





一个关系数据库会尝试我之前介绍的多种方式,优化器的真正工作是在有限的时间内找到较优的方案。
大部分时候,优化器都找不到最优的方案,而只能找到较优的方案。
对于小查询做一个粗暴的计算是可行的,对于中等查询为了粗暴计算,也有一种方法避免不必要的计算,其称为:动态编程。
动态编程
其思想就是很多执行计划其实是很相似的,比如下图:
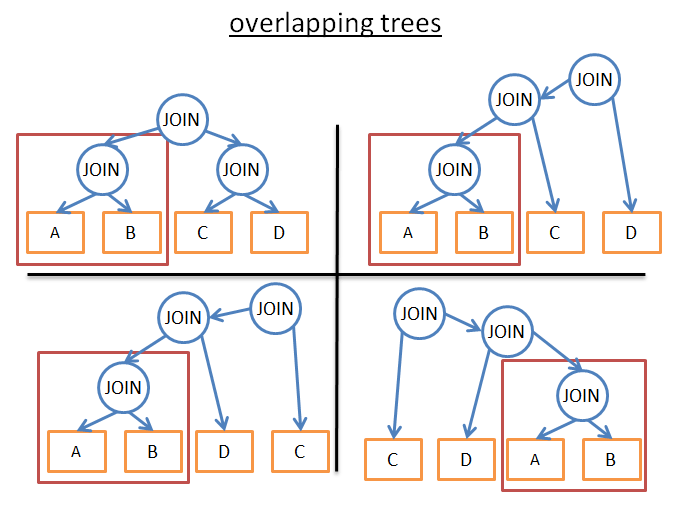
它们都有相同的子树(A join B),因此我们可以不用每个执行计划都计算一次A join B的成本,而是计算一次之后保存起来,后续直接使用即可。实际上我们面临的是有一个很普通的问题:重复问题。为了避免对于部分结果重复计算可以将其暂存起来。
这样我们的时间复杂度就从 (2*N)!/(N+1)!降为了3N。在之前的例子中我们又4次join,那么可能的join顺序数量就会从336降为81。如果是8次join,那么就是从57 657 600 降为 6561。
下边是一个我在Chapter 13: Query Optimization找到的算法例子,如果你擅长算法可以读一读:
procedure findbestplan(S)
if (bestplan[S].cost infinite)
return bestplan[S]
// else bestplan[S] has not been computed earlier, compute it now
if (S contains only 1 relation)
set bestplan[S].plan and bestplan[S].cost based on the best way
of accessing S /* Using selections on S and indices on S */
else for each non-empty subset S1 of S such that S1 != S
P1= findbestplan(S1)
P2= findbestplan(S - S1)
A = best algorithm for joining results of P1 and P2
cost = P1.cost + P2.cost + cost of A
if cost < bestplan[S].cost
bestplan[S].cost = cost
bestplan[S].plan = “execute P1.plan; execute P2.plan;
join results of P1 and P2 using A”
return bestplan[S]对于更大的查询,同样可以使用动态编程,也需要应用其他规则(比如:试探法)来降低可能性。
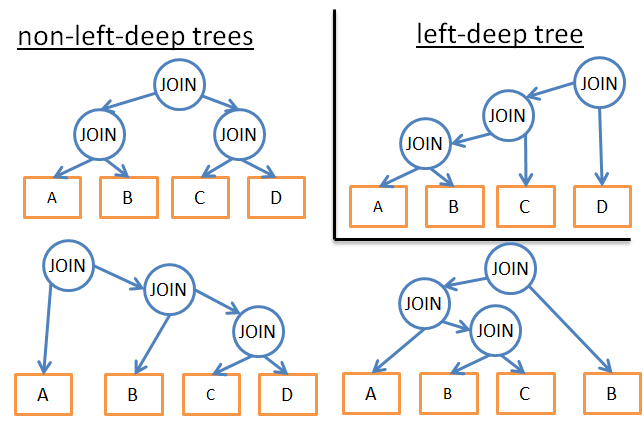
- 如果我只是分析特定类型的计划,比如左深度树,时间复杂度就会从3的n次方降为n*2n;
- 如果我们增加逻辑规则可能会避免一些模式的计划,比如如果一个表可以当做一个索引(译者注:比如只查询索引字段时),那么不要尝试merge表而仅仅merge索引,这样也会降低可能性而且并什么副作用。
- 如果我们改变流程也可以降低大量可能性,比如在其他关系操作之前执行join操作。
- …















 845
845











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









