







本文涉及的源码可从知识图谱推理该文章下方附件获取
概述
本研究深入探讨了基于图神经网络(GNN)的知识图谱推理,特别聚焦于传播路径的优化与应用。在智能问答、推荐系统等前沿应用中,知识图谱推理发挥着不可或缺的作用。然而,传统GNN方法在处理大规模知识图谱时,往往面临效率和准确度的双重挑战。为了克服这些局限,本研究提出了一种创新的自适应传播策略AdaProp,并通过与经典的Red-GNN方法进行对比实验,验证了其优越性。
论文名称:AdaProp: Learning Adaptive Propagation for Graph Neural Network based Knowledge Graph Reasoning
作者:Yongqi Zhang, Zhanke Zhou, Quanming Yao, Xiaowen Chu, and Bo Han
出处:Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD '23), August 6–10, 2023, Long Beach, CA, USA
在本论文的基础上添加tensorboard可视化结果
原代码链:https://github.com/LARS-research/AdaProp
方法介绍
通过有效的采样技术来动态调整传播路径,既考虑到查询实体和查询关系的依赖性,又避免在传播过程中涉及过多无关实体,从而提高推理效率并减少计算成本。这将涉及到开发新的采样策略,以确保在扩展传播路径时能够保持对目标答案实体的精确预测。为此,提出了一种名为AdaProp的基于GNN的方法,该算法可以根据给定的查询动态调整传播路径。
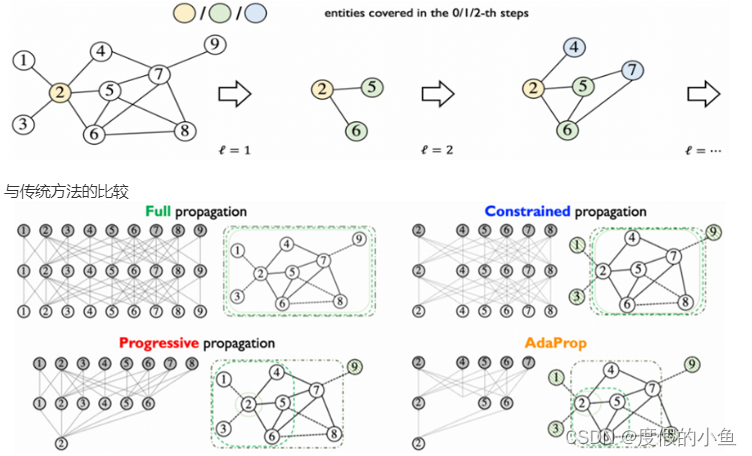
在知识图谱推理领域,传统的方法如全传播、渐进式传播和受限传播都各自有优势和局限。提出的AdaProp方法在效率和性能上对这些传统方法进行了显著的优化。
核心逻辑
实验条件
使用Python环境和PyTorch框架,在单个NVIDIA RTX 3070 GPU上进行,该GPU具有8GB的内存。实验的主要目的是验证AdaProp算法在传导(transductive)和归纳(inductive)设置下的有效性,并分析其各个组成部分在模型性能中的作用。
数据集
family数据集,存放在./transductive/data文件夹下
实验步骤
step1:安装环境依赖
torch == 1.12.1
torch_scatter == 2.0.9
numpy == 1.21.6
scipy == 1.10.1
step2:进入项目目录,进行训练

step3:输入tensorboard指令,可视化结果
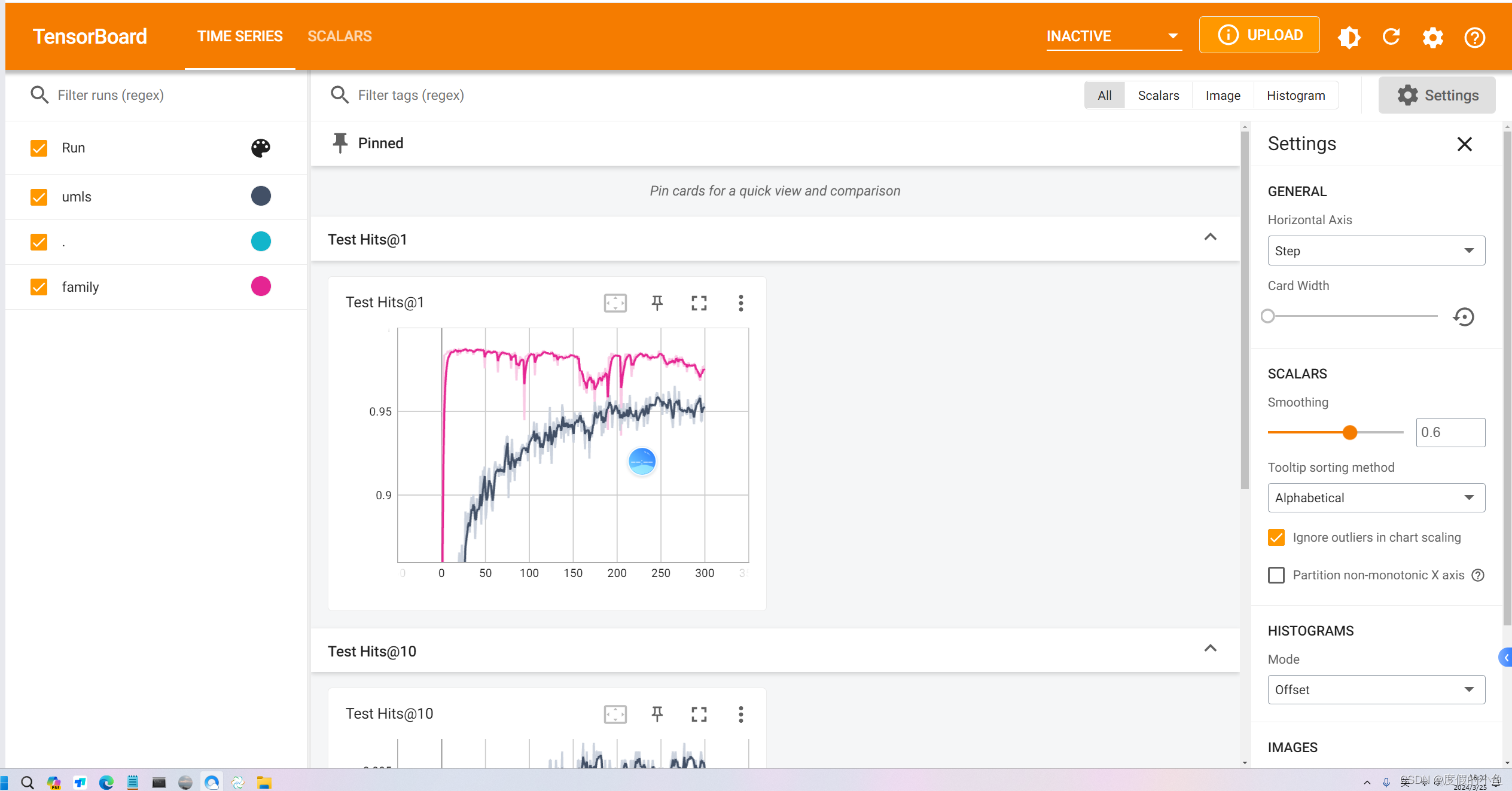
实验结果

核心代码
# start
check all output paths
checkPath('./results/')
checkPath(f'./results/{dataset}/')
checkPath(f'{loader.task_dir}/saveModel/')
model = BaseModel(opts, loader)
opts.perf_file = f'results/{dataset}/{model.modelName}_perf.txt'
print(f'==> perf_file: {opts.perf_file}')
config_str = '%.4f, %.4f, %.6f, %d, %d, %d, %d, %.4f,%s\n' % (
opts.lr, opts.decay_rate, opts.lamb, opts.hidden_dim, opts.attn_dim, opts.n_layer, opts.n_batch, opts.dropout,
opts.act)
print(config_str)
with open(opts.perf_file, 'a+') as f:
f.write(config_str)
if args.weight != None:
model.loadModel(args.weight)
model._update()
model.model.updateTopkNums(opts.n_node_topk)
if opts.train:
writer = SummaryWriter(log_dir=f'./tensorboard_logs/{dataset}')
# training mode
best_v_mrr = 0
for epoch in range(opts.epoch):
epoch_loss = model.train_batch()
if epoch_loss is not None:
writer.add_scalar('Training Loss', epoch_loss, epoch)
else:
print("Warning: Skipping logging of Training Loss due to NoneType.")
model.train_batch()
# eval on val/test set
if (epoch + 1) % args.eval_interval == 0:
result_dict, out_str = model.evaluate(eval_val=True, eval_test=True)
v_mrr, t_mrr = result_dict['v_mrr'], result_dict['t_mrr']
writer.add_scalar('Validation MRR', result_dict['v_mrr'], epoch)
writer.add_scalar('Validation Hits@1', result_dict['v_h1'], epoch)
writer.add_scalar('Validation Hits@10', result_dict['v_h10'], epoch)
writer.add_scalar('Test MRR', result_dict['t_mrr'], epoch)
writer.add_scalar('Test Hits@1', result_dict['t_h1'], epoch)
writer.add_scalar('Test Hits@10', result_dict['t_h10'], epoch)
print(out_str)
with open(opts.perf_file, 'a+') as f:
f.write(out_str)
if v_mrr > best_v_mrr:
best_v_mrr = v_mrr
best_str = out_str
print(str(epoch) + '\t' + best_str)
BestMetricStr = f'ValMRR_{str(v_mrr)[:5]}_TestMRR_{str(t_mrr)[:5]}'
model.saveModelToFiles(BestMetricStr, deleteLastFile=False)
# show the final result
print(best_str)
writer.close()
model.writer.close()
小结
AdaProp的成功并非偶然。其自适应传播策略使得模型能够根据不同的情况调整信息传播策略,从而更加精确地捕获节点之间的关系。这种灵活性是传统GNN所缺乏的,也是AdaProp能够在多个数据集上取得显著提升的关键原因。此外,AdaProp的引入也为知识图谱推理领域带来了新的研究方向和思路,为未来的研究提供了有益的参考。
本研究通过提出AdaProp自适应传播策略,并在多个数据集上进行实验验证,充分证明了其在知识图谱推理中的优越性。AdaProp不仅提高了推理的准确性和效率,还为该领域的未来发展提供了新的方向。未来,我们将继续探索AdaProp的潜力,优化其算法结构,以期在更多领域取得更加卓越的表现。同时,我们也期待更多的研究者能够关注这一领域,共同推动知识图谱推理技术的发展。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











