







Total Submission(s): 13452 Accepted Submission(s): 3804
Problem Description
A histogram is a polygon composed of a sequence of rectangles aligned at a common base line. The rectangles have equal widths but may have different heights. For example, the figure on the left shows the histogram that consists of rectangles with the heights 2, 1, 4, 5, 1, 3, 3, measured in units where 1 is the width of the rectangles:
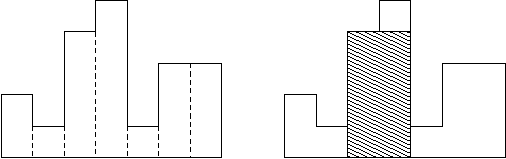
Usually, histograms are used to represent discrete distributions, e.g., the frequencies of characters in texts. Note that the order of the rectangles, i.e., their heights, is important. Calculate the area of the largest rectangle in a histogram that is aligned at the common base line, too. The figure on the right shows the largest aligned rectangle for the depicted histogram.
Usually, histograms are used to represent discrete distributions, e.g., the frequencies of characters in texts. Note that the order of the rectangles, i.e., their heights, is important. Calculate the area of the largest rectangle in a histogram that is aligned at the common base line, too. The figure on the right shows the largest aligned rectangle for the depicted histogram.
Input
The input contains several test cases. Each test case describes a histogram and starts with an integer n, denoting the number of rectangles it is composed of. You may assume that 1 <= n <= 100000. Then follow n integers h1, ..., hn, where 0 <= hi <= 1000000000. These numbers denote the heights of the rectangles of the histogram in left-to-right order. The width of each rectangle is 1. A zero follows the input for the last test case.
Output
For each test case output on a single line the area of the largest rectangle in the specified histogram. Remember that this rectangle must be aligned at the common base line.
Sample Input
7 2 1 4 5 1 3 3 4 1000 1000 1000 1000 0
Sample Output
8 4000
Source
我在想这题为什么和dp有关啊? 暂时还不知道
我认为就是一道思维题吧
对于每个小长方形的高度 我们需要求出以它为高的左右边界 左边的比它本身高的话,就一直递归找下去。右边也是这样。
#include <stdio.h>
#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
#define ll long long
#define Maxn 100010
int main()
{
//freopen("in.in","r",stdin);
int n;
while(scanf("%d",&n)!=EOF&&n)
{
int l[Maxn],r[Maxn];
ll a[Maxn];
ll maxn,area;
for(int i=1;i<=n;i++)
{
cin>>a[i];
r[i]=l[i]=i;
}
a[0]=a[n+1]=-1;
for(int i=1;i<=n;i++)
{
while(a[l[i]-1]>=a[i])
{
l[i]=l[l[i]-1];
}
}
for(int i=n;i>=1;i--)
{
while(a[r[i]+1]>=a[i])
{
r[i]=r[r[i]+1];
}
}
maxn=0;
for(int i=1;i<=n;i++)
{
area=(r[i]-l[i]+1)*a[i];
maxn= area>maxn?area:maxn;
}
printf("%lld\n",maxn);
}
return 0;
}

















 605
605

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









