







一、概述
1.1 在k8s中部署Prometheus监控的方法
通常在k8s中部署prometheus监控可以采取的方法有以下三种
- 通过yaml手动部署
- operator部署
- 通过helm chart部署
1.2 什么是Prometheus Operator
Prometheus Operator的本职就是一组用户自定义的CRD资源以及Controller的实现,Prometheus Operator负责监听这些自定义资源的变化,并且根据这些资源的定义自动化的完成如Prometheus Server自身以及配置的自动化管理工作。以下是Prometheus Operator的架构图:

1.3 为什么用Prometheus Operator
由于Prometheus本身没有提供管理配置的AP接口(尤其是管理监控目标和管理警报规则),也没有提供好用的多实例管理手段,因此这一块往往要自己写一些代码或脚本。为了简化这类应用程序的管理复杂度,CoreOS率先引入了Operator的概念,并且首先推出了针对在Kubernetes下运行和管理Etcd的Etcd Operator。并随后推出了Prometheus Operator.
1.4 kube-prometheus项目介绍
prometheus-operator官方地址:https://github.com/prometheus-operator/prometheus-operator
kube-prometheus官方地址:https://github.com/prometheus-operator/kube-prometheus
两个项目的关系:前者只包含了Prometheus Operator,后者既包含了Operator,又包含了Prometheus相关组件的部署及常用的Prometheus自定义监控,具体包含下面的组件:
- The Prometheus Operator:创建CRD自定义的资源对象
- Highly available Prometheus:创建高可用的Prometheus
- Highly available Alertmanager:创建高可用的告警组件
- Prometheus node-exporter:创建主机的监控组件
- Prometheus Adapter for Kubernetes Metrics APIs:创建自定义监控的指标工具(例如可以通过nginx的request来进行应用的自动伸缩)
- kube-state-metrics:监控k8s相关资源对象的状态指标
- Grafana:进行图像展示
二、环境介绍
本文的k8s环境是通过kubeadm搭建的v 1.23.5版本,由2master+2node组合,部署方式.
kube-prometheus 的兼容性说明请参考: https://github.com/prometheus-operator/kube-prometheus ,这里以 release-0.10版本作演示
三、清单准备
从官方的地址获取最新的release-0.10分支,或者直接打包下载release-0.10
[root@k8s-170 ~]# git clone https://github.com/prometheus-operator/kube-prometheus.git
[root@k8s-170 ~]# git checkout release-0.10
## manifests 目录就是所有的配置清单
[root@k8s-170 ~]# cd kube-prometheus/manifests
## 创建ngress文件,暴露外部访问
### altermanager ingress配置,可以通过 k8s-alter.kevin.com 来访问altermanager
[root@k8s-170 manifests]# cat alertmanager-route.yaml
kind: IngressRoute
apiVersion: traefik.containo.us/v1alpha1
metadata:
name: alertmanager-route
namespace: monitoring
spec:
entryPoints:
- web
routes:
- match: Host(`alertmanager.kevin.com`)
kind: Rule
services:
- name: alertmanager-main
port: 9093
### prometheus ingress配置,可以通过 k8s-prometheus.kevin.com 来访问prometheus
[root@k8s-170 manifests]# cat prometheus-route.yaml
kind: IngressRoute
apiVersion: traefik.containo.us/v1alpha1
metadata:
name: prometheus-route
namespace: monitoring
spec:
entryPoints:
- web
routes:
- match: Host(`prometheus.kevin.com`)
kind: Rule
services:
- name: prometheus-k8s
port: 9090
### grafanaingress配置,可以通过 k8s-grafana.kevin.com 来访问grafana
[root@k8s-170 manifests]# cat grafana-route.yaml
kind: IngressRoute
apiVersion: traefik.containo.us/v1alpha1
metadata:
name: grafana-route
namespace: monitoring
spec:
entryPoints:
- web
routes:
- match: Host(`grafana.kevin.com`)
kind: Rule
services:
- name: grafana
port: 3000
配置grafana 持久化存储
参考: https://blog.csdn.net/u013984806/article/details/124723548 中的 测试使用Pod和PVC 配置
配置 prometheus 持久化存储
参考: https://blog.csdn.net/u013984806/article/details/124723548 中的 测试使用Pod和PVC和默认的StorageClass 配置
应用所有资源清单
## 应用 setup目录下的所有配置清单
## 加 --server-side 参数,参考: https://github.com/prometheus-operator/kube-prometheus/issues/1533 ,不加会报错 `is invalid: metadata.annotations: Too long`
[root@k8s-170 manifests]# kubectl apply --server-side -f ./setup/
## 应用 当前目录下的所有配置清单
## 1、应用当前目录清单之前,需要将 kubeStateMetrics-deployment.yaml 和 prometheusAdapter-deployment.yaml 文件中的image改为能从hub.docker.com下载的,默认是使用google镜像,需要翻墙,注意保持版本一致即可。
## 2、grafana的时间默认为utc时间,比北京时间少8小时,可以使用 `sed -i 's/utc/utc+8/g' grafana-dashboardDefinitions.yaml` 和 `sed -i 's/UTC/UTC+8/g' grafana-dashboardDefinitions.yaml ` 将时间改为北京时间。
[root@k8s-170 manifests]# kubectl apply -f ./
等资源都启动完成后,并配置好DNS 解析,可以使用浏览器访问:
prometheus
altermanager
grafana
四、解决ControllerManager、Scheduler监控问题
默认安装后访问prometheus,会发现有以下有三个报警:
Watchdog、KubeControllerManagerDown、KubeSchedulerDown
Watchdog是一个正常的报警,这个告警的作用是:如果alermanger或者prometheus本身挂掉了就发不出告警了,因此一般会采用另一个监控来监控prometheus,或者自定义一个持续不断的告警通知,哪一天这个告警通知不发了,说明监控出现问题了。prometheus operator已经考虑了这一点,本身携带一个watchdog,作为对自身的监控。
如果需要关闭,删除或注释掉Watchdog部分
[root@k8s-170 manifests]# vim kubePrometheus-prometheusRule.yaml
- name: general.rules
rules:
- alert: TargetDown
annotations:
message: '{{ printf "%.4g" $value }}% of the {{ $labels.job }}/{{ $labels.service }} targets in {{ $labels.namespace }} namespace are down.'
expr: 100 * (count(up == 0) BY (job, namespace, service) / count(up) BY (job, namespace, service)) > 10
for: 10m
labels:
severity: warning
#######################注释掉以下部分 ########################
# - alert: Watchdog
# annotations:
# message: |
# This is an alert meant to ensure that the entire alerting pipeline is functional.
# This alert is always firing, therefore it should always be firing in Alertmanager
# and always fire against a receiver. There are integrations with various notification
# mechanisms that send a notification when this alert is not firing. For example the
# "DeadMansSnitch" integration in PagerDuty.
# expr: vector(1)
# labels:
# severity: none
#######重新应用配置,等待启动完成后,此报警会消除
[root@k8s-170 manifests]# apply -f kubePrometheus-prometheusRule.yaml
KubeControllerManagerDown、KubeSchedulerDown的解决
原因是因为在kubernetesControlPlane-serviceMonitorKubeControllerManager.yaml中有如下内容,但默认安装的集群并没有给系统kube-controller-manager组件创建service
selector:
matchLabels:
app.kubernetes.io/name: kube-controller-manager
修改kube-controller-manager的监听地址(所有controller-manager节点都修改,我这里是 192.168.0.170和192.168.0.171两个节点),改完配置会自动重启,不需要手动重启服务
[root@k8s-170 manifests]# vim /etc/kubernetes/manifests/kube-controller-manager.yaml
...
spec:
containers:
- command:
- kube-controller-manager
- --allocate-node-cidrs=true
- --authentication-kubeconfig=/etc/kubernetes/controller-manager.conf
- --authorization-kubeconfig=/etc/kubernetes/controller-manager.conf
- --bind-address=0.0.0.0 ##将此值改为0.0.0.0
[root@k8s-170 kube-prometheus]# netstat -lntup|grep kube-contro
tcp6 0 0 :::10257 :::* LISTEN 110416/kube-control
创建一个service
[root@k8s-170 kube-prometheus]# vim kubeControllerManagerServcie.yaml
apiVersion: v1
kind: Service
metadata:
name: kube-controller-manager
namespace: kube-system
labels:
# 必须和 kubernetesControlPlane-serviceMonitorKubeControllerManager.yaml 文件中的 selector.matchLabels 保持一致
app.kubernetes.io/name: kube-controller-manager
spec:
selector:
component: kube-controller-manager
ports:
- name: https-metrics
port: 10257
targetPort: 10257
protocol: TCP
## 应用配置,等待成功后, KubeControllerManagerDown警告消除。
[root@k8s-170 kube-prometheus]# kubectl apply -f kubeControllerManagerServcie.yaml
kube-scheduler同理,在kubernetesControlPlane-serviceMonitorKubeScheduler.yaml 中有如下内容,但默认安装的集群并没有给系统kube-controller-manager组件创建service。
spec:
## 其它配置...
selector:
matchLabels:
app.kubernetes.io/name: kube-scheduler
修改kube-scheduler的监听地址,(所有controller-scheduler节点都修改,我这里是 192.168.0.170和192.168.0.171两个节点),改完配置会自动重启,不需要手动重启服务
[root@k8s-170 manifests]# vim /etc/kubernetes/manifests/kube-scheduler.yaml
...
spec:
containers:
- command:
- kube-scheduler
- --authentication-kubeconfig=/etc/kubernetes/scheduler.conf
- --authorization-kubeconfig=/etc/kubernetes/scheduler.conf
- --bind-address=0.0.0.0 ##将此值改为0.0.0.0
- --kubeconfig=/etc/kubernetes/scheduler.conf
- --leader-elect=true
[root@k8s-170 kube-prometheus]# netstat -lntup|grep kube-sched
tcp6 0 0 :::10259 :::* LISTEN 183883/kube-schedul
创建一个service
[root@k8s-170 kube-prometheus]# vim kubeSchedulerService.yaml
apiVersion: v1
kind: Service
metadata:
name: kube-scheduler
namespace: kube-system
labels:
# 必须和 kubernetesControlPlane-serviceMonitorKubeScheduler.yaml 文件中的 selector.matchLabels 保持一致
app.kubernetes.io/name: kube-scheduler
spec:
selector:
component: kube-scheduler
ports:
- name: https-metrics
port: 10259
targetPort: 10259
protocol: TCP
## 应用配置,等待成功后, KubeSchedulerDown警告消除。
[root@k8s-170 kube-prometheus]# kubectl apply -f kubeSchedulerService.yaml
登陆grafana : 可以查看k8s容器中的监控的数据。
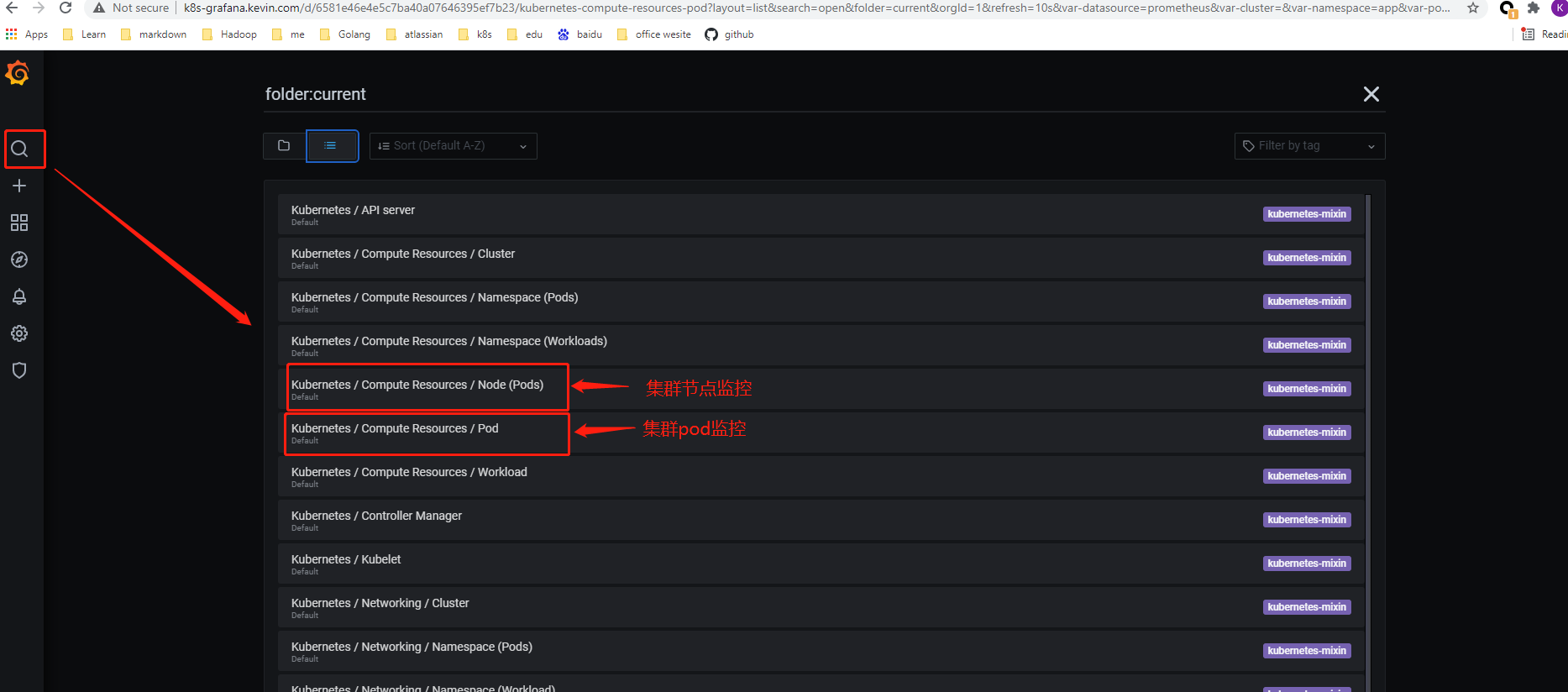
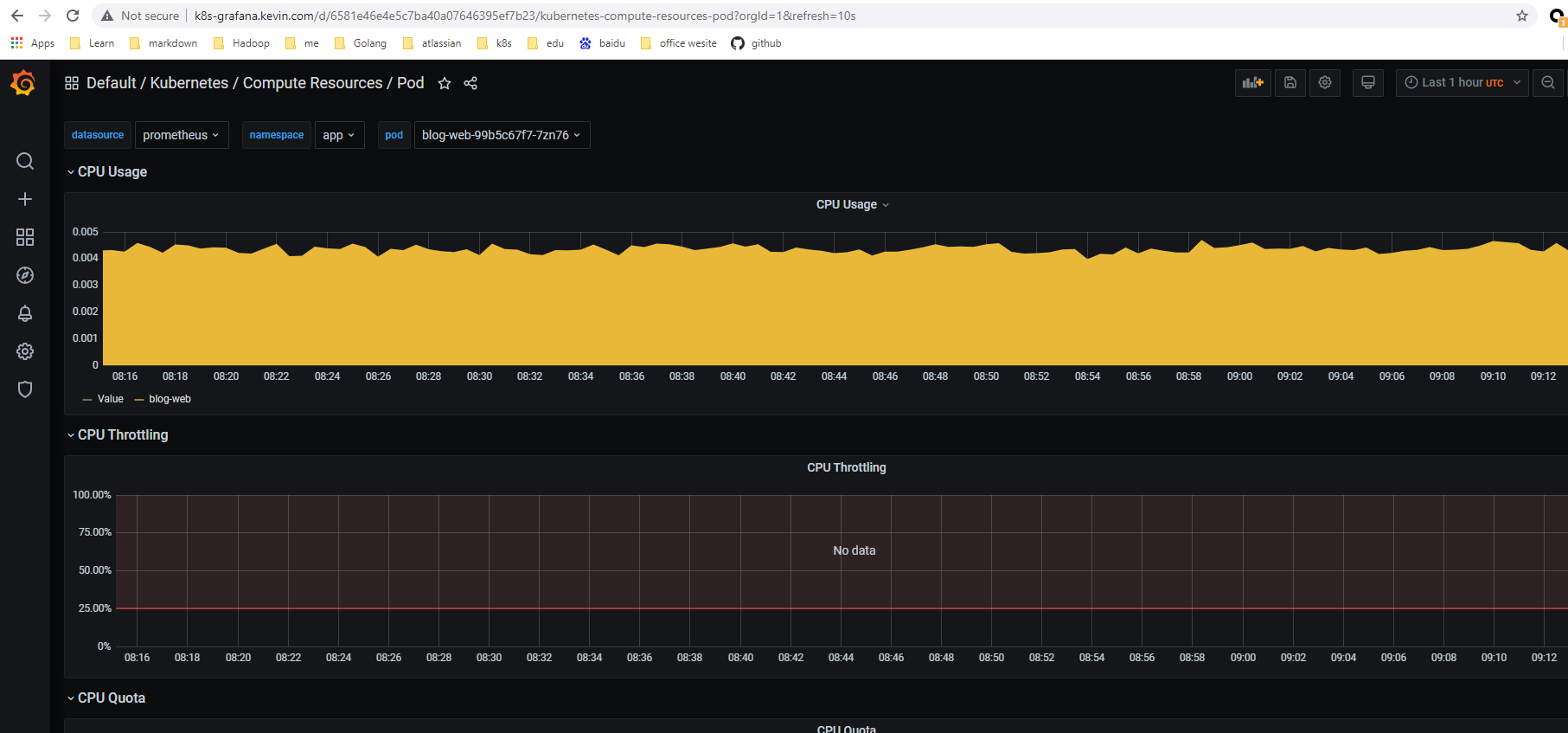
点击 Kubernetes / Compute Resources / Node (Pods) 查看pods监控信息如下图:
















 2827
2827











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











