






malloc是个库函数,用来申请内存使用。函数原型void *malloc(size_t size)。
这个函数在不同的c库有不同的实现方式,大致的实现过程相同,先尝试从c库中
申请一段线性空间,当空间不足时会通过系统调用在内核申请一段线性空间。
当进程需要访问这段地址时,linux通过缺页中断进入内核处理,
再分配具体物理地址。
malloc申请物理内存都是通过kernel的brk或者mmap系统调用。
mmap跟brk地址增长如图:
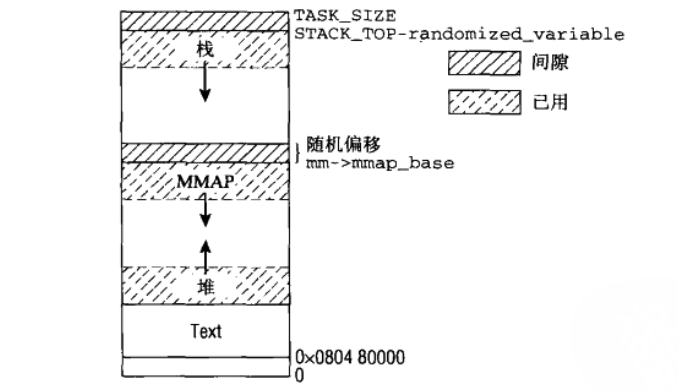
这个函数在不同的c库有不同的实现方式,大致的实现过程相同,先尝试从c库中
申请一段线性空间,当空间不足时会通过系统调用在内核申请一段线性空间。
当进程需要访问这段地址时,linux通过缺页中断进入内核处理,
再分配具体物理地址。
malloc申请物理内存都是通过kernel的brk或者mmap系统调用。
接下来就重点分析brk系统调用实现。
/*
参数brk用来指定当前进程heap段新的结束地址
这个系统调用用来申请一段线性地址空间
*/
SYSCALL_DEFINE1(brk, unsigned long, brk)
{
unsigned long rlim, retval;
unsigned long newbrk, oldbrk;
struct mm_struct *mm = current->mm;
unsigned long min_brk;
bool populate;
//获取内存管理区锁
down_write(&mm->mmap_sem);
#ifdef CONFIG_COMPAT_BRK
/*
* CONFIG_COMPAT_BRK can still be overridden by setting
* randomize_va_space to 2, which will still cause mm->start_brk
* to be arbitrarily shifted
*/
/*
一般用户进程地址空间划分,堆在数据段的上方,如果开始brk random属性,最小堆地址就没办法通过数据段直接获取。
*/
if (current->brk_randomized)
min_brk = mm->start_brk;
else
min_brk = mm->end_data;
#else
min_brk = mm->start_brk;
#endif
if (brk < min_brk)
goto out;
/*
* Check against rlimit here. If this check is done later after the test
* of oldbrk with newbrk then it can escape the test and let the data
* segment grow beyond its set limit the in case where the limit is
* not page aligned -Ram Gupta
*/
rlim = rlimit(RLIMIT_DATA);
if (rlim < RLIM_INFINITY && (brk - mm->start_brk) +
(mm->end_data - mm->start_data) > rlim)
goto out;
//brk按page size对齐
newbrk = PAGE_ALIGN(brk);
oldbrk = PAGE_ALIGN(mm->brk);//进程堆的结束地址
if (oldbrk == newbrk)
goto set_brk;
/* Always allow shrinking brk. */
//缩小mm 堆空间,malloc不会走到这里,跳过
if (brk <= mm->brk) {
if (!do_munmap(mm, newbrk, oldbrk-newbrk))
goto set_brk;
goto out;
}
/* Check against existing mmap mappings. */
//检查进程现有的vma区是否跟欲申请的地址范围有重叠,有的话不能继续本次的申请
if (find_vma_intersection(mm, oldbrk, newbrk+PAGE_SIZE))
goto out;
/* Ok, looks good - let it rip. */
if (do_brk(oldbrk, newbrk-oldbrk) != oldbrk)
goto out;
set_brk:
mm->brk = brk;
populate = newbrk > oldbrk && (mm->def_flags & VM_LOCKED) != 0;
up_write(&mm->mmap_sem);
if (populate)
mm_populate(oldbrk, newbrk - oldbrk);
return brk;
out:
retval = mm->brk;
up_write(&mm->mmap_sem);
return retval;
}
进程地址空间划分:

/* Look up the first VMA which intersects the interval start_addr..end_addr-1,
NULL if none. Assume start_addr < end_addr. */
//查找vma,vma的范围跟start_addr--end_addr有交集
static inline struct vm_area_struct * find_vma_intersection(struct mm_struct * mm, unsigned long start_addr, unsigned long end_addr)
{
struct vm_area_struct * vma = find_vma(mm,start_addr);
if (vma && end_addr <= vma->vm_start)
vma = NULL;
return vma;
}/* Look up the first VMA which satisfies addr < vm_end, NULL if none. */
/*现有vma是否跟要申请的地址空间有交叉或者说新的地址是否在已有的vma范围内
*/
struct vm_area_struct *find_vma(struct mm_struct *mm, unsigned long addr)
{
struct vm_area_struct *vma = NULL;
/* Check the cache first. *///根据程序访问局部性原理
/* (Cache hit rate is typically around 35%.) */
vma = ACCESS_ONCE(mm->mmap_cache);
//cache没有命中的话,就要从mm的vma组成的红黑树中查找
if (!(vma && vma->vm_end > addr && vma->vm_start <= addr)) {
struct rb_node *rb_node;
rb_node = mm->mm_rb.rb_node;//scan rb tree
vma = NULL;
while (rb_node) {
struct vm_area_struct *vma_tmp;
vma_tmp = rb_entry(rb_node,
struct vm_area_struct, vm_rb);
if (vma_tmp->vm_end > addr) {
vma = vma_tmp;
if (vma_tmp->vm_start <= addr)
break;
rb_node = rb_node->rb_left;
} else
rb_node = rb_node->rb_right;
}
if (vma)
mm->mmap_cache = vma;
}
return vma;
}接下来到了主体函数:
/*
* this is really a simplified "do_mmap". it only handles
* anonymous maps. eventually we may be able to do some
* brk-specific accounting here.
*/
static unsigned long do_brk(unsigned long addr, unsigned long len)
{
struct mm_struct * mm = current->mm;
struct vm_area_struct * vma, * prev;
unsigned long flags;
struct rb_node ** rb_link, * rb_parent;
pgoff_t pgoff = addr >> PAGE_SHIFT;
int error;
len = PAGE_ALIGN(len);
if (!len)
return addr;
flags = VM_DATA_DEFAULT_FLAGS | VM_ACCOUNT | mm->def_flags;
//是否有未被映射的vma可用
error = get_unmapped_area(NULL, addr, len, 0, MAP_FIXED);
if (error & ~PAGE_MASK)
return error;
/*
* mlock MCL_FUTURE?
*/
if (mm->def_flags & VM_LOCKED) {
unsigned long locked, lock_limit;
locked = len >> PAGE_SHIFT;
locked += mm->locked_vm;
lock_limit = rlimit(RLIMIT_MEMLOCK);
lock_limit >>= PAGE_SHIFT;
if (locked > lock_limit && !capable(CAP_IPC_LOCK))
return -EAGAIN;
}
/*
* mm->mmap_sem is required to protect against another thread
* changing the mappings in case we sleep.
*/
verify_mm_writelocked(mm);
/*
* Clear old maps. this also does some error checking for us
*/
munmap_back:
//查找最靠近申请区的vma
if (find_vma_links(mm, addr, addr + len, &prev, &rb_link, &rb_parent)) {
if (do_munmap(mm, addr, len))
return -ENOMEM;
goto munmap_back;
}
/* Check against address space limits *after* clearing old maps... */
if (!may_expand_vm(mm, len >> PAGE_SHIFT))
return -ENOMEM;
if (mm->map_count > sysctl_max_map_count)
return -ENOMEM;
if (security_vm_enough_memory_mm(mm, len >> PAGE_SHIFT))
return -ENOMEM;
/* Can we just expand an old private anonymous mapping? */
//上面查找到的vma能否跟欲申请的vma合并
vma = vma_merge(mm, prev, addr, addr + len, flags,
NULL, NULL, pgoff, NULL, NULL);
if (vma)
goto out;
/*
* create a vma struct for an anonymous mapping
*/
vma = kmem_cache_zalloc(vm_area_cachep, GFP_KERNEL);
if (!vma) {
vm_unacct_memory(len >> PAGE_SHIFT);
return -ENOMEM;
}
//不能合并vma的话,就新申请一个vma,然后插入mm红黑树中
INIT_LIST_HEAD(&vma->anon_vma_chain);
vma->vm_mm = mm;
vma->vm_start = addr;
vma->vm_end = addr + len;
vma->vm_pgoff = pgoff;
vma->vm_flags = flags;
vma->vm_page_prot = vm_get_page_prot(flags);
vma_link(mm, vma, prev, rb_link, rb_parent);
out:
perf_event_mmap(vma);
//total_vm 是虚拟地址page数
mm->total_vm += len >> PAGE_SHIFT;
if (flags & VM_LOCKED)
mm->locked_vm += (len >> PAGE_SHIFT);
return addr;
}//进程获取一块新的未映射的vma区
unsigned long
get_unmapped_area(struct file *file, unsigned long addr, unsigned long len,
unsigned long pgoff, unsigned long flags)
{
unsigned long (*get_area)(struct file *, unsigned long,
unsigned long, unsigned long, unsigned long);
unsigned long error = arch_mmap_check(addr, len, flags);
if (error)
return error;
/* Careful about overflows.. */
//确保vma在用户空间范围内
if (len > TASK_SIZE)//check if go ahead user space,vma should be user space
return -ENOMEM;
//get_area用于获取vma的操作
get_area = current->mm->get_unmapped_area;
//判断是否要用文件内存映射
if (file && file->f_op && file->f_op->get_unmapped_area)
get_area = file->f_op->get_unmapped_area;
addr = get_area(file, addr, len, pgoff, flags);
if (IS_ERR_VALUE(addr))
return addr;
if (addr > TASK_SIZE - len)
return -ENOMEM;
if (addr & ~PAGE_MASK)
return -EINVAL;
addr = arch_rebalance_pgtables(addr, len);
error = security_mmap_addr(addr);
return error ? error : addr;
}mmap跟brk地址增长如图:
//brk调用中get_area指向arch_get_unmapped_area:
//参照上图,brk系统调用地址从低到高地址扩展
unsigned long
arch_get_unmapped_area(struct file *filp, unsigned long addr,
unsigned long len, unsigned long pgoff, unsigned long flags)
{
struct mm_struct *mm = current->mm;
struct vm_area_struct *vma;
struct vm_unmapped_area_info info;
if (len > TASK_SIZE - mmap_min_addr)
return -ENOMEM;
if (flags & MAP_FIXED)
return addr;
//如果addr不为0,addr为指定的优先使用地址,检查下addr是否跟其他vma交叉
if (addr) {
addr = PAGE_ALIGN(addr);
vma = find_vma(mm, addr);
if (TASK_SIZE - len >= addr && addr >= mmap_min_addr &&
(!vma || addr + len <= vma->vm_start))//vma为空,或者vma起始地址最靠近要申请的空间范围,addr可用,直接返回addr
return addr;
}
//上层传下来的addr不可用时,只能由os内部分配一个vma
info.flags = 0;
info.length = len;
info.low_limit = TASK_UNMAPPED_BASE;
info.high_limit = TASK_SIZE;
info.align_mask = 0;
return vm_unmapped_area(&info);
}/*
1. 从vma红黑树的根开始遍历
2. 若当前结点有左子树则遍历其左子树,否则指向其右孩子。
3. 当某结点rb_subtree_gap可能是最后一个满足分配请求的空隙时,遍历结束。
4. 检测这个结点,判断这个结点与其前驱结点之间的空隙是否满足分配请求。满足则跳出循环。
5. 不满足分配请求时,指向其右孩子,判断其右孩子的rb_subtree_gap是否满足当前请求。
6. 满足则返回到2。不满足,回退其父结点,返回到4
*/
unsigned long unmapped_area(struct vm_unmapped_area_info *info)
{
/*
* We implement the search by looking for an rbtree node that
* immediately follows a suitable gap. That is,
* - gap_start = vma->vm_prev->vm_end <= info->high_limit - length;
* - gap_end = vma->vm_start >= info->low_limit + length;
* - gap_end - gap_start >= length
*/
struct mm_struct *mm = current->mm;
struct vm_area_struct *vma;
unsigned long length, low_limit, high_limit, gap_start, gap_end;
//high_limit 跟low_limit是堆可用的地址空间
/* Adjust search length to account for worst case alignment overhead */
length = info->length + info->align_mask;
if (length < info->length)
return -ENOMEM;
/* Adjust search limits by the desired length */
if (info->high_limit < length)
return -ENOMEM;
high_limit = info->high_limit - length;
if (info->low_limit > high_limit)
return -ENOMEM;
low_limit = info->low_limit + length;
/* Check if rbtree root looks promising */
if (RB_EMPTY_ROOT(&mm->mm_rb))
goto check_highest;
//rb tree root node
vma = rb_entry(mm->mm_rb.rb_node, struct vm_area_struct, vm_rb);
//rb_subtree_gap是当前结点与其前驱结点之间空隙 和 当前结点其左右子树中的结点间的最大空隙的最大值
//不同的vma之间是存在地址空隙,也就是说不同的vma并不能组成连续的线性空间
if (vma->rb_subtree_gap < length)
goto check_highest;
while (true) {
/* Visit left subtree if it looks promising */
//从左子树上一直查找,直到gap不满足
gap_end = vma->vm_start;
if (gap_end >= low_limit && vma->vm_rb.rb_left) {
struct vm_area_struct *left =
rb_entry(vma->vm_rb.rb_left,
struct vm_area_struct, vm_rb);
if (left->rb_subtree_gap >= length) {
vma = left;
continue;
}
}
//gap不满足条件后,检查上个满足条件的vma的gap值,
//满足下面条件就跳转到found
gap_start = vma->vm_prev ? vma->vm_prev->vm_end : 0;
check_current:
/* Check if current node has a suitable gap */
if (gap_start > high_limit)
return -ENOMEM;
if (gap_end >= low_limit && gap_end - gap_start >= length)
goto found;
/* Visit right subtree if it looks promising */
//左子树不满足条件的话,就从最后一次满足条件的右子树开始查找
if (vma->vm_rb.rb_right) {
struct vm_area_struct *right =
rb_entry(vma->vm_rb.rb_right,
struct vm_area_struct, vm_rb);
if (right->rb_subtree_gap >= length) {
vma = right;
continue;
}
}
/* Go back up the rbtree to find next candidate node */
//往上回退查找符合条件的节点
while (true) {
struct rb_node *prev = &vma->vm_rb;
if (!rb_parent(prev))
goto check_highest;
vma = rb_entry(rb_parent(prev),
struct vm_area_struct, vm_rb);
// 当前结点的前驱只可能是其左孩子,因为rb_subtree_gap是当前结点与其前驱的空隙
if (prev == vma->vm_rb.rb_left) {
gap_start = vma->vm_prev->vm_end;
gap_end = vma->vm_start;
goto check_current;
}
}
}
check_highest:
/* Check highest gap, which does not precede any rbtree node */
gap_start = mm->highest_vm_end;
gap_end = ULONG_MAX; /* Only for VM_BUG_ON below */
if (gap_start > high_limit)
return -ENOMEM;
found:
/* We found a suitable gap. Clip it with the original low_limit. */
if (gap_start < info->low_limit)
gap_start = info->low_limit;
/* Adjust gap address to the desired alignment */
gap_start += (info->align_offset - gap_start) & info->align_mask;
VM_BUG_ON(gap_start + info->length > info->high_limit);
VM_BUG_ON(gap_start + info->length > gap_end);
return gap_start;
}//找到addr在rb tree的可插入点
static int find_vma_links(struct mm_struct *mm, unsigned long addr,
unsigned long end, struct vm_area_struct **pprev,
struct rb_node ***rb_link, struct rb_node **rb_parent)
{
struct rb_node **__rb_link, *__rb_parent, *rb_prev;
__rb_link = &mm->mm_rb.rb_node;
rb_prev = __rb_parent = NULL;
while (*__rb_link) {
struct vm_area_struct *vma_tmp;
__rb_parent = *__rb_link;
vma_tmp = rb_entry(__rb_parent, struct vm_area_struct, vm_rb);
if (vma_tmp->vm_end > addr) {
/* Fail if an existing vma overlaps the area */
if (vma_tmp->vm_start < end)
return -ENOMEM;
__rb_link = &__rb_parent->rb_left;
} else {
rb_prev = __rb_parent;
__rb_link = &__rb_parent->rb_right;
}
}
*pprev = NULL;
if (rb_prev)
*pprev = rb_entry(rb_prev, struct vm_area_struct, vm_rb);
*rb_link = __rb_link;
*rb_parent = __rb_parent;
return 0;
}














 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









