






04-HBase(分布式数据库)-01-简介
Java开发
HDFS
文件系统fs,以64M为块进行存储管理。其逻辑概念是文件file.其接口是read,write.
HBase
是数据库管理系统dbms,同类产品是mysql,mondb,redis等。其逻辑概念是库,表,行,列。
面向列,有利于水平扩展。
| BigTable | HBase | |
| 文件存储系统 | GFS | HDFS |
| 海量数据处理 | MapReduce | Hadoop MapReduce |
| 协同服务管理 | Chubby | Zookeeper |
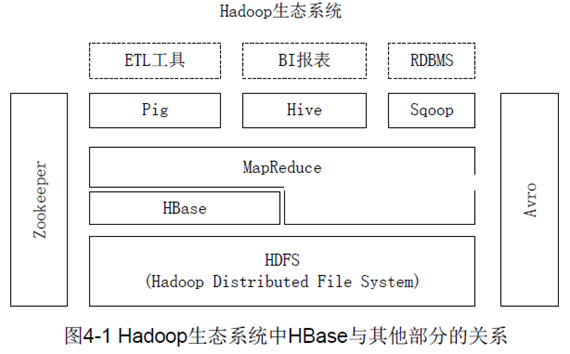
Hbase是BigTable的开源实现。
Hbase是基于HDFS文件系统的数据库。
已经有了关系型数据,也有了HDFS可以做分布式存储,为什么还需要HBase呢?
关系型数据和HDFS无法解决海量数据实时问题。
Hbase只有字符串类型,没有连接操作,列存储,没有更新操作。
读写方式:
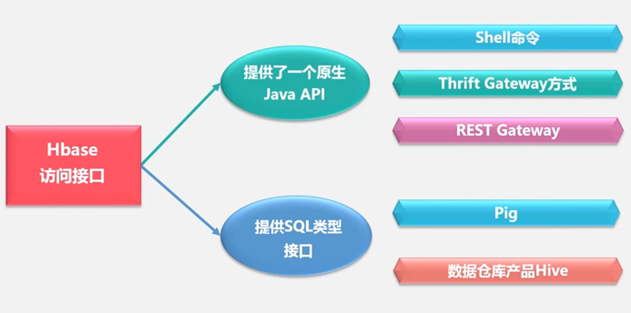
04-HBase-02-访问接口
| HBase 访问接口类型 | 特点 | 场合 |
| Java API | 最常规和高效的访问方式 | 适合Hadoop MapReduce作业 并行批处理HBase表数据 |
| HBase Shell | HBase的命令行工具,最简单的接口 | 适合HBase管理使用 |
| Thrift Gateway | 利用Thrift序列化技术, 支持C++、PHP、Python等多种语言 | 适合其他异构系统 在线访问HBase表数据 |
| REST Gateway | 解除了语言限制 | 支持REST风格的 Http API访问HBase |
| Pig | 使用Pig Latin流式编程语言来处理HBase中的数据 | 适合做数据统计 |
| Hive | 简单 | 当需要以类似SQL语言方式 来访问HBase的时候 |
04-HBase-03-数据模型
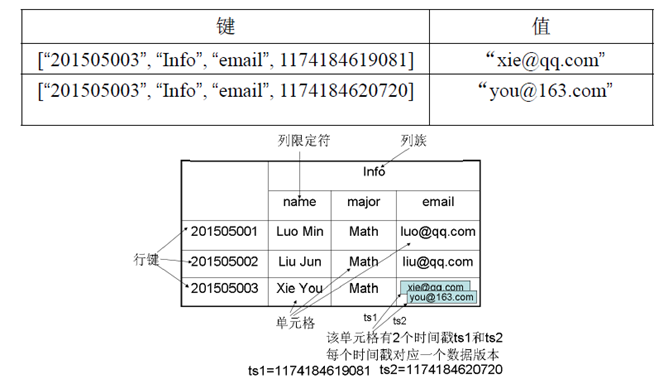
HBase中需要根据(行键、列族、列限定符和时间戳)来确定一个单元格,因此,可以视为一个“四维坐标”,即[行键, 列族, 列限定符, 时间戳].
04-HBase-04-实现原理
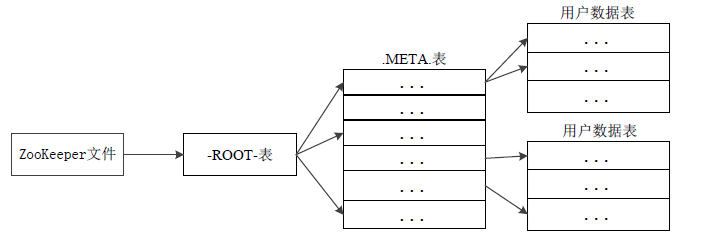
| 层次 | 名称 | 作用 |
| 第一层 | Zookeeper文件 | 记录了-ROOT-表的位置信息 |
| 第二层 | -ROOT-表 | 记录了.META.表的Region位置信息 -ROOT-表只能有一个Region。通过-ROOT-表,就可以访问.META.表中的数据 |
| 第三层 | .META.表 | 记录了用户数据表的Region位置信息,.META.表可以有多个Region,保存了HBase中所有用户数据表的Region位置信息 |
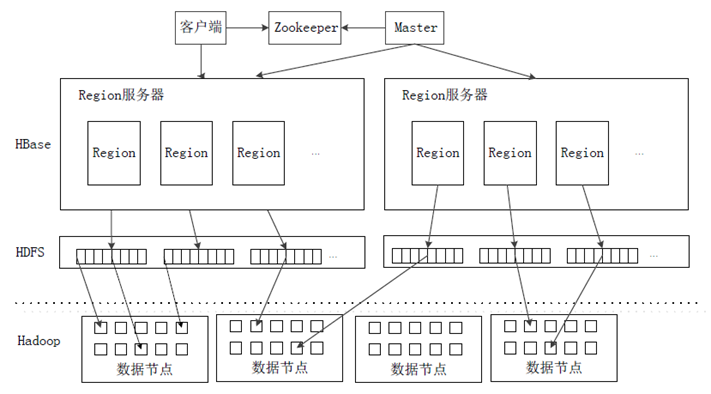
04-HBase-05-运行机制
1 系统架构
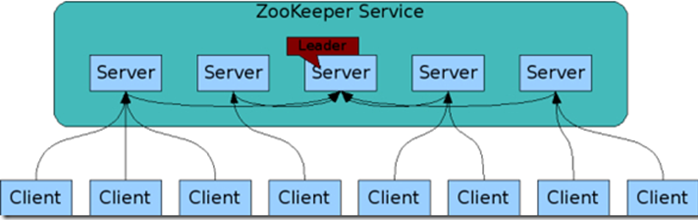
- 1. 客户端
– 客户端包含访问HBase的接口,同时在缓存中维护着已经访问过的Region位置信息,用来加快后续数据访问过程
- 2. Zookeeper服务器
– Zookeeper可以帮助选举出一个Master作为集群的总管,并保证在任何时刻总有唯一一个Master在运行,这就避免了Master的“单点失效”问题
- 3. Master
- 主服务器Master主要负责表和Region的管理工作:
– 管理用户对表的增加、删除、修改、查询等操作
– 实现不同Region服务器之间的负载均衡
– 在Region分裂或合并后,负责重新调整Region的分布
– 对发生故障失效的Region服务器上的Region进行迁移
- 4. Region服务器
– Region服务器是HBase中最核心的模块,负责维护分配给自己的Region,并响应用户的读写请求
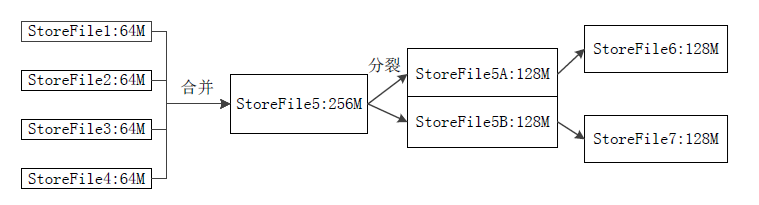
2 Store工作原理
先合并,如果合并后过大,那就再拆分。
04-HBase-06-应用方案
HBase只有一个针对行健的索引
访问HBase表中的行,只有三种方式:
- 通过单个行健访问
- 通过一个行健的区间来访问
- 全表扫描
使用其他产品为HBase行健提供索引功能:
- Hindex二级索引
- HBase+Redis
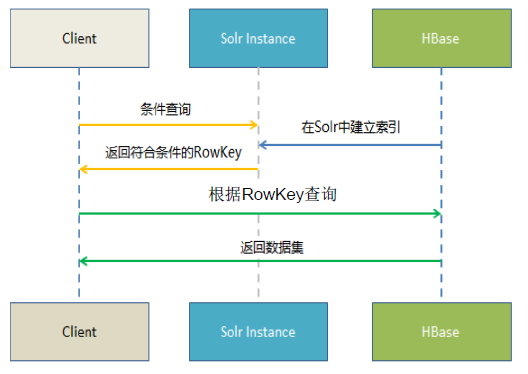
- HBase+solr
1 SQL引擎
(1) Hive整合HBase
(2) Phoenix
由Salesforce开源
Hindex 是华为公司开发的纯 Java 编写的HBase二级索引,兼容 Apache HBase 0.94.8。当前的特性如下:
- 多个表索引
- 多个列索引
- 基于部分列值的索引
2 二级索引
原生HBase只针对行键进行索引,但是使用其他产品为HBase行健提供索引功能。
基于HBase自带的存储器或者触发器Coprocessor功能,对HBase进行二次开发。
(1) 华为Hindex二级索引
(2) HBase+Redis
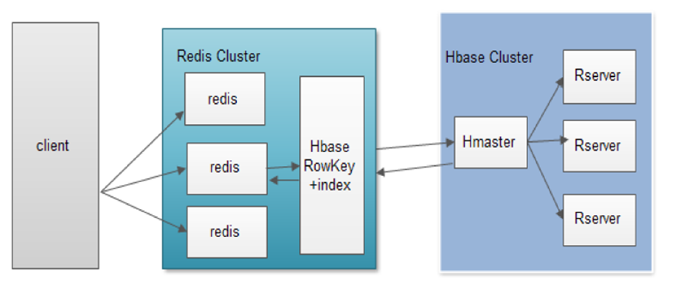
(3) HBase+solr















 124
124











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









