






docusaurus简介
Docusaurus 是 Facebook 专门为开源项目开发者提供的一款易于维护的静态网站创建工具,使用 Markdown 即可更新网站。构建一个带有主页、文档、API、帮助以及博客页面的静态网站,只需5分钟。
同类竞品还有vuepress,docusaurus是基于react,而vuepress是基于vue的
特点
启动简单 :Docusaurus的构建可以在很短的时间内启动和运行。Docusaurus已经构建了处理网站的过程,开发人员只需专注于项目。
本地化: Docusaurus 通过CrowdIn 提供本地化支持。通过翻译文档增强国际社区的地位。
可自定义:Docusaurus 可自定义项目需要的关键页面,包括主页,文档部分,博客和其他页面
创建项目
npx create-docusaurus@latest linux-book classic
使用心得
1、自动生成侧边栏
category.json
{
"position": 2.5,
"label": "Tutorial",
"collapsible": true,
"collapsed": false,
"className": "red",
"link": {
"type": "generated-index",
"title": "Tutorial overview"
},
"customProps": {
"description": "This description can be used in the swizzled DocCard"
}
}
2、自定义theme中的组件样式 Swizzle
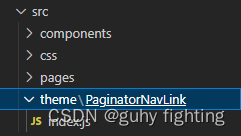
npm run swizzle @docusaurus/theme-classic PaginatorNavLink
运行以上命令会在src文件夹下生成theme文件夹














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









