







1 背景
公司后端服务是java体系,运用k8s进行搭建,服务监控是用Prometheus+Grafana进行监控,发现容器监控层面的WSS会持续增长,而RSS保持不变。故有个疑惑:
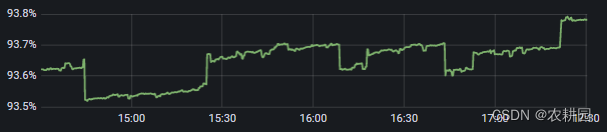
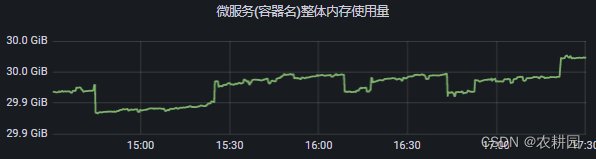
- WSS是什么指标
- 为什么WSS会持续增长
- WSS增长之后到极限值后,怎么处理
2 集群日志架构
3 基本概念
VSS:Virtual Set Size 虚拟耗用的内存(包含与其他进程共享占用的虚拟内存)
RSS:Resident Set Size实际使用的物理内存(包含与其他进程共享占用的内存)
PSS:Proportional Set Size实际使用的物理内存(按比例包含与其他进程共享占用的内存)
USS:Unique Set Size进程独自占用的物理内存(不包含与其他进程共享占用的内存)
对于单个进程,一般来说内存占用大小排序如下:VSS >= RSS >= PSS >= USS
4 分析
4.1 监控数据
监控数据是采集的kubernetes中监控程序cadvisor上报的container_memory_working_set_bytes字段。
指标参考地址:
https://github.com/google/cadvisor/blob/master/docs/storage/prometheus.md
| Metric name | Type | Metric name | Type |
|---|---|---|---|
| container_memory_rss | Gauge | Size of RSS | bytes |
| container_memory_swap | Gauge | Container swap usage | bytes |
| container_memory_usage_bytes | Gauge | Current memory usage, including all memory regardless of when it was accessed | bytes |
| container_memory_working_set_bytes | Gauge | Current working set | bytes |
查看cadvisor源码中setMemoryStats 可知,container_memory_working_set_bytes字段是cgroup memory.usage_in_bytes(RSS + Cache)与memory.stat total_inactive_file二者的差值
func setMemoryStats(s *cgroups.Stats, ret *info.ContainerStats) {
// ...
// ...
inactiveFileKeyName := "total_inactive_file"
if cgroups.IsCgroup2UnifiedMode() {
inactiveFileKeyName = "inactive_file"
}
workingSet := ret.Memory.Usage
if v, ok := s.MemoryStats.Stats[inactiveFileKeyName]; ok {
if workingSet < v {
workingSet = 0
} else {
workingSet -= v
}
}
ret.Memory.WorkingSet = workingSet
}
注意:
memory.usage_in_bytes的统计数据是包含了所有的file cache的,total_active_file和total_inactive_file都属于file cache的一部分,但是这两个数据并不是Pod中的程序真正占用的内存,只是系统为了提高磁盘IO的效率,将读写过的文件缓存在内存中。file cache并不会随着进程退出而释放,只会当容器销毁或者系统内存不足时才会由系统自动回收。
所以cadvisor采用memory.usage_in_bytes - total_inactive_file计算出的结果并不是当前Pod中程序所占用的内存,当Pod内存资源紧张时total_active_file也是可回收利用的。
4.2 验证
4.2.1 第一次遍历
找一个比较大的文件:
/app # ls -lah /data/log/xxxx.log
-rw-r--r-- 1 root root /data/log/xxxx.log
查看内存数据
在容器中进入/sys/fs/cgroup/memory/目录,并查看cat memory.stat内容
/app # cd /sys/fs/cgroup/memory/
/sys/fs/cgroup/memory # cat memory.stat
cache 714813440
rss 4415488
rss_huge 0
shmem 0
mapped_file 11218944
dirty 405504
writeback 135168
pgpgin 289641
pgpgout 113984
pgfault 149424
pgmajfault 66
inactive_anon 2248704
active_anon 2162688
inactive_file 18096128
active_file 696942592
unevictable 0
hierarchical_memory_limit 9223372036854771712
total_cache 20359831552
total_rss 11527815168
total_rss_huge 171966464
total_shmem 18653184
total_mapped_file 769241088
total_dirty 4325376
total_writeback 7163904
total_pgpgin 414322491
total_pgpgout 407001393
total_pgfault 536448693
total_pgmajfault 11979
total_inactive_anon 360513536
total_active_anon 10174644224
total_inactive_file 18857082880
total_active_file 2497884160
total_unevictable 0
记录此时
total_inactive_file 18857082880 Bytes =17,983.515625 M
total_active_file 2497884160 Bytes =2,382.16796875 M
计算方式:
18857082880/1024/1024 =17,983.515625
4.2.2 第二次遍历(待验证)
遍历日志文件,
/sys/fs/cgroup/memory # grep “data” /data/log/xxx.log
第二次查看;
4.2.3 第三次遍历(待验证)
遍历日志文件,第三次查看;
4.2.4 总结
根据上述实验结果可以印证内存持续增长但不会OOM的现象。服务启动并向磁盘中持续追加日志文件,随之file cache持续上涨,直至达到Pod的内存上限之后,会出现GC。
memory.usage_in_bytes统计包含了Cached和Buffers,Cached中除了mlock_file和Shmem(IPCS shared memory & tmpfs)外, 其他部分file cache是可以回收使用的,Buffers也是可以回收利用的,所以Pod容器所在cgroup实际使用的内存计算公式可以转化为 (因memory.stat未导出SReclaimable,这里忽略SReclaimable):
real_used = memory.usage_in_bytes – (Cached- Shmem - mlock_file + Buffers )
= memory.usage_in_bytes – memory.stat.total_active_file
因此cadvisor中container_memory_working_set_bytes字段在计算实际已使用内存时应该改为:
real_used = memory.usage_in_bytes – memory.stat.total_active_file















 2278
2278











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









