







根据官方提供的python streaming例子,测试了下,代码如下:
from pyspark import SparkConf, SparkContext
from pyspark.streaming import StreamingContext
conf = SparkConf().setMaster("local[2]").setAppName("My test")
sc = SparkContext(conf = conf)
ssc = StreamingContext(sc, 10)
lines = ssc.socketTextStream("192.168.1.118",2333)
words = lines.flatMap(lambda line : line.split(" "))
pairs = words.map(lambda word: (word, 1))
wordCounts = pairs.reduceByKey(lambda x, y: x + y)
wordCounts.pprint()
ssc.start()
ssc.awaitTermination()
ssc.stop()
sc.stop()笔记
1.
当在本地运行Spark流程序时,不要使用”local”或者”local[1]”作为master URL。因为,这意味着只用一个线程运行本地任务。如果你在使用一个基于接收者(如sockets, Kafka, Flume)的输入DStream,这个线程将会被用来运行接收者任务,就不会有线程来处理接收到的数据。所以,当运行在本地模式时,总是应该使用”local[n]”作为master URL,n要大于运行的接收都个数。
同样的道理,当运行在集群模式时,分配给Spark流程序的核心数也必须大于接收者的个数。否则,系统将只会接收数据,但是确不能处理数据。
2.
官方教程上有这一句:
Each RDD in a DStream contains data from a certain interval
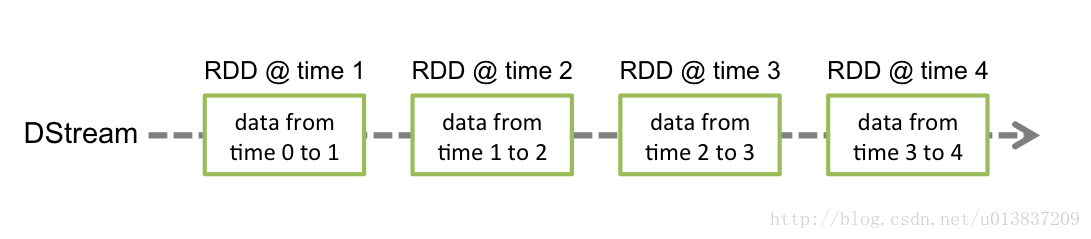
这里的certain interval就应该指的是生成的RDD包含的数据接收时间,上例的十秒钟。即一个时间间隔的数据都放在一个RDD中。
3.
socketTextStream API说明:
socketTextStream(hostname, port, storageLevel=StorageLevel(True, True, False, False, 2))
Create an input from TCP source hostname:port. Data is received using a TCP socket and receive byte is interpreted as UTF8 encoded \n delimited lines.socketTextStream函数监控的数据流以\n为结尾。否则数据将不处理。
官方教程:
http://spark.apache.org/docs/latest/streaming-programming-guide.html#discretized-streams-dstreams
官方API:
http://spark.apache.org/docs/latest/api/python/pyspark.streaming.html?highlight=sockettextstream














 1450
1450











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









