







字符串匹配问题
- 开始编辑时间:2022年5月19日
- 完成撰写时间:
1. 问题描述
在文本T中找到某个模式P出现的所有位置.若 T [ S + 1.. s + m ] = P [ 1.. m ] T[S+1..s+m]=P[1..m] T[S+1..s+m]=P[1..m],则称模式P在文本T中出现,偏移s是有效偏移。
1.1 算法概述
每一个字符串匹配算法:
- 第一步:基于模式进行预处理
- 第二步:找到所有有效偏移(匹配)
每个算法的预处理时间和匹配时间如下,总运行时间是预处理时间+匹配时间。
| 算法 | 预处理时间 | 匹配时间 |
|---|---|---|
| 朴素算法 | 0 | O ( ( n − m + 1 ) m ) O((n-m+1)m) O((n−m+1)m) |
| Rabin-Karp | Θ ( m ) \Theta(m) Θ(m) | O ( ( n − m + 1 ) m ) O((n-m+1)m) O((n−m+1)m) |
| 有限自动机算法 | O ( m ∣ Σ ∣ ) O(m|\Sigma|) O(m∣Σ∣) | Θ ( n ) \Theta(n) Θ(n) |
| Knuth-Morris-Pratt | Θ ( m ) \Theta(m) Θ(m) | Θ ( n ) \Theta(n) Θ(n) |
Σ \Sigma Σ : 字符串中字符的集合
∣ Σ ∣ |\Sigma| ∣Σ∣ : 集合的长度
1.2 相关概念
- 连结:字符串x和y的连结用"xy“表示
- 前缀:x=wy,则w是x的前缀, w ⊏ x w \sqsubset x w⊏x
- 后缀:x=yw,则w是x的后缀, w ⊐ x w \sqsupset x w⊐x
- 后缀重叠引理:若x,y均是z的后缀,且 ∣ x ∣ ≤ ∣ y ∣ |x| \le |y| ∣x∣≤∣y∣,则 x ⊐ y x \sqsupset y x⊐y
- 字符串相等判断:假设比较是从左向右进行,并且遇到第一个字符不匹配时终止,则需要 Θ ( t + 1 ) \Theta(t+1) Θ(t+1),其中t是x,y的最长公共前缀长度。
2. 朴素算法
对每一个偏移均进行检测是否相等。直到所有的偏移均检测完成。
NAVIE-STRING-MATCHER(T,P)
n = T.length
m = P.length
for s = 0 to n-m
if P[1..m] == T[s+1..s+m]
print "Patern occurs with shift" s
该算法最坏情况下运行时间为: O ( ( n − m + 1 ) m ) O((n-m+1)m) O((n−m+1)m)。这是因为该算法完全忽略了检测无效偏移s时获得的文本信息。后续算法因利用了此信息,算法效率更高。
2.1 算法导论习题讨论
32.1-1
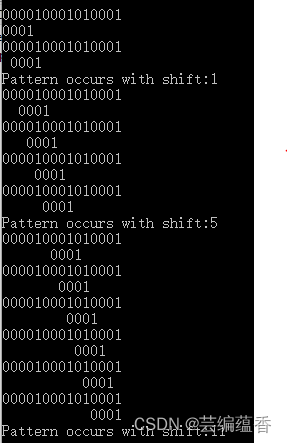
32.1-2
由于模式P中的所有字符都不相同,因此:设P[1…m]和T[s+1…s+m]的公共前缀长度为t。则NAVIE-STRING-MATCHER(T,P)算法中偏移量s每次比较后不进行s+1操作,进行s+t即可达到 O ( n ) O(n) O(n)
32.1-3
分析:循环体进行了(n-m+1)次循环,每次循环需要判断两个长度为m的字符串是否相等。若存在不相等,或完全匹配时终止。例如:第一个字符不相等,则立刻终止。
证明:
令P为单个字符比较匹配的概率,则1-P为失配的概率。
P
=
d
d
∗
d
=
d
−
1
P=\cfrac{d}{d*d}=d^{-1}
P=d∗dd=d−1
| 比较v次数 | 概率 | 比较次数*概率 |
|---|---|---|
| 1 | ( 1 − P ) (1-P) (1−P) | 1*(1-P) |
| 2 | P ( 1 − P ) P(1-P) P(1−P) | 2P(1-P) |
| 3 | P 2 ( 1 − P ) P^{2}(1-P) P2(1−P) | 3 ( P 2 ( 1 − P ) ) 3(P^{2}(1-P)) 3(P2(1−P)) |
| … | … | … |
| m | P m − 1 ( 1 − P ) + P m P^{m-1}(1-P) + P^{m} Pm−1(1−P)+Pm | m ( P m − 1 ( 1 − P ) + P m ) m(P^{m-1}(1-P) + P^{m}) m(Pm−1(1−P)+Pm) |
E
=
∑
k
=
1
m
k
P
k
−
1
(
1
−
P
)
+
m
P
m
E= \sum_{k=1}^m kP^{k-1}(1-P) + mP^{m}
E=∑k=1mkPk−1(1−P)+mPm
E
=
∑
k
=
1
m
P
m
−
1
=
1
−
d
−
m
1
−
d
−
1
E= \sum_{k=1}^m P^{m-1} = \cfrac{1-d^{-m}}{1-d^{-1}}
E=∑k=1mPm−1=1−d−11−d−m
令 f ( x ) = 1 − x − m 1 − x − 1 f(x)=\cfrac{1-x^{-m}}{1-x^{-1}} f(x)=1−x−11−x−m,求导可知x>=2时,导数为负,函数在x>=2时单掉递减。而 f ( 2 ) = 2 ( 1 − d − m ) < = 2 f(2)=2(1-d^{-m})<=2 f(2)=2(1−d−m)<=2.因此得证:朴素算法在字符集 ∑ d \sum_{d} ∑d中的预计比较次数:
( n − m + 1 ) 1 − d − m 1 − d − 1 < 2 ( n − m + 1 ) (n-m+1)\cfrac{1-d^{-m}}{1-d^{-1}}<2(n-m+1) (n−m+1)1−d−11−d−m<2(n−m+1)
由此可知,对于随机字符串,朴素算法的平均效率为 O ( 2 ( n − m + 1 ) ) O(2(n-m+1)) O(2(n−m+1))
32.1-4
改造上述朴素算法,将模式按照间隔符进行分割,分割成多个子字符串进行处理,在前一个子字符串匹配后,从文本匹配的下一个位置开始,匹配下一个子字符串。设*表示间隔字符
NAVIE-STRING-MATCHER-GAP(T,P)
n = T.length
m = P.length
p_list = P.split("*")
n_start = 0
for p_t in p_list:
p_m = p_t.length
for s = n_start to n-p_m:
if p_t[1..p_m] == T[n_start+1..n_start+p_m]
n_start += s+1
else:
return false
return true















 967
967











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









