







背景:妹子最近要复习英语,想找些英语故事~~~~~~
--------------------------------------------------------------------------------
项目描述:
爬取英语阅读网(http://www.enread.com/)中的英语故事、英语笑话栏目(其他几个栏目组织结构都类似),每天选取一篇推送到妹子手机上。
==============================================
1.爬取文章
比如英语故事:
分为几个栏目
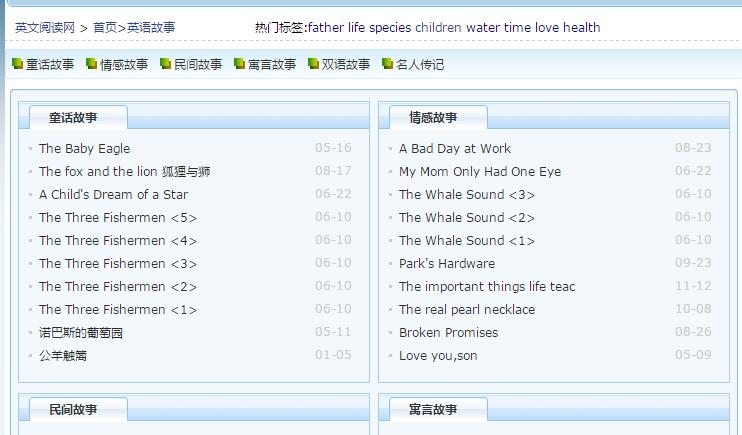
根据正则可以将每个类目都筛选出来
cateRex = 'class="title"><a href="(.*?)">(.*?)</a></div>'
pattern = re.compile(cateRex,re.S)
items = re.findall(pattern,html)
//items [<url->categoryname>,.....]
获取到每一个类目的url后,可以分别爬取每一个url,可以获取到对应的文章列表页
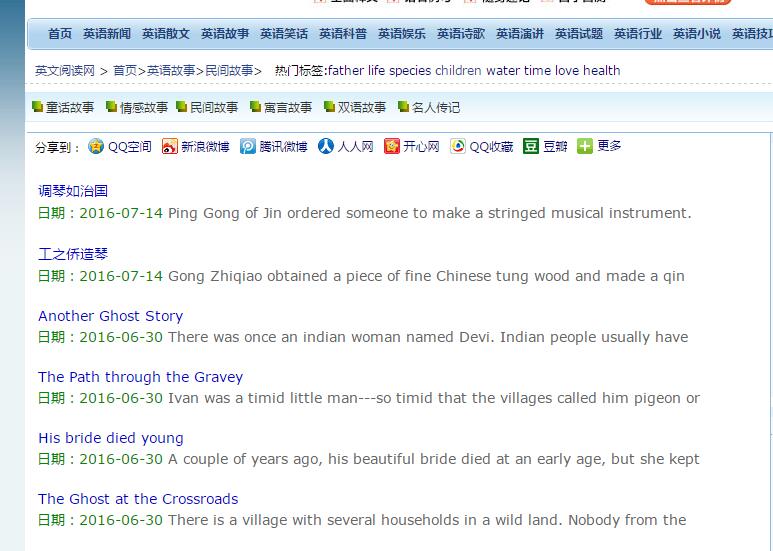
文章列表页,同理,可以针对类似的正则将每一个文章的题目和每一个文章的连接获取到,然后接着继续爬取每一个文章的具体正文。
2.数据入库
将爬取到的文章插入到Mysql数据库中
设计表:
文章具体信息表
CREATE TABLE `spider_english` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`categoryname` varchar(255) DEFAULT NULL COMMENT '文章类目',
`categoryurl` varchar(255) DEFAULT NULL COMMENT '文章类目url',
`articname` varchar(255) DEFAULT NULL COMMENT '文章题目',
`articurl` varchar(255) DEFAULT NULL COMMENT '文章url',
`artic` text COMMENT '文章',
`isread` int(2) DEFAULT NULL COMMENT '1为已推送,0为未推送',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=187 DEFAULT CHARSET=utf8;推送相关信息
CREATE TABLE `spider_english_history` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`artic` text,
`number` int(11) DEFAULT NULL COMMENT '推送次数',
`date` varchar(255) DEFAULT NULL COMMENT '文章推送日期',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=19 DEFAULT CHARSET=utf8;
3.文章推送
读取数据库中未推送的文章信息,推送,并且将isread置为1,插入推送历史信息表。
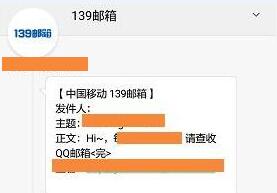
推送的方式为:短信推送+邮箱推送。
普通的发短信的推送是需要付费的,可以向139邮箱发送邮件,中国移动会自动发送短信~~~但是一般正文不会全部显示。
这里采用发短信提示邮箱有邮件,然后阅读邮件
最终成果如下:

4.核心代码:
#获取页面的html
def getHtml(url,header):
request = urllib.request.Request(url,headers=header)
response = urllib.request.urlopen(request)
page = response.read().decode('gbk')
return page
#获取故事的所有分类
def getCategory(html,rex):
pattern = re.compile(rex,re.S)
items = re.findall(pattern,html)
res = []
for item in items:
dict ={}
dict[item[0]] = item[1] # url -> name
res.append(dict)
return res
#获取故事的文章
def getArtic(html):
pattern = re.compile('dede_content">.*?<div>(.*?)</div> <br> <div class="dede_pages">',re.S)
items = re.findall(pattern,html)
return items发送邮件程序可以参考:http://www.runoob.com/python/python-email.html
5.定时任务
可以直接放到linux上,设置crontab
windows下可设置任务执行计划,参考:http://blog.csdn.net/wwy11/article/details/51100432















 9775
9775

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









