







hadoop2.0已经发布了很多稳定版本,增加了很多特性,比如HDFS HA、YARN等。最新的hadoop-2.7.2又增加了YARN HA
1、环境准备
修改主机名、IP地址。这些在之前博客有提过就不再写了。
配置IP地址和主机名映射关系。
sudo vi /etc/hosts

集群规划:
主机名 IP 安装的软件 运行的进程
spark01 192.168.2.201 jdk、hadoop NameNode、 DFSZKFailoverController(zkfc)
spark02 192.168.2.202 jdk、hadoop NameNode、DFSZKFailoverController(zkfc)
spark03 192.168.2.203 jdk、hadoop ResourceManager
spark04 192.168.2.204 jdk、hadoop ResourceManager
spark05 192.168.2.205 jdk、hadoop、zookeeper DataNode、NodeManager、JournalNode、QuorumPeerMain
spark06 192.168.2.206 jdk、hadoop、zookeeper DataNode、NodeManager、JournalNode、QuorumPeerMain
spark07 192.168.2.207 jdk、hadoop、zookeeper DataNode、NodeManager、JournalNode、QuorumPeerMain
2、安装zookeeper集群在spark05-07上
参考博客:http://blog.csdn.net/u013821825/article/details/51375860
3、安装配置hadoop集群(在spark01上操作)
3.1 解压
tar -zxvf hadoop-2.7.2.tar.gz -C /app/

3.2 配置HDFS(hadoop2.0所有的配置文件都在HADOOP_HOME/etc/hadoop目录下)
#将hadoop添加到环境变量中
sudo vi /etc/profile
export JAVA_HOME=/home/hadoop/app/jdk1.8.0_91
export HADOOP_HOME=/home/hadoop/app/hadoop-2.7.2
export PATH=JAVA_HOME/bin:
PATH:
HADOOP_HOME/bin
export CLASSPATH=.:
JAVAHOME/lib/dt.jar:
JAVA_HOME/lib/tools.jar
#hadoop2.0的配置文件全部在$HADOOP_HOME/etc/hadoop下
cd /home/hadoop/app/hadoop-2.7.2/etc/hadoop
a、修改hadoo-env.sh
export JAVA_HOME=/home/hadoop/app/jdk1.8.0_91

b、修改core-site.xml
<configuration>
<!-- 指定hdfs的nameservice为ns1 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns1/</value>
</property>
<!-- 指定hadoop临时目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/app/hadoop-2.7.2/tmp</value>
</property>
<!-- 指定zookeeper地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>spark05:2181,spark06:2181,spark07:2181</value>
</property>
</configuration>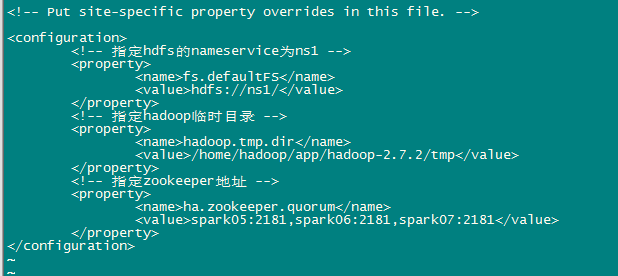
c、修改hdfs-site.xml
<configuration>
<!--指定hdfs的nameservice为ns1,需要和core-site.xml中的保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>ns1</value>
</property>
<!-- ns1下面有两个NameNode,分别是nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.ns1</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns1.nn1</name>
<value>spark01:9000</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns1.nn1</name>
<value>spark01:50070</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns1.nn2</name>
<value>spark02:9000</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns1.nn2</name>
<value>spark02:50070</value>
</property>
<!-- 指定NameNode的元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://spark05:8485;spark06:8485;spark07:8485/ns1</value>
</property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/hadoop/app/hadoop-2.7.2/journaldata</value>
</property>
<!-- 开启NameNode失败自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property> <name>dfs.client.failover.proxy.provider.ns1</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制方法,多个机制用换行分割,即每个机制暂用一行-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence
shell(/bin/true)
</value>
</property>
<!-- 使用sshfence隔离机制时需要ssh免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<!-- 配置sshfence隔离机制超时时间 -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
</configuration>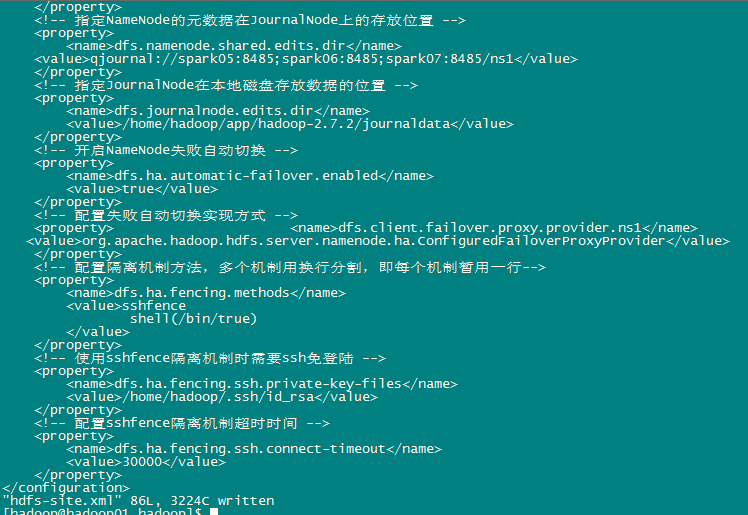
d、修改mapred-site.xml
先执行:[hadoop@hadoop01 hadoop]$ mv mapred-site.xml.template mapred-site.xml
<configuration>
<!-- 指定mr框架为yarn方式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>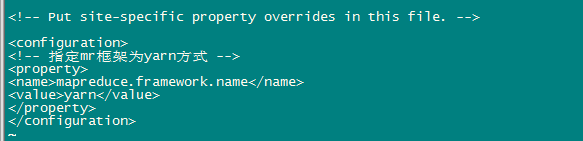
e、修改yarn-site.xml
<configuration>
<!-- 开启RM高可用 -->
<property> <name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定RM的cluster id -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yrc</value>
</property>
<!-- 指定RM的名字 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 分别指定RM的地址 -->
<property> <name>yarn.resourcemanager.hostname.rm1</name>
<value>spark03</value>
</property>
<property> <name>yarn.resourcemanager.hostname.rm2</name>
<value>spark04</value>
</property>
<!-- 指定zk集群地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name> <value>spark05:2181,spark06:2181,spark07:2181</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>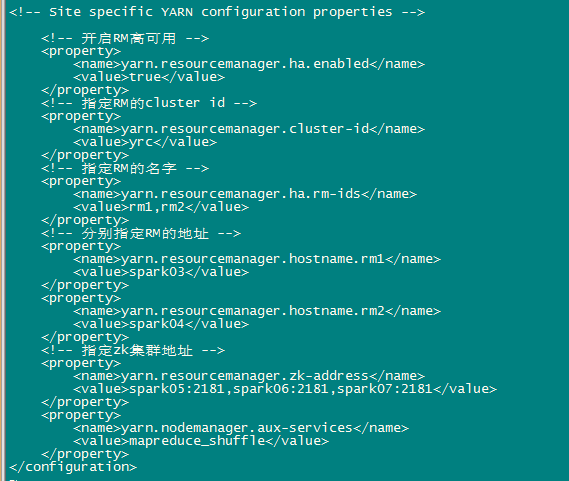
f、修改slaves(slaves是指定子节点的位置,因为要在spark01上启动HDFS、在spark03启动yarn,所以spark01上的slaves文件指定的是datanode的位置,spark03上的slaves文件指定的是nodemanager的位置)















 3343
3343

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









