






Redis:
单线程,高速读取和写入,数据存放在内存,缓存型的一种nosql数据库
被广泛的应用在应用与数据库的中间缓存、分布式事务的一致性、统一认证等等等等.每秒可达到十万级以上的读取和万级以上的每秒写入.
缓存的讲解:
什么是缓存:
原指CPU内部的存储单元.后期泛指这种高速可读写的存储区.
就像你要掏出打火机,兜里的打火机肯定最快被拿出;
而包里的就稍微慢一点;
那么去商店买的话,就再慢一点.
空间换时间的概念.
缓存的类别:
页面缓存:
manifest缓存也面文件
浏览器缓存:
强制缓存、过期缓存、协商缓存(常用的)
APP缓存:APP的内部缓存
网络端缓存
代理缓存:
Nginx
边缘缓存: 就近分配
CDN
服务器端缓存:
数据库缓存cache KV结构 引擎 buffer
平台缓存:GuavaCache、EhCache(二级缓存)、OSCache(页面缓存)等
中间件缓存(分布式缓存):Redis、Memcached、Tair(阿里)等,全部为K-V存储
缓存的优势:
提高可用性,提升用户体验
减轻服务器、数据库压力
提升系统性能
缓存的劣势:
硬件成本提升.
高并发的失效问题;
数据一致性的问题.
并发的执行顺序问题.
缓存的读写模式:
经典模式(旁路缓存):
查询缓存:
缓存有数据,返回;
缓存没数据,穿透数据库更新缓存;
更新缓存:
先更新数据库,再删除缓存.然后返回到查询步骤;如果遍历修改缓存,太影响效率,不如直接删掉重新加载.
也可异步开启线程去数据库获取数据加载到缓存.
高并发脏读情况:
先删缓存再更新数据库:
提交前另一用户读取.还是旧数据
先更新库,再更新缓存
提交失败就会导致数据不一致
先更新库,再删缓存:
提交前另一用户读取,还是旧数据.提交成了,缓存和数据库数据不一致了.
直读直写(Redis不支持该模式):
APP只操作缓存,缓存操作数据库
直读模式:APP读缓存,如果没有,缓存去数据库拿,写入缓存
直写模式:APP写入缓存,缓存再更新数据库
缓存再更新:
APP只更新缓存,缓存异步去执行更新数据库
缓存的设计思路:
缓存设置多个层级,某一层级的缓存失效后,不会影响可用性
数据类型:
简单类型使用mycache
多维复杂缓存Redis
数据格式:
同库复制缓存;
不一致逻辑缓存;
缓存的应用与对应的模块:
模块特性:
几乎无变更的数据:服务器本地缓存.一次加载完成
变更但是不需时效的数据.分布式缓存存储与本地缓存.
Redis基础回顾:
5.0后新版本 stream类型 消息流
命令不区分大小写,但key是区分大小写的.
key生成规则: ":"分割
缓存前缀为表名;接上ID和ID值,接上其他字段名
数据类型回顾:
setnx:value不存在时采用赋值,有就不赋值
多元命令操作原子性:set key value NX(setnx的命令) PX 设置过期时间
list:
左进右出=>队列
左进左出=>栈
set:
不重复,无序
sortedset:
有序的set 分数source概念
hash:
容器 k-v类型
不太常用的数据类型回顾:
位运算
bitmap:偏移量计算
geo地址位置:
Z阶曲线存储,将二维数据变为一个六位编码.再根据Base32编码形成一个字符串.这就是geoHash算法
redis使用52位整数存储, zset存储
staream数据流:
5.0后的新增
xadd x....
Redis底层数据结构:
实例=>DB=>KEY=>value(<=数据结构指针指向,不实际存储该类型作为value)
redisDB源码:
typedef 初始化对象
id:0-15 16个库
dict:存储字典
expires:过期时间存储
type:数据类型
encoding:编码
LRU:对象最后一次被访问的时间
lru:最后一次访问时间
lfu:访问次数
refcount:被引用的次数
ptr:指向底层数据结构的指针
Redis字符串:
SDS 字符串:
额外的属性:
len 已使用的数量
free 未使用的数量
buf[] 实际字符串长度
SDS字符串获取长度更快,因为有记录
SDS不会越界,因为有长度记录
可以存储二进制的数据,C的字符串是无法存空字符串的(带了个"\0")
缓冲区的支持
Redis跳跃表:

有序集合的底层实现进行分层,按照一定间隔进行一层一层的加装,查找时,先从最上层进行查找,找不到,再向下一层进行跳跃查找.查找机制类似二分法.
跳跃表的插入:
抛硬币的机制来决定插入节点层数,最多次越接近二分之一.
删除:
Redis字典(散列表):
数组:
存储数据的容器,时间复杂度O(1),非常快
Hash函数: 固定类型、固定长度的散列值
hash后的key转换为了一个整数.然后对数组长度取余获取到数据下标进行存储,如果hash冲突,该下标形成单向链表,for循环比对获取.
hash表dictht:
dictentry table 数组
size 大小
sizemask 映射位置掩码,永远等于size -1
use 已有节点数量 包含冲突的单向链表里的数据
hash表节点 dictentry
key:键
v:值 联合类型的
*next 单向链表指针,指向hash冲突的下一个节点
字典dict:
dictType type 类型来区分不同的使用模式
providata 模式下的参数
dictht ht[2] 0是原本的表, 1是用来扩容的表
rehashidx 是否已经扩容了 1扩了,-1正在,0没有
iterator 当前对象迭代器
字典dict扩容:
初次申请为扩4个,再次申请即扩为上次的一倍,扩充的过程叫rehash中.
旧数组复制给新的. rehash完成.
扩容时 服务器繁忙时 只扩一个节点
服务器不忙时 可批量100个同时扩容.
Reids压缩列表:
特殊编码的连续内存块组成的顺序型结构,
应用场景:
sorted-set和hash元素少而且是小整数或短字符串 直接使用
list作为快速链表时,其实是双向列表和压缩列表的组合
zkbytes 大小
zktail 尾元素对于起始位置的偏移量
zllen 元素个数
entry1.... 具体的各个节点
prevrawlensize 字段长度
prevrawlen存储的内容
lensize encoding字段长度
len 数据内容长度
headersize 头部长度
encoding 数据类型
*p 元素首地址
zlend 结尾,占一个字节0xFF 很C嘛...
Redis整数集合:
小整数放入set中,数据格式就为整数集合,如果整数超过2^64, 就是hashtable了
encoding 编码
length 长度
contents []保存数的数组
Redis快速列表quickList:
结合adlist和ziplist的数据类型,adlist中每个节点都是一个ziplist,能存储更多数据.

双向链表adlist:
普通链表为单向链表,从左到右、从右到左,而双向链表每个节点不光有指向下一个节点的指针,也有一个指向上一个节点的指针.可以双向遍历.多维化取出.
无环:头尾不指向.
压缩算法:LZF 记录位置和长度.
sz 压缩后占用的字节数
compressed 柔性数组 指向数据部分
Redis Stream流:
listpack 字符串列表的序列化,可存储字符串和整数
Rax树:基数树. 安装key的字典顺序排列 用于存储消息队列,ID为时间戳+序号, 有序时间序列

Redis编码:
总共10种
encoding 4位,存储编码类型
intset:
64位以内整数
hashtable:
64位以上的整数
String的编码类型:
int 整数;
embstr 小于44字节的字符串;
raw 大于44字节的字符串;
list编码类型:
quicklist 快速列表;
hash:
dict 字典 大整数、超长字符串、元素节点量大;
ziplist 压缩列表 小整数或段字符串,数组节点少;
set:
intset 小整数 小于2^64;
dict 字典 大整数;
zset:
ziplist 压缩列表 小整数或段字符串,数组节点少;
skiplist+dict 大整数、超长字符串、元素节点量大;
缓存过期和淘汰策略:
如果缓存一直在增加增加,达到物理内存的上限,那么就会频繁与磁盘做操作进行申请内存.这会严重拖垮redis的性能
所以redis有了缓存过期和淘汰的机制
关键项:
maxmemory 最大缓存大小(别超物理内存75%)
不设置的场景:数据固定,不会增加
做数据库使用,不能淘汰,做集群横向扩展分片
设置的场景:
不断新增数据
默认0 不限制
slaver模式下 更得让出一点给作为master时使用
设置:redis.conf:
#最大缓存
maxmemory: xxxmb
#淘汰策略
maxmemory-policy: 默认noeviction
allkeys-lru
过期策略:
set key value; 然后
expire key 1;先查有没有key 再添加过期字典
set key value PX 1000 在插入kv字典时顺便插入过期字典,没有查的步骤,原子操作,提高效率
删除策略:
惰性删除:访问失效时才删除.
下面这些都是maxmemory-policy的选项:
主动删除:
allkeys-lru算法,时间越大代表最近没被访问.其中的lfu表示被访问的次数.越少代表越冷.将会向数组的末尾移动.当移动到末尾,该数据将根据LRU算法将最近最少使用的节点移除,移除时不遍历,而是找lru值最大的节点淘汰(适合冷热数据交换)
volatile-lru:在设置过期时间里的keys根据最少使用进行淘汰
随机删除:
volatile-randow在设置过期的key随机选择淘汰
allkeys-random:所有的key里随机选择淘汰
TTL删除:
volatile-ttl 根据ttl表中剩余时间小的删除
Redis通信协议:
RESP协议,字符串数组形式来执行命令参数.command-specific来回复
通信协议:单进单线 tcp协议上
串行请求响应模式:ping-pong
一请求一响应.网络消耗高.

双工管道:pipeline
多请求统一发送,多响应返回;

事务批量:
基于事务批量通信
lua批量:
客户端向中继器发送,中继器负责统一发送给服务器通信.
发布订阅(pub/sub):
客户端出发,多客户端被动接收,通过服务器中转
请求数据格式:
内联:
telnet 形式 连接redis
规范格式:redis-cli
RESP格式:
\r\n:linux间隔符号 \n:windows间隔符号
+简单字符串
-error错误信息
$大字符串
:整数
*数组
命令处理流程:

启动initServer 注册事件eventLoop(文件事件、时间事件)
socket注册
socket建立连接
客户端cli与服务端创建client
注册socket
输入数据到缓冲区
获取命令 校验机制解析命令
执行命令流程图 贴图
响应格式:
\r\n:linux间隔符号 \n:windows间隔符号
+简单字符串 固定命令那种OK啊这样
-error错误信息
$字符串(都为自定义)
:整数
*数组
解析命令:
将命令字符切分,每组添加/r/n做完结,根据/r/n来判断每个命令.然后执行命令、判断合法性、记录是否慢查询等
Redis事件处理机制:
redis是典型的事件驱动系统,mvc是属于层级,一层层深入,事件驱动的典型是js,通过事件来调方法执行.redis分为文件事件和时间事件
文件事件:
Socket读写事件,也就是IO事件. file descriptor(文件描述符)
socket:连接套接字
Reactor:

redis使用单线程管理多个socket,传统的是线程池概念,多个线程来管理多个socket.而redis是单路IO复用模式
ServiceHandler负责接收client的事件,然后转发到多个RequestHandler.
结构:

Reactor:
事件的分派角色.事件注册、删除、接收主程序的事件请求等中转业务
Handler:
具体执行IO的操作句柄
Synchronous Event Demultiplexer:
操作系统级同步事件分离处理器,负责阻塞线程,等待事件触发,传递事件请求
EventHandler:
事件处理接口,提供统一的一些标准和方法
Concrete Event Handler:
具体事件处理器.执行操作.
具体流程:

=主程序先向Reactor注册事件;
=然后Reactor通过OS事件分离处理器(阻塞等待事件被触发)来监听事件;
=具体的事件处理器Concrete Event Handler返回响应表示准备就绪,等待触发;
=当主程序触发事件,Reactor也通过os事件分离器进行事件的传递,可以触发时响应给Reactor;
=然后Reactor去触发具体的事件Concrete Event Handler, 执行具体的事件操作
IO多路复用模型:
一个进程可监视多个描述符(socket) ,一旦就绪可用,就通知前面可以接收事件,不需要new新的线程,不可用时就阻塞,等着.
select:
调用该函数会阻塞,直到收到下列三个描述符或者超时才会执行返回.返回后遍历FD列表,找到就绪的描述符在哪.
writefds:写、readfds:读、exceptfds:异常
优点:
基本所有平台OS都支持,有良好的跨平台性.
缺点:
单个进程打开文件描述需要读写有限制,由FD_SETSIZE设置 默认1024 数组存储
采用了线性扫描的方法,在检查是否有就绪的描述符时,不管这个socket是否活跃,都会轮询一遍,效率较低.
poll:
结构中包含了要监控的事件和发生的事件,不使用select 参数-值 传递的方式;
优点:
采用了链表存储.对描述符数量没有有限制了,可超过select的1024
缺点:
同样采用线性扫描.效率较低
epoll:
linux2.6提出,将描述文件直接存放到内核事件表中,不需要来回复制事件表.先注册要监听的事件,只扫描注册的事件.
相关函数:
epoll_create(int size):
2.6.8后可忽略形参,建立一个epoll后就占用一个fd值,如果使用完毕没有close,那么会耗尽.
epoll_ctl(int epfd,int op,int fd ,struct epoll_event *event):
注册事件函数
epfd是create的返回值.
op是函数动作:
ADD添加fd到epfd MOD修改已注册的fd的事件
DEL删除一个fd
fd是被监听的fd
event是这个fd需要监听什么事件
epoll_wait(int epfd, struct epoll_event *events ,int maxevents ,int timeout):
等待内核返回可读写事件,最多返回maxevents个事件.
优点:
没有最大并发连接的限制,上线是最大可打开文件的数目,1G内存大约10万个连接处理
只扫描活跃的连接.跟连接总数无关,效率远远高于前两者
kqueue:
unix下的.与epoll相似
Redis持久化(RDB、AOF):
Redis是个内存型数据库,其持久化数据的完整性不被保证的,我们为了保护数据库,防止缓存雪崩的现象出现,就需要将缓存做一些持久化,来保证redis宕机重启后快速的恢复数据
RDB (Redis Database):

dbfilename *.rdb 将数据存储到指定文件.
快照的机制, 表示只存储某一时刻的redis内的数据.不关注过程.
触发快照的命令:
save或bgsave命令、符合自定义配置的快照规则、执行flushhall命令、主从复制启动;
save和bgsave:
save: ""不使用RDB存储
下面这些数值可修改,但不建议修改
save 900 1 15分内一个key被更新到快照
save 300 10 5分内10个key被更新到快照
save 60 10000 1分内10000个key被更新到快照
bgsave(后部复制):贴图
调用os的fork函数 复制自己的操作和数据,复制时进程阻塞;
这时子进程进行处理,先生成临时的rdb文件防止复制时被宕机导致无法恢复,复制完成后,覆盖写入rdb文件通知父进程save完毕.
RDB文件结构:
优点:
占用空间小、fork子进程将性能最大化,但主进程如果过于庞大,那么会影响性能
缺点:
会丢失最后一次快照后的所有数据. 20:00:00快照, 那么20:00:30时宕机,那么这30s的数据全部丢失......
AOF:
追加性质的持久化模式,但是会消耗redis的性能;
记录操作的过程.宕机后根据操作逆向恢复就可以了.
appendonly yes 开启 aof
appendsync always|everysec|no 追加形式
always:每个命令保存一次(太耗性能) 每次都阻塞主进程
everysec:每秒保存一次(默认) 后台fork子进程进行write和save. save不会阻塞主进程
no:不保存(只write操作命令给缓存,不save到aof文件到磁盘,在极端情况下才会save:redis关闭、aof关闭、缓存区满了,但这三种都会阻塞主进程)
AOF原理:
命令传播:选择适当的命令参数,存储为StringObject对象,根据RESP协议生成
缓存追加:将RESP文本写入缓存,
文件写入:然后写入到file对象,写入到AOF文件.
执行SAVE:save调用OS的fsync,将AOF文件保存到磁盘中
AOF重写:
针对key反复set数据,只返回最新的该key数据的集合,这种操作叫做aof重写,不会删除旧的set命令,会生成一个新的set记录.
不单写当前Redis的数据,还要把AOF重写缓存也要携带,写入到一个临时的AOF文件中,然后save覆盖当前的AOF文件
重写的触发:
redis.conf配置:
auto-aof-rewrite-min-size 64mb
最小触发AOF重写的aof文件大小,超过64mb后的AOF文件就要进行重写操作,进行整合然后覆盖
auto-aof-rewrite-percentage 100
当文件超过第一次重写的百分之多少后继续触发重写操作.比如超过第一次重写的64mb的100%就是128mb,会再次触发重写,之后是256、512、1024....这样
执行bgrewriteaof也可以触发AOF重写
RDB+AOF混合持久化:
RDB头+AOF身体 生成aof文件
aof-use-rdb-preamble yes 开启混合持久化
AOF还原的流程:

创建一个伪客户端,服务器端产生,从AOF中读取命令,使用伪客户端执行命令,一直到读取命令完毕
RBD和AOF的对比:
RDB占用空间小、AOF占用空间大
RDB性能较高、AOF性能较低
RDB会丢失最近一次快照后的数据,AOF每秒保存一次,只会丢失2秒的数据.
AOF不会保存过期的数据
应用场景选择:
做数据库用 混合 不易丢失数据 但如果有原始数据库提供数据,那么不需要持久化.但不能是太大的数据,太大还是开了吧.
缓存服务器: rdb 性能相对高, 但数据大 fork时就会阻塞了.
Redis扩展功能:
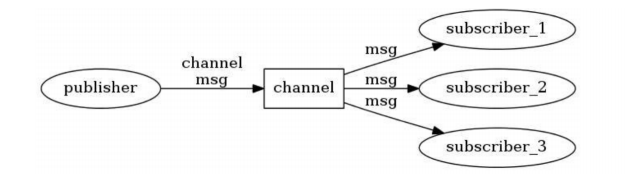
发布和订阅:
subscribe 频道1 频道2 ... 订阅消息
publish 频道号 消息 发布消息
unsubscribe 频道 取消订阅
psubscribe 频道通配符匹配 如 ch* ch开头的都能订阅到
punsubscribe 取消匹配的订阅
原理:
频道号是通道中存储订阅的客户端
频道匹配模式是该模式下存储客户端的数组
发出消息,先去查找频道号下的客户端进行发送消息,然后再去匹配模式下的客户端下发送消息
应用:
分布式锁的释放锁消息通知
哨兵模式中的消息传递
Redis事务:

原子性
redis是一个队列中的命令全执行或全不执行
一致性:
集群下只能保证最终一致性
隔离性:
事务执行时可能被其他客户端插入命令
持久性:
不保证完整的数据
multi 开启事务 而后的命令都会放到队列中
exec 提交事务 开始发送队列的命令,全部发给服务器
discard 清空队列命令 并取消事务
watch 监控key 监控某一key是否被修改 如果修改那么取消当前的事务 在multi前使用
unwatch 取消监控
事务的机制:
先检查是否在事务中,没有的话开始一个事务,然后将命令开始放入事务队列(在客户端中),当提交事务后,服务器进行遍历事务队列,进行执行命令.
弱事务性:
语法错误 导致的原子性事务问题,全部失败不执行.
逻辑错误 有的会成功,但有的会失败, 这又不是原子性,
不支持回滚 不需要保证数据高度一致性 所以没必要回滚 来保证性能

Redis Lua脚本:
nginx用了lua实现高并发
redis整合lua:redis2.6开始内置lua
下载lua:
curl -R -O http://www.lua.org/ftp/lua-5.3.5.tar.gz
安装:
tar -zxvf lua-5.3.5.tar.gz
在src目录下
make linux 或make install
make出错 找不到readline 执行以下命令:
yum -y install readline-devel ncurses-devel然后再次make
redis eval 执行lua脚本 :
EVAL:
EVAL script numkeys key [key ...] arg [arg ...]
eval "return {KEYS[1],KEYS[2],ARGV[1],ARGV[2]}" 2 key1 key2 first second
return为返回显示. keys为key数组的占位, 后面的2 就是标记他后面为key数组的具体值 key数组填写满了 后面为argv参数的值
eval "return redis.call('set',KEYS[1],ARGV[1])" 1 n1 zhaoyun
执行redis.call 执行redis的命令, 有错误不继续执行
EVALSHA:
script load 可将lua脚本生成一个sha编码.使用evalsha 该sha编码就代表执行生成编码的命令.
evalsha sha编码(3478dsg873y4h523r8923yr9283)
编写/执行lua脚本:
编写.lua文件 按照lua语法.
执行lua文件 ./redis-cli -h ip -p port --eval *.lua key , value; 空格为语法,必须携带哦
复杂点的语法:
local 声明变量
lua脚本复制:
lua脚本传播,传播到AOF和从库上.分为脚本传播和命令传播.
当使用时间函数或随机函数、内部状态时,redis就不允许lua传播,因为会出现主从不一致,但加上redis.replicate_commond()时,会将这些不确定的数据先生成再传播,就是命令传播
lua脚本执行时,其他客户端将被阻塞,达到了原子性的目的.但不能执行lua脚本时间过长,会影响整体性能.
Redis 慢查询:
配置:
#执行时间超过多少微秒的命令请求会被记录到日志上 0:全记录 <0 不记录
slowlog-log-slower-than 10000
#slowlog-max-len 存储慢查询日志条数
slowlog-max-len 128
查看慢查询:
slowlog get
清空慢查询
slowlog reset
查看慢查询条数:
slowlog len
慢查询的优化:
1、尽量使用短的key,对于value有些也可精简,能使用int就int。 数据的占位越小,性能越快嘛.
2、避免使用keys *、hgetall等全量操作. 就像select * 一样,少用.
3、减少大key的存取,打散为小key 组合set多个key成为一个大key 不要直接存一个很长的key
4、将rdb改为aof模式
rdb fork 子进程 主进程阻塞 redis大幅下降
关闭持久化 . 做缓存时就没必要持久化.
5、想要一次添加多条数据的时候可以使用管道 管道批量插入,batch save这种
6、尽可能地使用哈希存储 hset,查找快速,且存储快速
7、尽量限制下redis使用的内存大小,这样可以避免redis使用swap分区或者出现OOM错误内存与硬盘的swap,减少与磁盘的交互就会增加redis的性能.
Redis监视器:

client输入monitor命令即可变为监视器,就可查看服务器接收并处理的命令
监控平台:
grafana可视化工具.
prometheus 服务监控 使用HTTP协议
redis_exporter 导出redis数据给上面的监控
Redis主从复制:

执行命令:slaveof 5.0以后为replicaof
Redis可以构成一主多从的架构,从库下设从库.
流程:
主从复制设置:
主库无特殊操作.
从库配置文件配置:slaveof ip port(5.0前) 或者 replicaof ip port(5.0以上),也可以是命令行形式来输入这两个命令,只不过重启就没了
主从复制的机制:
其实是两个redis在socket通信.然后有个rdb对象和conmmand对象 一个存储文件对象, 一个存储命令
主从之间ping测试
主从复制权限验证:
如果主库配置了requirepass="" 从库就需要配置masterauth="" 来验证.两个值相同, 从库不配置的话在slaveof后也可以auth "password" 来验证.
主从复制数据同步:
分为全量同步和增量同步,一个是rdb文件,一个是命令形式,
2.8之前只能全量同步,一开始或同步中断后再次同步时从库的数据量全部清空,重新同步.
2.8之后支持了增量同步了,可以断点续传.根据当前同步的位置标记进行增量同步操作.实现了断点续传同步.
全量同步:
先是同步快照.然后同步写缓冲,最后同步增量.主从初次连接都是全量同步
增量同步:
主库收到写命令后同步传播给从库进行写入,在主从全量同步完成后,后期同步操作都为增量同步.
心跳检测:
每隔一秒主库向从库发送 replconf ack <replication_offset>
replication_offset:从服务器当前的复制偏移量
检测主从连接的状态;
辅助实现min-slaves;(不常用)
min-reliacas/slaves-to-write num 最小服务器数量.低了不干
min-reliacas/slaves-max-lag num 最大延迟检测
检测命令丢失: 根据从库缺失的数据进行补发,区别于增量同步,增量同步是网断了,而补发没有断网
Redis-Sentinel哨兵监控 redis高可用的解决方案:

一个或多个sentinel实例组成集群对一个或多个主从集群架构进行监控和管理.sentinel节点与redis节点互相都有通信,sentinel集群中通过选举选出leader,进行故障转移.主库崩溃后选择从库进行升主,旧主库恢复后将变为从库.
Sentinel搭建:
安装redis 省略
主库配置redis.conf: 无额外的配置.基本的redis配置
从库配置redis.conf:
修改端口;
replicaof 主库ip port 5.0以上好像只能设置replicaof
Sentinel搭建:其实也是个redis,只不过配置不同.
修改sentinel.conf:
修改端口;
(主要)sentinel monitor mymaster ip port 2(监控者下线数量认定,超过该数,认为该主库崩溃)
(主要)sentinel down-after-milliseconds 3000(主库3秒没有与监控应答视为下线)
启动sentinel:
./redis-sentinel sentinel.conf
Sentinel的流程:
Sentinel是一个特殊的redis服务器,不会持久化.
获取主库:
每个sentinel向主库发送2个连接: 命令连接, 订阅连接 频道sentinel
每隔10s 向被监控的主库发送info命令
获取从库
每个sentinel向每个从库发送2个连接: 命令连接, 订阅连接 频道_sentinel_:hello
每隔10s 向被监控的从库发送info命令
发送消息的内容:
sentinel集群内感知:
是靠订阅频道的主从库来实现的,当sentinel连接主从后,发布订阅,主从订阅接收消息,这时sentinel1发送消息,那么主从接收到后 sentinel2就可发现sentinel1监控节点(通过发送的消息内容获得信息),从而直接进行相互通信
检测主观下线状态:
sentinel向主库发送ping.在没有应答时间内回复,或者回复了无效回复(pong、loading、masterdown这三个为有效回复),那么sentinel就认为该节点下线;
sentinel通知其他sentinel该节点已下线.这其中无法组织其他sentinel继续ping该节点,其他sentinel节点给予回复,表明是否认同该主库下线,如果超过了数量认定,那么该主库就为客观下线状态.sentienl集群开始进行leader选举并选择新的redis主库.
Leader选举:
redis 采用raft协议来进行选举.通过心跳机制进行选举,初始状态集群内的所有节点选举权重为0;当出现无leader状态,开始触发选举,每个节点进入自荐模式,选举权重+1,raft的定时器机制是随机时间,这个是特点.
sentinel节点在与主库通信时进入主观下线状态,那么就会出发选举,首先自己成为候选者,按照正常情况,该节点成为leader的机会就很大,相对其他sentinel节点获得消息都是被动的.
sentinel选举流程尊崇raft的协议流程,自荐、拉票、统计票、上位.
sentinel中选举leader的一些细节:
半数投票数达成,还需要sentienl中配置的最小投票数也达成才视为选举成功.否则重新选举
故障转移:
先选出新的master,将其配置文件内容进行修改,配合也要修改sentinel集群自身的配置文件.
然后试图修改崩溃的旧master配置文件,尝试启动
如何选择从库上为主:
主观下线不被考虑
slave-priority 上主的权重.优先考虑
如果都没,就相比两个从库的偏移量,偏移量大的表明内容更完整
如果相同,那么选举run_id最小的,run_id代表该redis实例的重启次数.
Redis的集群和分区:
分区将一堆整体数据,分布在不同的redis库中
sentinel本身不支持分区的;
分片键的概念与MySQL一致,ID优先.
range分区:与mysql一样,会出现存储不均匀,但实现简单,扩容方便.只能为数字ID,uuid没法用,雪花能搞,用雪花算法.
hash分区:用hash算法进行计算,存储相对比较均匀.但不容易扩容.如果数据量大,那么hash算法将会较为复杂,为了缓解hash的问题,出了升级版hash,一致性hash:hash环.能解决分区扩容时的重整问题,如果扩容和缩容,那么只需要重整新增库的左面节点之间的数据,不需要整体重整呀.但是节点分布不均匀,会造成hash环偏移,所以需要设计好节点在hash环的位置,也可提供虚拟节点,对分布不均匀的节点进行映射,落到虚拟节点左侧的数据,将存储到映射的真实节点.相对缓解hash环偏移的问题
客户端分区:

在客户端进行分区操作:
客户端通过规则进行写入不同的redis库,客户端含有连接池,存储不同的redis连接(Jedis),但要做的处理相对更大,多个客户端势必会造成冲突,而且只能通过hash来搞,不是很理想.不太推荐用
Redis Cluster 官方分区方案:

5.0之前需要搞ruby,才能用.5.0后直接redis-cli
集群中每个主相互通信,代理通信每个主库,但每个从库只通信自己的主库啊,别闹,小弟可别乱搭腔.
Gossoip协议是cluster的传输协议,病毒式传输,随机找两个节点发送消息,以此类推.
一些通信命令:
meet:新节点申请加入.
ping:在吗?
pong:我在!
fail:有节点挂了!
publish:来来,打麻将了啊!有人吗!传播下去啊!
slot节点插槽:
有0-16383号插槽,把这些插槽均匀而连续的分配到所有的节点.写入请求来到时,通过CRC16的hash算法计算%16384,匹配到固定的插槽,根据插槽找到对应的节点库,将写入请求转发到redis库,hash冲突没有问题,形成hash链,插槽可存储很多.
优势:
多主性能提高,负载均衡、读写分离
高可用 主从复制,无中心节点,多主优势.可故障转移
高扩展 插槽概念,重整效率快
原生,直连集群环境,不通过代理连接.自己就是个代理嘛.
搭建方式:
安装redis.老流程没任何改动.
配置文件:
cluster-enabled yes 自动集群
启动写个脚本搞一下.
当配置了集群后启动redis时,就会生成一个node.conf配置文件,里面含有各个节点的配置信息,但是如果开启集群模式,那么里面只有自己的节点
集群模式启动:
./redis-cli --cluster create 集群下的所有节点IP:port --cluster-replicas 1
*--cluster-replicas 1 这个代表主从结构中从库数量,那么1就为一主一从,那么集群中主从结构的数量就为num/2 如果为6个节点,那么就有三个主从结构.排在前面的节点会被选为主机.
必须是新的redis库,不能有过数据记录.否则无法创建.
客户端连接集群:
./redis-cli -h ip -p port -c
Redis cluster分片:
moved重定向:

在写入时,会根据hash计算后的插槽值,选择节点,插槽如果不是当前连接的节点,那么会通知客户端,重定向到匹配的节点,再进行写入操作.
ASK重定向:

插槽迁移时出现.
当准备重定向插槽刚好被迁移至新的节点,那么旧节点就会发送给客户端一个ask重响应,表明我被移走,告知客户端新的节点信息,客户端再去向新节点发送写入.
moved和ask的区别
1、moved:槽已确认转移
2、ask:槽还在转移过程中
JedisCluster:

智能的客户端,将分片的计算,由服务器转换到客户端进行处理,它要存储所有节点信息jedis pool,并存储插槽与节点之间的关系 映射缓存,
如果jedis cluster 写入请求时与连接点不匹配,服务端处理后会返回moved异常,jedis cluster重新获取插槽映射缓存,再重新发出请求,但不超5次,超过5次则抛异常 too many cluster redirection 你咋老重定向呢?!没完啦?
Redis cluster迁移:
分片迁移,增容,缩容,重置插槽分布.
1:迁移的节点状态改为importing.
2:被迁移的节点将改为mgrating
3:进行数据迁移
4:重设两个节点的状态.
添加节点:
redis-cli --cluster add-node ip:port 集群中随意节点的IP:port
这么做只是添加,但没重新分配插槽.
./redis-cli --cluster reshard 节点ip:port
提示分配多少插槽给新节点:
提示接收插槽的节点ID
提示源节点IP或者如何分配:
all是从各个节点进行均匀分配
done 输入从哪些节点分割 然后输入done开始
提示是否开始迁移: yes.
添加从节点:
./redis-cli --cluster add-node ip:port 集群下随意节点的IP:port --cluster-slave --cluster-master-id 主库id
缩容:
./redis-cli --cluster del-node ip:port 从库id
Redis cluster故障迁移:
主节点之间相互ping pong
配置文件中有cluster-node-timeout 10 表示节点一段时间内无响应,
如:A主节点认为该B主节点主观下线
再向其他主节点发送ping 时就携带B主节点挂了的信息,其他节点向B主节点发送平时,也会得知B主节点挂掉,比如C节点,也会向A节点发送Ping 时携带B节点挂了的信息,然后A节点就这样收收,如果超过半数都发送了B点挂机,那么A节点认为B点挂掉,将广播发送B点挂掉的信息,B的从节点收到广播,开始进行选举,主从选举那段流程.
但是区别是,这里的投票是其他主节点投票,从库不参与了.
Redis cluster手动故障迁移:
1从节点发送 cluster failover命令(slaveof no one)
2:从节点通知其他节点需要手动更换主节点
3:主节阻塞所有客户端执行命令 10s
4:从节点从主节点的ping中获得偏移量信息
5:从节点复制达到主从一致,进行选举为主节点
6:切换完成,原主节点给所有客户端发送moved指令重定向到新节点
如果主节点已下线,那么 cluster failove force(直接进入选举) 或 cluster failove takeover(直接变为主节点) 进行强制切换
Redis cluster失效场景:
半数主节点挂掉.
主从结构下所有节点全挂了.插槽全丢掉了...那就完了.也叫slot不连续.
Redis cluster 副本漂移:
在主从集群中, 一个主从节点的从节点较多,而另一个主从节点中从节点较少,那么可以将较多的从节点飘移给较少的
主从节点中.
在代理proxy进行分区操作:
代理进行计算进行选择不同的redis库来写入.客户端直接将写入请求发送给代理,代理来根据算法进行选择写入的库,proxy也可实现故障转移.Codis(豌豆荚)就是一个代理框架. twemproxy 推特开发的
Codis:

核心组件:
codis server、codis proxy、codis fe、codis group
集群搭建流程(粗略,仅说明步骤):
环境需求:codis、go、zookeeper、jdk
需要搭建zookeeper,做为节点记录来使用
安装;
配置zookeeper的配置文件:
改dataDir:
配置codis:
zk:zookeeper的地址
product:集群名称
proxy_id: 代理ID
net_timeout:
配置redis 配置文件到codis的执行目录下:
配置redis sentinel
管理页面的一些细节:
group管理主从,所以要先添加组,再添加主从库
总共有1024插槽,均匀的分布在每个group中,需要点击reblance完成 .新增一个组 就会在均匀的分配并把部分数据迁移.
分片原理:
默认分配1024个插槽.写入的key进行crc32算法后%插槽,得到对应槽位.插槽大小可设置.这个插槽与主节点的映射关系存放在proxy中.
codis proxy集群后,插槽映射关系是存储在zk上,也可是Etcd(rest风格的注册中心),当dashbord修改后,zk节点信息修改,通知proxy集群.
优缺点:
优点:
对客户端透明,不需要关心codis如何组建管理.
可在线数据迁移.添加新组时插槽移动可自动迁移数据.
高可用.主从结构没问题,proxy可集群
最大支持1024的redis实例,可容纳海量数据
数据自动的均衡分配到每个组内
高性能.那是必然的
缺点:
只能使用自带的redis,不能使用原版的redis,且配置较为复杂.
不做proxy集群的情况下,性能会降低很多,必须做proxy集群.
redis的一些命令无法支持.
缓存的知识点:
线程不安全的缓存,就是我目前用的那种,HashMap+List
高并发级的缓存.guava cache框架. currentHashMap是线程安全的,但是要自己组装一下.
文件缓存仍在nginx里.
中间缓存就是redis了.也会用在mybatis二级缓存使用.
缓存命中:
从缓存中查询key的成功次数,没有查到就有去数据库查的风险,数据库会有压力.所以要根据info命令来查看缓存命中率来设计缓存的存储保证缓存的稳定.
缓存预热:
为了系统稳定,可用性好,需要将一些热点数据提前加载到缓存(jvm或者redis都行),也可异步加载DB的数据库.但不要求实时性.实时数据可别这么搞,差错很大.
缓存的一些问题:
缓存穿透:
数据库因为其设计原因导致无法做高并发的查询与写入
而这时,我们为了高可用性,就需要将数据库一些高频查询的数据进行放入缓存.当某段数据第一次被查询,redis中并没有查询到
那么就会去数据库进行查询并放入redis缓存中,这就是缓存穿透.
解决缓存穿透的问题:
1.设置空缓存,既没有查到也进行set,防止穿透,设置短TTL时间,进行定期更新数据库,但绝不允许用户直连库来获取数据.
2.布隆过滤器:
将查询的值在一个集合过滤器中先查询,如果有那么再允许进一步操作.防止恶意请求查询.
过滤器的集合是一个特殊的集合,采用二进制向量存储.通过crc16+crc32+自定义hash函数来获取到几个位标记,在对应的位标记设1. 这样在查找时 只需要通过hash计算后就能快速定位到这个key. 效率很高,将字符串转了位的概念,查询就很迅速.可有效拦截垃圾的查询.
缓存雪崩:
大面积缓存失效,突发性大并发.导致穿透到数据库.
redis重启导致所有缓存清空,直接穿透数据库.
解决办法:
设置不同的过期时间,错峰失效
设置二级缓存,在jvm缓存或其他缓存进行加载,防止查询数据库.(不一致风险很大)
设置高可用,防止redis崩溃(不一致的问题会有)
缓存击穿:
某一key在某一时间大量并发请求,导致数据库压力剧增.
如何解决:
分布式锁防止并发击穿,将并发进行串行化.阻塞大量数据库的请求,让缓存与数据库交互.
对于热点数据,不设过期时间,但会导致数据不一致,需要定时处理.
缓存穿透雪崩击穿.最可怕的情况.其实就是服务器崩了.后面还有cloud的熔断器呢,不会让他真崩.最多降低一些请求成功率.对吧.
数据不一致的问题:
缓存,永远只能保持最终一致性.针对不同的行业,对于数据实时一致性要求不一.决定出先更新缓存还是先更新数据库.
但会有最佳方案,比如延时双删:
先删除缓存,更新数据库数据.
间隔时间后再删除一次缓存
将缓存再设置TTL,双重删除来防止脏读
设置脏读日志,定时任务去比对进行删除.
binlog配合mq进行通知删除
以上这几条方案.最终一致性的间隔为越来越大,从秒级到小时级再到日级.但都能保证最终一致性
缓存与数据库的一致性:
更新策略:
redis LRU LFU缓存淘汰策略 一致性差
TTL被动更新 一致性一般
延时双删主动更新. 一致性很强
定时任务异步更新. 一致性弱.
mybatis二级缓存redis整合:
开启二级缓存,将缓存存储到redis.
数据并发竞争:
redis集群同时set同一个key.导致问题产生.
解决方案:
分布式锁:
多个redis向锁中心来获取锁,该锁拥有互斥性,犹如茅坑.每个人获得锁才能操作,但谁先获得锁呢?用时间戳来进行排名先后,用分布式锁来保证set的串行化.保证set是一次一次执行的.
消息队列就是串行化的,set时发送消息,队列负责串行处理.
热点数据:
一个数据突发性被大量请求,秒/几十万请求量.
预估热点数据;
设置计数器,根据统计来嗅探热数据.
如何解决这个热数据的问题:
设置本地缓存,但不保证数据一致性.
热点数据进行备份漂移,将分片数据形成的问题来进行防止,将热点数据复制到其他热点上,使用算法将热点数据的key进行加值,当查询时根据算法来负载到不同的redis.
直接熔断,但不能用在关键的页面.
大数据:
大量占用内存,在集群中无法均衡.
造成redis的性能下降,主从复制异常.
删除时,会导致服务阻塞.
如何发现:
--bigkeys命令来查找,但会很慢
rdb文件 通过rdbtools分析rdb生成csv导入数据库来发现
如何解决:
大数据可以考虑进入mongodb而不使用redis
集合拆分 hset、list、zset、hash,按照规则拆分到多个集合.
不使del,会让redis阻塞. 使用unlink,先将key和value进行解除关联.然后进行删除,主要是该操作为异步.
Redis分布式锁:
watch:乐观锁 监控这个key的状态嘛,去试一下,如果变化就不能继续操作了.但是是在事务开启的情况.
先watch一个key,然后开启事务,修改这个key,提交事务;
并发下,失败的是提交事务时,已经被提交了哦,watch监控数据不一致了.
setnx:在单redis上使用,就没法高可用
如果该key不存在,那就set,否则不成功.
主从下会出现多个用户获得锁.
业务没处理完有可能key过期,无法续租.
业务决定使用场景:
分布式锁为CP模型,强一致性.
redis是AP模型.强可用性.
Redission分布式锁:
实现原理:
加锁:
客户端本身先做锁处理,再hash算出节点.lua脚本来加锁.
通过机器客户端IDrandomUUid+:+threadId来进行加锁,采用hset,value设置为1,获得锁的用户也可也可以一直加锁;
释放锁:
当释放锁后发送消息来通知锁可被使用了.
不是当前用户加的锁 不可解锁
重入锁,需要一直解.一层一层的删掉
全都解完了再发消息,锁被释放了.1
分布式锁实际应用:
防止并发竞争:设置时间戳;
超库存现象:
两个线程都获取了锁,但下单的数量库存不足支撑2个订单数量;
先加锁,然后再查询库存.不适宜秒杀.秒杀还是watch乐观锁.
Zookeeper分布式锁:
临时节点创建相当于上锁,节点删除相当于释放锁.
etcd锁:
这三个锁的对比:贴图
阿里redis设计风格:
:分割 尽量简写key
拒绝大key 过大就分割, 更大就入mongoDB,这么大的bigkey不要del,不要设置过期时间 触发产出也会阻塞redis
注意控制key的生命周期.
禁用命令:del,flushall,flushdb;
单线程的redis为什么很快:
内存操作,不会与磁盘频繁IO
做DB时或数据过大,做集群分片.
数据结构简单,专门设计,压缩处理.
单线程不会涉及并发.
事件驱动模型.
IO多路复用.
使用多种通信协议, lua pingpong 管道 发布订阅 事务都可以
持久化时fork子进程,但数据量多大时 主进程在fork时会被阻塞.所以要注意控制数据量.















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









