







 本文详细介绍了中文语音识别的基础知识,包括声音采集与量化,音频数据集如common_voice,以及使用wav2vec和whisper模型进行训练和推理的步骤。通过在huggingface上获取资源,读者可以学习如何微调whisper模型进行中文ASR任务。
本文详细介绍了中文语音识别的基础知识,包括声音采集与量化,音频数据集如common_voice,以及使用wav2vec和whisper模型进行训练和推理的步骤。通过在huggingface上获取资源,读者可以学习如何微调whisper模型进行中文ASR任务。
写在前面的话
本博客主要介绍了
1. 语音识别基础知识
2. 中文语音识别数据集
3. 语音识别常用模型方法
4. 自己训练一个中文语音识别模型
注意: 代码中所涉及的模型及数据集,均可从huggingface下载得到,代码中的路劲,需要根据自身实际情况稍做调整。
目录
语音识别基础
音视频开发基础入门|声音的采集与量化、音频数字信号质量、音频码率_量化后的声音信号-CSDN博客
https://huggingface.co/learn/audio-course/chapter1/audio_data
数据集
common_voice
包含大陆,香港,台湾等地的语音数据。
https://huggingface.co/datasets/fsicoli/common_voice_17_0
其它
模型
wav2vec
https://huggingface.co/facebook/wav2vec2-base
whipser
Whisper是一种用于自动语音识别(ASR)和语音翻译的预训练模型。Whisper模型经过680k小时的标记数据训练,显示出强大的能力,可以在不需要微调的情况下推广到许多数据集和领域。
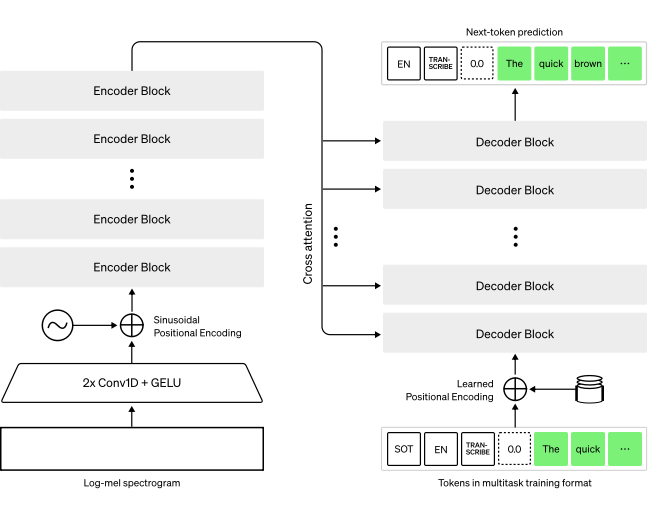
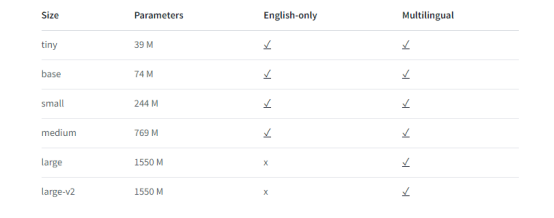
https://huggingface.co/docs/transformers/model_doc/whisper#transformers.WhisperProcessor
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 252
252

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









