








目录
前言
在前面几篇博文学习了数组、链表、队列、栈、散列表、跳表,这些就是典型的线性表。其特点是数据之间通过线性关系起来,每个数据只有头和尾的方向。
常见的非线性表有树、堆、图等,而通过前面的学习知道对于树这种数据结构其实是一种逻辑结构,其实现方式可通过数组或链表来实现。那么对于树何时该选择数组或链表来实现呢?树这种数据结构与线性表在实际应用场景上又有那些区别呢?
一、什么是树
还是一图胜千言,至于什么是树,见下图:

树的一些基本概念:
如下图所示:

节点:我们把树中每个元素称为节点,如图 A、B、C、D、E...元素;
父节点:A节点为B节点父节点;
子节点:B节点为A节点的子节点;
根节点:没有父节点的节点,如图中E节点;
兄弟节点:拥有同一个父节点的节点,如B、C、D;
叶子节点:没有子节点的节点,如 G、H、I、J、K、L;
左子树:在节点左边的为左子树,同理在节点右边的右子树;
树的另外三个定义高度、深度、层,如下图

引用百度百科的描述:
树是一种数据结构,它是由n(n>=1)个有限结点组成一个具有层次关系的集合。
树结构上具有的特点:
- 每个结点有零个或多个子结点;
- 没有父结点的结点称为根结点;
- 每一个非根结点有且只有一个父结点;
- 除了根结点外,每个子结点可以分为多个不相交的子树。
树的在运用方面最大的特点:是一种支持快速查找、删除、插入的动态数据结构。
二、常见的树<二叉树>
二叉树:每个节点最多只有左右节点的树;
满二叉树:每个节点都有左右节点,那么则为满二叉树,如图中的树2;
完全二叉树:
- 叶子节点都在最下两层;
- 最后一层的叶子节点都靠左排列;
- 除了最后一层,其他所有层都有左右节点。
完全二叉树如下图中的编号 3

区分完全二叉树,如下图:

通过上面的描述,知道满二叉树是完全二叉树的一种,对于满二叉树很容易理解,但对于完全二叉树就感觉有些怪了,为啥需要整出个这种类型树出来呢?为啥叶子节点只能在最后两层?为啥最下层叶子节点要靠左排列呢?
如要理解这一点就需要知道如何存储二叉树了?
常用的方法有,基于指针的链表式存储,还有一种就是基于数组的顺序存储。
链表式的存储二叉树
如下图:

通过上图知道,每个节点存储三个信息,分别是数据及指向左右节点的指针。这种方式,只需知道根节点,就可以通过根节点的左右指针把各个节点串成一颗树了。通常大部分的二叉树也是这么存储的。
数组存储二叉树
由于数组是顺序存储的,因此可设定父节点与子节点的数组下标关系,从而方便检索。如下图,假设节点X对应的数组下标为 "i",那么其左节点下标则为:2 * i,右节点为:2 * i + 1,父节点为i/2;一般情况下,为了方便计算通常设定根节点为数组下标1的位置,通过这种方式,只要知道根节点就可以求出其他各个节点的位置了。

通过上图,可知数组存储完全二叉树,浪费的空间只有数组为0的位置,当然也可以把0这个位置用起来,比如把根节点存入下标为0的位置,那么其左子树下标设置成 2 * 父节点下标 + 1,右子树 下标:2 * 父节点下标 + 2,但这从效率上来说影响不大,因为只是差了一个数组存储空间而已,但如果通过数组存储非完全二叉树就浪费很多空间了,如下图:

所以,对于稀疏树不适合用数组进行存储,如果某棵二叉树是一棵完全二叉树,那用数组存储无疑是最节省内存的一种方式。因为数组的存储方式并不需要像链式存储法那样,要存储额外的左右子节点的指针。这也是为什么完全二叉树会单独拎出来的原因,也是为什么完全二叉树要求最后一层的子节点都靠左的原因。
通过前面关于散列表以及跳表的学习,我们知道散列表对于查询、删除、插入操作时间复杂度都是O(1);跳表都是 O(logN); 那么为什么还需要学习树这种数据结构呢?是不是可以通过用散列表或跳表来替代树呢?这里就需要引入树主要作用了,对于树来说最主要的作用莫过于查找操作与维持相对顺序。

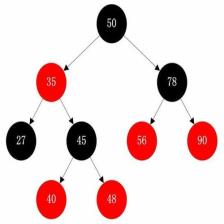
三、二叉查找树(Binary Search Tree)
二叉查找树:二叉查找树也叫二叉搜索树或二叉排序树,通过这命名就很容易知道其主要用途是用于搜索或者排序。
二叉查找树的特点:左子树所有节点都比右子树的小。
如下图所示:

二叉查找树基本操作与时间复杂度分析
1. 查找
由于二叉查找树左子树的节点比右子树小这一特性可以很容易得出如下图所示的查找过程。

通过上图的分析对于分布比较均衡的二叉查找树,其查找效率跟树的高度成正比。那么对于分布均衡的二叉查找树的高度 H 与节点数据 N 的关系是怎么样的呢?
这里假设为了方便分析直接假设其为满二叉树得了,那么很明显 H = log(N),也就是说在比较理想的状态下,二叉查找树检索数据的时间复杂度为 O(logN);
当然如果对于分布极其不均衡的,如下图所示中的第一个树,则其时间复杂度将变得链表对应的O(n)了。

2. 插入
插入操作类似与查找操作,插入元素首先得找到插入的位置,而找插入位置就需要从根节点依次与待插入的元素进行对比。如下图,插入55,与查找对比一个是查到则返回数据一个是没有则添加数据。同理,插入与查找的平均时间复杂度也为O(logN)。

3. 删除
删除相对来说就麻烦一点,因为这会可能会涉及移动数据。而且得看删除元素所在树的位置,一般分有删除叶子节点、删除只有一个子节点的节点、删除有左右子节点的节点这三种。
- 删除叶子节点:与查找类似,找到该节点,直接将该其父节点的指针置为null。比如上图删除55节点,直接将51节点的指针指为null便可。
- 删除只有一个子节点的节点:将其父节点的指针指向更新为指向其子节点的;如上图删除13号节点,那么只需要将更新17号节点的指针指向16号便可。
- 删除有左右节点的节点: 相对前面两种删除方式理解上来说比较容易,但对于这类节点的删除有一个问题需要考虑那就是删除该节点后,应该选择那个节点替换被删除的元素呢?
这里一开始没怎么理解,故引用该博客二叉查找树 - 删除节点 详解(Java实现)
满足同时存在左右节点的节点有 50,30,80,35 这 4 个节点,30 看起来更复杂,我们以 30 为例。
当二叉查找树以中序遍历时,遍历的结果是一个从小到大排列的顺序,如下图所示:

当我们删除 30 节点的时候,整个中序遍历的结果中,从 32 开始都往前移动了一位。32 是 30 的后继节点,就是比 30 大的节点中最小的节点。当某个节点存在右节点时,后继结点就是右节点中的最小值,由于左侧节点总比右侧节点和父节点小,所以后继节点一定没有左节点。从这一个特点就能看出来,后继结点有可能存在右节点,也有可能没有任何节点。后继结点还有一个特点,就是他比 30 的左节点大,比 30 所有的右节点都小,因此删除 30 的时候,可以直接将后继结点 32 的值(key)转移到 30 节点上,然后删除后继结点 32。由于后继结点最多只有一个子节点,因此删除后继节点时,就变成了 3 种情况中的前两种。图示如下:

根据上述的表述可知,对于二叉查找树的删除操作平均时间复杂度也为O(logN)。
总结:对于分布均衡的二叉查找树来说,其查找、删除、插入的时间复杂度稳定于O(logN)。
四、树的遍历
从宏观的角度来看,二叉树的遍历主要归为两类,分别是深度优先遍历(前中后序遍历)、广度优化遍历(层序遍历)。
从节点之间位置关系来看,树的遍历又分为前中后序遍历与层序遍历。
对于二叉树的遍历,为什么需要分几种遍历方式呢?
笔者个人认为主要是因为对于不同的遍历方式,输出的顺序是不一样的;况且对于不同的树针对不同的需求适合不同的遍历方式,因此就需要根据业务需求而选择不同的遍历方式。
例如:中序遍历二叉查找树,可以输出有序的数据序列,时间复杂度为O(n),在排序算法中算是非常非常高效的了。
注:下文所说的根节点其实可以简单理解成一个二叉树中拆分成一颗一颗树的父节点。
- 前序遍历:输出的顺序是根节点、左子树、右子树。
- 中序遍历:输出的顺序是左子树、根节点、右子树。
- 后序遍历:输出的顺序是先是左子树、右子树、根节点。
- 层序遍历:从根节点开始一层层地进行遍历。
- 注:通过上述描述,我想聪明的你会发现,前中后分别是对应着根节点而言了吧。

总的来说,对于不同的遍历方式,其实表示的是节点与其左右节点遍历输出的顺序的不同。
二叉查找树遍历代码实现
引用小灰漫画一书中的代码实现如下:
package chapter3.part2;
import java.util.Arrays;
import java.util.LinkedList;
/**
* Created by weimengshu on 2018/9/22.
*/
public class BinaryTreeTraversal {
/**
* 构建二叉树
* @param inputList 输入序列
*/
public static TreeNode createBinaryTree(LinkedList<Integer> inputList){
TreeNode node = null;
if(inputList==null || inputList.isEmpty()){
return null;
}
Integer data = inputList.removeFirst();
if(data != null){
node = new TreeNode(data);
node.leftChild = createBinaryTree(inputList);
node.rightChild = createBinaryTree(inputList);
}
return node;
}
/**
* 二叉树前序遍历
* @param node 二叉树节点
*/
public static void preOrderTraversal(TreeNode node){
if(node == null){
return;
}
System.out.println(node.data);
preOrderTraversal(node.leftChild);
preOrderTraversal(node.rightChild);
}
/**
* 二叉树中序遍历
* @param node 二叉树节点
*/
public static void inOrderTraversal(TreeNode node){
if(node == null){
return;
}
inOrderTraversal(node.leftChild);
System.out.println(node.data);
inOrderTraversal(node.rightChild);
}
/**
* 二叉树后序遍历
* @param node 二叉树节点
*/
public static void postOrderTraversal(TreeNode node){
if(node == null){
return;
}
postOrderTraversal(node.leftChild);
postOrderTraversal(node.rightChild);
System.out.println(node.data);
}
/**
* 二叉树节点
*/
private static class TreeNode {
int data;
TreeNode leftChild;
TreeNode rightChild;
TreeNode(int data) {
this.data = data;
}
}
public static void main(String[] args) {
LinkedList<Integer> inputList = new LinkedList<Integer>(Arrays.asList(new Integer[]{3,2,9,null,null,10,null,null,8,null,4,}));
TreeNode treeNode = createBinaryTree(inputList);
System.out.println("前序遍历:");
preOrderTraversal(treeNode);
System.out.println("中序遍历:");
inOrderTraversal(treeNode);
System.out.println("后序遍历:");
postOrderTraversal(treeNode);
}
}
有了如此高效的散列表,为什么还需要二叉树呢?
五、树的应用场景
- 1. RDBMS底层存储很多是用B树可B+树,如Mysql 索引底层存储用B+树;
- 2. Hbase与BigTable底层存储用LSM 树;
- 3. 高级语言中的Map容器用链表法+红黑树解决hash冲突;
- 4. 很多机器学习算法的底层数据存储也是基于树结构,如KNN算法运用KDTree。
该系列博文为笔者学习《数据结构与算法之美》的个人笔记小结















 430
430

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









