







哈夫曼编码的源代码资源链接:哈夫曼编码
1. 哈夫曼编码过程
- 将信源符号的概率从大到小依次排列
- 取最小的两个符号按规律进行码元赋值,比如最小的两个当中较大的对应码元’1’,较小的那个对应码元’0’
- 重复步骤1,直到所有的概率值都进行码元的赋值
- 从后往前跟踪符号概率出现的位置所对应的码元,该码元序列就是对应概率的哈夫曼码
2. 二叉树概念
1. 二叉树:
定义
二叉树是一个连通的无环图,并且每一个顶点的度不大于3。有根二叉树还要满足根结点的度不大于2。有了根结点之后,每个顶点定义了唯一的父结点,和最多2个子结点。然而,没有足够的信息来区分左结点和右结点。如果不考虑连通性,允许图中有多个连通分量,这样的结构叫做森林
程序结构
二叉树在程序里面是靠链表来实现的,而链表的基本单位就是结构体了,在程序中一个二叉树节点的基本结构就如下面的代码所展现的
struct BinTree
{
int value; //该节点的值
struct BinTree *L_Tree; //该节点的左子节点(如果有的话就赋值,没有的话就为空)
struct BinTree *R_Tree; //该节点的右子节点(如果有的话就赋值,没有的话就为空)
};图像结构
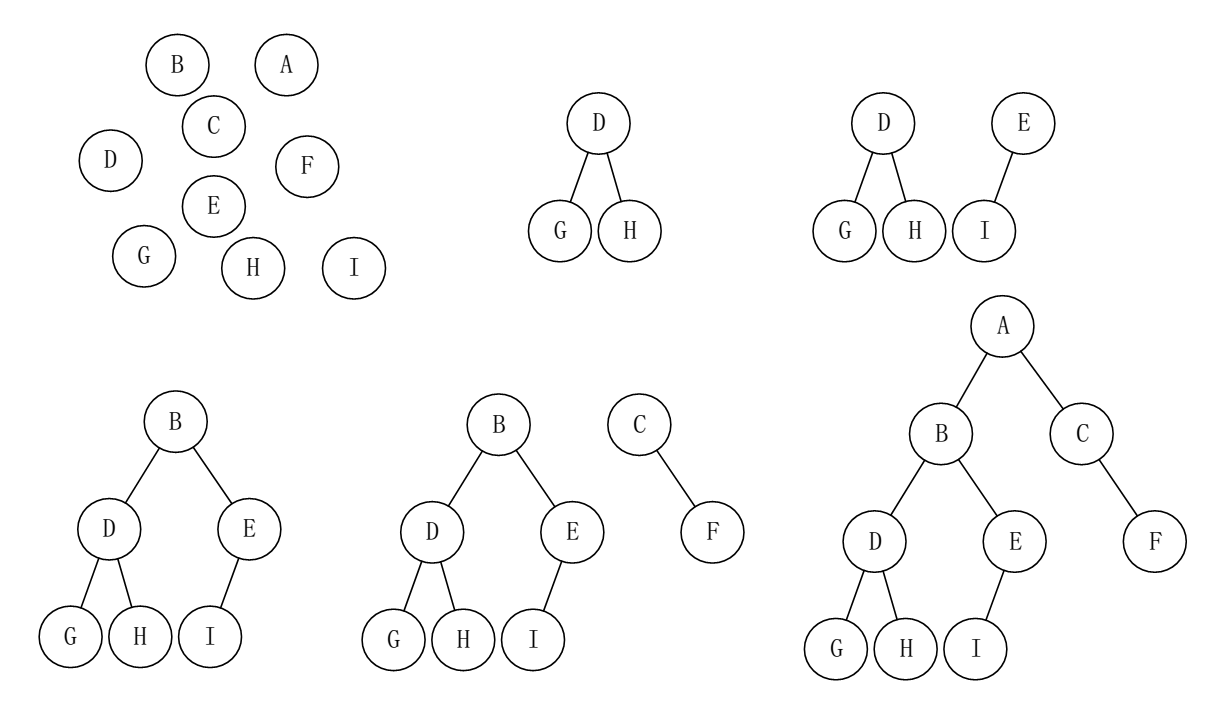
一个基本的二叉树在宏观结构上如下图所示

2. 二叉树的遍历
二叉树分为前序遍历、后序遍历、中序遍历
- 前序遍历:根节点->左子树->右子树
- 中序遍历:左子树->根节点->右子树
- 后序遍历:左子树->右子树->根节点
上图的二叉树结构如果分别用三种遍历方法进行遍历的话访问节点分别是
- 前序遍历:ABDGHEICF
- 中序遍历:GDHBIEACF
- 后序遍历:GHDIEBFCA
3. 二叉树的建立
- 先序建立:建立根节点->建立左子树->建立右子树
- 后序建立:建立左子树->建立右子树->建立根节点
先序建立的图像表达:(从左到右,从上到下)

后序建立的图像表达:(从左到右,从上到下)
3. 快速排序的概念
1. 快速排序的基本思想:
通过一趟排序将要排序的数据分为独立的两部分,其中一部分的数据都要比另一部分的数据大,然后对这两部分数据再次进行快排,分别分为独立的两部分,一直到整个数据序列变为有序的序列
举例:例如要排序的数据为(2,4,7,3,1,8,2,5)
第一次快速排序(基准值为 2,left 为 0,right 为 7),0 和 7 的来源就是要排序的数组下标范围,上面的数组下标范围就是 0 到 7,一共 8 个数。接下来就是 left 不断右移,也就是每次加一,找到大于 2 的数就把它放到此时 right 所对应的下标处。然后 right 不断左移,找到小于 2 的数就把它放到此时 left 所对应的下标,然后再转到 left,不断循环,直到 left 等于 right。我们现在先移动 right 2 2,4,7,3,1,8,2,5 left=0 right=6 2 1,4,7,3,1,8,2,5 left=0 right=4 2 1,4,7,3,4,8,2,5 left=1 right=4 2 1,4,7,3,4,8,2,5 left=1 right=1 2 1,2,7,3,4,8,2,5 left=1 right=1 然后分别对下标为 0-0 和 2-7(以7为基准) 的范围内的数据进行新一轮的快速排序,直到全部完成(0-0不需要再进行排序了)
2. 快速排序的程序实现(递归)
void quick_seq(struct huffman_bintree *t, int left, int right)
{
struct huffman_bintree key = t[left];
int low = left; //不改变 left 的值,因为要用 left 是否等于 right 来作为排序的结束标志
int high = right; //我们用 low 与 high 来替代 left 与 right 的作用
/* 如果 left >= right,程序就结束,不再进行快排 */
if(left < right)
{
/* 如果左下标小于右下标,并且右下标所在的值大于等于基准值的话,就把右下标的值向左移动,一直到
* 左下标等于右下标或者遇到右下标所在的值小于基准值的时候,替换右下标对应的值为左下标对应的值
*/
while((low < high) && (t[high].weight >= key.weight))
{
high --;
}
t[low] = t[high];
/* 如果左下标小于右下标,并且左下标所在的值小于等于基准值的话,就把左下标的值向右移动,一直到
* 左下标等于右下标或者遇到左下标所在的值大于基准值的时候,替换左下标对应的值为右下标对应的值
*/
while((low < high) && (t[low].weight <= key.weight))
{
low ++;
}
t[high] = t[low];
t[low] = key; //最后把基准值放回到左右下标对应的地方,此时左右下标相等,无所谓左边还是右边,放哪都可以
quick_seq(t, left, high - 1); //从基准值分开,对基准值左边的元素进行快排
quick_seq(t, low + 1, right); //从基准值分开,对基准值右边的元素进行快排
}
}4. 哈夫曼树相关概念
1. 哈夫曼树的建立
哈夫曼树是一种最优二叉树,哈夫曼树的节点建立是与每个节点的权重有关的
例如给定一组权重为(0.2,0.1,0.02,0.08,0.3,0.3),其哈夫曼树的构建步骤如下所示
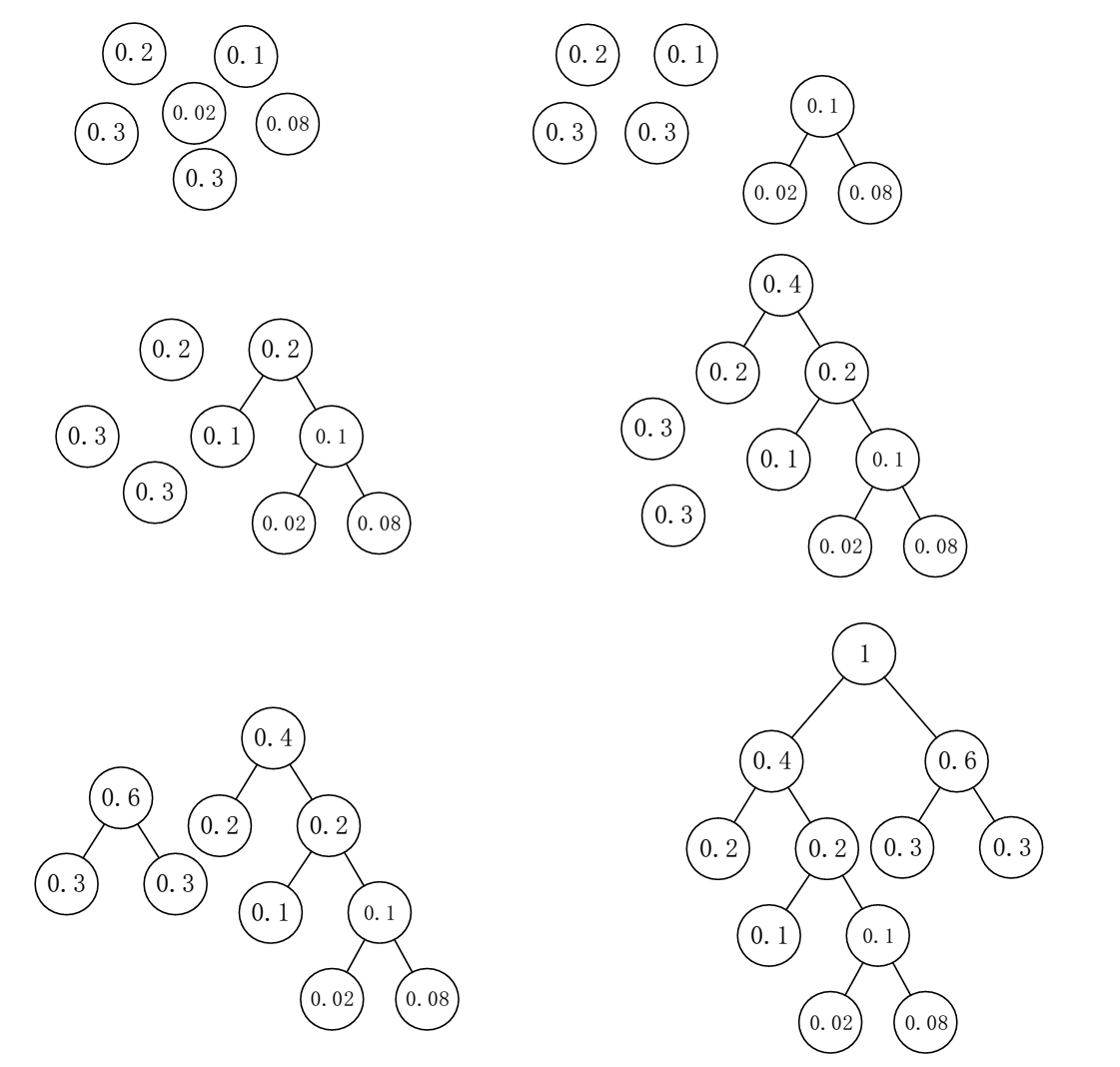
由上图可知,叶子节点的个数就是需要编码的字符的个数,而总的节点个数就是叶子节点个数 leaf*2 - 1 个,也就是说有 leaf-1 个节点是开始并没有的,而是在编码过程中产生的
2. 哈夫曼树建立的程序实现
/* 程序功能 :建立一个哈夫曼树
* forest : 森林(森林指的是所有节点的总和),此处森林的节点个数就是 leaf*2 - 1 个
* weight : 权重数组的开始
* character : 字符数组的开始
* leaf_node_num : 叶子节点个数
*/
void huffman_tree_init(struct huffman_bintree *forest, float *weight, char *character, int leaf_node_num)
{
int leaf_num = 0;
int i = 0;
int not_leaf_num = 0;
not_leaf_num = leaf_node_num - 1; //非叶子节点的数目是叶子节点数目减去1
/* 初始化叶子节点,把叶子节点相应的权值、字符、叶子节点标志、左右子树全部初始化 */
for (leaf_num = 0; leaf_num < leaf_node_num; leaf_num ++)
{
forest[leaf_num].weight = weight[leaf_num]; //根据传入的权值初始化叶子节点的权值
forest[leaf_num].character = character[leaf_num]; //根据传入的字符初始化叶子节点的字符
forest[leaf_num].leaf_node = 1; //1 代表这个节点是叶子节点,这个在遍历哈夫曼树的时候会用得到
forest[leaf_num].l_tree = forest[leaf_num].r_tree = NULL; //叶子节点没有左右子树,所以赋值为空
}
/* 初始化非叶子节点 */
for (i = 0; i < not_leaf_num; i ++)
{
quick_seq(forest, 2*i, i+leaf_node_num-1); //对第 2*i 个到第 i+leaf_node_num-1 减一个 forest 元素进行快速排序,最终结果由小到大排列
forest[i+leaf_node_num].weight = forest[i*2].weight + forest[i*2+1].weight; //新节点的权值等于经过快排之后最小的两个权值的和
forest[i+leaf_node_num].character = 0; //非叶子节点并没有字符
forest[i+leaf_node_num].leaf_node = 0; //非叶子节点,所以为0
/* 其实下面这个判断并不是强制的,只是为了我们平常的手工编码习惯设置的,当然可以一直选择下面任意一个分支 */
if(forest[i*2].weight - forest[i*2+1].weight == 0)
{
forest[i+leaf_node_num].l_tree = &forest[i*2];
forest[i+leaf_node_num].r_tree = &forest[i*2+1];
}
else
{
forest[i+leaf_node_num].l_tree = &forest[i*2+1];
forest[i+leaf_node_num].r_tree = &forest[i*2];
}
}
}3. 哈夫曼树的遍历
按照前序遍历的方式进行遍历,这里不再进行赘述
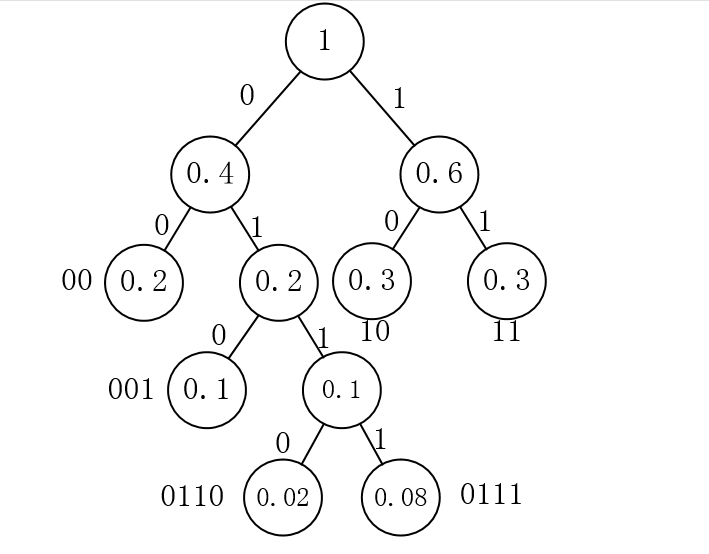
对哈夫曼树进行编码
也就是按照前序遍历的步骤,每遇到一个叶子节点就把当前已经遍历过的所有节点的编码值打印出来,然后退回一个码位,继续遍历,编码结果如下图所示
4. 编码的程序实现
/* 遍历哈夫曼树 */
void huffman_tree_trav(struct huffman_bintree T, char *h_code)
{
int i = 0;
/* 如果这个节点是非叶子节点 */
if(T.leaf_node == 0)
{
h_code[huff_count] = '0'; //先走左边分支,当然也可以先走右边的分支
huff_count ++; //编码数量加一
huffman_tree_trav(*T.l_tree, h_code); //递归进行编码
h_code[huff_count] = '1'; //当上面的函数返回的时候,会进行到这一步,这里走右分支
huff_count ++; //编码数量加一
huffman_tree_trav(*T.r_tree, h_code); //递归进行编码
}
else if(T.leaf_node == 1) //如果是叶子节点,就打印目前 h_code 数组里面存放的所有字符
{
h_code[huff_count] = '\0'; //字符串结束标志
printf("| letter : %c\thuffman_code : %s", T.character, h_code); //打印编码
/* 只是用作数据输出对齐,不用管这一部分 */
for (i = 0; i < 37 - strlen(h_code); i ++)
{
printf(" ");
}
printf("|\n");
huffman_code_length += T.weight*strlen(h_code); //计算平均码长
}
huff_count --; //当此函数返回的时候已经到达叶子节点,我们需要返回该叶子节点的根节点,然后进行另一个分支的遍历,所以编码数要减去一
}














 999
999

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









