






一 设计思路
1.1 系统定位
- 客户环境是一个不对外开放的封闭网络
- 公司方对客户环境的操作需要通过中间的人工过程
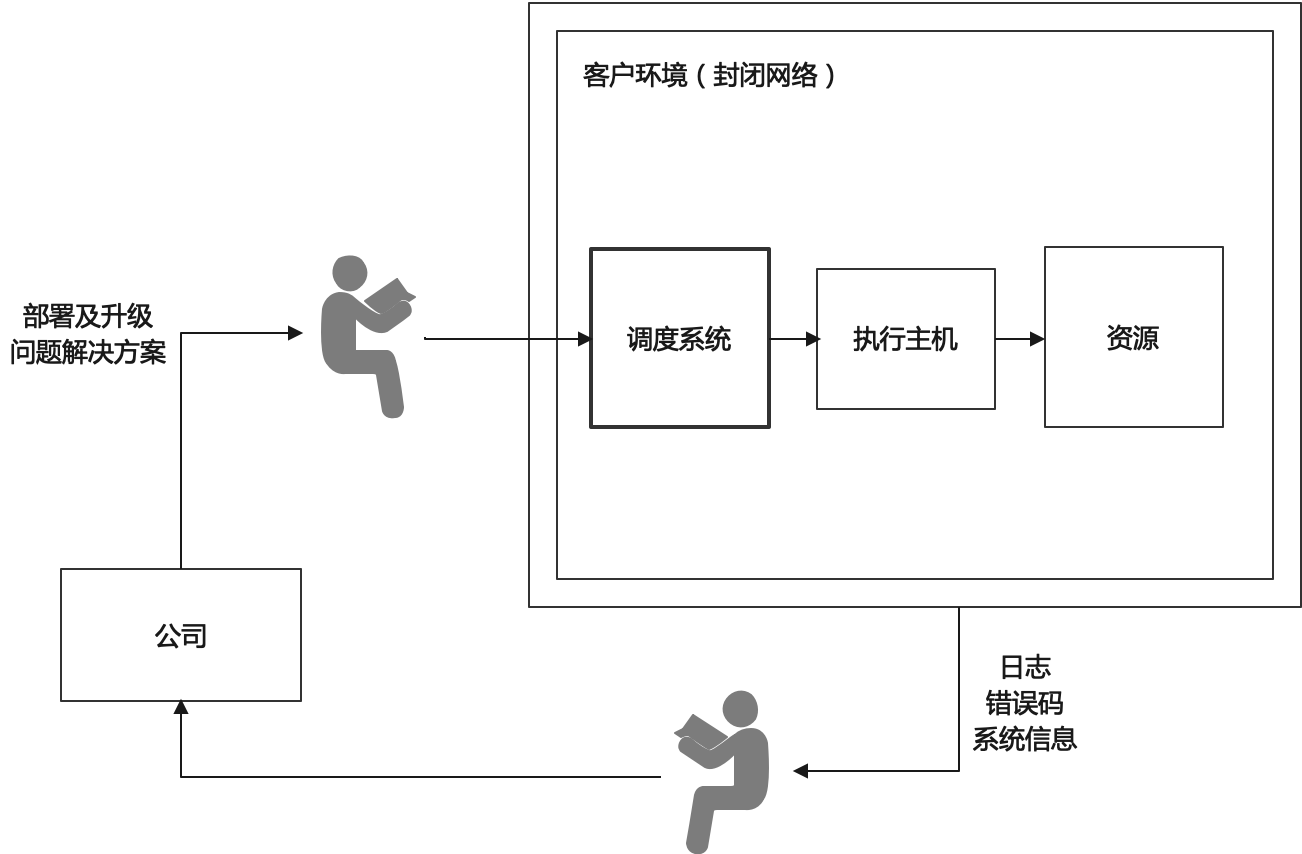
1.2 设计目标和原则
设计目标:
- 提升调度系统的稳定性
- 降低调度系统的维护成本(降低人力成本)
- 调度系统具备长期可用性
设计要点:
- 高稳定性
- 丰富的日志和错误码及导出查看机制
- 高容错性,丰富的问题处理接口和方式
- 可扩展性
二 整体架构
核心业务流:
- 任务管理系统:负责系统任务数据的增删改查及相关的操作
- 作业管理系统:负责系统作业数据的增删改查及相关的操作
- 任务/作业调度:包含两个部分
-
- 任务调度(TaskScheduler):根据任务的配置,进行任务的实例化和 Job 执行规划
- 作业调度(JobScheduler):根据任务配置和执行规划,执行 Job
- 作业执行(JobExecutor):根据当前的 Worker 情况,分配 Job 的执行资源,调用 Job 的执行脚本或程序代码
- 执行主机(Worker):负责作业的执行
- 执行目标主机及目标程序:脚本控制的目标主机以及目标程序,如果可监控,尽可能也将这些主机和程序进行监控(部署系统的 monitorClient )
守护业务流:
- 异常管理系统:存储系统发生的异常,并可针对异常进行处理方式的配置
- 异常处理(ExceptionHandle):搜集任务/作业执行过程中的异常,并根据配置进行自动化的处理或者智能化的处理
- 日志系统(LogSystem):任务/作业执行过程中的日志搜集
- 监控系统(Monitor):任务/作业执行过程中的监控数据搜集
- 数据/日志导出导入系统:导出系统方便客户导出任务/作业的日志和监控数据以及执行过程中的环境信息;导入系统,方便运维人员使用这些数据进行分析和查看

三 核心数据结构及逻辑
3.1 作业(Job)
3.1.1 数据结构
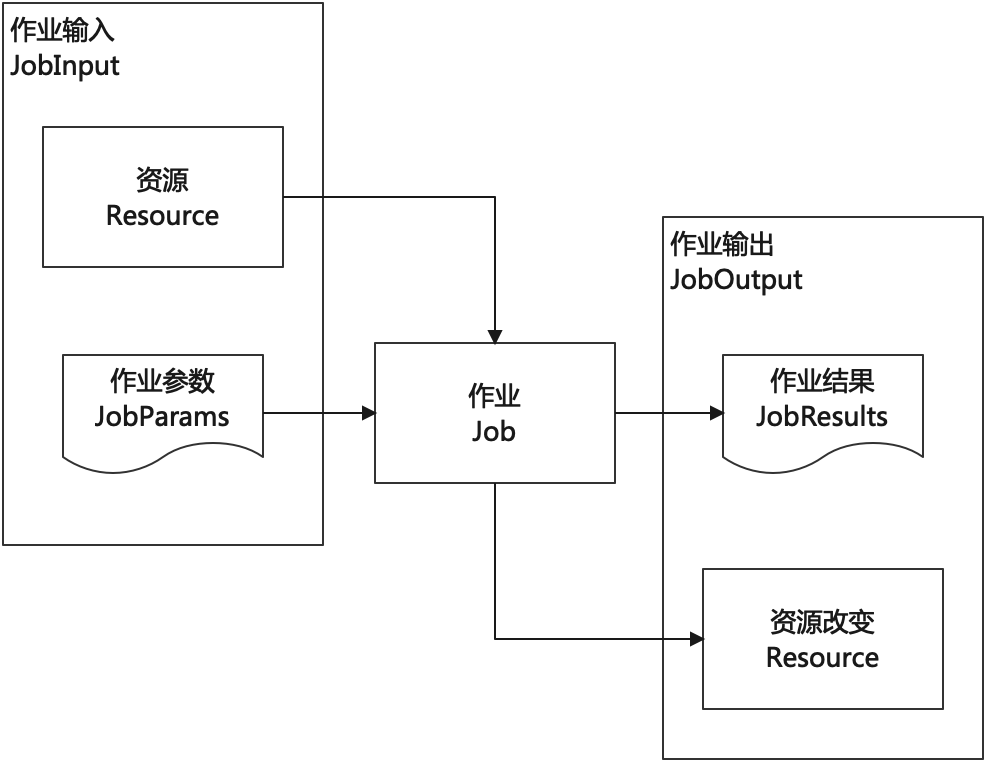
Job 是系统中的最小执行单元,一个作业包含作业输入和作业输出:
- 作业输入(JobInput):
-
- 包括作业参数(JobParams)和作业资源(Resource)
- 作业可以不包含任何输入,如等待作业,负责作业的一定时间的等待
- 作业参数包含两类:
-
-
- StaticParam:静态不变的参数,设置和执行时相同
- DynamicParam:动态参数,在执行时根据任务配置和任务执行情况动态注入
-
-
- 作业资源包含两类:StaticResource,DynamicResource
- 作业输出(JobOutput):
-
- 包括输出结果(JobResults)和作业资源(Resource)
- 作业没有任何输出,但必然引起状态的改变(不引起任何变化的作业,也就没有存在的必要了)
- 输出结果类型:
-
-
- Text 文本
- Number 数值
- Boolean 布尔
- File 文件(提供文件下载)
- Document 文档(提供文档预览和下载)
-
-
- 作业资源的改变必须转成 JobResult 才可查看
- 作业输入注入
-
- 定义好任务结构后,根据 JOB 的定义,自动生成参数表
- 任务填写参数表,作业执行时,通过任务的参数表获取相应的参数
- 同一 Job 可定义多份参数:根据参数的份数,可生成多个平级的 Job
-
-
- 引用格式为:$.JOB['323'][0]
-
-
- 通过 $ 符号,可定义参数的注入规则
-
-
- 如定义参数表达式为 $.JOB['323'].RESULT[0]
-
- 作业输出注入(前端页面可以进行用户友好性的处理):
-
- 如 Shell 脚本执行是没有返回结果的,那么如何构建作业的返回结果?
- 定义基础引用:$(任务执行上下文的引用)
-
-
- $.JOB['323'].OUTPUT(引用任务下 ID 为 323 作业的屏幕打印)
-
-
- 输出计算方式
-
-
- 正则提取:{$.JOB['323'].OUTPUT}:REGEX:(?<=开始).*?(?=结束)
- 逻辑表达式:{$.JOB['323'].OUTPUT} == '4', {$.JOB['323'].OUTPUT)}#'5'
-
-
- 文件注入:File(/home/sk/output/hello.zip)
- 输出列表和 Map:
-
-
- 输出可以是一个 List ,也可以是一个 Map
- 输出之间可互相应用,格式为 $.JOB['323'].RESULT[0],$.JOB['323'].RESULT['FilePath']
- 也可以引用输入参数:$.JOB['323'].PARAMS[0]
-
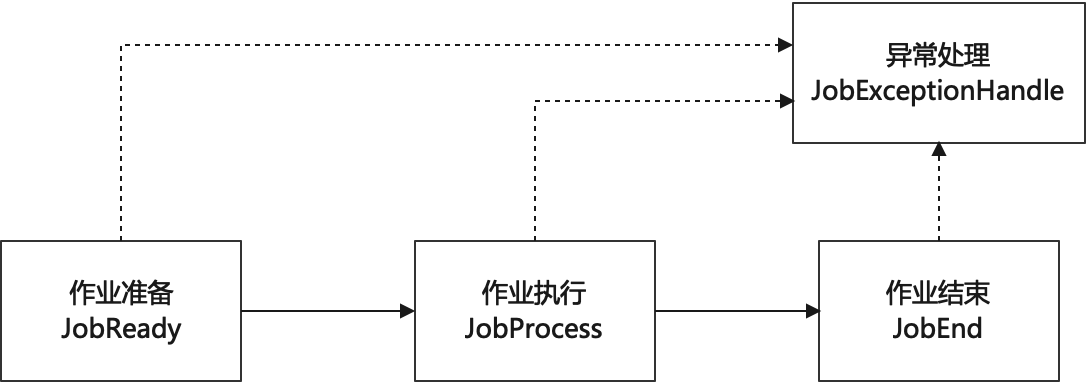
3.1.2 作业执行过程
一个作业的执行分成三个阶段和异常处理:
- 作业准备(JobReady):
-
- 参数注入和资源准备
- 进行参数校验和资源检查
- 作业执行(JobProcess):
- 作业结束(JobEnd):
-
- 确认作业的执行状态,生成作业执行结果
- 作业执行结果注入
- 作业执行成功的判定:
-
-
- 有明确的判定的依据:根据判定依据判定作业的执行情况
- 无明确的判定依据:作业执行过程无异常抛出,进程执行未超时结束
- 唤起式作业:如果作业的执行目标是唤起一个任务,则该任务被唤起后,作业执行成功
-
- 异常处理(JobExceptionHandle):作业抛出异常后的处理
- 作业监控(JobMonitor)
- 作业告警(JobAlert)
3.1.3 作业类型
3.1.3.1 按作业内容分类
| 基础类型 | Shell 脚本,Python 脚本,Linux 指令,Http 请求,Sql 语句,Java 代码(使用动态加载技术?) |
| 辅助类型 | 条件判定作业,等待作业 |
| 特殊类型 | 作业组(JobGroup),任务(Task) |
| 内置作业 | 文件读取,文件存在性判定,FTP 文件下载,文件解压,文本文件 Concat,HTTP 请求,SQL 查询,文件切分 |
3.1.3.2 按作业性质分类
- 同步作业:直到作业结束,系统才释放作业执行的资源
- 异步作业:
-
- 作业开始后,系统立刻释放执行作业的资源,用户可选择等待一段时间后进行作业执行结果的校验和生成,或者不做任何处理,系统自动将作业标记成成功
- 异步作业需要更复杂的业务员逻辑进行结果的处理
3.2 任务(Task)
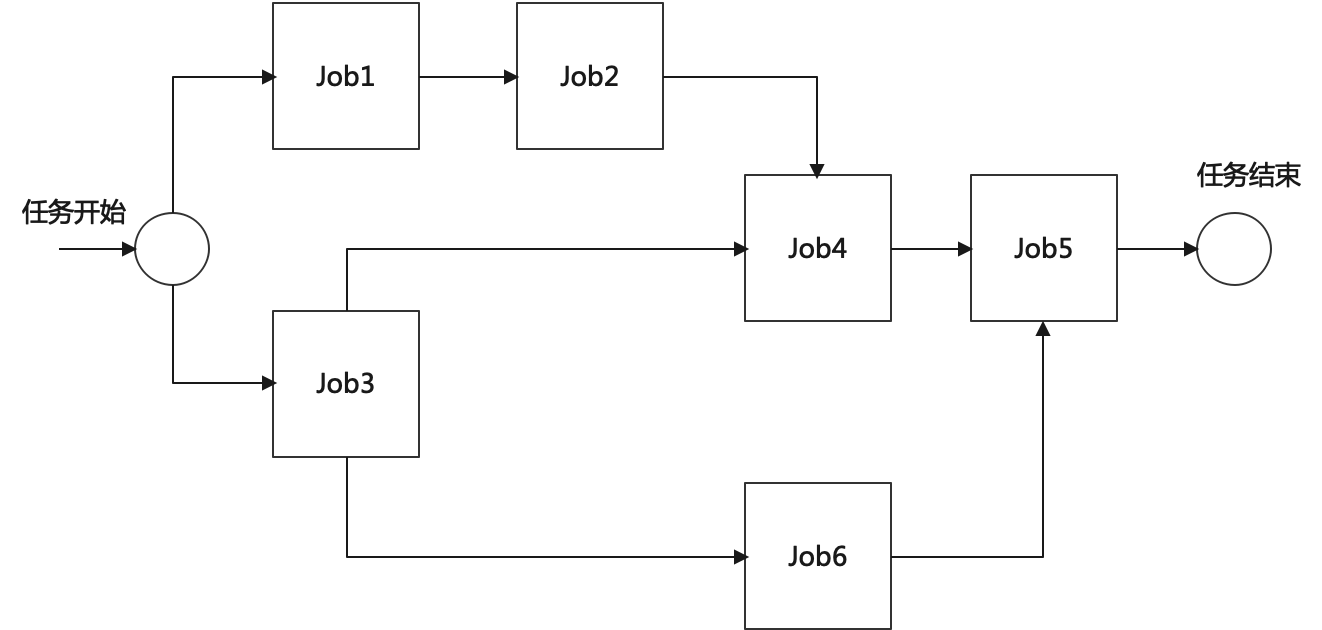
任务是基于特定的目标,使用 Job 构建的 DAG 图
3.2.1 数据结构
3.2.1.1 DAG 图
任务的数据结构如下图所示
存储结构:
- 任务参数(taskParams)
- 节点列表(nodeList):List<TaskNode>
- 任务节点(TaskNode)
-
- 节点作业(job)
- 节点序号(sort):离根节点的最长距离
- 前置节点(preNode):该节点依赖的节点,节点序号也等于最大前置节点数量
3.2.1.2 特殊类型的节点
包含批作业的任务
- 当任务中的某个 Job 节点的输入参数,在 Task 中被定义多份时,改 Job 即为批作业
- 批作业在任务执行时会根据参数的数量生成多个实例,数量等于参数的数量
- 批作业中的作业的序号都是相同的,如果批作业有前置节点,则他们的前置节点都是相同的

带条件判定作业的任务
- 当一个任务根据条件有不同的作业路径时,需要使用到条件判定的作业
- 条件判定的作业
-
- 判定条件:获取特定的资源和数据
- 分支:根据不同判定条件的不同取值结果,判定作业的后续作业不同
- 如下图,条件作业获取的 x 值,如果值为 1,则进行 Job4, 如果值为 2,则先执行 Job1 ,执行完 Job1 后,再判断条件是否达成,如果未达成,再执行 Job1,如果达成,则执行 Job4

带等待作业的任务
- WaitJob 可停止任务的执行,并等待特定时间后,再次启动任务后续过程
- 可以用于异步任务,或者 Job 的控制对象是外部资源时,可避免任务对资源的过度占用

3.2.2 任务执行
3.2.2.1 任务实例化
任务在执行时需要实例化为任务实例。一个任务被实例化,意味着一次任务执行。任务实例化的可能来自于:
- 手动执行任务:手动触发任务执行
- 定时执行任务:在一定的时间触发任务执行
- 定期执行任务:特定时间间隔或者特定时间点执行任务
- 自动触发:比如,任务失败重试,可自动触发任务的实例化;达到特定条件,某任务自动发生
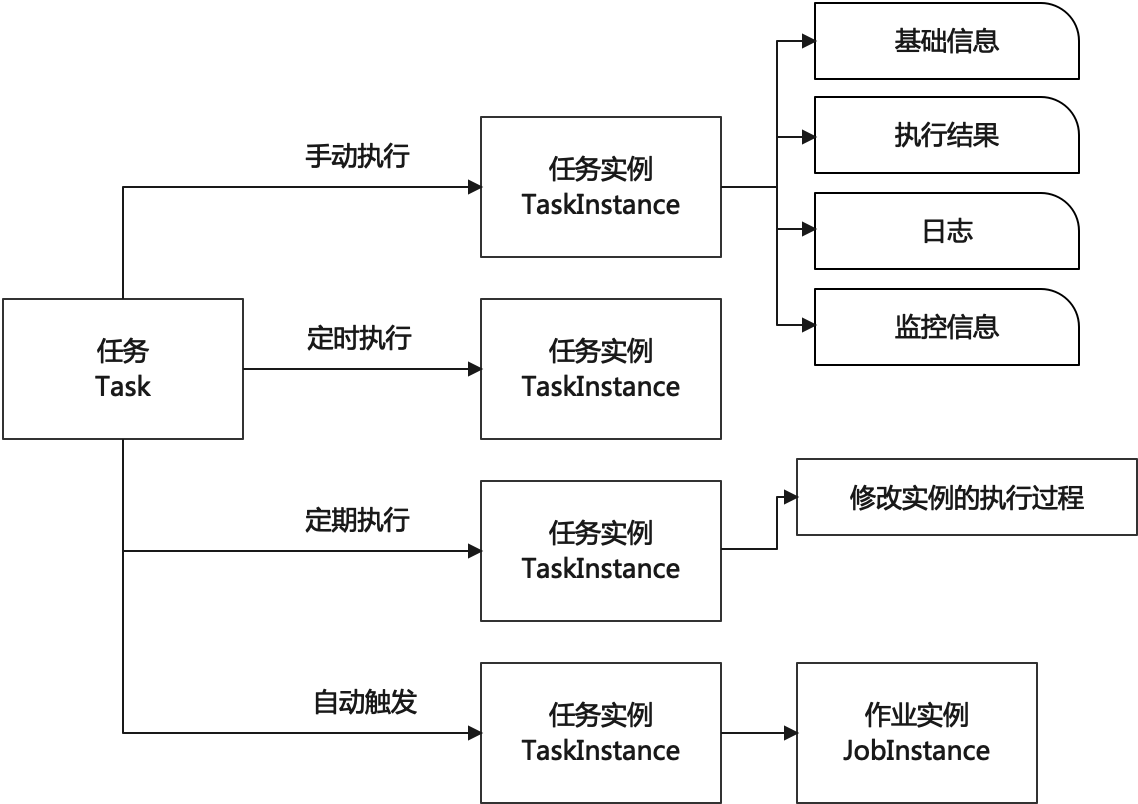
任务实例,在全生命周期,产生的数据有
- 基础信息:实例 ID,任务 ID,开始时间,结束时间,任务状态,异常描述,结果描述,执行次数
- 执行结果
- 日志:上下文日志,执行日志,Job 日志
- 监控信息:可监控 Job 的监控数据,任务执行过程中的执行器的监控数据引用
3.2.2.2 执行过程
任务为按路径执行
- 任务开始
- 构建任务上下文
- 开始执行 sort 为 1 的作业
- 有 sort 为 n 的任务结束,遍历 sort 为 n+1 的作业
-
- 如果有满足条件的作业,则执行该作业
- 如果无满足条件的作业,则进行条件等待
- 如果 sort 为 n+1 的作业不存在,表示任务执行完成
- 进行任务结果的判定和生成
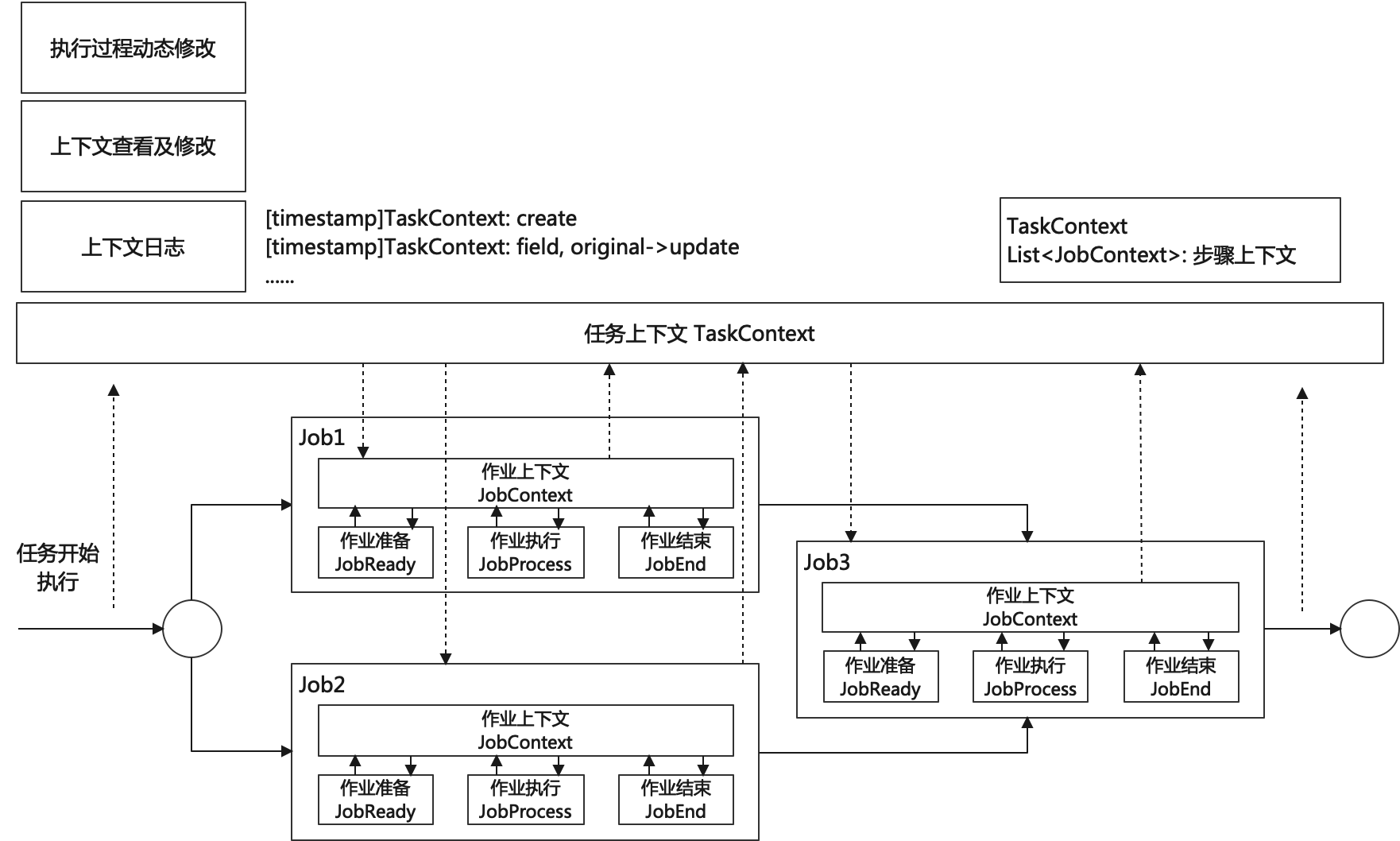
3.2.2.3 上下文(Context)
任务执行上下文(TaskContext):
- 任务开始后,将为每个任务构建一个上下文,任务上下文伴随任务的全生命周期
- 任务上下文可在任务的任何阶段被引用,可用于不同 Job 间的数据共享
- 任务上下文对任务状态进行管理
- 系统提供接口允许用户对任务上下文进行查看和动态的修改,为任务的异常处理提供入口
- 通过特定的标记,可以在任务和作业的配置中引用上下文中的数据,达到数据在执行时注入的目标
- 同一个任务在执行过程中也会为每一个 Job 构建一个作业上下文
作业上下文(JobContext):
- 每一个作业也都有自己的上下文,作业上下文,包含有对 TaskContext 的引用,允许作业引用其他作业的执行数据
上下文日志(ContextLog):
- 上下文日志记录了上下文从创建到每一次状态变化的时间点和内容
- 上下文日志可以有效的监控任务执行过程的每一个细节
- 通过上下文日志可以反演任务的执行过程
3.2.2.4 作业执行
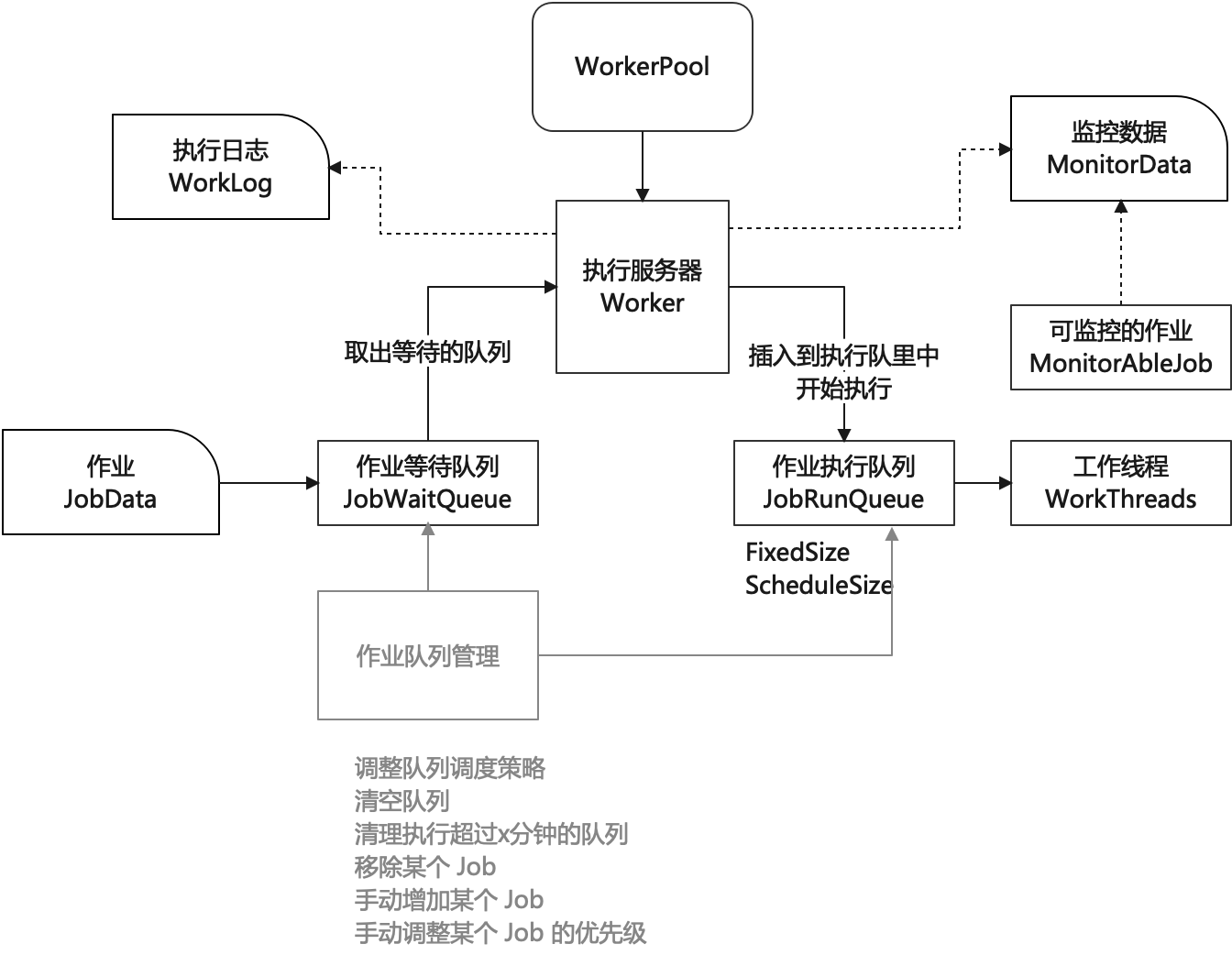
执行过程:
- 将任务的待执行的 Job 插入到作业等待队列
- 执行器从执行服务器池中选取空闲的服务器(如果只有一台,直接使用)
- 根据调度策略,将 Job 从等待队列中转移到执行队列中,并为其分配工作线程
- 如果执行器的执行队列无空闲位置,则作业一直等待,直到有空闲位置
- 设置有作业等待超时时间,如果等待超时,抛出等待超时的异常
日志及监控数据:
- 执行服务器维护有全局的执行日志和全局的系统监控数据
- 如果执行的是可监控的 Job,则记录作业的监控数据
- 如果执行的 Job 的目标服务器或程序是可监控的,则也采集相关的系统监控数据
处理接口:可以通过接口对执行器的作业队列进行操作
- 调整队列的调度策略,如 FixedSize,固定执行队列,ScheduleSize 根据负载调整队列大小
- 清空队列,被移除的 Job 抛出异常(可重试的异常)
- 清理执行超过 x 分钟的队列
- 移除某个 Job
- 手动增加某个 Job
- 手动调整某个 Job 的优先级
3.3 异常及错误码
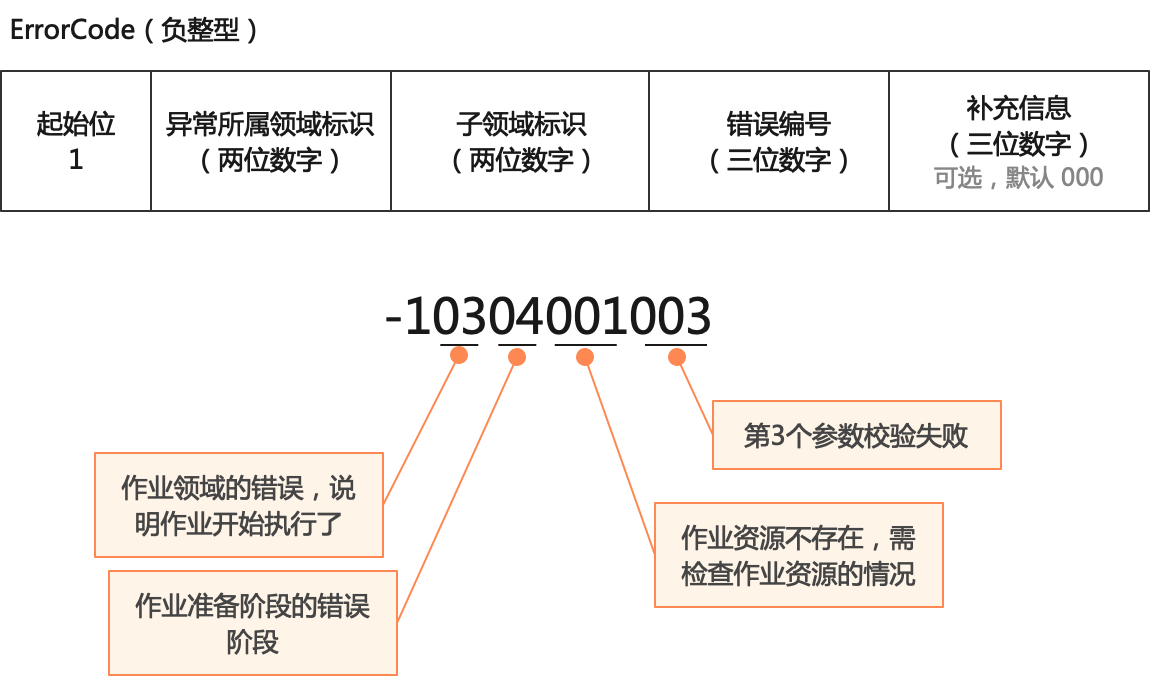
3.3.1 错误码(ErrorCode)
丰富的良好定义的系统错误码,可以极大提升系统的可维护性,降低系统的运维成本,因此时本系统的核心数据之一。系统错误码是负整型数据(Long),数据结构如下:
- 起始位,默认恒为 1
- 异常所属的领域或者模块的标识:两位数字,必填
- 子领域标识:两位数字,默认为 00
- 子领域下的错误编码:三位数字,必填
- 补充信息:三位数字,默认为 000,非必填
-
- 根据需要补充的额外信息,可用于更细节的错误描述
3.3.2 异常处理
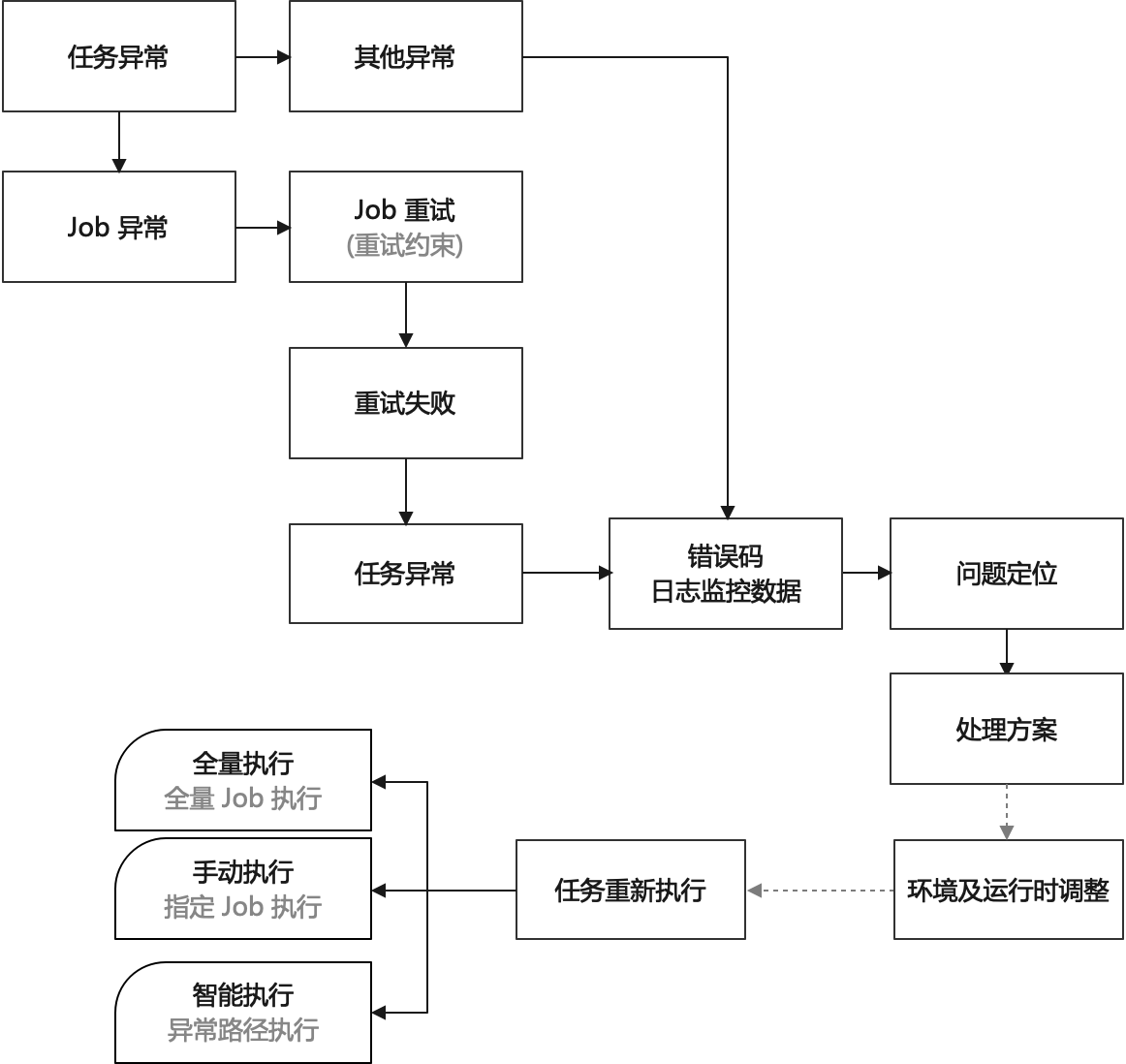
- 系统提供任务异常的处理入口,该入口可以对任务执行的上下文,系统的执行队列进行操作,并可选择任务重新执行的策略
- 任务异常如果是某个 Job 异常导致的,则处理过程如下:
-
- 进行 Job 重试,重试有一定的约束,如间隔 X 分钟重试三次,Job 重试策略可配置
- 如果在约束范围内重试失败,则任务标记为执行异常,同时抛出错误码
- 如果错误码较明确,则场外进行异常定位并提供处理方案(或者根据处理手册进行处理)
- 如果错误码不足定位问题,则导出日志监控数据,辅助定位
- 根据处理方案调整系统的环境及运行时的状态并重新执行任务
-
- 全量执行:任务重新开始
- 手动执行:重新执行某个 Job 及其依赖的 Job
- 智能执行:识别异常 Job,并重新执行依赖该 Job 的其他 Job
四 技术实现
4.1 整体结构

系统在技术实现上,可分成三个部分:
- MasterServer 核心主业务
- Client 客户端
-
- MonitorClient 监控客户端
- LogClient 日志采集客户端
- JobClient 作业执行客户端
- Frontend 前端可视化:为用户提供操作入口
4.2 数据表结构及类定义
4.2.1 Job 表(t_job)
| 字段 | 字段类型 | 说明 |
| id | bigint | 作业 ID |
| name | varchar(255) | 作业名称 |
| description | varchar(255) | 作业描述 |
| job_type | tinyint | 作业类型 |
| inputs | text | 作业输入定义(json 格式) |
| outputs | text | 作业输出定义(json 格式) |
| retry_category | varchar(255) | 作业重试机制 |
| success_condition | text | 作业成功条件 |
| content | text | 作业执行内容 |
Job 类定义:
- id: Long
- jobType: Integer
-
- 1 -- Shell 脚本 2 -- Python 脚本 3 -- Http 请求 4 -- Sql 命令 5 -- Linux 命令
- 6 -- 条件判定 7 -- 等待 8 -- 作业组 9 -- 任务 10 -- Java 代码
- jobInputs: JobInputs
-
- params: List<Params>
-
-
- name: 参数名称
- type: 参数类型,static -- 固定参数,dynamic 动态参数
- value:参数取值(如果为动态参数,value 为注入表达式),
-
-
-
-
- 如果不设置,则从 Task 中获取
- 如果 Task 中设置,则将覆盖 Job 中设置的值
-
-
-
- resources: List<JobResources>
-
-
- name: 资源名称
- type: 资源类型,file -- 文件,database -- 数据库,service -- 服务
- uri: 资源访问链接
- testCategory: TestCategory 资源检测策略
-
-
-
-
- FileTest: 检测文件是否存在
- DataBaseTest: 连通性检测,存在性检测
- ServiceTest: 返回状态及结果检测
-
-
- jobOutputs: JobOutputs
-
- results: List<JobResult>
-
-
- name: 结果名称
- injectExpression: 结果注入表达式
-
- retryCategory: RetryCategory
-
- retryTimes: 重试次数
- retryInterval: 重试间隔
- timeOut: 超时时间
- successCondition: Condition
-
- type 类型,logic -- 逻辑表达式,resouceTest 资源检测
- logicExpression 逻辑表达式
- testCategory: TestCategory 资源检测策略
- jobContent: JobContent 作业内容
-
- ready: ExecuteCode 准备阶段执行的指令
- process: ExecuteCode 处理阶段执行的指令
- end: ExecuteCode 结束阶段执行的指令
ExecuteCode 类定义:
- type: Code 类型,code -- 指令,text -- 脚本文件,binary -- 二进制文件,clazz -- 内置类,jobGroup -- 作业组,task -- 任务
- value:String
-
- type 为 code:vlaue 即为执行的指令
- type 为 text 和 binary:value 为文件链接或者文件地址
- type 为 clazz:vlaue 为执行的类名称
- type 为 jobGroup:value 为 job 的 id 列表
- type 为 task:value 为 task 的 id
4.2.2 Task 表(t_task)
| 字段 | 字段类型 | 说明 |
| id | bigint | 任务 ID |
| name | varchar(255) | 任务名称 |
| description | varchar(255) | 任务描述 |
| schedule_category | text | 任务调度策略(json 格式) |
| resource_limit | text | 任务运行资源限制 |
| job_params | text | 任务参数(json格式) |
| task_params | text | 任务参数(json格式) |
| nodes | text | 任务的作业节点信息(json 格式) |
Task 类定义
- id: 任务 ID
- name: 任务名称
- scheduleCategory: ScheduleCategory
-
- type: 调度类型,0 -- 定时执行,1 -- 固定间隔执行,2 -- 条件执行
- interval: 执行时间间隔
- cron: 定时执行表达式
- condition: Condition(待定)
- resourceLimit: ResourceLimit 运行资源限制(待定)
- jobParams: Map<Long, List<Params>> 任务的作业参数
-
- key 为 jobId
- value 为 job 对应的参数
- Params 类定义(同 Job 中的定义)
- taskParams: List<Params> 任务的全局参数
- nodes: List<TaskNodes>
-
- nodeId: UUID 节点 ID(节点在本任务中的唯一标识)
- jobId 节点的作业 ID
- sort 节点的序号
- preNode: List<UUID> 前置节点 ID
4.2.4 TaskInstance 表(t_task_instance)
任务实例表,当任务执行时,将生成任务的实例。
| 字段 | 字段类型 | 说明 |
| id | bigint | 实例 ID |
| task_id | bigint | 关联的任务 ID |
| create_time | timestamp | 实例创建时间 |
| start_time | timestamp | 任务开始执行的时间 |
| end_time | timestamp | 任务结束时间 |
| success | tinyint | 任务执行是否成功 |
| error_code | bigint | 任务错误码 |
| err_msg | text | 任务错误信息 |
| task_params | text | 任务参数,复制自任务 |
| task_results | text | 任务执行结果 |
| worker | bigint | 执行主机 |
| thread_id | varchar(255) | 执行线程 ID |
| ctx_log | varchar(255) | 上下文日志 ID 或路径 |
| job_log | varchar(255) | 作业日志 ID 或路径 |
| monitor_data_id | varchar(255) | 系统监控数据 ID 或路径 |
4.2.5 JobInstance 表(t_job_instance)
作业实例,任务实例创建时,也会创建相应的作业实例
| 字段 | 字段类型 | 说明 |
| id | bigint | 实例 ID |
| task_id | bigint | 关联的任务 ID |
| task_instance_id | bigint | 关联的任务实例 ID |
| job_id | bigint | 关联的作业 ID |
| create_time | timestamp | 实例创建时间 |
| start_time | timestamp | 作业开始执行的时间 |
| end_time | timestamp | 作业结束时间 |
| success | tinyint | 作业执行是否成功 |
| error_code | bigint | 作业错误码 |
| err_msg | text | 作业错误信息 |
| job_params | text | 作业参数,参数注入后的结果 |
| job_results | text | 作业执行结果 |
| worker | bigint | 执行主机 |
| thread_id | varchar(255) | 执行线程 ID |
| ctx_log | varchar(255) | 上下文日志 ID 或路径 |
| job_log | varchar(255) | 作业日志 ID 或路径 |
| monitor_data_id | varchar(255) | 系统监控数据 ID 或路径 |
4.2.6 Resource 表(t_resource)
对应 JobResource
| 字段 | 字段类型 | 说明 |
| id | bigint | 资源 ID |
| type | tinyint | 资源类型:1 -- file,2 -- database,3 -- http,4 -- ftp |
| uri | text | 资源访问路径 |
| request_param | text | 资源访问参数 |
| test_category | text | 资源测试方式 |
4.2.7 LogFile 日志文件
日志文件保存在系统的特定目录下
4.2.8 ThreadMonitorData 线程监控数据文件
线程监控数据保存在系统的特定目录下
4.2.9 SystemMonitorData 系统监控数据文件
系统监控数据文件保存在特定的目录下
4.2.10 ExecuteStat 表(t_execute_stat)
任务和 job 的执行统计表
| 字段 | 字段类型 | 说明 |
| id | bigint | 记录 ID |
| type | tinyint | 关联的对象类型:0 job,1 task |
| obj_id | bigint | 关联的对象 id |
| counts | bigint | 执行次数 |
| failed | bigint | 失败次数 |
| success | bigint | 成功次数 |
| max_execute_time | bigint | 最大执行时间 |
| avg_execute_time | bigint | 平均执行时长 |
| error_code_counts | text | 错误码统计信息 |
4.3 关键技术实现
4.3.1 参数注入与结果提取
- 参数注入与结果提取都是基础任务执行上下文进行的。任务上下文保存了任务生命周期中的全量数据。
- 通过反射和特定的表达式(如 JPath)以及特定的处理方式(如正则提取),可以提取上下文中的数据,并将其赋值给任务或者作业的参数以及结果。
- 任务上下文可以在任务下的 Job 实例间共享,因此 Job 可以引用任务下其他所有 Job 的数据。
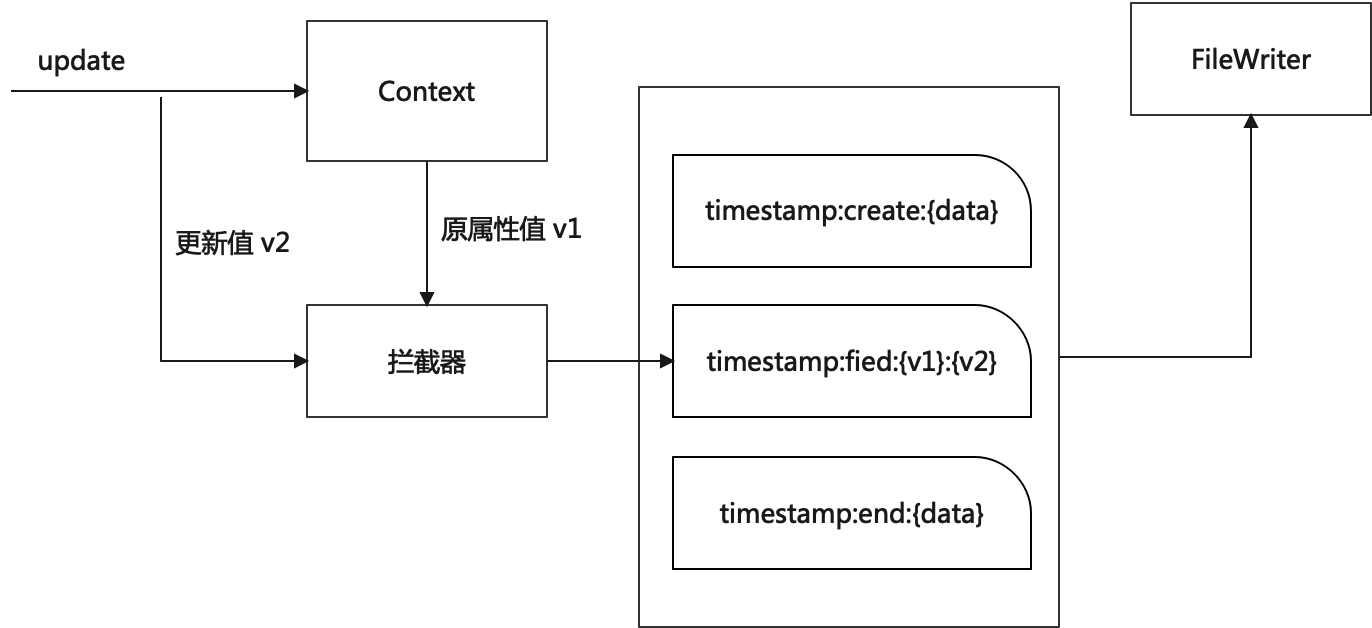
4.3.2 上下文日志
通过反射技术实现。Context(包括 TaskContext 和 JobContext) 每次更新操作都会留下一条操作记录,并保存到一份文件中,即上下文日志。
4.3.3 任务调度
使用过 Quartz 做为系统的任务调度器。
4.3.4 工作目录
每个任务实例执行时,都创建一个工作目录,目录名称为 task-{taskId}-{taskInstanceId},目录下的文件及子目录包括:
- ctx.json 记录当前的上下文信息
- ctx.log 上下文日志
- params.json 任务的参数文件
- currJobs 当前执行的作业
- jobs 目录,目录下为 job 相关的内容,目录名称为 job-{jobId}-{jobInstanceId}
-
- ctx.json 上下文信息
- ctx.log 上下文日志
- executeCode 执行的指令,为目录
-
-
- ready 第一阶段执行的指令
- process 第二阶段执行的指令
- end 第三阶段执行的指令
-
-
- status 状态标志,内容为 1 表示,执行成功(系统自动写入,用户通过脚本写入也可以)
- inputs 执行输入
- outputs 执行输出,目录
-
-
- {resultName} 名称为输出结果的名称,文件内容为输出结果的内容
-
-
- job.log 作业日志
- job-error.log 作业的错误日志
4.4 作业示例
4.4.1 文本文件合并
参数:file1,file2
输出:fileOutput: $.JOB['concat'].PARAMS['file1'] (输出文件等于输入的第一个文件)
作业成功标志:$.JOB['concat'].LOG#'success' (名称为 concat 的作业的输出日志包含 'sucess' 字符串)
作业内容:
- ready:无
- process:
#!/bin/bash
LINE1=`wc -l ${file1} | awk '{print $1}'`
echo ${LINE1}
LINE2=`wc -l ${file2} | awk '{print $1}'`
echo ${LINE2}
cat ${file2} >> ${file1}
LINE3=`wc -l ${file1} | awk '{print $1}'`
echo ${LINE3}
SUM=`expr ${LINE1}+${LINE2}`
if (( ${LINE3} == ${SUM} ))
then
echo 'success'
else
echo 'failed'
fi- end: 无
五 产品交互要点
- 参数注入和结果提取通过接口做成 Select ,避免复杂的注入表达式的编写
- 任务的 DAG 结构可以进行图形化的展示和编辑,任务执行过程也可以使用图形化的方式进行呈现
- 任务实例管理可以自动关联到对应的 Job 的管理(如打开 Job 列表)
- 任务提供日志和监控的查看及导出的功能,Job 也有类似的功能
- 系统需要用户和用户权限?


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









