







一、MongoDB 使用规范与限制
MongoDB 灵活文档的优势
-
灵活库/集合命名及字段增减
-
同一字段可存储不同类型数据
-
Json 文档可多层次嵌套文档
-
对于开发而言最自然的表达
MongoDB 灵活文档的烦恼
-
数据库集合字段名千奇百怪
-
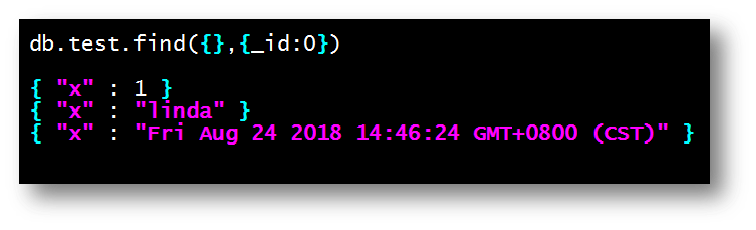
同一字段数据类型各不一样
-
业务异常可能写入“脏”数据
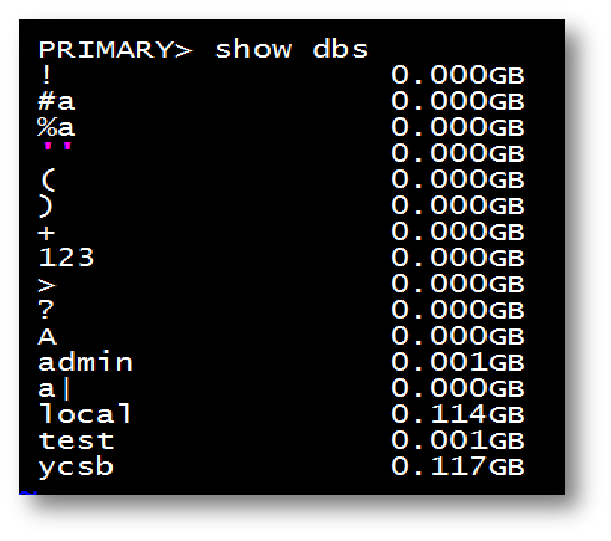
1.1 库命名规范
-
不能为空字符串 ""
-
不能以 $ 开头
-
不能包含 . 号 /\
-
数据库名大小写敏感
-
数据库名最长为 64 个字符
-
不能与系统库相同
最佳实践
-
数据库命名只包含小写英文字符加下划线 _
-
数据库名含多个单词考虑缩小并以下划线连接
-
如:package_manager
1.2 集合名规范
-
不能为空字符串 ""
-
不能以 system. 系统集合名开头
-
不因包含 ~!@#%^&*()-+
最佳实践
-
集合命名只包含下划线和小写英文字母
-
如: students_books
1.3 Bson 单文档的大小及嵌套限制
-
单文档不超过16 MB
-
嵌套不能超过100 层
如果单条记录超过 16 M 怎么办?
第一种办法:先处理后存储。可以先做压缩,或者也可以对字符进行先哈希,然后再存储,这样大概率就不会超过 16 MB。
第二种方法:通常来说 16 MB 的记录都可以直接写到文本文件里面,然后再将文件存到 MongoDB GridFS 里面或者先业务层处理后存储。
1.4 索引限制
-
单个集合最多包含 64 个索引
-
单个索引记录不超过 1024 字节
[failIndexKeyTooLong 默认 true 控制是否报错]
当然其实我们也有其他的方式来解决类似这样的一个问题这个我们后面再说
-
多列索引列个数最多不超过 31
-
前台模式 createIndexes内存限制500 MB
(maxIndexBuildMemoryUsageMegabytes 可调整)
-
不允许创建多列数组的组合索引
实际上为什么有这个限制呢?
MongoDB 如果索引字段是数组,那我们可以理解为对每个数组元素创建索引。如果要是多个数组字段建组合索引,就意味着它可能会产生笛卡尔级数据量的索引。所以为了避免这种索引的爆炸性增长,需要对此做了相应的一个限制。
-
TTL 索引如果是复合索引则过期将会失效
通常你想创建一个 TTL 索引,但创建的时候构建了多个字段的组合索引,那么 TTL 就会失效。
-
Hash 索引只支持单列 【<= 4.4 版本】
另外需要记住的就是哈希索引只支持单例,这个是在 4.4 之前的一个限制,到后面是做了调整,所以在这里也需要给大家提一下。我们本次分享为大部分内容的前提是小于等于 4.2 版本,主要原因在于 4.4 及其以上的 MongoDB 版本其实有很多企业里面都没有使用。
最佳实践
-
使用 background 模式批量创建索引
后台建索引意味着它不会阻塞我们的业务的写,否则的话就会加库级别的锁从而造成业务阻塞。当然还有一个情况就是当我们对同一个集合添加多个索引的时候,建议大家用 createIndexes 批量建索引。因为每次创建索引,实际上可以理解 MongoDB 都会去扫描整个集合,通过扫描整个集合去拿到对应字段的记录,然后将这些记录插入到索引文件里面,使用批量建索引只需要扫描一次,如果分开来建索引那么就需要扫描多次,故批量建索引能大大减少对业务的影响。
-
多列索引尽量不要超过 5 个字段
这个算是一个经验建议,当然 6 个字段也行。有时候要反过来想,当一个索引有 5 、6 个字段或者 7 、8 个字段的时候,我们应该第一时间要反思我们业务设计是否合理。当然有些业务场景比较特殊也确实有这种必要性,那该放开限制还的放开。
-
单个集合索引数量适当控制至 5 个
MongoDB 每次在数据插入更新删除的时候,实际上需要同步的去做索引的变更,所以索引越多,其实对于这些变更来说,它的代价就越大。所以,推荐创建尽量少的索引去满足更多的业务查询。
-
尽量避免对数组字段创建索引
前面说过,对存储数组的字段创建索引,实际上是多数组每个元素创建索引,同时,字段值更新也同步更新索引字段。所以,当数组元素量非常大的时候比如 1 w,5 w,这个时候的索引代价就会比较大。
1.5 副本集限制
-
副本集最多含有 50 个节点
-
副本集只可含 7 个投票节点
最佳问答
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 177
177











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









