







 本文详细介绍了MySQL的EXPLAIN关键字,用于分析SQL查询的执行计划,包括表的读取顺序、数据类型、索引使用等。通过案例展示了如何通过创建和优化索引来提升查询性能,强调了避免全表扫描、使用覆盖索引、合理利用索引顺序以及避免OR操作的重要性。此外,还讨论了ORDER BY和GROUP BY子句对查询效率的影响以及优化策略。
本文详细介绍了MySQL的EXPLAIN关键字,用于分析SQL查询的执行计划,包括表的读取顺序、数据类型、索引使用等。通过案例展示了如何通过创建和优化索引来提升查询性能,强调了避免全表扫描、使用覆盖索引、合理利用索引顺序以及避免OR操作的重要性。此外,还讨论了ORDER BY和GROUP BY子句对查询效率的影响以及优化策略。
一、explan 关键字解析
1.1、 explain 是什么?
使用 explan 关键字,你可以模拟mysql优化器执行SQL查询语句,从而知道 MYSQL 是如何处理你的SQL语句的,分析你的查询语句或是表结构的性能瓶颈。
1.2、使用 explain 能干什么?##
- 查看表的读取顺序:
- 数据读取操作的操作类型:
- 哪些索引可以使用:
- 哪些索引被实际使用:
- 表之间的引用:
- 每张表有多少行被优化器查询
1.3、使用方式
使用 EXPLAIN + 查询的语句,查看执行结果:

1.4、explan 字段解析
sql脚本如下:
CREATE TABLE `sys_user` (
`id` char(32) NOT NULL COMMENT '主键',
`org_id` char(32) NOT NULL,
`account` varchar(20) NOT NULL COMMENT '登陆账号',
`phone` varchar(15) NOT NULL COMMENT '手机号',
`password` varchar(100) NOT NULL COMMENT '登陆密码',
`email` varchar(50) DEFAULT NULL COMMENT '邮箱号',
`real_name` varchar(20) NOT NULL COMMENT '真实名称',
`sex` char(1) NOT NULL COMMENT '用户性别(1,男,2:女)',
`icon_path` varchar(100) DEFAULT NULL COMMENT '用户头像',
`birth` date DEFAULT NULL COMMENT '生日',
`user_status` char(1) NOT NULL COMMENT '用户状态',
PRIMARY KEY (`id`) USING BTREE,
UNIQUE KEY `account` (`account`) USING BTREE,
KEY `user_org_id` (`org_id`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci ROW_FORMAT=DYNAMIC COMMENT='用户基本信息表';
CREATE TABLE `sys_user_role` (
`id` char(32) NOT NULL,
`user_id` char(32) NOT NULL,
`role_id` char(32) NOT NULL,
PRIMARY KEY (`id`) USING BTREE,
KEY `FK_Reference_8` (`role_id`) USING BTREE,
KEY `sys_user_role_ibfk_1` (`user_id`) USING BTREE,
CONSTRAINT `sys_user_role_ibfk_1` FOREIGN KEY (`user_id`) REFERENCES `sys_user` (`id`) ON DELETE RESTRICT ON UPDATE RESTRICT,
CONSTRAINT `sys_user_role_ibfk_2` FOREIGN KEY (`role_id`) REFERENCES `sys_role` (`id`) ON DELETE RESTRICT ON UPDATE RESTRICT
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci ROW_FORMAT=DYNAMIC COMMENT='用户角色表';
CREATE TABLE `sys_role` (
`id` char(32) NOT NULL,
`app_id` char(32) NOT NULL COMMENT '应用id',
`role_code` varchar(20) NOT NULL COMMENT '角色编号',
`role_name` varchar(30) NOT NULL COMMENT '角色名称',
`role_status` char(1) NOT NULL COMMENT '角色状态(0:禁用,1:启用)',
`description` varchar(200) DEFAULT NULL COMMENT '描述',
`created_by` char(32) NOT NULL,
`created_date` datetime NOT NULL,
`last_modified_by` char(32) NOT NULL,
`last_modified_date` datetime NOT NULL,
PRIMARY KEY (`id`) USING BTREE,
KEY `role_app_id` (`app_id`) USING BTREE,
CONSTRAINT `sys_role_ibfk_1` FOREIGN KEY (`app_id`) REFERENCES `sys_app` (`id`) ON DELETE RESTRICT ON UPDATE RESTRICT
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci ROW_FORMAT=DYNAMIC COMMENT='角色表';
-
id
select 查询的序列号,由一组数字组成。
id 全相同,从上到下依次执行
id全不同,id值越大,会越先执行,如子查询。
id有相同,也有不同,id值数字大的先执行,id值相同的会从上到下顺序执行,可能会出现衍生表(DERIVED)。 -
select_type
主要用于区别复合查询、子查询、等复杂查询,值有:- SIMPLE
简单查询 ,查询中不包含子查询或 UNION - PRIMARY
查询中若包含任何复杂的子部分,最外层查询则被标记为 PRIMARY. - SUBQUERY
在select或where 列表中包含子查询。 - DERIVED
在 FROM列表中包含子查询被标记为 DERIVED(衍生) ,MYSQL会递归执行这些子查询,把结果放在临时表里。 - UNION
若在第二个SELECT出现了 union ,则被标记为 UNION;
若UNION包含在FROM了句的子查询中,外层SELECT将被标记为 DERIVED - UNION RESULT
从 UNION表获取结果的SELECT.
- SIMPLE
-
table
查询的表名 -
partitions
如果表使用了分区,会显示指定的访问分区 -
type
此参数与查询效率相关,从最差到最好排序如下(一般能优化到 range 级别会有较好的性能,最好能达到 ref 级别更好,以下列出的只是常见的,但type的值不仅只有如下几种):
ALL > index > range > ref > eq_ref > const > system- ALL
最差,从磁盘全表扫描,如果表中的数据量达到百万级别时,一定要优化。

- index
全索引扫描,从索引中读取,如查询的字段刚好是索引列,如下,id与account都创建了索引,不是使用 select * from xxx。

- range
使用between and或in或>、<、>=、<=查询。

- ref
非唯一性索引扫描,返回匹配某个单独值的所有行,本质上也是一种索引访问,它返回的所有匹配某个单独值的行,也有可能找到多个符合条件的行,所以他应该属于查找和扫描的混合体,如 explain select * from user where username = ‘xxx’ ,用户名相同的会有多个。

- eq_ref
唯一性索引扫描,对于每个索引键,表中只有一条记录与之匹配,常见于主键或唯一索引扫描,如两表关联,其中一张表只有一条记录。

- const
表示通过索引一次就找到了,如主键或唯一索引,如下:account字段为唯一索引。

- system
表中只有一行记录,这是const的特例,平时一般不会出现。
- ALL
-
possible_keys
显示可能应用到这张表中的索引,一个或多个,但不一定会被查询实际使用。 -
key
实际使用的索引,如果为 NULL, 则没有使用索引,如果查询中使用了覆盖索引,则该索引仅出现在 key 列表中,不会出现在 possible_keys 列表中。 -
ken_len
索引中使用的字节数,值越小越好。 -
ref
显示索引的哪一列被使用了,如果可能的话,是一个常数,哪些列或常量被用于查询索引列上的值。 -
rows
检索的行数,值越小越好。 -
Extra
其它扩展属性- Using filesort
mysql会对数据使用一个外部的索引排序,而不是按索引次序从表里读取行。此时mysql会根据联接类型浏览所有符合条件的记录,并保存排序关键字和行指针,然后排序关键字并按顺序检索行信息。这种情况下一般也是要考虑使用索引来优化的,如下,birth 字段未创建索引

- Using temporary
使用了临时表保存中间结果,出现这种情况一般是要进行优化的,首先是想到用索引来优化。

- USING index
这发生在对表的请求列都是同一索引的部分的时候,返回的列数据只使用了索引中的信息,而没有再去访问表中的行记录。是性能高的表现。如下,查询的 id 和 account 列都创建了索引。

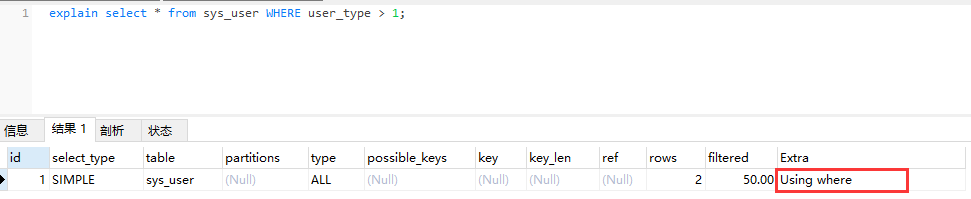
- Using where
mysql将在存储引擎检索行后再进行过滤。就是先读取整行数据,再按 where 条件进行检查,符合就留下,不符合就丢弃。
- Using join buffer
Block Nested-Loop Join算法:将外层循环的行/结果集存入join buffer, 内层循环的每一行与整个buffer中的记录做比较,从而减少内层循环的次数。优化器管理参数optimizer_switch中中的block_nested_loop参数控制着BNL是否被用于优化器。默认条件下是开启,若果设置为off,优化器在选择 join方式的时候会选择NLJ(Nested Loop Join)算法。
Batched Key Access原理:对于多表join语句,当MySQL使用索引访问第二个join表的时候,使用一个join buffer来收集第一个操作对象生成的相关列值。BKA构建好key后,批量传给引擎层做索引查找。key是通过MRR接口提交给引擎的(mrr目的是较为顺序)MRR使得查询更有效率,要使用BKA,必须调整系统参数optimizer_switch的值,batched_key_access设置为on,因为BKA使用了MRR,因此也要打开MRR,参考:http://www.cnblogs.com/chenpingzhao/p/6720531.html

- impossible where
where子句的值总是 false,不能用来获取任何元组。如下, where条件总是返回false.

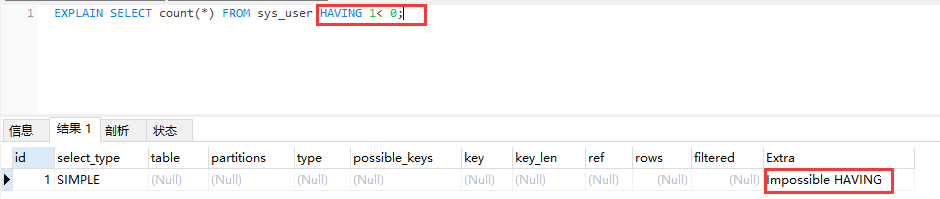
- Impossible HAVING
HAVING子句总是为false,不能选择任何行
- distinct
优化 distinct 操作,在找到第一个匹配的元组后即停止找同样值的动作。

- Using filesort
extra 属性还有其它的值,可参考官网文档 https://dev.mysql.com/doc/refman/8.0/en/explain-output.html#explain_extra。
二、sql优化案例
2.1、单表优化
CREATE TABLE `article` (
`id` varchar(36) NOT NULL,
`title` varchar(200) DEFAULT NULL,
`category_id` varchar(36) DEFAULT NULL,
`comments` int(10) DEFAULT NULL,
`views` int(10) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
在没有创建索引的情况下,当执行如下查询时,会全表扫描,且使用了 Using filesort:

创建索引后,type 变成了 range,而 Extra 还是会存在 Using filesort:
CREATE INDEX category_id_comments_views ON article(`category_id`, `comments`, `views`);

当将查询条件修改为 =时,查看 Extra值不再有 Using filesort

或者删除 comments 字段索引,如下:
DROP INDEX category_id_comments_views ON article;
CREATE INDEX category_id_comments_views ON article(`category_id`, `views`);

由上可知结论:范围之后使用的索引会失效
如果将 category_id 的查询条件删除,可知索引失效

如果将 comments 的查询条件删除,索引有效,但排序失效

由上可知结论:对于复合索引,如果不是根据创建时的索引顺序进行查询或排序,索引可能会失效
使用 select * 查询,排序字段都使用索引,并且都是降序排序,如下,mysql不会按索引次序从表里读取行

使用 select column 索引字段查询,并使用索引字段排序,但不是按全部升序/降序 排序,结果如下:

使用 select column 索引字段查询,并使用索引字段排序,且按全部升序/降序 排序,结果如下:

由上可知结论:查询字段不要使用 select * from xxx,需要指定字段名,排序字段要全部同时使用 升序/降序 排序
2.2、两表优化
CREATE TABLE `article` (
`id` varchar(36) NOT NULL,
`title` varchar(200) DEFAULT NULL,
`category_id` varchar(36) DEFAULT NULL,
`comments` int(10) DEFAULT NULL,
`views` int(10) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
CREATE TABLE `book` (
`id` varchar(36) NOT NULL,
`category_id` varchar(36) DEFAULT NULL,
`name` varchar(50) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
如上,两张表都有 category_id 字段,执行左连接查询时,两表都会使用 ALL:

假设在左边表 category_id 列创建索引,查看效果如下:
CREATE INDEX category_id ON article(`category_id`);
```sql

假设在右边表 `category_id` 列创建索引,查看效果如下:
```sql
DROP INDEX category_id ON article;
CREATE INDEX category_id ON book(`category_id`);
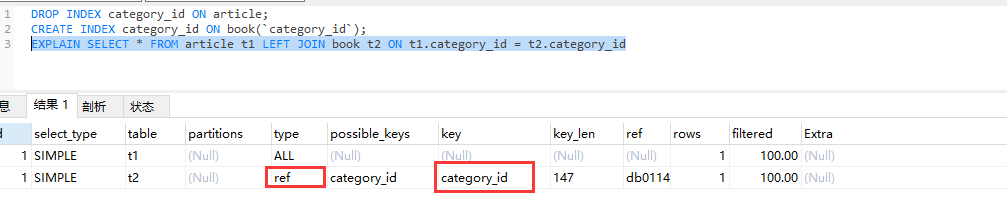
由上可知结论:使用LEFT JOIN 外键关联的字段,索引应该建立在右边表上。同理,使用 RIGNT JOIN 外键关联的字段,索引应该建立在左边表上。这里不再演示
2.3 多表优化
多表优化同两表优化类似,如果使用 LEFT JOIN ,索引建立在右边表外键上,如果使用 RIGHT JOIN,索引建立在左边表外键上,这里不再演示。
2.4 索引失效如何避免
-
全部匹配索引效率高
-
最佳左前缀法则
对于多列索引,应该根据创建索引的列顺序进行查询,如果中间有断开,在断开右边的索引会失效。 -
不要在索引列上做任何操作,(如计算、函数、自动或手动类型转换,这样会导致索引失效而专项全表扫描)
假设表中存在 category_id 列,并且该列的类型为 varchar,且创建了索引
如下:使用条件查询,值也为字符串,会使用到索引。

如下,如果将条件的值改为数字类型,索引失效。mysql内部优化器会执行自动 类型转换。

-
存储引擎不能使用索引中范围条件右边的列
-
尽量使用覆盖索引(只访问索引列的查询,减少 select *)
-
mysql 在使用不等于(!= 或者 <>)时可能会无法使用索引导致全表扫描,在8.0版本以上会使用索引
-
IS NULL / IS NOT NULL 也无法使用索引,在 8.0 版本以上会使用索引
-
LIKE 以通配符开头 (%xxx%) 时,mysql索引可能会失效变成全表扫描
使用LIKE %xxx%,并且 查询字段为select *,索引失效

如果将查询字段改为select id,category_id,即查询的列都创建了索引,使用通配符索引也会有效。

-
少用 or,用它来连接查询可能会导致索引失效
2.5、ORDER BY 子句
ORDER BY 尽量使用 Index 方式排序,避免使用 FileSort 方式排序。
尽可能在索引列上完成排序操作,遵照索引最佳左缀法则。
如果不在索引列上,filesort 有两种算法:
-
双路排序
会有两次磁盘IO,得到数据 -
单路排序
从磁盘读取查询所需要的所有列,按照ORDER BY在buffer对它进行排序,然后扫描排序后的列表进行输出,它的效率更快一些,避免了第二次读取数据。并且把随机IO变成了顺序IO,但是它会使用更多的空间,因为它把每一行都保存在了内存里。但有时候,使用单路排序一次性不能拿出所有数据,那么可能会比双路排序更消耗IO,效率会更慢。
什么情况下会导致单路排序失效呢?
在sort_buffer中,单路排序要比双路排序占很多空间,因为单路排序把所有的字段都取出,所以有可能取出的数据的总大小超出了sort_buffer的容量,导致每次只能读取sort_buffer容量大小的数据,进行排序(创建tmp文件,多路合并),排完再取sort_buffer容量大小,再次排序…从而多次I/O。偷鸡不成蚀把米。
比如:内存就是2M,一次查1000条数据刚好,也就是最大1000条数据,但是一次要查5000条,那么不够了,照这样需要查5次刚好,如果把2M改为10M,那么就刚好了。
提高ORDER BY速度的技巧:
1、ORDER BY时不要使用SELECT *,只查需要的字段。
a:当查询的字段大小综合小于max_length_for_sort_data而且排序字段不是TEXT|BLOB类型时,会用改进后的算法—单路排序,否则用老算法—多路排序。假设只需要查10个字段,但是SELECT *会查80个字段,那么就容易把sort_buffer缓冲区用满。
b:两种算法的数据都有可能超出sort_buffer的容量,超出之后,会创建tmp文件进行合并排序,导致多次I/O,但是用单路排序算法的风险会更大一些,所以要提高sort_buffer_size大小。
2、修改 my.conf 配置文件,增大sort_buffer_size参数大小
不管用哪种算法,提高这个参数都会提高效率。当然要根据系统能力去提高,因为这个参数是针对每个进程的。
3、修改 my.conf 配置文件,增大max_length_for_sort_data参数大小
提高这个参数,会增加用改进算法的概率。但是如果设的太高,数据总量超出sort_buffer_size的概率就增大,明显症状是高的磁盘I/O活动和低的处理器使用率。
2.6、GROUP BY 子句
group by 实质是先排序后进行分组,遵照索引创建的最佳左前缀。
当无法使用索引列时,增大 max_length_for_sort_data参数的设置和 sort_buffer_size 参数的值。
能写在where 限定的条件就不要写到 having 中去。


















 3116
3116

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











