







最近学习了《Mastering Opencv with Pratical Computer Vision Projects》中第五章:基于SVM和神经网络的车牌识别系统。原文最后提到:当训练OCR这样的机器学习算法时,需要知道所使用的最佳参数和特征,以及如何修正项目中出现的分类、识别和检测错误。文中给出的方法是直接读取保存样本特征的XML文件,将所有样本分为测试组(100个)和训练组,最后通过UNIX脚本来批量不同参数下误差率的计算,并使用gnuplot绘图显示。因为本人对UNIX脚本语言没有接触,这里提供一种生成.m文件,导入matlab实现误差率与所取特征可视化方法。
1.OCR算法评估类
class evalOCR {
public:
OCR ocr;
static const int TRAIN_DATA_TYPE_NUM=4;
public:
//随机选取100个样本
void generateRandom(int n,int min,int max,vector<int> *samples);
//对样本进行测试并求出误差率
float test(Mat samples,Mat classes);
//生成可视化".m"文件
void evaluate(const char* xml_file_path, const string &resName);
void evaluate(const char* xml_file_path,vector<vector<double>>& prec);
int PrintVector(FILE *f, const vector<double> &v, const string &name, int maxNum);
};2.OCR算法类的具体实现
#include "evalOCR.h"
char* data_type[4]={"TrainingDataF5","TrainingDataF10","TrainingDataF15","TrainingDataF20"};
//随机抽取100个样本
void evalOCR::generateRandom(int n,int min,int max,vector<int> *samples) {
int range=max-min;
int r=rand()%range+min;
if(samples->at(r)==0) {
samples->at(r)=1;
n++;
}
if(n<100) {
generateRandom(n,min,max,samples);
}
}
//通过训练模型分类结果与原始类别进行对比,求出错误率
float evalOCR::test(Mat samples,Mat classes) {
float errors=0;
for(int i=0;i<samples.rows;i++) {
int result=ocr.classify(samples.row(i));
if(result != classes.at<int>(i))
errors++;
}
return errors/samples.rows;
}
void evalOCR::evaluate(const char* xml_file_path, const string &resName) {
vector<vector<double>> prec(TRAIN_DATA_TYPE_NUM);
int NUM_MLP;
static const int SHOW_COLOR_NUM = 7;
static const char* colorShow[SHOW_COLOR_NUM] = {"'k'", "'b'", "'g'", "'r'", "'c'", "'m'", "'y'"};
FILE* f = fopen(resName.c_str(), "w");
CV_Assert(f != NULL);
fprintf(f, "clear;\nclose all;\nclc;\nhold on;\nfigure(1);\n\n");
evaluate(xml_file_path,prec);
string leglendStr("legend(");
for (int i = 0; i < TRAIN_DATA_TYPE_NUM; i++) {
string strPre = format("Precision_%s", data_type[i]);
PrintVector(f, prec[i], strPre,100);
fprintf(f, "plot(Precision_%s, %s, 'linewidth', 2);\n", data_type[i], colorShow[i % SHOW_COLOR_NUM]);
leglendStr += format("'%s', ", data_type[i]);
}
leglendStr.resize(leglendStr.size() - 2);
leglendStr += ");";
fprintf(f, "%s\nhold off;\nxlabel('Threshold');\nylabel('Precise');\ngrid on;", leglendStr.c_str());
fclose(f);
}
void evalOCR::evaluate(const char* xml_file_path,vector<vector<double>>& prec) {
//vector<vector<double>> prec;//(TRAIN_DATA_TYPE_NUM);
Mat classes;
Mat trainingData;
//Read file storage
FileStorage fs;
fs.open(xml_file_path,FileStorage::READ);
for(int j=0;j<4;j++) {
char* dataType=data_type[j];
fs[dataType]>>trainingData;
fs["classes"]>>classes;
float result;
//init random generator
srand(time(NULL));
//Create 100 random pos for samples
std::vector<int> isSample(trainingData.rows,0);
generateRandom(0,0,trainingData.rows-1,&isSample);
//Create sample data
Mat train,trainClasses;
Mat samples,samplesClasses;
for(int k=0;k<trainingData.rows;k++) {
if(isSample[k]==1) {
samples.push_back(trainingData.row(k));
samplesClasses.push_back(classes.row(k));
}
else {
train.push_back(trainingData.row(k));
trainClasses.push_back(classes.row(k));
}
}
result=0;
for(int numof_mlp=3;numof_mlp<=100;numof_mlp++) {
ocr.train(train,trainClasses,numof_mlp);
result=test(samples,samplesClasses);
prec[j].push_back(result);
}
}
}
int evalOCR::PrintVector(FILE *f, const vector<double> &v, const string &name, int maxNum)
{
fprintf(f, "%s = [", name.c_str());
maxNum = min(maxNum, (int)v.size());
int i;
for (i = 0; i < maxNum; i++) {
if (v[i] > 0.001) // Very small recall is too much noisy (may due to compression)
fprintf(f, "%g ", v[i]);
else
break;
}
fprintf(f, "];\n");
return i;
}
3.函数主框架
int main()
{
string resultFileName="D:\\EvaluateShow.m";
string xml_path="D:\\OCR.xml";
//vector<vector<double>> precise;
evalOCR evalocr;
evalocr.evaluate(xml_path.c_str(),resultFileName);
cout<<" Done! "<<endl;
getchar();
}
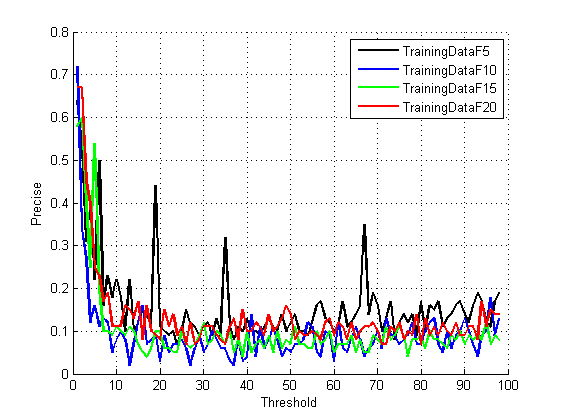
总结说明:
1.读入的"OCR.xml"文件保存了不同分辨率下(5*5,10*10,15*15,20*20)下的特征及所属类别,本文读取的是随书附带的".xml"文件,并未做修改,读入时请注意配置自己的文件路径,若需要自己选取字符特征进行识别判断,请生成自己的"xml"文件。
2.神经网络隐藏层数本测试规定为100层,在此仅仅提供一种可视化方法,并未对特征选取,参数选择做进一步的讨论,而这些对优化系统至关重要。
3.本人小菜鸟一枚,如有任何错误,请大神指出,还要不断努力学习。















 1661
1661

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









