







我们先展示一下k-means方法的过程:
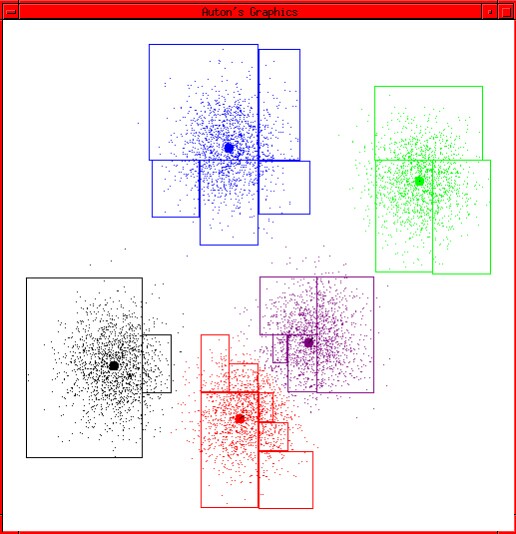
如图给出一个数据集:
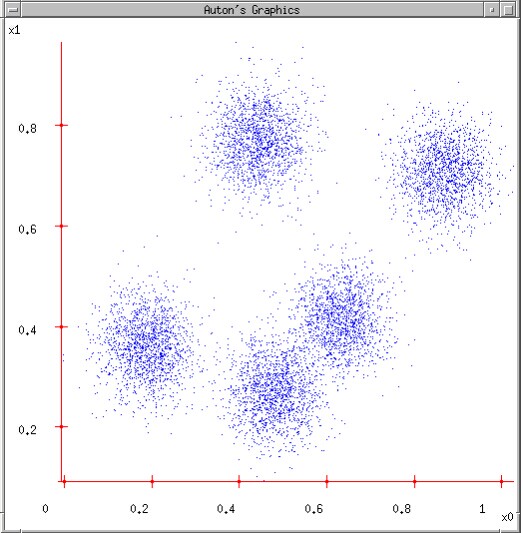
1.我们猜测它可以被分为5类,因此我们初始化k=5,然后我们随机设置5个中心点
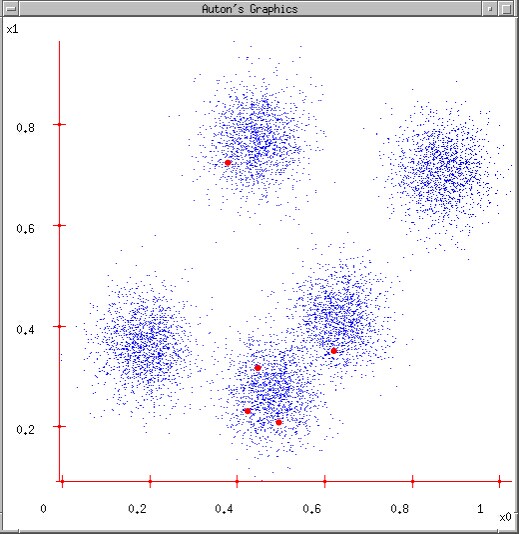
2.将数据与最近的中心点相匹配:
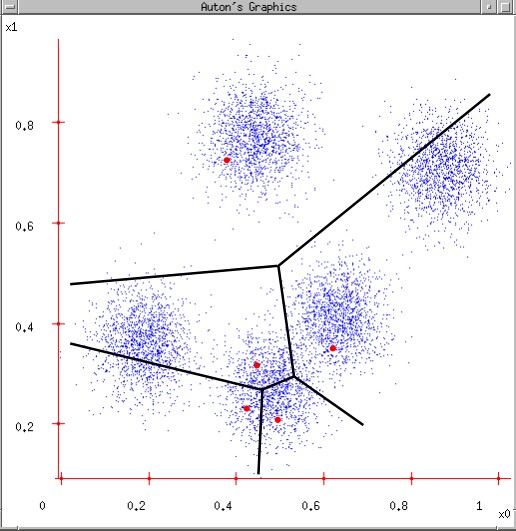
3.所有分为一类的数据重新计算中心点(均值):
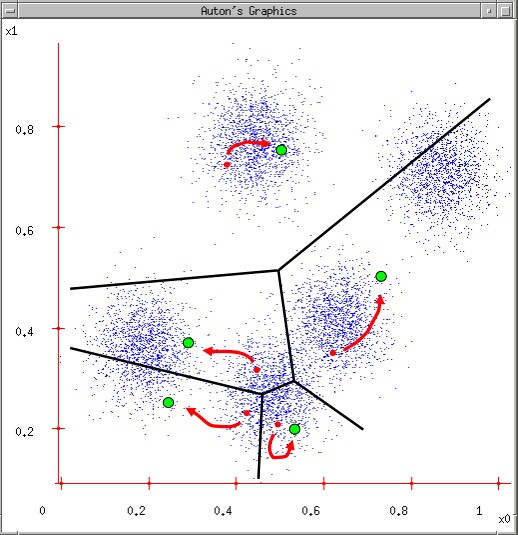
4.循环2,3过程直至收敛
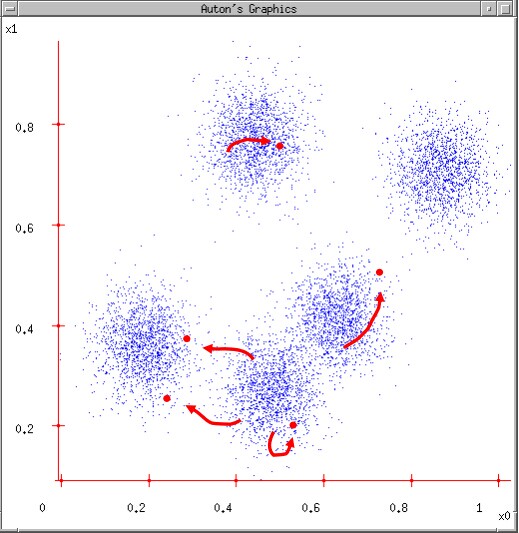
让我们审视一下整个的收敛过程:
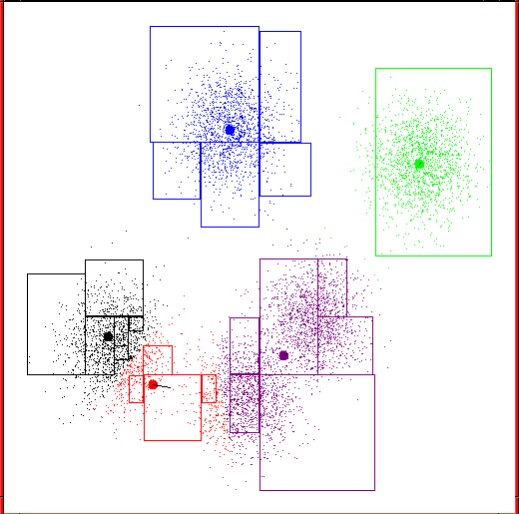
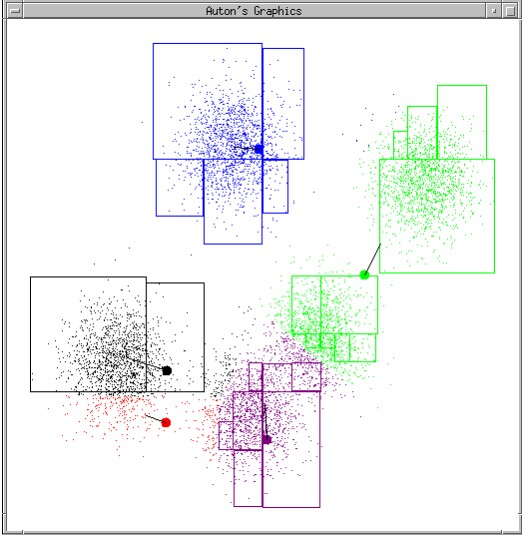
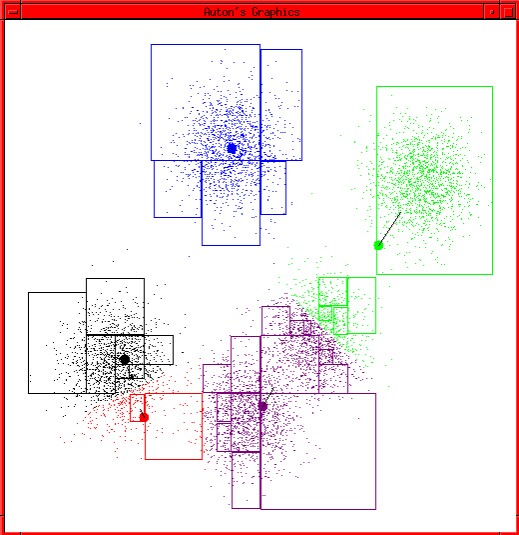
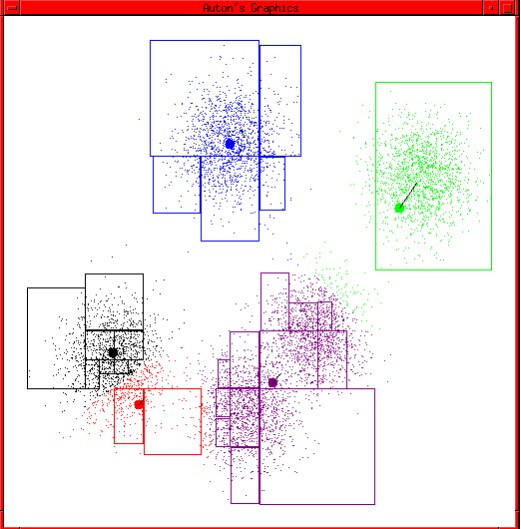
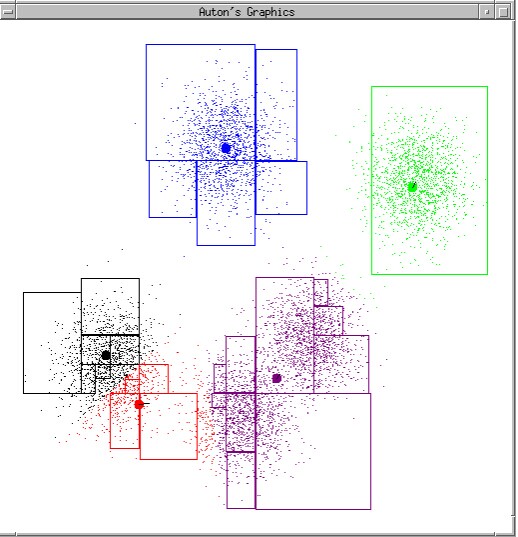
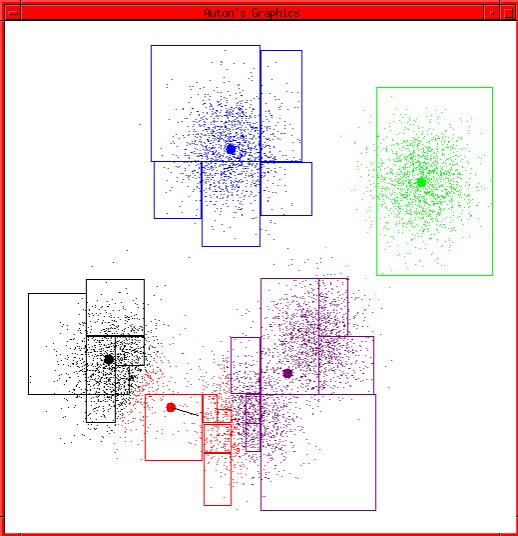

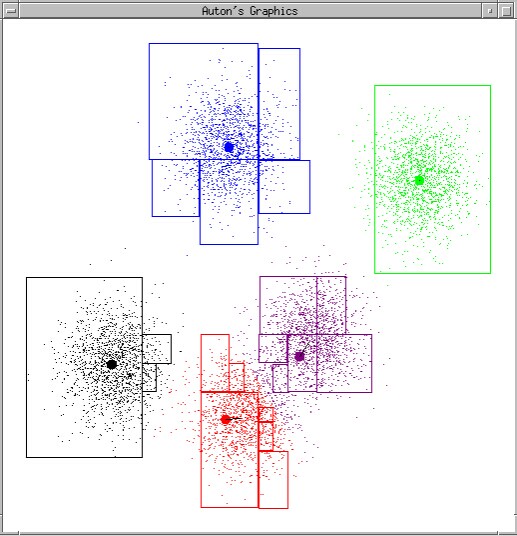
同样的,为了解决这个问题,我们也引入一个失真函数,在此之前我们先给出两个函数:
编码函数:
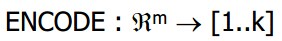
解码函数:
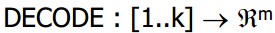
我们定义失真函数为:

又
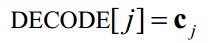
所以
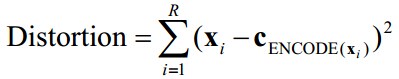
我们的目的是最小化失真函数,那么各个中心c1,c2…..,ck在失真函数最小的时候都会具有什么性能呢?
(1) xi必须被离他最近的中心所编码,否则我们可以通过替代ENCODE[xi]为最近的中心来减少失真函数
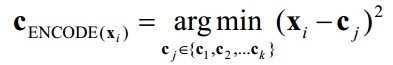
(2) 失真函数在每个中心点的偏导为0

在最小的情况下:
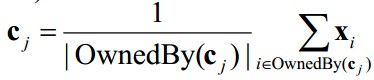
也就是说,每一个中心点,都是属于该类的数据的几何中心(均值)
事实上我们是可以找到一种分类方式,其失真函数不是最优的,但是算法依然收敛:
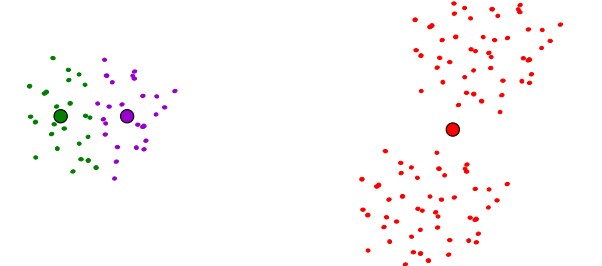
所以,算法的开始设置很重要,我们通常都会随机设置起点,第二点尽量离第一点远,第j点尽量离前j-1点远。但是怎么去选择中心点的个数呢?
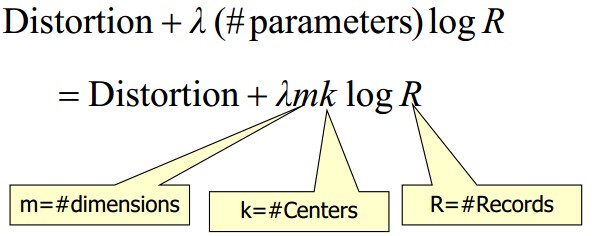
一个通用的方法是最小化Schwarz Criterion
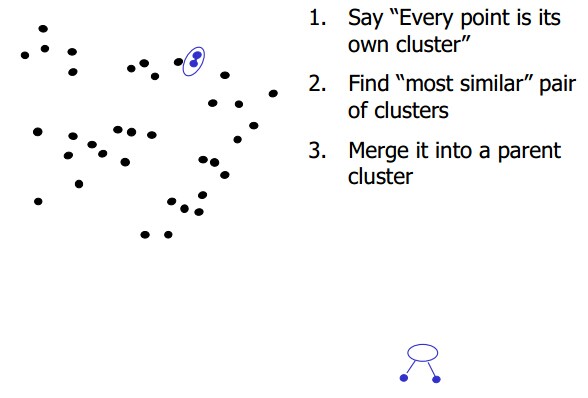
下面介绍一下单链接层级聚类:


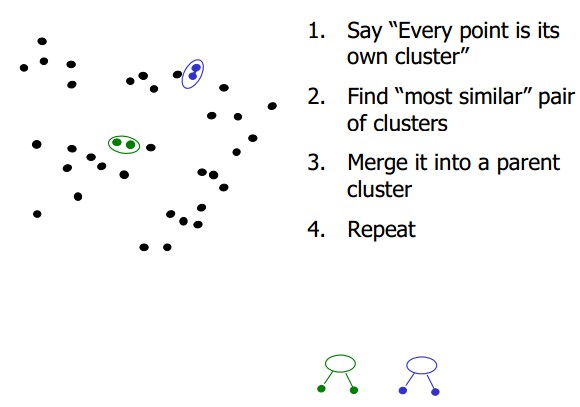
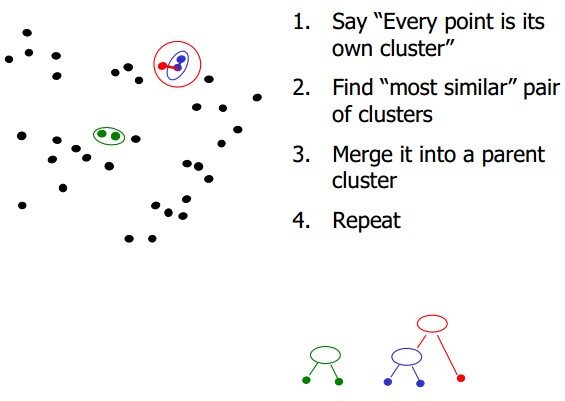
我们以什么标准来衡量相似度呢:
在每一群中的最小距离(这里通常使用欧几里得最小生成树)















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









