






# @File : douban_movie_top_250.py
# @function : 爬取豆瓣电影排行榜Top 250部电影的片名、海报图片地址并下载海报图片
# @Software : PyCharm Community Edition,谷歌Chrome浏览器
# @Knowledge: requests、正则表达式、图片下载
import os.path
import requests
import re
from bs4 import BeautifulSoup
from lxml import etree
# 豆瓣音乐排行榜网址
url = 'http://localhost:8080/douban/douban1.html'
base_url = 'http://localhost:8080/douban/'
# 补全代码:使用requests库发送请求并获取返回结果
response = requests.get(url)
response.encoding = response.apparent_encoding
html_content = response.content.decode('utf-8')
# 通过正则表达式获取片名title
def get_music_title():
# 补全代码
if 200 == response.status_code:
html = response.text
tree = etree.HTML(html)
musice_list = tree.xpath('//div[@class="pl2"]')
title_list = []
for musice in musice_list:
title = musice.xpath('.//a/text()')[0].strip()
title_list.append(title)
#print(title_list)
return title_list
# 通过正则表达式获取音乐海报图片网址
def get_music_images():
# 补全代码
pattern = re.compile(r'<img src="(.*?)"', re.S)
image_list = re.findall(pattern, html_content)
return image_list
def clean_filename(filename):
# 移除文件名中的特殊字符
# 它用于过滤字符串filename中的字符。具体地说,它保留字母数字字符,以及空格、下划线和破折号。
return "".join(c for c in filename if c.isalnum() or c in (' ', '_', '-'))
# 打印片名和海报图片网址,并通过requests库下载图片
def print_titles_download_images(titles, images):
# 下载的海报图片保存在imgs文件夹中,需要提前创建好imgs文件夹
# 补全代码:打印的片名前需要有序号
if not os.path.exists('imgs'):
os.mkdir('imgs')
for i, (title, image_url) in enumerate(zip(titles, images), 1):#同时获得每个元素的索引和对应的值,拥有相同索引的数组元素,组合在一起
clean_title = clean_filename(title)
print(f"{i}. Title: {title}, Image Url: {base_url+image_url.lstrip('./')}")
image_content = requests.get(base_url+image_url.lstrip('./')).content
with open(f'imgs/{i}_{clean_title}.jpg', 'wb') as f:
f.write(image_content)
if __name__ == "__main__":
#补全代码
titles = get_music_title()
images = get_music_images()
print_titles_download_images(titles, images)计算机程序设计员(三级)操作技能考核
试题单
准考证号:
试题代码:2.6.5
试题名称:豆瓣电影Top 250排行榜图片下载
考核时间:40 min
1.场地设备要求
(1)硬件设备:PC机,最低配置要求Intel(R) Core(TM)i5-6500 CPU,4G内存,200G硬盘。
(2)软件环境:预装Windows 7操作系统及以上版本、Microsoft Office 2010及以上版本。
(3)开发环境:预装JDK V1.8及以上版本开发环境包、Eclipse 4.3及以上版本集成开发环境、Python3.7及以上版本解释器、PyCharm集成开发环境、MySQL 5.0及以上版本。
(4)素材: /素材/douban_movie_top_250.py
2.工作任务
(1)考生须根据《设计任务书》,完成豆瓣电影Top 250排行榜图片下载模块中指定的程序代码编写。
(2)考生须根据《设计任务书》要求,调试运行无误后提交设计完成的项目。
3.技能要求
(1)能使用IDE创建项目
(2)能实现面向对象的数据封装
(3)能使用Requests库进行网页数据爬取操作
(4)能编写基本的正则表达式
(5)能对requests指令进行操作
4.质量指标
(1)正确创建项目
(2)代码编写无语法错误
(3)正确实现功能
《设计任务书》
需求概述
使用requests库和 re库来访问豆瓣电影Top 250排行榜,在控制台输出音乐名和音乐图片地址,并将下载的音乐专辑图片保存在imgs目录中。
访问的页面链接如下:
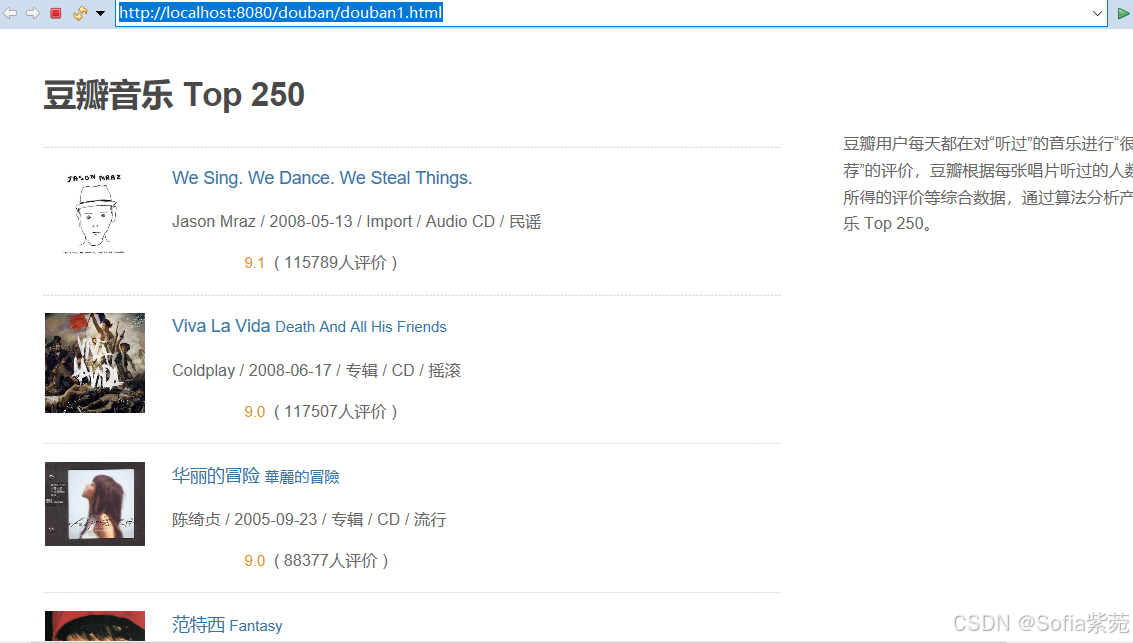
详细要求
(1)打开名为douban_movie_top_250的项目。
(2)在douban_movie_top_250.py文件中补全代码。要求使用requests库请求http://localhost:8080/douban/douban1.html页面并通过re库提取图片名、音乐海报图片地址的提取,并将电影海报图片保存在当前目录imgs文件夹下。
控制台的输出效果如下(以下截图只打印出了部分信息):
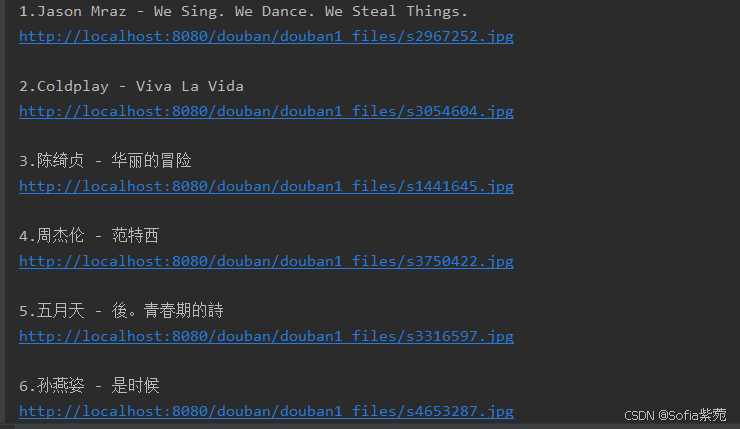
海报图片的效果如下:

(3)在桌面新建的一个文件夹中,文件夹命名为“准考证号+考位号+2.6”,请将douban_movie_top_250的项目储存在此文件夹。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









