






一、用户画像—计算用户偏好标签
下面介绍如何计算用户的偏好标签。
在上一篇写用户画像的文章 “用户画像—打用户行为标签”中,主要讲了如何对用户的每一次操作行为、业务行为进行记录打上相应的标签。在这篇博客中,主要讲如何对这些明细标签进行计算以及偏好的产品、内容的类目。
关于用户标签权重的计算,在这篇文章里面讲过了:
这里再详细介绍一下:
用户标签权重 = 行为类型权重 × 时间衰减 × 用户行为次数 × TF-IDF计算标签权重
公式中各参数的释义如下:
-
行为类型权重:用户浏览、搜索、收藏、下单、购买等不同行为对用户而言有着不同的重要性,一般而言操作复杂度越高的行为权重越大。该权重值一般由运营人员或数据分析人员主观给出;
-
时间衰减:用户某些行为受时间影响不断减弱,行为时间距现在越远,该行为对用户当前来说的意义越小;
-
行为次数:用户标签权重按天统计,用户某天与该标签产生的行为次数越多,该标签对用户的影响越大;
-
TF-IDF计算标签权重:每个标签的对用户的重要性及该标签在全体标签中重要性的乘积得出每个标签的客观权重值;
为计算用户偏好标签,需要在用户行为标签的基础上计算用户行为标签对应的权重值,而后对同类标签做权重汇总,算出用户偏好的标签。关于用户行为标签如何打,在这篇博客里面有介绍过了
下面介绍如何在用户行为标签表的基础上加工用户偏好标签:
1、用户标签权重表结构设计
 字段定义:
字段定义:
-
用户id(user_id):用户唯一id;
-
标签id(tag_id):图书id;
-
标签名称(tag_name):图书名称;
-
用户行为次数(cnt):用户当日产生该标签的次数,如用户当日浏览一本图书4次,则记录4;
-
行为日期(date_id):产生该条标签对应日期;
-
标签类型(tag_type_id):在本案例中通过与图书类型表相关联,取出每本图书对应的类型,如《钢铁是怎么炼成的》对应“名著”;
-
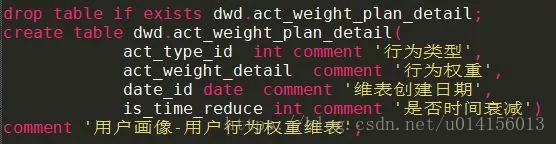
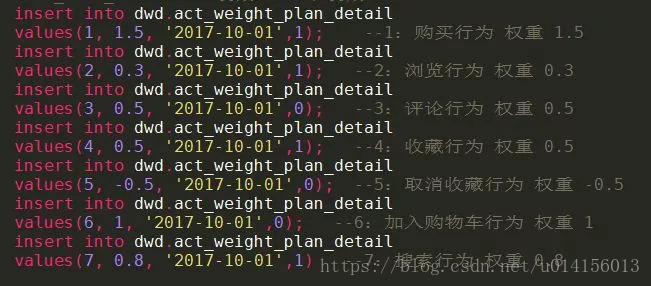
用户行为类型(act_type_id):即用户的购买、浏览、评论等操作行为,在本例中通过预设数值1~7来定义用户对应的行为类型。1:购买行为,2:浏览行为,3:评论行为,4:收藏行为,5:取消收藏行为,6:加入购物车行为,7:搜索行为;
2、在用户行为标签基础上加工权重表
加工标签权重表时,需要根据用户不同行为对应的权重建立一个权重维表:
向维表中插入数据:
3、对每个用户偏好的每个标签加总求权重值,对权重值做倒排序,取top N
二、用户画像—数据指标与表结构设计
本段文章介绍一下画像中需要开发的数据指标与开发过程中表结构的设计。
首先介绍画像开发的数据指标,画像开发过程中通用类的指标体系包括用户属性类、用户行为标签类、用户活跃时间段类、用户消费能力类、用户偏好类等
数据指标体系
用户属性指标
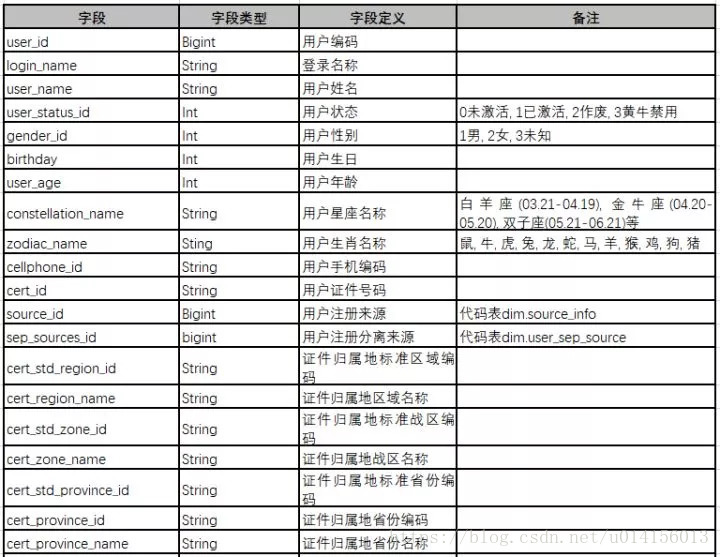
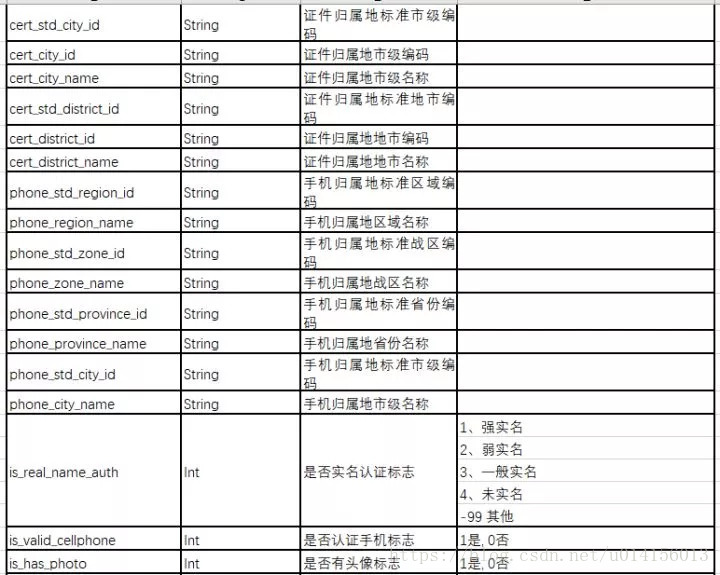
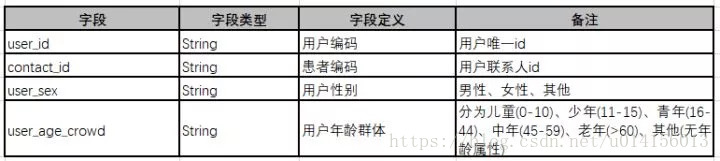
用户属性指标根据业务数据来源,尽可能全面地描述用户基础属性,这些基础属性值是短期内不会有改变的。如年龄、性别、手机号归属地、身份证归属地等
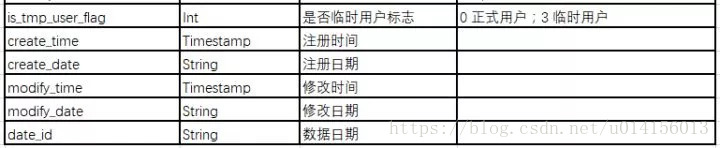
用户登录活跃指标
看用户近期登录时间段、登录时长、登录频次、常登陆地等指标
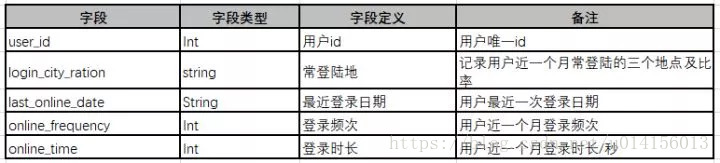
用户消费能力指标
看用户的消费金额、消费频次、最近消费时间。进一步结合用户登录活跃情况,可以对用户做RFM分层。
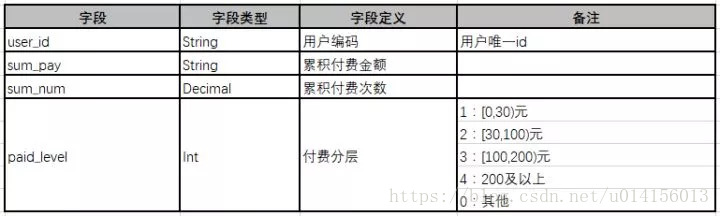
用户流失层级
根据用户的活跃度及消费情况,判断用户的流失意向。可及时对有流失趋向的用户做营销召回
用户年龄段划分
在做营销活动或站内推送时,可对不同年龄段做针对性运营
用户行为标签
记录用户在平台上每一次操作行为,及该次行为所带来的标签。后续可根据用户的行为标签计算用户的偏好标签,做推荐和营销等活动

表结构设计
对于画像数据的存储,除了用户属性这种基本上短期不会有变化的数据,其他相关数据的更新频率一般都比较高,为周更新或日更新
画像数据更新较为频繁,通常使用分区来将数据从物理上转移到离用户最近的地方。
一般对日期字段进行分区,当然事实上分区是为了优化查询性能,否则使用数据的用户也不需要关注这些字段是否分区。
例如说创建一个用户行为标签表:
CREATE TABLE userprofile( user_id string, tag_id string, tag_name string, cnt string, act_type_id string, tag_type_id string ) PARTITION BY (date_id string);
分区表改变了Hive对数据的存储方式,如果没做分区,创建的这个表目录为:
hdfs://master_server/user/hive/warehouse/userprofile
创建日期分区后,Hive可以更好地反映分区结构子目录:
hdfs://master_server/user/hive/warehouse/userprofile/date_id='2018-05-01'
在userprofile表下面,每个日期分区的数据可以存储截止到当日的全量历史数据,方便使用者查找。

















 1558
1558

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









