







linux内存管理——内存初始化2—分页机制
文章目录
1 多级页表的概念
1.1 虚拟内存
在用户的视角里,每个进程都有自己独立的地址空间,A进程的4GB和B进程4GB是完全独立不相关的,他们看到的都是操作系统虚拟出来的地址空间。但是呢,虚拟地址最终还是要落在实际内存的物理地址上进行操作的。操作系统就会通过页表的机制来实现进程的虚拟地址到物理地址的翻译工作。其中每一页的大小都是固定的。页表管理有两个关键点,分别是页面大小和页表级数。
1.2 页面大小
在Linux下,我们通过如下命令可以查看到当前操作系统的页大小
# getconf PAGE_SIZE
1.3 页表级数
页表级数越少,虚拟地址到物理地址的映射会很快,但是需要管理的页表项会很多,能支持的地址空间也有限。相反页表级数越多,需要的存储的页表数据就会越少,而且能支持到比较大的地址空间,但是虚拟地址到物理地址的映射就会越慢。
1.3.1 linux的二级页表
| 单元 | 描述 |
|---|---|
| 页目录表 | 31~22 |
| 页中间表 | 21~12 |
| 页内偏移 | 11~0 |
1.3.2 linux的三级页表
| 单元 | 描述 | bit |
|---|---|---|
| cr3 | 指向一个PDPT | crs寄存器存储 |
| 页全局目录(PGD:Page GlobalDirectory) | 指向PDPT中4个项中的一个 | 31~30 |
| 页中间目录(PMD:Page Middle Directory) | 指向页目录中512项中的一个 | 29~21 |
| 页表(PTE:Page Table Entry) | 指向页表中512项中的一个 | 20~12 |
| 页内偏移(Page Offset) | 4KB页中的偏移 | 11~0 |
现在就同时存在2级页表和3级页表,在代码管理上肯定不方便。巧妙的是,Linux采取了一种抽象方法:所有架构全部使用3级页表: 即PGD -> PMD -> PTE。那只使用2级页表(如非PAE)怎么办?
办法是针对使用2级页表的架构,把PMD抽象掉,即虚设一个PMD表项。这样在page table walk过程中,PGD本直接指向PTE的,现在不了,指向一个虚拟的PMD,然后再由PMD指向PTE。这种抽象保持了代码结构的统一。
1.3.3 linux的四级页表
| 单元 | 描述 | bit |
|---|---|---|
| 页全局目录(PGD:Page GlobalDirectory) | 指向页全局目录中512个项中的一个 | 47~39 |
| 页上级目录(PUD:Page Upper Directory) | 指向页上级目录中512项中的一个 | 38~30 |
| 页中间目录(PMD:Page Middle Directory) | 指向页中间目录中512项中的一个 | 29~21 |
| 页表(PTE:Page Table Entry) | 指向页表中512项中的一个 | 20~12 |
| 页内偏移(Page Offset) | 4KB页中的偏移 | 11~0 |
1.3.4 PGD: Page Global Directory
Linux系统中每个进程对应用户空间的pgd是不一样的,但是linux内核的pgd是一样的。当创建一个新的进程时,都要为新进程创建一个新的页面目录PGD,并从内核的页面目录swapper_pg_dir中复制内核区间页面目录项至新建进程页面目录PGD的相应位置,具体过程如下:
do_fork()->copy_mm()->mm_init()->pgd_alloc()->set_pgd_fast()->get_pgd_slow()->memcpy(&PGD+USER_PTRS_PER_PGD, swapper_pg_dir+USER_PTRS_PER_PGD, (PTRS_PER_PGD-USER_PTRS_PER_PGD) * sizeof(pgd_t))。
这样一来,每个进程的页面目录就分成了两部分,第一部分为“用户空间”,用来映射其整个进程空间(0x0000 0000-0xBFFF FFFF)即3G字节的虚拟地址;第二部分为“系统空间”,用来映射(0xC000 0000-0xFFFF FFFF)1G字节的虚拟地址。可以看出Linux系统中每个进程的页面目录的第二部分是相同的,所以从进程的角度来看,每个进程有4G字节的虚拟空间,较低的3G字节是自己的用户空间,最高的1G字节则为与所有进程以及内核共享的系统空间。每个进程有它自己的PGD( Page Global Directory),它是一个物理页,并包含一个pgd_t数组。
1.3.5 PTE: Page Table Entry
PGD中包含若干PUD的地址,PUD中包含若干PMD的地址,PMD中又包含若干PT的地址。每一个PTE页表项指向一个页框,也就是一个实际的物理页面。
1.4 页表带来的问题
虽然16K的页表数据支持起了256T的地址空间寻址。但是,这也带来了额外的问题,页表是存在内存里的。那就是一次内存IO光是虚拟地址到物理地址的转换就要去内存查4次页表,再算上真正的内存访问,竟然需要5次内存IO才能获取一个内存数据!
TLB应运而生
和CPU的L1、L2、L3的缓存思想一致,既然进行地址转换需要的内存IO次数多,且耗时。那么干脆就在CPU里把页表尽可能地cache起来不就行了么,所以就有了TLB(Translation Lookaside Buffer),专门用于改进虚拟地址到物理地址转换速度的缓存。其访问速度非常快,和寄存器相当,比L1访问还快。有了TLB之后,CPU访问某个虚拟内存地址的过程如下:
1.CPU产生一个虚拟地址
2.MMU从TLB中获取页表,翻译成物理地址
3.MMU把物理地址发送给L1/L2/L3/内存
4.L1/L2/L3/内存将地址对应数据返回给CPU
由于第2步是类似于寄存器的访问速度,所以如果TLB能命中,则虚拟地址到物理地址的时间开销几乎可以忽略。
2 内核页表和进程页表
内核页表:即主内核页表,在内核中其实就是一段内存,存放在主内核页全局目录init_mm.pgd(swapper_pg_dir)中,硬件并不直接使用。
进程页表:每个进程自己的页表,放在进程自身的页目录task_struct.pgd中。
在保护模式下,从硬件角度看,其运行的基本对象为“进程”(或线程),而寻址则依赖于“进程页表”,在进程调度而进行上下文切换时,会进行页表的切换:即将新进程的pgd(页目录)加载到CR3寄存器中。
1、 内核页表中的内容为所有进程共享,每个进程都有自己的“进程页表”,“进程页表中映射的线性地址包括两部分:用户态,内核态。
其中,内核态地址对应的相关页表项,对于所有进程来说都是相同的(因为内核空间对所有进程来说都是共享的),而这部分页表内容其实就来源于“内核页表”,即每个进程的“进程页表”中内核态地址相关的页表项都是“内核页表”的一个拷贝。
2、“内核页表”由内核自己维护并更新,在vmalloc区发生page fault时,将“内核页表”同步到“进程页表”中。以32位系统为例,内核页表主要包含两部分:线性映射区,vmalloc区。
其中,线性映射区即通过TASK_SIZE偏移进行映射的区域,对32系统来说就是0-896M这部分区域,映射对应的虚拟地址区域为TASK_SIZE~TASK_SIZE+896M。这部分区域在内核初始化时就已经完成映射,并创建好相应的页表,即这部分虚拟内存区域不会发生page fault。
vmalloc区,为896M~896M+128M,这部分区域用于映射高端内存,有三种映射方式:vmalloc、固定、临时。以vmalloc为例(最常使用),这部分区域对应的线性地址在内核使用vmalloc分配内存时,其实就已经分配了相应的物理内存,并做了相应的映射,建立了相应的页表项,但相关页表项仅写入了“内核页表”,并没有实时更新到“进程页表中”,内核在这里使用了“延迟更新”的策略,将“进程页表”真正更新推迟到第一次访问相关线性地址,发生page fault时,此时在page fault的处理流程中进行“进程页表”的更新。
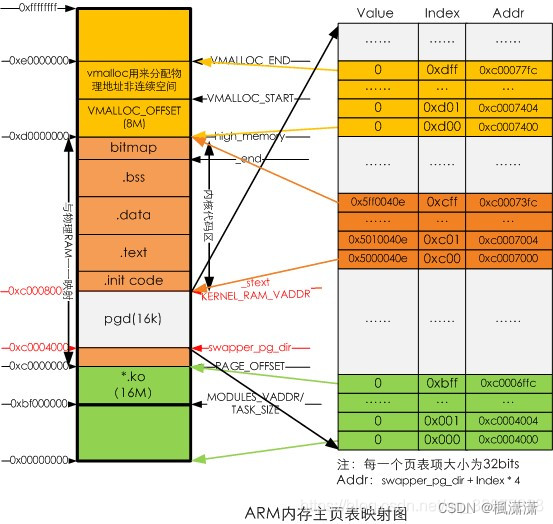
2.1 主内核页表 swapper_pg_dir
主内核页表负责维护内核空间的页表映射,完成后的内核空间主页表映射如下图
(每一项映射1M空间,lk项刚好映射4G虚拟空间)swapper_pg_dir用于存放内核PGD页表的地方,赋给内核页表init_mm.pgd。swapper_pd_dir的大小为16KB,对应的虚拟地址空间是从0xc0004000 - 0xc0008000,物理地址空间是0x1000400~0x10008000。swapper_pg_dir被定义了绝对地址,在arch/arm/kernel/head.S中定义。
2.2 用户进程页表
2.2.1 进程使用内存
毫无疑问,所有进程(执行的程序)都必须占用一定数量的内存,它或是用来存放从磁盘载入的程序代码,或是存放取自用户输入的数据等等。不过进程对这些内存的管理方式因内存用途不一而不尽相同,有些内存是事先静态分配和统一回收的,而有些却是按需要动态分配和回收的。
对任何一个普通进程来讲,它都会涉及到5种不同的数据段:
- 代码段(.text)
- 数据段(.data)
- bss段(.bss)
- 堆(.heap)
- 栈(.stack)
2.2.2 进程的内核全局目录装载过程
进程的内核页全局目录的装载过程
do_fork()->copy_process()->copy_mm()(如果是fork一个内核线程kernel thread的话,内核线程将会直接使用当前普通进程的页表集,内核线程并不拥有自己的页表集)->dup_mm()->mm_init()->mm_alloc_pgd()->pgd_alloc。
pgd_ctor(mm, pgd) //将swapper_pg_dir全局页目录(部分后256项–即内核最后1G的虚拟地址,这里指的是内核的页表)拷到pgd里,则可以看出,linux下所有进程的内核页全局目录是一样的,都是swapper_pg_dir里最后的1/4的内容,而每个进程的用户态的页表确是不同的,所以在dup_mmap会去将父进程的页表一项一项的爬出来设置为当前进程的页表。
进程的用户态地址页拷贝
dup_mmap()函数实现页表映射的拷贝
页表的复制
- copy_page_range()
- copy_pud_range()
- copy_pmd_range()
- copy_pte_range()
cr3寄存器的加载
cr3寄存器的加载是在进程调度的时候更新的,具体如下schedule()->context_switch()->switch_mm()->load_cr3(next->pgd)。load_cr3加载的是mm_struct->pgd,即线性地址,而实际上加裁到cr3寄存器的是实际的物理地址write_cr3(__pa(pgdir));在装载cr3寄存器时将线性地址通过__pa转换成了物理地址了,所以cr3寄存器是装的是实实在在的物理地址。
2.2.3 用户进程分配
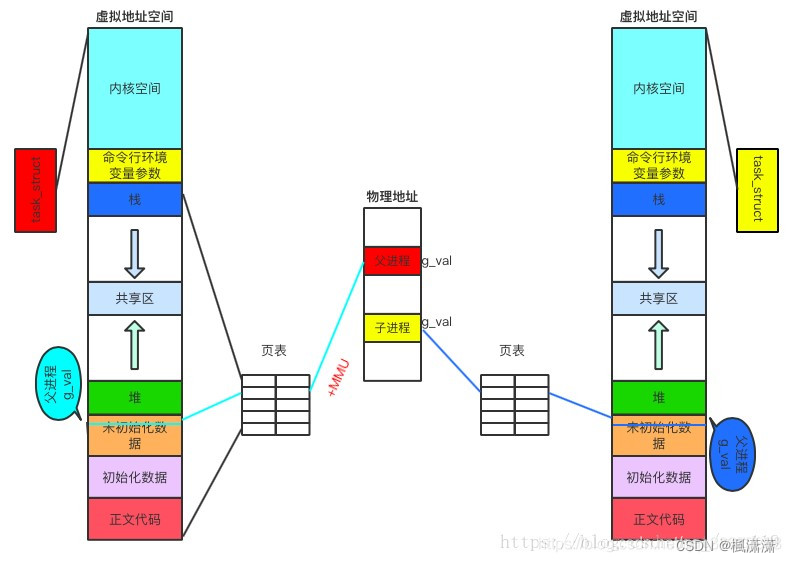
创建进程,虚拟地址和物理地址之间的映射关系
上面的图说明:同一个变量,地址相同,其实是虚拟地址相同,内容不同其实是被映射到了不同的物理地址!
过程:当访问虚拟内存时,会访问MMU(内存管理单元)去匹配对应的物理地址,而如果虚拟内存的页并不存在于物理内存中,会产生缺页中断,从磁盘中取得缺的页放入内存,如果内存已满,还会根据某种算法将磁盘中的页换出。(MMU中存储页表,用来匹配虚拟内存和物理内存)
的物理地址!















 2758
2758











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









