




 本文详细介绍了如何集成HDFS到Hue,包括修改core-site.xml和hdfs-site.xml配置,以及调整hue.ini以允许HTTPFS访问。接着,文章讲述了Hue与YARN的集成,涉及修改hue.ini以设置ResourceManager信息,并开启YARN的日志聚集服务。最后,提到了重启相关服务以应用配置更改。
本文详细介绍了如何集成HDFS到Hue,包括修改core-site.xml和hdfs-site.xml配置,以及调整hue.ini以允许HTTPFS访问。接着,文章讲述了Hue与YARN的集成,涉及修改hue.ini以设置ResourceManager信息,并开启YARN的日志聚集服务。最后,提到了重启相关服务以应用配置更改。
1 集成HDFS
注意修改完 HDFS 相关配置后,需要把配置 scp 给集群中每台机器,重启 hdfs集群。
1.1 修改 core-site.xml 配置
<!—允许通过 httpfs 方式访问 hdfs 的主机名 -->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<!—允许通过 httpfs 方式访问 hdfs 的用户组 -->
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
1.2 修改 hdfs-site.xml 配置
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
1.3 修改 hue.ini
cd /home/hue-3.9.0-cdh5.14.0/desktop/conf
vim hue.ini
[[hdfs_clusters]]
[[[default]]]
fs_defaultfs=hdfs://192.168.222.138:9000
#注意如果hadoop是2.X的则是50070
webhdfs_url=http://192.168.222.138:9870/webhdfs/v1
hadoop_hdfs_home= /home/hadoop-3.1.4
hadoop_bin=/home/hadoop-3.1.4/bin
hadoop_conf_dir=/home/hadoop-3.1.4/etc/hadoop
1.4 重启 HDFS、Hue
start-dfs.sh
cd /home/hue-3.9.0-cdh5.14.0/
build/env/bin/supervisor
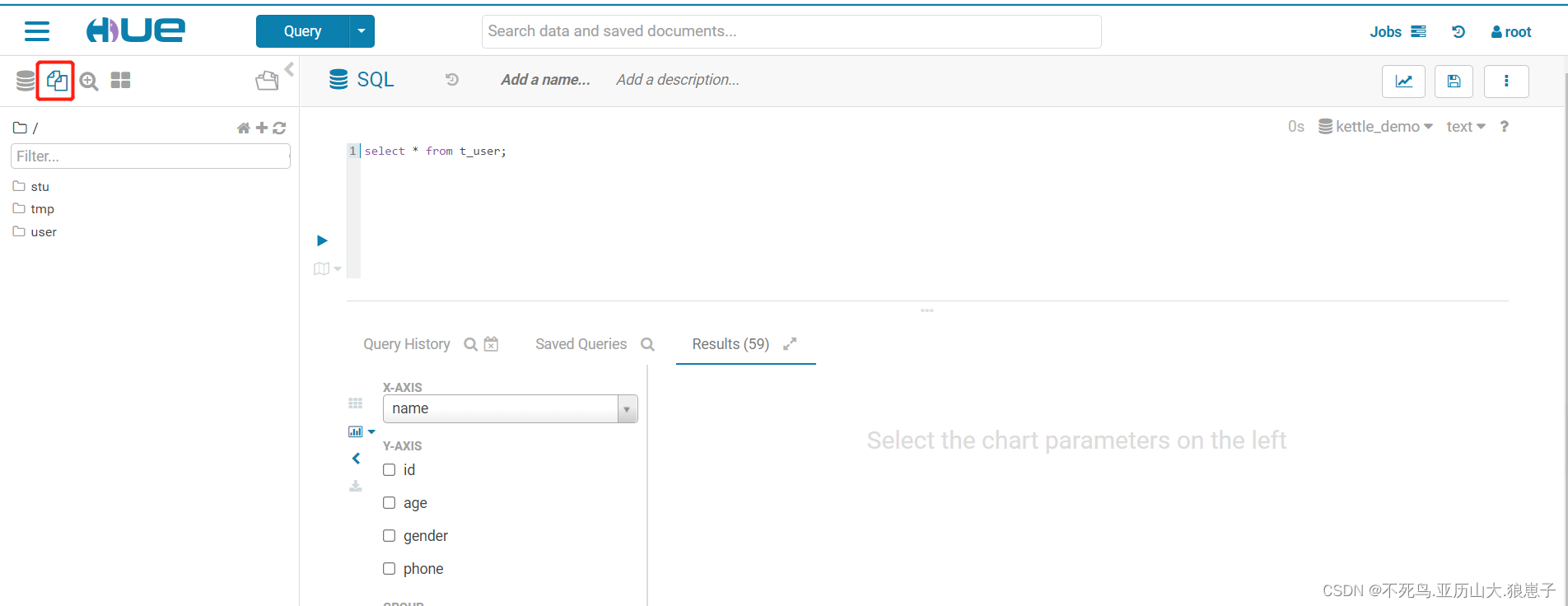
hue的webUI查看:
2 Hue 集成 YARN
2.1 修改 hue.ini
[[yarn_clusters]]
[[[default]]]
resourcemanager_host=192.168.222.138
resourcemanager_port=8032
submit_to=True
resourcemanager_api_url=http://192.168.222.138:8088
history_server_api_url=http://192.168.222.138:19888
2.2 开启 yarn 日志聚集服务
MapReduce 是在各个机器上运行的, 在运行过程中产生的日志存在于各个机器上,为了能够统一查看各个机器的运行日志,将日志集中存放在 HDFS 上,这个过程就是日志聚集。
修改yarn-site.xml文件:
<property> ##是否启用日志聚集功能。
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property> ##设置日志保留时间,单位是秒。
<name>yarn.log-aggregation.retain-seconds</name>
<value>106800</value>
</property>
2.3 重启 Yarn、Hue
build/env/bin/supervisor
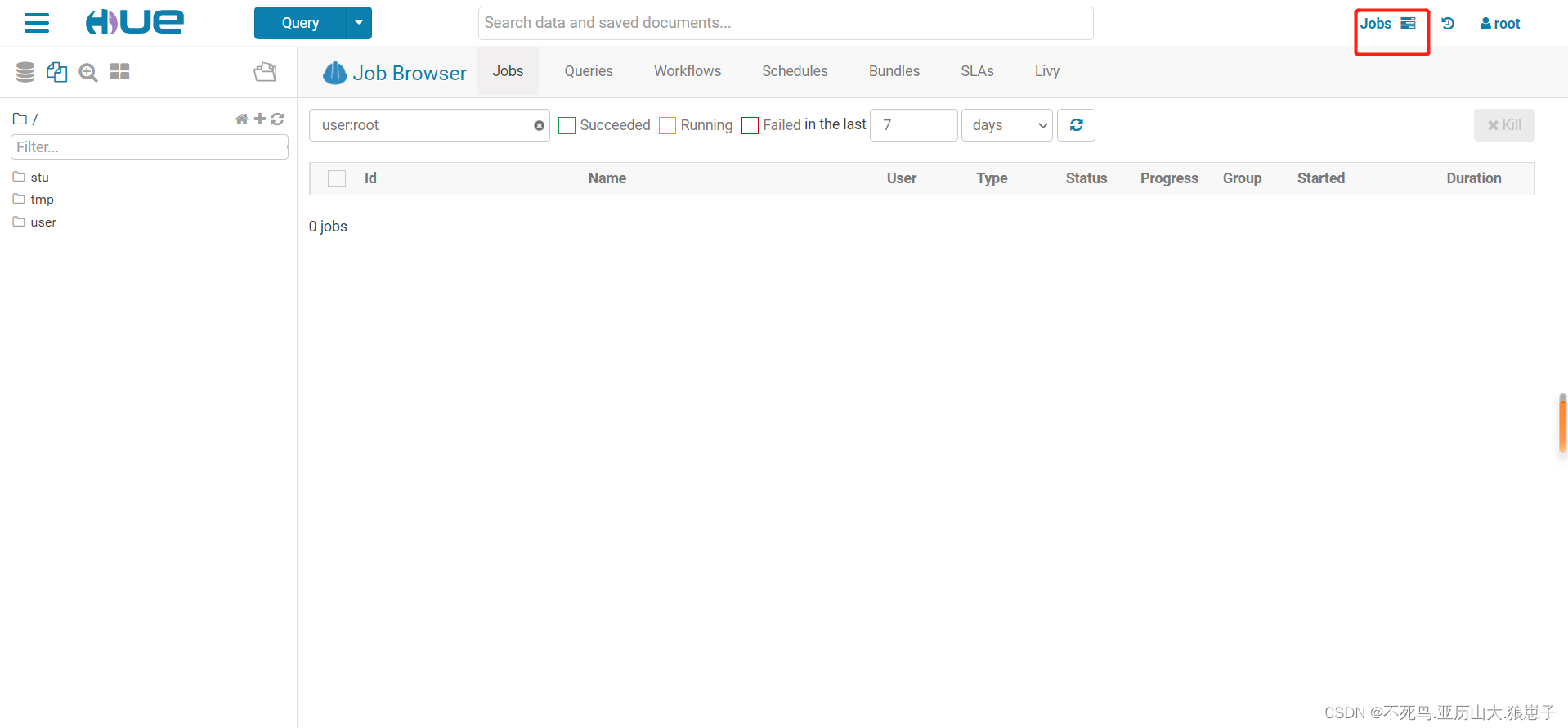
hue的webUI查看:



















 4049
4049

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











