 是同步的(许多线程可以使用它),使其成为 HashMap 的较慢形式。
1.4 设置
HashSet 和 LinkedHashSet 是 set 的实现,是一种存储不同值的数据结构接口(具有顺序的 HashSet)。
public class Main {
public static void main(String[] args) {
HashSet<String> cars = new HashSet<String>();
cars.add("Volvo");
cars.add("BMW");
cars.add("Ford");
cars.add("BMW");
cars.add("Mazda");
cars.contains("Mazda");
cars.remove("Volvo");
cars.clear();
}
}
1.5 HashMap 与 HashSet
Map接口由Hashmap实现。另一方面,HashSet 是集合接口的实现。对于其实现,HashMap 不使用 HashSet 或任何其他集合。TheHashSet的内部实现是基于Hashmap的。HashSet 只存储值而不是键值对。当尝试添加具有已存在键的值时,HashMap 会修改键的值,但是,HashSet 不允许您插入已存在的元素。
1.6 树
树是一种非线性数据结构,它根据层次关系组织数据元素。
// Binary tree node example
// Class containing left and right child
// of current node and key value
class Node {
int key;
Node left, right;
public Node(int item){
key = item;
left = right = null;
}
}
2.大O符号/复杂度
在选择算法时,会使用参数,其中之一是复杂性。最重要的两种复杂性是时间和空间复杂性。因为每件计算机硬件都是独一无二的,所以使用广泛的符号来描述复杂性。一个算法可以在瞬间完成,也可以花费 n 时间,其中 n 是输入。大 O 表示法是描述最坏时间复杂度的流行表示法。
2.1 复杂度比较,其中 n 是输入大小

O(n!)(阶乘)[糟糕] >
O(2^n)(指数(递增率增加到无穷无尽))[可怕] >
O(n^p)(多项式)[糟糕]>
O(n*logn)(对数线性)[差] >
O(n)(线性)[一般] >
O(logn) (对数(递增率下降到零)) [好] >
O(1)(常数)[完美]
在检查算法的难度时,将复杂度四舍五入,因为最大值定义了大部分性能;例如,O(n2+ n + 1) 被接受为 O(n2)。如果复杂度为 O(n+m) 并且两个值都可以通过变量更改,不会将复杂度四舍五入为 O(n+m)。
2.2 时间复杂度
一般来说,计算算法的循环时间。递归复杂性用于解释递归算法。
2.3 空间复杂度
被利用的集合加上辅助空间的元素计数被统计。
3.搜索算法
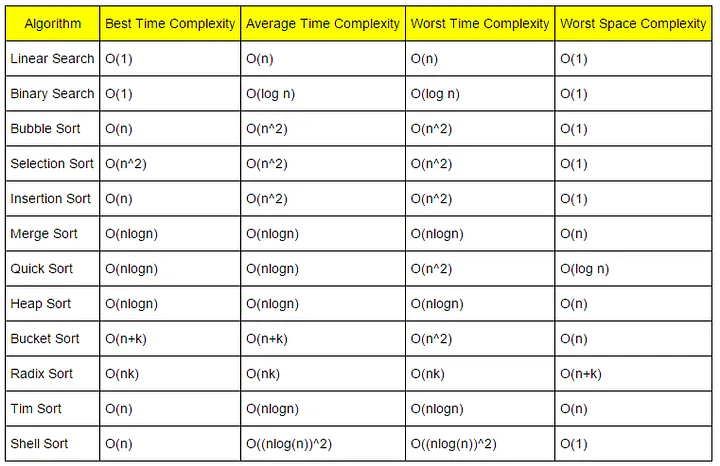
有 3 种基本搜索算法:
3.1 顺序搜索
实施简单,但工作缓慢。每个数据集都由算法单独检查。它具有 O(N) 复杂度,其中 N 是数据的数量。此外,数据结构必须通过键进行预排序。
public int selectionSort(int[] arr){
for (int i = 0; i < arr.length - 1; i++){
int index = i;
for (int j = i + 1; j < arr.length; j++){
if (arr[j] < arr[index]){
index = j;//searching for lowest index
}
}
int smallerNumber = arr[index];
arr[index] = arr[i];
arr[i] = smallerNumber;
}
return smallerNumber;
}
3.2 二分查找
使用最广泛的搜索算法。该算法检查中心的数据,并根据值相对于中值的位置搜索更高或更小的值。它具有公式 O(log 2(N))。此外,数据结构必须按关键字预先排序。
public void binarySearch(int arr[], int searched)
{
int low = 0, high = arr.length - 1;
// This below check covers all cases , so need to check
// for mid=lo-(high-low)/2
while (high - low > 1) {
int mid = (high + low) / 2;
if (arr[mid] < searched) {
low = mid + 1;
}
else {
high = mid;
}
}
if (arr[low] == searched) {
System.out.println("Found At Index " + low );
}
else if arr[high] == searched) {
System.out.println("Found At Index " + hi );
}
else {
System.out.println("Not Found" );
}
}
3.3 哈希搜索
散列是通过使用其输出值的位长度都相同的函数将数字或字母数字字符串分配给一段数据的过程。在理想情况下,最快的搜索算法具有 O(1) 复杂度。如果有很多碰撞,效率低下,如果有很多键,则无法避免碰撞。
public void findingFrequencyWithHashMap(int arr[])
{
// Creates an empty HashMap
HashMap<Integer, Integer> hmap = new HashMap<Integer, Integer>();
// Traverse through the given array
for (int i = 0; i < arr.length; i++) {
// Get if the element is present
Integer c = hmap.get(arr[i]);
// If this is first occurrence of element
// Insert the element
if (hmap.get(arr[i]) == null) {
hmap.put(arr[i], 1);
}
// If elements already exists in hash map
// Increment the count of element by 1
else {
hmap.put(arr[i], ++c);
}
}
// Print HashMap
System.out.println(hmap);
}
4 排序
4.1 选择排序
当数据是半排序时,这很有用。时间复杂度为O(n2),空间复杂度为O(1)。它从一个空数组开始,然后搜索最小值并不断将它们添加到其中。
public int[] selectionSort(int arr[]){
int index , smallest;
int lastIndex= arr.length()- 1;
for(int i = 1; i < lastIndex; i++){ //Starts from the beginning
smallest = arr[lastIndex]; //Last element accepted as the smallest
index = lastIndex;
for(int j = i; j < lastIndex; j++){ //Search for the smaller
if(arr[j] < smallest){
smallest = D[j];
index = j;
}
arr[index] = arr[i]; //If there is a smaller one relocate
arr[i] = smallest;
}
}
return arr;
}
4.2 冒泡排序
如果元素是有序的,而且元素个数很少,这个算法会更好。该算法具有 O(n²) 时间复杂度和 O(1) 空间复杂度。如果所有 c 个元素都未排序,则时间复杂度为 O(c*n)。该算法按顺序对每个相邻元素进行排序。
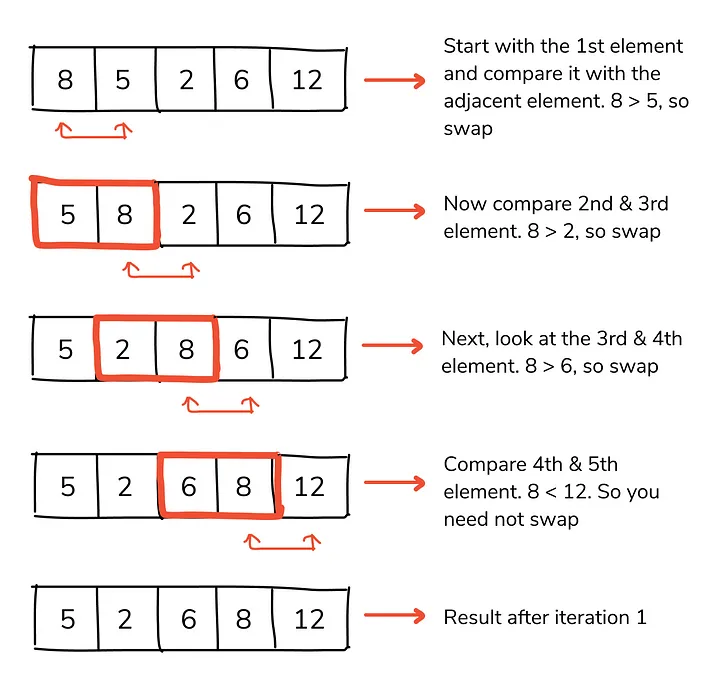
public static void bubbleSort(int [] arr){
int lastIndex = arr.length()-1;
for (int i=0; i<lastIndex; i++){
for(int j=0; j<lastIndex-i; j++){
if(arr[j+1] < arr[j]){
int temp = arr[j];
arr[j] = arr[j+1];
arr[j+1] = temp;
}
}
}
}
4.3 选择排序与冒泡排序
两者具有相同的时间和空间复杂度,但选择排序比冒泡排序执行更少的交换;因此,选择排序更快、更高效。
4.4 插入排序
该算法通过将数组未排序部分的元素连续插入数组已排序部分中的相应位置来对对象数组进行排序。时间复杂度为O(n2),空间复杂度为O(1)。
void sort(int arr[])
{
int n = arr.length;
for (int i = 1; i < n; ++i) {
int key = arr[i];
int j = i - 1;
/* Move elements of arr[0..i-1], that are
greater than key, to one position ahead
of their current position */
while (j >= 0 && arr[j] > key) {
arr[j + 1] = arr[j];
j = j - 1;
}
arr[j + 1] = key;
}
}
4.5 归并排序
空间复杂度为 O(n log(n)),而时间复杂度为 O(n)。归并排序是一种排序方法,将一个数组划分为更小的子数组,对每个子数组进行排序,然后将排序后的子数组合并生成最终的排序数组。构建简单,使用更大的数据集更快。与其他技术相比,冗长、占用更多空间并且处理小数据集时速度较慢。
void merge(int arr[], int left, int mid, int right)
{
// Find sizes of two subarrays to be merged
int size1 = mid - left + 1;
int size2 = right - mid;
/* Create temp arrays */
int Left[] = new int[size1];
int Right[] = new int[size2];
/*Copy data to temp arrays*/
for (int i = 0; i < size1; ++i){
Left[i] = arr[left + i];
}
for (int j = 0; j < size2; ++j){
Right[j] = arr[mid + 1 + j];
}
/* Merge the temp arrays */
// Initial indexes of first and second subarrays
int i = 0, j = 0;
// Initial index of merged subarray array
int mergedArrIndex = left;
while (i < size1 && j < size2) {
if (Left[i] <= Right[j]) {
arr[mergedArrIndex] = Left[i];
i++;
}
else {
arr[mergedArrIndex] = Right[j];
j++;
}
k++;
}
/* Copy remaining elements of L[] if any */
while (i < size1) {
arr[mergedArrIndex] = Left[i];
i++;
mergedArrIndex++;
}
/* Copy remaining elements of R[] if any */
while (j < size2) {
arr[mergedArrIndex] = Right[j];
j++;
mergedArrIndex++;
}
}
// Main function that sorts arr[l..r] using
// merge()
void sort(int arr[], int left, int right)
{
if (left < right) {
// Find the middle point
int mid = left + (right - left) / 2;
// Sort first and second halves
sort(arr, left, mid);
sort(arr, mid + 1, right);
// Merge the sorted halves
merge(arr, left, mid, right);
}
}
4.6 快速排序
空间复杂度为 O(n²),时间复杂度为 O(n)。它选择一个元素作为枢轴,并围绕枢轴对指定数组进行分区。quickSort 有许多变体,它们使用 pivot 作为第一个、最后一个、随机或中间元素。选择最后一块作为枢轴:
// A utility function to swap two elements
static void swap(int[] arr, int i, int j)
{
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
/* This function takes last element as pivot, places
the pivot element at its correct position in sorted
array, and places all smaller (smaller than pivot)
to left of pivot and all greater elements to right
of pivot */
static int partition(int[] arr, int low, int high)
{
// pivot
int pivot = arr[high];
// Index of smaller element and
// indicates the right position
// of pivot found so far
int i = (low - 1);
for (int j = low; j <= high - 1; j++) {
// If current element is smaller
// than the pivot
if (arr[j] < pivot) {
// Increment index of
// smaller element
i++;
swap(arr, i, j);
}
}
swap(arr, i + 1, high);
return (i + 1);
}
/* The main function that implements QuickSort
arr[] --> Array to be sorted,
low --> Starting index,
high --> Ending index
*/
static void quickSort(int[] arr, int low, int high)
{
if (low < high) {
// pi is partitioning index, arr[p]
// is now at right place
int pi = partition(arr, low, high);
// Separately sort elements before
// partition and after partition
quickSort(arr, low, pi - 1);
quickSort(arr, pi + 1, high);
}
}
4.7 堆排序
空间复杂度为 O(n log(n)),而时间复杂度为 O(1)。 堆排序是一种使用比较的排序技术,它基于二叉堆数据结构。它类似于选择排序,我们首先发现最小元素并将其设置在开头。对其余部分恢复前面的步骤。
public void sort(int arr[])
{
int size = arr.length;
// Build heap (rearrange array)
for (int i = size / 2 - 1; i >= 0; i--)
heapify(arr, size, i);
// One by one extract an element from heap
for (int i = size - 1; i > 0; i--) {
// Move current root to end
int temp = arr[0];
arr[0] = arr[i];
arr[i] = temp;
// call max heapify on the reduced heap
heapify(arr, i, 0);
}
}
// To heapify a subtree rooted with node i which is
// an index in arr[]. n is size of heap
void heapify(int arr[], int size, int i)
{
int largest = i; // Initialize largest as root
int l = 2 * i + 1; // left = 2*i + 1
int r = 2 * i + 2; // right = 2*i + 2
// If left child is larger than root
if (l < size && arr[l] > arr[largest])
largest = l;
// If right child is larger than largest so far
if (r < size && arr[r] > arr[largest])
largest = r;
// If largest is not root
if (largest != i) {
int swap = arr[i];
arr[i] = arr[largest];
arr[largest] = swap;
// Recursively heapify the affected sub-tree
heapify(arr, size, largest);
}
}
4.8 计数排序
时间复杂度为O(n+k),空间复杂度为O(k)。 计数排序是一种使用落在定义范围内的键的排序方法。它通过计算具有唯一键值(一种散列)的项目数来运行。之后,执行一些算术运算以确定每个对象在输出序列中的位置。
void sort(char arr[])
{
int n = arr.length;
// The output character array that will have sorted
// arr
char output[] = new char[n];
// Create a count array to store count of individual
// characters and initialize count array as 0
int count[] = new int[256];
for (int i = 0; i < 256; i++)
count[i] = 0;
// store count of each character
for (int i = 0; i < n; i++)
count[arr[i]]++;
// Change count[i] so that count[i] now contains
// actual position of this character in output array
for (int i = 1; i <= 255; i++)
count[i] += count[i - 1];
// Build the output character array
// To make it stable we are operating in reverse
// order.
for (int i = n - 1; i >= 0; i--) {
output[count[arr[i]] - 1] = arr[i];
count[arr[i]]--;
}
// Copy the output array to arr, so that arr now
// contains sorted characters
for (int i = 0; i < n; i++)
arr[i] = output[i];
}
4.9 Bucket排序
时间复杂度是 O(n+k),空间复杂度也是。
桶排序是一种排序算法,将数据统一划分为许多称为桶的组。然后使用任何排序方法对元素进行排序,最终以排序的方式收集元素。这部分将介绍桶排序的工作原理,包括其算法、复杂性、示例以及在 Java 程序中的实现。
// Bucket sort in Java
import java.util.ArrayList;
import java.util.Collections;
public class BucketSort {
public void bucketSort(float[] arr, int n) {
if (n <= 0)
return;
@SuppressWarnings("unchecked")
ArrayList<Float>[] bucket = new ArrayList[n];
// Create empty buckets
for (int i = 0; i < n; i++)
bucket[i] = new ArrayList<Float>();
// Add elements into the buckets
for (int i = 0; i < n; i++) {
int bucketIndex = (int) arr[i] * n;
bucket[bucketIndex].add(arr[i]);
}
// Sort the elements of each bucket
for (int i = 0; i < n; i++) {
Collections.sort((bucket[i]));
}
// Get the sorted array
int index = 0;
for (int i = 0; i < n; i++) {
for (int j = 0, size = bucket[i].size(); j < size; j++) {
arr[index++] = bucket[i].get(j);
}
}
}
4.10 Radix排序
时间复杂度为O(nk),空间复杂度为O(n+k)。基数排序是一种数字排序算法,根据数字的位置对整数进行排序。本质上,使用数字的位值。与大多数其他排序算法(如归并排序、插入排序和冒泡排序)不同,不比较数字。
4.11 Tim排序
空间复杂度为 O(nlog(n)),而时间复杂度为 O(n)。 Array被分成Run chunks。使用插入排序对这些运行进行逐一排序,然后将它们与归并排序的组合函数合并。如果数组的大小小于 run,则仅使用插入排序对数组进行排序。运行的大小可能在 32 到 64 之间,具体取决于数组的大小。值得注意的是,当 size 子数组是 2 的幂时,merge 函数有效。该概念基于插入排序对小数组有效的概念。
注意:Java 中的 Collections.sort() 使用 TimSort(mergeSort + sequentialSort)。
推荐书单
《项目驱动零起点学Java》
《项目驱动零起点学Java》共分 13 章,围绕 6 个项目和 258 个代码示例,分别介绍了走进Java 的世界、变量与数据类型、运算符、流程控制、方法、数组、面向对象、异常、常用类、集合、I/O流、多线程、网络编程相关内容。《项目驱动零起点学Java》总结了马士兵老师从事Java培训十余年来经受了市场检验的教研成果,通过6 个项目以及每章的示例和习题,可以帮助读者快速掌握Java 编程的语法以及算法实现。扫描每章提供的二维码可观看相应章节内容的视频讲解。
《项目驱动零起点学Java》贯穿6个完整项目,经过作者多年教学经验提炼而得,项目从小到大、从短到长,可以让读者在练习项目的过程中,快速掌握一系列知识点。
马士兵,马士兵教育创始人,毕业于清华大学,著名IT讲师,所讲课程广受欢迎,学生遍布全球大厂,擅长用简单的语言讲授复杂的问题,擅长项目驱动知识的综合学习。马士兵教育获得在线教育“名课堂”奖、“最受欢迎机构”奖。
赵珊珊,从事多年一线开发,曾为国税、地税税务系统工作。拥有7年一线教学经验,多年线上、线下教育的积累沉淀,培养学员数万名,讲解细致,脉络清晰。

精彩回顾
微信搜索关注《Java学研大本营》
访问【IT今日热榜】,发现每日技术热点














 1110
1110











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









