







🚀 作者主页: 有来技术
🔥 开源项目: youlai-mall 🍃 vue3-element-admin 🍃 youlai-boot
🌺 仓库主页: Gitee 💫 Github 💫 GitCode
💖 欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请纠正!
前言
在深入探索Spring框架的高级特性时,一个经常被提及的话题是“循环依赖”,特别是如何通过缓存机制来解决这个问题。循环依赖发生在两个或多个Bean相互依赖的情况下,如果没有合适的处理机制,就会导致应用启动失败或运行时错误。Spring框架通过引入一个三级缓存的机制来优雅地解决这一问题。这引发了一个有趣的问题:为什么是三级缓存而不是两级缓存?在本文中,我们将探讨Spring处理循环依赖的具体机制,尤其是为什么三级缓存是解决这一问题的关键。
什么是循环依赖?
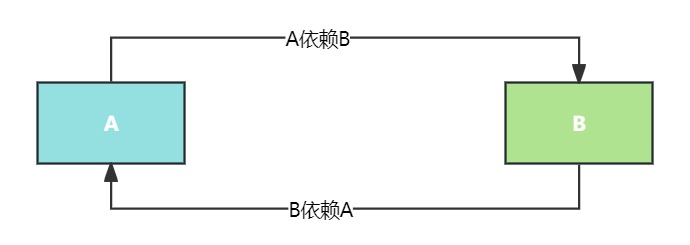
Spring循环依赖指的是两个或多个Bean之间存在直接或间接的循环引用关系。这种情况下,Bean A依赖于Bean B,同时Bean B又依赖于Bean A,形成一个循环依赖关系。在Spring容器中,如果不加以处理,这样的循环依赖可能导致程序无法正常启动或运行时出现异常。
举例说明,假设有两个服务类 A 和 B:
// A.java
@Service
public class A {
private B b;
@Autowired
public A(B b) {
this.b = b;
}
}
// B.java
@Service
public class B {
private A a;
@Autowired
public B(A a) {
this.a = a;
}
}
在上面的例子中,A 依赖于 B,而 B 依赖于 A,形成了一个循环依赖。
Sprring 的三级缓存
为了解决循环依赖问题,Spring使用了一个三级缓存的机制:
-
一级缓存(Singleton Objects):这是一个存储完全初始化好的bean的缓存。当一个bean被完全处理并准备好后,它会被放入这个缓存中。
-
二级缓存(Early Singleton Objects):这个缓存存储的是早期暴露的对象,即还没有完全初始化的bean。这些对象已经被实例化,但可能还没有完成依赖注入和初始化。
-
三级缓存(Singleton Factories):这个缓存存储的是bean工厂对象,它允许在bean完全初始化之前对其进行引用和操纵。
关于三级缓存逻辑在方法 DefaultSingletonBeanRegistry#getSingleton 体现的很全面。

为什么需要三级缓存?
Spring 解决循环为什么需要三级缓存?两级缓存不可以吗?
先说结论,两级缓存原则上可以解决循环依赖的问题,包括代理,但在某些情况下实现方式可能不够恰当。
| 缓存字段名 | 缓存级别 | 数据类型 | 描述 |
|---|---|---|---|
singletonObjects | 1 | Map<String, Object> | 存储 Bean 的完成品,完全初始化 |
earlySingletonObjects | 2 | Map<String, Object> | 存储 Bean 的半成品,尚未完成属性填充和初始化 |
singletonFactories | 3 | Map<String, ObjectFactory> | 存储创建 Bean 的 ObjectFactory 对象,生成半成品 Bean 放入二级缓存 |
两级缓存分为两种情况来说,分别是 一级缓存 + 二级缓存 和 一级缓存 + 三级缓存 两种组合。
-
组合一:一级缓存 + 二级缓存
singletonObjects+earlySingletonObjects理论可以解决依赖注入,也可以解决代理,但需要每次加入二级缓存都要是代理对象,如果没有代理就完全没有必要,同时也不符合 Spring 对 Bean 生命周期的定义。(对象都应该在创建建之后再进行动态代理而不是单纯的实例化以后就急着进行代理,如果循环依赖就是没办法的事) -
组合二:一级缓存 + 三级缓存
singletonObjects+singletonFactories可以解决依赖注入的问题,但是没法解决代理的问题,若要进行代理从ObjectFactory中获取对象实例进行代理,但是这样每次获取对象都不是同一个。
这里直接说结论,不理解没关系,可以先阅读后续的循环依赖流程和源码再来看结论。
Spring 循环依赖流程
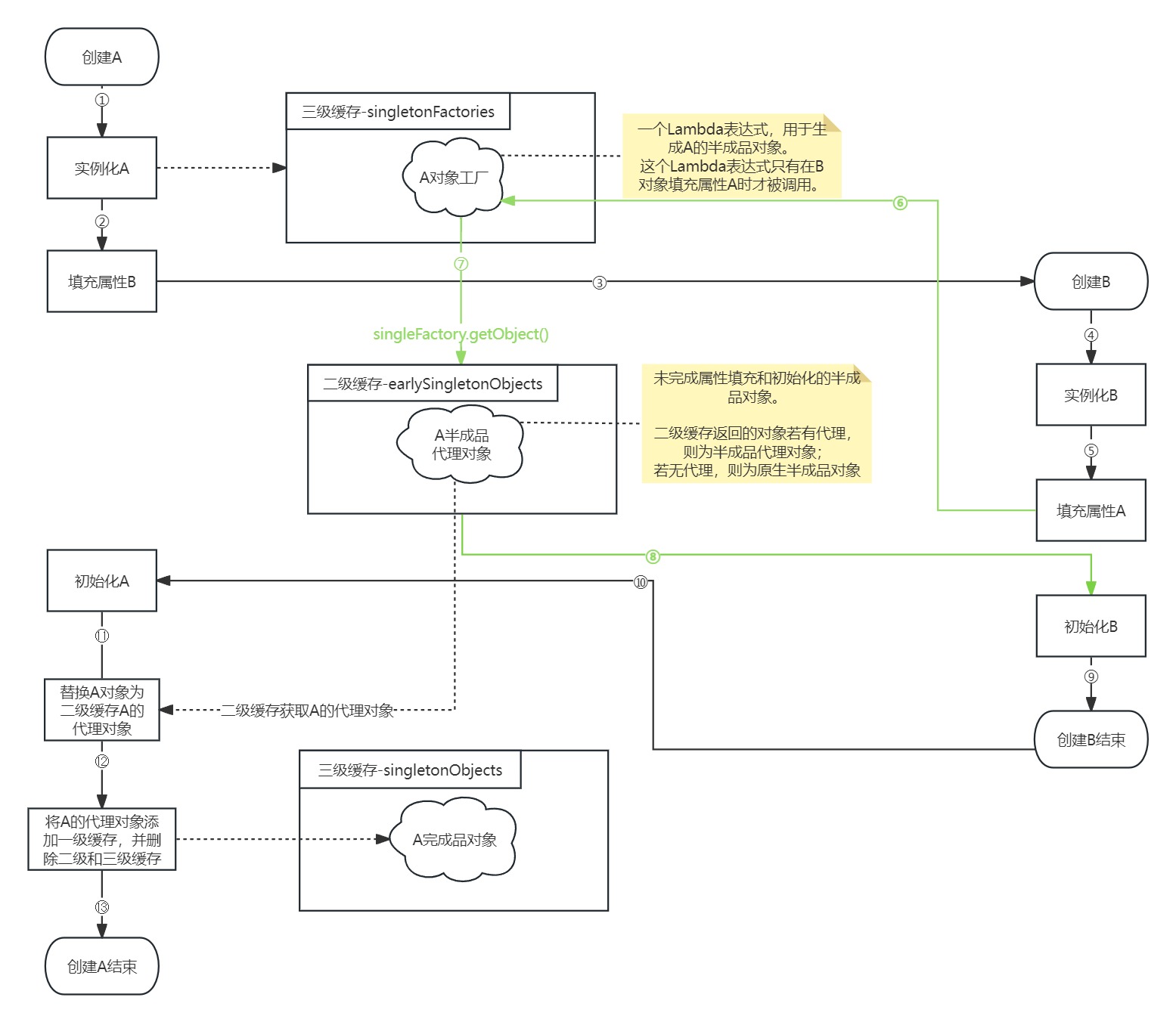
循环依赖的处理流程可以大致分为以下几个步骤:
- 实例化 A:Spring容器首先创建Bean A的实例。此时,A还未完全初始化,因为它依赖于B。
- 填充B的引用到A中:在A的创建过程中,Spring检测到A需要B的引用。但是,由于B还未创建,Spring容器会暂停A的创建过程,开始创建B。
- 实例化 B:Spring容器开始创建Bean B的实例。同样,此时B也未完全初始化,因为它依赖于A。
- 填充A的引用到B中:在B的创建过程中,Spring检测到B需要A的引用。这里就出现了循环依赖的情况。但是,由于A的实例已经部分创建,Spring容器可以使用已经存在的A的实例(尽管它还未完全初始化)来解决这个依赖。
- 完成 B 的创建:现在B有了A的引用,Spring可以完成B的初始化过程。
- 完成 A的创建:回到A的创建过程,现在B的实例已经可用,Spring可以完成A的初始化过程。
- 处理代理:如果A有代理(例如,使用了Spring AOP),这个代理将在这个阶段被创建和应用。通常,代理涉及到创建一个新的对象(代理对象),它包装了原始的A实例,并提供了额外的功能(如方法拦截、事务管理等)。
- 完全初始化的A和B:最终,A和B两个Bean都完全初始化了,并且它们相互引用,循环依赖得到了解决。
Spring通过使用三级缓存机制来解决循环依赖的问题。在这个机制中,Spring会在不同阶段将部分创建的Bean放入不同的缓存中,这样即使在Bean还没有完全初始化的情况下也可以提供这些Bean的引用,从而解决循环依赖的问题。
三级缓存源码解析
下面是 Spring 循环依赖的调用栈,A和B相互依赖,其中A存在代理。
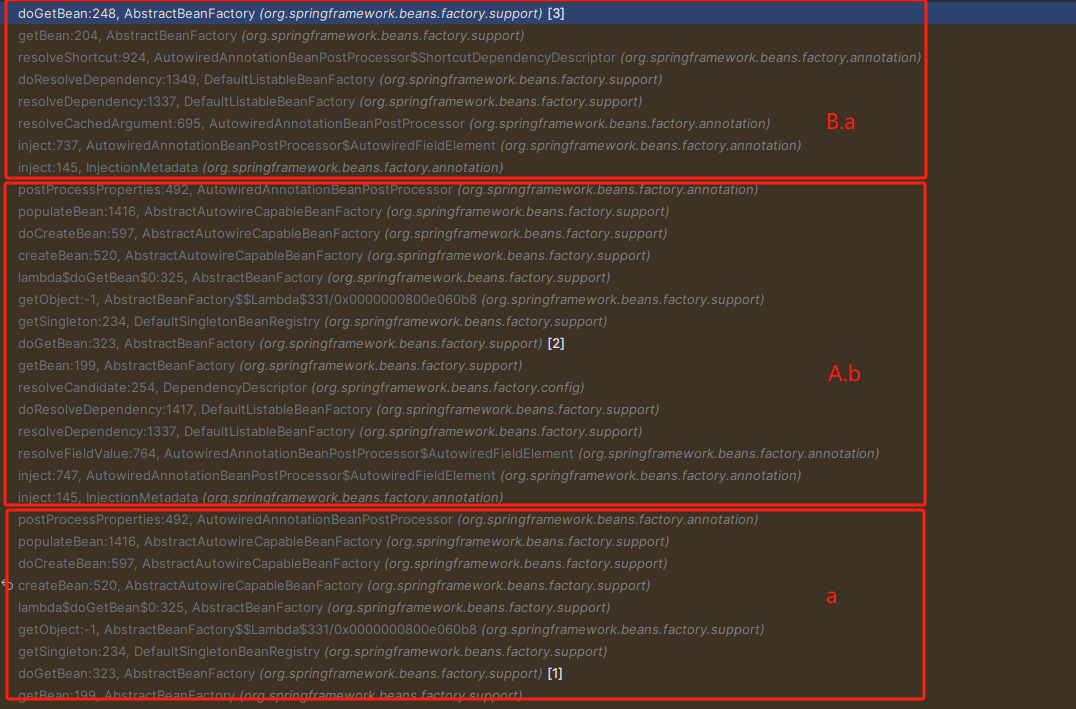
一切的开始 AbstractBeanFactory#doGetBean
protected <T> T doGetBean(
String name, @Nullable Class<T> requiredType, @Nullable Object[] args, boolean typeCheckOnly)
throws BeansException {
Object beanInstance;
// 首先尝试从单例缓存中获取手动注册的单例 Bean。
Object sharedInstance = getSingleton(beanName);
if (sharedInstance != null && args == null) {
} else {
// 标识 bean 创建中
StartupStep beanCreation = this.applicationStartup.start("spring.beans.instantiate")
.tag("beanName", name);
try {
if (mbd.isSingleton()) {
// 如果 Bean 定义为单例模式
sharedInstance = getSingleton(beanName, () -> {
try {
// 创建一个新的 Bean 实例。
return createBean(beanName, mbd, args);
}
catch (BeansException ex) {
// 创建失败时销毁单例。
destroySingleton(beanName);
throw ex;
}
});
// 获取 Bean 实例对象,处理特殊情况。
beanInstance = getObjectForBeanInstance(sharedInstance, name, beanName, mbd);
}
// 原型 Bean 的处理逻辑
else if (mbd.isPrototype()) {
}
}
finally {
// 标识 Bean 创建结束
beanCreation.end();
}
}
// 将 Bean 实例适配为所需类型。
return adaptBeanInsance(name, beanInstance, requiredType);
}
代理对象的处理
实例化A的时候将A工厂(lambda)表达式添加到三级缓存,B填充属性A调用DefaultSingletonBeanRegistry#getSingleton 方法通过singletonFactory.getObject();从三级缓存获取A对象,AbstractAutowireCapableBeanFactory#getEarlyBeanReference → AbstractAutoProxyCreator#getEarlyBeanReference→AbstractAutoProxyCreator#wrapIfNecessary

关于wrapIfNecessary方法,它是在AOP相关处理中非常关键的一个步骤。如果A的定义中包含了AOP相关的配置(如拦截器、通知等),那么Spring会为A创建一个代理对象,这个代理对象会包含所有的AOP逻辑。
如果一个bean没有被定义为需要AOP代理,那么wrapIfNecessary方法确实会返回一个原生的半成品对象。这里的“半成品对象”指的是bean实例已经被创建,但可能还没有完成所有的依赖注入或初始化。
结语
经过对Spring循环依赖处理机制的深入分析,我们可以总结出为什么Spring采用三级缓存而非两级缓存的原因。三级缓存不仅可以解决循环依赖中的依赖注入问题,还能有效处理潜在的代理问题。如果只使用两级缓存,虽然理论上可以解决依赖注入问题,但在处理代理和确保Bean生命周期的一致性方面可能不够完善。三级缓存允许Spring在不完全初始化Bean的情况下提供对其的引用,同时确保在Bean最终完成创建之前,可以对其进行代理和其他必要的处理。这种机制不仅解决了循环依赖的核心问题,而且保持了Spring对Bean生命周期的精确控制,这对于构建稳定和可维护的企业级应用至关重要。通过这种方式,Spring展现了其作为一个成熟和灵活的框架的实力,使开发者能够在复杂的应用场景中有效地管理依赖关系。















 1792
1792











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











