







1. 数据集 Dataset
数据是深度学习的基础,高质量的数据输入将在整个深度神经网络中起到积极作用。MindSpore提供基于Pipeline的数据引擎,通过数据集(Dataset)和数据变换(Transforms)实现高效的数据预处理。其中Dataset是Pipeline的起始,用于加载原始数据。mindspore.dataset提供了内置的文本、图像、音频等数据集加载接口,并提供了自定义数据集加载接口。
此外MindSpore的领域开发库也提供了大量的预加载数据集,可以使用API一键下载使用。本文将分别对不同的数据集加载方式、数据集常见操作和自定义数据集方法进行详细阐述。
1.1 导入依赖
# 导入numpy库,它是一个强大的数学库,用于在Python中进行数值计算。
import numpy as np
# 从MindSpore的dataset模块中导入vision子模块。
# 这个子模块包含了一些常用的图像处理函数,用于数据增强和图像变换。
from mindspore.dataset import vision
# 从MindSpore的dataset模块中导入MnistDataset和GeneratorDataset类。
# MnistDataset是一个用于加载和解析MNIST数据集的类。
# GeneratorDataset是一个用于创建自定义数据集的类,可以通过一个生成器函数来提供数据。
from mindspore.dataset import MnistDataset, GeneratorDataset
# 导入matplotlib的pyplot子模块,它是一个绘图库,用于在Python中创建静态、交互式和动画可视化。
import matplotlib.pyplot as plt
1.2 数据集加载
我们使用Mnist数据集作为样例,介绍使用mindspore.dataset进行加载的方法。
1.2.1 下载数据集
mindspore.dataset提供的接口仅支持解压后的数据文件,因此我们使用download库下载数据集并解压。
# 导入下载模块,用于下载文件
from download import download
# 定义MNIST数据集的URL地址
url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/" \
"notebook/datasets/MNIST_Data.zip"
# 调用download模块,下载文件并保存到当前目录下
# 参数kind="zip"指定下载的文件类型为zip
# 参数replace=True指定如果文件已存在,则替换它
path = download(url, "./", kind="zip", replace=True)
输出:
Downloading data from https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/MNIST_Data.zip (10.3 MB)
file_sizes: 100%|███████████████████████████| 10.8M/10.8M [00:00<00:00, 104MB/s]
Extracting zip file...
Successfully downloaded / unzipped to ./
该下载模块会自动解压并删除压缩文件
1.2.2 查看下载的数据集
[... MNIST_Data]$ du -ah
45M ./train/train-images-idx3-ubyte
60K ./train/train-labels-idx1-ubyte
45M ./train
7.5M ./test/t10k-images-idx3-ubyte
12K ./test/t10k-labels-idx1-ubyte
7.5M ./test
53M .
可以看到同时下载了训练数据集和测试数据集,每个数据集都包括了图像和标签(标准答案)两个部分
1.2.3 加载数据集
# 创建MnistDataset类的实例,用于加载MNIST训练数据集
# 参数"MNIST_Data/train"指定了数据集的目录
# 参数shuffle=False指定在加载时不打乱数据的顺序。从训练角度讲,可能设置为true效果更好。
train_dataset = MnistDataset("MNIST_Data/train", shuffle=False)
# 打印train_dataset的类型,这将显示MnistDataset类的类型
print(type(train_dataset))
输出:
<class 'mindspore.dataset.engine.datasets_vision.MnistDataset'>
可以看到数据类型为 MnistDataset
1.3 数据集迭代
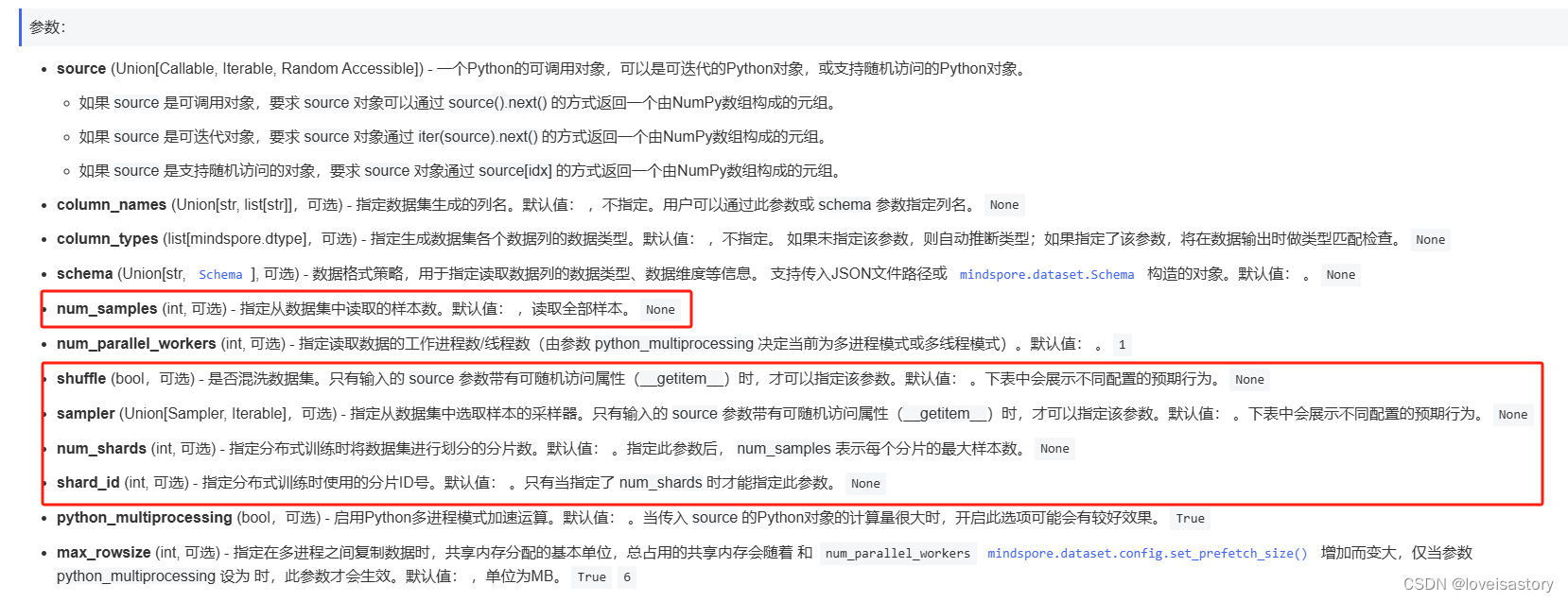
数据集加载后,一般以迭代方式获取数据,然后送入神经网络中进行训练。我们可以用create_tuple_iterator或create_dict_iterator接口创建元组或字典数据迭代器,迭代访问数据。
访问的数据类型默认为Tensor;若设置output_numpy=True,访问的数据类型为Numpy。
下面定义一个可视化函数,迭代9张图片进行展示。
# 定义一个可视化函数,传入数据集,绘制前9个图像
def visualize(dataset):
# 创建一个matplotlib的Figure对象,用于绘制图像。
# figsize参数指定了Figure对象的大小,这里是一个正方形。4代表4英寸,在96DPI(每英寸像素数)屏幕上为384像素(4inch*96px/inch)
figure = plt.figure(figsize=(4, 4))
# 定义子图中的列数和行数。
cols, rows = 3, 3
# 调整子图之间的间距。行间距和列间距各为图像宽度和高度的一半
plt.subplots_adjust(wspace=0.5, hspace=0.5)
# 遍历数据集,这里使用了MindSpore的create_tuple_iterator方法来创建一个迭代器。
# idx是enumerate为dataset中的每一个元素生成的索引
# image和label分别是对应的图像和标签数据
for idx, (image, label) in enumerate(dataset.create_tuple_iterator()):
# 在Figure对象中添加一个3*3的子图。由于子图位置从1开始,而idx从0开始,所以需要idx+1
figure.add_subplot(rows, cols, idx + 1)
# 设置子图的标题为标签的整数形式。
plt.title(int(label))
# 关闭子图的坐标轴。
plt.axis("off")
# 将图像数据转换为numpy数组,并使用squeeze方法去除维度为1的轴。
# 然后使用imshow方法在子图中显示图像,使用灰度颜色映射。
# 在处理图像数据时,通常会有一个额外的维度,表示颜色通道(例如,对于灰度图像,这个额外的维度是1)。
# squeeze()方法移除了这个额外的维度,使得图像数据变成一个二维数组,这样就可以使用imshow()方法来正确显示图像了。
# 如果图像是彩色的,通常会有3个颜色通道(红、绿、蓝),这时就不会使用squeeze()方法,因为imshow()期望彩色图像数据是三维数组。
# cmap="gray": 这个参数指定了用于显示图像的颜色映射(colormap)。
# "gray"表示使用灰度颜色映射来显示图像。这对于只有亮度信息,没有颜色信息的灰度图像是合适的
# 如果图像是彩色的,你应该省略cmap="gray"参数,这样imshow()会自动使用默认的颜色映射来显示彩色图像。
plt.imshow(image.asnumpy().squeeze(), cmap="gray")
# 如果已经显示了rows * cols=9个子图,则停止循环。
if idx == cols * rows - 1:
break
# 显示所有的子图。
plt.show()
# 调用可视化函数绘制图像
visualize(train_dataset)
输出:

1.4 数据集常用操作
Pipeline的设计理念使得数据集的常用操作采用dataset = dataset.operation()的异步执行方式,执行操作返回新的Dataset,此时不执行具体操作,而是在Pipeline中加入节点,最终进行迭代时,并行执行整个Pipeline。
下面分别介绍几种常见的数据集操作。
1.4.1 shuffle
数据集随机shuffle可以消除数据排列造成的分布不均问题。
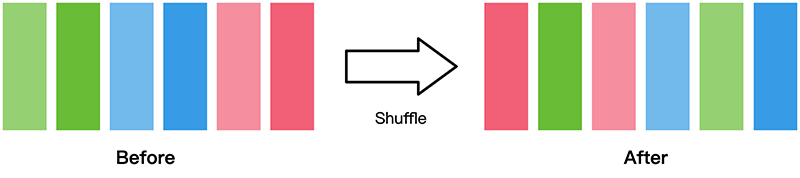
mindspore.dataset提供的数据集在加载时可配置shuffle=True,或使用如下操作:
# shuffle方法从数据集中随机选择64个样本放入缓冲区,然后从缓冲区中随机选择样本输出。buffer_size=64参数指定了洗牌缓冲区的大小。
# 这样可以增加数据的随机性,有助于提高模型训练的效率和质量。
# 在训练机器学习模型时,通常会对训练数据进行打乱,以确保模型不会因为数据的顺序而产生偏见。
train_dataset = train_dataset.shuffle(buffer_size=64)
# 重新绘制打乱后的前9个训练图像
visualize(train_dataset)
输出:

1.4.2 map
map操作是数据预处理的关键操作,可以针对数据集指定列(column)添加数据变换(Transforms),将数据变换应用于该列数据的每个元素,并返回包含变换后元素的新数据集。
Dataset支持的不同变换类型详见数据变换Transforms。
# 从train_dataset数据集中获取下一个样本,并将其解构成image和label两个部分。
image, label = next(train_dataset.create_tuple_iterator())
# 打印image变量的形状和数据类型。shape属性返回一个元组,表示数据的维度。dtype属性返回数据的类型。
print(image.shape, image.dtype)
输出:
(28, 28, 1) UInt8
可以看到图像为28*28像素的灰度图像,数据类型是uint8,8位无符号整形。
我们对Mnist数据集做数据缩放处理,将图像统一除以255,数据类型由uint8转为float32。
# map定义一个映射操作
# Rescale函数将图像的像素值从0到255调整到0到1,精度从int8转为float32
# 输入的图像数据位于'image'列中
train_dataset = train_dataset.map(vision.Rescale(1.0 / 255.0, 0), input_columns='image')
# 解构下一个数据
image, label = next(train_dataset.create_tuple_iterator())
# 重新打印形状和数据类型
print(image.shape, image.dtype)
输出:
(28, 28, 1) Float32
可以看到数据类型已经变成 float32了。
可能会有疑问,图像大小像素值不是已经除以255了吗,为什么打印出来还是2828
这是因为rescale函数本身只改变图像大小代表的数据,并不改变图像本身。图像依然是2828像素大小。
如果将image对象的数据打印出来,会发现是一个28行乘28列的二维数组,数组中的值均为0-1的值,而没有rescale之前,数组中的值为0-255。
rescale之前:image数据形如:[[0][127]…一共28列…[238][0]] 这样的数据共28行
rescale之前:image数据变为:[[0][0.4980392]…共28列…[0.9333333][0]],同样是28行。所以像素个数没变,数据精度发生了变化
1.4.3 batch
将数据集打包为固定大小的batch是在有限硬件资源下使用梯度下降进行模型优化的折中方法,可以保证梯度下降的随机性和优化计算量。
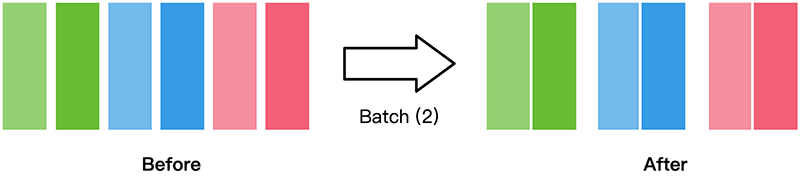
一般我们会设置一个固定的batch size,将连续的数据分为若干批(batch)。
# 创建一个数据集的迭代器,该迭代器可以按批次访问数据集。
# batch方法对train_dataset数据集进行批量打包处理。batch_size=32参数指定了每个批次的大小,即每个批次包含32个样本。
# 这样可以提高模型的训练效率,因为模型可以同时处理多个样本,而不是逐个处理。
train_dataset = train_dataset.batch(batch_size=32)
# 获取下一个批次的数据
image, label = next(train_dataset.create_tuple_iterator())
# 打印当前批次图像的形状和数据类型
print(image.shape, image.dtype)
输出:
(32, 28, 28, 1) Float32
可以看到,batch后的数据shape增加了一维,其值为batch_size。
1.5 自定义数据集
mindspore.dataset模块提供了一些常用的公开数据集和标准格式数据集的加载API。
对于MindSpore暂不支持直接加载的数据集,可以构造自定义数据加载类或自定义数据集生成函数的方式来生成数据集,然后通过GeneratorDataset接口实现自定义方式的数据集加载。
GeneratorDataset支持通过可随机访问数据集对象、可迭代数据集对象和生成器(generator)构造自定义数据集,下面分别对其进行介绍。
1.5.1 可随机访问数据集
可随机访问数据集是实现了__getitem__和__len__方法的数据集,表示可以通过索引/键直接访问对应位置的数据样本。
例如,当使用dataset[idx]访问这样的数据集时,可以读取dataset内容中第idx个样本或标签。
# 定义可随机访问数据集类,用于随机访问数据
class RandomAccessDataset:
# 初始化方法,用于在创建对象时初始化数据集
def __init__(self):
# self._data 是一个5行2列,元素全为1的NumPy数组,用于存储数据
self._data = np.ones((5, 2))
# self._label 是一个5行1列,元素全为0NumPy数组,用于存储标签
self._label = np.zeros((5, 1))
# 实现__getitem__方法,使得数据集对象可以像列表一样被索引
# index 是一个整数,表示要获取的数据的索引
def __getitem__(self, index):
# 返回的数据是self._data[index]和self._label[index],它们分别是数据和标签
return self._data[index], self._label[index]
# 实现__len__方法,使得数据集对象可以像列表一样被获取长度
def __len__(self):
# 返回len(self._data),即数据集中的样本数量
return len(self._data)
# 创建自定义的可随机访问数据集类
loader = RandomAccessDataset()
# GeneratorDataset是一个特殊的数据集类型,它允许你通过一个生成器函数来提供数据。
# source参数被设置为loader对象,即我们自定义的数据集。
# column_names参数是一个列表,它定义了数据集中每个列的名称。在这个例子中,数据集包含两个列:data和label。
# 形成的数据集,包含data和label两列,其中data共5行2列,所有元素都是1;label共5行1列,所有元素都是0
dataset = GeneratorDataset(source=loader, column_names=["data", "label"])
# 遍历dataset数据集
for data in dataset:
# 打印每一个数据
print(data)
输出:
[Tensor(shape=[2], dtype=Float64, value= [ 1.00000000e+00, 1.00000000e+00]), Tensor(shape=[1], dtype=Float64, value= [ 0.00000000e+00])]
[Tensor(shape=[2], dtype=Float64, value= [ 1.00000000e+00, 1.00000000e+00]), Tensor(shape=[1], dtype=Float64, value= [ 0.00000000e+00])]
[Tensor(shape=[2], dtype=Float64, value= [ 1.00000000e+00, 1.00000000e+00]), Tensor(shape=[1], dtype=Float64, value= [ 0.00000000e+00])]
[Tensor(shape=[2], dtype=Float64, value= [ 1.00000000e+00, 1.00000000e+00]), Tensor(shape=[1], dtype=Float64, value= [ 0.00000000e+00])]
[Tensor(shape=[2], dtype=Float64, value= [ 1.00000000e+00, 1.00000000e+00]), Tensor(shape=[1], dtype=Float64, value= [ 0.00000000e+00])]
# 创建一个名为load的列表
# numpy.array是numpy库中的一个类,用于创建和操作多维数组。
# np.array(0):创建了一个0维数组,即标量,数组中只有一个元素,即数字0。
# np.array(1):创建了一个0维数组,即标量,数组中只有一个元素,即数字1。
# np.array(2):创建了一个0维数组,即标量,数组中只有一个元素,即数字2。
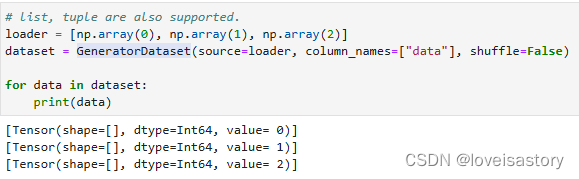
loader = [np.array(0), np.array(1), np.array(2)]
# 生成数据集,列名为data,数据为[0,1,2]
dataset = GeneratorDataset(source=loader, column_names=["data"],shuffle=false)
# 遍历数据集
for data in dataset:
# 打印每一个数据
print(data)
输出:
[Tensor(shape=[], dtype=Int64, value= 0)]
[Tensor(shape=[], dtype=Int64, value= 2)]
[Tensor(shape=[], dtype=Int64, value= 1)]
恩,很神奇地看到,打印出来的数据居然是无序的
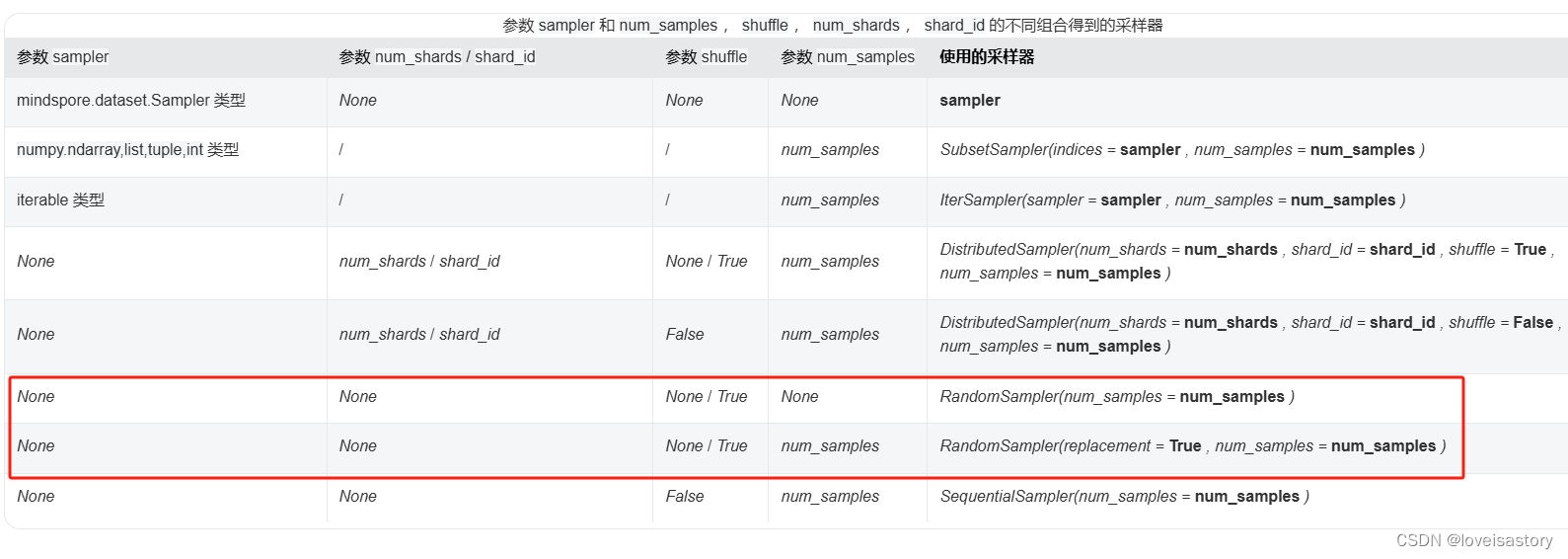
明明定义的loader是个有序的数组,为什么从这个数组生成数据集后,就无序了
找遍了整个新手教程也没有相关的说明
恩,此处要特别感谢一下@牧野老师的解惑
原来答案藏在API文档里:mindspore.dataset.GeneratorDataset
当传入参数为图上两种组合时,就会使用随机采样器。
而默认参数表就默符合这个配置。
若要生成有序数据集,只要将 shuffle设置为False即可,如图:
1.5.2 可迭代数据集
可迭代的数据集是实现了__iter__和__next__方法的数据集,表示可以通过迭代的方式逐步获取数据样本。这种类型的数据集特别适用于随机访问成本太高或者不可行的情况。
例如,当使用iter(dataset)的形式访问数据集时,可以读取从数据库、远程服务器返回的数据流。
下面构造一个简单迭代器,并将其加载至GeneratorDataset。
# 定义一个名为IterableDataset的迭代器类
# python中,迭代器是实现了__iter__() 和 __next__() 方法的对象。
# __iter__()方法返回迭代器本身,而 __next__()方法返回序列中的下一个值。
# 当调用 __next__()方法时,它会返回序列中的下一个值,并向前移动序列的位置。
# 仅管知道如此,当阅读以下代码试图了解他的工作原理时,对我来说还是太困难了,CPU都要干烧了。
# 如果您不关心他具体的工作原理,请跳过这些冗长的理解过程(##和###注释的部分)。
class IterableDataset:
# 初始化方法,用于初始化类对象并持有数据
def __init__(self, start, end):
'''初始化方法,设置起始值和结束值,以便后续生成数据集。'''
# 设置起始值和结束值
## 初始化方法指定了迭代器的范围,这没有什么好说的
self.start = start
self.end = end
# 定义__next__方法,用于迭代一个数据并返回
def __next__(self):
'''迭代器方法,用于获取下一个数据项。
当调用__next__时,它将返回下一个数据项。
'''
# 使用next()函数获取数据
## 这是为什么,next()函数为什么能获取序列中的下一个数据
## next是python内置函数,用于获取迭代器的下一个数据,这要求self.data必须是一个迭代器
## 这意味着迭代器类中必须完成self.data的迭代器创建,否则next函数将无法正常完成工作。
## 所以next(self.data)获取的是self.data的下一个值,并向前移动索引的位置。
## 由于next(self.data)就是__next__方法的返回值,所以__next__()方法和next()的执行逻辑是相同的
return next(self.data)
# 定义__iter__方法,用于重置迭代器
def __iter__(self):
'''迭代器方法,用于重置迭代器的状态。
当调用__iter__时,它将创建一个新的迭代器,并将其设置为从start到end之间的整数。
'''
# 创建一个迭代器,用于生成从start到end之间的整数,不包含end
# range方法会创建一个start到end,不含end的一个整数迭代器
## iter方法会调用迭代器的__iter__,并且返回迭代器本身。在这里就是调用range的__iter__方法,返回range创建的迭代器
## 所以self.data就会变成range创建的整数迭代器
self.data = iter(range(self.start, self.end))
# 返回迭代器对象
## 到此整个迭代器的定义过程已经结束,可以看到self.data在__iter__()被调用时,就会创建一个迭代器,所以__next__方法也能正常工作
return self
# 创建一个名为loader的IterableDataset实例,起始值为1,结束值为5,不含5
## loader创建时,会自动调用IterableDataset的__init__方法。实际上,他只是初始化了start和end的数值,没有发生其他任何事情。
## 它只是完成了迭代器类型实例的对象创建,并不包含迭代器的数据
loader = IterableDataset(1, 5)
# 创建一个名为dataset的GeneratorDataset实例,使用loader作为数据源,并指定列名为"data"
## GeneratorDataset的工作只是负责把数据类型从整型改成张量,并不改变迭代的行为和过程,所以在理解迭代器工作时,可以把他放一边
dataset = GeneratorDataset(source=loader, column_names=["data"])
## 假定此处的dataset是load,for循环开始执行时,会自动调用IterableDataset的__iter__()方法
## 此时self.data才开始真正创建,变成包含[1,2,3,4]4个元素的一个迭代器。
## __iter__()返回迭代器被for循环获得后,for循环又会自动去调用迭代器的__next__()方法获取到元素后步长会加1,进入到下一次循环
## 直至完成所有元素的获取。
### 所以总体来说,该迭代器就是通过next(self.data)和iter(创建具体的迭代器)两个内建函数来实现自定义的迭代器
### 可以预见,在python源码部分,next()和iter()本身应该也是保持一样的逻辑,
### 即next()方法的核心是通过__next__()方法获取迭代器的下一个数值,完成步长增长和边界检查等动作
### iter()方法的核心是调用__iter__()方法完成迭代器的创建并返回迭代器本身
### 当然也完全可以自己去实现next()和iter()的逻辑,保持__iter()__和__next()__核心功能一致即可
# 遍历dataset,打印每个数据项
for d in dataset:
print(d)
输出:
[Tensor(shape=[], dtype=Int64, value= 1)]
[Tensor(shape=[], dtype=Int64, value= 2)]
[Tensor(shape=[], dtype=Int64, value= 3)]
[Tensor(shape=[], dtype=Int64, value= 4)]
1.5.3 生成器
生成器也属于可迭代的数据集类型,其直接依赖Python的生成器类型generator返回数据,直至生成器抛出StopIteration异常。
下面构造一个生成器,并将其加载至GeneratorDataset。
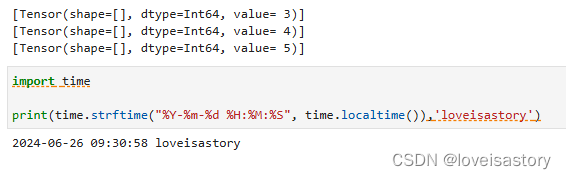
# 定义一个名为my_generator的函数,该函数接受两个参数:start和end。生成一个整数序列
def my_generator(start, end):
# 定义一个for循环,用于生成从start到end之间的整数,但不包括end
for i in range(start, end):
# yield语句的作用是生成一个迭代器,返回当前循环的值i
# 每次调用next()方法时,都会返回下一个值,直到遇到StopIteration异常
yield i
# 创建一个名为dataset的GeneratorDataset对象,使用lambda函数作为数据源
dataset = GeneratorDataset(source=lambda: my_generator(3, 6), column_names=["data"])
# 遍历dataset,打印每个数据项
for d in dataset:
print(d)
输出:
2. 总结
今天主要学习了MindSpore中的数据集(Dataset)的相关操作。包括标准数据集的加载、迭代、常用操作和自定义数据集的加载方法。
其中数据集的常用操作包括打乱、数据变换和批量打包。
打乱可以消除数据排列造成的分布不均问题,使模型算法更全面,以提高模型的泛化能力和减少对数据顺序的依赖。
数据变换是数据预处理过程中的一个关键步骤,其目的是为了使数据更适合于后续的分析和模型训练。通过数据变换,可以提高模型的性能,减少过拟合的风险,并使模型更加健壮。
数据批量打包是深度学习和机器学习中的一种常见技术,通过批量打包可以实现提高模型训练效率,增加训练数据的随机性,稳定梯度,优化内存使用等作用。















 1001
1001

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









