









前言:什么是决策树算法
- Decision Tree 算法是一种基于输入特征对实例进行分类的树结构模型。
- 其结构组成:非叶子节点与叶子节点,非叶子节点表示一个特征或划分实例类别的条件,叶子节点表示一个类别。
- 决策树是既能够用于分类,也能用于回归的有监督学习算法。
一、决策树算法原理
- 通过对训练数据进行学习最终构建成一棵泛化能力强的分类树;
- 根据步骤 1 生成的树对待预测的实例进行预测,决策的过程就是从根节点开始,根据待预测实例的特征,按照其值选择输出分支,依次向下,直到到达叶子节点,将叶子节点存放的类别或者回归函数的运算结果作为输出(决策)结果。
简单Demo说明

这棵树的作用,是对要不要接受一个 Offer 做出判断。
树共有7个节点,有4个叶子节点和3个非叶子节点,每个非叶子节点对应一个划分特征,每个叶子节点对应一个类别。
- 理论上讲,一棵分类树有 n 个叶子节点(n>1,只有一个结果也就不用分类了)时,可能对应2~n 个类别。不同判断路径是可能得到相同结果的(殊途同归)。
以上例而言,拿到一个 Offer 后,要判断三个条件:(1)年薪;(2)通勤时间;(3)免费 咖啡。
这三个条件的重要程度显然是不一样的,最重要的是根节点,越靠近根节点,也就越重要—— 如果年薪低于5万美元,也就不用考虑了,直接 say no;
当工资足够时,如果通勤时间大于一个小时,也不去那里上班;就算通勤时间不超过一小时,还要看是不是有免费咖啡,没有也不去。
这三个非叶子节点(含根节点),统称决策节点,每个节点对应一个条件判断,这个条件判断 的条件,我们叫做特征。上例是一个有三个特征的分类树。
当我们用这棵树来做判断一个 Offer 的时候,我们就需要从这个 Offer 中提取年薪、通勤时间
和有否免费咖啡三个特征出来,将这三个值(比如:[ $ 65,000,0.5 hour, don’t offer free
coffee])输入给该树。 该树按照根节点向下的顺序筛选一个个条件,直到到达叶子为止。到达的叶子所对应的类别就 是预测结果。
如上所述,发现决策树的决策过程简单明了,因此对于该算法重点是在于如何构建决策树。
决策树的构建过程
- 标明训练数据所属类别;
- 选择划分特征并将其进行数值化;
- 将通过上面的1-2步获得的训练数据输入给训练算法,训练算法通过一定的原则,决定各个
特征的重要性程度,然后按照决策重要性从高到底,生成决策树。
在这一步常用的算法有:ID3、C4.5、CART。后文再详细给出这几个算法的基本原理。
sklearn 中DecisionTreeClassifier 默认的就是CART算法。
二、Decision Tree 简单编码样例
from sklearn import datasets
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
# 获取iris数据
iris = datasets.load_iris()
# 分割数据,取两个数据特征做为训练数据的特征,测试时发现如何将四个特征都做用起来,
# 准确率基本为 1,这样反而不方便调试了
x_train, x_test, y_train, y_test = train_test_split(iris.data[:, [0, 2]], iris.target,
test_size=0.20, random_state=2)
# 初始化模型, max_depth 限制树的最大深度
# 可以使用"gini"或者"entropy",前者代表基尼系数,后者代表信息增益。
# 一般说使用默认的基尼系数"gini"就可以了,即CART算法。除非你更喜欢类似ID3, C4.5的最优特征选择方法。
clf = DecisionTreeClassifier(max_depth=5, criterion="gini")
# 训练模型
clf.fit(x_train, y_train)
print("训练数据的预测准确率:", (clf.score(x_train, y_train)))
print("测试数据的预测准确率:", (clf.score(x_test, y_test)))
预测结果如下:
训练数据的预测准确率: 0.975
测试数据的预测准确率: 0.9666666666666667
sklearn iris 部分样例数据
{'data': array([[5.1, 3.5, 1.4, 0.2],
....
....
[6.3, 2.5, 5. , 1.9],
[6.5, 3. , 5.2, 2. ],
[6.2, 3.4, 5.4, 2.3],
[5.9, 3. , 5.1, 1.8]]),
'target': array([
0, 0, 0, 0, 0, 0, 0, 0,
1, 1, 1, 1, 1,
2, 2, 2, 2, 2, 2, 2]),
'target_names': array(['setosa', 'versicolor', 'virginica'],
dtype='<U10'),
}
sklearn 决策树的算法参数
- sklearn中使用sklearn.tree.DecisionTreeClassifier类来实现决策树分类算法。其中几个典型的参数解释如下:
| 名称 | 功能 | 描述 |
|---|---|---|
| criterion | 特征选择标准 | ‘gini’ or ‘entropy’ (default=”gini”),前者是基尼系数,后者是信息熵。两种算法差异不大对准确率无影响,信息墒运算效率低一点,因为它有对数运算。一般说使用默认的基尼系数”gini”就可以了,即CART算法。除非你更喜欢类似ID3, C4.5的最优特征选择方法。 |
| splitter | 特征划分标准 | ‘best’ or ‘random’ (default=”best”) 前者在特征的所有划分点中找出最优的划分点。后者是随机的在部分划分点中找局部最优的划分点。 默认的”best”适合样本量不大的时候,而如果样本数据量非常大,此时决策树构建推荐”random” 。 |
| max_depth | 决策树最大深度 | int or None, optional (default=None) 一般来说,数据少或者特征少的时候可以不管这个值。如果模型样本量多,特征也多的情况下,推荐限制这个最大深度,具体的取值取决于数据的分布。常用的可以取值10-100之间。常用来解决过拟合 |
| min_impurity_decrease | 节点划分最小不纯度 | float, optional (default=0.) 这个值限制了决策树的增长,如果某节点的不纯度(基尼系数,信息增益,均方差,绝对差)小于这个阈值,则该节点不再生成子节点。 sklearn 0.19.1版本之前叫 min_impurity_split |
| min_samples_split | 内部节点再划分所需最小样本数 | int, float, optional (default=2) 如果是 int,则取传入值本身作为最小样本数; 如果是 float,则去 ceil(min_samples_split * 样本数量) 的值作为最小样本数,即向上取整。 |
| min_samples_leaf | 叶子节点最少样本数 | 如果是 int,则取传入值本身作为最小样本数; 如果是 float,则去 ceil(min_samples_leaf * 样本数量) 的值作为最小样本数,即向上取整。 这个值限制了叶子节点最少的样本数,如果某叶子节点数目小于样本数,则会和兄弟节点一起被剪枝。 |
| max_leaf_nodes | 最大叶子节点数 | int or None, optional (default=None) 通过限制最大叶子节点数,可以防止过拟合,默认是”None”,即不限制最大的叶子节点数。如果加了限制,算法会建立在最大叶子节点数内最优的决策树。如果特征不多,可以不考虑这个值,但是如果特征分成多的话,可以加以限制,具体的值可以通过交叉验证得到。 |
| min_impurity_split | 信息增益的阀值 | 决策树在创建分支时,信息增益必须大于这个阀值,否则不分裂 |
| min_weight_fraction_leaf | 叶子节点最小的样本权重和 | float, optional (default=0.) 这个值限制了叶子节点所有样本权重和的最小值,如果小于这个值,则会和兄弟节点一起被剪枝。 默认是0,就是不考虑权重问题。一般来说,如果我们有较多样本有缺失值,或者分类树样本的分布类别偏差很大,就会引入样本权重,这时我们就要注意这个值了。 |
| class_weight | 类别权重 | dict, list of dicts, “balanced” or None, default=None 指定样本各类别的的权重,主要是为了防止训练集某些类别的样本过多,导致训练的决策树过于偏向这些类别。这里可以自己指定各个样本的权重,或者用“balanced”,如果使用“balanced”,则算法会自己计算权重,样本量少的类别所对应的样本权重会高。当然,如果你的样本类别分布没有明显的偏倚,则可以不管这个参数,选择默认的”None” 不适用于回归树 sklearn.tree.DecisionTreeRegressor |
三、Decision Tree 算法的优缺点
1.优点:
决策树算法的主要优点是模型具有可读性,分类速度快,对中间值缺失不敏感。
2.缺点:
可能会产生过度匹配问题。
改进算法 : 待整理
四、Decision Tree 算法常用的训练算法
决策树学习过程的第一步就是“特征选择”。所谓的特征选择其实是分两个步骤的:
- 首先,需要选择对训练数据具有最大分类能力的特征进行树的叶子节点的分裂;
- 然后,选择该特征合适的分裂点进行分裂。
- 注:这里有一点需要解释下,以离散型变量为例,寻找特征分裂点的方法也不是固定的:对于 ID3和C4.5 等传统决策树算法使用的是将所有特征值作为分支,生成多叉树结构在进行算法描述前先引入两个概念信息熵与信息增益。
信息熵
熵(Entropy) 是表示随机变量不确定性的度量。假设是一个具有有限个值的离散型随机变量,服从如下的概率分布:
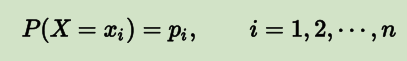
随机变量的熵定义为:
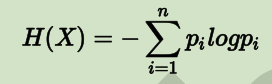
- 注:1948年,香农引入信息熵;一个系统越是有序,信息熵就越低,一个系统越是混乱,信息熵就越高,所以信息熵被认为是一个系统有序程度的度量。
信息量:指的是一个样本/事件所蕴含的信息,如果一个事件的概率越大,那么就可以认为该事件所蕴含的信息越少。极端情况下,比如:“太阳从东方升起”,因为是确定事件,所以不携带任何信息量。
条件熵
- 给定条件X的情况下,随机变量Y的信息熵就叫做条件熵。
信息增益
- 信息增益:熵 - 条件熵。
- 信息增益大的特征具有更强的分类能力。
- 如果信息增益度的值越大,也在该特征属性上会损失的纯度越大,那么该属性就越应该在决策树的上层,计算公式为:
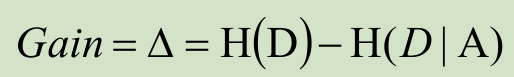
Gain为A为特征对训练数据集D的信息增益,它为集合D的经验熵H(D)与特征A给定条件下D的经验条件熵H(D|A)之差。
基尼系数
- 是一种不等性度量;
- 通常用来度量收入不平衡,可以用来度量任何不均匀分布;
- 是介于0~1之间的数,0-完全相等,1-完全不相等;
- 总体内包含的类别越杂乱,GINI指数就越大(跟熵的概念很相似)
1. ID3
ID3算法是决策树的一个经典的构造算法,内部使用信息增益来进行构建;
每次迭代选择信息增益最大的特征属性作为分割属性。
主要涉及公式如下:
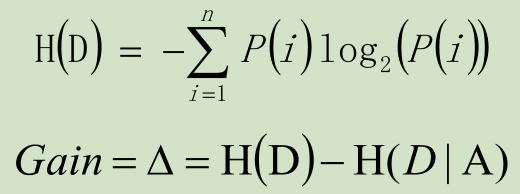
优点:
- 决策树构建速度快;实现简单;
缺点:
- 计算依赖于特征数目较多的特征,而属性值最多的属性并不一定最优;
- ID3算法不是递增算法;
- ID3算法是单变量决策树,对于特征属性之间的关系不会考虑;
- 抗噪性差;
- 只适合小规模数据集,需要将数据放到内存中;
2. C4.5
- 在ID3算法的基础上,进行算法优化提出的一种算法(C4.5);
- 现在C4.5已经是特别经典的一种决策树构造算法;
- 使用信息增益率来取代ID3算法中的信息增益,在树的构造过程中会进行剪枝操作进行优化;
- 能够自动完成对连续属性的离散化处理;
- C4.5算法在选中分割属性的时候选择信息增益率最大的属性,涉及到的公式为:
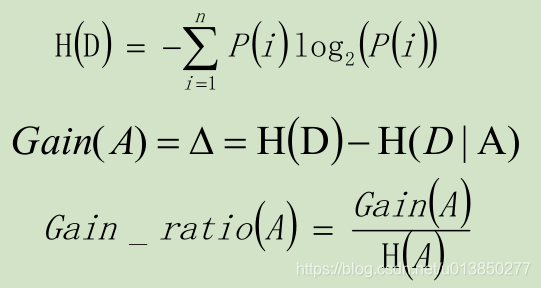
优点:
- 产生的规则易于理解;
- 准确率较高;
- 实现简单;
缺点:
- 对数据集需要进行多次顺序扫描和排序,所以效率较低;
- 只适合小规模数据集,需要将数据放到内存中;
3. CART
- 使用基尼系数作为数据纯度的量化指标来构建的决策树算法就叫做CART(Classification And Regression Tree,分类回归树)算法。
- CART算法使用GINI增益作为分割属性选择的标准,选择GINI增益最大的作为当前数据集的分割属性;可用于分类和回归两类问题。
- 注:CART构建的是二叉树。
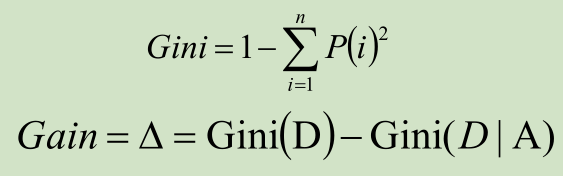
ID3、C4.5、CART分类树算法总结
- 三种算法的区别仅仅只是对于当前树的评价标准不同而已,ID3使用信息增益、C4.5使用信息增益率、CART使用基尼系数。
- ID3和C4.5算法均只适合在小规模数据集上使用;
- ID3和C4.5算法都是单变量决策树;
- 当属性值取值比较多的时候,最好考虑C4.5算法,ID3得出的效果会比较差;
- 决策树分类一般情况只适合小数据量的情况(数据可以放内存);
- CART算法是三种算法中最常用的一种决策树构建算法。
- CART算法构建的一定是二叉树,ID3和C4.5构建的不一定是二叉树。
五、决策树的剪枝策略
学到这里,我们都知道决策树的生成算法递归得构建决策树,直到不能继续构建为止。
因此,这样产生的决策树很容易过分的学习训练样本,使得它对未知的测试数据的分类效果比较差,即这样产生的决策树很容易过拟合。
过拟合的原因在于我们构建的决策树过分复杂,导致其过多地学习训练样本的分布,而对未知样本的学习泛化能力较弱。
解决这个问题的方法就是简化已生成的决策树,使其变得更简单。
在决策树学习的过程中将已经生成的决策树进行简化的过程称作“剪枝”。
也就是说,我们可以将决策树中划分的过细的叶子节点剪去,退回到其父节点成为新的叶子节点,使得新的决策树变得简单,并且能够在未知的测试数据的预测上取得更好的分类结果。
剪枝分为预剪枝和后剪枝:
预剪枝
- 每一个结点所包含的最小样本数目,例如10,则该结点总样本数小于10时,则不再分;
- 指定树的高度或者深度,例如树的最大深度为4;
- 指定结点的熵小于某个值,不再划分。
后剪枝
总体思路为:由完全树 T0 开始,剪枝部分结点得到 T1,再次剪枝部分结点得到 T2……直到剩下树根的树 Tk;在验证数据集上对这 k 个树分别评价,选择损失函数最小的树 Ta。
参考文档:
https://gitbook.cn/gitchat/column/5ad70dea9a722231b25ddbf8?utm_source=jpk180829
中的 - 第16课:决策树——既能分类又能回归的模型
李航老师:《统计学习方法》
周志华老师:《机器学习》


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









