







在上一篇文章中,我们分析了node的EventEmitter与EventLoop的关系,结论就是它们真的没多大关系,代码表现出异步只是emit函数调用的时机被我们手动设定在eventloop里面。
OK,跟着独操引擎的男人继续我们的代码之旅~

JS对象与C++ Runtime 代码
这一部分涉及到V8引擎的代码优化,对这个不感兴趣的伙伴可以略过这一部分,直接看后面的loop分析,个人觉得理解了function在引擎的表示有助于理解eventloop的真实面目。
之前的v8系列文章一经介绍过Handle跟Persistent这两个模板类,分析了V8的内存管理以及GC的回收算法,JS的源代码经过v8 Full Complier 的前端编译生成AST,然后代码生成开始做一些代码优化,JS的对象模型我会在另一篇文章进行更详细的分析,这里主要介绍内联缓存(Inline Cache 简称 IC),为什么会有IC呢,其实是一种迭代优化算法,假设一个function编译后位于内存区的一个Stub X,相对于一次具体的调用过程P,编译器认为源代码并不需要这么复杂, 所以为它生成了一段优化代码的Stub X1,这个X1是个简单粗暴的形式,编译器并不能确保永远都执行这个Stub,因为执行器到现在只运行了一次invocation,所以它居然大胆地断言,AST中所有挂载这个function的结点都用这个Stub X1替代(mapping),这下好办了,C++ Runtime已经不用担心有自己的事了,因为编译器完全可以分配一个寄存器Rx,将X1在段中的偏移地址读到Rx,然后CPU每次调用直接高速读取Rx的地址,直接跳转过去就完事了,生成的代码大概是这样(假设Stub在R[ebx] + n), Rx = eax x86机器架构):
mov %eax -0x0n(%ebx) ;load the address of stub, cache the code for all invocation
call <entry of the stub> ;invocation
...
entry:
tst <if this stub works>
jne <missed>
...
missed:
<new stub X2 generated by C++ runtime>所以一旦发生了另外一次调用P1,编译器发现这个stub无法满足优化它的条件,这时候就是cache miss了,C++ runtime代码负责善后,针对旧的Stub再次协调新的的调用需求,生成另外一个优化代码Stub X2,这下X2可能还是简单粗暴的版本,但相对于P,P1两次调用,好像也没什么问题,但是让代码变得简单,可能只是简单的从寄存器读取或者偶尔的一两次加减操作,不涉及什么循环移位,消耗更少的CPU时间,好的,现在又可以将这个X2缓存起来,让所有的调用直接跳到X2的入口地址,如果不行再退回runtime代码处理新的优化,如此迭代,就可以生成一个有穷状态机,对于一个Pi,我都可以进入一个优化状态Si,比如下面一个switch语句的描述:
switch(P) {
case Pi:
//turn to Si
__stub_pi_();
break;
case Pj:
//turn to Sj
__stub_pj_();
break;
...
default:
//turn back to initialized state
//notify runtime code to generate a new stub
__runtime_to_generate_new_stub();
}回想上一篇文章中的emit函数的实现,是不是觉得也有个跟上面很像的switch语句结构,没错那其实也相当于模拟了引擎层的IC,为个别的调用情况生成一些特例化的版本,跟一个回退的非优化版本,其实这种结构的代码在node的源代码中出现的还是比较多的。
一段神奇的代码
为了说明eventloop的各个阶段,我特意写了一段代码:
const timeOut = 10;
let horribleLoop = () => {
//entry nextTick event invoked by Module.runMain() (within JS code stack), so the node::MakeCallback is never called util node will be exited
process.nextTick(() => {
logger.log('entry next tick task executed');
});
//check event
setImmediate(() => {
logger.log('end this phase of event loop');
//but the AsyncWrap::MakeCallback invoked nextTick callback block this turn of event loop
for (let i = 0; i < 5; i++) {
process.nextTick(() => {
logger.log('current stack phase id ==> ' + (++recursiveCounter));
});
}
}, timeOut);
//timer event
setTimeout(() => {
logger.log('timer task executed');
}, timeOut);
//poll event
fs.readFile(path.resolve('../cherry'), (err, data) => {
if(err) {
logger.log(err.message);
return;
}
logger.log('poll event executed ==> ' + data.toString());
});
};
horribleLoop();大家可以先想一下运行的log输出顺序,这段程序基本涵盖了eventloop的大多数阶段,好啦,我们来运行一下,在我的机器上node v6.3.0 & Mac 10.11.6环境得到如下结果:
entry next tick task executed
end this phase of event loop
current stack phase id ==> 1
current stack phase id ==> 2
current stack phase id ==> 3
current stack phase id ==> 4
current stack phase id ==> 5
poll event executed ==> ####async test write
timer task executed或许会有一些发愣,但这就是我们诠释eventloop的真理,这个结果的解释我会放在最后,为了更好理解这个确定的结果(运行多次并不带有轮询时长的随机性),先逐个理解一些函数,比如setImmediate,setTimeout,process.nextTick, 我们先来看看eventloop的一张简要的描述:
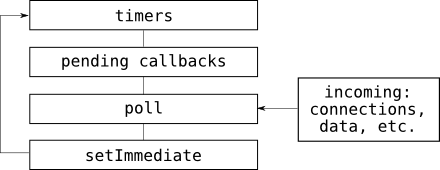
其实清楚的代码可以在node循环启动代码里面看到:
bool more;
do {
v8_platform.PumpMessageLoop(isolate);
more = uv_run(env.event_loop(), UV_RUN_ONCE);
if (more == false) {
v8_platform.PumpMessageLoop(isolate);
EmitBeforeExit(&env);
// Emit `beforeExit` if the loop became alive either after emitting
// event, or after running some callbacks.
more = uv_loop_alive(env.event_loop());
if (uv_run(env.event_loop(), UV_RUN_NOWAIT) != 0)
more = true;
}
} while (more == true);
首先要执行的是V8的消息队列,V8 platform是个多线程模型,其中可能会有多个V8实例(即isolate指针),这主要是为chrome的多进程架构所考虑的,不过在node这个单线程模型中,这个不给予详细讨论,线程以isolate指针值作为key,保存在在一个集合中,执行消息队列时,在当前的线程只需要取出当前isolate标识的队列,里面的任务是一些定时器任务,针对于浏览器环境下的延时操作,定时器以pair<double, Task*> 的结构维护一颗rb tree,便于查找最早的定时器,执行它的任务,Task是一个定时任务的基类,它提供一个虚函数run供子类进行具体实现。
uv_run函数就是libuv层事件循环的入口,开始执行我们上面定义的循环,不过node采用了一些异常保护措施,这次只先试着执行一次,出现异常了触发一个事件(参考注释),loop还有可能继续被触发,因为我们在调用EmitBeforeExit 时也将会调用node::MakeCallback() ,这个函数如果没有提前增加异步回调计数(分析这个函数时会提到)将会在当前循环帧(phase)提前插入nextTick 的操作,nextTick函数触发的操作可能还是个异步事件,比如再次访问数据库,这下loop里面的handle可能会再次被引用,然后loop又开始工作,这次的运行模式是非阻塞,高效的访问里面注册的各个handle,有个有趣的做法,Enviroment 对象(负责handle的初始化,桥接C++ binding层跟libuv层),在初始化handle后会释放它们的引用,这样就不会占着引用当没有事件轮询时让CPU空转。
关于libuv的handle,其实就是一种closure的类实现,jsers会很熟悉js语言中的闭包,允许我们返回一个函数并且引用原来的context变量,却执行在另外的堆栈,这就为我们实现回调函数提供了诸多方便,然而libuv是一个C库,并没有原生的函数闭包,所以我们需要handle来模拟这个闭包,我们一般将数据(多数为js对象的引用放在handle->data这个void指针,可以通过static_cast<T*>(handle->data))进行还原,然后将封装好的函数主体放到handle->cb 这个函数指针,它接受handle作为参数,所以回调调用需要的参数也需要存放到handle里面。
熟悉node架构的伙伴应该都知道异步的事件循环大多发生在底层的libuv,libuv主要的loop原理也就是一个很大的循环,不断地轮询在loop里面注册的事件句柄,称之为uv_handle_t 结构,它是所有事件句柄的基类(C代码里面并没有基类的说法,这是一个宏扩展),如果有句柄处于活跃状态,就遍历它们的请求队列,获得回调,直到没有活跃的句柄(没有被引用)时,循环主体(在libuv中称为uv_loot_t 结构),大概的过程是这样的:
for (;;) {
if(all_handle_in_loop_is_unrefed(loop)) break;
handle = GET_HANDLE_FROM_QUEUE(loop);
if (!IsAlive(handle)) continue;
while (!(req = NEXT_REQ_FROM_QUEUE(handle)).IsEmpty()) {
call_pebding_cb_in_reqs(req);
}
}关于底层的事件AIO模型,也是调用了操作系统的多路复用IO进行操作,Linux下有epoll,Mac下有kqueue,它们比早些版本的select要智能一点,告诉了我们哪些流对象是需要我们去处理的,如果没有就让线程(线程池中的worker threads)进行休眠,避免CPU空转,大概是这个样子:
while(true) {
select(ref_streams[]); //if its state is idle, the worker thread will sleep
//if something active needed to be resolved
for (stream in ref_streams) {
//if some data at stream object
//read / write until unavailable
}
}epoll中采用rb tree存放我们关心的流,便于快速查找哪些流已经通过底层注册的回调(这不算真正意义的回调,只是syscall 由于硬件中断而返回,比如网卡的缓冲区到达一定字节数向内核发出通知,返回read)通知内核需要我们处理了的流,我们把这些流快速收集到一个双向链表里面,可以高效地添加删除一个结点,然后像上面的伪代码一样逐个处理流的读写操作即可。
上面的分析也是poll events 的主要过程,调用相关操作系统的接口。
然后我们再深入libuv的loop看看具体的循环:
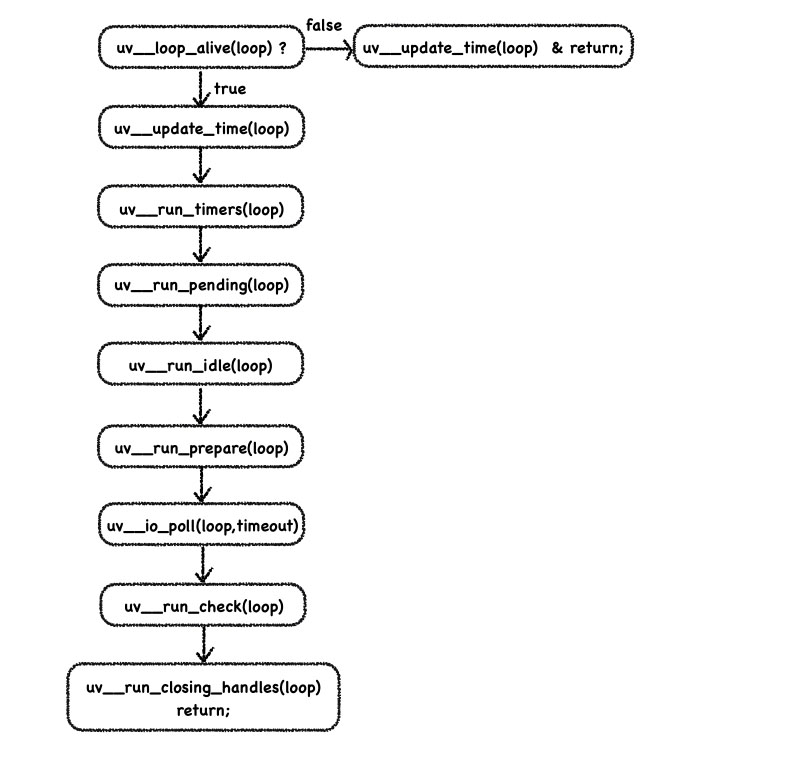
setTimeout
相信看了这个图,大家会觉悟到了上面代码结果的一点线索,沿着循环的时间线,我们来看看第一个函数 setTimeout,它发生的时间点位于uv__run_timers, loop在每一个周期都会先更新自维护的时间(loop time ,通常为一个数值),然后再检查有没有超时的定时器,注意,这里的定时器可不止我们setTimeout函数设定的定时器,还可能存在其他IO事件的定时器,比如一个TCP连接超时计时都需要依赖内部的timer, 先看看这个函数里面包含了什么,我模拟时省略了用于IC的代码。
export.setTimeout = function(callback, after) {
var timer = new Timeout(after);
//ignore some IC codes
//wrap callbacks
ontimeout = () => callback.call(timer,args);
timer._onTimeout = ontimeout;
register_timer_into_list(timer);
return timer;
};其实整个模型可以用一个生产者-消费者模型来说明,首先我们的callback经过wrapper,挂载到定时器上,定时器是一个巧妙的结构,它需要解决timer的增删,还要检查timer是否超时,然后执行回调,timers维护在一个双向链表结构,所有的链表构成一个Map,这个Map以定时的时间作为key存储所有的链表,之所以使用链表是为了更高效的利用V8堆空间,避免大块内存的分配,双向链表也有很高效的增删结点性能,链表的结点结构:
function TimersList(msecs, unrefed) {
this._idleNext = null; // Create the list with the linkedlist properties to
this._idlePrev = null; // prevent any unnecessary hidden class changes.
this._timer = new TimerWrap();
this._unrefed = unrefed;
this.msecs = msecs;
}这是一个链表结点的constructor,由于它的属性是由一个Timeout对象拷贝而来,后者拥有前驱指针跟后继指针用来构成双链表,为了避免在实例化结点之后再进行动态的属性增加(这样做会引起对象的class Map失效,编译器会生成新的Map来表示这个对象,这个以后分析js对象模型会分析),造成无法执行IC后的优化代码(本来属性的偏移地址可以通过一次寄存器访问迅速读取,属性的存取非常快速),所以为了避免这个问题,特意在constructor也加上这两个属性,迟早都要带的东西还不如现在就带上,unrefed是表示这个timer在非active状态下是不是还要被loop轮询,它将调用uv_unref函数取消一个对handle的引用,这样如果没有其他流引用这个handle,loop就会完全忽略它啦。

TimerWrap类是一个C++ binding对象,也就是一个addon模块,它被编译成一个动态库供node在runtime进行链接,这个库可以给我们的JS对象原型链绑定一些方法,
env->SetProtoMethod(constructor, "close", HandleWrap::Close);
env->SetProtoMethod(constructor, "ref", HandleWrap::Ref);
env->SetProtoMethod(constructor, "unref", HandleWrap::Unref);
env->SetProtoMethod(constructor, "hasRef", HandleWrap::HasRef);
env->SetProtoMethod(constructor, "start", Start);
env->SetProtoMethod(constructor, "stop", Stop);C++层中可以由一个FunctionTemplate对象构造出constructor的蓝本,再将作为桥接的T::New函数wrap对象就好,即C++的对象可以把自己的实例的指针存放在JS handle里面的InternalFields里面,需要时可以通过获取JS函数binding函数的Holder()获得 JS对象引用,访问InternalFields,
T* pointer = static_cast<T*>(args.Holder()->GetAlignedPointerFromInternalField(0));handle可以作为C++的一个persistent<T> 供native代码访问,这也是接下来回调传递的基础。
接下来timer会被加入到链表,完成一次production,重点来了,这个回调会被怎样consume ,首先我们肯定知道消费肯定是在底层的eventloop的某个phase被触发,所以我们只需要找到注册到timers event的回调:
//in TimerWrap::Start
int err = uv_timer_start(&wrap->handle_, OnTimeout, timeout, repeat);
//in OnTimeout
TimerWrap* wrap = static_cast<TimerWrap*>(handle->data);
Environment* env = wrap->env();
HandleScope handle_scope(env->isolate());
Context::Scope context_scope(env->context());
wrap->MakeCallback(kOnTimeout, 0, nullptr);
注意AsyncWrap::MakeCallback 是人为调用JS堆栈的回调,我们没有检查这个时候JS stack上contextify的状态,而是直接拷贝一个当前执行环境的一个context,这就是为什么如果我们没有显示指定函数的this,这时候就会发生contextify的扰乱,这也是上面回调要被wrapped的原因,虽然MakeCallback的调用还是指定了context(爱心),看到这里,还是有点疑惑,这里只给AsyncWrap::MakeCallback传递了一个key,我还没有看到JS的回调,是的,但我们可以通过key来获取一个JS Object的Element(Elements 是Object对象模型的组成,独立于属性查找,以数字进行索引),kOnTimeout我们约定为0,
v8::Local<v8::Value> cb_v = object()->Get(index);然后我们就得到了JS堆栈上的一个回调的Stub,它真正的类型是
v8::Local<v8::Function>函数object() 得到的是保存的persistent handle,我们先用一个暂时的Local引用它,这个handle正是我们构造出来的JS对象的实例在引擎中的引用,
new TimerWrap(env, args.This());根据类的继承链一致往上找,在基类BaseObject构造函数被调用时可以看到,JS的this引用就是保存的persistent handle,也就是对应着这个:
this._timer = new TimerWrap();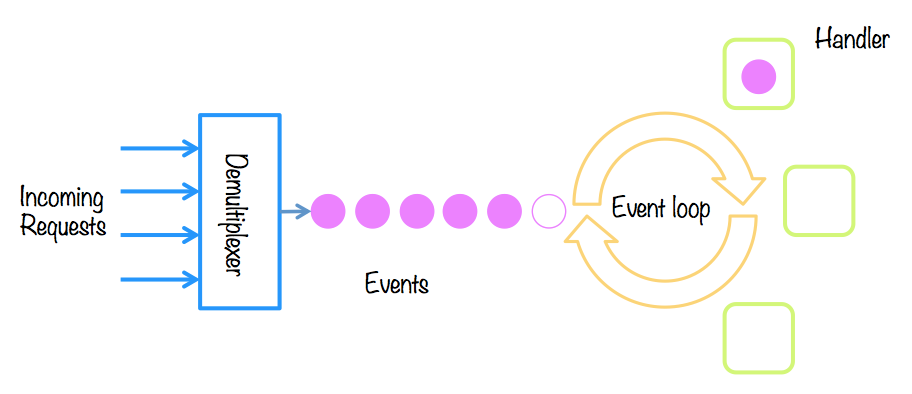
所以我们知道每一次timer events被loop处理时,这个位于_timer对象索引为0的函数就被调用,这下问题就很简单了 ,看到了这个:
lists[msecs] = list;
list._timer[kOnTimeout] = listOnTimeout;终于找到了这个最终consumer执行的函数,我们看看它干了什么:
while (timer = L.peek(list)) {
diff = now - timer._idleStart;
// Check if this loop iteration is too early for the next timer.
// This happens if there are more timers scheduled for later in the list.
// The actual logic for when a timeout happens.
L.remove(timer);
assert(timer !== L.peek(list));
if (!timer._onTimeout) continue;
tryOnTimeout(timer, list);
}主要的步骤就是这些,不断遍历集合的各个列表,计算启动时间,检查有没有过时,为了防止loop提早处理了一写没有到达定时时间的timer,前面做了一些重置工作,最后在tryOnTimeout函数里面最终执行每一个定时器的回调,并且捕获异常,这里我们可以看到与其它AIO事件不同,这里只处理我们setTimeout函数注册的回调,由这个Stub统一处理所有timeout事件,所以JS堆栈上看上去那么多的回调在loop中被当成一个统一的proxy在一帧作为一个回调执行,至于所有AIO事件的处理,当然在loop中还维护着一个timers的集合,这个集合是一个小顶堆,没有严格的排序,但可以保证每次访问堆顶都可以获取最小的key,这个key还是定时的时间,每次取出最早的定时器进行比较就好,过时了就弹出堆,否则继续扔回去,
//insert timers to looper
heap_insert((struct heap*) &handle->loop->timer_heap,
(struct heap_node*) &handle->heap_node,
timer_less_than);
//handle refed
uv__handle_start(handle);
...
//run timers
struct heap_node* heap_node;
uv_timer_t* handle;
for (;;) {
heap_node = heap_min((struct heap*) &loop->timer_heap);
if (heap_node == NULL)
break;
handle = container_of(heap_node, uv_timer_t, heap_node);
if (handle->timeout > loop->time)
break;
uv_timer_stop(handle);
//for setInternal() carried a repeat parameter
uv_timer_again(handle);
handle->timer_cb(handle);
}上面就是loop处理timers的过程,本质还是一个循环结构,不过对于setInternal函数也会经过这里,并且会执行uv_timer_again函数,最后都触发了回调,为了防止定时器的不占用loop的CPU资源,没用之后要及时unref释放引用。
这下我们应该清楚了一个setTimeout函数是怎么产生回调,以及在loop中是怎么被消费,调用链是怎么从loop的回调传递到JS堆栈的回调代理,这时候才在我们JS堆栈上进行定时器的轮询,也知道它是在比较早的phase被loop处理的,所以在那段神奇的代码中loop发现它时还没有超时,当然poll event也还没有返回,它们得等到下一个迭代周期,所以这两个的出现是有一定的时间间隔,最后等到loop再次询问timers发现它已经就绪我们才执行最后的回调,这时候有可能poll event就绪也有可能没有就绪,在上面的代码中,当延时参数K >= 5时,poll event就已经就绪,(readFile函数原理类似,也是将loop中的handle跟JS堆栈的proxy绑定在一起,触发回调),所以这种情况timers事件被超越,它需要等到下一个迭代周期才会被执行(例子中的K = 10),所以它是最晚的一个log,延迟一到两个iteration,上面的分析也解释了callstack的缺失,因为这是一个通过MakeCallback调用的JS堆栈的过程,我们写成递归也是没有堆栈累积的(异步递归)。
下一篇文章我将带领大家继续分析setImmediate函数,nextTick的原理以及MakeCallback函数,更多的精彩敬请期待~~~独操引擎的男人,还在继续~















 1293
1293

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









