







REDIS 实践笔记和源码分析
魏言华 联系方式:15313236435
目录
10.4 Redis Sentinel 的执行过程和初始化... 135
通过持久化功能,Redis 保证了即使在服务器重启的情况下也不会丢失(或少量丢失)数据,但是由于数据是存储在一台服务器上的,如果这台服务器出现故障,比如硬盘坏了, 也会导致数据丢失。
为了避免单点故障,需要将数据复制多份部署在多台不同的服务器上,即使有一台服务器出现故障其他服务器依然可以继续提供服务。
这就要求当一台服务器上的数据更新后,自动将更新的数据同步到其他服务器上,redis主从复制功能正式解决此类问题的。
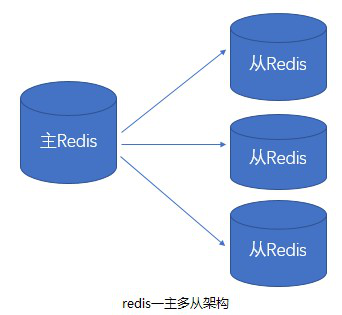
Redis 提供了复制(replication)功能来自动实现多台 redis 服务器的数据同步,可以通过部署多台 redis,并在配置文件中指定这几台 redis 之间的主从关系,主负责写入数据, 同时把写入的数据实时同步到从机器, 这种模式叫做主从复制, 即master/slave,并且 redis 默认 master 用于写,slave 用于读。
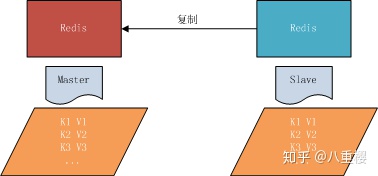
从节点开启主从复制,有3种方式:
1. 配置文件: 在从服务器的配置文件中加入:slaveof <masterip> <masterport>
2. 启动命令: redis-server启动命令后加入 --slaveof <masterip> <masterport>
3. 客户端命令: Redis服务器启动后,直接通过客户端执行命令:slaveof <masterip>
<masterport>,则该Redis实例成为从节点。
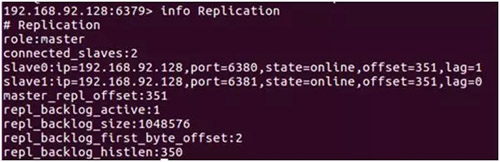
通过 info replication 命令可以看到复制的一些信息
1.1 配置文件方式搭建主从集群
模拟多 Reids 服务器, 在一台已经安装 Redis 的机器上,运行多个 Redis 应用模拟多个 Reids 服务器。一个 Master,两个 Slave.
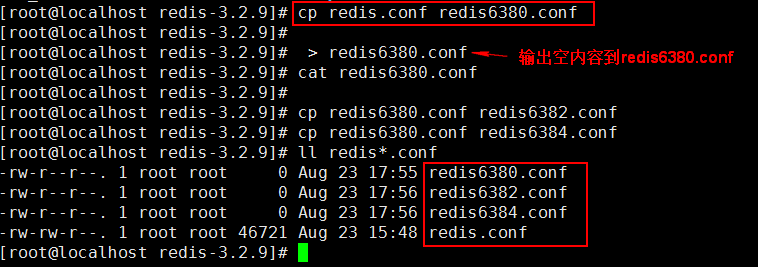
新建三个 Redis 的配置文件
如果 Redis 启动,先停止。
作为 Master 的 Redis 端口是 6380
作为 Slaver 的 Redis 端口分别是 6382 , 6384
从原有的 redis.conf 拷贝三份,分别命名为 redis6380.conf, redis6382.conf , redis6384.conf
1.1.1 编辑主从配置文件
编辑 Master 配置文件
编辑 Master 的配置文件 redis6380.conf : 在空文件加入如下内容
include /usr/local/redis-3.2.9/redis.conf
daemonize yes port 6380
pidfile /var/run/redis_6380.pid logfile 6380.log
dbfilename dump6380.rdb
配置项说明
| 1 | include | 包含原来的配置文件内容 |
| 2 | daemonize:yes | 后台运行redis |
| 3 | pidfile | 自定义的文件,表示当前程序的 pid ,进程 id |
| 4 | dbfilename | 持久化的 rdb 文件名 |
编辑 Slave 配置文件
编辑 Slave 的配置文件 redis6382.conf 和 redis6384.conf: 在空文件加入如下内容redis6382.conf:
include /usr/local/redis-3.2.9/redis.conf
daemonize yes
port 6382
pidfile /var/run/redis_6382.pid logfile 6382.log
dbfilename dump6382.rdb
slaveof 127.0.0.1 6380
1.1.2启动主从redis集群
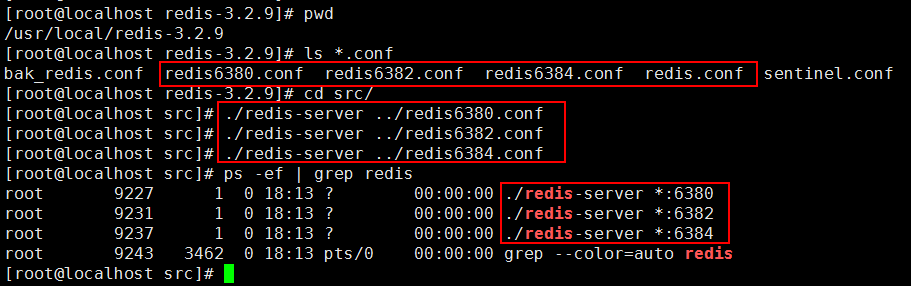
1.1.3 查看服务信息
Master 服务的查看结果
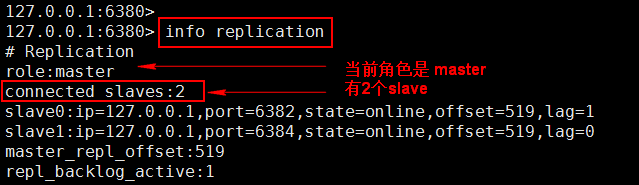
Slave服务的查看结果

1.2 容灾处理
master 上(冷处理:机器挂掉了,再处理)当 Master 服务出现故障,需手动将 slave 中的一个提升为 master, 剩下的 slave 挂至新的
命令:
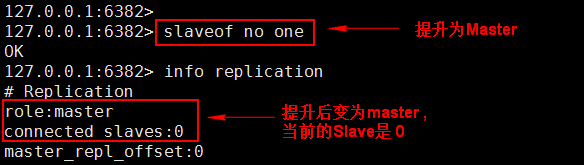
①:slaveof no one,将一台 slave 服务器提升为 Master (提升某 slave 为 master)
②:slaveof 127.0.0.1 6381 (将 slave 挂至新的 master 上)
执行步骤:
A、将 Master:6380 停止(模拟挂掉)

B、 选择一个 Slave 升到 Master,其它的 Slave 挂到新提升的 Master
C、 将其他 Slave 挂到新的 Master
在 Slave 6384 上执行
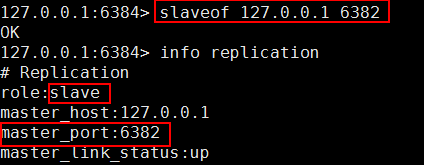
现在的主从(Master/Slave)关系:Master 是 6382 , Slave 是 6384
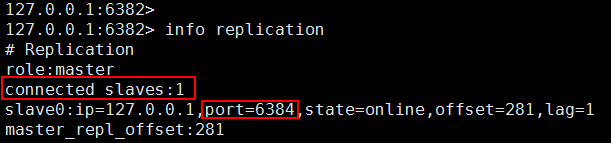
查看 6382:
D、原来的服务器重新添加到主从结构中
6380 的服务器修改后,从新工作,需要把它添加到现有的Master/Slave 中
先启动 6380 的 Redis 服务
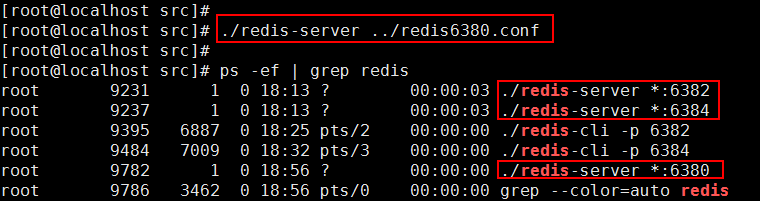
连接到 6380 端口
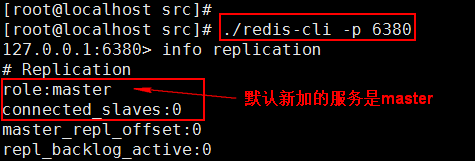
当前服务挂到 Master 上
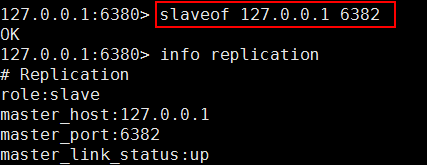
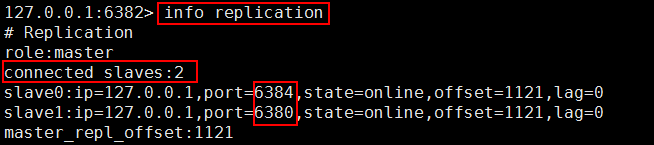
E、 查看新的 Master 信息
在 6382 执行:
1.3 主从架构特点
| 序号 | 描述 |
| 1 | 一个 master 可以有多个 slave |
| 2 | slave 下线,读请求的处理性能下降 |
| 3 | master 下线,写请求无法执行 |
| 4 | 当 master 发生故障,需手动将其中一台 slave 使用 slaveof no one 命令提升为 master,其它 slave 执行 slaveof 命令指向这个新的master,从新的master处同步数据。 |
| 5 | 主从复制模式的故障转移需要手动操作,要实现自动化处理,这就需要 Sentinel 哨兵,实现故障自动转移 |
1.4 主从复制原理
主从同步分为 2 个步骤:同步和命令传播
同步:将从服务器的数据库状态更新成主服务器当前的数据库状态。
命令传播:当主服务器数据库状态被修改后,导致主从服务器数据库状态不一致,此时需要让主从数据同步到一致的过程。
这里需要提前说明一下:在 Redis 2.8 版本之前,进行主从复制时一定会顺序执行上述两个步骤,而从 2.8 开始则可能只需要执行命令传播即可。
1.4.1 同步
从服务器对主服务的同步操作,需要通过 sync 命令来实现,以下是 sync 命令的执行步骤:
| 序号 | 步骤 |
| 1 | 从服务器向主服务器发送 sync 命令 |
| 2 | 收到 sync 命令后,主服务器执行 bgsave 命令,用来生成 rdb 文件,并在一个缓冲区中记录从现在开始执行的写命令。 |
| 3 | bgsave 执行完成后,将生成的 rdb 文件发送给从服务器,用来给从服务器更新数据 |
| 4 | 主服务器再将缓冲区记录的写命令发送给从服务器,从服务器执行完这些写命令后,此时的数据库状态便和主服务器一致了 |
1.4.1.1 主从建立连接
1.4.1.2 主从全量复制的流程

| 序号 | 步骤 |
| 1 | slave服务器连接到master服务器,便开始进行数据同步,发送psync命令(Redis2.8之前是sync命令) |
| 2 | master服务器收到psync命令之后,开始执行bgsave命令生成RDB快照文件并使用缓存区记录此后执行的所有写命令 |
| 3 | master服务器bgsave执行完之后,就会向所有Slava服务器发送快照文件,并在发送期间继续在缓冲区内记录被执行的写命令 |
| 4 | slave服务器收到RDB快照文件后,会将接收到的数据写入磁盘,然后清空所有旧数据,在从本地磁盘载入收到的快照到内存中,同时基于旧的数据版本对外提供服务 |
| 5 | master服务器发送完RDB快照文件之后,便开始向slave服务器发送缓冲区中的写命令 |
| 6 | slave服务器完成对快照的载入,开始接收命令请求,并执行来自主服务器缓冲区的写命令 |
| 7 | 如果slave node开启了AOF,那么会立即执行BGREWRITEAOF,重写AOF |
| |
1.4.2 命令传播
经过同步操作,此时主从的数据库状态其实已经一致了,但这种一致的状态的并不是一成不变的。
在完成同步之后,也许主服务器马上就接受到了新的写命令,执行完该命令后,主从的数据库状态又不一致。
为了再次让主从数据库状态一致,主服务器就需要向从服务器执行命令传播操作 ,即把刚才造成不一致的写命令,发送给从服务器去执行。从服务器执行完成之后,主从数据库状态就又恢复一致了。
1.4.3 全量同步和部分同步
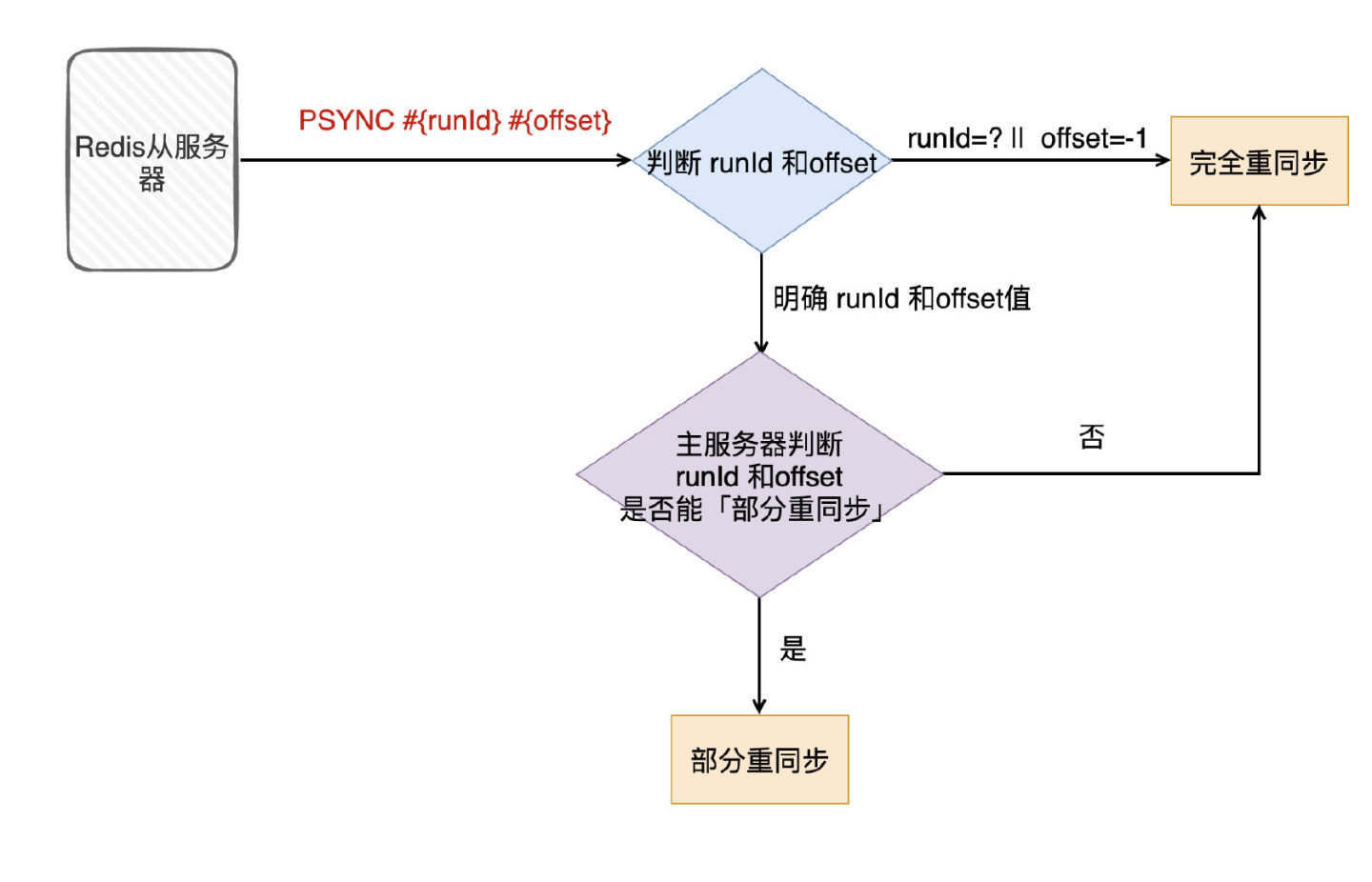
psync 具有完整重同步和部分重同步两种模式:
1.完整重同步:用于初次复制情况,执行过程同 sync,在这不赘述了。
2.部分重同步:用于断线后重复制情况,如果满足一定条件,主服务器只需要将断线期间执行的写命令发送给从服务器即可。
因此很明显,当主从同步出现断线后重复制的情况,psync 的部分重同步模式可以解决 sync 的低效情况。
redis2.8之前使用sync[runId][offset]同步命令,redis2.8之后使用psync[runId][offset]命令。
两者不同在于,sync命令仅支持全量复制过程,psync支持全量和部分复制。
介绍同步之前,先介绍几个概念:
1)runId:每个redis节点启动都会生成唯一的uuid,每次redis重启后,runId都会发生变化。
2)offset:主节点和从节点都各自维护自己的主从复制偏移量offset,当主节点有写入命令时,offset=offset+命令的字节长度。从节点在收到主节点发送的命令后,也会增加自己的offset,并把自己的offset发送给主节点。这样,主节点同时保存自己的offset和从节点的offset,通过对比offset来判断主从节点数据是否一致。
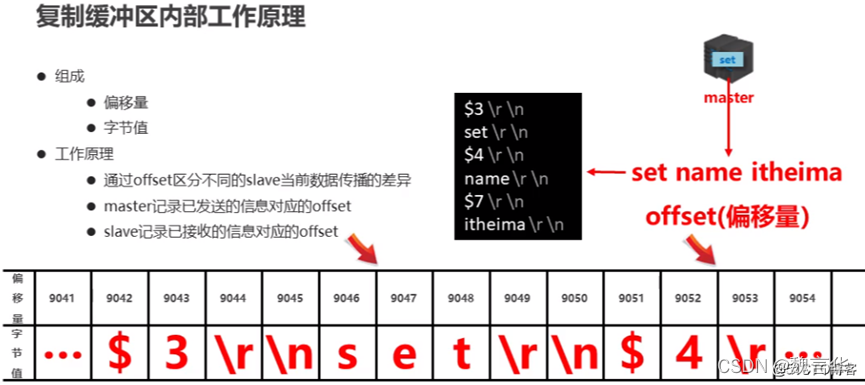
3)repl_backlog_size:保存在主节点上的一个固定长度的先进先出队列,默认大小是1MB。
主节点发送数据给从节点过程中,主节点还会进行一些写操作,这时候的数据存储在复制缓冲区中。从节点同步主节点数据完成后,主节点将缓冲区的数据继续发送给从节点,用于部分复制。
主节点响应写命令时,不但会把命名发送给从节点,还会写入复制积压缓冲区,用于复制命令丢失的数据补救。
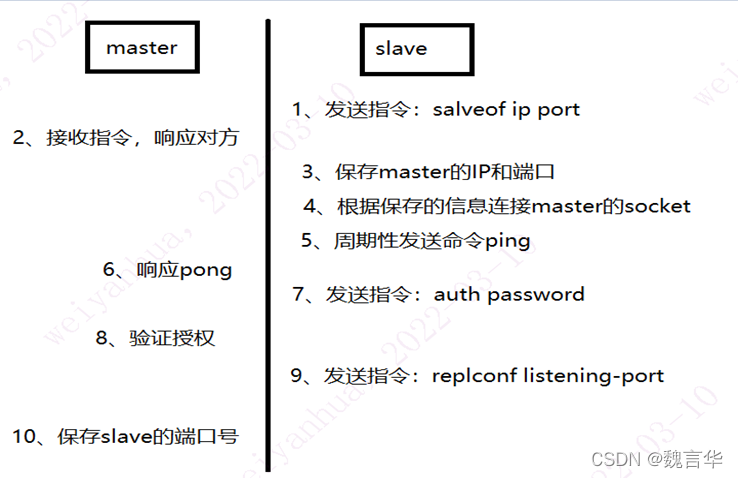
上面是psync的执行流程:
从节点发送psync[runId][offset]命令,主节点有三种响应:
1)主节点返回 fullresync {runid} {offset}回复,表示主节点要求与从节点进行数据的完整全量复制,其中runid表示主节点的运行ID,offset表示当前主节点的复制偏移量
2)如果主服务器返回 +continue,表示主节点与从节点会进行部分数据的同步操作,将从服务器缺失的数据复制过来即可
3)如果主服务器返回 -err,表示主服务器的Redis版本低于2.8,无法识别psync命令,此时从服务器会向主服务器发送sync命令,进行完整的数据全量复制
1.4.4全量复制和部分复制的过程
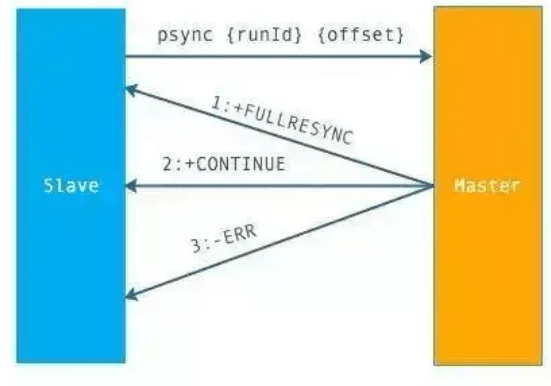
| 序号 | 步骤 |
| 1 | 从节点发送psync ? -1命令(因为第一次发送,不知道主节点的runId,所以为?,因为是第一次复制,所以offset=-1) |
| 2 | 主节点发现从节点是第一次复制,返回FULLRESYNC {runId} {offset},runId是主节点的runId,offset是主节点目前的offset |
| 3 | 从节点接收主节点信息后,保存到info中 |
| 4 | 主节点在发送FULLRESYNC后,启动bgsave命令,生成RDB文件(数据持久化) |
| 5 | 主节点发送RDB文件给从节点。到从节点加载数据完成这段期间主节点的写命令放入缓冲区 |
| 6 | 从节点清理自己的数据库数据,从节点加载RDB文件,将数据保存到自己的数据库中。如果从节点开启了AOF,从节点会异步重写AOF文件 |
部分复制说明:
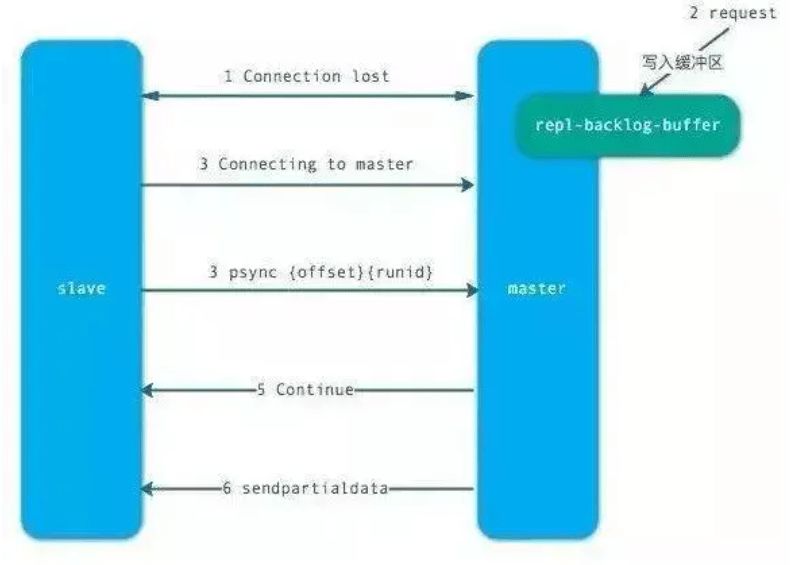
1)部分复制主要是Redis针对全量复制的过高开销做出的一种优化措施,使用psync[runId][offset]命令实现。当从节点正在复制主节点时,如果出现网络闪断或者命令丢失等异常情况时,从节点会向主节点要求补发丢失的命令数据,主节点的复制积压缓冲区将这部分数据直接发送给从节点,这样就可以保持主从节点复制的一致性。补发的这部分数据一般远远小于全量数据。
2)主从连接中断期间主节点依然响应命令,但因复制连接中断命令无法发送给从节点,不过主节点内的复制积压缓冲区依然可以保存最近一段时间的写命令数据。
3)当主从连接恢复后,由于从节点之前保存了自身已复制的偏移量和主节点的运行ID。因此会把它们当做psync参数发送给主节点,要求进行部分复制。
4)主节点接收到psync命令后首先核对参数runId是否与自身一致,如果一致,说明之前复制的是当前主节点;之后根据参数offset在复制积压缓冲区中查找,如果offset之后的数据存在,则对从节点发送+COUTINUE命令,表示可以进行部分复制。因为缓冲区大小固定,若发生缓冲溢出,则进行全量复制。
5)主节点根据偏移量把复制积压缓冲区里的数据发送给从节点,保证主从复制进入正常状态。
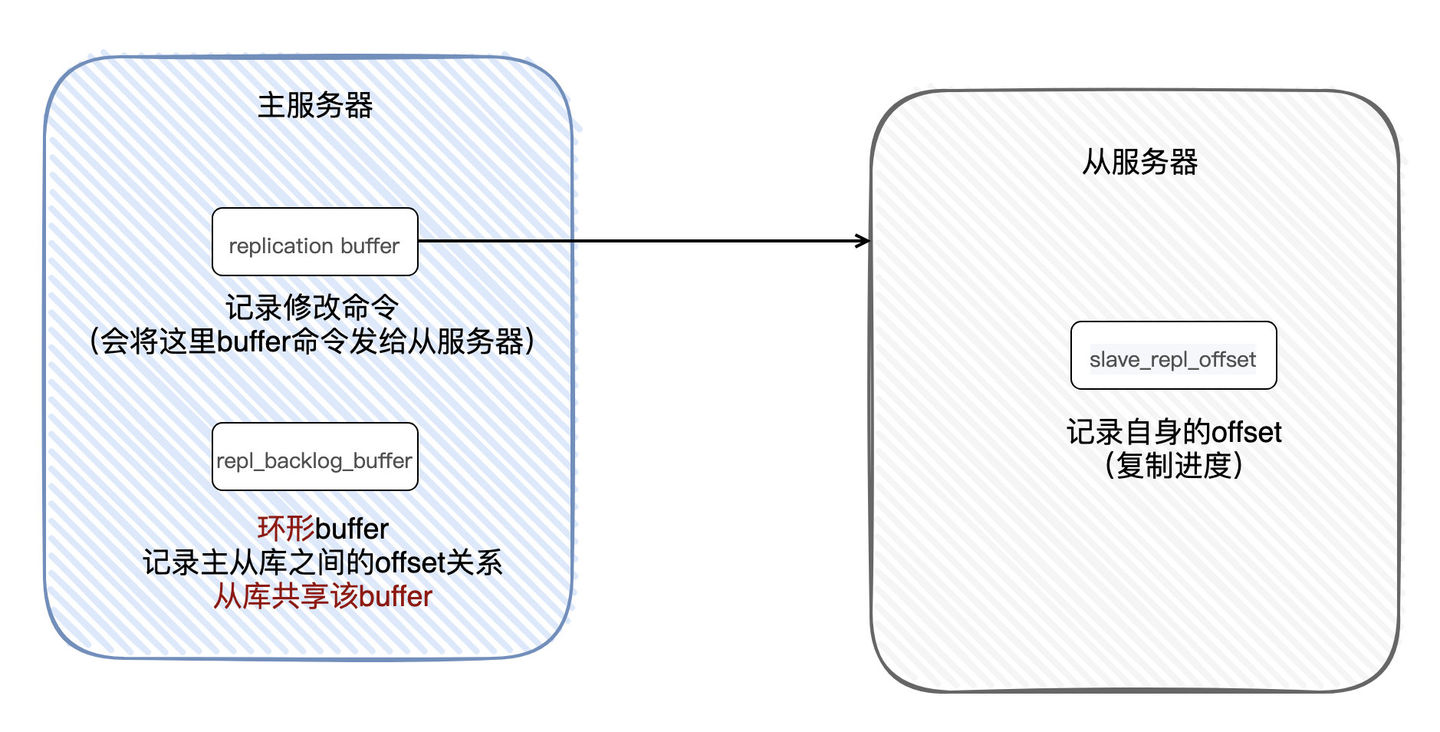
主从间的部分同步其实就是靠offset来进行同步的,每次主服务器传播命令时都会把offset给到从服务器,主从服务器都会把offset保存起来(如果两边offset存在差异,说明主从服务器间未安全同步)。
从服务器断连重新连接后,就会发送PSYNC命令给主服务器,同样也会带着RUNID,offset。主服务器收到后看RUNID是否与自身的匹配,如果匹配说明之前已经同步过一部分数据,接着检查offset若环形队列存在从服务器的offset偏移量 + 1 后的数据,则进行部分重同步,否则进行完整重同步。
1.4.5复制缓冲区原理

1.5主从报活
当完成了同步之后,主从服务器就会进入命令传播阶段,此时从服务器会以每秒 1 次的频率,向主服务器发送命令:REPLCONF ACK <replication_offset> 其中 replication_offset 是从服务器当前的复制偏移量
发送这个命令主要有三个作用:
1)检测主从服务器的网络状态
2)辅助实现 min-slaves 选项
3)检测命令丢失(若丢失,主服务器会将丢失的写命令重新发给从服务器)
在命令传播阶段,从服务器默认以每秒一次的频率,向主服务器发送命令:
REPLCONF ACK <replication_offset> //replication_offset是从服务器当前的复制偏移量。
心跳检测的作用:检测主服务器的网络连接状态;辅助实现min-slaves选项;检测命令丢失。
通过向主服务器发送INFO replication命令,可以列出从服务器列表,可以看出从最后一次向主发送命令距离现在过了多少秒。

辅助实现min-slaves选项
Redis可以通过配置防止主服务器在不安全的情况下执行写命令;
min-slaves-to-write 3
min-slaves-max-lag 10
上面的配置表示:从服务器的数量少于3个,或者三个从服务器的延迟(lag)值都大于或等于10秒时,主服务器将拒绝执行写命令。这里的延迟值就是上面INFOreplication命令的lag值。
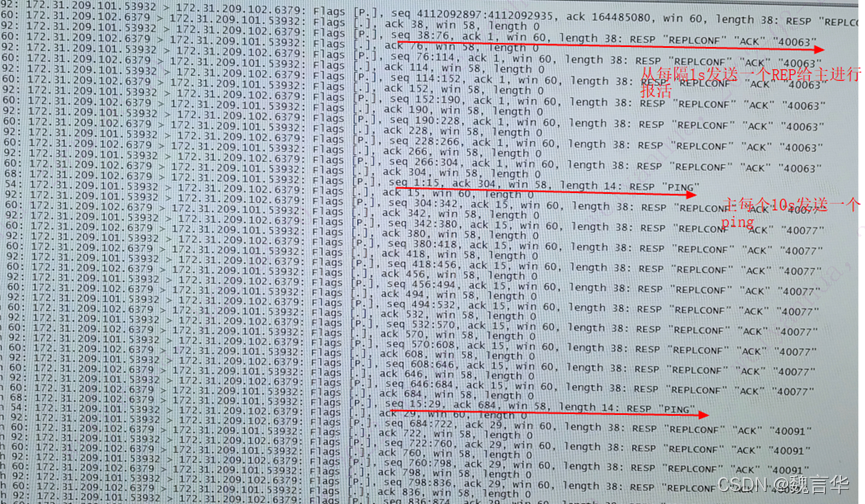
1.6主从常见问题
1.6.1读写分离及其中的问题
在主从复制基础上实现的读写分离,可以实现Redis的读负载均衡:由主节点提供写服务,由一个或多个从节点提供读服务(多个从节点既可以提高数据冗余程度,也可以最大化读负载能力);在读负载较大的应用场景下,可以大大提高Redis服务器的并发量。下面介绍在使用Redis读写分离时,需要注意的问题。
1)延迟与不一致问题
前面已经讲到,由于主从复制的命令传播是异步的,延迟与数据的不一致不可避免。如果应用对数据不一致的接受程度程度较低,可能的优化措施包括:优化主从节点之间的网络环境(如在同机房部署);监控主从节点延迟(通过offset)判断,如果从节点延迟过大,通知应用不再通过该从节点读取数据;使用集群同时扩展写负载和读负载等。
在命令传播阶段以外的其他情况下,从节点的数据不一致可能更加严重,例如连接在数据同步阶段,或从节点失去与主节点的连接时等。从节点的slave-serve-stale-data参数便与此有关:它控制这种情况下从节点的表现;如果为yes(默认值),则从节点仍能够响应客户端的命令,如果为no,则从节点只能响应info、slaveof等少数命令。该参数的设置与应用对数据一致性的要求有关;如果对数据一致性要求很高,则应设置为no。
2)数据过期问题
在单机版Redis中,存在两种删除策略:
惰性删除:服务器不会主动删除数据,只有当客户端查询某个数据时,服务器判断该数据是否过期,如果过期则删除。
定期删除:服务器执行定时任务删除过期数据,但是考虑到内存和CPU的折中(删除会释放内存,但是频繁的删除操作对CPU不友好),该删除的频率和执行时间都受到了限制。
在主从复制场景下,为了主从节点的数据一致性,从节点不会主动删除数据,而是由主节点控制从节点中过期数据的删除。由于主节点的惰性删除和定期删除策略,都不能保证主节点及时对过期数据执行删除操作,因此,当客户端通过Redis从节点读取数据时,很容易读取到已经过期的数据。
Redis 3.2中,从节点在读取数据时,增加了对数据是否过期的判断:如果该数据已过期,则不返回给客户端;将Redis升级到3.2可以解决数据过期问题。
3)故障切换问题
在没有使用哨兵的读写分离场景下,应用针对读和写分别连接不同的Redis节点;当主节点或从节点出现问题而发生更改时,需要及时修改应用程序读写Redis数据的连接;连接的切换可以手动进行,或者自己写监控程序进行切换,但前者响应慢、容易出错,后者实现复杂,成本都不算低。
在使用读写分离之前,可以考虑其他方法增加Redis的读负载能力:如尽量优化主节点(减少慢查询、减少持久化等其他情况带来的阻塞等)提高负载能力;使用Redis集群同时提高读负载能力和写负载能力等。如果使用读写分离,可以使用哨兵,使主从节点的故障切换尽可能自动化,并减少对应用程序的侵入。
1.6.2复制超时问题
在复制连接建立过程中及之后,主从节点都有机制判断连接是否超时,其意义在于:
如果主节点判断连接超时,其会释放相应从节点的连接,从而释放各种资源,否则无效的从节点仍会占用主节点的各种资源(输出缓冲区、带宽、连接等);此外连接超时的判断可以让主节点更准确的知道当前有效从节点的个数,有助于保证数据安全(配合前面讲到的min-slaves-to-write等参数)。
如果从节点判断连接超时,则可以及时重新建立连接,避免与主节点数据长期的不一致。
判断机制
主从复制超时判断的核心,在于repl-timeout参数,该参数规定了超时时间的阈值(默认60s),对于主节点和从节点同时有效;主从节点触发超时的条件分别如下:
主节点:每秒1次调用复制定时函数replicationCron(),在其中判断当前时间距离上次收到各个从节点REPLCONF ACK的时间,是否超过了repl-timeout值,如果超过了则释放相应从节点的连接。
从节点:从节点对超时的判断同样是在复制定时函数中判断,基本逻辑是:
如果当前处于连接建立阶段,且距离上次收到主节点的信息的时间已超过repl-timeout,则释放与主节点的连接;
如果当前处于数据同步阶段,且收到主节点的RDB文件的时间超时,则停止数据同步,释放连接;
如果当前处于命令传播阶段,且距离上次收到主节点的PING命令或数据的时间已超过repl-timeout值,则释放与主节点的连接。
1.6.3 常见问题
1)数据同步阶段:在主从节点进行全量复制bgsave时,主节点需要首先fork子进程将当前数据保存到RDB文件中,然后再将RDB文件通过网络传输到从节点。如果RDB文件过大,主节点在fork子进程+保存RDB文件时耗时过多,可能会导致从节点长时间收不到数据而触发超时;此时从节点会重连主节点,然后再次全量复制,再次超时,再次重连……这是个悲伤的循环。为了避免这种情况的发生,除了注意Redis单机数据量不要过大,另一方面就是适当增大repl-timeout值,具体的大小可以根据bgsave耗时来调整。
2)命令传播阶段:如前所述,在该阶段主节点会向从节点发送PING命令,频率由repl-ping-slave-period控制;该参数应明显小于repl-timeout值(后者至少是前者的几倍)。否则,如果两个参数相等或接近,网络抖动导致个别PING命令丢失,此时恰巧主节点也没有向从节点发送数据,则从节点很容易判断超时。
3)慢查询导致的阻塞:如果主节点或从节点执行了一些慢查询(如keys *或者对大数据的hgetall等),导致服务器阻塞;阻塞期间无法响应复制连接中对方节点的请求,可能导致复制超时。
2 哨兵部署
2.1 哨兵的作用
Redis Sentinel,即 Redis 哨兵,在 Redis 2.8 版本开始引入。哨兵的核心功能是主节点的自动故障转移。
下面是 Redis 官方文档对于哨兵功能的描述:
- 监控(Monitoring):哨兵会不断地检查主节点和从节点是否运作正常。
- 自动故障转移(Automatic failover):当主节点不能正常工作时,哨兵会开始自动故障转移操作,它会将失效主节点的其中一个从节点升级为新的主节点,并让其他从节点改为复制新的主节点。
- 配置提供者(Configurationprovider):客户端在初始化时,通过连接哨兵来获得当前 Redis 服务的主节点地址。
- 通知(Notification):哨兵可以将故障转移的结果发送给客户端。
其中,监控和自动故障转移功能,使得哨兵可以及时发现主节点故障并完成转移;而配置提供者和通知功能,则需要在与客户端的交互中才能体现。
这里对“客户端”一词在本文的用法做一个说明:在前面的文章中,只要通过 API 访问 Redis 服务器,都会称作客户端,包括 redis-cli、Java 客户端 Jedis 等。
为了便于区分说明,本文中的客户端并不包括 redis-cli,而是比 redis-cli 更加复杂。
redis-cli 使用的是 Redis 提供的底层接口,而客户端则对这些接口、功能进行了封装,以便充分利用哨兵的配置提供者和通知功能。
2.2 哨兵部署架构
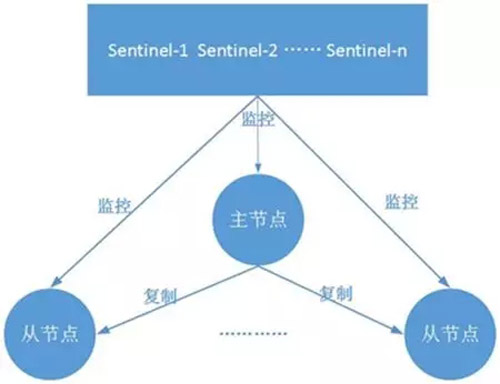
它由两部分组成,哨兵节点和数据节点:
1)哨兵节点:哨兵系统由一个或多个哨兵节点组成,哨兵节点是特殊的 Redis 节点,不存储数据。
2)数据节点:主节点和从节点都是数据节点。
2.3 哨兵系统的部署方法
这一部分将部署一个简单的哨兵系统,包含 1 个主节点、2 个从节点和 3 个哨兵节点。
方便起见:所有这些节点都部署在一台机器上(局域网 IP:192.168.92.128),使用端口号区分;节点的配置尽可能简化。
2.3.1部署主从节点
哨兵系统中的主从节点,与普通的主从节点配置是一样的,并不需要做任何额外配置。
下面分别是主节点(port=6379)和 2 个从节点(port=6380/6381)的配置文件
#redis-6379.conf
port 6379
daemonize yes
logfile "6379.log"
dbfilename "dump-6379.rdb"
#redis-6380.conf
port 6380
daemonize yes
logfile "6380.log"
dbfilename "dump-6380.rdb"
slaveof 192.168.92.128 6379
#redis-6381.conf
port 6381
daemonize yes
logfile "6381.log"
dbfilename "dump-6381.rdb"
slaveof 192.168.92.128 6379
配置完成后,依次启动主节点和从节点:
redis-server redis-6379.conf redis-server redis-6380.conf redis-server redis-6381.conf 节点启动后,连接主节点查看主从状态是否正常,如下图所示:
2.3.2部署哨兵节点
哨兵节点本质上是特殊的 Redis 节点。3 个哨兵节点的配置几乎是完全一样的,主要区别在于端口号的不同(26379/26380/26381)。
下面以 26379 节点为例,介绍节点的配置和启动方式
复制
#sentinel-26379.conf
port 26379
daemonize yes
logfile "26379.log"
sentinel monitor mymaster 192.168.92.128 6379 2
sentinel down-after-milliseconds mymaster 30000
sentinel parallel-syncs mymaster 1
sentinel failover-timeout mymaster 180000
| 序号 | 解析 |
| 1 | port 26379:对外服务端口号 |
| 2 | dir /tmp:存储哨兵的工作信息 |
| 3 | sentinel monitor mymaster 127.0.0.1 6379 2:监控的是谁,名字可以自定义,后边的 2 代表的是,如果有俩个哨兵判断这个主节点挂了那这个主节点就挂了,通常设置为哨兵个数一半加一 |
| 4 | sentinel down-after-milliseconds mymaster 30000:哨兵连接主节点多长时间没有响应就代表挂了。后边 30000 是毫秒,也就是 30 秒 |
| 5 | sentinel parallel-syncs mymaster 1:这个配置项是指在故障转移时,最多有多少个从节点同时对新的主节点进行同步 这个值越小完成故障转移的时间就越长,这个值越大就意味着越多的从节点因为同步数据而不可用 |
| 6 | sentinel failover-timeout mymaster 180000:在进行同步的过程中,多长时间完成算有效,系统默认值是 3 分钟 |
哨兵节点的启动有两种方式,二者作用是完全相同的:
redis-sentinel sentinel-26379.conf
redis-server sentinel-26379.conf --sentinel
按照上述方式配置和启动之后,整个哨兵系统就启动完毕了,可以通过 redis-cli 连接哨兵节点进行验证。
如下图所示:可以看出 26379 哨兵节点已经在监控 mymaster 主节点(即192.168.92.128:6379),并发现了其 2 个从节点和另外 2 个哨兵节点。
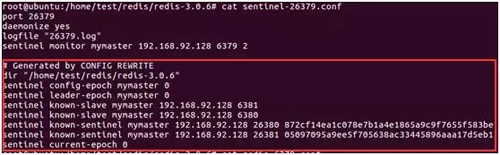
known-slave 和 known-sentinel 显示哨兵已经发现了从节点和其他哨兵。
带有 epoch 的参数与配置纪元有关(配置纪元是一个从 0 开始的计数器,每进行一次哨兵选举,都会 +1;哨兵选举是故障转移阶段的一个操作)
2.3.3演示故障转移
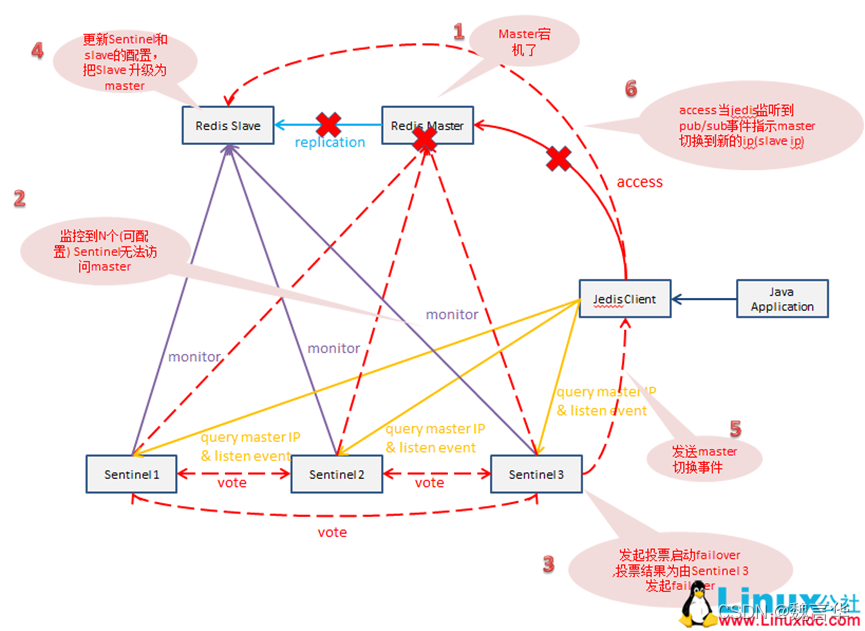
这一小节将演示当主节点发生故障时,哨兵的监控和自动故障转移功能。
- 首先,使用 Kill 命令杀掉主节点:

2)如果此时立即在哨兵节点中使用 info Sentinel 命令查看,会发现主节点还没有切换过来,因为哨兵发现主节点故障并转移,需要一段时间。

- 一段时间以后,再次在哨兵节点中执行 info Sentinel 查看,发现主节点已经切换成 6380 节点

同时可以发现,哨兵节点认为新的主节点仍然有 2 个从节点,这是因为哨兵在将 6380 切换成主节点的同时,将 6379 节点置为其从节点。
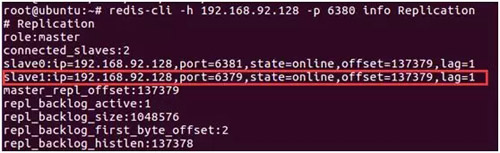
虽然 6379 从节点已经挂掉,但是由于哨兵并不会对从节点进行客观下线,因此认为该从节点一直存在,当 6379 节点重新启动后,会自动变成 6380 节点的从节点。
- 重启 6379 节点:可以看到 6379 节点成为了 6380 节点的从节点
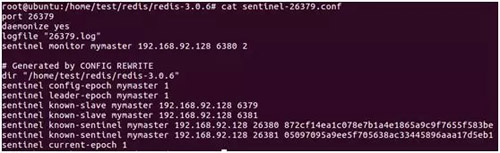
- 在故障转移阶段,哨兵和主从节点的配置文件都会被改写
对于主从节点,主要是 slaveof 配置的变化:新的主节点没有了 slaveof 配置,其从节点则 slaveof 新的主节点。
对于哨兵节点,除了主从节点信息的变化,纪元(epoch)也会变化,下图中可以看到纪元相关的参数都 +1 了
2.4 哨兵的基本原理
哨兵节点作为运行在特殊模式下的 Redis 节点,其支持的命令与普通的 Redis 节点不同。
在运维中,我们可以通过这些命令查询或修改哨兵系统;不过更重要的是,哨兵系统要实现故障发现、故障转移等各种功能,离不开哨兵节点之间的通信。
而通信的很大一部分是通过哨兵节点支持的命令来实现的。下面介绍哨兵节点支持的主要命令
| sentinel info | 获取监控的所有redis节点的基本信息 |
| sentinel masters | 获取监控的所有主节点的详细信息 |
| sentinel master mymaster | 获取监控的主节点 mymaster 的详细信息 |
| sentinel slaves mymaster | 获取监控的主节点 mymaster 的从节点的详细信息 |
| sentinel sentinels mymaster | 获取监控的主节点 mymaster 的哨兵节点的详细信息 |
| sentinel get-master-addr-by-name mymaster | 获取监控的主节点 mymaster 的地址信息 |
| sentinel is-master-down-by-addr | 哨兵节点之间可以通过该命令询问主节点是否下线,从而对是否客观下线做出判断 |
| sentinel monitor mymaster2 192.168.92.128 16379 2 | 增加监控主节点 |
| sentinel remove mymaster2 | 取消当前哨兵节点对主节点 mymaster2 的监控 |
| sentinel failover mymaster | 该命令可以强制对 mymaster 执行故障转移,即便当前的主节点运行完好。 例如,如果当前主节点所在机器即将报废,便可以提前通过failover命令进行故障转移 |
2.4.1基本原理
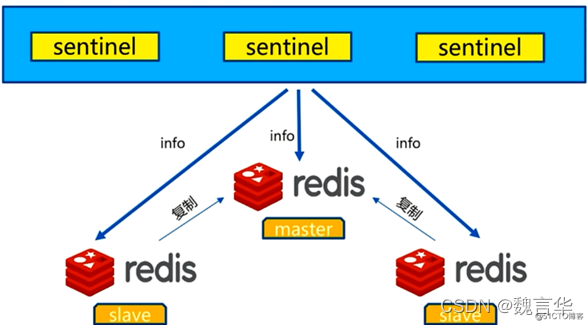
1)定时任务
每个哨兵节点维护了 3 个定时任务,定时任务的功能分别如下:
- 通过向主从节点发送 info 命令获取redis实例的主从结构;
b)通过发布订阅功能获取其他哨兵节点的信息;
c)通过向其他节点发送 ping 命令进行心跳检测,判断是否下线;
2)主观下线
在心跳检测的定时任务中,如果其他节点超过一定时间没有回复,哨兵节点就会将其进行主观下线。
顾名思义,主观下线的意思是一个哨兵节点“主观地”判断下线;与主观下线相对应的是客观下线。
3)客观下线
哨兵节点在对主节点进行主观下线后,会通过 sentinelis-master-down-by-addr 命令询问其他哨兵节点该主节点的状态。
如果判断主节点下线的哨兵数量达到一定数值,则对该主节点进行客观下线。
需要特别注意的是,客观下线是主节点才有的概念;如果从节点和哨兵节点发生故障,被哨兵主观下线后,不会再有后续的客观下线和故障转移操作。
4)选举哨兵节点
当主节点被判断客观下线以后,各个哨兵节点会进行协商,选举出一个哨兵节点,并由该节点对其进行故障转移操作。
监视该主节点的所有哨兵都有可能被选为leader,选举使用的算法是 Raft 算法。
Raft 算法的基本思路是先到先得:即在一轮选举中,哨兵 A 向 B 发送成为leader的申请,如果 B 没有同意过其他哨兵,则会同意 A 成为leader。
选举的具体过程这里不做详细描述,一般来说,哨兵选择的过程很快,谁先完成客观下线,一般就能成为leader。
5)故障转移
选举出的leader哨兵,开始进行故障转移操作,该操作大体可以分为 3 个步骤:
a)在从节点中选择新的主节点:选择的原则是,首先过滤掉不健康的从节点,然后选择优先级高的从节点(由 slave-priority 指定)。
b) 如果优先级无法区分,则选择复制偏移量大的从节点;如果仍无法区分,则选择 runid 最小的从节点。
c)更新主从状态:通过 slaveof no one 命令,让选出来的从节点成为主节点;并通过 slaveof 命令让其他节点成为其从节点。并将已经下线的主节点(即 6379)设置为新的主节点的从节点,当 6379 重新上线后,它会成为新的主节点的从节点。
通过上述几个关键概念,可以基本了解哨兵的工作原理。为了更形象的说明,下图展示了leader哨兵节点的日志,包括从节点启动到完成故障转移。
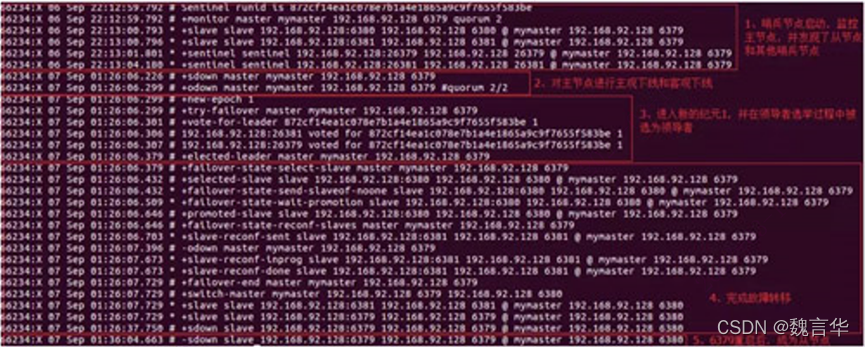
2.4.2哨兵配置与实践建议
sentinel monitor {masterName} {masterIp} {masterPort}{quorum}
sentinel monitor 是哨兵最核心的配置,在前文讲述部署哨兵节点时已说明,其中:masterName 指定了主节点名称,masterIp 和 masterPort 指定了主节点地址,quorum 是判断主节点客观下线的哨兵数量阈值。
当判定主节点下线的哨兵数量达到 quorum 时,对主节点进行客观下线。建议取值为哨兵数量的一半加 1。
sentinel down-after-milliseconds {masterName} {time}
sentinel down-after-milliseconds 与主观下线的判断有关:哨兵使用 ping 命令对其他节点进行心跳检测。
如果其他节点超过 down-after-milliseconds 配置的时间没有回复,哨兵就会将其进行主观下线,该配置对主节点、从节点和哨兵节点的主观下线判定都有效。
down-after-milliseconds 的默认值是 30000,即 30s;可以根据不同的网络环境和应用要求来调整。
值越大,对主观下线的判定会越宽松,好处是误判的可能性小,坏处是故障发现和故障转移的时间变长,客户端等待的时间也会变长。
例如,如果应用对可用性要求较高,则可以将值适当调小,当故障发生时尽快完成转移;如果网络环境相对较差,可以适当提高该阈值,避免频繁误判。
sentinel parallel-syncs {masterName} {number}
sentinel parallel-syncs 与故障转移之后从节点的复制有关:它规定了每次向新的主节点发起复制操作的从节点个数。
例如,假设主节点切换完成之后,有 3 个从节点要向新的主节点发起复制;如果 parallel-syncs=1,则从节点会一个一个开始复制;如果 parallel-syncs=3,则 3 个从节点会一起开始复制。
parallel-syncs 取值越大,从节点完成复制的时间越快,但是对主节点的网络负载、硬盘负载造成的压力也越大;应根据实际情况设置。
例如,如果主节点的负载较低,而从节点对服务可用的要求较高,可以适量增加 parallel-syncs 取值。parallel-syncs 的默认值是 1。
sentinel failover-timeout {masterName} {time}
sentinel failover-timeout 与故障转移超时的判断有关,但是该参数不是用来判断整个故障转移阶段的超时,而是其几个子阶段的超时。
例如如果主节点晋升从节点时间超过 timeout,或从节点向新的主节点发起复制操作的时间(不包括复制数据的时间)超过 timeout,都会导致故障转移超时失败。
failover-timeout 的默认值是 180000,即 180s;如果超时,则下一次该值会变为原来的 2 倍。
2.4.3 哨兵定时任务
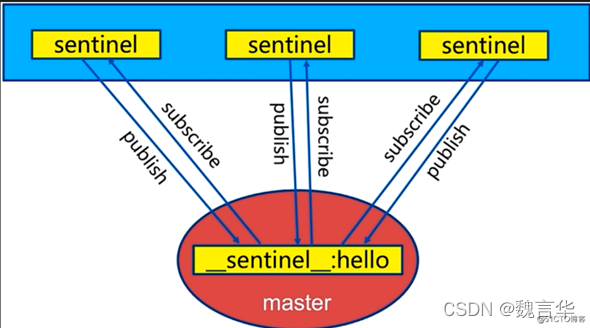
第一个定时任务:每10秒每个sentinel对master和slave执行info
1)发现slave节点
2)确认主从关系
第二个定时任务:每2秒每个sentinel通过master节点的channel交换信息(pub/sub)
1)通过sentinel__:hello频道交互
2)交互对节点的“看法”和自身信息
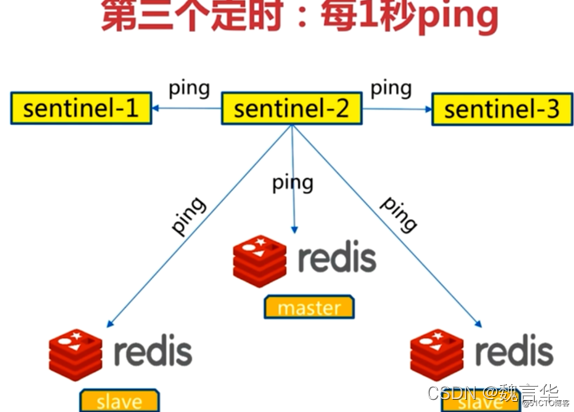
第三个定时任务:每1秒每个sentinel对其他sentinel和redis执行ping
- 心跳检测,失败判定的依据
2.4.4客户端
Sentinel是Redis官方提供的一种高可用方案(除了Sentinel,Redis Cluster是另一种方案),它可以自动监控Redis master/slave的运行状态,如果发现master无法访问了,就会启动failover把其中一台可以访问的slave切换为master,并且通过pub/sub事件通知Redis客户端新的master的ip地址。
支持Sentinel的Redis客户端(例如Java得Jedis)会在连接Redis服务器的时候向Sentinel询问master的ip,并且会在收到master切换的pub/sub事件后自动重新连接到新的master。对调用Redis客户端的业务系统来说,这些都是完全透明的。
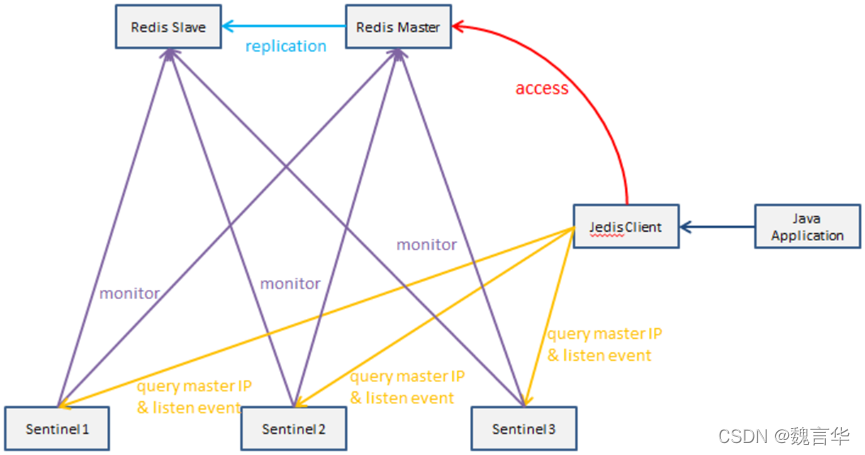
- master宕机后,failover的发起流程
2.5 哨兵优缺点
1)优点:
哨兵集群,基于主从复制模式,所有主从复制的优点,它都有。
主从可以切换,故障可以转移,系统的可用性更好。
哨兵模式是主从模式的升级,手动到自动,更加健壮
2)缺点:
实现哨兵模式的配置其实是很麻烦的,里面有很多配置项
Redis不好在线扩容,集群容量一旦达到上限,在线扩容就十分麻烦
2.6 哨兵配置文件
| # Example sentinel.conf # 哨兵sentinel实例运行的端口 默认26379 port 26379 # 哨兵sentinel的工作目录 dir /tmp # 哨兵sentinel监控的redis主节点的 ip port # master-name 可以自己命名的主节点名字 只能由字母A-z、数字0-9 、这三个字符".-_"组成。 # quorum 当这些quorum个数sentinel哨兵认为master主节点失联 那么这时 客观上认为主节点失联了 # sentinel monitor <master-name> <ip> <redis-port> <quorum> sentinel monitor mymaster 127.0.0.1 6379 1 # 当在Redis实例中开启了requirepass foobared 授权密码 这样所有连接Redis实例的客户端都要提供密码 # 设置哨兵sentinel 连接主从的密码 注意必须为主从设置一样的验证密码 # sentinel auth-pass <master-name> <password> sentinel auth-pass mymaster MySUPER--secret-0123passw0rd # 指定多少毫秒之后 主节点没有应答哨兵sentinel 此时 哨兵主观上认为主节点下线 默认30秒 # sentinel down-after-milliseconds <master-name> <milliseconds> sentinel down-after-milliseconds mymaster 30000 # 这个配置项指定了在发生failover主备切换时最多可以有多少个slave同时对新的master进行 同步, 这个数字越小,完成failover所需的时间就越长, 但是如果这个数字越大,就意味着越 多的slave因为replication而不可用。 可以通过将这个值设为 1 来保证每次只有一个slave 处于不能处理命令请求的状态。 # sentinel parallel-syncs <master-name> <numslaves> sentinel parallel-syncs mymaster 1 # 故障转移的超时时间 failover-timeout 可以用在以下这些方面: #1. 同一个sentinel对同一个master两次failover之间的间隔时间。 #2. 当一个slave从一个错误的master那里同步数据开始计算时间。直到slave被纠正为向正确的master那里同步数据时。 #3.当想要取消一个正在进行的failover所需要的时间。 #4.当进行failover时,配置所有slaves指向新的master所需的最大时间。不过,即使过了这个超时,slaves依然会被正确配置为指向master,但是就不按parallel-syncs所配置的规则来了 # 默认三分钟 # sentinel failover-timeout <master-name> <milliseconds> sentinel failover-timeout mymaster 180000 # SCRIPTS EXECUTION #配置当某一事件发生时所需要执行的脚本,可以通过脚本来通知管理员,例如当系统运行不正常时发邮件通知相关人员。 #对于脚本的运行结果有以下规则: #若脚本执行后返回1,那么该脚本稍后将会被再次执行,重复次数目前默认为10 #若脚本执行后返回2,或者比2更高的一个返回值,脚本将不会重复执行。 #如果脚本在执行过程中由于收到系统中断信号被终止了,则同返回值为1时的行为相同。 #一个脚本的最大执行时间为60s,如果超过这个时间,脚本将会被一个SIGKILL信号终止,之后重新执行。 #通知型脚本:当sentinel有任何警告级别的事件发生时(比如说redis实例的主观失效和客观失效等等),将会去调用这个脚本, #这时这个脚本应该通过邮件,SMS等方式去通知系统管理员关于系统不正常运行的信息。调用该脚本时,将传给脚本两个参数, #一个是事件的类型, #一个是事件的描述。 #如果sentinel.conf配置文件中配置了这个脚本路径,那么必须保证这个脚本存在于这个路径,并且是可执行的,否则sentinel无法正常启动成功。 #通知脚本 # sentinel notification-script <master-name> <script-path> sentinel notification-script mymaster /var/redis/notify.sh # 客户端重新配置主节点参数脚本 # 当一个master由于failover而发生改变时,这个脚本将会被调用,通知相关的客户端关于master地址已经发生改变的信息。 # 以下参数将会在调用脚本时传给脚本: # <master-name> <role> <state> <from-ip> <from-port> <to-ip> <to-port> # 目前<state>总是“failover”, # <role>是“leader”或者“observer”中的一个。 # 参数 from-ip, from-port, to-ip, to-port是用来和旧的master和新的master(即旧的slave)通信的 # 这个脚本应该是通用的,能被多次调用,不是针对性的。 # sentinel client-reconfig-script <master-name> <script-path> sentinel client-reconfig-script mymaster /var/redis/reconfig.sh |
3 集群部署
Redis集群(Redis Cluster) 是Redis提供的分布式数据库方案,通过 分片(sharding) 来进行数据共享,并提供复制和故障转移功能。相比于主从复制、哨兵模式,Redis集群实现了较为完善的高可用方案,解决了存储能力受到单机限制,写操作无法负载均衡的问题。
3.1 cluster集群搭建
集群环境的所有节点全部位于同一个服务器上,共6个节点以端口号区分,3个主节点+3个从节点。集群的简单架构如图
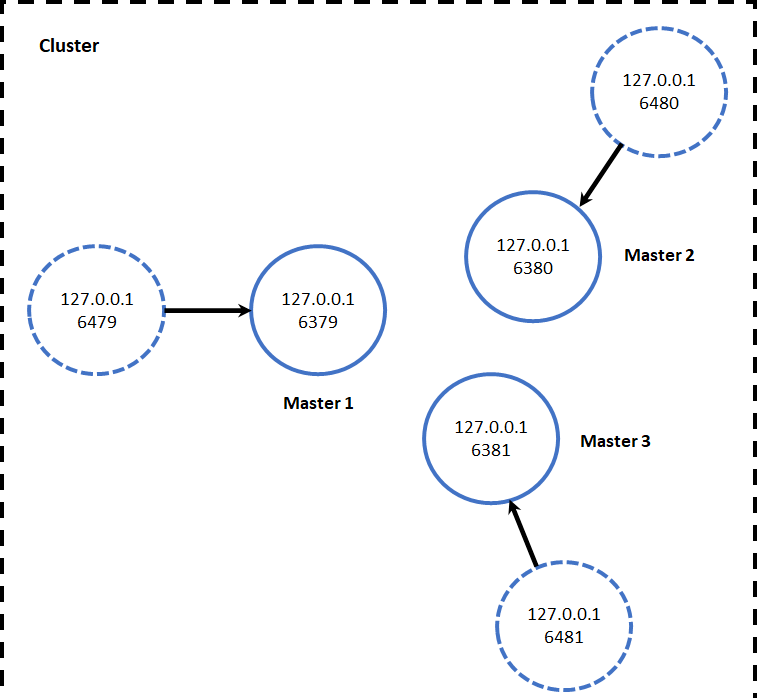
集群的搭建可以分为四步:
1)启动节点:将节点以集群方式启动,此时节点是独立的。
2)节点握手:将独立的节点连成网络。
3)槽指派:将16384个槽位分配给主节点,以达到分片保存数据库键值对的效果。
4)主从复制:为从节点指定主节点。
3.1.1 启动节点
每个节点初始状态仍为 Master服务器,唯一不同的是:使用 Cluster 模式启动。需要对配置文件进行修改,以端口号为6379的节点为例,主要修改如下几项:
| # redis_6379_cluster.conf |
其中 cluster-config-file 参数指定了集群配置文件的位置,每个节点在运行过程中,会维护一份集群配置文件;每当集群信息发生变化时(如增减节点),集群内所有节点会将最新信息更新到该配置文件;当节点重启后,会重新读取该配置文件,获取集群信息,可以方便的重新加入到集群中,集群配置文件由Redis节点维护,不需要人工修改。
3.1.2 节点握手
每个节点启动后,节点间是相互独立的,他们都处于一个只包含自己的集群当中,以端口号6379的服务器为例,利用 CLUSTER NODES 查看当前集群包含的节点。需要将各个独立的节点连接起来,构成一个包含多个节点的集群,使用 CLUSTER MEET 命令
| 127.0.0.1:6379> CLUSTER MEET 127.0.0.1 6380 OK 127.0.0.1:6379> CLUSTER MEET 127.0.0.1 6381 OK 127.0.0.1:6379> CLUSTER MEET 127.0.0.1 6480 OK 127.0.0.1:6379> CLUSTER MEET 127.0.0.1 6381 OK 127.0.0.1:6379> CLUSTER MEET 127.0.0.1 6382 OK |
再次查看此时集群中包含的节点情况
| 127.0.0.1:6379> CLUSTER NODES c47598b25205cc88abe2e5094d5bfd9ea202335f 127.0.0.1:6380@16380 master - 0 1603632309283 4 connected 87b7dfacde34b3cf57d5f46ab44fd6fffb2e4f52 127.0.0.1:6379@16379 myself,master - 0 1603632308000 1 connected 51081a64ddb3ccf5432c435a8cf20d45ab795dd8 127.0.0.1:6381@16381 master - 0 1603632310292 2 connected 9d587b75bdaed26ca582036ed706df8b2282b0aa 127.0.0.1:6481@16481 master - 0 1603632309000 5 connected 4c23b25bd4bcef7f4b77d8287e330ae72e738883 127.0.0.1:6479@16479 master - 0 1603632308000 3 connected 32ed645a9c9d13ca68dba5a147937fb1d05922ee 127.0.0.1:6480@16480 master - 0 1603632311302 0 connected |
3.1.3 节点配置槽号
Redis集群通过分片(sharding)的方式保存数据库的键值对,整个数据库被分为16384个槽(slot),数据库每个键都属于这16384个槽的一个,集群中的每个节点都可以处理0个或者最多16384个slot。
槽是数据管理和迁移的基本单位。当数据库中的16384个槽都分配了节点时,集群处于上线状态(ok);如果有任意一个槽没有分配节点,则集群处于下线状态(fail)。
注意,只有主节点有处理槽的能力,如果将槽指派步骤放在主从复制之后,并且将槽位分配给从节点,那么集群将无法正常工作(处于下线状态)。
| redis-cli -p 6379 cluster addslots {0..5000} |
3.1.4 主从复制
集群节点均作为主节点存在,仍不能实现Redis的高可用,配置主从复制之后,才算真正实现了集群的高可用功能。
CLUSTER REPLICATE <node_id> 用来让集群中接收命令的节点成为 node_id 所指定节点的从节点,并开始对主节点进行复制。

3.1.5 在集群中执行命令
集群此时处于上线状态,可以通过客户端向集群中的节点发送命令。接收命令的节点会计算出命令要处理的键属于哪个槽,并检查这个槽是否指派给自己。
如果键所在的slot刚好指派给了当前节点,会直接执行这个命令。
否则,节点向客户端返回 MOVED 错误,指引客户端转向 redirect 至正确的节点,并再次发送此前的命令。
3.1.6 集群伸缩
集群伸缩的关键在于对集群的进行重新分片,实现槽位在节点间的迁移。本节将以在集群中添加节点和删除节点为例,对槽迁移进行实践
3.1.6.1 集群伸缩-添加节点
考虑在集群中添加两个节点,端口号为6382和6482,其中节点6482对6382进行复制
(1) 启动节点:按照1.1中介绍的步骤,启动6382和6482节点。
(2) 节点握手:借助 redis-cli --cluster add-node 命令分别添加节点6382和6482。
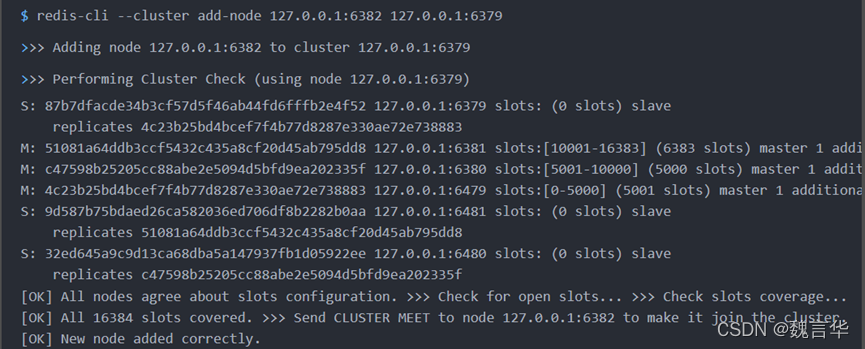
使用redis-cli --cluster reshard 重新分配槽号
| redis-cli --cluster reshard 127.0.0.1:6379 --cluster-from all --cluster-to <目的节点ID> |
使用redis-cli --cluster rebalance 可以按照节点权重调节每个节点上的槽数量
| redis-cli --cluster rebalance 127.0.0.1:6379 |
3.1.6.2 集群伸缩-删除节点
这里考虑将新添加的两个节点6382和6482删除,需要将节点6382上分配的槽位迁移到其他节点。
- 重新分片: 同样借助 redis-cli --cluster reshard 命令,将6382节点上的槽位全部转移到节点6479上。
- 删除节点: 利用 redis-cli --cluster del-node 命令依次删除从节点6482和主节点6382。
| redis-cli --cluster del-node 127.0.0.1:6482 <节点ID> |
3.2 cluster集群常用命令详解
3.2.1 set-timeout
set-timeout用来设置集群节点间心跳连接的超时时间,单位是毫秒,不得小于100毫秒,因为100毫秒对于心跳时间来说太短了。该命令修改是节点配置参数cluster-node-timeout,默认是15000毫秒
| [root@cache01 src]# redis-cli --cluster set-timeout 192.168.75.187:7001 30000 |
3.2.2 call
call命令可以用来在集群的全部节点执行相同的命令。call命令也是需要通过集群的一个节点地址,连上整个集群,然后在集群的每个节点执行该命令。
| [root@cache01 src]# redis-cli --cluster call 192.168.75.187:7001 get name |
3.2.3 reshard在线迁移slot
reshard命令可以在线把集群的一些slot从集群原来slot负责节点迁移到新的节点,利用reshard可以完成集群的在线横向扩容和缩容。
| 命令 | 参数说明 |
| host:port | 这个是必传参数,用来从一个节点获取整个集群信息,相当于获取集群信息的入口 |
| -- cluster-from | 需要从哪些源节点上迁移slot,可从多个源节点完成迁移,以逗号隔开,传递的是节点的node id,还可以直接传递–cluster-from all,这样源节点就是集群的所有节点,不传递该参数的话,则会在迁移过程中提示用户输入 |
| -- cluster-to | slot需要迁移的目的节点的node id,目的节点只能填写一个,不传递该参数的话,则会在迁移过程中提示用户输入 |
| -- cluster-slots | 需要迁移的slot数量,不传递该参数的话,则会在迁移过程中提示用户输入 |
| -- cluster-yes | 设置该参数,可以在打印执行reshard计划的时候,提示用户输入yes确认后再执行reshard |
3.2.3 rebalance平衡集群节点slot数量
rebalance命令可以根据用户传入的参数平衡集群节点的slot数量,rebalance功能非常强大,可以传入的参数很多,以下是rebalance的参数列表和命令示例。
| rebalance host:port --cluster-weight <node1=w1...nodeN=wN> --cluster-use-empty-masters --cluster-timeout <arg> --cluster-simulate --cluster-pipeline <arg> --cluster-threshold <arg> --cluster-replace |
| 命令 | 参数说明 |
| host:port | 这个是必传参数,用来从一个节点获取整个集群信息,相当于获取集群信息的入口 |
| -- cluster-weight <node1=w1…nodeN=wN> | 节点的权重,格式为node_id=weight,可为多个节点分配权重。没有传递–weight的节点的权重默认为1 |
| -- cluster-use-empty-masters | rebalance是否考虑没有节点的master,默认没有分配slot节点的master是不参与rebalance的,设置--cluster-use-empty-masters可以让没有分配slot的节点参与rebalance |
| -- cluster-timeout | 设置migrate命令的超时时间 |
| -- cluster-simulate | 设置该参数,可以模拟rebalance操作,提示用户会迁移哪些slots,而不会真正执行迁移操作 |
3.2.4 add-node将新节点加入集群
add-node命令可以将新节点加入集群,节点可以为master,也可以为某个master节点的slave
| 命令 | 参数说明 |
| new_host:new_port | 新节点的ip:port |
| existing_host:existing_port | existing_host:existing_port,要加入集群的一个master的ip:port |
| -- cluster-slave | 设置该参数,则新节点以slave的角色加入集群 |
| -- cluster-master-id | 新加入的节点要放到哪个master下。这个参数需要设置了--cluster-slave才能生效,如果不设置该参数,则会随机为新节点选择一个master节点 |
3.2.5 del-node从集群中删除节点
del-node可以把某个节点从集群中删除。del-node只能删除没有分配slot的节点,
| 命令 | 参数说明 |
| host:port | 从该节点获取集群信息 |
| node_id | 需要删除的节点id |
4. LRU 算法概述
4.1 LRU 概述
LRU 是 Least Recently Used 的缩写,即最近最少使用,是内存管理的一种页面置换算法。算法的核心是:如果一个数据在最近一段时间内没有被访问到,那么它在将来被访问的可能性也很小。换言之,当内存达到极限时,应该把内存中最久没有被访问的数据淘汰掉。
那么,如何表示这个最久呢?Redis 在实现上引入了一个 LRU 时钟来代替 unix 时间戳,每个对象的每次被访问都会记录下当前服务器的 LRU 时钟,然后用服务器的 LRU 时钟减去对象本身的时钟,得到的就是这个对象没有被访问的时间间隔(也称空闲时间),空闲时间最大的就是需要淘汰的对象。
4.2 LRU 时钟
#define LRU_BITS 24
#define LRU_CLOCK_MAX ((1<<LRU_BITS)-1)
#define LRU_CLOCK_RESOLUTION 1000
unsigned int getLRUClock(void) {
return (mstime()/LRU_CLOCK_RESOLUTION) & LRU_CLOCK_MAX;
}
以上这段代码的含义是通过当前的 unix 时间戳获取 LRU 时钟。unix 时间戳通过接口 mstime 获取,得到的是从 1970年1月1日早上8点到当前时刻的时间间隔,以毫秒为单位(mstime底层实现用的是 c 的系统函数 gettimeofday)。
其中,LRU_BITS 表示 LRU 时钟的位数;LRU_CLOCK_MAX 为 LRU 时钟的最大值;LRU_CLOCK_RESOLUTION 则表示每个 LRU 基本单位对应到自然时钟的毫秒数,即精度,按照这个宏定义,LRU 时钟的最小刻度为 1000 毫秒。

如图所示,将自然时钟和 LRU 时钟作对比:
a) 自然时钟最大值为 11:59:59,LRU 时钟最大值为 LRU_CLOCK_MAX = 2^24 - 1;
b) 自然时钟的最小刻度为 1秒, LRU 时钟的最小刻度为 1000 毫秒;
c) 自然时钟的一个轮回是 12小时,LRU 时钟的一个轮回是 2^24 * 1000 毫秒(一轮的计算方式是:( 时钟最大值 + 1 ) * 最小刻度);
因为 LRU_CLOCK_MAX 是 2 的幂减 1,即它的二进制表示全是 1,所以这里的 & 其实是取模的意思。那么 getLRUClock 函数的含义就是定位到 LRU 时钟的某个刻度。
4.3 Redis 中的 LRU 时钟
4.3.1 Redis 对象
Redis 中的所有对象定义为 redisObject 结构体,也正是这些对象采用了 LRU 算法进行内存回收,所以每个对象需要一个成员来用来记录该对象的最近一次被访问的时间(即 lru 成员),由于时钟的最大值只需要 24 个比特位就能表示,所以结构体定义时采用了位域。定义如下:
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:LRU_BITS;
int refcount;
void *ptr;
} robj;
4.3.2 Redis 定时器
Redis 中有一个全局的定时器函数 serverCron,用于刷新服务器的 LRU 时钟,函数大致实现如下:
int serverCron(...) {
...
server.lruclock = getLRUClock();
...
}
其中,server.lruclock 代表服务器的 LRU 时钟,这个时钟的刷新频率由 server.hz 决定,即每秒钟会调用 server.hz (默认值为 10)次 serverCron 函数。那么,服务器每 1 / server.hz 秒就会调用一次定时器函数 serverCron。
4.3.3 Redis 对象的 LRU 时钟
每个 Redis 对象的 LRU 时钟的计算方式由宏 LRU_CLOCK 给出,实现如下
#define LRU_CLOCK() ((1000/server.hz <= LRU_CLOCK_RESOLUTION) ? server.lruclock : getLRUClock())
正如上文所提到的,1 / server.hz 代表了 serverCron 这个定时器函数两次调用之间的最小时间间隔(以秒为单位),那么 1000 / server.hz 就是以毫秒为单位了。如果这个最小时间间隔小于等于 LRU 时钟的精度,那么不需要重新计算 LRU时钟,直接用服务器 LRU时钟做近似值即可,因为时间间隔越小,server.lruclock 刷新的越频繁;相反,当时间间隔很大的时候,server.lruclock 的刷新可能不及时,所以需要用 getLRUClock 重新计算准确的 LRU 时钟。

如图所示,以 server.hz = 10 为例,sc 代表每次 serverCron 调用的时间结点,两次调用间隔 100ms,每次调用就会利用 getLRUClock 函数计算一次 LRU 时钟。由于 LRU时钟的最小刻度为 1000ms,所以图中 LRU_x 和 LRU_y 之间是没有其它刻度的,那么所有落在 LRU_x 和 LRU_y 之间计算出来的 LRU时钟 的值都为 LRU_x,于是为了避免重复计算,减少调用系统函数 gettimeofday 的时间,可以用最近一次计算得到的 LRU 时钟作为近似值,即 server.lruclock。
Redis 对象更新 LRU 时钟的地方有两个:a) 对象创建时;b) 对象被使用时。
a) createObject 函数用于创建一个 Redis 对象,代码实现在 object.c 中:
robj *createObject(int type, void *ptr) {
robj *o = zmalloc(sizeof(*o));
o->type = type;
o->encoding = OBJ_ENCODING_RAW;
o->ptr = ptr;
o->refcount = 1;
o->lru = LRU_CLOCK();
return o;
}
这里调用 LRU_CLOCK() 对 Redis 的对象成员 lru 进行 LRU 时钟的设置,其中 robj 是 redisObject 的别名,见上文的定义。
b) lookupKey 不会直接被 redis 命令调用,往往是通过lookupKeyRead()、lookupKeyWrite() 、lookupKeyReadWithFlags() 间接调用的,这个函数的作用是通过传入的 key 查找对应的 redis 对象,并且会在条件满足时设置上 LRU 时钟。为了便于阐述,这里简化了代码,源码实现在 db.c 中:
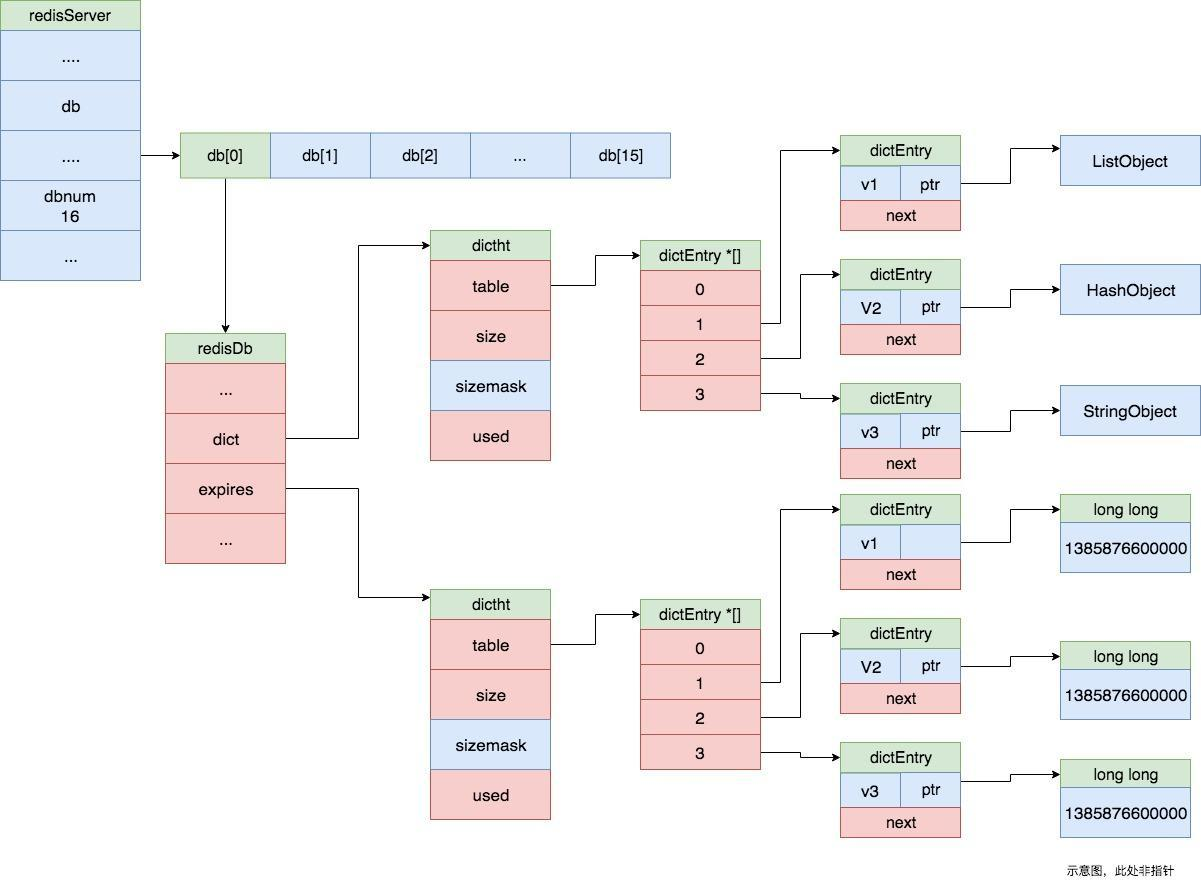
robj *lookupKey(redisDb *db, robj *key, int flags) {
dictEntry *de = dictFind(db->dict,key->ptr);
if (de) {
robj *val = dictGetVal(de);
...
val->lru = LRU_CLOCK();
...
return val;
} else {
return NULL;
}
}
4.4 redis LRU内存回收
4.4.1内存回收策略
当内存达到极限,就要开始利用回收策略对内存进行回收释放。回收的配置在 redis.conf 中填写,如下:
maxmemory 1073741824
maxmemory-policy noeviction
maxmemory-samples 5
这三个配置项决定了 Redis 内存回收时的机制,maxmemory 指定了内存使用的极限,以字节为单位。当内存达到极限时,他会尝试去删除一些键值。删除的策略由 maxmemory-policy 配置来指定。如果根据指定的策略无法删除键或者策略本身就是 'noeviction',那么,Redis 会根据命令的类型做出不同的回应:会给需要更多内存的命令返回一个错误,例如 SET、LPUSH 等等;而像 GET 这样的只读命令则可以继续正常运行。
maxmemory :当你的 Redis 是主 Redis 时 (Redis 采用主从模式时),需要预留一部分系统内存给同步队列缓存。当然,如果设置的删除策略 'noeviction',则不需要考虑这个问题。
maxmemory-policy : 当内存达到 maxmemory 时,采用的回收策略,总共有如下六种:
a) volatile-lru : 针对设置了过期时间的键采用 LRU 算法进行回收;
b) allkeys-lru : 对所有键采用 LRU 算法进行回收;
c) volatile-random : 针对设置了过期时间的键采用随机回收;
d) allkeys-random : 对所有键随机回收;
e) volatile-ttl: 过期时间最近 (TTL 最小) 的键进行回收;
f) noeviction :不进行任何回收,对写操作返回错误;
#define MAXMEMORY_VOLATILE_LRU 0
#define MAXMEMORY_VOLATILE_TTL 1
#define MAXMEMORY_VOLATILE_RANDOM 2
#define MAXMEMORY_ALLKEYS_LRU 3
#define MAXMEMORY_ALLKEYS_RANDOM 4
#define MAXMEMORY_NO_EVICTION 5
maxmemory-samples :指定了在进行删除时的键的采样数量。LRU 和 TTL 都是近似算法,所以可以根据参数来进行取舍,到底是要速度还是精确度。默认值一般填 5。10 的话已经非常近似正式的 LRU 算法了,但是会多一些 CPU 消耗;3 的话执行更快,然而不够精确。
4.4.2 空闲时间
LRU 算法的执行依据是将空闲时间最大的淘汰掉,每个对象知道自己上次使用的时间,那么就可以计算出自己空闲了多久,可以通过 estimateObjectIdleTime 接口得出 idletime,实现在 object.c 中:
unsigned long long estimateObjectIdleTime(robj *o) {
unsigned long long lruclock = LRU_CLOCK();
if (lruclock >= o->lru) {
return (lruclock - o->lru) * LRU_CLOCK_RESOLUTION;
} else {
return (lruclock + (LRU_CLOCK_MAX - o->lru)) * LRU_CLOCK_RESOLUTION;
}
}
由于时钟是循环的,所以需要考虑服务器当前时钟和对象本身时钟的相对大小,从而计算出对象的空闲时间。然后通过对这个空闲时间的排序,就能筛选出空闲时间最长的进行回收了。
4.4.3 LRU 回收流程
Redis 的数据库是一个巨大的字典,最上层是由键值对组成的。当内存使用超过最大使用数时,就需要采用回收策略进行内存回收。如果回收策略采用 LRU,那么就会在这个大字典里面随机采样,挑选出空闲时间最大的键进行删除。而回收池会存在于整个服务器的生命周期中,所以它是一个全局变量。
1) 这个删除操作发生在每一次处理客户端命令时。当 server.maxmemory 的值非 0,则检测是否有需要回收的内存。如果有则执行 2) ;
2) 随机从大字典中取出 server.maxmemory_samples 个键(实际取到的数量取决于大字典原本的大小),然后用一个长度为 16 (由宏 MAXMEMORY_EVICTION_POOL_SIZE 指定) 的 evictionPool (回收池)对这几个键进行筛选,筛选出 idletime (空闲时间)最长的键,并且按照 idletime 从小到大的顺序排列在 evictionPool 中;
3) 从 evictionPool 池中取出 idletime 最大且在字典中存在的键作为 bestkey 执行删除,并且从 evictionPool 池中移除;
以上 evictionPool 扮演的是大顶堆的角色,并且在 Redis 服务器启动后一直存在。最后,看下 LRU 回收算法的实际执行流程:
#define MAXMEMORY_EVICTION_POOL_SIZE 16
struct evictionPoolEntry { /* a */
unsigned long long idle;
sds key;
};
int processCommand(client *c) {
...
if (server.maxmemory) freeMemoryIfNeeded(); /* b */
...
}
int freeMemoryIfNeeded(void) {
...
if (server.maxmemory_policy == MAXMEMORY_ALLKEYS_LRU ||
server.maxmemory_policy == MAXMEMORY_VOLATILE_LRU) {
struct evictionPoolEntry *pool = db->eviction_pool; /* c */
while(bestkey == NULL) {
evictionPoolPopulate(dict, db->dict, db->eviction_pool); /* d */
for (k = MAXMEMORY_EVICTION_POOL_SIZE-1; k >= 0; k--) {
if (pool[k].key == NULL) continue;
de = dictFind(dict,pool[k].key);
sdsfree(pool[k].key);
memmove(pool+k,pool+k+1,
sizeof(pool[0])*(MAXMEMORY_EVICTION_POOL_SIZE-k-1));
pool[MAXMEMORY_EVICTION_POOL_SIZE-1].key = NULL;
pool[MAXMEMORY_EVICTION_POOL_SIZE-1].idle = 0;
if (de) {
bestkey = dictGetKey(de); /* e */
break;
} else {
continue;
}
}
}
}
...
}
a) evictionPoolEntry 是回收池中的元素结构体,由一个空闲时间 idle 和 键名key 组成;
b) freeMemoryIfNeeded(...) 接口用于收集 evictionPool 元素并且找出空闲时间最大的键并进行释放;
c) eviction_pool 是数据库对象 db 的成员,代表回收池,是 a) 中提到的 evictionPoolEntry 类型的数组,数组长度由宏 MAXMEMORY_EVICTION_POOL_SIZE 指定,默认值为 16;
d) evictionPoolPopulate(...) 接口用于随机采样数据库中的键,并且逐一和回收池中的键的空闲时间进行比较,筛选出空闲时间最大的键留在回收池中,这个接口的实现下文会具体讲述;
e) 找出空闲时间最大且存在的键,等待执行删除操作;
4.4.4回收池更新
evictionPoolPopulate 的实现在 server.c, 主要是利用采样出来的键对回收池进行更新筛选,源码如下:
#define EVICTION_SAMPLES_ARRAY_SIZE 16
void evictionPoolPopulate(dict *sampledict, dict *keydict, struct evictionPoolEntry *pool) {
int j, k, count;
dictEntry *_samples[EVICTION_SAMPLES_ARRAY_SIZE];
dictEntry **samples;
if (server.maxmemory_samples <= EVICTION_SAMPLES_ARRAY_SIZE) {
samples = _samples;
} else {
samples = zmalloc(sizeof(samples[0])*server.maxmemory_samples);
}
count = dictGetSomeKeys(sampledict,samples,server.maxmemory_samples);
for (j = 0; j < count; j++) {
unsigned long long idle;
sds key;
robj *o;
dictEntry *de;
de = samples[j];
key = dictGetKey(de);
if (sampledict != keydict) de = dictFind(keydict, key);
o = dictGetVal(de);
idle = estimateObjectIdleTime(o);
k = 0;
while (k < MAXMEMORY_EVICTION_POOL_SIZE &&
pool[k].key &&
pool[k].idle < idle) k++;
if (k == 0 && pool[MAXMEMORY_EVICTION_POOL_SIZE-1].key != NULL) {
continue; /* a */
} else if (k < MAXMEMORY_EVICTION_POOL_SIZE && pool[k].key == NULL) { /* b */
} else {
if (pool[MAXMEMORY_EVICTION_POOL_SIZE-1].key == NULL) { /* c */
memmove(pool+k+1,pool+k,
sizeof(pool[0])*(MAXMEMORY_EVICTION_POOL_SIZE-k-1));
} else {
k--; /* d */
sdsfree(pool[0].key);
memmove(pool,pool+1,sizeof(pool[0])*k);
}
}
pool[k].key = sdsdup(key);
pool[k].idle = idle;
}
if (samples != _samples) zfree(samples);
}
这是 LRU 算法的核心,首先从目标字典中随机采样出 server.maxmemory_samples 个键,缓存在 samples 数组中,然后一个一个取出来,并且和回收池中的已有的键对比空闲时间,从而更新回收池。更新的过程首先,利用遍历找到每个键的实际插入位置 k ,然后,总共涉及四种情况如下:
a) 回收池已满,且当前插入的元素的空闲时间最小,则不作任何操作;
b) 回收池未满,且将要插入的位置 k 原本没有键,则可直接执行插入操作;
c) 回收池未满,且将要插入的位置 k 原本已经有键,则将当前第 k 个以后的元素往后挪一个位置,然后执行插入操作;
d) 回收池已满,则将当前第 k 个以前的元素往前挪一个位置,然后执行插入操作;
下图中的四个子图分别代表上文提到的四种情况,其中红色箭头代表 k 的位置,红色方块代表插入的元素:

5 redis 命令执行
一条命令执行完成并且返回数据一共涉及三部分,第一步是建立连接阶段,响应了socket的建立,并且创建了client对象;第二步是处理阶段,从socket读取数据到输入缓冲区,然后解析并获得命令,执行命令并将返回值存储到输出缓冲区中;第三步是数据返回阶段,将返回值从输出缓冲区写到socket中,返回给客户端,最后关闭client。
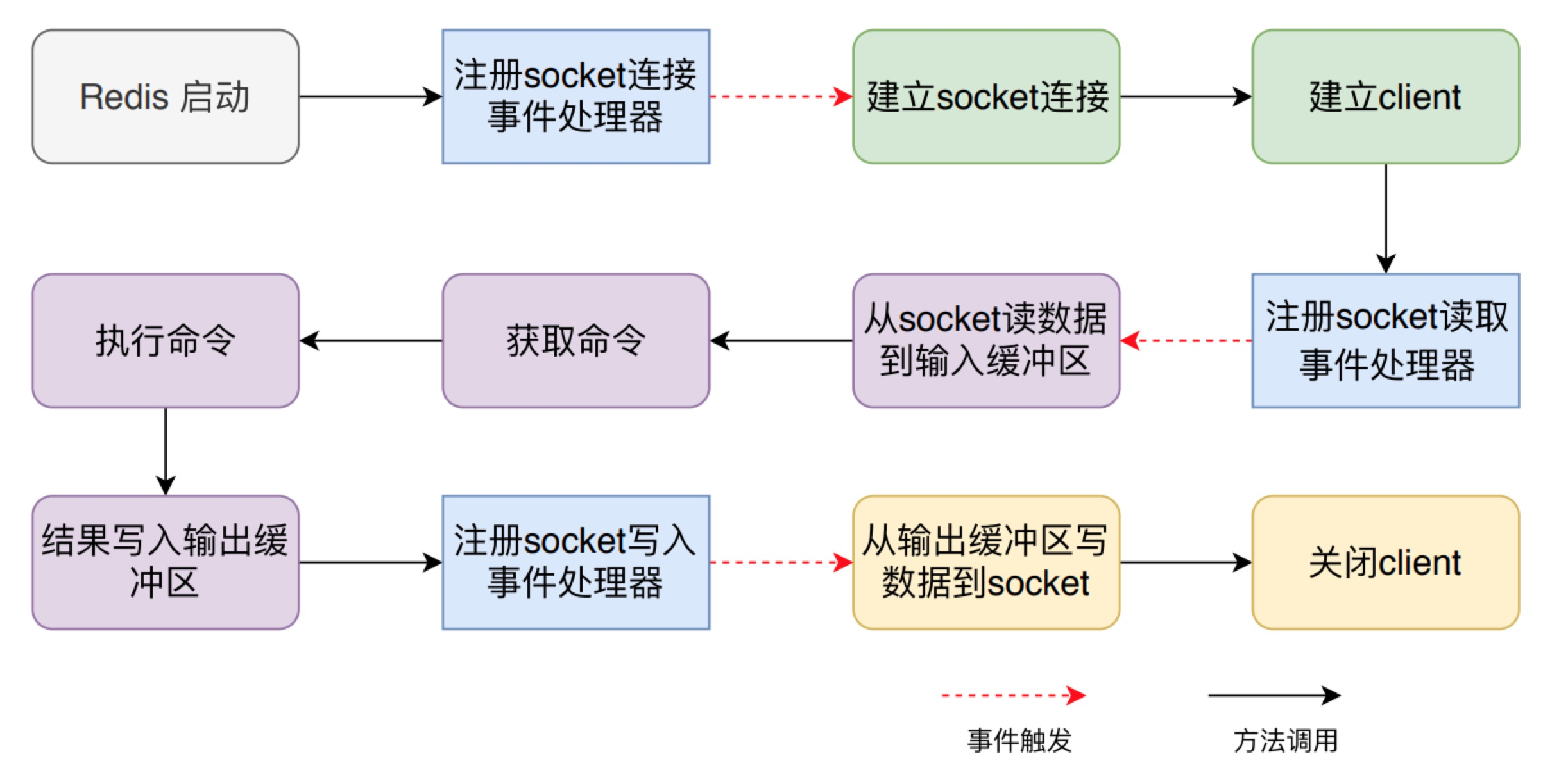
这三个阶段之间是通过事件机制串联了,在 Redis 启动阶段首先要注册socket连接建立事件处理器:
1)户端发来建立socket的连接的请求时,对应的处理器方法会被执行,建立连接阶段的相关处理就会进行,然后注册socket读取事件处理器
2)户端发来命令时,读取事件处理器方法会被执行,对应处理阶段的相关逻辑都会被执行,然后注册socket写事件处理器
3)事件处理器被执行时,就是将返回值写回到socket中。
5.1 启动时监听socket
Redis 服务器启动时,会调用 initServer 方法,首先会建立 Redis 自己的事件机制 eventLoop,然后在其上注册周期时间事件处理器,最后在所监听的 socket 上
创建文件事件处理器,监听 socket 建立连接的事件,其处理函数为acceptTcpHandler。
| void initServer(void) { // server.c .... /** * 创建eventLoop */ server.el = aeCreateEventLoop(server.maxclients+CONFIG_FDSET_INCR); /* Open the TCP listening socket for the user commands. */ if (server.port != 0 && listenToPort(server.port,server.ipfd,&server.ipfd_count) == C_ERR) exit(1); /** * 注册周期时间事件,处理后台操作,比如说客户端操作、过期键等 */ if (aeCreateTimeEvent(server.el, 1, serverCron, NULL, NULL) == AE_ERR) { serverPanic("Can't create event loop timers."); exit(1); } /** * 为所有监听的socket创建文件事件,监听可读事件;事件处理函数为acceptTcpHandler * */ for (j = 0; j < server.ipfd_count; j++) { if (aeCreateFileEvent(server.el, server.ipfd[j], AE_READABLE, acceptTcpHandler,NULL) == AE_ERR) { serverPanic( "Unrecoverable error creating server.ipfd file event."); } } .... } |
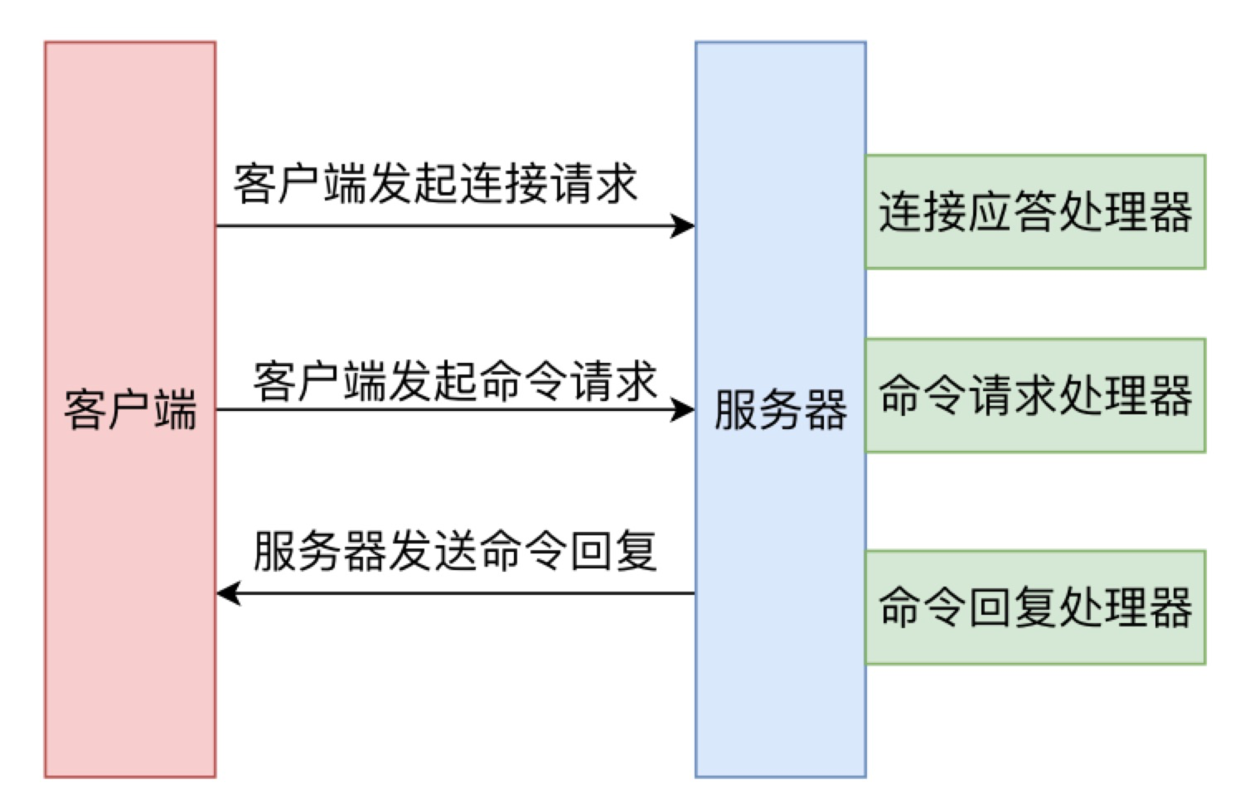
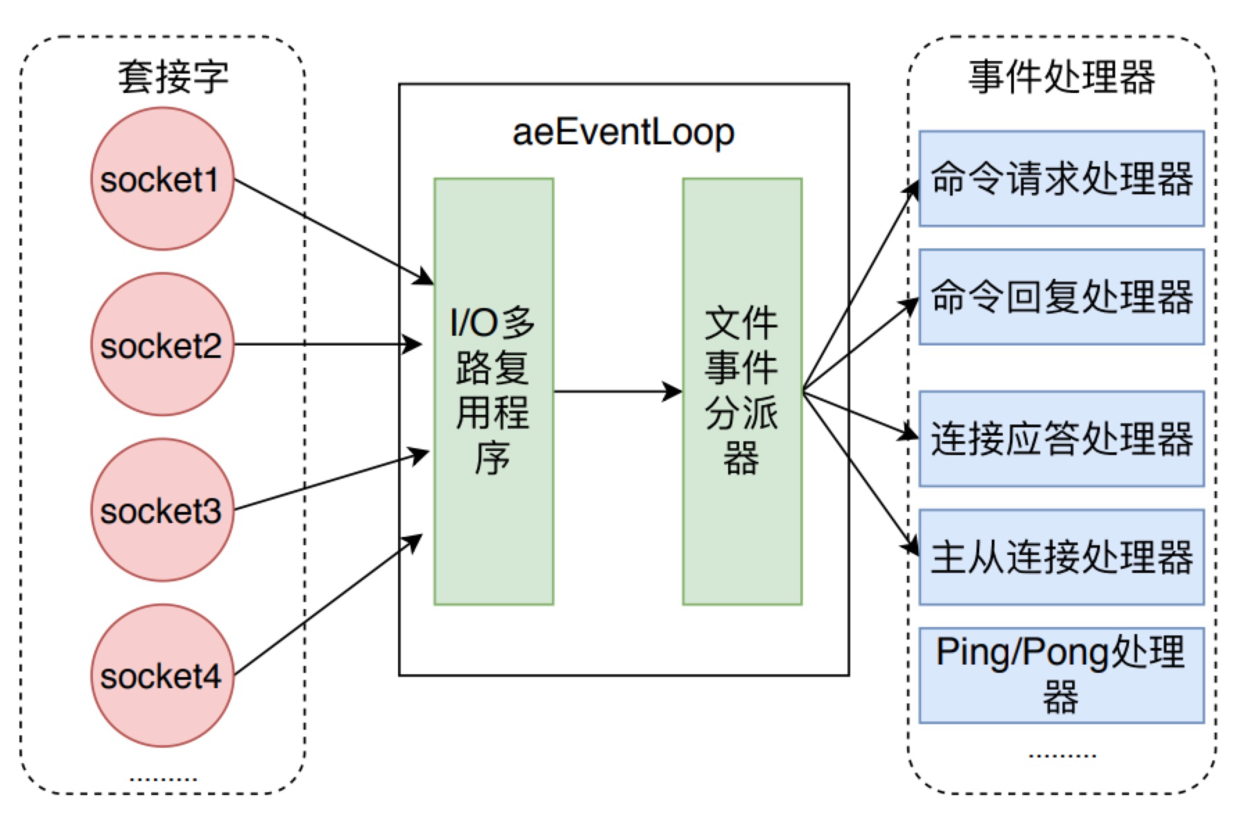
Redis 命令执行过程中都是由事件机制协调管理的,也就是 initServer 方法中生成的 aeEventLoop。当socket发生对应的事件时,aeEventLoop 对调用已经注册的对应的事件处理器。
5.2 建立连接和Client
当客户端向 Redis 建立 socket时,aeEventLoop 会调用 acceptTcpHandler 处理函数,服务器会为每个链接创建一个 Client 对象,并创建相应文件事件来监听socket的可读事件,并指定事件处理函数。
acceptTcpHandler 函数会首先调用 anetTcpAccept方法,它底层会调用 socket 的 accept 方法,也就是接受客户端来的建立连接请求,然后调用 acceptCommonHandler方法,继续后续的逻辑处理。
| // 当客户端建立链接时进行的eventloop处理函数 networking.c void acceptTcpHandler(aeEventLoop *el, int fd, void *privdata, int mask) { .... // 层层调用,最后在anet.c 中 anetGenericAccept 方法中调用 socket 的 accept 方法 cfd = anetTcpAccept(server.neterr, fd, cip, sizeof(cip), &cport); if (cfd == ANET_ERR) { if (errno != EWOULDBLOCK) serverLog(LL_WARNING, "Accepting client connection: %s", server.neterr); return; } serverLog(LL_VERBOSE,"Accepted %s:%d", cip, cport); /** * 进行socket 建立连接后的处理 */ acceptCommonHandler(cfd,0,cip); } |
acceptCommonHandler 则首先调用 createClient 创建 client,接着判断当前 client 的数量是否超出了配置的 maxclients,如果超过,则给客户端发送错误信息,并且释放 client。
| static void acceptCommonHandler(int fd, int flags, char *ip) { //networking.c client *c; // 创建redisClient c = createClient(fd) // 当 maxClient 属性被设置,并且client数量已经超出时,给client发送error,然后释放连接 if (listLength(server.clients) > server.maxclients) { char *err = "-ERR max number of clients reached\r\n"; if (write(c->fd,err,strlen(err)) == -1) { } server.stat_rejected_conn++; freeClient(c); return; } .... // 处理为设置密码时默认保护状态的客户端连接 // 统计连接数 server.stat_numconnections++; c->flags |= flags; } |
createClient 方法用于创建 client,它代表着连接到 Redis 客户端,每个客户端都有各自的输入缓冲区和输出缓冲区,输入缓冲区存储客户端通过 socket 发送过来的数据,输出缓冲区则存储着 Redis 对客户端的响应数据。client一共有三种类型,不同类型的对应缓冲区的大小都不同。
- 客户端是除了复制和订阅的客户端之外的所有连接
- 户端用于主从复制,主节点会为每个从节点单独建立一条连接用于命令复制
3)户端用于发布订阅功能
createClient 方法除了创建 client 结构体并设置其属性值外,还会对 socket进行配置并注册读事件处理器
设置 socket 为 非阻塞 socket、设置 NO_DELAY 和 SO_KEEPALIVE标志位来关闭 Nagle 算法并且启动 socket 存活检查机制。
设置读事件处理器,当客户端通过 socket 发送来数据后,Redis 会调用 readQueryFromClient 方法。
| client *createClient(int fd) { client *c = zmalloc(sizeof(client)); // fd 为 -1,表示其他特殊情况创建的client,redis在进行比如lua脚本执行之类的情况下也会创建client if (fd != -1) { // 配置socket为非阻塞、NO_DELAY不开启Nagle算法和SO_KEEPALIVE anetNonBlock(NULL,fd); anetEnableTcpNoDelay(NULL,fd); if (server.tcpkeepalive) anetKeepAlive(NULL,fd,server.tcpkeepalive); /** * 向 eventLoop 中注册了 readQueryFromClient。 * readQueryFromClient 的作用就是从client中读取客户端的查询缓冲区内容。 * 绑定读事件到事件 loop (开始接收命令请求) */ if (aeCreateFileEvent(server.el,fd,AE_READABLE, readQueryFromClient, c) == AE_ERR) { close(fd); zfree(c); return NULL; } } // 默认选择数据库 selectDb(c,0); uint64_t client_id; atomicGetIncr(server.next_client_id,client_id,1); c->id = client_id; c->fd = fd; .... // 设置client的属性 return c; } |
5.3 读取socket数据到输入缓冲区
readQueryFromClient 方法会调用 read 方法从 socket 中读取数据到输入缓冲区中,然后判断其大小是否大于系统设置的 client_max_querybuf_len,如果大于,则向 Redis返回错误信息,并关闭 client。
将数据读取到输入缓冲区后,readQueryFromClient 方法会根据 client 的类型来做不同的处理,如果是普通类型,则直接调用 processInputBuffer 来处理;如果是主从客户端,还需要将命令同步到自己的从服务器中。也就是说,Redis实例将主实例传来的命令执行后,继续将命令同步给自己的从实例。
| // 处理从client中读取客户端的输入缓冲区内容。 void readQueryFromClient(aeEventLoop *el, int fd, void *privdata, int mask) { client *c = (client*) privdata; .... if (c->querybuf_peak < qblen) c->querybuf_peak = qblen; c->querybuf = sdsMakeRoomFor(c->querybuf, readlen); // 从 fd 对应的socket中读取到 client 中的 querybuf 输入缓冲区 nread = read(fd, c->querybuf+qblen, readlen); if (nread == -1) { .... // 出错释放 client } else if (nread == 0) { // 客户端主动关闭 connection serverLog(LL_VERBOSE, "Client closed connection"); freeClient(c); return; } else if (c->flags & CLIENT_MASTER) { /* * 当这个client代表主从的master节点时,将query buffer和 pending_querybuf结合 * 用于主从复制中的命令传播???? */ c->pending_querybuf = sdscatlen(c->pending_querybuf, c->querybuf+qblen,nread); } // 增加已经读取的字节数 sdsIncrLen(c->querybuf,nread); c->lastinteraction = server.unixtime; if (c->flags & CLIENT_MASTER) c->read_reploff += nread; server.stat_net_input_bytes += nread; // 如果大于系统配置的最大客户端缓存区大小,也就是配置文件中的client-query-buffer-limit if (sdslen(c->querybuf) > server.client_max_querybuf_len) { sds ci = catClientInfoString(sdsempty(),c), bytes = sdsempty(); // 返回错误信息,并且关闭client bytes = sdscatrepr(bytes,c->querybuf,64); serverLog(LL_WARNING,"Closing client that reached max query buffer length: %s (qbuf initial bytes: %s)", ci, bytes); sdsfree(ci); sdsfree(bytes); freeClient(c); return; }
if (!(c->flags & CLIENT_MASTER)) { // processInputBuffer 处理输入缓冲区 processInputBuffer(c); } else { // 如果client是master的连接 size_t prev_offset = c->reploff; processInputBuffer(c); // 判断是否同步偏移量发生变化,则通知到后续的slave size_t applied = c->reploff - prev_offset; if (applied) { replicationFeedSlavesFromMasterStream(server.slaves, c->pending_querybuf, applied); sdsrange(c->pending_querybuf,applied,-1); } } } |
5.4 解析获取命令
processInputBuffer 主要是将输入缓冲区中的数据解析成对应的命令,根据命令类型是 PROTO_REQ_MULTIBULK 还是 PROTO_REQ_INLINE,来分别调用 processInlineBuffer 和 processMultibulkBuffer 方法来解析命令。
然后调用 processCommand 方法来执行命令。执行成功后,如果是主从客户端,还需要更新同步偏移量 reploff 属性,然后重置 client,让client可以接收一条命令。
| void processInputBuffer(client *c) { // networking.c server.current_client = c; /* 当缓冲区中还有数据时就一直处理 */ while(sdslen(c->querybuf)) { .... // 处理 client 的各种状态 /* 判断命令请求类型 telnet发送的命令和redis-cli发送的命令请求格式不同 */ if (!c->reqtype) { if (c->querybuf[0] == '*') { c->reqtype = PROTO_REQ_MULTIBULK; } else { c->reqtype = PROTO_REQ_INLINE; } } /** * 从缓冲区解析命令 */ if (c->reqtype == PROTO_REQ_INLINE) { if (processInlineBuffer(c) != C_OK) break; } else if (c->reqtype == PROTO_REQ_MULTIBULK) { if (processMultibulkBuffer(c) != C_OK) break; } else { serverPanic("Unknown request type"); } /* 参数个数为0时重置client,可以接受下一个命令 */ if (c->argc == 0) { resetClient(c); } else { // 执行命令 if (processCommand(c) == C_OK) { if (c->flags & CLIENT_MASTER && !(c->flags & CLIENT_MULTI)) { // 如果是master的client发来的命令,则 更新 reploff c->reploff = c->read_reploff - sdslen(c->querybuf); } // 如果不是阻塞状态,则重置client,可以接受下一个命令 if (!(c->flags & CLIENT_BLOCKED) || c->btype != BLOCKED_MODULE) resetClient(c); } } } server.current_client = NULL; } |
5.5 执行命令
processCommand 方法会处理很多逻辑,不过大致可以分为三个部分:
- 是调用 lookupCommand 方法获得对应的 redisCommand;
- 是检测当前 Redis 是否可以执行该命令;
- 最后是调用 call 方法真正执行命令。
| 序号 | 命令解析 |
| 1 | 如果命令名称为 quit,则直接返回,并且设置客户端标志位 |
| 2 | 根据 argv[0] 查找对应的 redisCommand,所有的命令都存储在命令字典 redisCommandTable 中,根据命令名称可以获取对应的命令 |
| 3 | 进行用户权限校验 |
| 4 | 如果是集群模式,处理集群重定向。当命令发送者是 master 或者 命令没有任何 key 的参数时可以不重定向。 |
| 5 | 预防 maxmemory 情况,先尝试回收一下,如果不行,则返回异常 |
| 6 | 当此服务器是 master 时:aof 持久化失败时,或上一次 bgsave 执行错误,且配置 bgsave 参数和 stop_writes_on_bgsave_err;禁止执行写命令。 |
| 7 | 当此服务器时master, slave数目小于min-slaves-to-write时,禁止写入,lag延时大于min-slaves-max-lag时,禁止写入 |
| 8 | 只读slave时,除了 master 的不接受其他写命令 |
| 9 | 当客户端正在订阅频道时,只会执行部分命令 |
| 10 | 服务器为slave,但是没有连接 master 时,只会执行带有 CMD_STALE 标志的命令,如 info 等 |
| 11 | 正在加载数据库时,只会执行带有 CMD_LOADING 标志的命令,其余都会被拒绝 |
| 12 | 当服务器因为执行lua脚本阻塞时,只会执行部分命令,其余都会拒绝 |
| 13 | 如果是事务命令,则开启事务,命令进入等待队列;否则直接执行命令。 |
| int processCommand(client *c) { // 1 处理 quit 命令 if (!strcasecmp(c->argv[0]->ptr,"quit")) { addReply(c,shared.ok); c->flags |= CLIENT_CLOSE_AFTER_REPLY; return C_ERR; } /** * 根据 argv[0] 查找对应的 command * 2 命令字典查找指定命令;所有的命令都存储在命令字典中 struct redisCommand redisCommandTable[]={} */ c->cmd = c->lastcmd = lookupCommand(c->argv[0]->ptr); if (!c->cmd) { // 处理未知命令 } else if ((c->cmd->arity > 0 && c->cmd->arity != c->argc) || (c->argc < -c->cmd->arity)) { // 处理参数错误 } // 3 检查用户验证 if (server.requirepass && !c->authenticated && c->cmd->proc != authCommand) { flagTransaction(c); addReply(c,shared.noautherr); return C_OK; } /** * 4 如果是集群模式,处理集群重定向。当命令发送者是master或者 命令没有任何key的参数时可以不重定向 */ if (server.cluster_enabled && !(c->flags & CLIENT_MASTER) && !(c->flags & CLIENT_LUA && server.lua_caller->flags & CLIENT_MASTER) && !(c->cmd->getkeys_proc == NULL && c->cmd->firstkey == 0 && c->cmd->proc != execCommand)) { int hashslot; int error_code; // 查询可以执行的node信息 clusterNode *n = getNodeByQuery(c,c->cmd,c->argv,c->argc, &hashslot,&error_code); if (n == NULL || n != server.cluster->myself) { if (c->cmd->proc == execCommand) { discardTransaction(c); } else { flagTransaction(c); } clusterRedirectClient(c,n,hashslot,error_code); return C_OK; } } // 5 处理maxmemory请求,先尝试回收一下,如果不行,则返回异常 if (server.maxmemory) { int retval = freeMemoryIfNeeded(); .... } /** * 6 当此服务器是master时:aof持久化失败时,或上一次bgsave执行错误, * 且配置bgsave参数和stop_writes_on_bgsave_err;禁止执行写命令 */ if (((server.stop_writes_on_bgsave_err && server.saveparamslen > 0 && server.lastbgsave_status == C_ERR) || server.aof_last_write_status == C_ERR) && server.masterhost == NULL && (c->cmd->flags & CMD_WRITE || c->cmd->proc == pingCommand)) { .... } /** * 7 当此服务器时master时:如果配置了repl_min_slaves_to_write, * 当slave数目小于时,禁止执行写命令 */ if (server.masterhost == NULL && server.repl_min_slaves_to_write && server.repl_min_slaves_max_lag && c->cmd->flags & CMD_WRITE && server.repl_good_slaves_count < server.repl_min_slaves_to_write) { .... } /** * 8 当时只读slave时,除了master的不接受其他写命令 */ if (server.masterhost && server.repl_slave_ro && !(c->flags & CLIENT_MASTER) && c->cmd->flags & CMD_WRITE) { .... } /** * 9 当客户端正在订阅频道时,只会执行以下命令 */ if (c->flags & CLIENT_PUBSUB && c->cmd->proc != pingCommand && c->cmd->proc != subscribeCommand && c->cmd->proc != unsubscribeCommand && c->cmd->proc != psubscribeCommand && c->cmd->proc != punsubscribeCommand) { .... } /** * 10 服务器为slave,但没有正确连接master时,只会执行带有CMD_STALE标志的命令,如info等 */ if (server.masterhost && server.repl_state != REPL_STATE_CONNECTED && server.repl_serve_stale_data == 0 && !(c->cmd->flags & CMD_STALE)) {...} /** * 11 正在加载数据库时,只会执行带有CMD_LOADING标志的命令,其余都会被拒绝 */ if (server.loading && !(c->cmd->flags & CMD_LOADING)) { .... } /** * 12 当服务器因为执行lua脚本阻塞时,只会执行以下几个命令,其余都会拒绝 */ if (server.lua_timedout && c->cmd->proc != authCommand && c->cmd->proc != replconfCommand && !(c->cmd->proc == shutdownCommand && c->argc == 2 && tolower(((char*)c->argv[1]->ptr)[0]) == 'n') && !(c->cmd->proc == scriptCommand && c->argc == 2 && tolower(((char*)c->argv[1]->ptr)[0]) == 'k')) {....} /** * 13 开始执行命令 */ if (c->flags & CLIENT_MULTI && c->cmd->proc != execCommand && c->cmd->proc != discardCommand && c->cmd->proc != multiCommand && c->cmd->proc != watchCommand) { /** * 开启了事务,命令只会入队列 */ queueMultiCommand(c); addReply(c,shared.queued); } else { /** * 直接执行命令 */ call(c,CMD_CALL_FULL); c->woff = server.master_repl_offset; if (listLength(server.ready_keys)) handleClientsBlockedOnLists(); } return C_OK; } struct redisCommand redisCommandTable[] = { {"get",getCommand,2,"rF",0,NULL,1,1,1,0,0}, {"set",setCommand,-3,"wm",0,NULL,1,1,1,0,0}, {"hmset",hsetCommand,-4,"wmF",0,NULL,1,1,1,0,0}, .... // 所有的 redis 命令都有 } |
call 方法是 Redis 中执行命令的通用方法,它会处理通用的执行命令的前置和后续操作
| 序号 | 操作步骤 |
| 1 | 如果有监视器 monitor,则需要将命令发送给监视器 |
| 2 | 调用 redisCommand 的proc 方法,执行对应具体的命令逻辑 |
| 3 | 如果开启了 CMD_CALL_SLOWLOG,则需要记录慢查询日志 |
| 4 | 如果开启了 CMD_CALL_STATS,则需要记录一些统计信息 |
| 5 | 如果开启了 CMD_CALL_PROPAGATE,则当 dirty大于0时,需要调用 propagate 方法来进行命令传播 |
| // 执行client中持有的 redisCommand 命令 void call(client *c, int flags) { /** * dirty记录数据库修改次数;start记录命令开始执行时间us;duration记录命令执行花费时间 */ long long dirty, start, duration; int client_old_flags = c->flags; /** * 有监视器的话,需要将不是从AOF获取的命令会发送给监视器。当然,这里会消耗时间 */ if (listLength(server.monitors) && !server.loading && !(c->cmd->flags & (CMD_SKIP_MONITOR|CMD_ADMIN))) { replicationFeedMonitors(c,server.monitors,c->db->id,c->argv,c->argc); } .... /* Call the command. */ dirty = server.dirty; start = ustime(); // 处理命令,调用命令处理函数 c->cmd->proc(c); duration = ustime()-start; dirty = server.dirty-dirty; if (dirty < 0) dirty = 0; .... // Lua 脚本的一些特殊处理 /** * CMD_CALL_SLOWLOG 表示要记录慢查询日志 */ if (flags & CMD_CALL_SLOWLOG && c->cmd->proc != execCommand) { char *latency_event = (c->cmd->flags & CMD_FAST) ? "fast-command" : "command"; latencyAddSampleIfNeeded(latency_event,duration/1000); slowlogPushEntryIfNeeded(c,c->argv,c->argc,duration); } /** * CMD_CALL_STATS 表示要统计 */ if (flags & CMD_CALL_STATS) { c->lastcmd->microseconds += duration; c->lastcmd->calls++; } /** * CMD_CALL_PROPAGATE表示要进行广播命令 */ if (flags & CMD_CALL_PROPAGATE && (c->flags & CLIENT_PREVENT_PROP) != CLIENT_PREVENT_PROP) { int propagate_flags = PROPAGATE_NONE; /** * dirty大于0时,需要广播命令给slave和aof */ if (dirty) propagate_flags |= (PROPAGATE_AOF|PROPAGATE_REPL); .... /** * 广播命令,写如aof,发送命令到slave * 也就是传说中的传播命令 */ if (propagate_flags != PROPAGATE_NONE && !(c->cmd->flags & CMD_MODULE)) propagate(c->cmd,c->db->id,c->argv,c->argc,propagate_flags); } .... } |
5.6 set命令具体实现
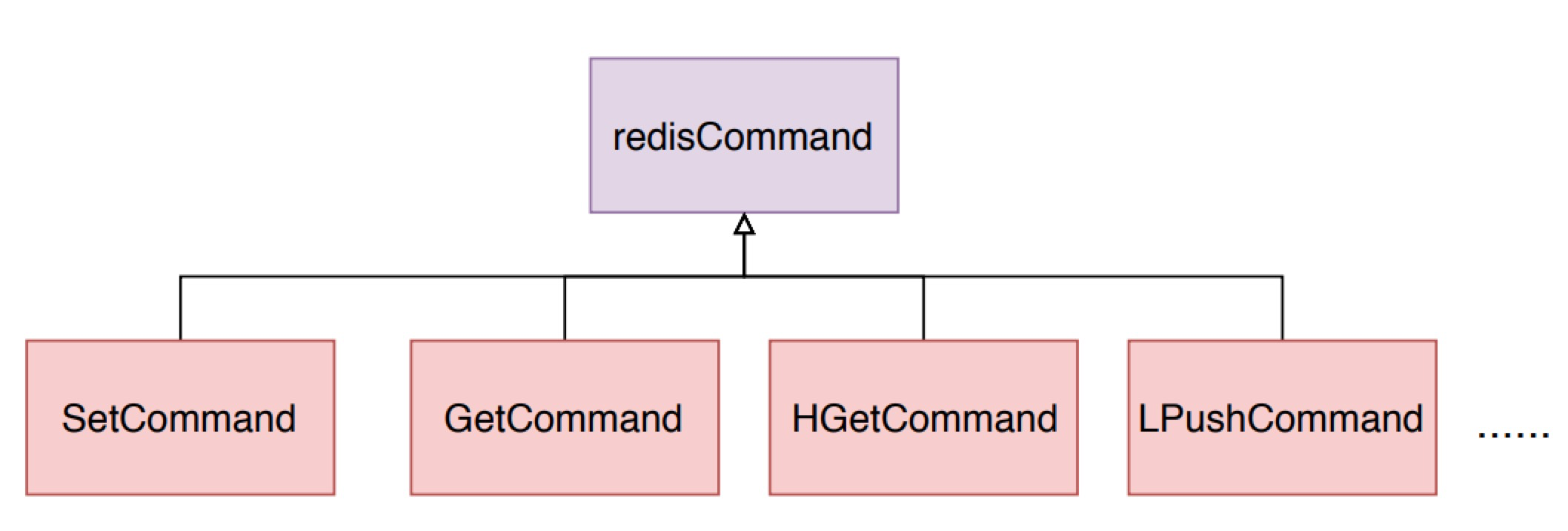
rocessCommand 方法会从输入缓冲区中解析出对应的 redisCommand,然后调用 call 方法执行解析出来的 redisCommand的 proc 方法。不同命令的的 proc 方法是不同的,比如说名为 set 的 redisCommand 的 proc 是 setCommand 方法,而 get 的则是 getCommand 方法
| void call(client *c, int flags) { .... c->cmd->proc(c); .... } // redisCommand结构体 struct redisCommand { char *name; // 对应方法的函数范式 redisCommandProc *proc; .... // 其他定义 }; // 使用 typedef 定义的别名 typedef void redisCommandProc(client *c); // 不同的命令,调用不同的方法。 struct redisCommand redisCommandTable[] = { {"get",getCommand,2,"rF",0,NULL,1,1,1,0,0}, {"set",setCommand,-3,"wm",0,NULL,1,1,1,0,0}, {"hmset",hsetCommand,-4,"wmF",0,NULL,1,1,1,0,0}, .... // 所有的 redis 命令都有 } |
setCommand 会判断set命令是否携带了nx、xx、ex或者px等可选参数,然后调用setGenericCommand命令。我们直接来看 setGenericCommand 方法。
setGenericCommand 方法的处理逻辑如下所示:
1)判断 set 的类型是 set_nx 还是 set_xx,如果是 nx 并且 key 已经存在则直接返回;如果是 xx 并且 key 不存在则直接返回。
- setKey 方法将键值添加到对应的 Redis 数据库中。
- 有过期时间,则调用 setExpire 将设置过期时间
- 键空间通知
- 对应的值给客户端。
|
5.7 get命令具体实现
getGenericCommand 方法会调用 lookupKeyReadOrReply 来从 dict 数据哈希表中查找对应的 key值。如果找不到,则直接返回 C_OK;如果找到了,则根据值的类型,调用 addReply 或者 addReplyBulk 方法将值添加到输出缓冲区中。
| int getGenericCommand(client *c) { robj *o; if ((o = lookupKeyReadOrReply(c,c->argv[1],shared.nullbulk)) == NULL) return C_OK; if (o->type != OBJ_STRING) { addReply(c,shared.wrongtypeerr); return C_ERR; } else { addReplyBulk(c,o); return C_OK; } } |
lookupKeyReadWithFlags 会从 redisDb 中查找对应的键值对,它首先会调用 expireIfNeeded判断键是否过期并且需要删除,如果为过期,则调用 lookupKey 方法从 dict 哈希表中查找并返回
| /* * 查找key的读操作,如果key找不到或者已经逻辑上过期返回 NULL,有一些副作用 * 1 如果key到达过期时间,它会被设备为过期,并且删除 * 2 更新key的最近访问时间 * 3 更新全局缓存击中概率 * flags 有两个值: LOOKUP_NONE 一般都是这个;LOOKUP_NOTOUCH 不修改最近访问时间 */ robj *lookupKeyReadWithFlags(redisDb *db, robj *key, int flags) { // db.c robj *val; // 检查键是否过期 if (expireIfNeeded(db,key) == 1) { .... // master和 slave 对这种情况的特殊处理 } // 查找键值字典 val = lookupKey(db,key,flags); // 更新全局缓存命中率 if (val == NULL) server.stat_keyspace_misses++; else server.stat_keyspace_hits++; return val; } |
Redis 在调用查找键值系列方法前都会先调用 expireIfNeeded 来判断键是否过期,然后根据 Redis 是否配置了懒删除来进行同步删除或者异步删除,在判断键释放过期的逻辑中有两个特殊情况:
1)当前 Redis 是主从结构中的从实例,则只判断键是否过期,不直接对键进行删除,而是要等待主实例发送过来的删除命令后再进行删除。如果当前 Redis 是主实例,则调用 propagateExpire 来传播过期指令。
2)当前正在进行 Lua 脚本执行,因为其原子性和事务性,整个执行过期中时间都按照其开始执行的那一刻计算,也就是说lua执行时未过期的键,在它整个执行过程中也都不会过期。

| /* * 在调用 lookupKey*系列方法前调用该方法。 * 如果是slave: * slave 并不主动过期删除key,但是返回值仍然会返回键已经被删除。 * master 如果key过期了,会主动删除过期键,并且触发 AOF 和同步操作。 * 返回值为0表示键仍然有效,否则返回1 */ int expireIfNeeded(redisDb *db, robj *key) { // db.c // 获取键的过期时间 mstime_t when = getExpire(db,key); mstime_t now; if (when < 0) return 0; /* * 如果当前是在执行lua脚本,根据其原子性,整个执行过期中时间都按照其开始执行的那一刻计算 * 也就是说lua执行时未过期的键,在它整个执行过程中也都不会过期。 */ now = server.lua_caller ? server.lua_time_start : mstime(); // slave 直接返回键是否过期 if (server.masterhost != NULL) return now > when; // master时,键未过期直接返回 if (now <= when) return 0; // 键过期,删除键 server.stat_expiredkeys++; // 触发命令传播 propagateExpire(db,key,server.lazyfree_lazy_expire); // 和键空间事件 notifyKeyspaceEvent(NOTIFY_EXPIRED, "expired",key,db->id); // 根据是否懒删除,调用不同的函数 return server.lazyfree_lazy_expire ? dbAsyncDelete(db,key) : dbSyncDelete(db,key); } |
lookupKey 方法则是通过 dictFind 方法从 redisDb 的 dict 哈希表中查找键值,如果能找到,则根据 redis 的 maxmemory_policy 策略来判断是更新 lru 的最近访问时间,还是调用 updateFU 方法更新其他指标,这些指标可以在后续内存不足时对键值进行回收
| robj *lookupKey(redisDb *db, robj *key, int flags) { // dictFind 根据 key 获取字典的entry dictEntry *de = dictFind(db->dict,key->ptr); if (de) { // 获取 value robj *val = dictGetVal(de); // 当处于 rdb aof 子进程复制阶段或者 flags 不是 LOOKUP_NOTOUCH if (server.rdb_child_pid == -1 && server.aof_child_pid == -1 && !(flags & LOOKUP_NOTOUCH)) { // 如果是 MAXMEMORY_FLAG_LFU 则进行相应操作 if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU) { updateLFU(val); } else { // 更新最近访问时间 val->lru = LRU_CLOCK(); } } return val; } else { return NULL; } } |
在所有的 redisCommand 执行的最后,一般都会调用 addReply 方法进行结果返回,ddReply 方法做了两件事情:
- prepareClientToWrite 判断是否需要返回数据,并且将当前 client 添加到等待写返回数据队列中
- 调用 _addReplyToBuffer 和 _addReplyObjectToList 方法将返回值写入到输出缓冲区中,等待写入 socekt
| void addReply(client *c, robj *obj) { if (prepareClientToWrite(c) != C_OK) return; if (sdsEncodedObject(obj)) { // 需要将响应内容添加到output buffer中。总体思路是,先尝试向固定buffer添加,添加失败的话,在尝试添加到响应链表 if (_addReplyToBuffer(c,obj->ptr,sdslen(obj->ptr)) != C_OK) _addReplyObjectToList(c,obj); } else if (obj->encoding == OBJ_ENCODING_INT) { .... // 特殊情况的优化 } else { serverPanic("Wrong obj->encoding in addReply()"); } } |
prepareClientToWrite 首先判断了当前 client是否需要返回数据:
- Lua 脚本执行的 client 则需要返回值;
- 如果客户端发送来 REPLY OFF 或者 SKIP 命令,则不需要返回值;
- 如果是主从复制时的主实例 client,则不需要返回值;
- 当前是在 AOF loading 状态的假 client,则不需要返回值。
接着如果这个 client 还未处于延迟等待写入 (CLIENT_PENDING_WRITE)的状态,则将其设置为该状态,并将其加入到 Redis 的等待写入返回值客户端队列中,也就是 clients_pending_write队列。
| int prepareClientToWrite(client *c) { // 如果是 lua client 则直接OK if (c->flags & (CLIENT_LUA|CLIENT_MODULE)) return C_OK; // 客户端发来过 REPLY OFF 或者 SKIP 命令,不需要发送返回值 if (c->flags & (CLIENT_REPLY_OFF|CLIENT_REPLY_SKIP)) return C_ERR; // master 作为client 向 slave 发送命令,不需要接收返回值 if ((c->flags & CLIENT_MASTER) && !(c->flags & CLIENT_MASTER_FORCE_REPLY)) return C_ERR; // AOF loading 时的假client 不需要返回值 if (c->fd <= 0) return C_ERR; // 将client加入到等待写入返回值队列中,下次事件周期会进行返回值写入。 if (!clientHasPendingReplies(c) && !(c->flags & CLIENT_PENDING_WRITE) && (c->replstate == REPL_STATE_NONE || (c->replstate == SLAVE_STATE_ONLINE && !c->repl_put_online_on_ack))) { // 设置标志位并且将client加入到 clients_pending_write 队列中 c->flags |= CLIENT_PENDING_WRITE; listAddNodeHead(server.clients_pending_write,c); } // 表示已经在排队,进行返回数据 return C_OK; } |
Redis 将存储等待返回的响应数据的空间,也就是输出缓冲区分成两部分,一个固定大小的 buffer 和一个响应内容数据的链表。在链表为空并且 buffer 有足够空间时,则将响应添加到 buffer 中。如果 buffer 满了则创建一个节点追加到链表上。_addReplyToBuffer 和 _addReplyObjectToList 就是分别向这两个空间写数据的方法。
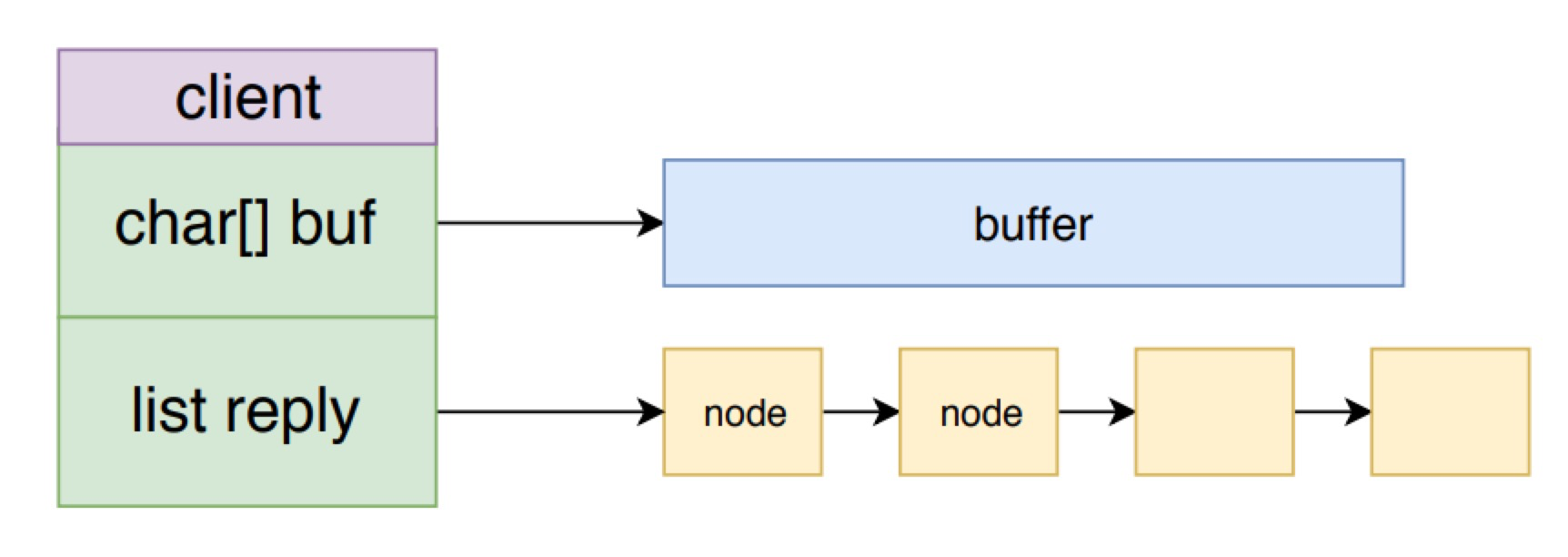
prepareClientToWrite 函数,将客户端加入到了Redis 的等待写入返回值客户端队列中,也就是 clients_pending_write 队列。请求处理的事件处理逻辑就结束了,等待 Redis 下一次事件循环处理时,将响应从输出缓冲区写入到 socket 中。
5.8 返回信息给client
Redis 在两次事件循环之间会调用 beforeSleep 方法处理一些事情,而对 clients_pending_write 列表的处理就在其中
aeMain 方法就是 Redis 事件循环的主逻辑,可以看到每次循环时都会调用 beforesleep 方法
| void aeMain(aeEventLoop *eventLoop) { // ae.c eventLoop->stop = 0; while (!eventLoop->stop) { /* 如果有需要在事件处理前执行的函数,那么执行它 */ if (eventLoop->beforesleep != NULL) eventLoop->beforesleep(eventLoop); /* 开始处理事件*/ aeProcessEvents(eventLoop, AE_ALL_EVENTS|AE_CALL_AFTER_SLEEP); } } |
beforeSleep 函数会调用 handleClientsWithPendingWrites 函数来处理 clients_pending_write 列表。
handleClientsWithPendingWrites 方法会遍历 clients_pending_write 列表,对于每个 client 都会先调用 writeToClient 方法来尝试将返回数据从输出缓存区写入到 socekt中,如果还未写完,则只能调用 aeCreateFileEvent 方法来注册一个写数据事件处理器 sendReplyToClient,等待 Redis 事件机制的再次调用。
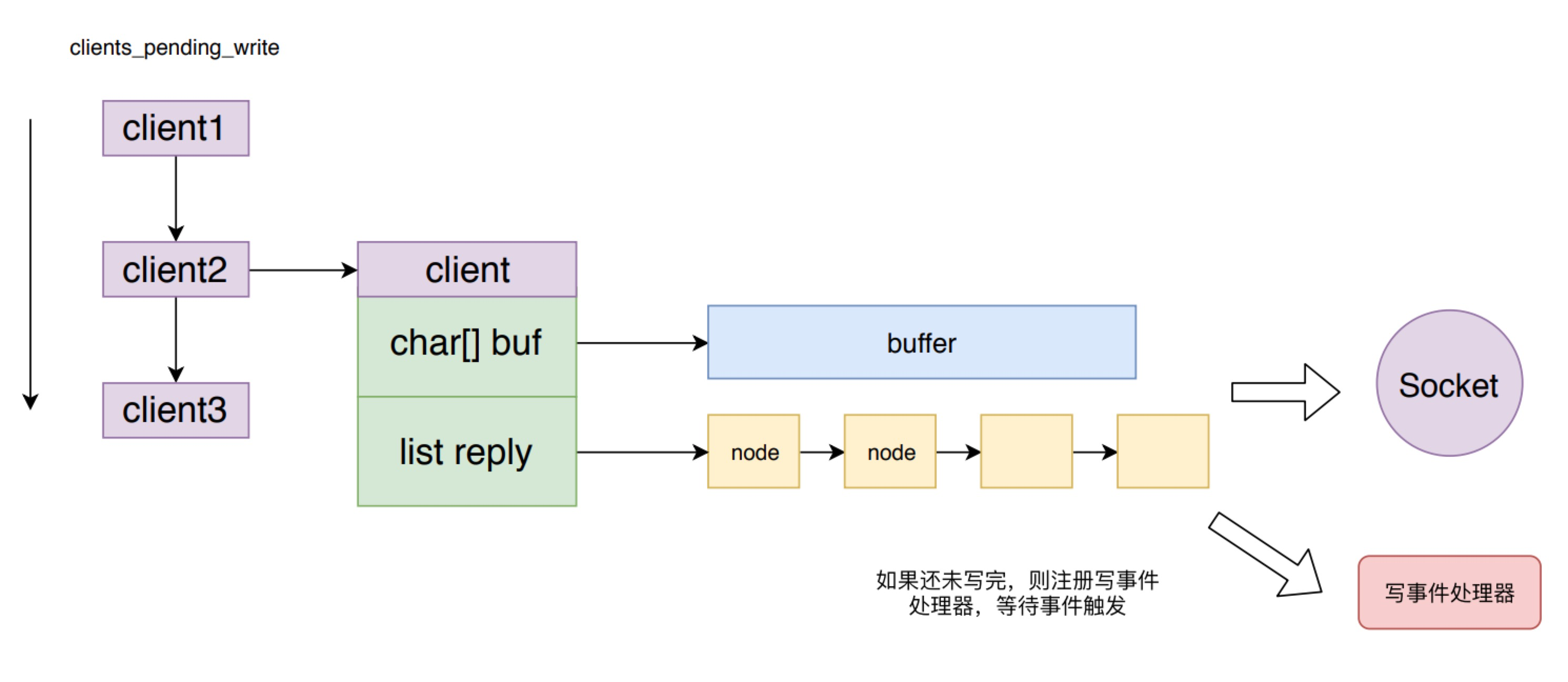
这样的好处是对于返回数据较少的客户端,不需要麻烦的注册写数据事件,等待事件触发再写数据到 socket,而是在下一次事件循环周期就直接将数据写到 socket中,加快了数据返回的响应速度。
但是从这里也会发现,如果 clients_pending_write 队列过长,则处理时间也会很久,阻塞正常的事件响应处理,导致 Redis 后续命令延时增加。
| int handleClientsWithPendingWrites(void) { listIter li; listNode *ln; int processed = listLength(server.clients_pending_write); listRewind(server.clients_pending_write,&li); while((ln = listNext(&li))) { client *c = listNodeValue(ln); c->flags &= ~CLIENT_PENDING_WRITE; listDelNode(server.clients_pending_write,ln); /* If a client is protected, don't do anything, * that may trigger write error or recreate handler. */ if (c->flags & CLIENT_PROTECTED) continue; /* Try to write buffers to the client socket. */ if (writeToClient(c->fd,c,0) == C_ERR) continue; /* If after the synchronous writes above we still have data to * output to the client, we need to install the writable handler. */ if (clientHasPendingReplies(c)) { int ae_flags = AE_WRITABLE; /* For the fsync=always policy, we want that a given FD is never * served for reading and writing in the same event loop iteration, * so that in the middle of receiving the query, and serving it * to the client, we'll call beforeSleep() that will do the * actual fsync of AOF to disk. AE_BARRIER ensures that. */ if (server.aof_state == AOF_ON && server.aof_fsync == AOF_FSYNC_ALWAYS) { ae_flags |= AE_BARRIER; } if (aeCreateFileEvent(server.el, c->fd, ae_flags, sendReplyToClient, c) == AE_ERR) { freeClientAsync(c); } } } return processed; } |
sendReplyToClient 方法其实也会调用 writeToClient 方法,该方法就是将输出缓冲区中的 buf 和 reply 列表中的数据都尽可能多的写入到对应的 socket中。
| /* Write event handler. Just send data to the client. */ void sendReplyToClient(aeEventLoop *el, int fd, void *privdata, int mask) { UNUSED(el); UNUSED(mask); writeToClient(fd,privdata,1); } |
| // 将输出缓冲区中的数据写入socket,如果还有数据未处理则返回C_OK int writeToClient(int fd, client *c, int handler_installed) { ssize_t nwritten = 0, totwritten = 0; size_t objlen; sds o; // 仍然有数据未写入 while(clientHasPendingReplies(c)) { // 如果缓冲区有数据 if (c->bufpos > 0) { // 写入到 fd 代表的 socket 中 nwritten = write(fd,c->buf+c->sentlen,c->bufpos-c->sentlen); if (nwritten <= 0) break; c->sentlen += nwritten; // 统计本次一共输出了多少子节 totwritten += nwritten; // buffer中的数据已经发送,则重置标志位,让响应的后续数据写入buffer if ((int)c->sentlen == c->bufpos) { c->bufpos = 0; c->sentlen = 0; } } else { // 缓冲区没有数据,从reply队列中拿 o = listNodeValue(listFirst(c->reply)); objlen = sdslen(o); if (objlen == 0) { listDelNode(c->reply,listFirst(c->reply)); continue; } // 将队列中的数据写入 socket nwritten = write(fd, o + c->sentlen, objlen - c->sentlen); if (nwritten <= 0) break; c->sentlen += nwritten; totwritten += nwritten; // 如果写入成功,则删除队列 if (c->sentlen == objlen) { listDelNode(c->reply,listFirst(c->reply)); c->sentlen = 0; c->reply_bytes -= objlen; if (listLength(c->reply) == 0) serverAssert(c->reply_bytes == 0); } } // 如果输出的字节数量已经超过NET_MAX_WRITES_PER_EVENT限制,break if (totwritten > NET_MAX_WRITES_PER_EVENT && (server.maxmemory == 0 || zmalloc_used_memory() < server.maxmemory) && !(c->flags & CLIENT_SLAVE)) break; } server.stat_net_output_bytes += totwritten; if (nwritten == -1) { if (errno == EAGAIN) { nwritten = 0; } else { serverLog(LL_VERBOSE, "Error writing to client: %s", strerror(errno)); freeClient(c); return C_ERR; } } if (!clientHasPendingReplies(c)) { c->sentlen = 0; //如果内容已经全部输出,删除事件处理器 if (handler_installed) aeDeleteFileEvent(server.el,c->fd,AE_WRITABLE); // 数据全部返回,则关闭client和连接 if (c->flags & CLIENT_CLOSE_AFTER_REPLY) { freeClient(c); return C_ERR; } } return C_OK; } |
6 AOF分析
6.1 AOF配置
| appendonly no # aof开关,默认关闭 appendfilename "appendonly.aof" # 保存的文件名,默认appendonly.aof # 有三种刷数据的策略 appendfsync always # always是只要有数据改动,就把数据刷到磁盘里,最安全但性能也最差 appendfsync everysec # 每隔一秒钟刷一次数据,数据安全性和性能折中,这也是redis默认和推荐的配置。 appendfsync no # 不主动刷,什么时候数据刷到磁盘里取决于操作系统,在大多数Linux系统中每30秒提交一次,性能最好,但数据安全性最差。 |
6.2 AOF文件格式

6.3 AOF 持久化的实现

如上图所示,AOF 持久化功能的实现可以分为命令追加( append )、文件写入( write )、文件同步( sync )、文件重写(rewrite)和重启加载(load)。其流程如下:
- 所有的写命令会追加到 AOF 缓冲中。
- AOF 缓冲区根据对应的策略向硬盘进行同步操作。
- 随着 AOF 文件越来越大,需要定期对 AOF 文件进行重写,达到压缩的目的。
4)当 Redis 重启时,可以加载 AOF 文件进行数据恢复
6.3.1 命令追加
当 AOF 持久化功能处于打开状态时,Redis 在执行完一个写命令之后,会以协议格式(也就是RESP,即 Redis 客户端和服务器交互的通信协议 )将被执行的写命令追加到 Redis 服务端维护的 AOF 缓冲区末尾。
比如说 SET mykey myvalue 这条命令就以如下格式记录到 AOF 缓冲中。
"*3\r\n$3\r\nSET\r\n$5\r\nmykey\r\n$7\r\nmyvalue\r\n"
| void propagate(struct redisCommand *cmd, int dbid, robj **argv, int argc, int flags) { if (server.aof_state != AOF_OFF && flags & PROPAGATE_AOF) feedAppendOnlyFile(cmd,dbid,argv,argc); if (flags & PROPAGATE_REPL) replicationFeedSlaves(server.slaves,dbid,argv,argc); } |
feedAppendOnlyFile 函数会把命令追加到aof_buf中
| void feedAppendOnlyFile(struct redisCommand *cmd, int dictid, robj **argv, int argc) { sds buf = sdsempty(); robj *tmpargv[3]; /* The DB this command was targeting is not the same as the last command * we appended. To issue a SELECT command is needed. */ if (dictid != server.aof_selected_db) { char seldb[64]; snprintf(seldb,sizeof(seldb),"%d",dictid); buf = sdscatprintf(buf,"*2\r\n$6\r\nSELECT\r\n$%lu\r\n%s\r\n", (unsigned long)strlen(seldb),seldb); server.aof_selected_db = dictid; } if (cmd->proc == expireCommand || cmd->proc == pexpireCommand || cmd->proc == expireatCommand) { /* Translate EXPIRE/PEXPIRE/EXPIREAT into PEXPIREAT */ buf = catAppendOnlyExpireAtCommand(buf,cmd,argv[1],argv[2]); } else if (cmd->proc == setexCommand || cmd->proc == psetexCommand) { /* Translate SETEX/PSETEX to SET and PEXPIREAT */ tmpargv[0] = createStringObject("SET",3); tmpargv[1] = argv[1]; tmpargv[2] = argv[3]; buf = catAppendOnlyGenericCommand(buf,3,tmpargv); decrRefCount(tmpargv[0]); buf = catAppendOnlyExpireAtCommand(buf,cmd,argv[1],argv[2]); } else if (cmd->proc == setCommand && argc > 3) { int i; robj *exarg = NULL, *pxarg = NULL; /* Translate SET [EX seconds][PX milliseconds] to SET and PEXPIREAT */ buf = catAppendOnlyGenericCommand(buf,3,argv); for (i = 3; i < argc; i ++) { if (!strcasecmp(argv[i]->ptr, "ex")) exarg = argv[i+1]; if (!strcasecmp(argv[i]->ptr, "px")) pxarg = argv[i+1]; } serverAssert(!(exarg && pxarg)); if (exarg) buf = catAppendOnlyExpireAtCommand(buf,server.expireCommand,argv[1], exarg); if (pxarg) buf = catAppendOnlyExpireAtCommand(buf,server.pexpireCommand,argv[1], pxarg); } else { /* All the other commands don't need translation or need the * same translation already operated in the command vector * for the replication itself. */ buf = catAppendOnlyGenericCommand(buf,argc,argv); } /* Append to the AOF buffer. This will be flushed on disk just before * of re-entering the event loop, so before the client will get a * positive reply about the operation performed. */ if (server.aof_state == AOF_ON) server.aof_buf = sdscatlen(server.aof_buf,buf,sdslen(buf)); /*如果后台仅AOF文件重写正在进行,以便在子进程完成其工作时将差异附加到新的仅附加文件*/ if (server.aof_child_pid != -1) aofRewriteBufferAppend((unsigned char*)buf,sdslen(buf)); sdsfree(buf); } |
6.3.2 文件写入和同步
写入aof文件的核心代码在flushAppendOnlyFile()中,flushAppendOnlyFile在serverCron、beforeSleep和prepareForShutdown中都有被调用,它的作用就是将缓冲区的数据写到aof文件中。
Redis 每次结束一个事件循环之前,它都会调用 flushAppendOnlyFile 函数,判断是否需要将 AOF 缓存区中的内容写入和同步到 AOF 文件中。
flushAppendOnlyFile 函数的行为由 redis.conf 配置中的 appendfsync 选项的值来决定。该选项有三个可选值,分别是 always、 everysec 和 no:
1)always:Redis 在每个事件循环都要将 AOF 缓冲区中的所有内容写入到 AOF 文件,并且同步 AOF 文件,所以 always 的效率是 appendfsync 选项三个值当中最差的一个,但从安全性来说,也是最安全的。当发生故障停机时,AOF 持久化也只会丢失一个事件循环中所产生的命令数据。
2)everysec:Redis 在每个事件循环都要将 AOF 缓冲区中的所有内容写入到 AOF 文件中,并且每隔一秒就要在子线程中对 AOF 文件进行一次同步。从效率上看,该模式足够快。当发生故障停机时,只会丢失一秒钟的命令数据。
3)no:Redis 在每一个事件循环都要将 AOF 缓冲区中的所有内容写入到 AOF 文件。而 AOF 文件的同步由操作系统控制。这种模式下速度最快,但是同步的时间间隔较长,出现故障时可能会丢失较多数据。
| void flushAppendOnlyFile(int force) { ssize_t nwritten; int sync_in_progress = 0; mstime_t latency; if (sdslen(server.aof_buf) == 0) { /* Check if we need to do fsync even the aof buffer is empty, * because previously in AOF_FSYNC_EVERYSEC mode, fsync is * called only when aof buffer is not empty, so if users * stop write commands before fsync called in one second, * the data in page cache cannot be flushed in time. */ if (server.aof_fsync == AOF_FSYNC_EVERYSEC && server.aof_fsync_offset != server.aof_current_size && server.unixtime > server.aof_last_fsync && !(sync_in_progress = aofFsyncInProgress())) { goto try_fsync; } else { return; } } if (server.aof_fsync == AOF_FSYNC_EVERYSEC) sync_in_progress = aofFsyncInProgress(); if (server.aof_fsync == AOF_FSYNC_EVERYSEC && !force) { /* With this append fsync policy we do background fsyncing. * If the fsync is still in progress we can try to delay * the write for a couple of seconds. */ if (sync_in_progress) { if (server.aof_flush_postponed_start == 0) { /* No previous write postponing, remember that we are * postponing the flush and return. */ server.aof_flush_postponed_start = server.unixtime; return; } else if (server.unixtime - server.aof_flush_postponed_start < 2) { /* We were already waiting for fsync to finish, but for less * than two seconds this is still ok. Postpone again. */ return; } /* Otherwise fall trough, and go write since we can't wait * over two seconds. */ server.aof_delayed_fsync++; } } latencyStartMonitor(latency); nwritten = aofWrite(server.aof_fd,server.aof_buf,sdslen(server.aof_buf)); latencyEndMonitor(latency);
……… server.aof_current_size += nwritten; /* 释放aof_buf */ if ((sdslen(server.aof_buf)+sdsavail(server.aof_buf)) < 4000) { sdsclear(server.aof_buf); } else { sdsfree(server.aof_buf); server.aof_buf = sdsempty(); } try_fsync: /* Don't fsync if no-appendfsync-on-rewrite is set to yes and there are * children doing I/O in the background. */ if (server.aof_no_fsync_on_rewrite && (server.aof_child_pid != -1 || server.rdb_child_pid != -1)) return; /* Perform the fsync if needed. */ if (server.aof_fsync == AOF_FSYNC_ALWAYS) { /* redis_fsync is defined as fdatasync() for Linux in order to avoid * flushing metadata. */ latencyStartMonitor(latency); redis_fsync(server.aof_fd); /* Let's try to get this data on the disk */ latencyEndMonitor(latency); latencyAddSampleIfNeeded("aof-fsync-always",latency); server.aof_fsync_offset = server.aof_current_size; server.aof_last_fsync = server.unixtime; } else if ((server.aof_fsync == AOF_FSYNC_EVERYSEC && server.unixtime > server.aof_last_fsync)) { if (!sync_in_progress) { aof_background_fsync(server.aof_fd); server.aof_fsync_offset = server.aof_current_size; } server.aof_last_fsync = server.unixtime; } } |
6.3.3 AOF 数据恢复
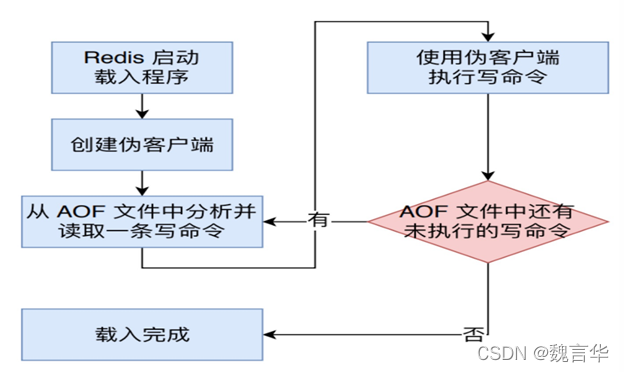
Redis 读取 AOF 文件并且还原数据库状态的详细步骤如下:
1)创建一个不带网络连接的的伪客户端( fake client),因为 Redis 的命令只能在客户端上下文中执行,而载入 AOF 文件时所使用的的命令直接来源于 AOF 文件而不是网络连接,所以服务器使用了一个没有网络连接的伪客户端来执行 AOF 文件保存的写命令,伪客户端执行命令的效果和带网络连接的客户端执行命令的效果完全一样的。
2)从 AOF 文件中分析并取出一条写命令。
3)使用伪客户端执行被读出的写命令。
4)一直执行步骤 2 和步骤3,直到 AOF 文件中的所有写命令都被处理完毕为止。
当完成以上步骤之后,AOF 文件所保存的数据库状态就会被完整还原出来。
loadDataFromDisk --- loadAppendOnlyFile
6.3.4 AOF 重写
因为 AOF 持久化是通过保存被执行的写命令来记录 Redis 状态的,所以随着 Redis 长时间运行,AOF 文件中的内容会越来越多,文件的体积也会越来越大,如果不加以控制的话,体积过大的 AOF 文件很可能对 Redis 甚至宿主计算机造成影响。
为了解决 AOF 文件体积膨胀的问题,Redis 提供了 AOF 文件重写( rewrite) 功能。通过该功能,Redis 可以创建一个新的 AOF 文件来替代现有的 AOF 文件。新旧两个 AOF 文件所保存的 Redis 状态相同,但是新的 AOF 文件不会包含任何浪费空间的荣誉命令,所以新 AOF 文件的体积通常比旧 AOF 文件的体积要小得很多。
AOF 文件重写并不需要对现有的 AOF 文件进行任何读取、分析或者写入操作,而是通过读取服务器当前的数据库状态来实现的。首先从数据库中读取键现在的值,然后用一条命令去记录键值对,代替之前记录这个键值对的多条命令,这就是 AOF 重写功能的实现原理。
在实际过程中,为了避免在执行命令时造成客户端输入缓冲区溢出,AOF 重写在处理列表、哈希表、集合和有序集合这四种可能会带有多个元素的键时,会先检查键所包含的元素数量,如果数量超过 REDISAOFREWRITEITEMSPER_CMD ( 一般为64 )常量,则使用多条命令记录该键的值,而不是一条命令。
rewrite的触发机制主要有一下三个:
- 手动调用 bgrewriteaof 命令,如果当前有正在运行的 rewrite 子进程,则本次rewrite 会推迟执行,否则,直接触发一次 rewrite。
| void bgrewriteaofCommand(client *c) { if (server.aof_child_pid != -1) { addReplyError(c,"Background append only file rewriting already in progress"); } else if (server.rdb_child_pid != -1) { server.aof_rewrite_scheduled = 1; addReplyStatus(c,"Background append only file rewriting scheduled"); } else if (rewriteAppendOnlyFileBackground() == C_OK) { addReplyStatus(c,"Background append only file rewriting started"); } else { addReply(c,shared.err); } } |
- 通过配置指令手动开启 AOF 功能,如果没有 RDB 子进程的情况下,会触发一次 rewrite,将当前数据库中的数据写入 rewrite 文件。
| /* Called when the user switches from "appendonly no" to "appendonly yes" * at runtime using the CONFIG command. */ int startAppendOnly(void) { char cwd[MAXPATHLEN]; /* Current working dir path for error messages. */ int newfd; newfd = open(server.aof_filename,O_WRONLY|O_APPEND|O_CREAT,0644); serverAssert(server.aof_state == AOF_OFF); if (newfd == -1) { char *cwdp = getcwd(cwd,MAXPATHLEN); return C_ERR; } /* 正在进行db的存储,则稍后进行aof的重写 */ if (server.rdb_child_pid != -1) { server.aof_rewrite_scheduled = 1; } else { /* If there is a pending AOF rewrite, we need to switch it off and * start a new one: the old one cannot be reused because it is not * accumulating the AOF buffer. */ if (server.aof_child_pid != -1) { serverLog(LL_WARNING,"AOF was enabled but there is already an AOF rewriting in background. Stopping background AOF and starting a rewrite now."); killAppendOnlyChild(); } if (rewriteAppendOnlyFileBackground() == C_ERR) { close(newfd); serverLog(LL_WARNING,"Redis needs to enable the AOF but can't trigger a background AOF rewrite operation. Check the above logs for more info about the error."); return C_ERR; } } /* We correctly switched on AOF, now wait for the rewrite to be complete * in order to append data on disk. */ server.aof_state = AOF_WAIT_REWRITE; server.aof_last_fsync = server.unixtime; server.aof_fd = newfd; return C_OK; } |
3)在 Redis 定时器中,如果有需要退出执行的 rewrite 并且没有正在运行的 RDB 或者 rewrite 子进程时,触发一次或者 AOF 文件大小已经到达配置的 rewrite 条件也会自动触发一次。默认大于64M字节时开始重写aof文件
| /* Start a scheduled AOF rewrite if this was requested by the user while * a BGSAVE was in progress. */ if (server.rdb_child_pid == -1 && server.aof_child_pid == -1 && server.aof_rewrite_scheduled) { rewriteAppendOnlyFileBackground(); } /* Trigger an AOF rewrite if needed. */ if (server.aof_state == AOF_ON && server.rdb_child_pid == -1 && server.aof_child_pid == -1 && server.aof_rewrite_perc && server.aof_current_size > server.aof_rewrite_min_size) { long long base = server.aof_rewrite_base_size ? server.aof_rewrite_base_size : 1; long long growth = (server.aof_current_size*100/base) - 100; if (growth >= server.aof_rewrite_perc) { serverLog(LL_NOTICE,"Starting automatic rewriting of AOF on %lld%% growth",growth); rewriteAppendOnlyFileBackground(); } } |
| int rewriteAppendOnlyFileBackground(void) { pid_t childpid; long long start; if (server.aof_child_pid != -1 || server.rdb_child_pid != -1) return C_ERR; if (aofCreatePipes() != C_OK) return C_ERR; openChildInfoPipe(); start = ustime(); if ((childpid = fork()) == 0) { char tmpfile[256]; /* Child */ closeClildUnusedResourceAfterFork(); redisSetProcTitle("redis-aof-rewrite"); snprintf(tmpfile,256,"temp-rewriteaof-bg-%d.aof", (int) getpid()); if (rewriteAppendOnlyFile(tmpfile) == C_OK) { size_t private_dirty = zmalloc_get_private_dirty(-1); if (private_dirty) { serverLog(LL_NOTICE, "AOF rewrite: %zu MB of memory used by copy-on-write", private_dirty/(1024*1024)); } server.child_info_data.cow_size = private_dirty; sendChildInfo(CHILD_INFO_TYPE_AOF); exitFromChild(0); } else { exitFromChild(1); } } else { /* Parent */ server.stat_fork_time = ustime()-start; server.stat_fork_rate = (double) zmalloc_used_memory() * 1000000 / server.stat_fork_time / (1024*1024*1024); /* GB per second. */ latencyAddSampleIfNeeded("fork",server.stat_fork_time/1000); if (childpid == -1) { closeChildInfoPipe(); serverLog(LL_WARNING, "Can't rewrite append only file in background: fork: %s", strerror(errno)); aofClosePipes(); return C_ERR; } serverLog(LL_NOTICE, "Background append only file rewriting started by pid %d",childpid); server.aof_rewrite_scheduled = 0; server.aof_rewrite_time_start = time(NULL); server.aof_child_pid = childpid; updateDictResizePolicy(); /* We set appendseldb to -1 in order to force the next call to the * feedAppendOnlyFile() to issue a SELECT command, so the differences * accumulated by the parent into server.aof_rewrite_buf will start * with a SELECT statement and it will be safe to merge. */ server.aof_selected_db = -1; replicationScriptCacheFlush(); return C_OK; } return C_OK; /* unreached */ } |
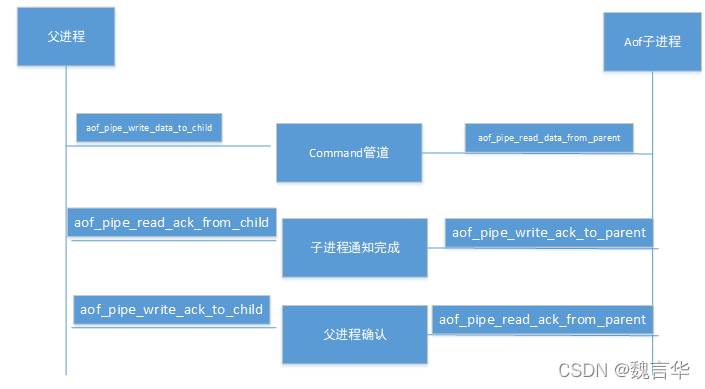
由于aof后台存储是异步进行的,所以在写aof时,可以正常提供client的服务。后台子进程在写aof文件时直接从db中读取,那client端写入的数据是怎样存储到aof文件的呢,redis通过管道实现父进程和子进程的通信,把client端写入的数据通过管道传到后端存储子进程。
父进程:feedAppendOnlyFile ---> aofRewriteBufferAppend ---> aofChildWriteDiffData
| /* Append data to the AOF rewrite buffer, allocating new blocks if needed. */ void aofRewriteBufferAppend(unsigned char *s, unsigned long len) { listNode *ln = listLast(server.aof_rewrite_buf_blocks); aofrwblock *block = ln ? ln->value : NULL; while(len) { /* If we already got at least an allocated block, try appending * at least some piece into it. */ if (block) { unsigned long thislen = (block->free < len) ? block->free : len; if (thislen) { /* The current block is not already full. */ memcpy(block->buf+block->used, s, thislen); block->used += thislen; block->free -= thislen; s += thislen; len -= thislen; } } if (len) { /* First block to allocate, or need another block. */ int numblocks; block = zmalloc(sizeof(*block)); block->free = AOF_RW_BUF_BLOCK_SIZE; block->used = 0; listAddNodeTail(server.aof_rewrite_buf_blocks,block); /* Log every time we cross more 10 or 100 blocks, respectively * as a notice or warning. */ numblocks = listLength(server.aof_rewrite_buf_blocks); if (((numblocks+1) % 10) == 0) { int level = ((numblocks+1) % 100) == 0 ? LL_WARNING : LL_NOTICE; serverLog(level,"Background AOF buffer size: %lu MB", aofRewriteBufferSize()/(1024*1024)); } } } /* Install a file event to send data to the rewrite child if there is * not one already. */ if (aeGetFileEvents(server.el,server.aof_pipe_write_data_to_child) == 0) { aeCreateFileEvent(server.el, server.aof_pipe_write_data_to_child, AE_WRITABLE, aofChildWriteDiffData, NULL); } } void aofChildWriteDiffData(aeEventLoop *el, int fd, void *privdata, int mask) { listNode *ln; aofrwblock *block; ssize_t nwritten; UNUSED(el); UNUSED(fd); UNUSED(privdata); UNUSED(mask); while(1) { ln = listFirst(server.aof_rewrite_buf_blocks); block = ln ? ln->value : NULL; if (server.aof_stop_sending_diff || !block) { aeDeleteFileEvent(server.el,server.aof_pipe_write_data_to_child, AE_WRITABLE); return; } if (block->used > 0) { nwritten = write(server.aof_pipe_write_data_to_child, block->buf,block->used); if (nwritten <= 0) return; memmove(block->buf,block->buf+nwritten,block->used-nwritten); block->used -= nwritten; block->free += nwritten; } if (block->used == 0) listDelNode(server.aof_rewrite_buf_blocks,ln); } } |
子进程:rewriteAppendOnlyFile---> aofReadDiffFromParent
| ssize_t aofReadDiffFromParent(void) { char buf[65536]; /* Default pipe buffer size on most Linux systems. */ ssize_t nread, total = 0; while ((nread = read(server.aof_pipe_read_data_from_parent,buf,sizeof(buf))) > 0) { server.aof_child_diff = sdscatlen(server.aof_child_diff,buf,nread); total += nread; } return total; } |
7 RDB分析
RDB 触发机制分为使用指令手动触发和自动触发
1)save ,该指令会阻塞当前 Redis 服务器,执行 save 指令期间,Redis 不能处理其他命令,直到 RDB 过程完成为止。
2)bgsave,执行该命令时,Redis 会在后台异步执行快照操作,此时 Redis 仍然可以相应客户端请求。具体操作是 Redis 进程执行 fork 操作创建子进程,RDB 持久化过程由子进程负责,完成后自动结束。Redis 只会在 fork 期间发生阻塞,但是一般时间都很短。但是如果 Redis 数据量特别大,fork 时间就会变长,而且占用内存会加倍,这一点需要特别注意。
3)自动触发 RDB 的默认配置如下所示
save 900 1 # 表示900 秒内如果至少有 1 个 key 的值变化,则触发RDB
save 300 10 # 表示300 秒内如果至少有 10 个 key 的值变化,则触发RDB
save 60 10000 # 表示60 秒内如果至少有 10000 个 key 的值变化,则触发RDB
Redis 服务器周期操作函数 serverCron 默认每个 100 毫秒就会执行一次,该函数用于正在运行的服务器进行维护,它的一项工作就是检查 save 选项所设置的条件是否有一项被满足,如果满足的话,就执行 bgsave 指令
7.1 执行流程

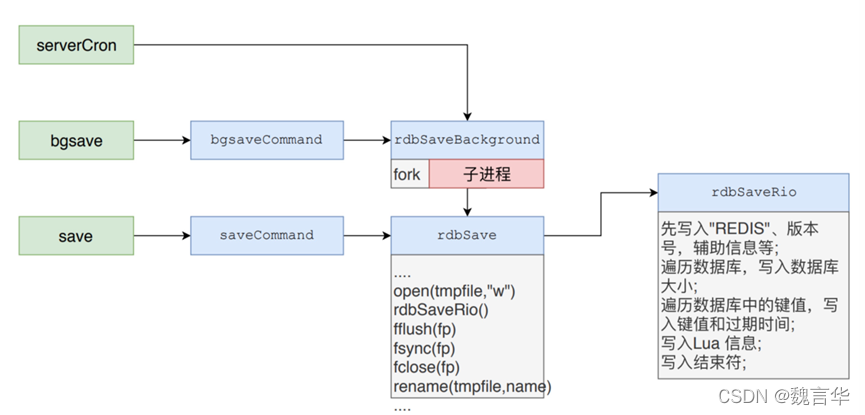
1) Redis父进程首先判断:当前是否在执行save,或bgsave/bgrewriteaof(后面会详细介绍该命令)的子进程,如果在执行则bgsave命令直接返回。bgsave/bgrewriteaof 的子进程不能同时执行,主要是基于性能方面的考虑:两个并发的子进程同时执行大量的磁盘写操作,可能引起严重的性能问题。
2) 父进程执行fork操作创建子进程,这个过程中父进程是阻塞的,Redis不能执行来自客户端的任何命令
3) 父进程fork后,bgsave命令返回”Background saving started”信息并不再阻塞父进程,并可以响应其他命令
4) 子进程创建RDB文件,根据父进程内存快照生成临时快照文件,完成后对原有文件进行原子替换
5) 子进程发送信号给父进程表示完成,父进程更新统计信息
7.2 RDB文件格式
RDB文件是经过压缩的二进制文件, RDB文件的存储路径既可以在启动前配置,也可以通过命令动态设定。默认是Redis根目录下的dump.rdb文件。动态设定:Redis启动后也可以动态修改RDB存储路径,在磁盘损害或空间不足时非常有用;执行命令为
config set dir {newdir}和config set dbfilename {newFileName}
RDB文件格式:
![]()
1) REDIS:常量,保存着”REDIS”5个字符。
2) db_version:RDB文件的版本号,注意不是Redis的版本号。
3) SELECTDB 0 pairs:表示一个完整的数据库(0号数据库),同理SELECTDB 3 pairs表示完整的3号数据库;只有当数据库中有键值对时,RDB文件中才会有该数据库的信息(上图所示的Redis中只有0号和3号数据库有键值对);如果Redis中所有的数据库都没有键值对,则这一部分直接省略。其中:SELECTDB是一个常量,代表后面跟着的是数据库号码;0和3是数据库号码;pairs则存储了具体的键值对信息,包括key、value值,及其数据类型、内部编码、过期时间、压缩信息等等。
4) EOF:常量,标志RDB文件正文内容结束。
5) check_sum:前面所有内容的校验和;Redis在载入RBD文件时,会计算前面的校验和并与check_sum值比较,判断文件是否损坏。Redis默认采用LZF算法对RDB文件进行压缩。虽然压缩耗时,但是可以大大减小RDB文件的体积,因此压缩默认开启;可以通过命令关闭,RDB文件的压缩并不是针对整个文件进行的,而是对数据库中的字符串进行的,且只有在字符串达到一定长度(20字节)时才会进行
7.3 RDB持久化实现
7.3.1 自动触发 RDB 持久化

如上图所示,redisServer 结构体的save_params指向拥有三个值的数组,该数组的值与 redis.conf 文件中 save 配置项一一对应。分别是 save 900 1、save 300 10 和 save 60 10000。dirty 记录着有多少键值发生变化,lastsave记录着上次 RDB 持久化的时间。
| int serverCron(struct aeEventLoop *eventLoop, long long id, void *clientData) { .... /* Check if a background saving or AOF rewrite in progress terminated. */ /* 判断后台是否正在进行 rdb 或者 aof 操作 */ if (server.rdb_child_pid != -1 || server.aof_child_pid != -1 || ldbPendingChildren()) { .... } else { // 到这儿就能确定 当前木有进行 rdb 或者 aof 操作 // 遍历每一个 rdb 保存条件 for (j = 0; j < server.saveparamslen; j++) { struct saveparam *sp = server.saveparams+j; //如果数据保存记录 大于规定的修改次数 且距离 上一次保存的时间大于规定时间或者上次BGSAVE命令执行成功,才执行 BGSAVE 操作 if (server.dirty >= sp->changes && server.unixtime-server.lastsave > sp->seconds && (server.unixtime-server.lastbgsave_try > CONFIG_BGSAVE_RETRY_DELAY || server.lastbgsave_status == C_OK)) { //记录日志 serverLog(LL_NOTICE,"%d changes in %d seconds. Saving...", sp->changes, (int)sp->seconds); rdbSaveInfo rsi, *rsiptr; rsiptr = rdbPopulateSaveInfo(&rsi); // 异步保存操作 rdbSaveBackground(server.rdb_filename,rsiptr); break; } } } .... server.cronloops++; return 1000/server.hz; } |
如果符合触发 RDB 持久化的条件,serverCron会调用rdbSaveBackground函数,也就是 bgsave 指令会触发的函数
| int rdbSaveBackground(char *filename, rdbSaveInfo *rsi) { pid_t childpid; long long start; // 检查后台是否正在执行 aof 或者 rdb 操作 if (server.aof_child_pid != -1 || server.rdb_child_pid != -1) return C_ERR; // 拿出 数据保存记录,保存为 上次记录 server.dirty_before_bgsave = server.dirty; // bgsave 时间 server.lastbgsave_try = time(NULL); start = ustime(); // fork 子进程 if ((childpid = fork()) == 0) { int retval; /* 关闭子进程继承的 socket 监听 */ closeListeningSockets(0); // 子进程 title 修改 redisSetProcTitle("redis-rdb-bgsave"); // 执行rdb 写入操作 retval = rdbSave(filename,rsi); // 执行完毕以后 .... // 退出子进程 exitFromChild((retval == C_OK) ? 0 : 1); } else { /* 父进程,进行fork时间的统计和信息记录,比如说rdb_save_time_start、rdb_child_pid、和rdb_child_type */ .... // rdb 保存开始时间 bgsave 子进程 server.rdb_save_time_start = time(NULL); server.rdb_child_pid = childpid; server.rdb_child_type = RDB_CHILD_TYPE_DISK; updateDictResizePolicy(); return C_OK; } return C_OK; /* unreached */ } |
rdbSaveBackground 函数中最主要的工作就是调用 fork 命令生成子流程,然后在子流程中执行 rdbSave函数,也就是 save 指令最终会触发的函数。
为什么 Redis 使用子进程而不是线程来进行后台 RDB 持久化呢?主要是出于Redis性能的考虑,我们知道Redis对客户端响应请求的工作模型是单进程和单线程的,如果在主进程内启动一个线程,这样会造成对数据的竞争条件。所以为了避免使用锁降低性能,Redis选择启动新的子进程,独立拥有一份父进程的内存拷贝,以此为基础执行RDB持久化。
但是需要注意的是,fork 会消耗一定时间,并且父子进程所占据的内存是相同的,当 Redis 键值较大时,fork 的时间会很长,这段时间内 Redis 是无法响应其他命令的。除此之外,Redis 占据的内存空间会翻倍
Redis 的 rdbSave 函数是真正进行 RDB 持久化的函数,它的大致流程如下:
首先打开一个临时文件
1)调用 rdbSaveRio函数,将当前 Redis 的内存信息写入到这个临时文件中,
2)接着调用 fflush、fsync 和 fclose 接口将文件写入磁盘中,
3)使用 rename 将临时文件改名为 正式的 RDB 文件,
4)最后记录 dirty 和 lastsave等状态信息。这些状态信息在 serverCron时会使用到。
| int rdbSave(char *filename, rdbSaveInfo *rsi) { char tmpfile[256]; // 当前工作目录 char cwd[MAXPATHLEN]; FILE *fp; rio rdb; int error = 0; /* 生成tmpfile文件名 temp-[pid].rdb */ snprintf(tmpfile,256,"temp-%d.rdb", (int) getpid()); /* 打开文件 */ fp = fopen(tmpfile,"w"); ..... /* 初始化rio结构 */ rioInitWithFile(&rdb,fp); if (rdbSaveRio(&rdb,&error,RDB_SAVE_NONE,rsi) == C_ERR) { errno = error; goto werr; } if (fflush(fp) == EOF) goto werr; if (fsync(fileno(fp)) == -1) goto werr; if (fclose(fp) == EOF) goto werr; /* 重新命名 rdb 文件,把之前临时的名称修改为正式的 rdb 文件名称 */ if (rename(tmpfile,filename) == -1) { // 异常处理 .... } // 写入完成,打印日志 serverLog(LL_NOTICE,"DB saved on disk"); // 清理数据保存记录 server.dirty = 0; // 最后一次完成 SAVE 命令的时间 server.lastsave = time(NULL); // 最后一次 bgsave 的状态置位 成功 server.lastbgsave_status = C_OK; return C_OK; .... } |
fflush函数用于 FILE* 指针上,将缓存数据从应用层缓存刷新到内核中,而fsync 函数则更加底层,作用于文件描述符,用于将内核缓存刷新到物理设备上
rdbSaveRio 会将 Redis 内存中的数据以相对紧凑的格式写入到文件中,其文件格式的示意图如下所示

rdbSaveRio函数的写入大致流程如下:
1)先写入 REDIS 魔法值,然后是 RDB 文件的版本( rdb_version ),额外辅助信息 ( aux )。辅助信息中包含了 Redis 的版本,内存占用和复制库( repl-id )和偏移量( repl-offset )等。
2)然后 rdbSaveRio 会遍历当前 Redis 的所有数据库,将数据库的信息依次写入。先写入 RDB_OPCODE_SELECTDB识别码和数据库编号,接着写入RDB_OPCODE_RESIZEDB识别码和数据库键值数量和待失效键值数量,最后会遍历所有的键值,依次写入。
3)在写入键值时,当该键值有失效时间时,会先写入RDB_OPCODE_EXPIRETIME_MS识别码和失效时间,然后写入键值类型的识别码,最后再写入键和值。
4)写完数据库信息后,还会把 Lua 相关的信息写入,最后再写入 RDB_OPCODE_EOF结束符识别码和校验值。
| int rdbSaveRio(rio *rdb, int *error, int flags, rdbSaveInfo *rsi) { dictIterator *di = NULL; dictEntry *de; char magic[10]; int j; uint64_t cksum; size_t processed = 0; if (server.rdb_checksum) rdb->update_cksum = rioGenericUpdateChecksum; snprintf(magic,sizeof(magic),"REDIS%04d",RDB_VERSION); if (rdbWriteRaw(rdb,magic,9) == -1) goto werr; if (rdbSaveInfoAuxFields(rdb,flags,rsi) == -1) goto werr; if (rdbSaveModulesAux(rdb, REDISMODULE_AUX_BEFORE_RDB) == -1) goto werr; for (j = 0; j < server.dbnum; j++) { redisDb *db = server.db+j; dict *d = db->dict; if (dictSize(d) == 0) continue; di = dictGetSafeIterator(d); /* Write the SELECT DB opcode */ if (rdbSaveType(rdb,RDB_OPCODE_SELECTDB) == -1) goto werr; if (rdbSaveLen(rdb,j) == -1) goto werr; /* Write the RESIZE DB opcode. We trim the size to UINT32_MAX, which * is currently the largest type we are able to represent in RDB sizes. * However this does not limit the actual size of the DB to load since * these sizes are just hints to resize the hash tables. */ uint64_t db_size, expires_size; db_size = dictSize(db->dict); expires_size = dictSize(db->expires); if (rdbSaveType(rdb,RDB_OPCODE_RESIZEDB) == -1) goto werr; if (rdbSaveLen(rdb,db_size) == -1) goto werr; if (rdbSaveLen(rdb,expires_size) == -1) goto werr; /* Iterate this DB writing every entry */ while((de = dictNext(di)) != NULL) { sds keystr = dictGetKey(de); robj key, *o = dictGetVal(de); long long expire; initStaticStringObject(key,keystr); expire = getExpire(db,&key); if (rdbSaveKeyValuePair(rdb,&key,o,expire) == -1) goto werr; /* When this RDB is produced as part of an AOF rewrite, move * accumulated diff from parent to child while rewriting in * order to have a smaller final write. */ if (flags & RDB_SAVE_AOF_PREAMBLE && rdb->processed_bytes > processed+AOF_READ_DIFF_INTERVAL_BYTES) { processed = rdb->processed_bytes; aofReadDiffFromParent(); } } dictReleaseIterator(di); di = NULL; /* So that we don't release it again on error. */ } /* If we are storing the replication information on disk, persist * the script cache as well: on successful PSYNC after a restart, we need * to be able to process any EVALSHA inside the replication backlog the * master will send us. */ if (rsi && dictSize(server.lua_scripts)) { di = dictGetIterator(server.lua_scripts); while((de = dictNext(di)) != NULL) { robj *body = dictGetVal(de); if (rdbSaveAuxField(rdb,"lua",3,body->ptr,sdslen(body->ptr)) == -1) goto werr; } dictReleaseIterator(di); di = NULL; /* So that we don't release it again on error. */ } if (rdbSaveModulesAux(rdb, REDISMODULE_AUX_AFTER_RDB) == -1) goto werr; /* EOF opcode */ if (rdbSaveType(rdb,RDB_OPCODE_EOF) == -1) goto werr; /* CRC64 checksum. It will be zero if checksum computation is disabled, the * loading code skips the check in this case. */ cksum = rdb->cksum; memrev64ifbe(&cksum); if (rioWrite(rdb,&cksum,8) == 0) goto werr; return C_OK; werr: if (error) *error = errno; if (di) dictReleaseIterator(di); return C_ERR; } |
rdbSaveRio在写键值时,会调用rdbSaveKeyValuePair 函数。该函数会依次写入键值的过期时间,键的类型,键和值。
| int rdbSaveKeyValuePair(rio *rdb, robj *key, robj *val, long long expiretime) { int savelru = server.maxmemory_policy & MAXMEMORY_FLAG_LRU; int savelfu = server.maxmemory_policy & MAXMEMORY_FLAG_LFU; /* Save the expire time */ if (expiretime != -1) { if (rdbSaveType(rdb,RDB_OPCODE_EXPIRETIME_MS) == -1) return -1; if (rdbSaveMillisecondTime(rdb,expiretime) == -1) return -1; } /* Save the LRU info. */ if (savelru) { uint64_t idletime = estimateObjectIdleTime(val); idletime /= 1000; /* Using seconds is enough and requires less space.*/ if (rdbSaveType(rdb,RDB_OPCODE_IDLE) == -1) return -1; if (rdbSaveLen(rdb,idletime) == -1) return -1; } /* Save the LFU info. */ if (savelfu) { uint8_t buf[1]; buf[0] = LFUDecrAndReturn(val); /* We can encode this in exactly two bytes: the opcode and an 8 * bit counter, since the frequency is logarithmic with a 0-255 range. * Note that we do not store the halving time because to reset it * a single time when loading does not affect the frequency much. */ if (rdbSaveType(rdb,RDB_OPCODE_FREQ) == -1) return -1; if (rdbWriteRaw(rdb,buf,1) == -1) return -1; } /* Save type, key, value */ if (rdbSaveObjectType(rdb,val) == -1) return -1; if (rdbSaveStringObject(rdb,key) == -1) return -1; if (rdbSaveObject(rdb,val,key) == -1) return -1; return 1; } |
根据键的不同类型写入不同格式,各种键值的类型和格式如下所示

7.3.2 bgsave处理流程
| void bgsaveCommand(client *c) { int schedule = 0; /* The SCHEDULE option changes the behavior of BGSAVE when an AOF rewrite * is in progress. Instead of returning an error a BGSAVE gets scheduled. */ if (c->argc > 1) { if (c->argc == 2 && !strcasecmp(c->argv[1]->ptr,"schedule")) { schedule = 1; } else { addReply(c,shared.syntaxerr); return; } } rdbSaveInfo rsi, *rsiptr; rsiptr = rdbPopulateSaveInfo(&rsi); if (server.rdb_child_pid != -1) { addReplyError(c,"Background save already in progress"); } else if (server.aof_child_pid != -1) { if (schedule) { server.rdb_bgsave_scheduled = 1; addReplyStatus(c,"Background saving scheduled"); } else { addReplyError(c, "An AOF log rewriting in progress: can't BGSAVE right now. " "Use BGSAVE SCHEDULE in order to schedule a BGSAVE whenever " "possible."); } } else if (rdbSaveBackground(server.rdb_filename,rsiptr) == C_OK) { addReplyStatus(c,"Background saving started"); } else { addReply(c,shared.err); } } |
7.3.3 savecommand处理流程
略
7.4 RDB load
RDB文件的载入工作是在服务器启动时自动执行的,并没有专门的命令。但是由于AOF的优先级更高,因此当AOF开启时,Redis会优先载入AOF文件来恢复数据;只有当AOF关闭时,才会在Redis服务器启动时检测RDB文件,并自动载入。服务器载入RDB文件期间处于阻塞状态,直到载入完成为止。
Redis载入RDB文件时,会对RDB文件进行校验,如果文件损坏,则日志中会打印错误,Redis启动失败。
loadDataFromDisk --- > rdbLoad --- > rdbLoadRio --- > dbAdd
8 redis 主从同步
8.1 核心概念
1)建立主从命令slaveof
slaveof no one: 取消现有的主从关系,使slave变成master
slaveof host port:将当前实例变成指定节点的从节点。
2)主从命令slaveof实现(定时任务驱动)
通过定时任务和主节点建立连接并进行复制前逻辑
定时任务流程:
(1)任务发现存在新的主节点,建立连接
(2)发送ping
(3)鉴权 如果主节点有requirepass。那么从节点需要配置masterauth
(4)同步全量数据
(5)持续发送写命令到从节点
3)内部数据同步使用psync命令
psync命令响应:
+FULLRESYNC:全量复制
+CONTINUE 部分复制
+ERR 版本太低
4)全量同步
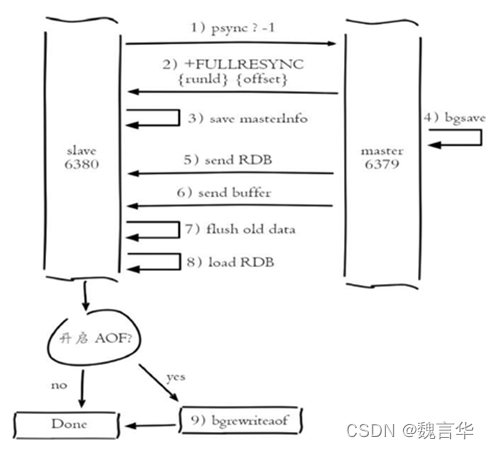
5)部分复制
通过offset 以及 运行id来实现部分复制,如果主节点的复制积压缓冲区(back_log)存在数据的话。直接返回给从节点可进行部分复制。 这里说一下部分复制依赖的是slave的offset,以及主节点的back_log。主节点的back_log是一个1M大小的环形链表。主节点每次处理命令的时候都会将命令写入back_log。
8.2 同步原理
Redis的slave通过server.repl_state状态来区分当前的复制状态。整个复制流程就是状态转变的过程。
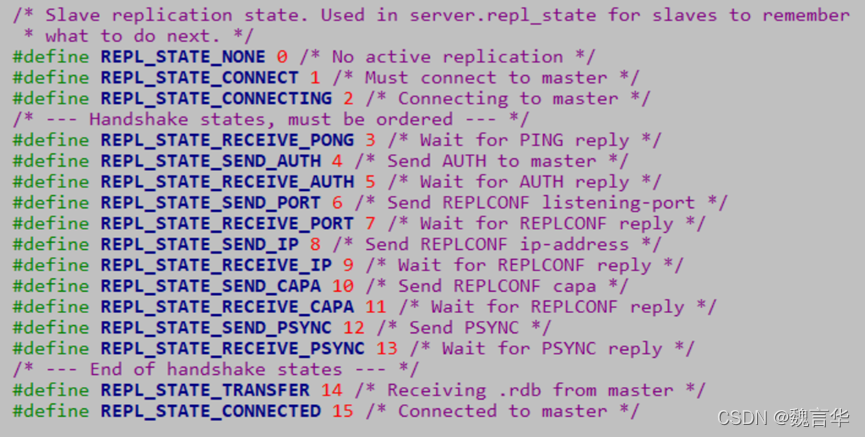
Redis的master通过对应slave客户端的replstate来记录当前客户端的状态
8.2.1 slave处理流程
slaveof host port 设置节点的master,其command的定义和处理如下:
{"slaveof",replicaofCommand,3,"ast",0,NULL,0,0,0,0,0},
{"replicaof",replicaofCommand,3,"ast",0,NULL,0,0,0,0,0},
replicaofCommand --- > replicationSetMaster
| void replicationSetMaster(char *ip, int port) { int was_master = server.masterhost == NULL; sdsfree(server.masterhost); server.masterhost = sdsnew(ip); server.masterport = port; if (server.master) { freeClient(server.master); } disconnectAllBlockedClients(); /* Clients blocked in master, now slave. */ /* Force our slaves to resync with us as well. They may hopefully be able * to partially resync with us, but we can notify the replid change. */ disconnectSlaves(); cancelReplicationHandshake(); /* Before destroying our master state, create a cached master using * our own parameters, to later PSYNC with the new master. */ if (was_master) { replicationDiscardCachedMaster(); replicationCacheMasterUsingMyself(); } server.repl_state = REPL_STATE_CONNECT; } |
这个方法主要是指定新master之前的清理工作
1.清除原有的主服务器信息
2.断开所有从服务器连接,强制所有从服务器执行重同步。因为redis支持树状复制。
3.清空master缓冲区,以及backlog缓冲区。以为暂时不会进行psync了。
4.取消之前的复制任务
5.将复制状态设置为REDIS_REPL_CONNECT(连接状态)
replicationCron方法,这个方法为redis的复制函数,每1s执行一次。
5.向主节点发送ACK,并发送当前复制偏移量。
6.定时向所有从节点发送ping命令(并不是每次都执行,到达定时时间才会执行,repl_ping_slave_period控制)
7.断开超时的从服务器
| void replicationCron(void) { static long long replication_cron_loops = 0; /*1.和master建立连接过程超时*/ if (server.masterhost && (server.repl_state == REPL_STATE_CONNECTING || slaveIsInHandshakeState()) && (time(NULL)-server.repl_transfer_lastio) > server.repl_timeout) { serverLog(LL_WARNING,"Timeout connecting to the MASTER..."); cancelReplicationHandshake(); } /* 2.rdb文件传输超时*/ if (server.masterhost && server.repl_state == REPL_STATE_TRANSFER && (time(NULL)-server.repl_transfer_lastio) > server.repl_timeout) { serverLog(LL_WARNING,"Timeout receiving bulk data from MASTER... If the problem persists try to set the 'repl-timeout' parameter in redis.conf to a larger value."); cancelReplicationHandshake(); } /* 3.曾经成功建立连接,但是现在超时*/ if (server.masterhost && server.repl_state == REPL_STATE_CONNECTED && (time(NULL)-server.master->lastinteraction) > server.repl_timeout) { serverLog(LL_WARNING,"MASTER timeout: no data nor PING received..."); freeClient(server.master); } /* 4. 尝试跟master建立链接,成功后更新状态为REDIS_REPL_CONNECTING */ if (server.repl_state == REPL_STATE_CONNECT) { serverLog(LL_NOTICE,"Connecting to MASTER %s:%d", server.masterhost, server.masterport); if (connectWithMaster() == C_OK) { serverLog(LL_NOTICE,"MASTER <-> REPLICA sync started"); } } ………… } |
| int connectWithMaster(void) { int fd; fd = anetTcpNonBlockBestEffortBindConnect(NULL, server.masterhost,server.masterport,NET_FIRST_BIND_ADDR); if (fd == -1) { serverLog(LL_WARNING,"Unable to connect to MASTER: %s", strerror(errno)); return C_ERR; } if (aeCreateFileEvent(server.el,fd,AE_READABLE|AE_WRITABLE,syncWithMaster,NULL) == AE_ERR) { close(fd); serverLog(LL_WARNING,"Can't create readable event for SYNC"); return C_ERR; } server.repl_transfer_lastio = server.unixtime; server.repl_transfer_s = fd; server.repl_state = REPL_STATE_CONNECTING; return C_OK; } |
主服务器建立连接时,会注册syncWithMaster回调函数,用于同步主服务器的数据
1.发送ping探测,并设置server.repl_state = REPL_STATE_RECEIVE_PONG
| /* Send a PING to check the master is able to reply without errors. */ if (server.repl_state == REPL_STATE_CONNECTING) { serverLog(LL_NOTICE,"Non blocking connect for SYNC fired the event."); /* Delete the writable event so that the readable event remains * registered and we can wait for the PONG reply. */ aeDeleteFileEvent(server.el,fd,AE_WRITABLE); server.repl_state = REPL_STATE_RECEIVE_PONG; /* Send the PING, don't check for errors at all, we have the timeout * that will take care about this. */ err = sendSynchronousCommand(SYNC_CMD_WRITE,fd,"PING",NULL); if (err) goto write_error; return; } |
2.接收PONG,并设置server.repl_state = REPL_STATE_SEND_AUTH
| /* Receive the PONG command. */ if (server.repl_state == REPL_STATE_RECEIVE_PONG) { err = sendSynchronousCommand(SYNC_CMD_READ,fd,NULL); /* We accept only two replies as valid, a positive +PONG reply * (we just check for "+") or an authentication error. * Note that older versions of Redis replied with "operation not * permitted" instead of using a proper error code, so we test * both. */ if (err[0] != '+' && strncmp(err,"-NOAUTH",7) != 0 && strncmp(err,"-ERR operation not permitted",28) != 0) { serverLog(LL_WARNING,"Error reply to PING from master: '%s'",err); sdsfree(err); goto error; } else { serverLog(LL_NOTICE, "Master replied to PING, replication can continue..."); } sdsfree(err); server.repl_state = REPL_STATE_SEND_AUTH; } |
3.进行密码验证,如果没有设置密码则直接进入REPL_STATE_SEND_PORT状态
| /* AUTH with the master if required. */ if (server.repl_state == REPL_STATE_SEND_AUTH) { if (server.masterauth) { err = sendSynchronousCommand(SYNC_CMD_WRITE,fd,"AUTH",server.masterauth,NULL); if (err) goto write_error; server.repl_state = REPL_STATE_RECEIVE_AUTH; return; } else { server.repl_state = REPL_STATE_SEND_PORT; } } |
4. 发送同步端口,并设置server.repl_state = REPL_STATE_RECEIVE_PORT
| /* Set the slave port, so that Master's INFO command can list the * slave listening port correctly. */ if (server.repl_state == REPL_STATE_SEND_PORT) { sds port = sdsfromlonglong(server.slave_announce_port ? server.slave_announce_port : server.port); err = sendSynchronousCommand(SYNC_CMD_WRITE,fd,"REPLCONF", "listening-port",port, NULL); sdsfree(port); if (err) goto write_error; sdsfree(err); server.repl_state = REPL_STATE_RECEIVE_PORT; return; } |
5. 发送同步IP地址,并设置server.repl_state = REPL_STATE_SEND_CAPA;
| /* Receive REPLCONF listening-port reply. */ if (server.repl_state == REPL_STATE_RECEIVE_PORT) { err = sendSynchronousCommand(SYNC_CMD_READ,fd,NULL); /* Ignore the error if any, not all the Redis versions support * REPLCONF listening-port. */ if (err[0] == '-') { serverLog(LL_NOTICE,"(Non critical) Master does not understand " "REPLCONF listening-port: %s", err); } sdsfree(err); server.repl_state = REPL_STATE_SEND_IP; } /* Skip REPLCONF ip-address if there is no slave-announce-ip option set. */ if (server.repl_state == REPL_STATE_SEND_IP && server.slave_announce_ip == NULL) { server.repl_state = REPL_STATE_SEND_CAPA; } /* Set the slave ip, so that Master's INFO command can list the * slave IP address port correctly in case of port forwarding or NAT. */ if (server.repl_state == REPL_STATE_SEND_IP) { err = sendSynchronousCommand(SYNC_CMD_WRITE,fd,"REPLCONF", "ip-address",server.slave_announce_ip, NULL); if (err) goto write_error; sdsfree(err); server.repl_state = REPL_STATE_RECEIVE_IP; return; } /* Receive REPLCONF ip-address reply. */ if (server.repl_state == REPL_STATE_RECEIVE_IP) { err = sendSynchronousCommand(SYNC_CMD_READ,fd,NULL); /* Ignore the error if any, not all the Redis versions support * REPLCONF listening-port. */ if (err[0] == '-') { serverLog(LL_NOTICE,"(Non critical) Master does not understand " "REPLCONF ip-address: %s", err); } sdsfree(err); server.repl_state = REPL_STATE_SEND_CAPA; } |
6. 发送支持的同步标准,并设置server.repl_state = REPL_STATE_SEND_PSYNC
| if (server.repl_state == REPL_STATE_SEND_CAPA) { err = sendSynchronousCommand(SYNC_CMD_WRITE,fd,"REPLCONF", "capa","eof","capa","psync2",NULL); if (err) goto write_error; sdsfree(err); server.repl_state = REPL_STATE_RECEIVE_CAPA; return; } /* Receive CAPA reply. */ if (server.repl_state == REPL_STATE_RECEIVE_CAPA) { err = sendSynchronousCommand(SYNC_CMD_READ,fd,NULL); /* Ignore the error if any, not all the Redis versions support * REPLCONF capa. */ if (err[0] == '-') { serverLog(LL_NOTICE,"(Non critical) Master does not understand " "REPLCONF capa: %s", err); } sdsfree(err); server.repl_state = REPL_STATE_SEND_PSYNC; } |
7.发送全量同步请求,并设置server.repl_state = REPL_STATE_RECEIVE_PSYNC
| if (server.repl_state == REPL_STATE_SEND_PSYNC) { if (slaveTryPartialResynchronization(fd,0) == PSYNC_WRITE_ERROR) { err = sdsnew("Write error sending the PSYNC command."); goto write_error; } server.repl_state = REPL_STATE_RECEIVE_PSYNC; return; } |
slaveTryPartialResynchronization 判断执行增量复制还是全量复制,如果当前节点的cached_master存在,则给主节点发送PSYNC <master_run_id> <repl_offset> 命令。否则发送PSYNC ? -1 主节点会根据当前的run_id和back_lag数据判断是否可以进行增量同步。如果不可以则进行全量同步。
| int slaveTryPartialResynchronization(int fd, int read_reply) { char *psync_replid; char psync_offset[32]; sds reply; /* Writing half */ if (!read_reply) { /* Initially set master_initial_offset to -1 to mark the current * master run_id and offset as not valid. Later if we'll be able to do * a FULL resync using the PSYNC command we'll set the offset at the * right value, so that this information will be propagated to the * client structure representing the master into server.master. */ server.master_initial_offset = -1; if (server.cached_master) { psync_replid = server.cached_master->replid; snprintf(psync_offset,sizeof(psync_offset),"%lld", server.cached_master->reploff+1); serverLog(LL_NOTICE,"Trying a partial resynchronization (request %s:%s).", psync_replid, psync_offset); } else { serverLog(LL_NOTICE,"Partial resynchronization not possible (no cached master)"); psync_replid = "?"; memcpy(psync_offset,"-1",3); } /* Issue the PSYNC command */ reply = sendSynchronousCommand(SYNC_CMD_WRITE,fd,"PSYNC",psync_replid,psync_offset,NULL); if (reply != NULL) { serverLog(LL_WARNING,"Unable to send PSYNC to master: %s",reply); sdsfree(reply); aeDeleteFileEvent(server.el,fd,AE_READABLE); return PSYNC_WRITE_ERROR; } return PSYNC_WAIT_REPLY; } 。。。。。。。。。。 } |
8. 等待master返回
| psync_result = slaveTryPartialResynchronization(fd,1); if (psync_result == PSYNC_WAIT_REPLY) return; /* Try again later... */ /* If the master is in an transient error, we should try to PSYNC * from scratch later, so go to the error path. This happens when * the server is loading the dataset or is not connected with its * master and so forth. */ if (psync_result == PSYNC_TRY_LATER) goto error; /* Note: if PSYNC does not return WAIT_REPLY, it will take care of * uninstalling the read handler from the file descriptor. */ if (psync_result == PSYNC_CONTINUE) { serverLog(LL_NOTICE, "MASTER <-> REPLICA sync: Master accepted a Partial Resynchronization."); return; } 。。。。。。。。 /* 布置psync,则使用sync进行同步 */ if (psync_result == PSYNC_NOT_SUPPORTED) { serverLog(LL_NOTICE,"Retrying with SYNC..."); if (syncWrite(fd,"SYNC\r\n",6,server.repl_syncio_timeout*1000) == -1) { serverLog(LL_WARNING,"I/O error writing to MASTER: %s", strerror(errno)); goto error; } } |
slaveTryPartialResynchronization 根据master的状态返回下面6中状态:
#define PSYNC_WRITE_ERROR 0
#define PSYNC_WAIT_REPLY 1
#define PSYNC_CONTINUE 2
#define PSYNC_FULLRESYNC 3
#define PSYNC_NOT_SUPPORTED 4
#define PSYNC_TRY_LATER 5
如果是+CONTINUE,则调用replicationResurrectCachedMaster方法,将当前server的master恢复。并更新repl_state为REDIS_REPL_CONNECTED,然后注册当前fd的读写回调。
| void replicationResurrectCachedMaster(int newfd) { server.master = server.cached_master; server.cached_master = NULL; server.master->fd = newfd; server.master->flags &= ~(CLIENT_CLOSE_AFTER_REPLY|CLIENT_CLOSE_ASAP); server.master->authenticated = 1; server.master->lastinteraction = server.unixtime; server.repl_state = REPL_STATE_CONNECTED; server.repl_down_since = 0; /* Re-add to the list of clients. */ linkClient(server.master); if (aeCreateFileEvent(server.el, newfd, AE_READABLE, readQueryFromClient, server.master)) { serverLog(LL_WARNING,"Error resurrecting the cached master, impossible to add the readable handler: %s", strerror(errno)); freeClientAsync(server.master); /* Close ASAP. */ } /* We may also need to install the write handler as well if there is * pending data in the write buffers. */ if (clientHasPendingReplies(server.master)) { if (aeCreateFileEvent(server.el, newfd, AE_WRITABLE, sendReplyToClient, server.master)) { serverLog(LL_WARNING,"Error resurrecting the cached master, impossible to add the writable handler: %s", strerror(errno)); freeClientAsync(server.master); /* Close ASAP. */ } } } |
如果是+FULLRESYNC,则说明要增量同步。这里会更新当前节点的run_id和offset。
通过readSyncBulkPayload异步接受rdb文件,读取流程:
1.读取数据头部
2.分片读取数据体
3.持久化到本地
4.清空本地数据库
5.load rdb文件
8.2.2 master同步流程
{"sync",syncCommand,1,"ars",0,NULL,0,0,0,0,0},
{"psync",syncCommand,3,"ars",0,NULL,0,0,0,0,0},
syncCommand首先执行masterTryPartialResynchronization方法。判断是否可执行增量同步。如果成功则表示能进行增量同步,直接返回。否则进行全同步。
masterTryPartialResynchronization方法
这个方法流程如下:
1.校验发来的runID,如果不一致,执行全量同步。
2.没有back_log或者offset不在back_log中,执行全量同步
| int masterTryPartialResynchronization(client *c) { long long psync_offset, psync_len; char *master_replid = c->argv[1]->ptr; char buf[128]; int buflen; if (getLongLongFromObjectOrReply(c,c->argv[2],&psync_offset,NULL) != C_OK) goto need_full_resync; if (strcasecmp(master_replid, server.replid) && (strcasecmp(master_replid, server.replid2) || psync_offset > server.second_replid_offset)) { /* Run id "?" is used by slaves that want to force a full resync. */ if (master_replid[0] != '?') { if (strcasecmp(master_replid, server.replid) && strcasecmp(master_replid, server.replid2)) { serverLog(LL_NOTICE,"Partial resynchronization not accepted: " "Replication ID mismatch (Replica asked for '%s', my " "replication IDs are '%s' and '%s')", master_replid, server.replid, server.replid2); } else { serverLog(LL_NOTICE,"Partial resynchronization not accepted: " "Requested offset for second ID was %lld, but I can reply " "up to %lld", psync_offset, server.second_replid_offset); } } else { serverLog(LL_NOTICE,"Full resync requested by replica %s", replicationGetSlaveName(c)); } goto need_full_resync; } /* We still have the data our slave is asking for? */ if (!server.repl_backlog || psync_offset < server.repl_backlog_off || psync_offset > (server.repl_backlog_off + server.repl_backlog_histlen)) { serverLog(LL_NOTICE, "Unable to partial resync with replica %s for lack of backlog (Replica request was: %lld).", replicationGetSlaveName(c), psync_offset); if (psync_offset > server.master_repl_offset) { serverLog(LL_WARNING, "Warning: replica %s tried to PSYNC with an offset that is greater than the master replication offset.", replicationGetSlaveName(c)); } goto need_full_resync; } /* If we reached this point, we are able to perform a partial resync: * 1) Set client state to make it a slave. * 2) Inform the client we can continue with +CONTINUE * 3) Send the backlog data (from the offset to the end) to the slave. */ c->flags |= CLIENT_SLAVE; c->replstate = SLAVE_STATE_ONLINE; c->repl_ack_time = server.unixtime; c->repl_put_online_on_ack = 0; listAddNodeTail(server.slaves,c); /* We can't use the connection buffers since they are used to accumulate * new commands at this stage. But we are sure the socket send buffer is * empty so this write will never fail actually. */ if (c->slave_capa & SLAVE_CAPA_PSYNC2) { buflen = snprintf(buf,sizeof(buf),"+CONTINUE %s\r\n", server.replid); } else { buflen = snprintf(buf,sizeof(buf),"+CONTINUE\r\n"); } if (write(c->fd,buf,buflen) != buflen) { freeClientAsync(c); return C_OK; } psync_len = addReplyReplicationBacklog(c,psync_offset); serverLog(LL_NOTICE, "Partial resynchronization request from %s accepted. Sending %lld bytes of backlog starting from offset %lld.", replicationGetSlaveName(c), psync_len, psync_offset); /* Note that we don't need to set the selected DB at server.slaveseldb * to -1 to force the master to emit SELECT, since the slave already * has this state from the previous connection with the master. */ refreshGoodSlavesCount(); return C_OK; /* The caller can return, no full resync needed. */ need_full_resync: return C_ERR; } |
如果两点都满足,执行增量同步,返回客户端+CONTINUE。并调用addReplyReplicationBacklog将back_log中客户端需要的命令发送给客户端。
否则进行全量同步,先给客户端同步写+FULLRESYNC,runid ;以及当前复制偏移量。这个偏移量会后面会作为客户端复制偏移量
1.首先判断当前是否有bgsave在执行。如果有跳转到2,否则3
2.判断当前bgsave是否是客户端复制触发的。也就是判断是否有slave的标志为REDIS_REPL_WAIT_BGSAVE_END,如果有说明可以复用这个bgsave产生的rdb文件。那么我们直接拷贝这个客户端的缓冲区。
3.如果没有bgsave,调用rdbSaveBackground触发bgsave执行。也就是fork当前父进程。生成内存快照。这个对copy_on_write熟悉的应该清楚,只会copy内存页表,只有在主服务器处理写命令的时候,才会有内存拷贝。
4.将当前slave加入到server.slaves
Rdb执行完毕后,当前进程会发送一个信号给父进程。父进程在serverCron()->backgroundSaveDoneHandler()方法处理这个逻辑,更新当前slave的复制数据以及状态 注册写事件处理器。 sendBulkToSlave这个方法主要就是将rdb文件发送给客户端。
| void sendBulkToSlave(aeEventLoop *el, int fd, void *privdata, int mask) { client *slave = privdata; UNUSED(el); UNUSED(mask); char buf[PROTO_IOBUF_LEN]; ssize_t nwritten, buflen; /* Before sending the RDB file, we send the preamble as configured by the * replication process. Currently the preamble is just the bulk count of * the file in the form "$<length>\r\n". */ if (slave->replpreamble) { nwritten = write(fd,slave->replpreamble,sdslen(slave->replpreamble)); if (nwritten == -1) { serverLog(LL_VERBOSE,"Write error sending RDB preamble to replica: %s", strerror(errno)); freeClient(slave); return; } server.stat_net_output_bytes += nwritten; sdsrange(slave->replpreamble,nwritten,-1); if (sdslen(slave->replpreamble) == 0) { sdsfree(slave->replpreamble); slave->replpreamble = NULL; /* fall through sending data. */ } else { return; } } /* If the preamble was already transferred, send the RDB bulk data. */ lseek(slave->repldbfd,slave->repldboff,SEEK_SET); buflen = read(slave->repldbfd,buf,PROTO_IOBUF_LEN); if (buflen <= 0) { serverLog(LL_WARNING,"Read error sending DB to replica: %s", (buflen == 0) ? "premature EOF" : strerror(errno)); freeClient(slave); return; } if ((nwritten = write(fd,buf,buflen)) == -1) { if (errno != EAGAIN) { serverLog(LL_WARNING,"Write error sending DB to replica: %s", strerror(errno)); freeClient(slave); } return; } slave->repldboff += nwritten; server.stat_net_output_bytes += nwritten; if (slave->repldboff == slave->repldbsize) { close(slave->repldbfd); slave->repldbfd = -1; aeDeleteFileEvent(server.el,slave->fd,AE_WRITABLE); putSlaveOnline(slave); } } |
Rdb文件发送完成后,putSlaveOnline函数然后重新注册一个写事件回调。将缓冲区的数据返回给客户端。这些数据主要是客户端执行全复制过程中积压的命令。
| void putSlaveOnline(client *slave) { slave->replstate = SLAVE_STATE_ONLINE; slave->repl_put_online_on_ack = 0; slave->repl_ack_time = server.unixtime; /* Prevent false timeout. */ if (aeCreateFileEvent(server.el, slave->fd, AE_WRITABLE, sendReplyToClient, slave) == AE_ERR) { serverLog(LL_WARNING,"Unable to register writable event for replica bulk transfer: %s", strerror(errno)); freeClient(slave); return; } refreshGoodSlavesCount(); serverLog(LL_NOTICE,"Synchronization with replica %s succeeded", replicationGetSlaveName(slave)); } |
replicationCron--- > replicationFeedSlaves 把积压缓冲中的数据发给slave
到这里整个复制流程就结束了。
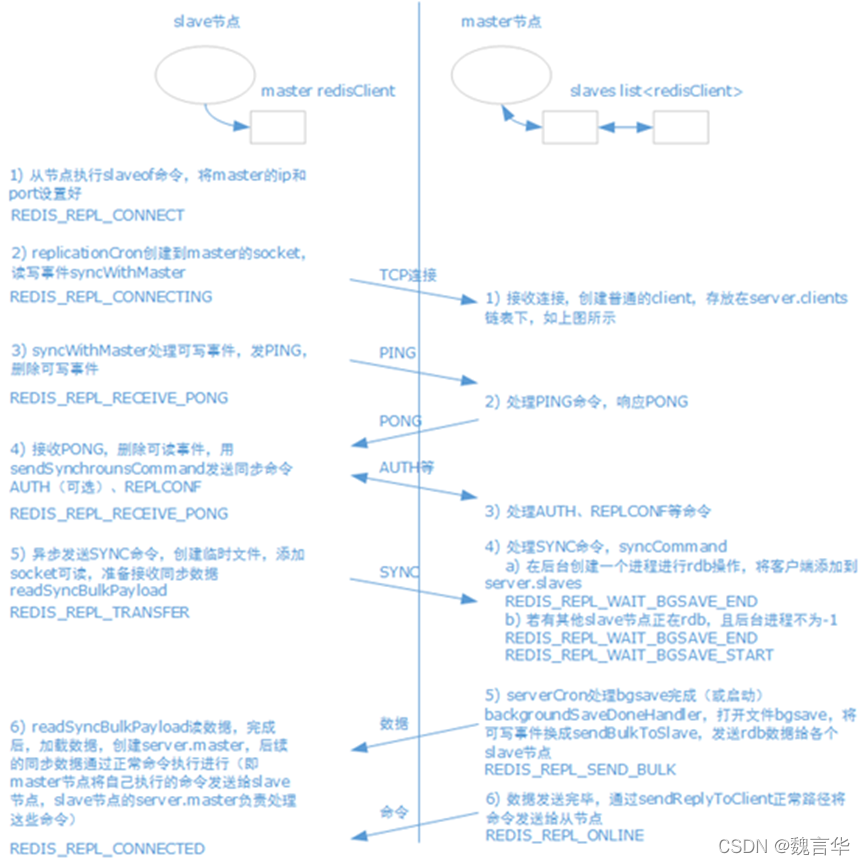
8.2.3 积压缓冲区实现
Redis中的积压队列server.repl_backlog,是一个固定大小的循环队列。所谓循环队列,举个简单的例子,假设server.repl_backlog的大小为10个字节,则向其中插入数据”abcdefg”之后,该积压队列的内容如下:

现在插入数据”hijklmn”,则积压队列的内容如下:
也就是说,插入数据时,一旦到达了积压队列的尾部,则重新从头部开始插入,覆盖最早插入的内容。

要理解积压队列,关键在于理解下面的,有关积压队列的属性:
server.master_repl_offset:一个全局性的计数器,当存在积压队列时,每次收到客户端发来的,长度为len的请求命令时,就会将server.master_repl_offset增加len。
该属性也就是所谓的主节点上的复制偏移量。当从节点发来PSYNC命令后,主节点回复从节点"+FULLRESYNC <runid> <offset>"消息时,其中的offset就是取的主节点当时的server.master_repl_offset的值。这样当从节点收到该消息后,将该值保存在复制偏移量server.master->reploff中。
进入命令传播阶段后,每当主节点收到客户端的命令请求,则将命令的长度增加到server.master_repl_offset上,然后将命令传播给从节点,从节点收到后,也会将命令长度加到server.master->reploff上,从而保证了主节点上的复制偏移量server.master_repl_offset和从节点上的复制偏移量server.master->reploff的一致性。
需要注意的,server.master_repl_offset的值并不是严格的从0开始增加的。它只是一个计数器,只要能保证主从节点上的复制偏移量一致即可。比如如果它的初始值为10,发送给从节点后,从节点保存的复制偏移量初始值也为10,当新的命令来临时,主从节点上的复制偏移量都会相应增加该命令的长度,因此这并不影响主从节点上偏移量的一致性。
server.repl_backlog_size:积压队列server.repl_backlog的总容量。
server.repl_backlog_idx:在积压队列server.repl_backlog中,每次写入新数据时的起始索引,是一个相对于server.repl_backlog的索引。当server.repl_backlog_idx 等于server.repl_backlog的长度server.repl_backlog_size时,置其值为0,表示从头开始。
以上面那个积压队列为例,server.repl_backlog_idx的初始值为0,插入”abcdefg”之后,该值变为7;插入”hijklmn”之后,该值变为4。
server.repl_backlog_histlen:积压队列server.repl_backlog中,当前累积的数据量的大小。该值不会超过积压队列的总容量server.repl_backlog_size。
server.repl_backlog_off:在积压队列中,最早保存的命令的首字节,在全局范围内(而非积压队列内)的偏移量。在累积命令流时,下列等式恒成立:
server.master_repl_offset - server.repl_backlog_off + 1 = server.repl_backlog_histlen。
还是以上面那个积压队列为例:如果在插入”abcdefg”之前,server.master_repl_offset的初始值为2,则插入”abcdefg”之后,积压队列中当前的数据量,也就是属性server.repl_backlog_histlen的值为7。属性server.master_repl_offset的值变为9,此时命令的首字节为”a”,它在全局的偏移量就是3。满足上面的等式。
在插入”hijklmn”之后,积压队列中当前的数据量,也就是属性server.repl_backlog_histlen的值为10。属性server.master_repl_offset的值变为16。此时最早保存的命令首字节为”e”,它在全局的偏移量是7,满足上面的等式。
根据上面的等式,主节点的积压队列中累积的命令流,首字节和尾字节在全局范围内的偏移量分别是server.repl_backlog_off和server.master_repl_offset。
当从节点断链重连后,向主节点发送”PSYNC <runid> <offset>”消息,其中的<offset>表示需要接收的下一条命令首字节的偏移量。也就是server.master->reploff + 1。
主节点判断<offset>的值,如果该值在下面的范围内,就表示可以进行部分重同步:
[server.repl_backlog_off, server.repl_backlog_off + server.repl_backlog_histlen]。如果<offset>的值为server.repl_backlog_off+ server.repl_backlog_histlen,也就是server.master_repl_offset + 1,说明从节点断链期间,主节点没有收到过新的命令请求。
8.3 同步常见问题
1)全量复制
repl-timeout为传输时间,如果rdb文件过大,可能会导致传输超时,导致同步失败。 全量复制过程中,主节点的写操作会被写入复制客户端的缓冲区。如果复制时间过久,会导致复制缓冲区溢出。
2)部分复制
这是redis对于断线的优化,但如果积压缓冲区没有对应数据,则会触发全量复制。我们应该尽量避免全量复制。 通过配置repl_backlog_size>net_break_time*write_size_per_minute避免全量复制,write_size_per_minute可以通过info replication的master_repl_offset 每秒差值确定。
3)异步复制带来的问题
从节点不会主动删除过期数据。所以读取从节点可能会导致读取到过期的数据。 升级到3.2版本以上可以避免该问题。 主从尽量保证内存方面的配置一致。
9 redis底层数据结构
Redis 是一个基于内存中的数据结构存储系统,可以用作数据库、缓存和消息中间件。Redis 支持五种常见对象类型:字符串(String)、哈希(Hash)、列表(List)、集合(Set)以及有序集合(Zset),我们在日常工作中也会经常使用它们。知其然,更要知其所以然,本文将会带你读懂这五种常见对象类型的底层数据结构。
9.1对象类型和编码
Redis 使用对象来存储键和值的,在Redis中,每个对象都由 redisObject 结构表示。redisObject 结构主要包含三个属性:type、encoding 和 ptr
| typedef struct redisObject { unsigned type:4; unsigned encoding:4; unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or * LFU data (least significant 8 bits frequency * and most significant 16 bits access time). */ int refcount; void *ptr; } robj; |
其中 type 属性记录了对象的类型。对于 Redis 来说,键对象总是字符串类型,值对象可以是任意支持的类型。因此,当我们说 Redis 键采用哪种对象类型的时候,指的是对应的值采用哪种对象类型。
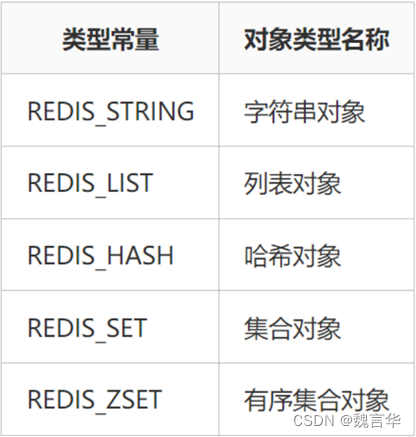
*ptr 属性指向了对象的底层数据结构,而这些数据结构由 encoding 属性决定
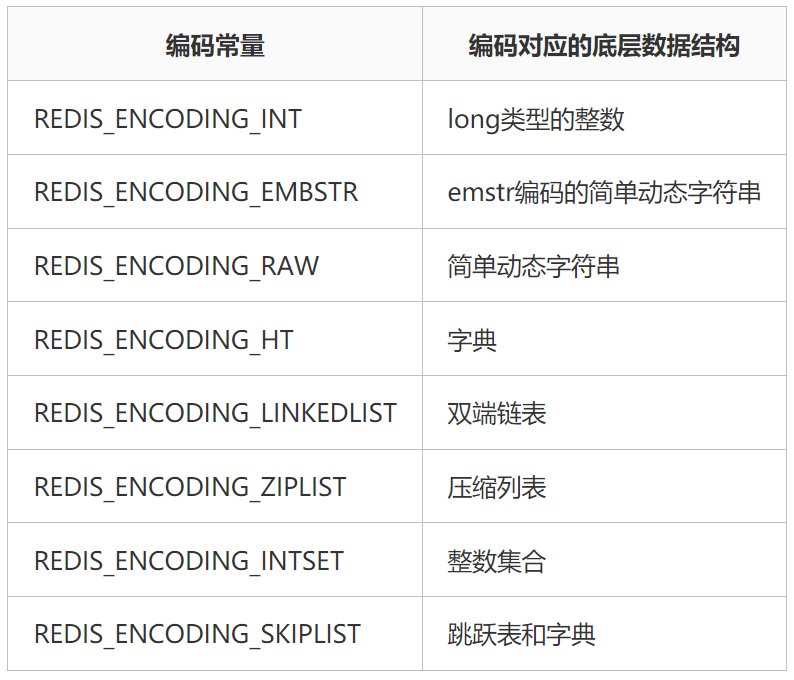
之所以由 encoding 属性来决定对象的底层数据结构,是为了实现同一对象类型,支持不同的底层实现。这样就能在不同场景下,使用不同的底层数据结构,进而极大提升Redis的灵活性和效率。
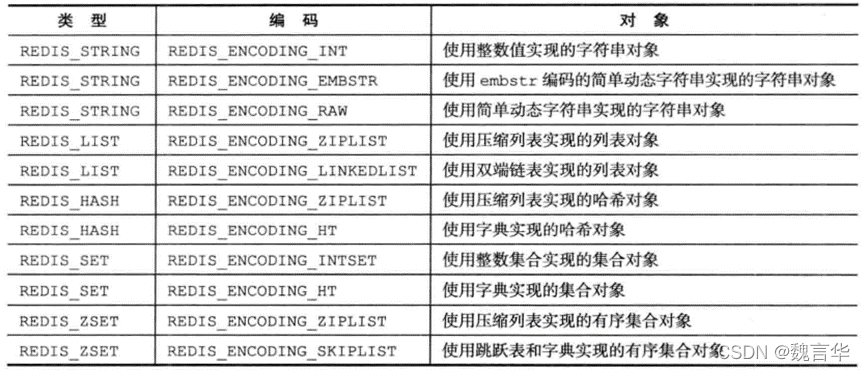
type + key 可以查看key对应的对象类型(字符串、列表、hash、集合、有序集合),通过object encodeing 命令可以查看key对应的值得编码(REIDS_ENCODING_INT、REDIS_ENCODING_RAW、REDIS_ENCODING_HT等共8中)
9.2 字符串对象
字符串是我们日常工作中用得最多的对象类型,它对应的编码可以是 REIDS_ENCODING_INT、REDIS_ENCODING_RAW、REDIS_ENCODING_EMBSTR。
如果一个字符串对象保存的是不超过 long 类型的整数值,此时编码类型即为 int,其底层数据结构直接就是 long 类型。例如执行 set number 10086,就会创建 int 编码的字符串对象作为 number 键的值。
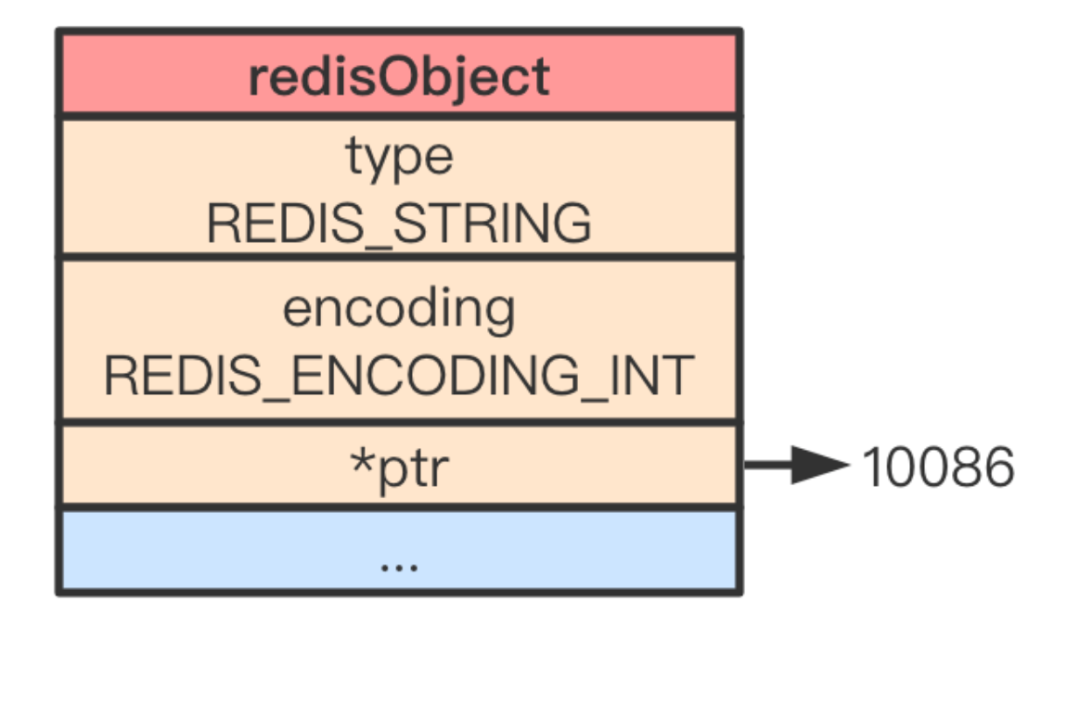
如果字符串对象保存的是一个长度大于 32 字节的字符串,此时编码类型即为 raw,其底层数据结构是简单动态字符串(SDS);
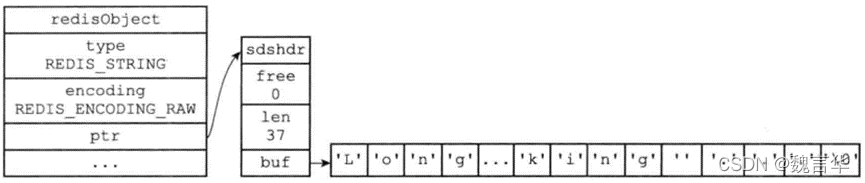
如果长度小于等于 32个字节,编码类型则为 embstr,底层数据结构就是 embstr 编码 SDS。

raw与embstr的优缺点对比:
- embstr编码是专门用于保存短字符串的方式,与raw一样都使用redisobject和sdshdr两个结构来表示字符串对象,但raw会调研两次内存分配来创建redisobject和sdshdr两个结构,而embstr则只用一次内存分配来创建两个结构。同样释放的时候也只用一次内存释放调用。
- 一次内存分配,分配到的内存是连续的,与raw相比能更好的利用CPU cache。
9.2.1 简单动态字符串SDS
SDS 遵循了 C 字符串以空字符结尾的惯例,保存空字符的 1 字节不会计算在 len 属性里面。例如,Redis 这个字符串在 SDS 里面的数据可能是如下形式
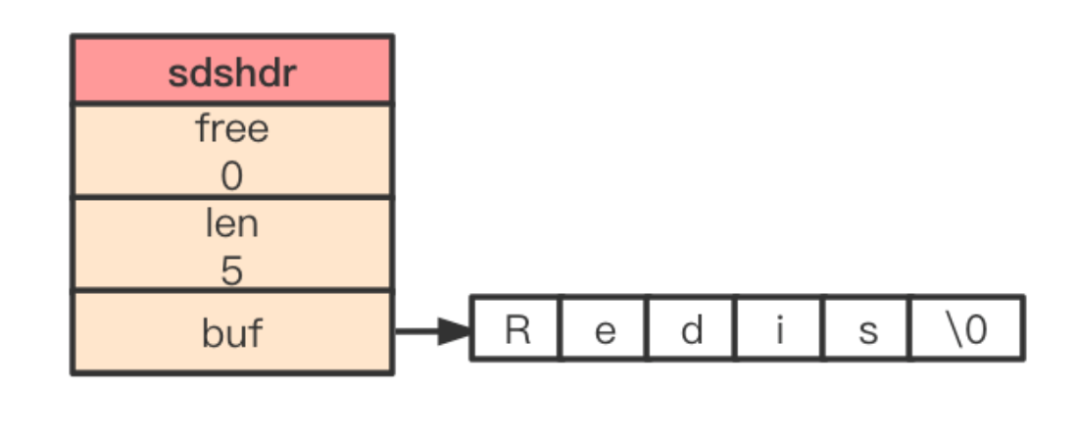
SDS 与 C 字符串的区别
C 语言使用长度为 N+1 的字符数组来表示长度为N的字符串,并且字符串的最后一个元素是空字符 0。Redis 采用 SDS 相对于 C 字符串有如下几个优势:
1) 常数复杂度获取字符串长度;
2) 杜绝缓冲区溢出;
3) 减少修改字符串时带来的内存重分配次数;
4) 二进制安全。
- 常数复杂度获取字符串长度
因为 C 字符串并不记录自身的长度信息,所以为了获取字符串的长度,必须遍历整个字符串,时间复杂度是 O(N)。而 SDS 使用 len 属性记录了字符串的长度,因此获取 SDS字符串长度的时间复杂度是 O(1)。
- 杜绝缓冲区溢出
C 字符串不记录自身长度带来的另一个问题是, 很容易造成缓存区溢出。比如使用字符串拼接函数(stract)的时候,很容易覆盖掉字符数组原有的数据。
与 C 字符串不同,SDS 的空间分配策略完全杜绝了发生缓存区溢出的可能性。当 SDS 进行字符串扩充时,首先会检查当前的字节数组的长度是否足够。如果不够的话,会先进行自动扩容,然后再进行字符串操作,减少修改字符串时带来的内存重分配次数
因为 C 字符串的长度和底层数据是紧密关联的,所以每次增长或者缩短一个字符串,程序都要对这个数组进行一次内存重分配:
如果是增长字符串操作,需要先通过内存重分配来扩展底层数组空间大小,不这么做就导致缓存区溢出;
如果是缩短字符串操作,需要先通过内存重分配来来回收不再使用的空间,不这么做就导致内存泄漏。
因为内存重分配涉及复杂的算法,并且可能需要执行系统调用,所以通常是个比较耗时的操作。对于 Redis 来说,字符串修改是一个十分频繁的操作。如果每次都像 C 字符串那样进行内存重分配,对性能影响太大了,显然是无法接受的。
SDS 通过空闲空间解除了字符串长度和底层数据之间的关联。在 SDS 中,数组中可以包含未使用的字节,这些字节数量由 free 属性记录。 通过空闲空间,SDS 实现了空间预分配。
3) 配和惰性空间释放两种优化策略。
3.1)空间预分配
空间预分配是用于优化 SDS 字符串增长操作的,简单来说就是当字节数组空间不足触发重分配的时候,总是会预留一部分空闲空间。这样的话,就能减少连续执行字符串增长操作时的内存重分配次数。
有两种预分配的策略:
len 小于 1MB 时:每次重分配时会多分配同样大小的空闲空间;
len 大于等于 1MB 时:每次重分配时会多分配 1MB 大小的空闲空间。
3.2)惰性空间释放
惰性空间释放是用于优化 SDS 字符串缩短操作的。简单来说就是当字符串缩短时,并不立即使用内存重分配来回收多出来的字节,而是用 free 属性记录,等待将来使用。SDS 也提供直接释放未使用空间的 API,在需要的时候,也能真正的释放掉多余的空间。
4)二进制安全
C 字符串中的字符必须符合某种编码,并且除了字符串末尾之外,其它位置不允许出现空字符。这些限制使得 C 字符串只能保存文本数据。
但是对于 Redis 来说,不仅仅需要保存文本,还要支持保存二进制数据。为了实现这一目标,SDS 的 API 全部做到了二进制安全(binary-safe)。
9.3 列表对象
列表对象的编码可以是 REDIS_ENCODING_LINKEDLIST和REIDS_ENCODING_ZIPLIST,对应的底层数据结构是链表和压缩列表。列表对象相关命令可参考:Redis 命令-List。
默认情况下,当列表对象保存的所有字符串元素的长度都小于 64 字节,且元素个数小于 512 个时,列表对象采用的是 REIDS_ENCODING_ZIPLIST编码,否则使用 REDIS_ENCODING_LINKEDLIST编码。可以通过list-max-ziplist-value和 list-mac-ziplist-entries选项来进行修改。
9.3.1 压缩列表
压缩列表(ziplist)是列表键和哈希键的底层实现之一。压缩列表主要目的是为了节约内存,是由一系列特殊编码的连续内存块组成的顺序型数据结构。一个压缩列表可以包含任意多个节点,每个节点可以保存一个字节数组或者一个整数值。

9.3.2 链表
链表是一种非常常见的数据结构,提供了高效的节点重排能力以及顺序性的节点访问方式。在 Redis 中,每个链表节点使用 listNode 结构表示:
| typedef struct listNode { struct listNode *prev; struct listNode *next; void *value; } listNode; |
多个 listNode 通过 prev 和 next 指针组成双端链表,如下图所示

| typedef struct list { listNode *head; listNode *tail; void *(*dup)(void *ptr); void (*free)(void *ptr); int (*match)(void *ptr, void *key); unsigned long len; } list; |
Redis 链表实现的特征总结如下:
| 1 | 双端 | 链表节点带有 prev 和 next 指针,获取某个节点的前置节点和后置节点的复杂度都是 O(n) |
| 2 | 无环 | 表头节点的 prev 指针和表尾节点的 next 指针都指向 NULL,对链表的访问以 NULL 为终点 |
| 3 | 表头指针和表尾指针 | 通过 list 结构的 head 指针和 tail 指针,程序获取链表的表头节点和表尾节点的复杂度为 O(1) |
| 4 | 长度计数器 | 程序使用 list 结构的 len 属性来对 list 持有的节点进行计数,程序获取链表中节点数量的复杂度为 O(1) |
| 5 | 多态 | 链表节点使用 void* 指针来保存节点值,可以保存各种不同类型的值 |
9.4 哈希对象
哈希对象的编码可以是 ziplist 或者 hashtable
9.4.1 压缩列表
ziplist 底层使用的是压缩列表实现,上文已经详细介绍了压缩列表的实现原理。每当有新的键值对要加入哈希对象时,先把保存了键的节点推入压缩列表表尾,然后再将保存了值的节点推入压缩列表表尾。比如,我们执行如下三条 HSET 命令:
HSETprofile name "tom" HSET profile age 25 HSET profile career "Programmer"
如果此时使用 ziplist 编码,那么该 Hash 对象在内存中的结构如下
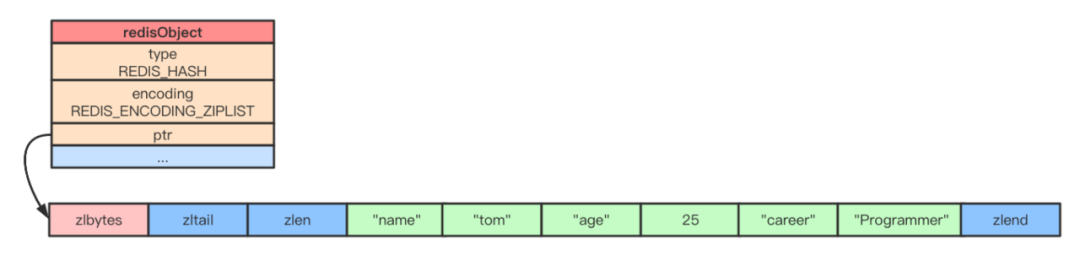
9.4.2 hashtable
Redis 使用的哈希表由 dictht 结构定义
| typedef struct dictht { dictEntry **table; unsigned long size; unsigned long sizemask; unsigned long used; } dictht; |
table 属性是一个数组,数组中的每个元素都是一个指向 dictEntry 结构的指针,每个 dictEntry 结构保存着一个键值对。
size 属性记录了哈希表的大小,即 table 数组的大小。used 属性记录了哈希表目前已有节点数量。sizemask 总是等于 size-1,这个值主要用于数组索引,比如下图展示了一个大小为 4 的空哈希表。
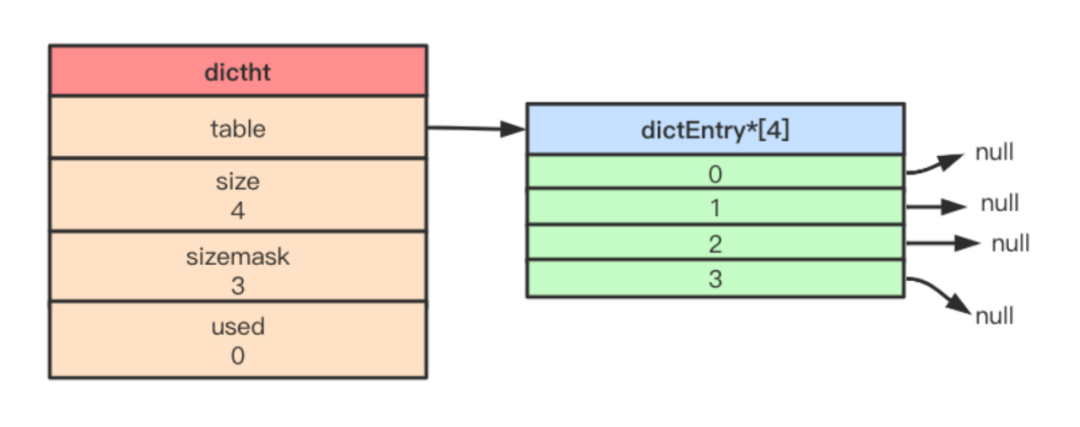
哈希表节点使用 dictEntry 结构表示,每个 dictEntry 结构都保存着一个键值对
| typedef struct dictEntry { void *key; union { void *val; uint64_t u64; int64_t s64; double d; } v; struct dictEntry *next; } dictEntry; |
key 属性保存着键值对中的键,而 v 属性则保存了键值对中的值。值可以是一个指针,一个 uint64_t 整数或者是 int64_t 整数。next 属性指向了另一个 dictEntry 节点,在数组桶位相同的情况下,将多个 dictEntry 节点串联成一个链表,以此来解决键冲突问题(链地址法)
Redis 字典由 dict 结构表示
| typedef struct dict { dictType *type; void *privdata; dictht ht[2]; long rehashidx; /* rehashing not in progress if rehashidx == -1 */ unsigned long iterators; /* number of iterators currently running */ } dict; |
ht 是大小为 2,且每个元素都指向 dictht 哈希表。一般情况下,字典只会使用 ht[0] 哈希表,ht[1] 哈希表只会在对 ht[0] 哈希表进行 rehash 时使用。rehashidx 记录了 rehash 的进度,如果目前没有进行 rehash,值为 -1。
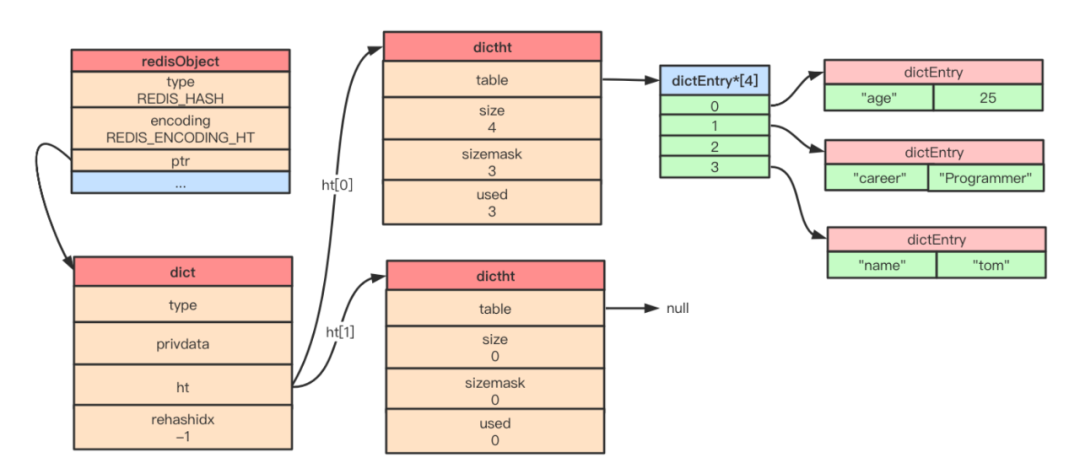
9.5 集合
集合对象的编码可以是 intset 或者 hashtable。当集合对象保存的元素都是整数,并且个数不超过 512 个时,使用 intset 编码,否则使用 hashtable 编码。
9.5.1 intset
整数集合(intset)是 Redis 用于保存整数值的集合抽象数据结构,它可以保存类型为 int16_t、int32_t 或者 int64_t 的整数值,并且保证集合中的数据不会重复。Redis 使用 intset 结构表示一个整数集合。
| typedef struct intset { uint32_t encoding; uint32_t length; int8_t contents[]; } intset; |
contents 数组是整数集合的底层实现:整数集合的每个元素都是 contents 数组的一个数组项,各个项在数组中按值大小从小到大有序排列,并且数组中不包含重复项。
虽然 contents 属性声明为 int8_t 类型的数组,但实际上,contents 数组不保存任何 int8_t 类型的值,数组中真正保存的值类型取决于 encoding。
#define INTSET_ENC_INT16 (sizeof(int16_t))
#define INTSET_ENC_INT32 (sizeof(int32_t))
#define INTSET_ENC_INT64 (sizeof(int64_t))
如果 encoding 属性值为 INTSET_ENC_INT16,那么 contents 数组就是 int16_t 类型的数组。当新插入元素的类型比整数集合现有类型元素的类型大时,整数集合必须先升级,然后才能将新元素添加进来。这个过程分以下三步进行:
1)根据新元素类型,扩展整数集合底层数组空间大小;
2)将底层数组现有所有元素都转换为与新元素相同的类型,并且维持底层数组的有序性;
3)将新元素添加到底层数组里面。
4)还有一点需要注意的是, 整数集合不支持降级。一旦对数组进行了升级,编码就会一直保持升级后的状态
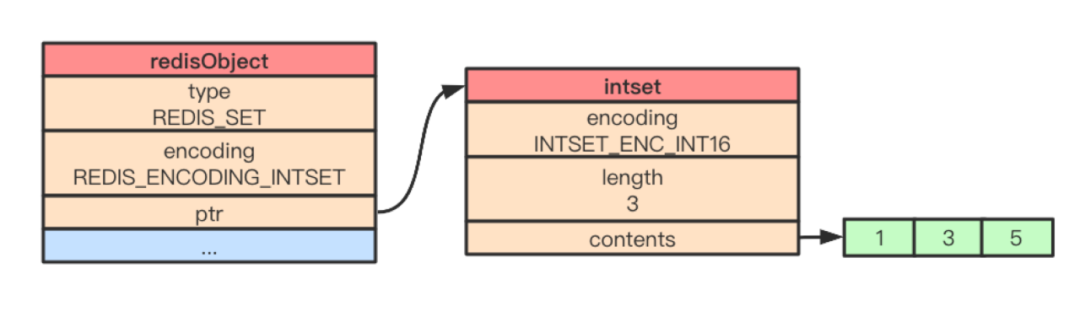
9.5.2 hashtable
hashtable 编码的集合对象使用字典作为底层实现。字典的每个键都是一个字符串对象,每个字符串对象对应一个集合元素,字典的值都是 NULL。
当我们执行 SADD fruits "apple" "banana" "cherry" 向集合对象插入数据时,该集合对象在内存的结构如下:
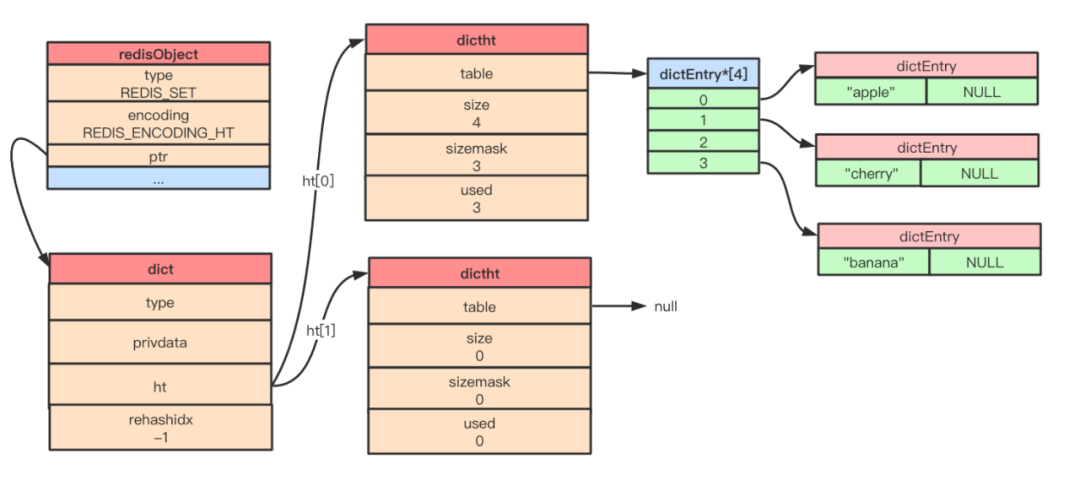
9.6 有序集合
有序集合的编码可以是 ziplist 或者 skiplist。当有序集合保存的元素个数小于 128 个,且所有元素成员长度都小于 64 字节时,使用 ziplist 编码,否则使用 skiplist 编码。
9.6.1 压缩列表
ziplist 编码的有序集合使用压缩列表作为底层实现。每个集合元素使用两个紧挨着一起的两个压缩列表节点表示,第一个节点保存元素的成员(member),第二个节点保存元素的分值(score)。
压缩列表内的集合元素按照分值从小到大排列。如果我们执行 ZADD price 8.5 apple 5.0 banana 6.0 cherry 命令向有序集合插入元素,该有序集合在内存中的结构如下:

9.6.2 跳跃表
10 sentinel 分析
10.1 sentinel概述
常见的 Redis sentinel 架构如下

主要由 sentinel 集群 和 Redis 数据服务器 组成,sentinel 集群对 所有 Redis 数据服务器进行监控,同时 sentinel 集群中 各个哨兵 服务器又相互监控,保证 哨兵监控集群的可用;不过一般 一个稳健的 Redis Sentinel 集群,应该使用至少 三个 Sentinel 实例,并且保证讲这些实例放到 不同的机器 上,甚至不同的 物理区域
Redis sentinel 哨兵的职责主要在于 主服务器存活检测、主从运行状态监控、自动故障转移、主从切换 等,针对 Redis 数据服务器 的功能主要有如下几点:
- 监控 不断定期检查 主从数据服务器 的存活状况以及运行状态
- 通知 如果 监控目标服务器出现问题,通过 API 向 管理员 或者 其他应用程序 发送通知
- 自动故障转移 如果主服务器 下线而不能正常工作的时候,sentinel 会开始执行自动故障转移 操作,从 下线主服务器 下属的 从服务器中 选举出一个作为 主服务器,并且将 其他 从服务器 指向 新的主服务器;不过 下线判断 也分情况,默认 sentinel 会对其监控的 其他 sentinel 节点 和 数据服务器节点 进行每秒一次的 PING 命令检测
- 主观下线 SDOWN 如果 监控的服务器节点 在 down-after-milliseconds 设置的毫秒时效内没有响应检测,则会被判定为 主观下线;这个状态适用所有服务器节点
- 客观下线 ODOWN 主服务器节点在发生故障的时候,sentinel 会通过 is-master-down-by-addr 命令向其他 sentinel 节点询问 该主服务器节点的状态,如果超过 quorum 个数的哨兵节点都认为 主服务器节点不可达,则判定为 客观下线;这个状态只会针对 主服务器节点
- 配置提供者 在 Redis Sentinel 结构中,客户端在初始化的时候连接的是Sentinel 节点集合,通过sentinel get-master-addr-by-name <masterName>从中获取主节点信息。
10.2 sentinel交互
- sentinel 节点 和 redis 数据节点 之间
- PING sentinel 向 redis 数据节点发送 PING 命令,检查其状态
- INFO sentinel 向 redis 数据节点的 主服务器节点发送 INFO 命令,获取 其他从服务器节点信息
- PUBLISH sentinel 向 redis 数据节点 __sentinel__:hello 频道 发布自己的信息及主服务器节点相关的配置
- SUBSCRIBE sentinel 通过订阅 redis 主从服务器节点 的 __sentinel__:hello 频道,获取正在监控相同服务的其他 sentinel 节点信息
- sentinel 节点 和 sentinel 节点 之间
- PING sentinel 向其他 sentinel节点 发送 PING 命令,检查节点状态
- is-master-down-by-addr 和其他 sentinel 协商 主服务器节点 的状态,如果 主服务器 处于 SDOWN 状态,则投票自动选出新的 主服务器节点
10.3 sentinel客户端
Sentinel节点集合具备了监控、通知、自动故障转移、配置提供者若干功能,也就是说实际上最了解主节点信息的就是Sentinel节点集合,而各个主节点可以通过<master-name>进行标识的,所以,无论是哪种编程语言的客户端,如果需要正确地连接Redis Sentinel,必须有Sentinel节点集合和masterName两个参数。
10.3.1 Redis Sentinel客户端基本实现原理
实现一个Redis Sentinel客户端的基本步骤如下:
1)遍历Sentinel节点集合获取一个可用的Sentinel节点,从任意一个Sentinel节点获取主节点信息都是可以的;
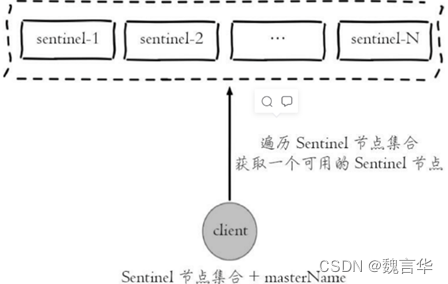
2)通过sentinel get-master-addr-by-name master-name这个API来获取对应主节点的相关信息;
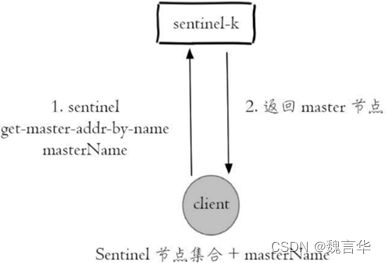
3)验证当前获取的“主节点”是真正的主节点,这样做的目的是为了防止故障转移期间主节点的变化;
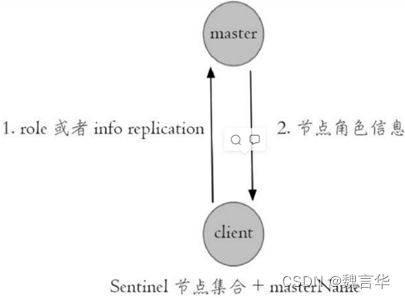
4)保持和Sentinel节点集合的“联系”,时刻获取关于主节点的相关“信息”。
客户端为每一个Sentinel节点单独启动一个线程, 利用Redis的发布订阅功能, 每个线程订阅Sentinel节点上切换master的相关频道+switch-master。
订阅Sentinel节点的+switch-master频道, 它就是Redis Sentinel在结束对主节点故障转移后会发布切换主节点的消息, Sentinel节点基本将故障转移的各个阶段发生的行为都通过这种发布订阅的形式对外提供, 开发者只需订阅感兴趣的频道即可。
当完成故障转移之后,客户端程序会在这个channel上接收新的主节点信息,从而连接新的主节点。
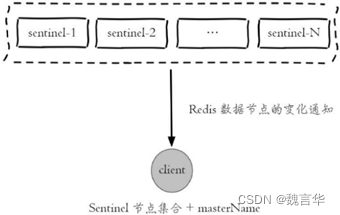
10.4 Redis Sentinel 的执行过程和初始化
Sentinel本质上是一个运行在特殊模式下的Redis服务器,无论如何,都是执行服务器的main来启动。主函数中关于Sentinel启动的代码如下:
| int main(int argc, char **argv) { // 1. 检查开启哨兵模式的两种方式 server.sentinel_mode = checkForSentinelMode(argc,argv); // 2. 如果已开启哨兵模式,初始化哨兵的配置 if (server.sentinel_mode) { initSentinelConfig(); initSentinel(); } // 3. 载入配置文件 loadServerConfig(configfile,options); // 开启哨兵模式,哨兵模式和集群模式只能开启一种 if (!server.sentinel_mode) { // 在不是哨兵模式下,会载入AOF文件和RDB文件,打印内存警告,集群模式载入数据等等操作。 } else { sentinelIsRunning(); } } |
10.4.1 检查是否开启哨兵模式
- redis-sentinel sentinel.conf
- redis-server sentinel.conf --sentinel
主函数中调用了checkForSentinelMode()函数来判断是否开启哨兵模式
| int checkForSentinelMode(int argc, char **argv) { int j; if (strstr(argv[0],"redis-sentinel") != NULL) return 1; for (j = 1; j < argc; j++) if (!strcmp(argv[j],"--sentinel")) return 1; return 0; } |
如果开启了哨兵模式,就会将server.sentinel_mode设置为1
10.4.2 初始化哨兵的配置
在主函数中调用了两个函数initSentinelConfig()和initSentinel(),前者用来初始化Sentinel节点的默认配置,后者用来初始化Sentinel节点的状态。
- initSentinelConfig(),初始化哨兵节点的默认端口为26379。
| // 设置Sentinel的默认端口,覆盖服务器的默认属性 void initSentinelConfig(void) { server.port = REDIS_SENTINEL_PORT; } |
- initSentinel(),初始化哨兵节点的状态
| void initSentinel(void) { unsigned int j; /* Remove usual Redis commands from the command table, then just add * the SENTINEL command. */ dictEmpty(server.commands,NULL); for (j = 0; j < sizeof(sentinelcmds)/sizeof(sentinelcmds[0]); j++) { int retval; struct redisCommand *cmd = sentinelcmds+j; retval = dictAdd(server.commands, sdsnew(cmd->name), cmd); serverAssert(retval == DICT_OK); } /* Initialize various data structures. */ sentinel.current_epoch = 0; sentinel.masters = dictCreate(&instancesDictType,NULL); sentinel.tilt = 0; sentinel.tilt_start_time = 0; sentinel.previous_time = mstime(); sentinel.running_scripts = 0; sentinel.scripts_queue = listCreate(); sentinel.announce_ip = NULL; sentinel.announce_port = 0; sentinel.simfailure_flags = SENTINEL_SIMFAILURE_NONE; sentinel.deny_scripts_reconfig = SENTINEL_DEFAULT_DENY_SCRIPTS_RECONFIG; memset(sentinel.myid,0,sizeof(sentinel.myid)); } |
struct redisCommand sentinelcmds[] = {
{"ping",pingCommand,1,"",0,NULL,0,0,0,0,0},
{"sentinel",sentinelCommand,-2,"",0,NULL,0,0,0,0,0},
{"subscribe",subscribeCommand,-2,"",0,NULL,0,0,0,0,0},
{"unsubscribe",unsubscribeCommand,-1,"",0,NULL,0,0,0,0,0},
{"psubscribe",psubscribeCommand,-2,"",0,NULL,0,0,0,0,0},
{"punsubscribe",punsubscribeCommand,-1,"",0,NULL,0,0,0,0,0},
{"publish",sentinelPublishCommand,3,"",0,NULL,0,0,0,0,0},
{"info",sentinelInfoCommand,-1,"",0,NULL,0,0,0,0,0},
{"role",sentinelRoleCommand,1,"l",0,NULL,0,0,0,0,0},
{"client",clientCommand,-2,"rs",0,NULL,0,0,0,0,0},
{"shutdown",shutdownCommand,-1,"",0,NULL,0,0,0,0,0},
{"auth",authCommand,2,"sltF",0,NULL,0,0,0,0,0}
};
10.4.3 载入配置文件
loadServerConfig --- > loadServerConfigFromString --- > sentinelHandleConfiguration
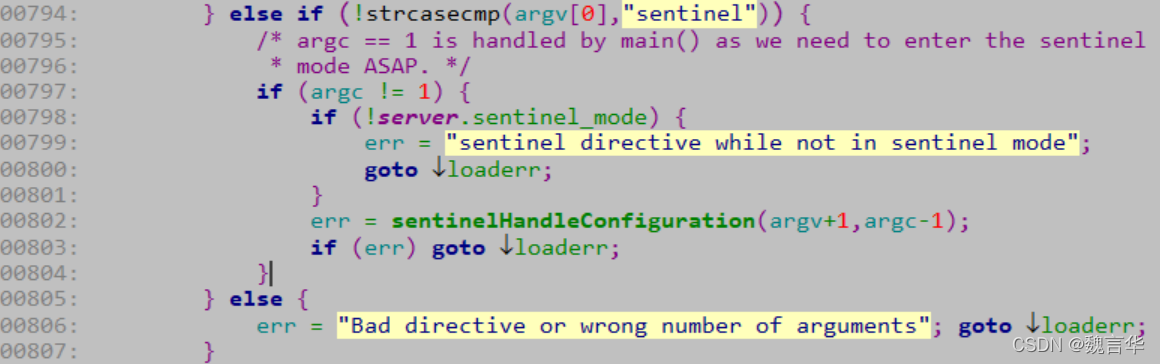
载入配置文件主要使用了两个函数createSentinelRedisInstance()和sentinelGetMasterByName()。前者用来根据指定监控的主节点来创建实例,而后者则要根据名字找到对应的主节点实例来设置配置的参数。
10.4.4 开启 Sentinel
载入完配置文件,就会调用sentinelIsRunning()函数开启Sentinel。该函数主要干了这几个事:
检查配置文件是否可写,因为要重写配置文件。
为没有runid的哨兵节点分配 ID,并重写到配置文件中,并且打印到日志中。
生成一个+monitor事件通知。
所以在启动一个哨兵节点时,查看日志会发现
| 12775:X 28 May 15:14:34.953 # Sentinel ID is a4dce0267abdb89f7422c9a42960e6cb6e4 d565a 12775:X 28 May 15:14:34.953 # +monitor master mymaster 127.0.0.1 6379 quorum 2 |
10.4.5 sentinel数据结构
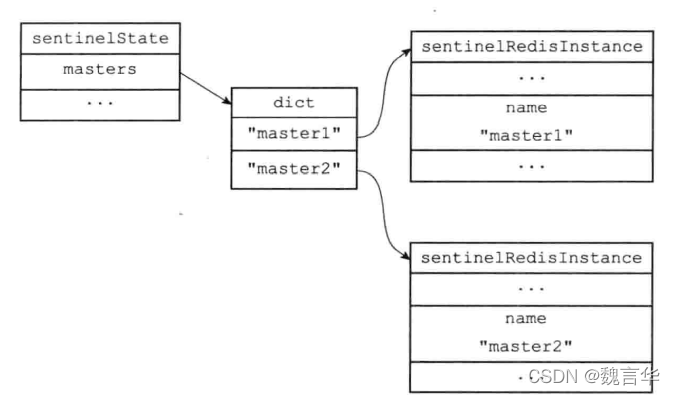
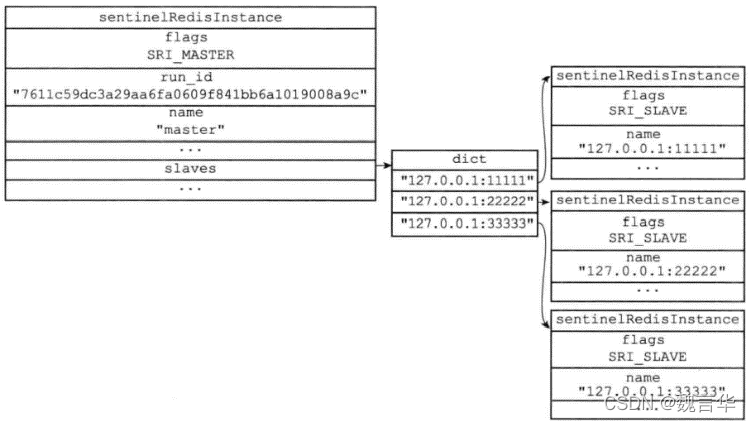
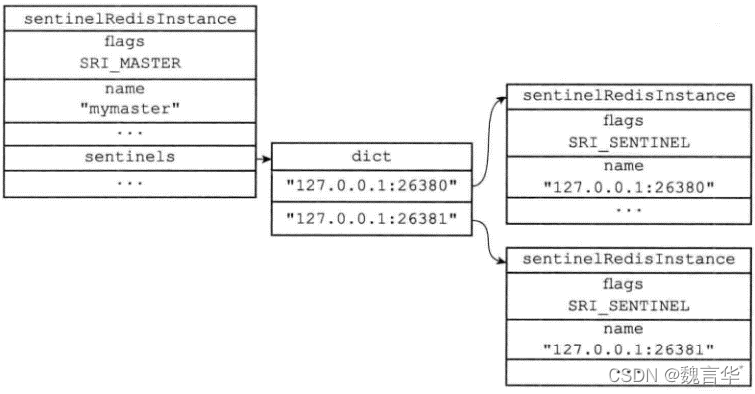
10.4.6 sentinel 事件处理流程
哨兵的操作是由时间事件进行操作的,也就是由 serverCron() 函数发起的,以 100毫秒的 频率执行 sentinelTimer() 事件,对 sentinel 各种事件进行周期性调度
执行周期性函数sentinelHandleDictOfRedisInstances()
void sentinelHandleDictOfRedisInstances(dict *instances) {
dictIterator *di;
dictEntry *de;
sentinelRedisInstance *switch_to_promoted = NULL;
// 获取监控对象实例迭代器
di = dictGetIterator(instances);
// 遍历监控对象实例
while((de = dictNext(di)) != NULL) {
// 获取实例
sentinelRedisInstance *ri = dictGetVal(de);
// 对指定的实例执行周期操作
sentinelHandleRedisInstance(ri);
// 如果当前实例为主服务器节点
if (ri->flags & SRI_MASTER) {
// 递归对当前实例的从节点执行周期函数
sentinelHandleDictOfRedisInstances(ri->slaves);
// 递归对当前实例的 sentinel 节点执行周期函数
sentinelHandleDictOfRedisInstances(ri->sentinels);
// 如果当前实例处于完成故障转移状态而且所有从节点已经完成了对新主节点的同步操作,那么设置 主从转换标识
if (ri->failover_state == SENTINEL_FAILOVER_STATE_UPDATE_CONFIG) {
switch_to_promoted = ri;
}
}
}
// 如果设置了主从转换标识
if (switch_to_promoted)
// 将原来的主节点从表中删除,使用晋升的新主节点替代,那么所有 从节点 和 旧主节点 都从属当前新的主节点
sentinelFailoverSwitchToPromotedSlave(switch_to_promoted);
// 释放迭代器
dictReleaseIterator(di);
}
- sentinelHandleRedisInstance()函数用来处理主节点、从节点和哨兵节点的周期性操作。
- sentinelFailoverSwitchToPromotedSlave()函数用来处理发生主从切换的情况。
| void sentinelHandleRedisInstance(sentinelRedisInstance *ri) { /* ========== MONITORING HALF ============ */ /* ========== 一半监控操作 ============ */ /* Every kind of instance */ /* 对所有的类型的实例进行操作 */ // 为Sentinel和ri实例创建一个网络连接,包括cc和pc sentinelReconnectInstance(ri); // 定期发送PING、PONG、PUBLISH命令到ri实例中 sentinelSendPeriodicCommands(ri); /* ============== ACTING HALF ============= */ /* ============== 一半故障检测 ============= */ // 如果Sentinel处于TILT模式,则不进行故障检测 if (sentinel.tilt) { // 如果TILT模式的时间没到,则不执行后面的动作,直接返回 if (mstime()-sentinel.tilt_start_time < SENTINEL_TILT_PERIOD) return; // 如果TILT模式时间已经到了,取消TILT模式的标识 sentinel.tilt = 0; sentinelEvent(LL_WARNING,"-tilt",NULL,"#tilt mode exited"); } /* Every kind of instance */ // 对于各种实例进行是否下线的检测,是否处于主观下线状态 sentinelCheckSubjectivelyDown(ri); /* Masters and slaves */ // 目前对主节点和从节点的实例什么都不做 if (ri->flags & (SRI_MASTER|SRI_SLAVE)) { /* Nothing so far. */ } /* Only masters */ // 只对主节点进行操作 if (ri->flags & SRI_MASTER) { // 检查从节点是否客观下线 sentinelCheckObjectivelyDown(ri); // 如果处于客观下线状态,则进行故障转移的状态设置 if (sentinelStartFailoverIfNeeded(ri)) // 强制向其他Sentinel节点发送SENTINEL IS-MASTER-DOWN-BY-ADDR给所有的Sentinel获取回复 // 尝试获得足够的票数,标记主节点为客观下线状态,触发故障转移 sentinelAskMasterStateToOtherSentinels(ri,SENTINEL_ASK_FORCED); // 执行故障转移操作 sentinelFailoverStateMachine(ri); // 主节点ri没有处于客观下线的状态,那么也要尝试发送SENTINEL IS-MASTER-DOWN-BY-ADDR给所有的Sentinel获取回复 // 因为ri主节点如果有回复延迟等等状况,可以通过该命令,更新一些主节点状态 sentinelAskMasterStateToOtherSentinels(ri,SENTINEL_NO_FLAGS); } } |
很明显,该函数将周期性的操作分为两个部分,一部分是对一个的实例进行监控的操作,另一部分是对该实例执行故障检测。
10.4.6.1 建立链接
执行的第一个函数就是sentinelReconnectInstance()函数,因为在载入配置的时候,我们将创建的主节点实例加入到sentinel.masters字典的时候,该主节点的连接是关闭的,所以第一件事就是为主节点和哨兵节点建立网络连接。
| void sentinelReconnectInstance(sentinelRedisInstance *ri) { // 如果ri实例没有连接中断,则直接返回 if (ri->link->disconnected == 0) return; // ri实例地址非法 if (ri->addr->port == 0) return; /* port == 0 means invalid address. */ instanceLink *link = ri->link; mstime_t now = mstime(); // 如果还没有最近一次重连的时间距离现在太短,小于1s,则直接返回 if (now - ri->link->last_reconn_time < SENTINEL_PING_PERIOD) return; // 设置最近重连的时间 ri->link->last_reconn_time = now; /* Commands connection. */ // cc:命令连接 if (link->cc == NULL) { // 绑定ri实例的连接地址并建立连接 link->cc = redisAsyncConnectBind(ri->addr->ip,ri->addr->port,NET_FIRST_BIND_ADDR); // 命令连接失败,则事件通知,且断开cc连接 if (link->cc->err) { sentinelEvent(LL_DEBUG,"-cmd-link-reconnection",ri,"%@ #%s", link->cc->errstr); instanceLinkCloseConnection(link,link->cc); // 命令连接成功 } else { // 重置cc连接的属性 link->pending_commands = 0; link->cc_conn_time = mstime(); link->cc->data = link; // 将服务器的事件循环关联到cc连接的上下文中 redisAeAttach(server.el,link->cc); // 设置确立连接的回调函数 redisAsyncSetConnectCallback(link->cc, sentinelLinkEstablishedCallback); // 设置断开连接的回调处理 redisAsyncSetDisconnectCallback(link->cc, sentinelDisconnectCallback); // 发送AUTH 命令认证 sentinelSendAuthIfNeeded(ri,link->cc); // 发送连接名字 sentinelSetClientName(ri,link->cc,"cmd"); /* Send a PING ASAP when reconnecting. */ // 立即向ri实例发送PING命令 sentinelSendPing(ri); } } /* Pub / Sub */ // pc:发布订阅连接 // 只对主节点和从节点如果没有设置pc连接则建立一个 if ((ri->flags & (SRI_MASTER|SRI_SLAVE)) && link->pc == NULL) { // 绑定指定ri的连接地址并建立连接 link->pc = redisAsyncConnectBind(ri->addr->ip,ri->addr->port,NET_FIRST_BIND_ADDR); // pc连接失败,则事件通知,且断开pc连接 if (link->pc->err) { sentinelEvent(LL_DEBUG,"-pubsub-link-reconnection",ri,"%@ #%s", link->pc->errstr); instanceLinkCloseConnection(link,link->pc); // pc连接成功 } else { int retval; link->pc_conn_time = mstime(); link->pc->data = link; // 将服务器的事件循环关联到pc连接的上下文中 redisAeAttach(server.el,link->pc); // 设置确立连接的回调函数 redisAsyncSetConnectCallback(link->pc, sentinelLinkEstablishedCallback); // 设置断开连接的回调处理 redisAsyncSetDisconnectCallback(link->pc, sentinelDisconnectCallback); // 发送AUTH 命令认证 sentinelSendAuthIfNeeded(ri,link->pc); // 发送连接名字 sentinelSetClientName(ri,link->pc,"pubsub"); // 发送订阅 __sentinel__:hello 频道的命令,设置回调函数处理回复 // sentinelReceiveHelloMessages是处理Pub/Sub的频道返回信息的回调函数,可以发现订阅同一master的Sentinel节点 retval = redisAsyncCommand(link->pc, sentinelReceiveHelloMessages, ri, "SUBSCRIBE %s", SENTINEL_HELLO_CHANNEL); // 订阅频道出错,关闭 if (retval != C_OK) { // 关闭pc连接 instanceLinkCloseConnection(link,link->pc); return; } } } // 如果已经建立了新的连接,则清除断开连接的状态。表示已经建立了连接 if (link->cc && (ri->flags & SRI_SENTINEL || link->pc)) link->disconnected = 0; } |
建立连接的函数redisAsyncConnectBind()是Redis的官方C语言客户端hiredis的异步连接函数,当连接成功时需要调用redisAeAttach()函数来将服务器的事件循环(ae)与连接的上下文相关联起来(因为hiredis提供了多种适配器,包括事件ae,libev,libevent,libuv),在关联的时候,会设置了网络连接的可写可读事件的处理程序。接下来还会设置该连接的确立时和断开时的回调函数redisAsyncSetConnectCallback()和redisAsyncSetDisconnectCallback() 。
从该函数中可以很明显的看出来:
1)如论是主节点、从节点还是哨兵节点,都会与当前哨兵建立命令连接(Commands connection)。
2)只有主节点或从节点才会建立发布订阅连接(Pub / Sub connection)。
3)当建立了命令连接(cc)之后立即执行了三个动作:

4)当建立了发布订阅连接(pc)之后立即执行的动作
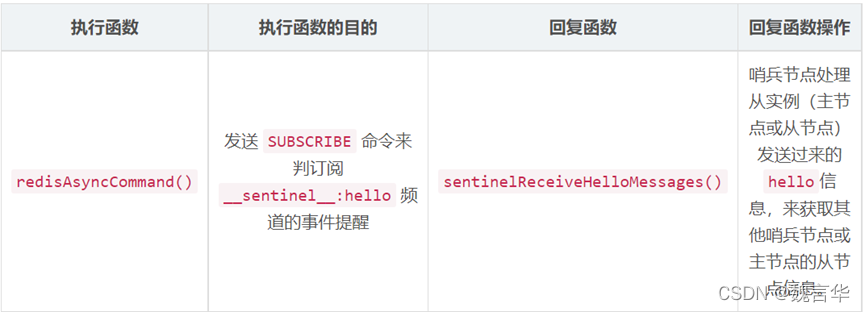
如果成功建立连接,之后会清除连接断开的标志,以表示连接已建立。
如果不是第一次执行,那么会判断连接是否建立,如果断开,则重新给建立,如果没有断开,那么什么都不会做直接返回。
10.4.6.2 发送监控命令
执行完建立网络连接的函数,接下来会执行sentinelSendPeriodicCommands()函数,该函数就是定期发送一些监控命令到主节点或从节点或哨兵节点,这些节点会将哨兵节点作为客户端来处理。
| void sentinelSendPeriodicCommands(sentinelRedisInstance *ri) { mstime_t now = mstime(); mstime_t info_period, ping_period; int retval; // 如果ri实例连接处于关闭状态,直接返回 if (ri->link->disconnected) return; // 对于不是发送关键命令的INFO,PING,PUBLISH,我们也有SENTINEL_MAX_PENDING_COMMANDS的限制。 我们不想使用大量的内存,只是因为连接对象无法正常工作(请注意,无论如何,还有一个冗余的保护措施,即如果检测到长时间的超时条件,连接将被断开连接并重新连接 // 每个实例的已发送未回复的命令个数不能超过100个,否则直接返回 if (ri->link->pending_commands >= SENTINEL_MAX_PENDING_COMMANDS * ri->link->refcount) return; // 如果主节点处于O_DOWN状态下,那么Sentinel默认每秒发送INFO命令给它的从节点,而不是通常的SENTINEL_INFO_PERIOD(10s)周期。在这种状态下,我们想更密切的监控从节点,万一他们被其他的Sentinel晋升为主节点 // 如果从节点报告和主节点断开连接,我们同样也监控INFO命令的输出更加频繁,以便我们能有一个更新鲜的断开连接的时间 // 如果ri是从节点,且他的主节点处于故障状态的状态或者从节点和主节点断开复制了 if ((ri->flags & SRI_SLAVE) && ((ri->master->flags & (SRI_O_DOWN|SRI_FAILOVER_IN_PROGRESS)) || (ri->master_link_down_time != 0))) { // 设置INFO命令的周期时间为1s info_period = 1000; } else { // 否则就是默认的10s info_period = SENTINEL_INFO_PERIOD; } // 每次最后一次接收到的PONG比配置的 'down-after-milliseconds' 时间更长,但是如果 'down-after-milliseconds'大于1秒,则每秒钟进行一次ping // 获取ri设置的主观下线的时间 ping_period = ri->down_after_period; // 如果大于1秒,则设置为1秒 if (ping_period > SENTINEL_PING_PERIOD) ping_period = SENTINEL_PING_PERIOD; // 如果实例不是Sentinel节点且Sentinel节点从该数据节点(主节点或从节点)没有收到过INFO回复或者收到INFO回复超时 if ((ri->flags & SRI_SENTINEL) == 0 && (ri->info_refresh == 0 || (now - ri->info_refresh) > info_period)) { // 发送INFO命令给主节点和从节点 retval = redisAsyncCommand(ri->link->cc, sentinelInfoReplyCallback, ri, "INFO"); // 已发送未回复的命令个数加1 if (retval == C_OK) ri->link->pending_commands++; // 如果发送和回复PING命令超时 } else if ((now - ri->link->last_pong_time) > ping_period && (now - ri->link->last_ping_time) > ping_period/2) { // 发送一个PING命令给ri实例,并且更新act_ping_time sentinelSendPing(ri); // 发送频道的定时命令超时 } else if ((now - ri->last_pub_time) > SENTINEL_PUBLISH_PERIOD) { // 发布hello信息给ri实例 sentinelSendHello(ri); } } |
从这个函数我们可以了解到一下信息:
1)一个连接对发送命令的个数有限制。因为连接是一个异步操作,发送了不一定会立即接收到,因此会为了节约内存而有一个限制,已发送未回复的命令个数不能超过100个,否则不做操作。
2)当该哨兵节点正在监控从节点时,但是从节点从属的主节点发送了故障,那么会设置发送INFO命令的频率为1s,否则就是默认的10s发送一次INFO命令。
3)PING命令的频率是1s发送一次。
4)每2S发送一次hello
INFO命令解析
哨兵节点只将INFO命令发送给主节点或从节点。并且设置sentinelInfoReplyCallback()函数来处理INFO命令的回复信息。当INFO命令的回复正确时,会调用sentinelRefreshInstanceInfo()函数来处理INFO命令的回复。处理INFO命令的回复有两部分:
1)获取该连接的节点实例最基本的信息,如:run_id,role,如果是发送给主节点,会获取到从节点信息;如果是发送给从节点,会获取到其主节点的信息。总之会获取当前整个集群网络的所有活跃的节点信息,并将其保存到当前哨兵的状态中,而且会刷新配置文件。这就是为什么在配置文件中不需要配置从节点的信息,因为通过这一操作会自动发现从节点。
2)处理角色变化的情况。当接收到INFO命令的回复,有可能发现当前哨兵连接的节点的角色状态发生变化
PING命令
| int sentinelSendPing(sentinelRedisInstance *ri) { // 异步发送一个PING命令给实例ri int retval = redisAsyncCommand(ri->link->cc, sentinelPingReplyCallback, ri, "PING"); // 发送成功 if (retval == C_OK) { // 已发送未回复的命令个数加1 ri->link->pending_commands++; // 更新最近一次发送PING命令的时间 ri->link->last_ping_time = mstime(); // 更新最近一次发送PING命令,但没有收到PONG命令的时间 if (ri->link->act_ping_time == 0) ri->link->act_ping_time = ri->link->last_ping_time; return 1; } else { return 0; } } |
该函数,发送给实例一个PING并且更新所有连接的状态。设置sentinelPingReplyCallback()来处理PING命令的回复。
PING命令的回复有以下两种:
1)状态回复或者错误回复PONG、LOADING、MASTERDOWN这三个是可以接受的回复,会更新最近的交互时间,用来判断实例和哨兵之间的网络可达。
忙回复
2)BUSY这个可能会是因为执行脚本而表现为下线状态。所以会发送一个SCRIPT KILL命令来终止脚本的执行。
无论如何,只要接受到回复,都会更新最近一次收到PING命令回复的状态,表示连接可达。
PUBLISH命令
发送PUBLISH命令,可以叫发送hello信息。因为这个操作像是和订阅该主节点的其他哨兵节点打招呼。
函数sentinelSendHello()用来发送hello信息,该函数主要做了两步操作:
1)构建hello信息的内容。hello信息的格式如下:
sentinel_ip,sentinel_port,sentinel_runid,current_epoch,master_name,master_ip,master_port,master_config_epoch这些信息包含有:当前哨兵的信息和主节点信息。
2)发送PUBLISH命令,将hello信息发布到创建连接时建立的频道。
3)设置sentinelPublishReplyCallback()函数为处理PUBLISH命令的回复。该命令主要就是更新通过频道进行通信的时间,以便保持发布订阅连接的可达。
通过发送PUBLISH命令给任意类型实例,最终都是将主节点信息和当前哨兵信息广播给所有的订阅指定频道的哨兵节点,这样就可以将监控相同主节点的哨兵保存在哨兵实例的sentinels字典中。
10.4.6.3 判断主节点的主观下线状态
当前哨兵节点发送完所有的监控命令,有可能发送成功且顺利收到回复,也有可能发送和回复都没有成功收到等等可能,因此要对当前节点实例(所有类型都要进行判断)调用sentinelCheckSubjectivelyDown()函数进行主观下线判断
| void sentinelCheckSubjectivelyDown(sentinelRedisInstance *ri) { mstime_t elapsed = 0; // 获取ri实例回复命令已经过去的时长 if (ri->link->act_ping_time) // 获取最近一次发送PING命令过去了多少时间 elapsed = mstime() - ri->link->act_ping_time; // 如果实例的连接已经断开 else if (ri->link->disconnected) // 获取最近一次回复PING命令过去了多少时间 elapsed = mstime() - ri->link->last_avail_time; // 如果连接处于低活跃度,那么进行重新连接 // cc命令连接超过了1.5s,并且之前发送过PING命令但是连接活跃度很低 if (ri->link->cc && (mstime() - ri->link->cc_conn_time) > SENTINEL_MIN_LINK_RECONNECT_PERIOD && ri->link->act_ping_time != 0 && /* Ther is a pending ping... */ /* The pending ping is delayed, and we did not received * error replies as well. */ (mstime() - ri->link->act_ping_time) > (ri->down_after_period/2) && (mstime() - ri->link->last_pong_time) > (ri->down_after_period/2)) { // 断开ri实例的cc命令连接 instanceLinkCloseConnection(ri->link,ri->link->cc); } // 检查pc发布订阅的连接是否也处于低活跃状态 if (ri->link->pc && (mstime() - ri->link->pc_conn_time) > SENTINEL_MIN_LINK_RECONNECT_PERIOD && (mstime() - ri->link->pc_last_activity) > (SENTINEL_PUBLISH_PERIOD*3)) { // 断开ri实例的pc发布订阅连接 instanceLinkCloseConnection(ri->link,ri->link->pc); } // 更新主观下线标志,条件如下: /* 1. 没有回复命令 2. Sentinel节点认为ri是主节点,但是它报告它是从节点 */ // ri实例回复命令已经过去的时长已经超过主观下线的时限,并且ri实例是主节点,但是报告是从节点 if (elapsed > ri->down_after_period || (ri->flags & SRI_MASTER && ri->role_reported == SRI_SLAVE && mstime() - ri->role_reported_time > (ri->down_after_period+SENTINEL_INFO_PERIOD*2))) { /* Is subjectively down */ // 设置主观下线的标识 if ((ri->flags & SRI_S_DOWN) == 0) { // 发送"+sdown"的事件通知 sentinelEvent(LL_WARNING,"+sdown",ri,"%@"); // 设置实例被判断主观下线的时间 ri->s_down_since_time = mstime(); ri->flags |= SRI_S_DOWN; } } else { /* Is subjectively up */ // 如果设置了主观下线的标识,则取消标识 if (ri->flags & SRI_S_DOWN) { sentinelEvent(LL_WARNING,"-sdown",ri,"%@"); ri->flags &= ~(SRI_S_DOWN|SRI_SCRIPT_KILL_SENT); } } } |
该函数主要做了两件事:
1)根据命令连接和发布订阅连接的活跃度来判断是否要执行断开对应连接的操作。以便下次时钟循环在重新连接,以保证可靠性。
2)获取回复PING命令过去的时间,然后进行判断是否已经下线。如果满足主观下线的条件,那么会设置主观下线的标识。主观下线条件有两个:
a) 回复PING命令超时
b)哨兵节点发现他的角色发生变化。认为它是主节点但是报告显示它是从节点。
当判断完主观下线后,虽然对实例设置了主观下线的标识,但是只有该实例是主节点,才会执行进一步的判断。否则对于其他类型节点来说,他们的周期性操作已经执行完成。
10.4.6.4 判断主节点的客观下线状态
| void sentinelHandleRedisInstance(sentinelRedisInstance *ri) { ……………………………………….. /* Only masters */ if (ri->flags & SRI_MASTER) { sentinelCheckObjectivelyDown(ri); if (sentinelStartFailoverIfNeeded(ri)) sentinelAskMasterStateToOtherSentinels(ri,SENTINEL_ASK_FORCED); sentinelFailoverStateMachine(ri); sentinelAskMasterStateToOtherSentinels(ri,SENTINEL_NO_FLAGS); } } |
| void sentinelCheckObjectivelyDown(sentinelRedisInstance *master) { dictIterator *di; dictEntry *de; unsigned int quorum = 0, odown = 0; // 如果该master实例已经被当前Sentinel节点判断为主观下线 if (master->flags & SRI_S_DOWN) { /* Is down for enough sentinels? */ // 当前Sentinel节点认为下线投1票 quorum = 1; /* the current sentinel. */ /* Count all the other sentinels. */ di = dictGetIterator(master->sentinels); // 遍历监控该master实例的所有的Sentinel节点 while((de = dictNext(di)) != NULL) { sentinelRedisInstance *ri = dictGetVal(de); // 如果Sentinel也认为master实例主观下线,那么增加投票数 if (ri->flags & SRI_MASTER_DOWN) quorum++; } dictReleaseIterator(di); // 如果超过master设置的客观下线票数,则设置客观下线标识 if (quorum >= master->quorum) odown = 1; } /* Set the flag accordingly to the outcome. */ // 如果被判断为客观下线 if (odown) { // master没有客观下线标识则要设置 if ((master->flags & SRI_O_DOWN) == 0) { // 发送"+odown"事件通知 sentinelEvent(LL_WARNING,"+odown",master,"%@ #quorum %d/%d", quorum, master->quorum); // 设置master客观下线标识 master->flags |= SRI_O_DOWN; // 设置master被判断客观下线的时间 master->o_down_since_time = mstime(); } // master实例没有客观下线 } else { // 取消master客观下线标识 if (master->flags & SRI_O_DOWN) { // 发送"-odown"事件通知 sentinelEvent(LL_WARNING,"-odown",master,"%@"); master->flags &= ~SRI_O_DOWN; } } } |
该函数做了两个工作:
1)遍历监控该主节点的所有其他的哨兵节点,如果这些哨兵节点也认为当前主节点下线(SRI_MASTER_DOWN),那么投票数加1,当超过设置的投票数,标识客观下线的标志。
2)如果客观下线的标志(odown)为真,那么打开主节点的客观下线的表示,否则取消主节点客观下线的标识。
执行完的客观下线判断,如果发现主节点打开了客观下线的状态标识,那么就进一步进行判断,否则就执行跳过判断。执行这进一步判断的函数是:sentinelStartFailoverIfNeeded()。该函数用来判断能不能进行故障转移
- 主节点必须处于客观下线状态。如果没有打开客观下线的标识,就会直接返回0。
- 没有正在对主节点进行故障转移。
- 一段时间内没有尝试进行故障转移,防止频繁执行故障转移。
如果以上条件都满足,那么会调用sentinelStartFailover()函数,将更新主节点的故障转移状态,会执行下面这句关键的代码
master->failover_state = SENTINEL_FAILOVER_STATE_WAIT_START;
master->flags |= SRI_FAILOVER_IN_PROGRESS;
并且返回1,执行if条件中的代码:
sentinelAskMasterStateToOtherSentinels(ri,SENTINEL_ASK_FORCED);
| void sentinelAskMasterStateToOtherSentinels(sentinelRedisInstance *master, int flags) { dictIterator *di; dictEntry *de; di = dictGetIterator(master->sentinels); // 遍历监控master的所有的Sentinel节点 while((de = dictNext(di)) != NULL) { sentinelRedisInstance *ri = dictGetVal(de); // 当前Sentinel实例最近一个回复SENTINEL IS-MASTER-DOWN-BY-ADDR命令所过去的时间 mstime_t elapsed = mstime() - ri->last_master_down_reply_time; char port[32]; int retval; /* If the master state from other sentinel is too old, we clear it. */ // 如果master状态太旧没有更新,则清除它保存的主节点状态 if (elapsed > SENTINEL_ASK_PERIOD*5) { ri->flags &= ~SRI_MASTER_DOWN; sdsfree(ri->leader); ri->leader = NULL; } // 满足以下条件向其他Sentinel节点询问主节点是否下线 /* 1. 当前Sentinel节点认为它已经下线,并且处于故障转移状态 2. 其他Sentinel与当前Sentinel保持连接状态 3. 在SENTINEL_ASK_PERIOD毫秒内没有收到INFO回复 */ // 主节点没有处于客观下线状态,则跳过当前Sentinel节点 if ((master->flags & SRI_S_DOWN) == 0) continue; // 如果当前Sentinel节点断开连接,也跳过 if (ri->link->disconnected) continue; // 最近回复SENTINEL IS-MASTER-DOWN-BY-ADDR命令在SENTINEL_ASK_PERIODms时间内已经回复过了,则跳过 if (!(flags & SENTINEL_ASK_FORCED) && mstime() - ri->last_master_down_reply_time < SENTINEL_ASK_PERIOD) continue; /* Ask */ // 发送SENTINEL IS-MASTER-DOWN-BY-ADDR命令 ll2string(port,sizeof(port),master->addr->port); // 异步发送命令 retval = redisAsyncCommand(ri->link->cc, sentinelReceiveIsMasterDownReply, ri, "SENTINEL is-master-down-by-addr %s %s %llu %s", master->addr->ip, port, sentinel.current_epoch, // 如果主节点处于故障转移的状态,那么发送该Sentinel的ID,让收到命令的Sentinel节点选举自己为领头 // 否则发送"*"表示发送投票 (master->failover_state > SENTINEL_FAILOVER_STATE_NONE) ? sentinel.myid : "*"); // 已发送未回复的命令个数加1 if (retval == C_OK) ri->link->pending_commands++; } dictReleaseIterator(di); } |
10.4.6.5 对主节点执行故障转移
| void sentinelFailoverStateMachine(sentinelRedisInstance *ri) { // ri实例必须是主节点 serverAssert(ri->flags & SRI_MASTER); // 如果主节点不处于进行故障转移操作的状态,则直接返回 if (!(ri->flags & SRI_FAILOVER_IN_PROGRESS)) return; // 根据故障转移的状态,执行合适的操作 switch(ri->failover_state) { // 故障转移开始 case SENTINEL_FAILOVER_STATE_WAIT_START: sentinelFailoverWaitStart(ri); break; // 选择一个要晋升的从节点 case SENTINEL_FAILOVER_STATE_SELECT_SLAVE: sentinelFailoverSelectSlave(ri); break; // 发送slaveof no one命令,使从节点变为主节点 case SENTINEL_FAILOVER_STATE_SEND_SLAVEOF_NOONE: sentinelFailoverSendSlaveOfNoOne(ri); break; // 等待被选择的从节点晋升为主节点,如果超时则重新选择晋升的从节点 case SENTINEL_FAILOVER_STATE_WAIT_PROMOTION: sentinelFailoverWaitPromotion(ri); break; // 给所有的从节点发送slaveof命令,同步新的主节点 case SENTINEL_FAILOVER_STATE_RECONF_SLAVES: sentinelFailoverReconfNextSlave(ri); break; } } |
当执行完所有类型的节点的周期性任务之后,会执行sentinelHandleDictOfRedisInstances()下面的代码:
| while((de = dictNext(di)) != NULL) { sentinelRedisInstance *ri = dictGetVal(de); // 递归对所有节点执行周期性操作 ...... // 如果ri实例处于完成故障转移操作的状态,所有从节点已经完成对新主节点的同步 if (ri->failover_state == SENTINEL_FAILOVER_STATE_UPDATE_CONFIG) { // 设置主从转换的标识 switch_to_promoted = ri; } } // 如果主从节点发生了转换 if (switch_to_promoted) // 将原来的主节点从主节点表中删除,并用晋升的主节点替代 // 意味着已经用新晋升的主节点代替旧的主节点,包括所有从节点和旧的主节点从属当前新的主节点 sentinelFailoverSwitchToPromotedSlave(switch_to_promoted); dictReleaseIterator(di); |
还记得当前强制将主节点的故障状态更新的状态吗?对,就是SENTINEL_FAILOVER_STATE_UPDATE_CONFIG状态。这个状态表示已经完成在故障转移状态下,所有从节点对新主节点的同步操作。因此需要调用sentinelFailoverSwitchToPromotedSlave()函数特殊处理发送主从切换的情况。
该函数会发送事件通知然后调用sentinelResetMasterAndChangeAddress()来用新晋升的主节点代替旧的主节点,包括所有从节点和旧的主节点从属当前新的主节点。
| int sentinelResetMasterAndChangeAddress(sentinelRedisInstance *master, char *ip, int port) { sentinelAddr *oldaddr, *newaddr; sentinelAddr **slaves = NULL; int numslaves = 0, j; dictIterator *di; dictEntry *de; // 创建ip:port地址字符串 newaddr = createSentinelAddr(ip,port); if (newaddr == NULL) return C_ERR; // 创建一个从节点表,将重置后的主节点添加到该表中 // 不包含有我们要转换地址的那一个从节点 di = dictGetIterator(master->slaves); // 遍历所有的从节点 while((de = dictNext(di)) != NULL) { sentinelRedisInstance *slave = dictGetVal(de); // 如果当前从节点的地址和指定的地址相同,说明该从节点是要晋升为主节点的,因此跳过该从节点 if (sentinelAddrIsEqual(slave->addr,newaddr)) continue; // 否则将该从节点加入到一个数组中 slaves = zrealloc(slaves,sizeof(sentinelAddr*)*(numslaves+1)); slaves[numslaves++] = createSentinelAddr(slave->addr->ip, slave->addr->port); } dictReleaseIterator(di); // 如果指定的地址和主节点地址不相同,说明,该主节点是要被替换的,那么将该主节点地址加入到从节点数组中 if (!sentinelAddrIsEqual(newaddr,master->addr)) { slaves = zrealloc(slaves,sizeof(sentinelAddr*)*(numslaves+1)); slaves[numslaves++] = createSentinelAddr(master->addr->ip, master->addr->port); } // 重置主节点,但不删除所有监控自己的Sentinel节点 sentinelResetMaster(master,SENTINEL_RESET_NO_SENTINELS); // 备份旧地址 oldaddr = master->addr; // 设置新地址 master->addr = newaddr; // 下线时间清零 master->o_down_since_time = 0; master->s_down_since_time = 0; /* Add slaves back. */ // 为新的主节点加入从节点 for (j = 0; j < numslaves; j++) { sentinelRedisInstance *slave; // 遍历所有的从节点表,创建从节点实例,并将该实例从属到当前新的主节点中 slave = createSentinelRedisInstance(NULL,SRI_SLAVE,slaves[j]->ip, slaves[j]->port, master->quorum, master); // 释放原有的表中的从节点 releaseSentinelAddr(slaves[j]); // 事件通知 if (slave) sentinelEvent(LL_NOTICE,"+slave",slave,"%@"); } // 释放从节点表 zfree(slaves); // 将原主节点地址释放 releaseSentinelAddr(oldaddr); // 刷新配置文件 sentinelFlushConfig(); return C_OK; } |

















 1322
1322

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









