









来自:
[1]此说明书由华南师范大学外文学院2007研究生张杏娟编写,导师何安平订正和补充。
其中限定范围的检索方法由香港城市大学D.Lee博士提供,仅此致谢。
AntConc3.2.0的使用说明[1]
- 提取语境共现
1.1设置检索项
(1)单项检索
- 点击file下拉菜单中的“open files”,选择要打开的语料(如果想打开整个文件夹,可以选择open directory);
- 在“Search Term”一栏键入要检索的词项,如go;
- 在“Search Window Size” 一栏设置每一共现行出现的词数;
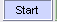
- 点击
 ,开始检索。
,开始检索。
检索结果如图1.1所示:
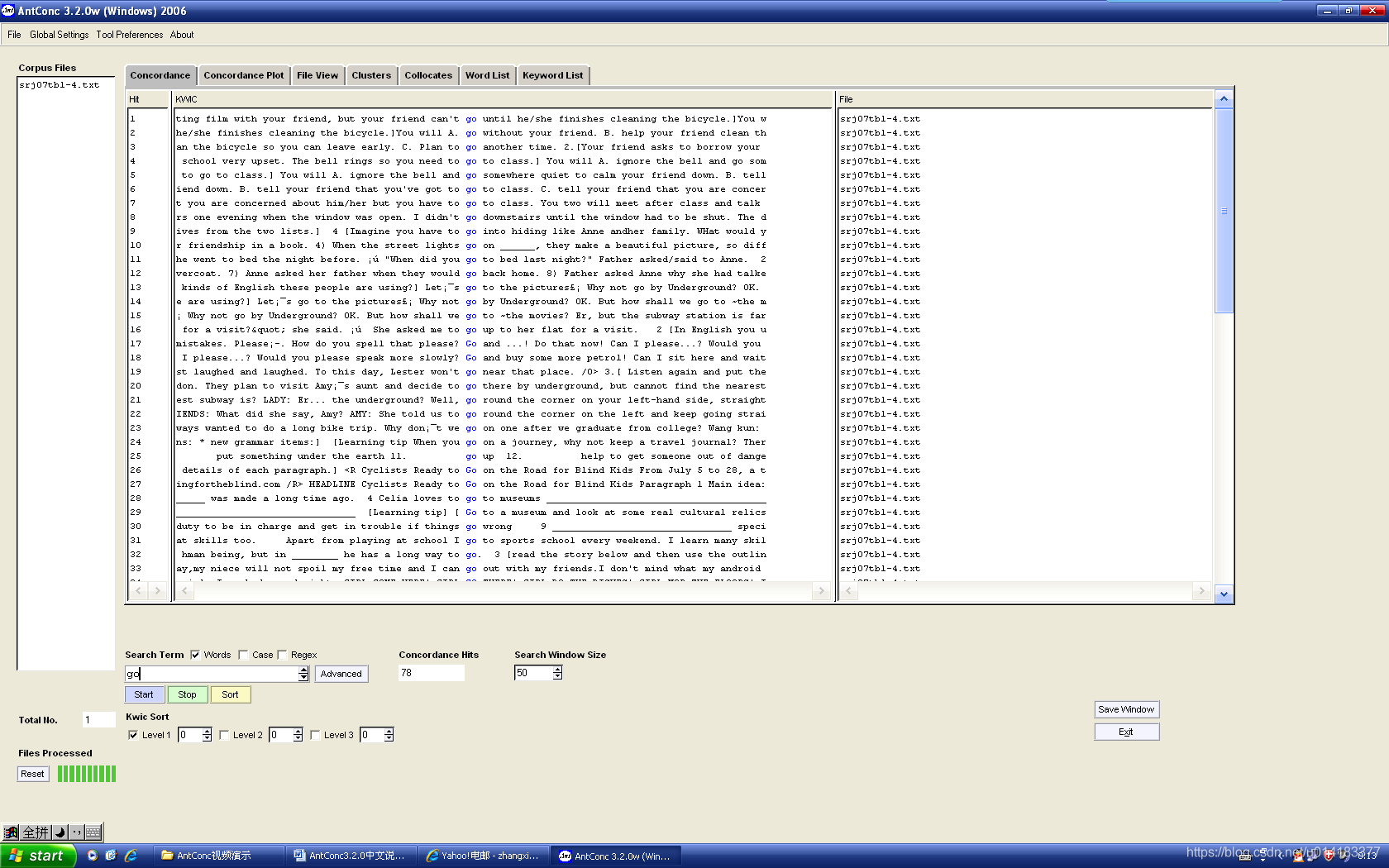
图1.1单项检索结果
(2)多项检索
- 设置多项检索
除了检索单个词项以外,AntConc还具有检索多个词项的功能,检索方法为在检索项间键入“|”符号。
例:要检索动词go的各种时态形式,可在“Search Term”中输入go|went|gone|goes
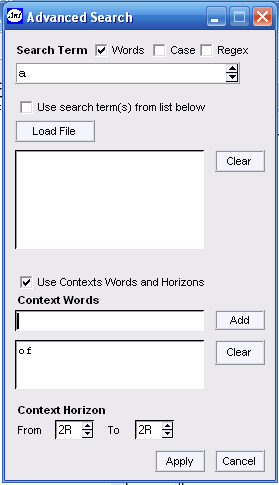
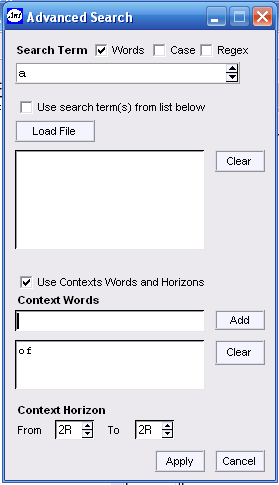 设置语境词检索
设置语境词检索
为了限制语境共现的检索,可以设定一个语境词在检索项周边一定的语境范围内出现。
例:如要研究 a … of 这一类词组,可通过AntConc提取所有的词项,检索方法如下:
-
- 在“Search Term”一栏键入a;
|
点击“Search Term”旁的![]() ,进入“Advanced Search”界面,如图1.2所示。点击“Use context words and horizons”,然后在“Context Words”一栏键入of,点击
,进入“Advanced Search”界面,如图1.2所示。点击“Use context words and horizons”,然后在“Context Words”一栏键入of,点击![]() 。如要重新设置语境词,可先点击
。如要重新设置语境词,可先点击![]() 清除原来语境词,后重复以上操作。另外,还需设定语境词距离检索项的位置,如本研究中,of在a的右二位置,所以“Content Horizon”确定为
清除原来语境词,后重复以上操作。另外,还需设定语境词距离检索项的位置,如本研究中,of在a的右二位置,所以“Content Horizon”确定为![]() ,最后点击
,最后点击![]() ;
;
-
- 回到语境共现的界面后,点击
 ,开始检索。结果可提取a lot of, a bit of 等词块。
,开始检索。结果可提取a lot of, a bit of 等词块。
- 回到语境共现的界面后,点击
- 设置多字语检索
在研究中,如需检索多个词项,除了使用“|”以外,也可使用以下方法,尤其适合检索项数目较多的情况。
例:研究感官动词watch, sound, feel, hear, smell
- 在TXT文本中键入所有要检索的词项,可多达250个词。然后为该文本起名保存。需注意:键入的词项需以列的形式排列。如:
feel
feels
felt
- 点击Search Term旁的
 ,选择“Use search term(s) from list below”。 点击
,选择“Use search term(s) from list below”。 点击
 ,在保存以上新建的文本的盘符路径点击文本名,然后点击
,在保存以上新建的文本的盘符路径点击文本名,然后点击![]() ;
;
- 回到语境共现的界面后,点击
 ,开始检索。
,开始检索。
(3)类别检索
- 使用通配符检索
| 符号 | 意义 | 检索项 | 检索结果 |
| * | 零个或多个字符 | book* | 提取所有以book打头的词,如book、books、booking、bookshop等 |
| *book | 提取所有以book结尾的词,如book、notebook等 | ||
| *book* | 可以同时提取包括以上两类词 | ||
| + | 零个或一个字符 | book+ | 提取所有以book打头的词,但之后有零个或一个字母,如book、books |
| ? | 任意一个字符 | ?ough | 提取所有以字母组合ough结尾的,但之前有一个字母的词,如cough、rough等 |
| @ | 零个或一个词 | think@of
| 提取所有含有的词组,如think of、think highly of等 |
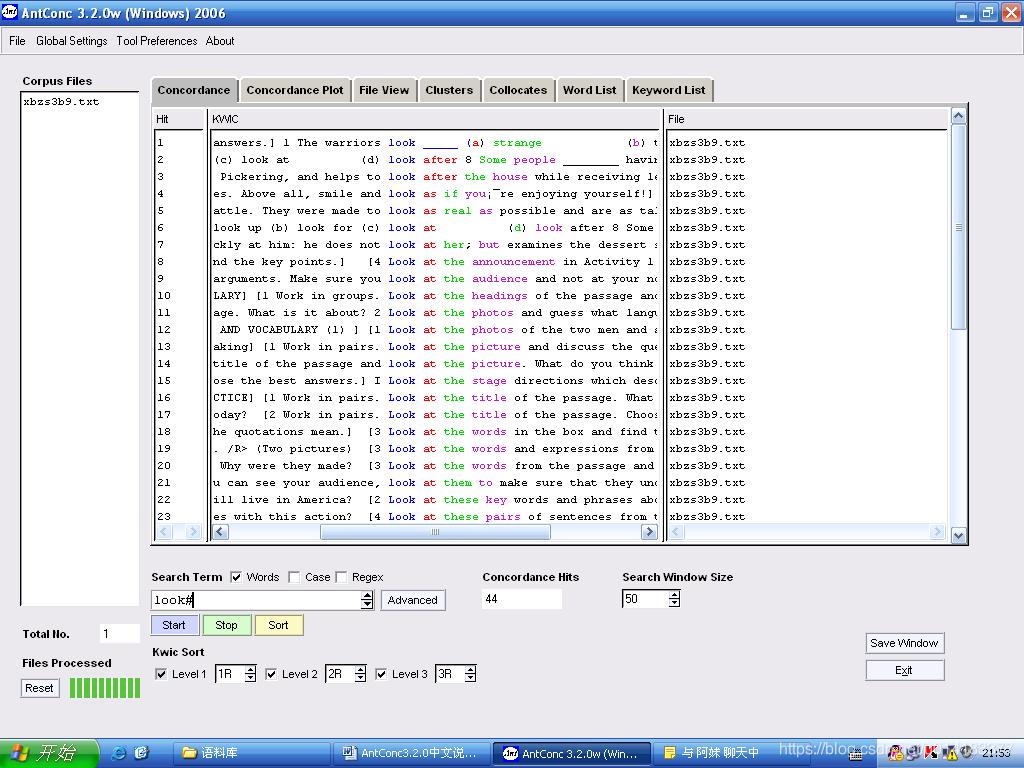
| # | 任意一个词 | look# | 提取所有与look的搭配,如look after、look at等 |
- 附码检索
因研究需要,有些语料经过整理加工并附加上各种符号标记,称为“附码语料库”。 如附有词性标注的LOBTAG和附有错误类型标记的CLEC等。检索时只需键入某个标记符号便可提取带附有该标码的所有词。
例:提取LOBTAG语料库中所有的名词,只需键入*_NN(NN为名词标码,关于其他词性的详细标记,请参阅何安平,2004,《语料库语言学与英语教学》一书的附录113页。
(4)在指定范围内检索
a) 在concordance的检索界面上选择"Regex" (regular expression),键入\[.*\] 为检索项便可提取语料库中所有在起止符号“[”和“]”之间的所有文字内容,其他符号照似类推。
b) 在concordance的检索界面上选择"Regex" (regular expression),键入\[.*write.*\] 为检索项便可提取语料库中所有在起止符号“[”和“]”之内的“write”的语境共现行,其他词项照似类推。键入的检索项计较大小写,但是可以用通配符*。
1.2分析检索结果
(1)观察频数、分布
- 频数即该检索项出现的次数,可在“Concordance Hits”一栏中获得。
- 点击
 ,查看检索项在语料文本中的分布状况。
,查看检索项在语料文本中的分布状况。
(2)凸显周边语境词
|
 为了具体某个教学等目的,可通过凸显检索项周边的某些词汇。方法是选择“Kwic Sort”, R1和L1分别代表检索项右方和左方的第一个词,一次可设置三列凸现词,均按字母顺序排列。检索结果如图1.3所示。如想使凸显内容的颜色一致,可通过设置
为了具体某个教学等目的,可通过凸显检索项周边的某些词汇。方法是选择“Kwic Sort”, R1和L1分别代表检索项右方和左方的第一个词,一次可设置三列凸现词,均按字母顺序排列。检索结果如图1.3所示。如想使凸显内容的颜色一致,可通过设置![]() 下拉菜单中的“Color Settings”改变颜色。另外,若要凸显的部分不是一个词,而是单词中的字母,可选择
下拉菜单中的“Color Settings”改变颜色。另外,若要凸显的部分不是一个词,而是单词中的字母,可选择![]() 下拉菜单中的“Concordance”选项中的“Sort by characters instead of words”,如图1.4所示。
下拉菜单中的“Concordance”选项中的“Sort by characters instead of words”,如图1.4所示。
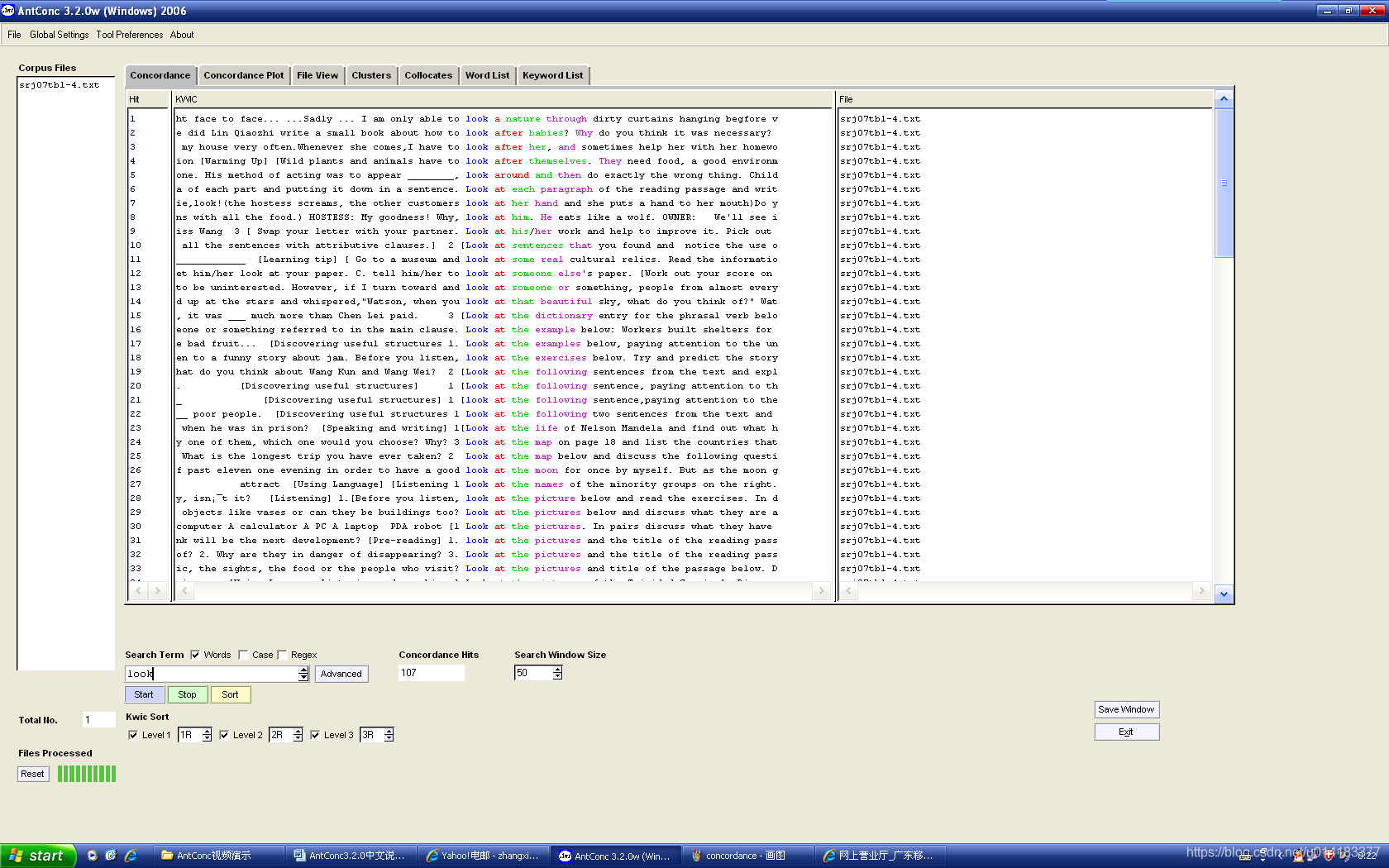
图1.3凸显周边语境词检索结果
(3)提取搭配词表
通过点击主界面中的![]() ,可获得检索项的搭配词表,同时可以设置搭配词的位置、出现的最少次数与词表的排列方式。
,可获得检索项的搭配词表,同时可以设置搭配词的位置、出现的最少次数与词表的排列方式。
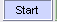
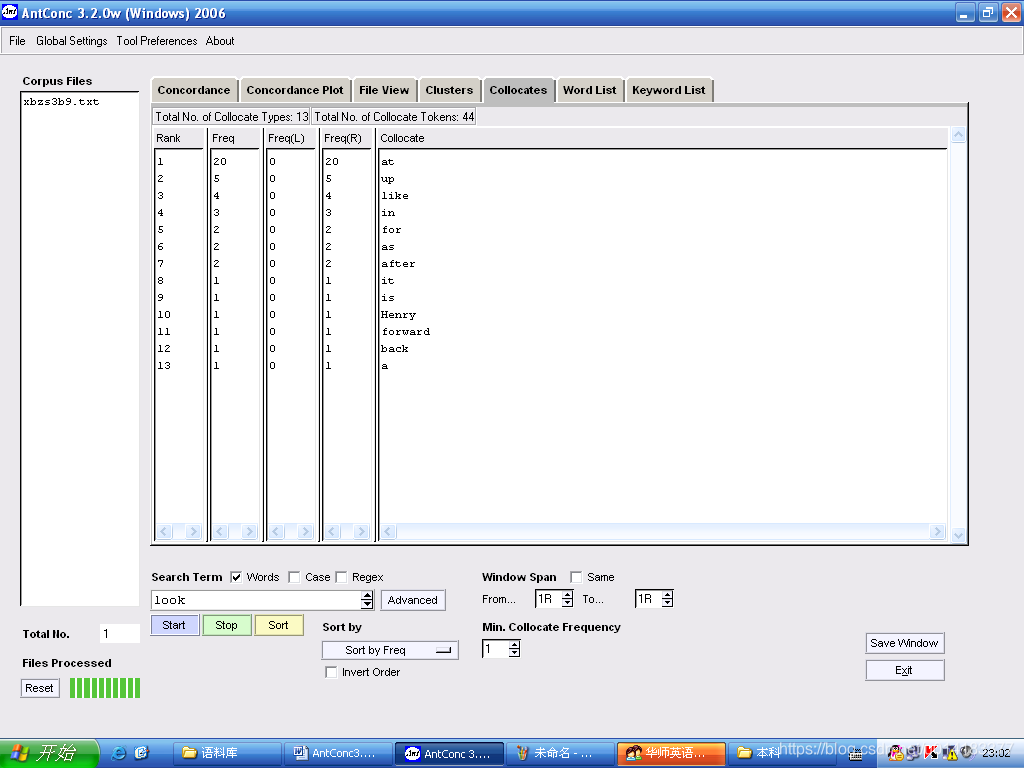
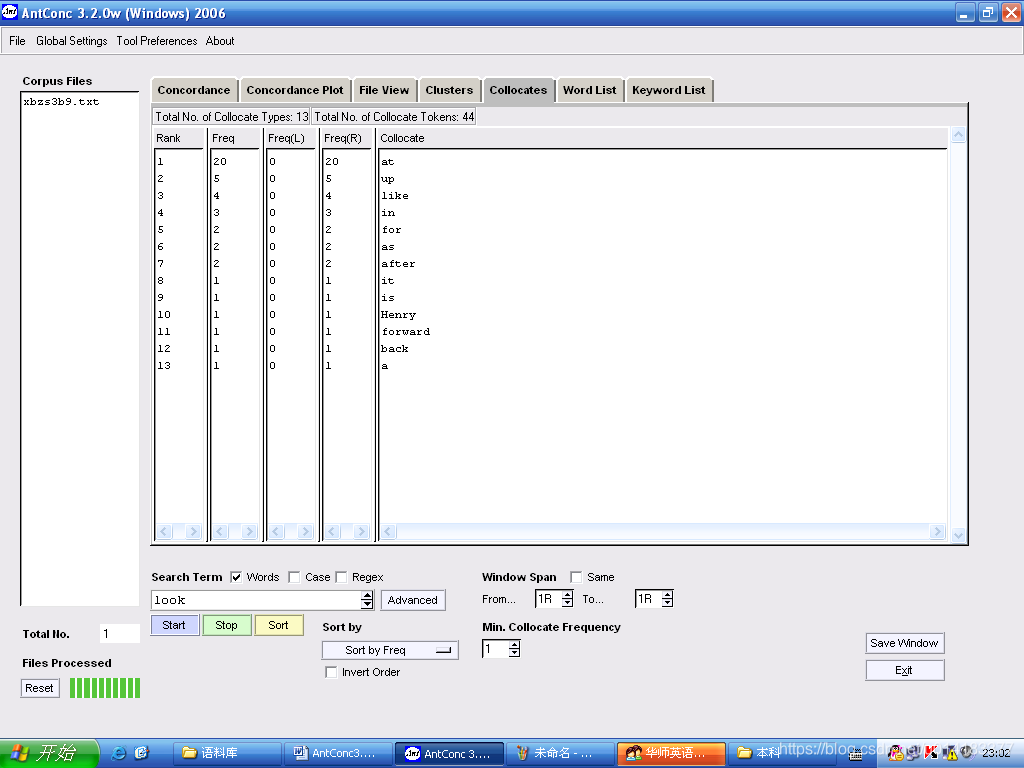
例:观察look右一的搭配词
- 点击主界面中的
 ;
; - 在“Search Term”一栏键入look;
- 设置搭配词的位置,如
 ;
; - 点击
 ,开始检索,检索结果如图1.5所示。
,开始检索,检索结果如图1.5所示。 - 点击“Sort by Freq” 可根据不同的需要设定搭配词表的排列方式,如按频数排,按拼写字母排等等。
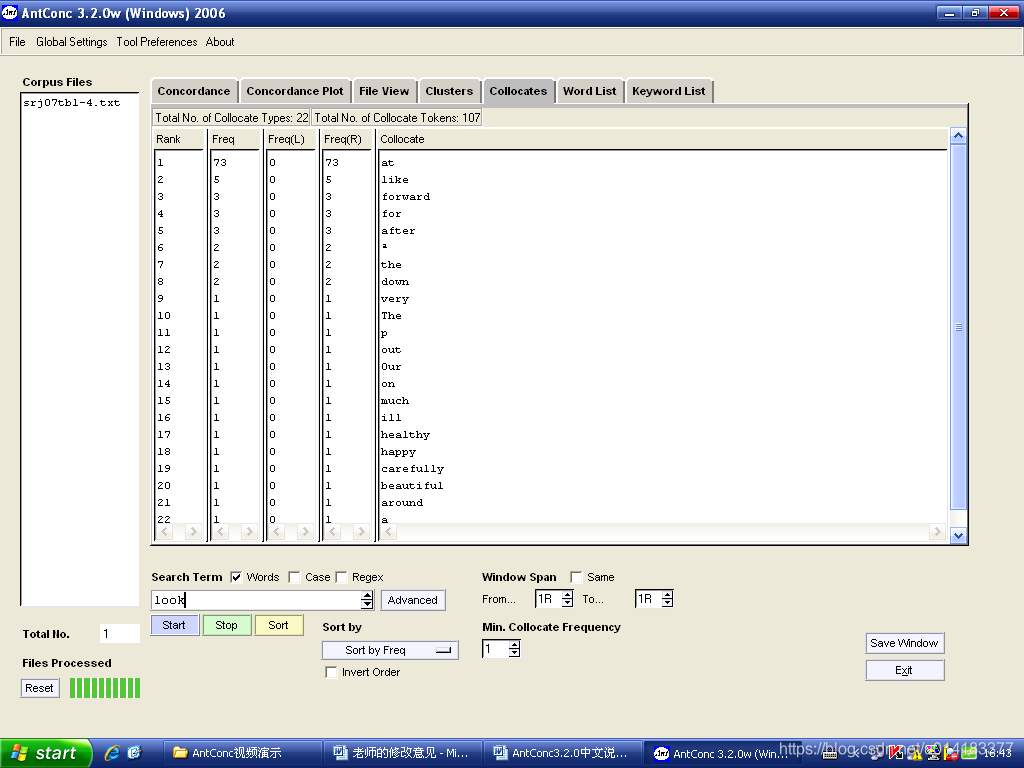
图1.5 提取搭配词表检索结果
 (4)提取搭配短语
(4)提取搭配短语
另外,也可以使用![]() 这一工具来提取搭配词块,且可设置检索项在词块中的位置。
这一工具来提取搭配词块,且可设置检索项在词块中的位置。
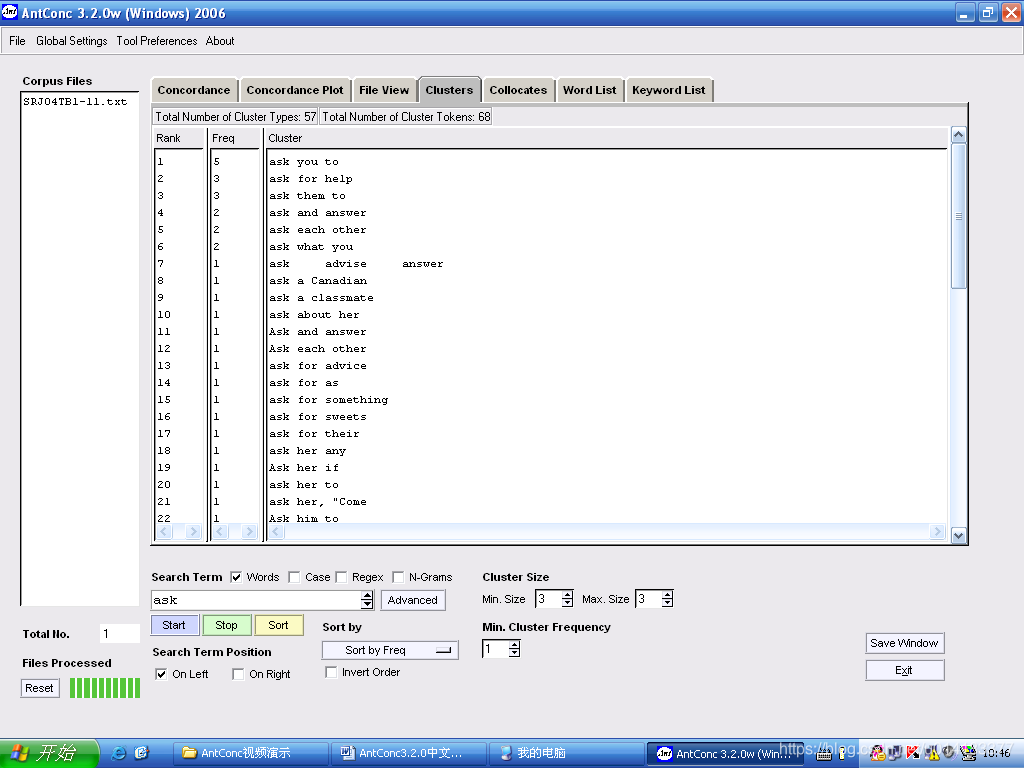
例:检索以ask开头的搭配词块
- 点击主界面中的
 ;
; - 在“Search Term”一栏键入ask;
- 设置检索项的位置,如选择“On the left”;
- 设置搭配词块的长度,如Min.Size:3, Max.Size:3;
|
点击![]() ,开始检索,检索结果如图1.6所示,所有的ask被列在词块的左边。
,开始检索,检索结果如图1.6所示,所有的ask被列在词块的左边。
(5)隐藏、分类和删除
“隐藏”是指把检索结果中的检索项挖空,可用于教学或测试。具体操作方法如下:
- 在“Search Term”一栏键入要检索的词项,如look;
- 点击
 ,选择“Concordance”,再选择“Hide search term in KWIC display”, 最后点击
,选择“Concordance”,再选择“Hide search term in KWIC display”, 最后点击 ;
; - 点击
 ,开始检索。
,开始检索。
检索结果如下:
you always do your own homework? Do you ******* for help when you think it necessary? Do you help
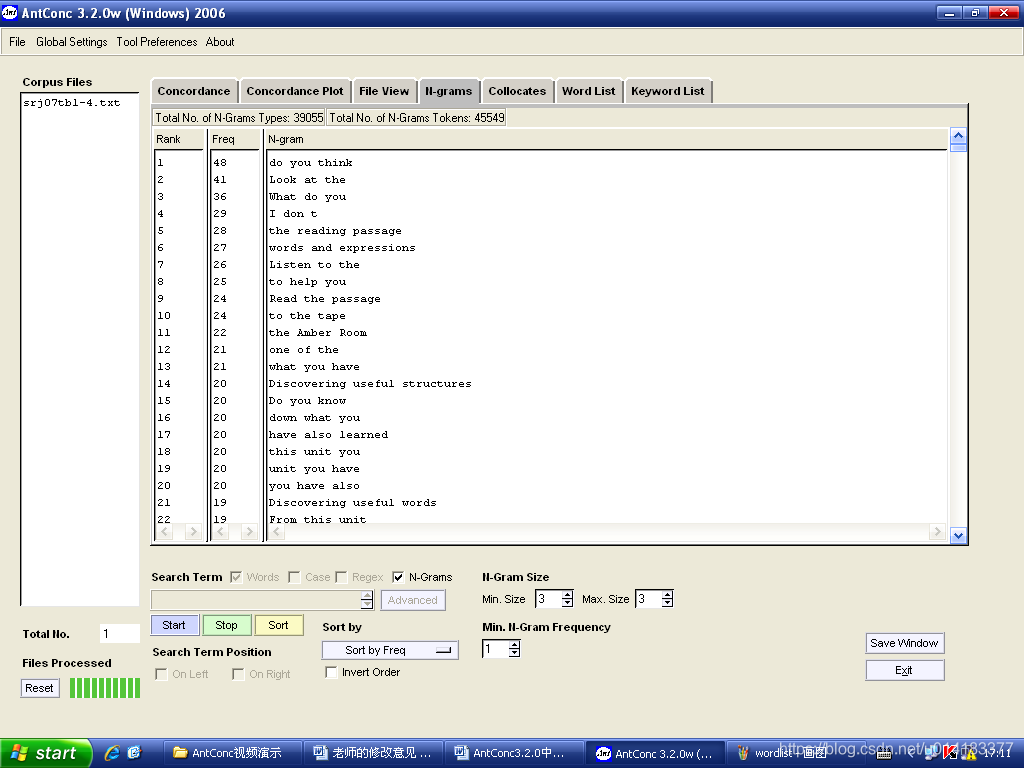
2. 提取词频表
2.1单字和N字语词频表
单字词频表是指目标语料库的单词表,且词频表的检索结果是以每个词的形式及其频数排列。方法如下:
- 选择要生成单字词频的目标语料库;
- 进入
 界面,设置词频表排列排序方式,如“Sort by Freq”;也可以设置为按词头的或者词尾的拼写字母顺序排列。
界面,设置词频表排列排序方式,如“Sort by Freq”;也可以设置为按词头的或者词尾的拼写字母顺序排列。 - 点击
 ,开始检索,检索结果如图2.1所示。
,开始检索,检索结果如图2.1所示。
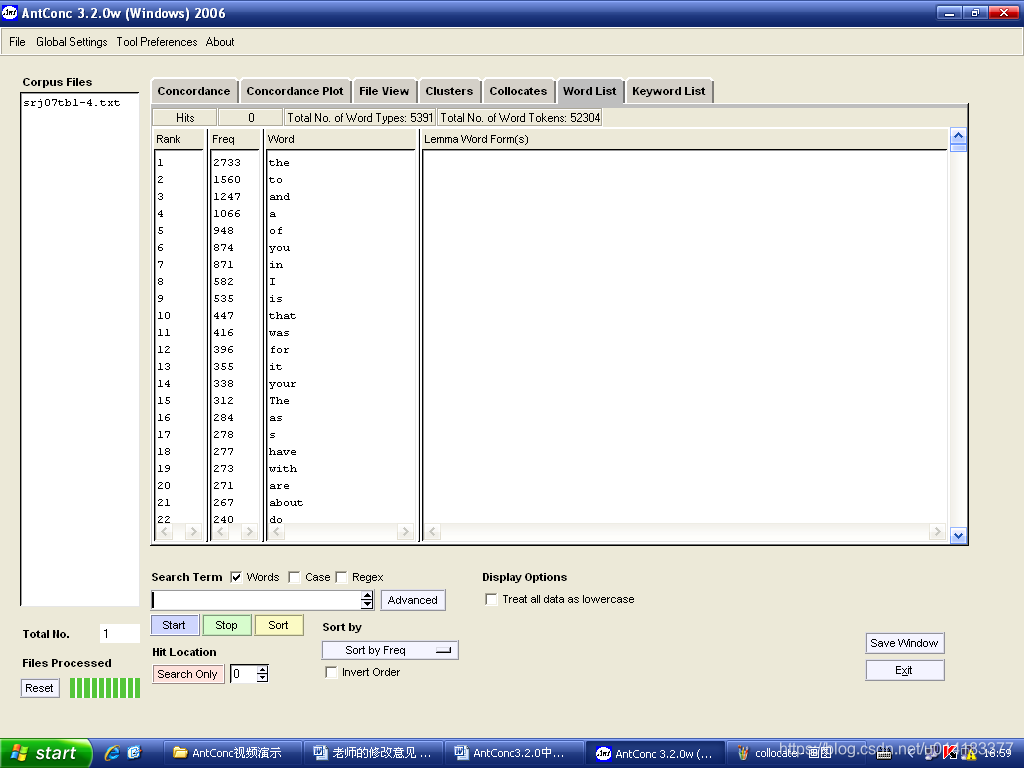
图2.1 单字词频表检索结果
N字语词频表是指目标语料库的多字语频数表。例如,检索句子“This is a pen”的2字语词频表结果为:“this is”、“is a”、“a pen”。N字语词频表的提取方法如下:
- 选择要生成单字词频的目标语料库;
- 进入界面,后点击
 ;
; - 设置N字语词频表的长度,如
- 选择词表的排序方式,如“Sort by Freq”;
- 点击
 ,开始检索,检索结果如图2.2所示。
,开始检索,检索结果如图2.2所示。
图2.2 N字语词频表检索结果
2.2词项重组---词簇化(lemmatizing)
词簇化是将同一词性的某个词的所有曲折变化形式作削尾处理,并归为一个词簇来计算频数。其好处是可以简约词频表并且引起对构词法的关注。对词频表进行词簇化的方法如下:
在![]() 界面生成词频表之后,拉下Tool Preference菜单,选择Lemma list options, 点击open 和load,上传lemma1文档(可在本网站下载)点击Apply (如图2. 3所示)。词簇化的部分结果见图2.4.
界面生成词频表之后,拉下Tool Preference菜单,选择Lemma list options, 点击open 和load,上传lemma1文档(可在本网站下载)点击Apply (如图2. 3所示)。词簇化的部分结果见图2.4.
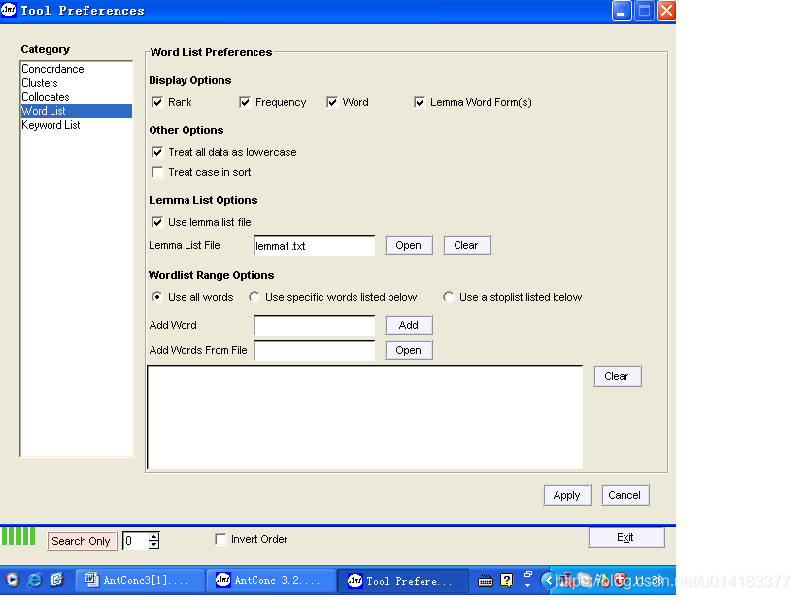
图2. 3 设置词簇化界面
图2.4 词频表被词簇化后的结果(部分)。
图中1142例a和133例an被归为同一个词簇a共1275例。
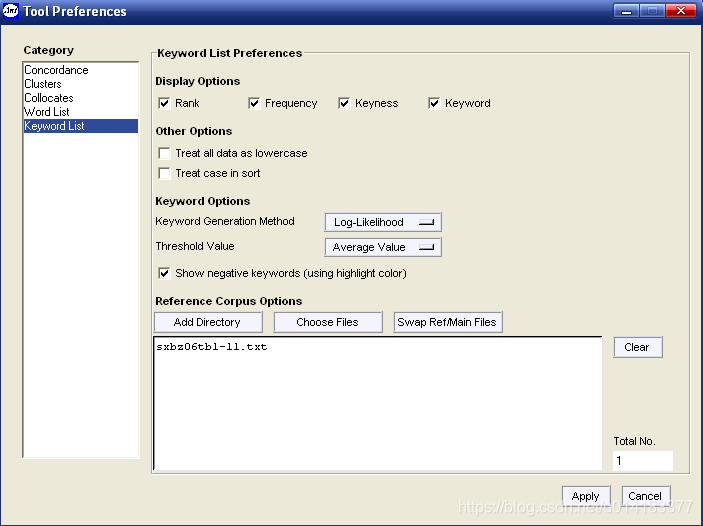
3. 提取关键词表
关键词表是指两个语料库的词频表相比,其中一个明显地高频于另一个的那部分词项表。前一个称目标语料库;后一个称参照语语料库,通常规模要大一些,以此来凸现目标语料库的一些特别高频词以浮现该语料库的主题或内容特色。
3.1凸显目标语料库中显著性高频于对照语料库的词项
具体操作方法如下:
 点击file下拉菜单中的“open files”,选择要对比的目标语料的语料(如果对比整个文件夹,可以选择open directory);
点击file下拉菜单中的“open files”,选择要对比的目标语料的语料(如果对比整个文件夹,可以选择open directory);- 点击主界面中的
 ;
; - 点击
 ,选择“Keyword List”,如图3.1所示;
,选择“Keyword List”,如图3.1所示; - 选择“Show negative keywords”,可在检索结果中显示对照语料明显高于目标语料的词;
|
点击![]() ,选择对照语料,最后点击
,选择对照语料,最后点击![]() ;
;
- 点击
 ,开始检索,检索结果如图3.2所示。
,开始检索,检索结果如图3.2所示。
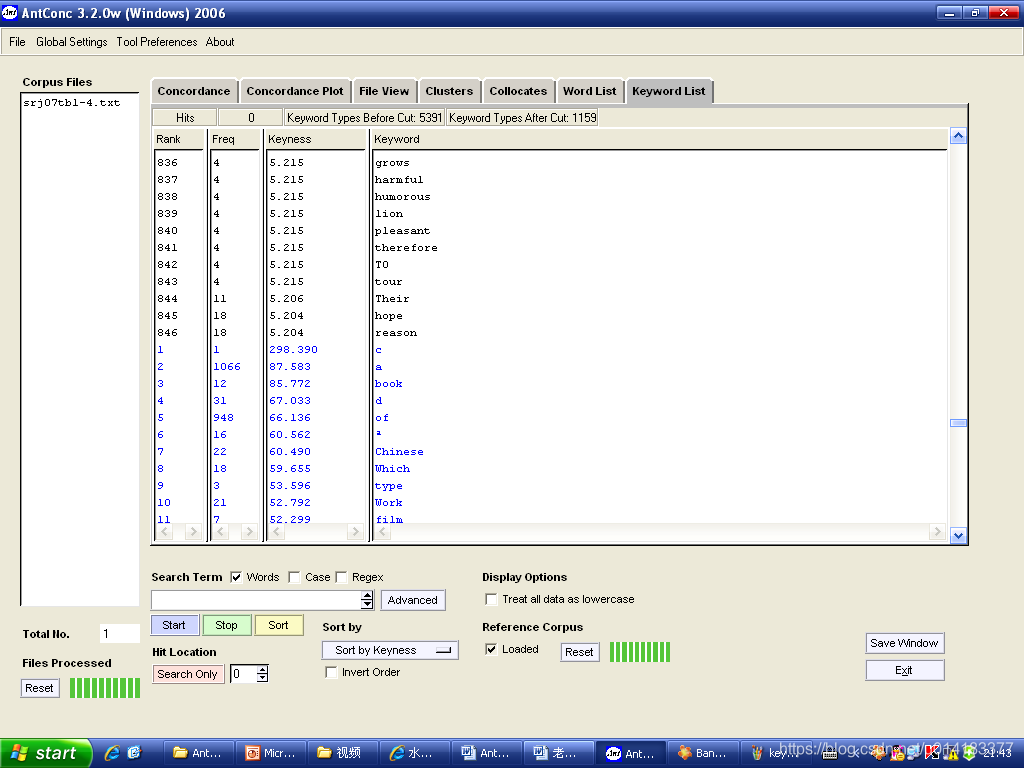
图3.2 提取关键词表检索结果
[1] 此说明书由华南师范大学外文学院2007研究生张杏娟编写,导师何安平订正和补充。
其中限定范围的检索方法由香港城市大学D.Lee博士提供,仅此致谢。

















 8236
8236

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









