






·spark认识
Spark使用Scala语言进行实现,它是一种面向对象、函数式编程语言,能够像操作本地集合对象一样轻松地操作分布式数据集,在Spark官网上介绍,它具有运行速度快、易用性好、通用性强和随处运行等特点。
spark特点
·运行速度快
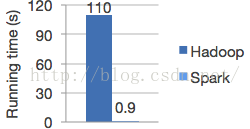
spark在内存中对数据进行迭代计算如果数据由内存读取是hadoop MapReduce的100倍。Spark是基于内存的迭代计算框架,适用于需要多次操作特定数据集的应用场合。需要反复操作的次数越多,所需读取的数据量越大,受益越大,数据量小但是计算密集度较大的场合,受益就相对较小.
·易用性好
支持Scala编程java编程 Python等语言(Scala是一种高效可扩展语言,使用简洁)
·一次编译,随意执行
spark运行在Hadoop,cloud上,能够读取HDFS,HBase Cassandra等数据源
·通用性强
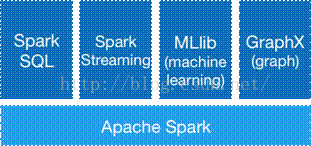
spark生态圈(BDAS)包括spark Core、spark SQL Spark Streaming等组件,这些组件提供spark Core处理内存计算框架
·Spak 和Hadoop区别
spark是在MapReduce上发展而来,继承了其分布式并行计算的优点并改进了MapReduce明显的缺陷:
1.提高了效率
Spark把中间数据放到内存中,迭代运算效率高。MapReduce中计算结果需要落地,保存到磁盘上,这样势必会影响整体速度,而Spark支持DAG图的分布式并行计算的编程框架,减少了迭代过程中数据的落地,提高了处理效率
2.容错性高
Spark引进了弹性分布式数据集RDD (Resilient Distributed Dataset) 的抽象,它是分布在一组节点中的只读对象集合,这些集合是弹性的,如果数据集一部分丢失,需要进行重建。
相比来说spark更加通用,spark提供了更多的数据集操作类型,处理节点之间通信模型不是向hadoop只采用Shuffle模式,而是采用用户可命名,控制中
间结果的存储,分区。
·Spark Core
1)提供了有向无环图(DAG)的分布式并行计算框架,并提供Cache机制来支持多次迭代计算或者数据共享,大大减少迭代计算之间读取数据局的开销,这对于需要进行多次迭代的数据挖掘和分析性能有很大提升
2)在Spark中引入了RDD (Resilient Distributed Dataset) 的抽象,它是分布在一组节点中的只读对象集合,这些集合是弹性的,如果数据集一部分丢失,则可以根据“血统”对它们进行重建,保证了数据的高容错性;
移动计算而非移动数据,RDD Partition可以就近读取分布式文件系统中的数据块到各个节点内存中进行计算
使用多线程池模型来减少task启动开稍
3)采用容错的、高可伸缩性的akka作为通讯框架
·Spark Streaming
SparkStreaming是一个对实时数据流进行高通量、容错处理的流式处理系统,可以对多种数据源(如Kdfka、Flume、Twitter、Zero和TCP 套接字)进行类似Map、Reduce和Join等复杂操作,并将结果保存到外部文件系统、数据库或应用到实时仪表盘。
·Spark SQL
SparkSQL的前身是Shark,Shark是伯克利实验室Spark生态环境的组件之一,它修改了内存管理、物理计划、执行三个模块,并使之能运行在Spark引擎上,从而使得SQL查询的速度得到10-100倍的提升。Shark过于依赖Hive,它是当时唯一运行在Hadoop上的SQL-on-Hadoop工具。但是MapReduce计算过程中大量的中间磁盘落地过程消耗了大量的I/O,降低运行效率.SparkSQL在数据兼容性、性能优化、组件扩展等方面做了很大提升。

















 918
918

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









