







######《Extensive Facial Landmark Localization with Coarse-to-fine Convolutional Network Cascade》
- ICCV2013,Face++在DCNN模型上进行改进,提出由粗到精的人脸关键点检测算法。
实现了68个点的高精度定位,该算法将人脸关键点分为内部关键点和轮廓关键点,内部关键点包含眉毛、眼睛、鼻子、嘴巴共计51个关键点,轮廓关键点包含17个关键点。
论文中4级CNN的级联网络设计:
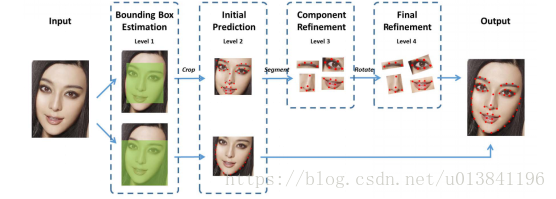
1)针对内部 51 个关键点,采用四个层级的级联网络进行检测。其中,Level-1主要作用是获得面部器官的边界框;Level-2 的输出是51个关键点预测位置,这里起到一个粗定位作用,目的是为了给 Level-3 进行初始化;Level-3 会依据不同器官进行从粗到精的定位;Level-4 的输入是将 Level-3 的输出进行一定的旋转,最终将51个关键点的位置进行输出。
2)针对外部 17 个关键点,仅采用两个层级的级联网络进行检测。Level-1 与内部关键点检测的作用一样,主要是获得轮廓的 bounding box;Level-2直接预测17个关键点,没有从粗到精定位的过程,因为轮廓关键点的区域较大,若加上Level-3和Level-4,会比较耗时间。
注:单一模型在多点检测的效果上不好。
边界点的定位难点:1.局部纹理信息少;2.定义模糊,背景噪声大。
如果68个点在一起训练,边界点的L2损失将占主导作用,loss不均衡的问题。
网络结构:
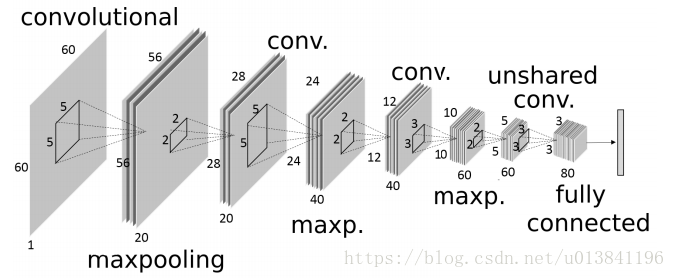
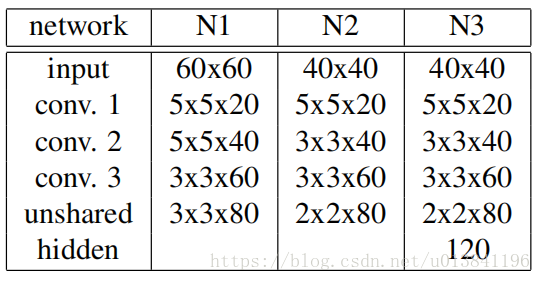
其中,N1是内部关键点的第二级,N2是轮廓关键点,N3为其它结构。
算法主要创新点由以下三点:(1)把人脸的关键点定位问题,划分为内部关键点和轮廓关键点分开预测,有效的避免了 loss 不均衡问题;(2)在内部关键点检测部分,并未像DCNN 那样每个关键点采用两个CNN 进行预测,而是每个器官采用一个CNN 进行预测,从而减少计算量;(3)相比于DCNN,没有直接采用人脸检测器返回的结果作为输入,而是增加一个边界框检测层(Level-1),可以大大提高关键点粗定位网络的精度。
注:博众家之所长,集群英之荟萃。



















 694
694

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











