







浅谈命令查询职责分离(CQRS)模式
在常用的三层架构中,通常都是通过数据访问层来修改或者查询数据,一般修改和查询使用的是相同的实体。在一些业务逻辑简单的系统中可能没有什么问题,但是随着系统逻辑变得复杂,用户增多,这种设计就会出现一些性能问题。虽然在DB上可以做一些读写分离的设计,但在业务上如果在读写方面混合在一起的话,仍然会出现一些问题。
本文介绍了命令查询职责分离模式(Command Query Responsibility Segregation,CQRS),该模式从业务上分离修改 (Command,增,删,改,会对系统状态进行修改)和查询(Query,查,不会对系统状态进行修改)的行为。从而使得逻辑更加清晰,便于对不同部分进行针对性的优化。文章首先简要介绍了传统的CRUD方式存在的问题,接着介绍了CQRS模式,最后以一个简单的在线日记系统演示了如何实现CQRS模式。要谈到读写操作,首先我们来看传统的CRUD的问题。
一 CRUD方式的问题
在以前的管理系统中,命令(Command,通常用来更新数据,操作DB)和查询(Query)通常使用的是在数据访问层中Repository中的实体对象(这些对象是对DB中表的映射),这些实体有可能是SQLServer中的一行数据或者多个表。
通常对DB执行的增,删,改,查(CRUD)都是针对的系统的实体对象。如通过数据访问层获取数据,然后通过数据传输对象DTO传给表现层。或者,用户需要更新数据,通过DTO对象将数据传给Model,然后通过数据访问层写回数据库,系统中的所有交互都是和数据查询和存储有关,可以认为是数据驱动(Data-Driven)的,如下图:
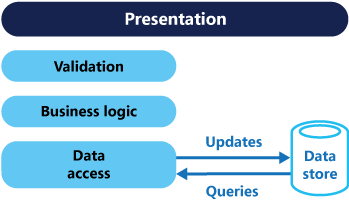
对于一些比较简单的系统,使用这种CRUD的设计方式能够满足要求。特别是通过一些代码生成工具及ORM等能够非常方便快速的实现功能。
但是传统的CRUD方法有一些问题:
- 使用同一个对象实体来进行数据库读写可能会太粗糙,大多数情况下,比如编辑的时候可能只需要更新个别字段,但是却需要将整个对象都穿进去,有些字段其实是不需要更新的。在查询的时候在表现层可能只需要个别字段,但是需要查询和返回整个实体对象。
- 使用同一实体对象对同一数据进行读写操作的时候,可能会遇到资源竞争的情况,经常要处理的锁的问题,在写入数据的时候,需要加锁。读取数据的时候需要判断是否允许脏读。这样使得系统的逻辑性和复杂性增加,并且会对系统吞吐量的增长会产生影响。
- 同步的,直接与数据库进行交互在大数据量同时访问的情况下可能会影响性能和响应性,并且可能会产生性能瓶颈。
- 由于同一实体对象都会在读写操作中用到,所以对于安全和权限的管理会变得比较复杂。
这里面很重要的一个问题是,系统中的读写频率比,是偏向读,还是偏向写,就如同一般的数据结构在查找和修改上时间复杂度不一样,在设计系统的结构时也需要考虑这样的问题。解决方法就是我们经常用到的对数据库进行读写分离。 让主数据库处理事务性的增,删,改操作(Insert,Update,Delete)操作,让从数据库处理查询操作(Select操作),数据库复制被用来将事务性操作导致的变更同步到集群中的从数据库。这只是从DB角度处理了读写分离,但是从业务或者系统上面读和写仍然是存放在一起的。他们都是用的同一个实体对象。
要从业务上将读和写分离,就是接下来要介绍的命令查询职责分离模式。
二 什么是CQRS
CQRS最早来自于Betrand Meyer(Eiffel语言之父,开-闭原则OCP提出者)在 Object-Oriented Software Construction 这本书中提到的一种 命令查询分离 (Command Query Separation,CQS) 的概念。其基本思想在于,任何一个对象的方法可以分为两大类:
- 命令(Command):不返回任何结果(void),但会改变对象的状态。
- 查询(Query):返回结果,但是不会改变对象的状态,对系统没有副作用。
根据CQS的思想,任何一个方法都可以拆分为命令和查询两部分,比如:
private int i = 0;
private int Increase(int value)
{
i += value;
return i;
}
这个方法,我们执行了一个命令即对变量i进行相加,同时又执行了一个Query,即查询返回了i的值,如果按照CQS的思想,该方法可以拆成Command和Query两个方法,如下:
private void IncreaseCommand(int value)
{
i += value;
}
private int QueryValue()
{
return i;
}
操作和查询分离使得我们能够更好的把握对象的细节,能够更好的理解哪些操作会改变系统的状态。当然CQS也有一些缺点,比如代码需要处理多线程的情况。
CQRS是对CQS模式的进一步改进成的一种简单模式。 它由Greg Young在CQRS, Task Based UIs, Event Sourcing agh! 这篇文章中提出。“CQRS只是简单的将之前只需要创建一个对象拆分成了两个对象,这种分离是基于方法是执行命令还是执行查询这一原则来定的(这个和CQS的定义一致)”。
CQRS使用分离的接口将数据查询操作(Queries)和数据修改操作(Commands)分离开来,这也意味着在查询和更新过程中使用的数据模型也是不一样的。这样读和写逻辑就隔离开来了。

使用CQRS分离了读写职责之后,可以对数据进行读写分离操作来改进性能,可扩展性和安全。如下图:
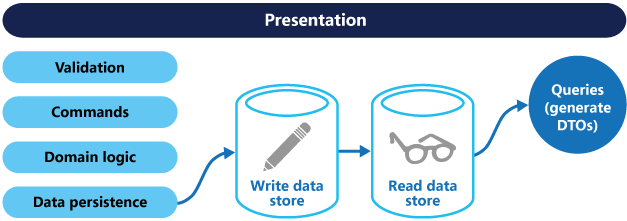
主数据库处理CUD,从库处理R,从库的的结构可以和主库的结构完全一样,也可以不一样,从库主要用来进行只读的查询操作。在数量上从库的个数也可以根据查询的规模进行扩展,在业务逻辑上,也可以根据专题从主库中划分出不同的从库。从库也可以实现成ReportingDatabase,根据查询的业务需求,从主库中抽取一些必要的数据生成一系列查询报表来存储。

使用ReportingDatabase的一些优点通常可以使得查询变得更加简单高效:
- ReportingDatabase的结构和数据表会针对常用的查询请求进行设计。
- ReportingDatabase数据库通常会去正规化,存储一些冗余而减少必要的Join等联合查询操作,使得查询简化和高效,一些在主数据库中用不到的数据信息,在ReportingDatabase可以不用存储。
- 可以对ReportingDatabase重构优化,而不用去改变操作数据库。
- 对ReportingDatabase数据库的查询不会给操作数据库带来任何压力。
- 可以针对不同的查询请求建立不同的ReportingDatabase库。
当然这也有一些缺点,比如从库数据的更新。如果使用SQLServer,本身也提供了一些如故障转移和复制机制来方便部署。
三 什么时候可以考虑CQRS
CQRS模式有一些优点:
- 分工明确,可以负责不同的部分
- 将业务上的命令和查询的职责分离能够提高系统的性能、可扩展性和安全性。并且在系统的演化中能够保持高度的灵活性,能够防止出现CRUD模式中,对查询或者修改中的某一方进行改动,导致另一方出现问题的情况。
- 逻辑清晰,能够看到系统中的那些行为或者操作导致了系统的状态变化。
- 可以从数据驱动(Data-Driven) 转到任务驱动(Task-Driven)以及事件驱动(Event-Driven).
在下场景中,可以考虑使用CQRS模式:
- 当在业务逻辑层有很多操作需要相同的实体或者对象进行操作的时候。CQRS使得我们可以对读和写定义不同的实体和方法,从而可以减少或者避免对某一方面的更改造成冲突
- 对于一些基于任务的用户交互系统,通常这类系统会引导用户通过一系列复杂的步骤和操作,通常会需要一些复杂的领域模型,并且整个团队已经熟悉领域驱动设计技术。写模型有很多和业务逻辑相关的命令操作的堆,输入验证,业务逻辑验证来保证数据的一致性。读模型没有业务逻辑以及验证堆,仅仅是返回DTO对象为视图模型提供数据。读模型最终和写模型相一致。
- 适用于一些需要对查询性能和写入性能分开进行优化的系统,尤其是读/写比非常高的系统,横向扩展是必须的。比如,在很多系统中读操作的请求时远大于写操作。为适应这种场景,可以考虑将写模型抽离出来单独扩展,而将写模型运行在一个或者少数几个实例上。少量的写模型实例能够减少合并冲突发生的情况
- 适用于一些团队中,一些有经验的开发者可以关注复杂的领域模型,这些用到写操作,而另一些经验较少的开发者可以关注用户界面上的读模型。
- 对于系统在将来会随着时间不段演化,有可能会包含不同版本的模型,或者业务规则经常变化的系统
- 需要和其他系统整合,特别是需要和事件溯源Event Sourcing进行整合的系统,这样子系统的临时异常不会影响整个系统的其他部分。
但是在以下场景中,可能不适宜使用CQRS:
- 领域模型或者业务逻辑比较简单,这种情况下使用CQRS会把系统搞复杂。
- 对于简单的,CRUD模式的用户界面以及与之相关的数据访问操作已经足够的话,没必要使用CQRS,这些都是一个简单的对数据进行增删改查。
- 不适合在整个系统中到处使用该模式。在整个数据管理场景中的特定模块中CQRS可能比较有用。但是在有些地方使用CQRS会增加系统不必要的复杂性。















 1422
1422

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









