






Linux进程地址空间
内核使用内存描述符结构体表示进程的地址空间,该结构体包含了和进程地址空间有关的全部信息。内存描述符由mm_struct结构体表示,定义在文件<linux/sched.h>中。进程地址空间由每个进程的线性地址区(vm_area_struct)组成。通过内核,进程可以给自己的地址空间动态的添加或减少线性区域。如下图是内存描述符mm_struct和线性区域描述符vm_area_struct的关系:


mm_users域记录正在使用该地址的进程数目。比如,如果两个进程共享该地址空间,那么mm_users的值便等于2;mm_count域是mm_struct的结构体的主引用计数,只要mm_users不为0,那么mm_count值就等于1.当mm_users值减为0(两个线程都退出)时,mm_count域的值才变为0。如果mm_count的值等于0,说明已经没有任何指向该mm_struct结构体的引用了,这时该结构体会被销毁。mmap和mm_rb这两个不同的数据结构描述的对象是相同的:该地址空间中的全部内存区域。mmap结构体最为链表,利于简单,高效地遍历所有元素;而mm_rb结构体作为红-黑树,更适合搜索指定元素。所有的mm_struct结构体通过自身的mmlist域连接在一个双向链表中,该链表的首元素是init_mm内存描述符,它代表0号进程的地址空间。在进程的进程描述符中,mm域存放着该进程使用的内存描述符。copy_process函数利用copy_mm函数复制父进程的内存描述符。像vfork和clone系统调用指定的CLONE_VM标志的,仅仅需要在调用copy_mm()函数中将mm域指向其父进程的内存描述符就可以了:
- if(clone_flags & CLONE_VM){
- atomic_inc(&oldmm->mm_users);
- mm = oldmm;
- goto good_mm;
- }
而fork系统调用产生的子进程中的mm_struct结构体实际是通过文件kernel/fork.c中的alloc_mm()宏从mm_cachep slab缓存中分配得到的。通常,每个进程都有一个唯一的mm_struct结构体,即唯一的进程地址空间。是否共享地址空间,几乎是进程和Linux中所谓线程间本质上的唯一区别。

vm_start域指向线性区域的首地址,vm_end域指向尾地址之后的第一个字节,也就是说,vm_start是线性区域的开始地址,vm_end是线性区域的结束地址。vm_mm域指向和VMA相关的mm_struct结构体,注意每个VMA对其相关的mm_struct结构体来说都是唯一的,所以即使两个独立的进程将同一个文件映射到各自的地址空间,他们分别都会有一个vm_area_struct结构体来标志自己的内存区域;但是如果两个线程共享一个地址空间,那么他们也同时共享其中的所有vm_area_struct结构体。
- #include <linux/module.h>
- #include <linux/init.h>
- #include <linux/proc_fs.h>
- #include <linux/list.h>
- #include <linux/types.h>
- #include <linux/sched.h>
- int read_myproc(char *page, char **start, off_t off, int count, int *eof, void *data){
- struct task_struct *p;
- struct vm_area_struct *first;
- p = list_entry(init_task.tasks.next, struct task_struct, tasks);
- printk("%20s %20s\n", "vm_area_start", "vm_area_end");
- for(first = p->mm->mmap; first != NULL;){
- printk("%20lx %20lx\n", first->vm_start, first->vm_end);
- first = first->vm->next;
- }
- return 0;
- }
- static int __init myproc_init(void){
- struct proc_dir_entry * e = create_proc_read_entry("myproc",0,NULL,read_myproc,NULL);
- e->read_proc = read_myproc;
- return 0;
- }
- static void __exit myproc_exit(void){
- removre_proc_entry("myproc",NULL);
- }
- module_init(myproc_init);
- module_exit(myproc_exit);
- MODULE_LICENSE("GPL");
- MODULE_AUTHOR("liwanpeng");
查看init进程的地址空间效果如下:

------------------------------------------------
内存映射与DMA
1、mmap系统调用的实现过程,该系统调用直接将设备内存映射到用户进程的地址空间。
2、用户空间内存如何映射到内核中(get_user_pages)。
3、直接内存访问(DMA),他使得外设具有直接访问系统内存的能力。
linux中地址类型:用户虚拟地址、内核虚拟地址、内核逻辑地址(与物理地址是线性关系)、物理地址
用户空间与内核空间:内核将4G的虚拟地址空间分割为用户空间与内核空间;在二者的上下文中使用同样的映射。内核无法操作没有映射到内核地址空间的内存。在内核地址中有一块地址空间专门用于用户空间到内核的虚拟映射。
低端内存:存在于内核空间上的逻辑内存地址。
高端内存:是指那些不存在逻辑地址的内存。
内核中处理内存的函数趋向使用指向page结构的指针,该数据结构用来保存内核需要的所有物理内存的信息
页表:处理器使用页表将虚拟地址转换为相应的物理地址。
虚拟内存区(VMA):用于管理进程地址空间中不同区域的内核数据结构。每个进程在编译、链接后形成的映象文件有一个代码段、数据段、还有堆栈段(如下图1所示),所有一个内存映射(至少)包含下面这些区域:
1)程序的可执行代码区域
2)多个数据区,其中包括初始化数据区、非初始化数据区及程序堆栈。
3)与每个活动的内存映射对应的区域

图1(进程虚拟空间的划分)
通常,进程所使用到的虚存空间不连续,且各部分虚存空间的访问属性也可能不同。所以一个进程的虚存空间需要多个vm_area_struct结构来描述。
在vm_area_struct结构的数目较少的时候,各个vm_area_struct按照升序排序,以单链表的形式组织数据(通过vm_next指针指向下一个vm_area_struct结构)。但是当vm_area_struct结构的数据较多的时候,仍然采用链表组织的化,势必会影响到它的搜索速度。针对这个问题,vm_area_struct还添加了vm_avl_hight(树高)、vm_avl_left(左子节点)、vm_avl_right(右子节点)三个成员来实现AVL树,以提高vm_area_struct的搜索速度。
假如该vm_area_struct描述的是一个文件映射的虚存空间,成员vm_file便指向被映射的文件的file结构,vm_pgoff是该虚存空间起始地址在vm_file文件里面的文件偏移,单位为物理页面。

图2 进程虚拟地址示意图
mmap系统调用所完成的工作就是准备这样一段虚存空间,并建立vm_area_struct结构体,将其传给具体的设备驱动程序,这些都是由内核完成。
用户空间进程调用mmap将设备内存映射到他的地址空间时,系统通过创建一个表示该映射的新VMA作为响应,支持mmap的驱动程序需要帮助进程完成VMA的初始化。
----------------------------------------------------------------------------------------------------------------------------------------------------------------------
mmap的实现原理和应用
https://blog.csdn.net/edwardlulinux/article/details/8604400
很多文章分析了mmap的实现原理。从代码的逻辑来分析,总是觉没有把mmap后读写映射区域和普通的read/write联系起来。不得不产生疑问:
1,普通的read/write和mmap后的映射区域的读写到底有什么区别。
2, 为什么有时候会选择mmap而放弃普通的read/write。
3,如果文章中的内容有不对是或者是不妥的地方,欢迎大家指正。
围绕着这两个问题分析一下,其实在考虑这些问题的同时不免和其他的很多系统机制产生交互。虽然是讲解mmap,但是很多知识还是为了阐明问题做必要的铺垫。这些知识也正是Linux的繁琐所在。一个应用往往和系统中的多种机制交互。这篇文章中尽量减少对源代码的引用和分析。把这样的工作留到以后的细节分析中。但是很多分析的理论依据还是来自于源代码。可见源代码的重要地位。
基础知识:
1, 进程每次切换后,都会在tlb base寄存器中重新load属于每一个进程自己的地址转换基地址。在cpu当前运行的进程中都会有current宏来表示当前的进程的信息。因为这个代码实现涉及到硬件架构的问题,为了避免差异的存在在文章中用到硬件知识的时候还是指明是x86的架构,毕竟x86的资料和分析的研究人员也比较多。其实arm还有其他类似的RISC的芯片,只要有mmu支持的,都会有类似的基地址寄存器。
2, 在系统运行进程之前都会为每一个进程分配属于它自己的运行空间。并且这个空间的有效性依赖于tlb base中的内容。32位的系统中访问的空间大小为4G。在这个空间中进程是“自由”的。所谓“自由”不是说对于4G的任何一个地址或者一段空间都可以访问。如果要访问,还是要遵循地址有效性,就是tlb base中所指向的任何页表转换后的物理地址。其中的有效性有越界,权限等等检查。
3, 任何一个用户进程的运行在系统分配的空间中。这个空间可以有
vma:struct vm_area_struct来表示。所有的运行空间可以有这个结构体描述。用户进程可以分为text data 段。这些段的具体在4G中的位置有不同的vma来描述。Vma的管理又有其他机制保证,这些机制涉及到了算法和物理内存管理等。请看一下两个图片:
图 一:HY:关注mm_struct的pgd和mmap域

图 二:

系统调用中的write和read:
这里没有指定确切的文件系统类型作为分析的对象。找到系统调用号,然后确定具体的文件系统所带的file operation。在特定的file operation中有属于每一种文件系统自己的操作函数集合。其中就有read和write。
图 三:
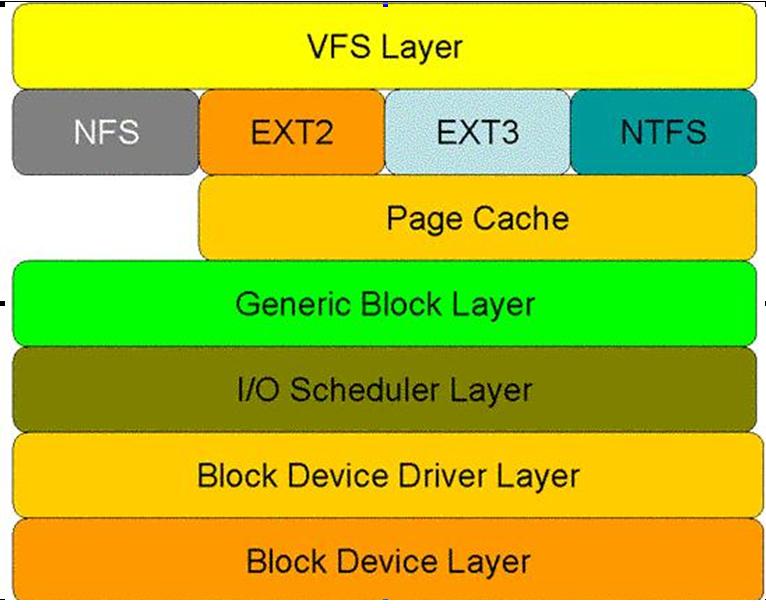
在真正的把用户数据读写到磁盘或者是存储设备前,内核还会在page cache中管理这些数据。这些page的存在有效的管理了用户数据和读写的效率。用户数据不是直接来自于应用层,读(read)或者是写入(write)磁盘和存储介质,而是被一层一层的应用所划分,在每一层次中都会有不同的功能对应。最后发生交互时,在最恰当的时机触发磁盘的操作,通过IO驱动写入磁盘和存储介质。这里主要强调page cache的管理。因为page的管理设计到了缓存,这些缓存以page的单位管理。在没有IO操作之前,暂时存放在系统空间中,而并未直接写入磁盘或者存贮介质。
系统调用中的mmap:
当创建一个或者切换一个进程的同时,会把属于这个当前进程的系统信息载入。这些系统信息中包含了当前进程的运行空间。当用户程序调用mmap后。函数会在当前进程的空间中找到适合的vma来描述自己将要映射的区域。这个区域的作用就是将mmap函数中文件描述符所指向的具体文件中内容映射过来。
原理是:mmap的执行,仅仅是在内核中建立了文件与虚拟内存空间的对应关系。用户访问这些虚拟内存空间时,页面表里面是没有这些空间的表项的。当用户程序试图访问这些映射的空间时,于是产生缺页异常。内核捕捉这些异常,逐渐将文件载入。所谓的载入过程,具体的操作就是read和write在管理pagecache。Vma的结构体中有很文件操作集。vma操作集中会有自己关于page cache的操作集合。这样,虽然是两种不同的系统调用,由于操作和调用触发的路径不同。但是最后还是落实到了page cache的管理。实现了文件内容的操作。
Ps:
文件的page cache管理也是很好的内容。涉及到了address space的操作。其中很多的内容和文件操作相关。
效率对比:
这里应用了网上一篇文章。发现较好的分析,着这里引用一下。
Mmap:
#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>
#include <sys/mman.h>
void main()
{
int fd = open("test.file", 0);
struct stat statbuf;
char *start;
char buf[2] = {0};
int ret = 0;
fstat(fd, &statbuf);
start = mmap(NULL, statbuf.st_size, PROT_READ, MAP_PRIVATE, fd, 0);
do {
*buf = start[ret++];
}while(ret < statbuf.st_size);
}
Read:
#include <stdio.h>
#include <stdlib.h>
void main()
{
FILE *pf = fopen("test.file", "r");
char buf[2] = {0};
int ret = 0;
do {
ret = fread(buf, 1, 1, pf);
}while(ret);
}
运行结果:
[xiangy@compiling-server test_read]$ time ./fread
real 0m0.901s
user 0m0.892s
sys 0m0.010s
[xiangy@compiling-server test_read]$ time ./mmap
real 0m0.112s
user 0m0.106s
sys 0m0.006s
[xiangy@compiling-server test_read]$ time ./read
real 0m15.549s
user 0m3.933s
sys 0m11.566s
[xiangy@compiling-server test_read]$ ll test.file
-rw-r--r-- 1 xiangy svx8004 23955531 Sep 24 17:17 test.file
可以看出使用mmap后发现,系统调用所消耗的时间远远比普通的read少很多。















 1880
1880











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









